El curso completo en ruso se puede encontrar en este enlace .
El curso de inglés original está disponible en este enlace .

Nuevas conferencias están programadas cada 2-3 días.
Contenido
- Entrevista con Sebastian Trun
- Introduccion
- Conjunto de datos de perros y gatos
- Imágenes de varios tamaños.
- Imágenes a color. Parte 1
- Imágenes a color. Parte 2
- Operación de convolución en imágenes en color
- La operación de submuestreo por el valor máximo en imágenes en color
- CoLab: gatos y perros
- Softmax y sigmoide
- Cheque
- Extensión de imagen
- Excepción
- CoLab: perros y gatos. Repetición
- Otras técnicas para prevenir el reentrenamiento
- Ejercicio: clasificación de imágenes en color
- Resumen
Softmax y Sigmoide
En nuestro último CoLab práctico, utilizamos la siguiente arquitectura de red neuronal convolucional:
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Tenga en cuenta que nuestra última capa (nuestro clasificador) consiste en una capa completamente conectada con dos neuronas de salida y una softmax activación softmax :
tf.keras.layers.Dense(2, activation='softmax')
Otro enfoque popular para resolver problemas de clasificación binaria es el uso de un clasificador, que consiste en una capa completamente conectada con 1 neurona de salida y sigmoid activación sigmoid :
tf.keras.layers.Dense(1, activation='sigmoid')
Ambas opciones funcionarán bien en el problema de clasificación binaria. Sin embargo, lo que debe tener en cuenta si decide usar la sigmoid activación sigmoid en su clasificador, también deberá cambiar la función de pérdida en el método model.compile() de sparse_categorical_crossentropy a binary_crossentropy como en el ejemplo a continuación:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Validación
En clases pasadas, estudiamos la precisión de nuestras redes neuronales convolucionales utilizando la métrica de accuracy en un conjunto de datos de prueba. Cuando desarrollamos una red neuronal convolucional para clasificar imágenes del conjunto de datos FASHION MNIST, obtuvimos un 97% de precisión en el conjunto de datos de entrenamiento y solo un 92% de precisión en el conjunto de datos de prueba. Todo esto sucedió porque nuestro modelo fue reentrenado. En otras palabras, nuestra red neuronal convolucional estaba empezando a recordar el conjunto de datos de entrenamiento. Sin embargo, pudimos aprender sobre la reentrenamiento solo después de entrenar y probar el modelo con los datos disponibles al comparar la precisión del conjunto de datos de entrenamiento y el conjunto de datos de prueba.
Para evitar este problema, a menudo utilizamos un conjunto de datos para la validación:
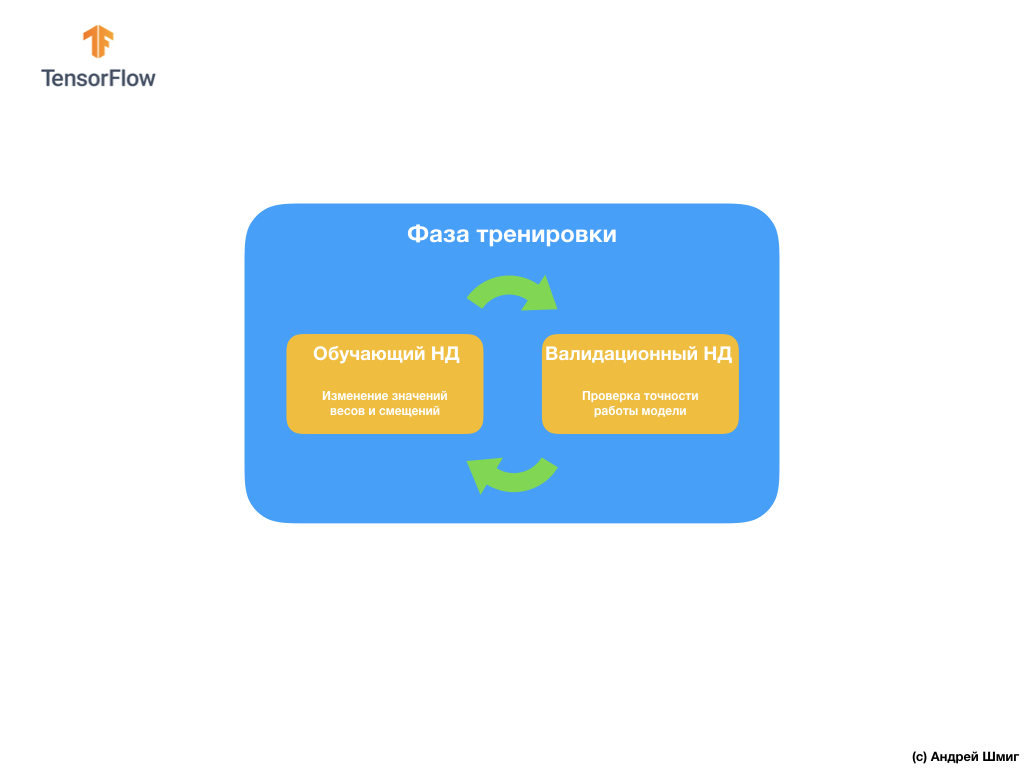
Durante el entrenamiento, nuestra red neuronal convolucional "ve" solo el conjunto de datos de entrenamiento y toma decisiones sobre cómo cambiar los valores de los parámetros internos: pesos y desplazamientos. Después de cada iteración de entrenamiento, verificamos el estado del modelo calculando el valor de la función de pérdida en el conjunto de datos de entrenamiento y en el conjunto de datos de validación. Vale la pena señalar y prestar especial atención al hecho de que el modelo no utiliza los datos del conjunto de validación para ajustar los valores de los parámetros internos. La verificación de la precisión del modelo en el conjunto de datos de validación solo nos dice qué tan bien funciona nuestro modelo en este mismo conjunto de datos. Por lo tanto, los resultados del modelo en el conjunto de datos de validación nos dicen qué tan bien nuestro modelo ha aprendido a generalizar los datos obtenidos y aplicar esta generalización a un nuevo conjunto de datos.
La idea es que, dado que no usamos el conjunto de datos de validación cuando entrenamos el modelo, probar el modelo en el conjunto de validación nos permitirá comprender si el modelo está reentrenado o no.
Veamos un ejemplo.
En CoLab, que realizamos algunos puntos arriba, entrenamos nuestra red neuronal durante 15 iteraciones.
Epoch 15/15 10/10 [===] - loss: 1.0124 - acc: 0.7170 20/20 [===] - loss: 0.0528 - acc: 0.9900 - val_loss: 1.0124 - val_acc: 0.7070
Si observamos la precisión de las predicciones en los conjuntos de datos de entrenamiento y validación en la decimoquinta iteración de entrenamiento, podemos ver que hemos logrado una alta precisión en el conjunto de datos de entrenamiento y un indicador significativamente bajo en el conjunto de datos de validación: 0.9900 versus 0.7070 .
Este es un signo obvio de reciclaje. La red neuronal recordó el conjunto de datos de entrenamiento, por lo tanto, funciona con una precisión increíble en los datos de entrada. Sin embargo, tan pronto como se trata de verificar la precisión en un conjunto de datos de validación que el modelo no "vio", los resultados se reducen significativamente.
Una forma de evitar el reentrenamiento es estudiar cuidadosamente el gráfico de los valores de la función de pérdida en los conjuntos de datos de entrenamiento y validación en todas las iteraciones de entrenamiento:
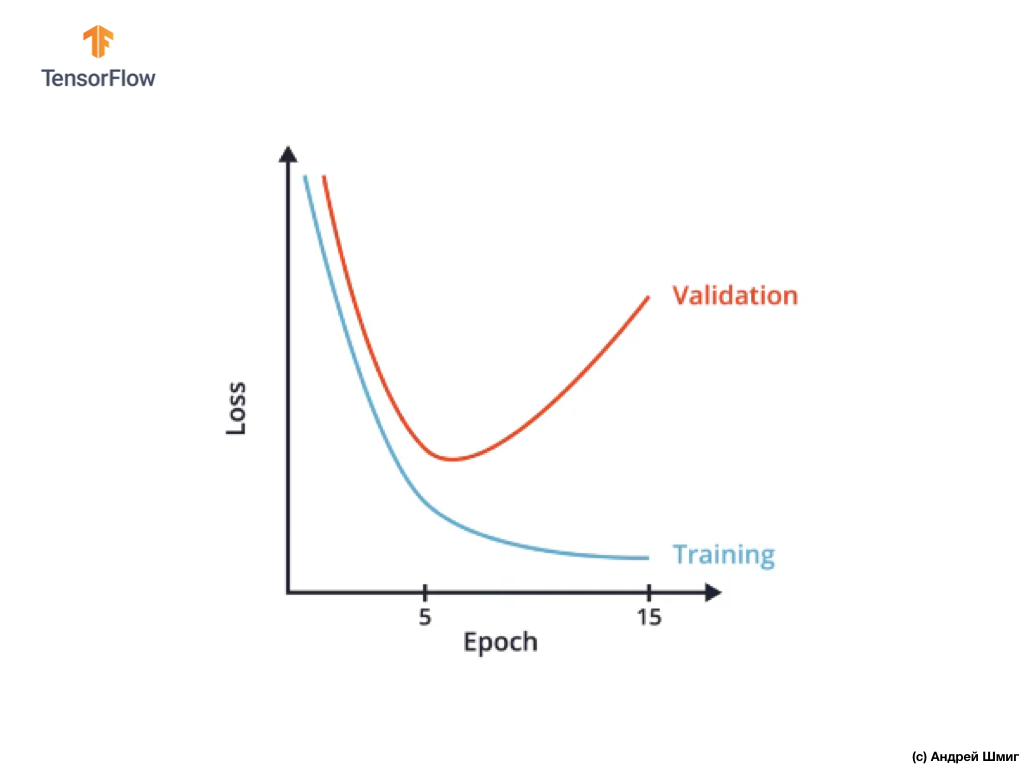
En CoLab, creamos un gráfico similar y obtuvimos algo similar al gráfico anterior de la dependencia de la función de pérdida en la iteración de entrenamiento.
Puede notar que después de una determinada iteración de entrenamiento, el valor de la función de pérdida en el conjunto de datos de validación comienza a aumentar, mientras que el valor de la función de pérdida en el conjunto de datos de entrenamiento continúa disminuyendo.
Al final de la 15ª iteración de entrenamiento, notamos que el valor de la función de pérdida en el conjunto de datos de validación es extremadamente alto, y el valor de la función de pérdida en el conjunto de datos de entrenamiento es extremadamente pequeño. En realidad, este es el indicador del reentrenamiento de la red neuronal.
Al observar cuidadosamente el gráfico, puede comprender que, literalmente, después de algunas iteraciones de entrenamiento, nuestra red neuronal comienza a almacenar simplemente datos de entrenamiento, lo que significa que la capacidad del modelo para generalizar se reduce, lo que conduce a un deterioro en la precisión del conjunto de datos de validación.
Como probablemente ya haya entendido, el conjunto de datos de validación nos permite determinar la cantidad de iteraciones de entrenamiento que deben realizarse para que nuestra red neuronal convolucional sea precisa y, al mismo tiempo, no se vuelva a entrenar.
Tal enfoque puede ser extremadamente útil si tenemos la opción de varias arquitecturas de redes neuronales convolucionales:

Por ejemplo, si decide el número de capas en una red neuronal convolucional, puede crear varias arquitecturas de redes neuronales y luego comparar su precisión utilizando un conjunto de datos para la validación.
La arquitectura de la red neuronal, que le permite alcanzar el valor mínimo de la función de pérdida y será la mejor para resolver su tarea.
La siguiente pregunta que puede tener es ¿por qué crear un conjunto de datos de validación si ya tenemos un conjunto de datos de prueba? ¿Podemos usar un conjunto de datos de prueba para la validación?
El problema es que, a pesar del hecho de que no usamos el conjunto de datos de validación en el proceso de capacitación del modelo, usamos los resultados de trabajar en el conjunto de datos de prueba para mejorar la precisión del modelo, lo que significa que el conjunto de datos de prueba afecta los pesos y sesgos en los nervios red
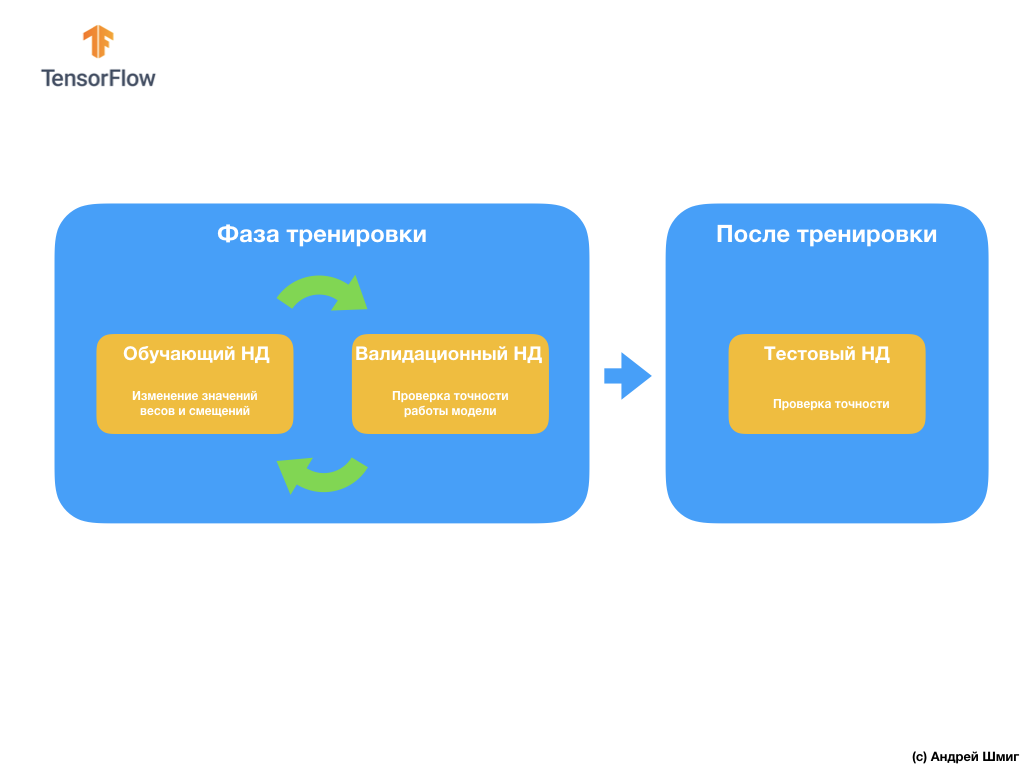
Es por esta razón que necesitamos un conjunto de datos de validación que nuestro modelo nunca haya visto antes para verificar con precisión su rendimiento.
Acabamos de descubrir cómo un conjunto de datos validado puede ayudarnos a evitar el reciclaje. En las siguientes partes, hablaremos sobre la expansión de datos (el llamado aumento) y la desconexión (el llamado abandono) de las neuronas, dos técnicas populares que también pueden ayudarnos a evitar el reentrenamiento.
Extensión de imagen (aumento)
Al entrenar redes neuronales para determinar objetos de una determinada clase, queremos que nuestra red neuronal encuentre estos objetos, independientemente de su ubicación y tamaño en la imagen.
Por ejemplo, supongamos que queremos entrenar nuestra red neuronal para reconocer perros en imágenes:

Por lo tanto, queremos que nuestra red neuronal determine la presencia de un perro en la imagen, independientemente de qué tan grande sea el perro y en qué parte de la imagen sea, si parte del perro es visible o todo el perro. Queremos asegurarnos de que nuestra red neuronal pueda procesar todas estas opciones durante el entrenamiento.
Si tienes la suerte y tienes un gran conjunto de datos de entrenamiento, entonces podemos decir con confianza que tienes suerte y que es poco probable que tu red neuronal se vuelva a entrenar. Sin embargo, lo que sucede con bastante frecuencia, tenemos que trabajar con un conjunto limitado de imágenes (datos de entrenamiento), que, a su vez, conducirán a nuestra red neuronal convolucional con una alta probabilidad de reentrenamiento y reducirán su capacidad de generalizar y producir el resultado deseado en datos que no "vio" antes.
Este problema se puede resolver utilizando una técnica llamada "extensión" (aumento de imagen). La expansión de imágenes (datos) funciona creando (generando) nuevas imágenes para el entrenamiento mediante la aplicación de transformaciones arbitrarias del conjunto original de imágenes del conjunto de entrenamiento.
Por ejemplo, podemos tomar una de las imágenes de origen de nuestro conjunto de datos de entrenamiento y aplicarle varias transformaciones arbitrarias: voltearla en X grados, reflejarla horizontalmente y hacer un aumento arbitrario.

Al agregar las imágenes generadas a nuestro conjunto de datos de entrenamiento, estamos convencidos de que nuestra red neuronal "verá" un número suficiente de ejemplos diferentes para el entrenamiento. Como resultado de tales acciones, nuestra red neuronal convolucional se generalizará mejor y trabajará en los datos que aún no ha visto y podremos evitar el reentrenamiento.
En la siguiente parte, aprenderemos qué es un abandono (un apagado), otra técnica para evitar sobreajustar un modelo.
Excepción (abandono)
En esta parte, aprenderemos una nueva técnica: el abandono, que también nos ayudará a evitar un entrenamiento excesivo del modelo. Como ya sabemos desde las primeras partes, la red neuronal optimiza los parámetros internos (pesos y desplazamientos) para minimizar la función de pérdida.
Uno de los problemas que se pueden encontrar al entrenar una red neuronal son los valores enormes en una parte de la red neuronal y los valores pequeños en la otra parte de la red neuronal.

Como resultado, resulta que las neuronas con mayor peso juegan un papel más importante en el proceso de aprendizaje, mientras que las neuronas con menor peso dejan de ser significativas y están cada vez menos sujetas a cambios. Una forma de evitar esto es usar un abandono arbitrario de neuronas.
Apagado (abandono): el proceso de apagado selectivo de neuronas en el proceso de aprendizaje.
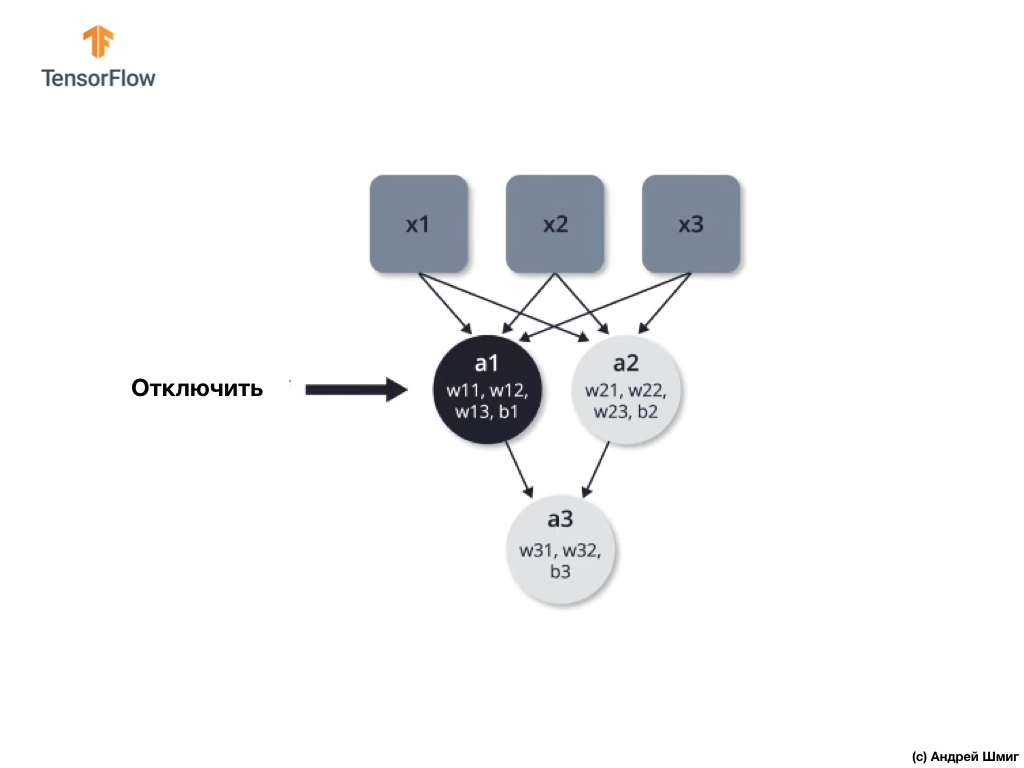
El apagado selectivo de algunas neuronas en el proceso de aprendizaje le permite involucrar activamente a otras neuronas en el aprendizaje. Durante las iteraciones de entrenamiento, deshabilitamos arbitrariamente algunas neuronas.
Veamos un ejemplo. Imagine que en la primera iteración de entrenamiento, apagamos dos neuronas resaltadas en negro:
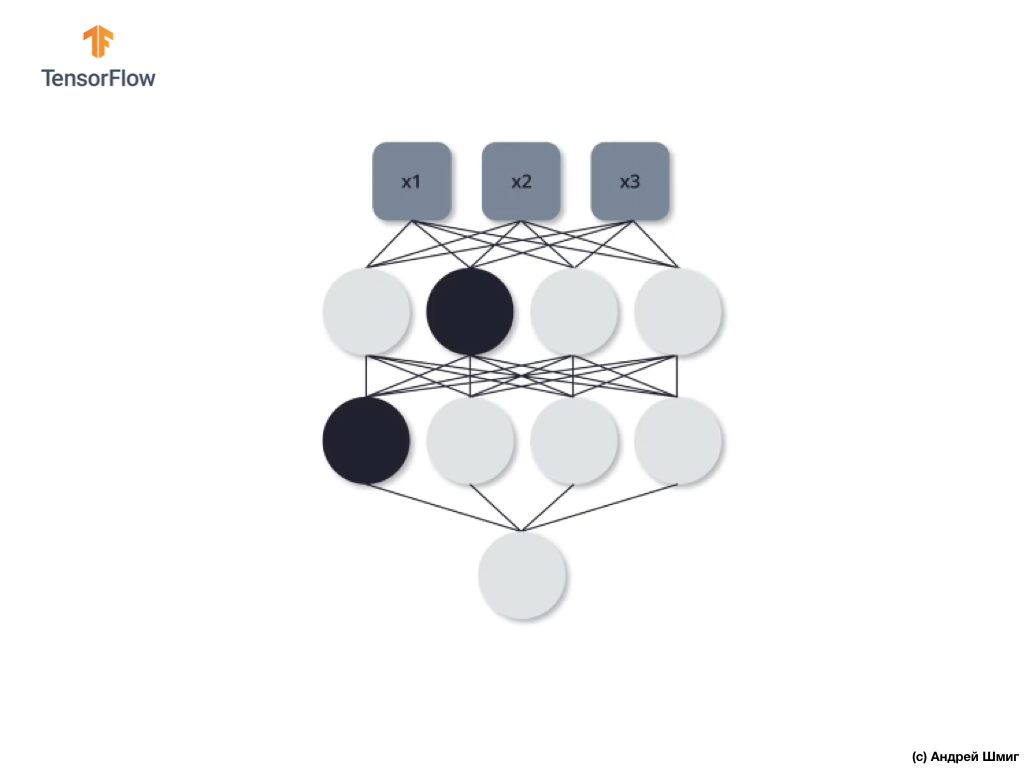
Los procesos de propagación directa y propagación inversa se producen sin el uso de dos neuronas aisladas.
En la segunda iteración de entrenamiento, decidimos no usar las siguientes tres neuronas: desactívelas:

Como en el caso anterior, en los procesos de propagación directa e inversa, no utilizamos estas tres neuronas. En la última iteración del tercer entrenamiento, decidimos no usar estas dos neuronas:
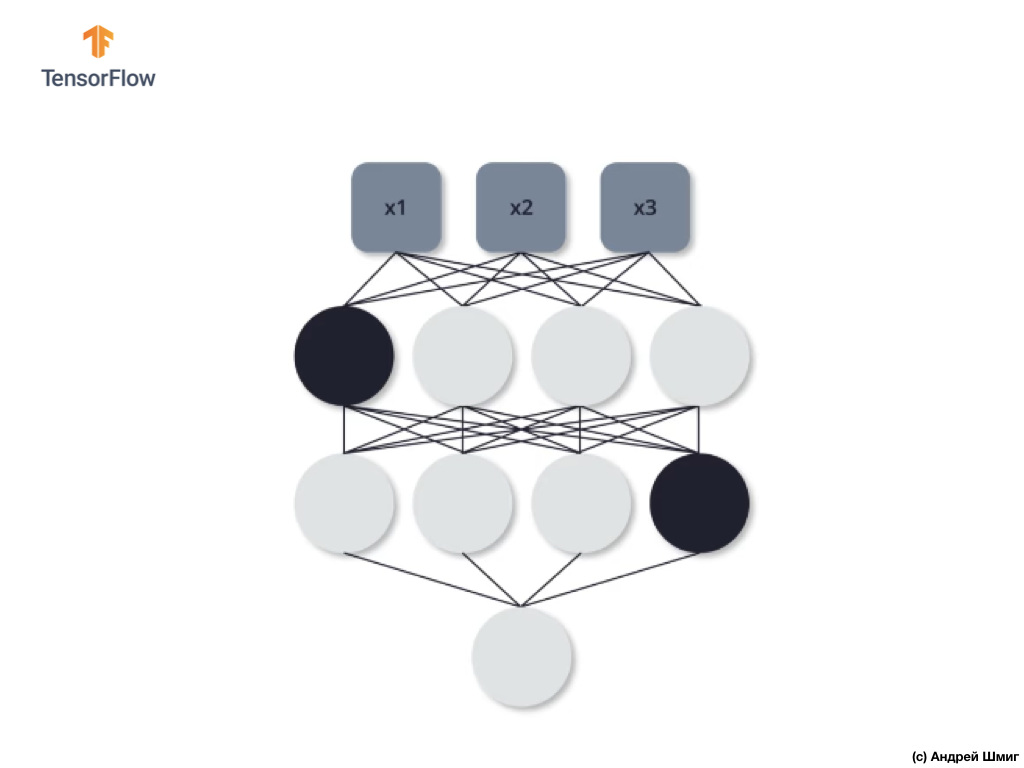
Y en este caso, no usamos neuronas desconectadas en los procesos de propagación directa e inversa. Y así sucesivamente.
Al entrenar nuestra red neuronal de esta manera, podemos evitar el reentrenamiento. Podemos decir que nuestra red neuronal se está volviendo más estable, porque con este enfoque, no puede confiar en absolutamente todas las neuronas para resolver el problema. Por lo tanto, otras neuronas comienzan a tomar una parte más activa en la formación del valor de salida requerido y también comienzan a hacer frente a la tarea.
En la práctica, este enfoque requiere indicar la probabilidad de eliminar cada una de las neuronas en cualquier iteración de entrenamiento. Tenga en cuenta que, al indicar la probabilidad de que nos encontremos en una situación en la que algunas neuronas se desconectarán con más frecuencia que otras, y algunas no se desconectarán en absoluto. Sin embargo, esto no es un problema, porque este proceso se realiza muchas veces y, en promedio, cada neurona con la misma probabilidad puede desconectarse.
Ahora apliquemos el conocimiento teórico adquirido en la práctica y refinemos nuestro clasificador de imágenes de gatos y perros.
CoLab: perros y gatos. Repetición
CoLab en inglés está disponible en este enlace .
CoLab en ruso está disponible en este enlace .
Gatos VS Perros: clasificación de imágenes con extensión
En este tutorial, discutiremos cómo clasificar las imágenes de gatos y perros. Desarrollaremos un clasificador de imágenes utilizando el modelo tf.keras.Sequential y usaremos tf.keras.Sequential para cargar los datos.
Ideas para ser cubiertas en esta parte:
Obtendremos experiencia práctica en el desarrollo de un clasificador y desarrollaremos una comprensión intuitiva de los siguientes conceptos:
- Construir un modelo de flujo de datos ( tuberías de entrada de datos ) usando la clase
tf.keras.preprocessing.image.ImageDataGenerator (¿Cómo trabajar eficientemente con datos en el disco que interactúan con el modelo?) - Reciclaje: ¿qué es y cómo determinarlo?
- El aumento de datos y el método de abandono son técnicas clave en la lucha contra el reciclaje en las tareas de reconocimiento de patrones que implementaremos en nuestro proceso de capacitación modelo.
Seguiremos el enfoque básico en el desarrollo de modelos de aprendizaje automático:
- Explore y comprenda datos
- Configurar flujo de entrada
- Construir modelo
- Modelo de tren
- Modelo de prueba
- Mejorar modelo / repetir proceso
Antes de comenzar ...
Antes de comenzar el código en el editor, le recomendamos que restablezca todas las configuraciones en Runtime -> Restablecer todo en el menú superior. Tal acción ayudará a evitar problemas con la falta de memoria, si trabajó en paralelo o trabajó con varios editores.
Importar paquetes
Comencemos importando los paquetes que necesita:
os - leer archivos y estructuras de directorios;numpy : para algunas operaciones matriciales fuera de TensorFlow;matplotlib.pyplot : trazar y mostrar imágenes de un conjunto de datos de prueba y validación.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
Importar TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Carga de datos
Comenzamos el desarrollo de nuestro clasificador cargando un conjunto de datos. El conjunto de datos que utilizamos es una versión filtrada del conjunto de datos Dogs vs Cats del servicio Kaggle (al final, Microsoft Research proporciona este conjunto de datos).
En el pasado, CoLab y yo usamos un conjunto de datos del propio módulo TensorFlow Dataset , que es extremadamente conveniente para el trabajo y las pruebas. En este CoLab, sin embargo, utilizaremos la clase tf.keras.preprocessing.image.ImageDataGenerator para leer datos del disco. Por lo tanto, primero debemos descargar el conjunto de datos Dog VS Cats y descomprimirlo.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
El conjunto de datos que descargamos tiene la siguiente estructura:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Para obtener la lista completa de directores, puede usar el siguiente comando:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
Salida (al comenzar desde CoLab):
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Ahora asigne las rutas correctas a los directorios con los conjuntos de datos para capacitación y validación de las variables:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Comprender los datos y su estructura.
Veamos cuántas imágenes de gatos y perros tenemos en los conjuntos de datos de prueba y validación (directorios).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
Conclusión
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Establecer parámetros del modelo
Para mayor comodidad, colocaremos la instalación de las variables que necesitamos para un mayor procesamiento de datos y capacitación de modelos en un anuncio separado:
BATCH_SIZE = 100
Extensión de datos
La reentrenamiento generalmente ocurre cuando hay pocos ejemplos de capacitación en nuestro conjunto de datos. Una forma de eliminar la escasez de datos es expandirlos al número correcto de instancias y la variabilidad correcta. La extensión de datos es el proceso de generar datos a partir de instancias existentes mediante la aplicación de diversas transformaciones al conjunto de datos original. El propósito de este método es aumentar el número de instancias de entrada únicas que el modelo nunca volverá a ver, lo que, a su vez, permitirá que el modelo generalice mejor los datos de entrada y muestre una mayor precisión en el conjunto de datos de validación.
Usando tf.keras podemos implementar tales transformaciones aleatorias y generar nuevas imágenes a través de la clase ImageDataGenerator . Será suficiente para nosotros pasar en forma de parámetros varias transformaciones que nos gustaría aplicar a las imágenes, y la clase misma se encargará del resto durante el entrenamiento del modelo.
Primero, escriba una función que muestre imágenes obtenidas como resultado de transformaciones aleatorias. Luego examinaremos con más detalle las transformaciones utilizadas en el proceso de expansión del conjunto de datos original.
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show()
Voltear la imagen horizontalmente
Podemos comenzar con una conversión simple: volteo horizontal de la imagen. Veamos cómo se verá esta transformación aplicada a nuestras imágenes de origen. horizontal_flip=True ImageDataGenerator .
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
. ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):
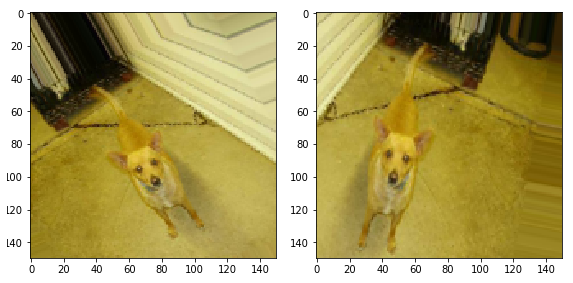
. 45.
image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
— 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

— 50%.
image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
, — 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):

, , , ImageDataGenerator .
— , 45 , , , .
image_gen_train = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) train_data_gen = image_gen_train.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
:
Found 2000 images belonging to 2 classes.
, .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

, , , . , , .
image_gen_val = ImageDataGenerator(rescale=1./255) val_data_gen = image_gen_val.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
4 .
0.5. , 50% 0. .
512 relu . — — softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.5), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
adam . sparse_categorical_crossentropy . , accuracy metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
summary :
model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0 _________________________________________________________________
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
:
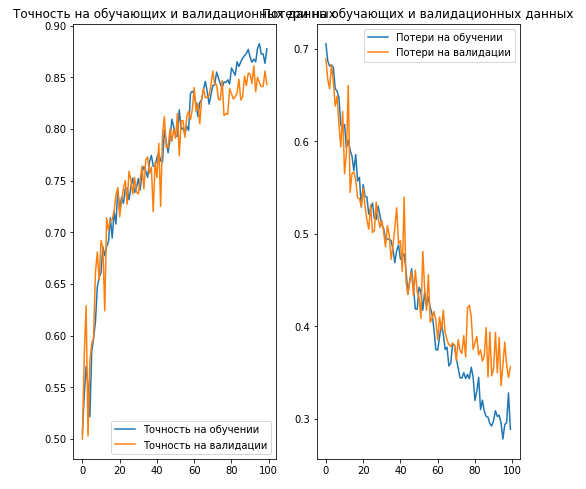
, :
- : ( ).
- (.. augmentation) : .
- / (.. dropout) : ( , ).
, . .
:
CoLab .
CoLab .
. CoLab . CoLab . CoLab , .
CoLab. CoLab , , .
!
# tf.keras
CoLab . tf.keras.Sequential , ImageDataGenerator .
. os , numpy python- numpy- , , matplotlib.pyplot .
from __future__ import absolute_import, division, print_function, unicode_literals import os import numpy as np import glob import shutil import matplotlib.pyplot as plt
TODO: TensorFlow Keras-
TensorFlow tf Keras- , . , ImageDataGenerator - Keras .
— . .
.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz" zip_file = tf.keras.utils.get_file(origin=_URL, fname="flower_photos.tgz", extract=True) base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')
, , 5 :
:
classes = ['', '', '', '', '']
, , :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips
. . , .
2 train val 5 - ( ). , 80% , 20% . :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips |__ train |______ daisy: [1.jpg, 2.jpg, 3.jpg ....] |______ dandelion: [1.jpg, 2.jpg, 3.jpg ....] |______ roses: [1.jpg, 2.jpg, 3.jpg ....] |______ sunflowers: [1.jpg, 2.jpg, 3.jpg ....] |______ tulips: [1.jpg, 2.jpg, 3.jpg ....] |__ val |______ daisy: [507.jpg, 508.jpg, 509.jpg ....] |______ dandelion: [719.jpg, 720.jpg, 721.jpg ....] |______ roses: [514.jpg, 515.jpg, 516.jpg ....] |______ sunflowers: [560.jpg, 561.jpg, 562.jpg .....] |______ tulips: [640.jpg, 641.jpg, 642.jpg ....]
, , . .
for cl in classes: img_path = os.path.join(base_dir, cl) images = glob.glob(img_path + '/*.jpg') print("{}: {} ".format(cl, len(images))) train, val = images[:round(len(images)*0.8)], images[round(len(images)*0.8):] for t in train: if not os.path.exists(os.path.join(base_dir, 'train', cl)): os.makedirs(os.path.join(base_dir, 'train', cl)) shutil.move(t, os.path.join(base_dir, 'train', cl)) for v in val: if not os.path.exists(os.path.join(base_dir, 'val', cl)): os.makedirs(os.path.join(base_dir, 'val', cl)) shutil.move(v, os.path.join(base_dir, 'val', cl))
:
train_dir = os.path.join(base_dir, 'train') val_dir = os.path.join(base_dir, 'val')
, , , . — (.. augmentation) . . , , — , . .
tf.keras , — ImageDataGenerator . .
. — () batch_size , IMG_SHAPE .
TODO:
100 batch_size 150 IMG_SHAPE :
batch_size = IMG_SHAPE =
TODO:
ImageDataGenerator , , . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 45 . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 50%. .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator :
flow_from_directory . , , , .
image_gen_train = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
. , , ImageDataGenerator , . flow_from_directory . , , . .
image_gen_val = val_data_gen =
TODO:
, 3 — . 16 , — 32 , — 64 . 33. 22.
Flatten , 512 . 5 , softmax . relu . , , 20%.
model =
TODO:
, adam sparse_categorical_crossentropy . , compile(...) .
TODO:
, fit_generator fit , . fit_generator ImageDataGenerator . 80 , fit_generator -.
epochs = history =
TODO: /
, :
acc = val_acc = loss = val_loss = epochs_range =
TODO:
( + ) 512 . . . , , .. , ImageDataGenerator — . , .
?
.
RGB- :
- : , ( );
- : 3D-;
- RGB- : 3 : , ;
- : (). , (). — .
- : . , .
- : . , .
:
. , . .
… call-to-action — , share :)
YouTube
Telegrama
VKontakte