Buen día, Khabravchane. Trabajo en Veeam Software y soy uno de los desarrolladores de nuestra solución de respaldo de Linux. Por ocupación, me encontré con BTRFS. Más recientemente, pasó del estado de "aún no adecuado" al estado de "estable". Y mientras sus primeros usuarios en la red discutían áreas problemáticas y problemas de estabilidad, en Veeam lo empujamos con una varita e intentamos hacer una copia de seguridad. Resultó, por decirlo suavemente, no mucho: es demasiado diferente, no como los sistemas de archivos tradicionales. Tuve que estudiar muchos aspectos y recolectar muchos rastrillos antes de aprender a trabajar con ellos. En el proceso de aprendizaje, BTRFS logró impresionarme, tanto en el buen sentido como no tanto. Estoy seguro de que no dejará indiferente a ningún especialista en TI del mundo Linux: algunos escupirán, otros elogiarán.
Si has oído hablar de este sistema de archivos, pero no sabes por qué, si estás interesado en los detalles o estás buscando dónde empezar a conocerlo, te invito a que te contacte.
Introduccion
BTRFS (B-Tree Filesystem): sistema de archivos para sistemas operativos tipo Unix, basado en la técnica Copy on Write (CoW), diseñado para facilitar la escala del sistema de archivos, un alto grado de confiabilidad y seguridad de los datos, flexibilidad de configuración y facilidad de administración, mientras se mantiene Al mismo tiempo de alta velocidad. Al menos eso es lo que dice la
página wiki principal .
Para cumplir con las formalidades, enumeramos las características principales de btrfs:
- Tamaño máximo de archivo 2 ^ 64 bytes
- Mesa dinámica de inodo
- Deduplicación de datos
- Almacenamiento efectivo de archivos de tamaños muy pequeños y muy grandes
- Crear subwolums e instantáneas
- Cuotas de subvolumen
- Sumas de verificación para datos y metadatos
- La capacidad de combinar múltiples unidades en un solo sistema de archivos
- Crear una configuración RAID a nivel del sistema de archivos
- Compresión de datos
- Desfragmentar datos sobre la marcha
Quiero advertirle de inmediato que BTRFS se está desarrollando activamente, y algunos puntos pueden diferir de una versión a otra. El enlace:
https://btrfs.wiki.kernel.org/index.php/Changelog, puede averiguar cuándo se agregó, modificó o arregló la funcionalidad.
Sí, BTRFS es un sistema de archivos joven y moderno que resuelve una amplia gama de tareas, pero no sin sus inconvenientes:
- Su desarrollo activo conduce a un cambio en cualquier punto clave en el que las utilidades de terceros puedan confiar al trabajar con él.
- A pesar de las garantías de los desarrolladores sobre la estabilidad de BTRFS, los usuarios regularmente encuentran problemas que pueden conducir a la pérdida de datos. Como regla, son de naturaleza "flotante", por lo que aún no han sido estudiados y corregidos.
- Alta susceptibilidad a la fragmentación.
- Documentación escasa ya veces desactualizada.
Una página completa está dedicada a los problemas del sistema de archivos en diferentes versiones de los núcleos:
https://btrfs.wiki.kernel.org/index.php/Gotchas . Le recomiendo encarecidamente que mire allí: resulta muy interesante y no obvio.
Estructura BTRFS
El dispositivo BTRFS simplificado se puede dividir en los siguientes niveles:

Los dispositivos de bloque están ubicados en el nivel más bajo, representando uno o más espacios de direcciones físicas separados (el mismo "físico" que los dispositivos de bloque, pero estos ya son detalles). A través de estructuras especiales, los bloques asignados de memoria física se combinan en un solo espacio de dirección virtual.
Las estructuras y bloques de metadatos con datos de usuario (extensiones) ya se abordan a nivel lógico. Como resultado, los datos ubicados secuencialmente a un nivel lógico pueden residir físicamente en diferentes dispositivos de bloque.
Las estructuras de metadatos se pueden dividir en niveles. Por supuesto, no los clasificaré, hay muchos de ellos, y esos detalles de bajo nivel son el tema de un artículo separado. Es importante aquí que algunas estructuras en la jerarquía resulten ser de mayor nivel que otras, y en la parte superior habrá una estructura que es un subvolumen.
Subvolumen es un tipo de punto de entrada, o más bien, los elementos raíz del sistema de archivos. Forman una capa separada de representación de datos, que encapsula el trabajo de las capas inferiores, presentando los datos del usuario en la forma habitual: directorios y archivos. Además, los sublobos son un elemento clave del mecanismo CoW en BTRFS. Los mismos archivos en dos subvolúmenes pueden resultar ser el mismo conjunto de datos en los niveles inferiores.
La última capa es la capa de datos. Como el usuario los ve. Estos son archivos y directorios ubicados en subvolumen.
Pero suficiente teoría. ¡Es hora de pasar a practicar!
Btrfs-progs
Este es un conjunto estándar de utilidades para administrar BTRFS. Dependiendo del paquete de distribución, el paquete con estas utilidades en el repositorio puede tener diferentes nombres:
btrfsprogs ,
btrfs-progs ,
btrfs-tools , etc. Si su repositorio no tenía nada similar, siempre puede compilarlo manualmente, las fuentes no están muy lejos:
https://github.com/kdave/btrfs-progs .
Las utilidades más importantes en este paquete son
btrfs y
mkfs.btrfs . Desde el segundo, creo, todo está muy claro: es necesario crear BTRFS en un dispositivo de bloque. Primero,
btrfs es la utilidad principal que te permite hacer el resto. Una especie de "cuchillo suizo".
En este artículo, utilicé la versión v4.15.1. La utilidad se está desarrollando de manera muy activa y existen diferencias notables de una versión a otra. Entonces, si no tenía el comando necesario, verifique la versión de la utilidad
btrfs , es posible que ya no esté actualizada.
Además, lo más probable es que las utilidades
btrfsck y
btrfstune se encuentren en el paquete.
- El primero de ellos sirve para verificar el sistema de archivos en busca de errores y para correcciones posteriores, sin embargo, no recomiendo usarlo: está en estado obsoleto , su funcionalidad se ha movido al comando de verificación btrfs .
- El segundo le permite realizar algunas operaciones útiles en btrfs, por ejemplo, cambiar el identificador único del sistema de archivos (FS UUID) o habilitar cierta funcionalidad del sistema de archivos.
Además de las utilidades enumeradas anteriormente, hay varias utilidades más en el paquete, pero son principalmente necesarias para depurar btrfs y no nos serán útiles en este artículo.
Formatear un disco en BTRFS
En la práctica, todo es más simple. Comencemos con una unidad.
El formateo de un solo disco en btrfs se produce con el comando habitual:
mkfs.btrfs /dev/sdc -L single_drive
En respuesta, la utilidad generará los parámetros del sistema de archivos creado en la consola:
btrfs-progs v4.15.1 See http://btrfs.wiki.kernel.org for more information. Label: single_drive UUID: 59307d69-6d2f-4d2e-aae2-a5189ad3c256 Node size: 16384 Sector size: 4096 Filesystem size: 1.00GiB Block group profiles: Data: single 8.00MiB Metadata: DUP 51.19MiB System: DUP 8.00MiB SSD detected: no Incompat features: extref, skinny-metadata Number of devices: 1 Devices: ID SIZE PATH 1 1.00GiB /dev/sdc
Veamos los parámetros presentados.
Al marcar un dispositivo de bloque, por defecto btrfs aplicará duplicación a los metadatos y datos del sistema, y los datos del usuario permanecerán en los medios en una sola copia. La creación de btrfs en varios discos a la vez aplicará el perfil "RAID0" a los datos del usuario de forma predeterminada, y "RAID1" a los metadatos.
Este grupo de parámetros se controla mediante dos teclas:
-d para datos y
-m para metadatos y datos del sistema.
Pero hay un matiz ... Las cosas son diferentes con los SSD. El hecho es que si estuviéramos marcando una unidad SSD (o unidad flash), entonces, por defecto, el sistema de archivos no duplicaría los metadatos. Los SSD pueden extender la deduplicación de datos para extender la vida útil de los elementos de memoria. Es decir teniendo dos copias lógicas de los datos, de hecho solo se grabará una en el medio. Como resultado, cuando falla un segmento de memoria, se dañarán "ambas copias" de los datos. Además, al escribir datos dos veces, el recurso SSD simplemente se consume más rápido.
Para determinar el tipo de medio, btrfs verifica el contenido del archivo
/ sys / block / DEV / queue / rotational , donde "DEV" es el nombre del dispositivo de bloque a verificar.
Por supuesto, incluso en el caso de un SSD, se puede forzar el perfil de almacenamiento.
Para crear una instancia de btrfs en varios dispositivos, solo especifíquelos con un espacio:
sudo mkfs.btrfs /dev/sdc /dev/sdd -L double_drive
o con perfiles:
sudo mkfs.btrfs /dev/sdc /dev/sdd -d raid1 -m raid1 -L raid1_drive
Cabe señalar que los medios no tienen que ser del mismo tamaño, incluso si se utiliza la duplicación completa. Sin embargo, tan pronto como no haya suficiente espacio en la unidad más pequeña para asignar memoria, el sistema de archivos mostrará un mensaje que indica que no hay espacio libre, aunque físicamente todavía puede haber espacio libre en otros medios.
Montaje
El primer montaje de btrfs recién creados no es diferente de otros sistemas de archivos:
mount /dev/sdc /mnt
Si el sistema de archivos está ubicado en varios discos, entonces para el montaje es suficiente especificar cualquiera de ellos.
En general, montar btrfs siempre implica montar uno o más de sus subvolúmenes. Si el comando de montaje no se especifica qué subvolumen se debe montar, entonces btrfs leerá del registro especial la ID del subvolumen, que se debe montar de forma predeterminada. Esta entrada se puede cambiar más tarde con el
btrfs set-default , pero cuando la monta por primera vez en btrfs, solo hay un subvolumen: el raíz. Se especifica por defecto para el montaje.
El submundo raíz en btrfs siempre está presente. Aparece junto con el sistema de archivos y no está sujeto a ningún cambio en el futuro.
Hay dos formas de montar cualquier subvolumen que no sea el predeterminado:
especifique la ruta desde el subvolumen raíz btrfs:
mount -o subvol=/path/to/subvol /dev/sdc /mnt
especifique la ID del subvolumen:
mount -o subvolid=257 /dev/sdc /mnt
Como ya se mencionó, uno de los subvolúmenes btrfs se especifica como montado de forma predeterminada. Descubra cuál es posible haciendo:
btrfs subvolume get-default /path/to/any/subvolume
Para instalar el submontaje predeterminado, puede usar el comando:
btrfs subvolume set-default 258 /path/to/any/subvolume
La ruta al subvolumen en este caso solo es necesaria para indicar la instancia específica de btrfs a la que se aplica el comando. Por cierto, esto no tiene que ser un submundo; la ruta a cualquier directorio también es adecuada.
El comando
mount acepta una gran cantidad de opciones para controlar las capacidades de btrfs: desfragmentación, vaciado de caché, compresión, vaca, registro, equilibrio, soporte de SSD y muchas otras cosas específicas de btrfs. No los consideraré en el marco de este artículo, porque son necesarios para ajustar el sistema de archivos, y en la gran mayoría de los casos puede prescindir de ellos.
Subvolumen es
Un subvolumen es un elemento clave de btrfs que realiza varias funciones:
- almacenamiento de datos de usuario y otros subvolúmenes,
- proporcionar acceso a datos (montaje),
- Mecanismo de vaca
- creando instantáneas.
En una primera aproximación, el subvolumen es un directorio normal. Puede cambiarles el nombre / moverlos, ver su contenido, colocar y modificar archivos dentro de ellos. No se requieren utilidades especiales.
La creación y eliminación de un subvolumen se realiza en btrfs montados utilizando comandos especiales:
btrfs subvolume create /mnt/subvolume_name btrfs subvolume delete /mnt/subvolume_name
Observo que si intenta eliminar el subvolumen utilizando el administrador de archivos o la utilidad
rm , la operación finalizará con un error de
operación no permitida (la operación no está permitida).
UPD: a partir de la versión 4.18.0 del kernel, las subvolúmenes se pueden eliminar mediante la utilidad
rm o las herramientas del administrador de archivos. Aparentemente, fue un error, no una característica. Gracias a Prototik
habravchanin por la aclaración.
Después de crear un subvolumen, puede ver sus propiedades:
btrfs subvolume show /mnt/subvolume_name Name: subx UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Parent UUID: - Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 268 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Veamos las principales propiedades del subwolume:
- Nombre : el nombre del subvolumen
- UUID es un identificador único universal que sirve principalmente para determinar las relaciones de subwoofer-instantánea,
- UUID principal : identificador del antecesor de subvolumen del que se deriva el actual,
- UUID recibido : identificador del ancestro de subvolumen enviado a través de btrfs send ,
- ID de subvolumen : un identificador único para la colocación en el árbol B,
- Generación : número de transacción en la última actualización de los metadatos de subvolumen,
- Gen en la creación : número de transacción en el momento en que se creó el subvolumen,
- ID principal : identificador del subvolumen en el que está incrustado el actual,
- La ID de nivel superior es exactamente la misma que la ID principal,
- Banderas : banderas (de hecho, solo 1 bandera es de solo lectura ),
- Instantáneas : una lista de instantáneas tomadas de este subvolumen.
El subvolumen tiene un parámetro más: esta es su ruta desde el elemento raíz btrfs. La ruta se muestra al enumerar el subvolumen:
btrfs subvolume list /path/to/any/btrfs/mountpoint
Pero aquí todo es simple y claro: ni siquiera tiene sentido traer el resultado del comando.
Al igual que con los comandos
get-default y
set-default , aquí puede especificar la ruta a cualquier subvolumen, el resultado de esto no cambiará. Esta ruta se utiliza para encontrar el subbolum raíz btrfs. Después de lo cual se lee todo el árbol subwolum.
Si intenta copiar el subvolumen, por ejemplo, con la utilidad
cp , la operación de copia tendrá éxito, pero como resultado, no se creará el subvolumen, sino el directorio habitual. Sin embargo, btrfs proporciona una herramienta mucho más flexible para crear tales copias: instantáneas.
Instantánea es
Instantánea también es un submundo, solo que tiene propiedades avanzadas.
Su principal diferencia es que la instantánea tiene registros de qué subwolum se produjo. Estos son los campos
UUID principal y
UUID recibido . En el subwoofer, estos campos también están presentes, pero siempre están vacíos. Entonces, de hecho, una instantánea y un subvolumen son lo mismo.
Al crear, puede bloquear la instantánea para cambios utilizando el modificador
-r .
btrfs subvolume snapshot -r /path/to/subvol /path/to/snapshot
En este caso, se garantiza que los archivos permanecerán en el estado en que se encontraban en el momento en que se creó la instantánea.
El indicador de solo lectura también se puede controlar manualmente, esto funciona para cualquier subvolumen:
btrfs property get /path/to/subvol ro btrfs property set /path/to/subvol ro true
Si ahora miramos las propiedades de la instantánea, veremos el campo
UUID principal lleno:
btrfs subvolume show /path/to/snapshot Name: subx UUID: d08612d8-596a-11e9-8647-d663bd873d93 Parent UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 269 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Una característica importante de la operación de instantánea es que no es recursiva. En lugar de subvolumen anidado, se crearán directorios vacíos en la instantánea.
Pasemos al siguiente ejemplo.
En el sistema de archivos hay un subwoofer "sub0", dentro del cual hay un subwoofer
subA y un directorio
dirB . Dentro de cada uno de ellos están el
archivo A y el
archivo B, respectivamente.
Eliminar instantánea:
btrfs subvolume snapshot sub0 snap0
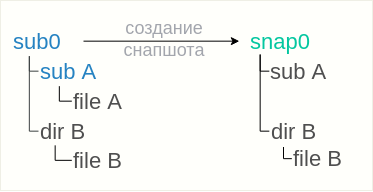
La instantánea
snap0 creada heredará todos los archivos y directorios de su padre, sin embargo, el
subwoofer subA no aparecerá dentro de la instantánea. En cambio, solo aparecerá un directorio vacío en la instantánea, es decir el contenido del subvolumen
subA no se heredará.
Por un lado, esto es bueno: eliminamos la instantánea de un subvolumen específico, y todos los anidados no nos interesan. Por otro lado, si se requiere una instantánea recursiva, btrfs no tiene una solución para este problema. Tendremos que buscar rondas de trabajo.
La primera solución se basa en el hecho de que la instantánea se eliminó sin un indicador de solo lectura, lo que le permite solucionar la situación de manera bastante simple:
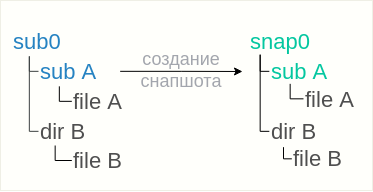
Si la instantánea se eliminó con el indicador de solo lectura, la opción anterior no funcionará, porque en
snap0 no puede eliminar el directorio ni colocar una instantánea. Solo hay una opción: colocar instantáneas en algún lugar cerca del
subwoofer snap0:
btrfs subvolume snapshot sub0/subA snapA
y luego monte
snapA dentro de la instantánea
snap0 , el directorio para esto ya está allí:
mount -o subvol=snapA snap0/subA
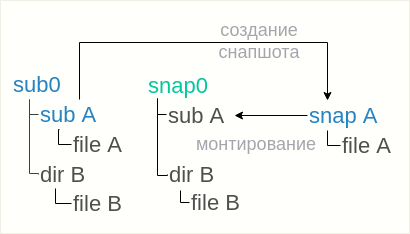
En cualquier caso, es importante comprender que las instantáneas recursivas se tomarán en diferentes operaciones, en diferentes momentos. No se puede hablar de ninguna eliminación atómica de una instantánea de varios subvolúmenes.
Copia en escritura
Un poco sobre subvolumen y enfoque CoW. Imagine que hay un subvolumen en el sistema de archivos y que se encuentra un archivo en él (tome el caso ideal: el archivo no está fragmentado). A continuación, se elimina una instantánea del subwolly.

Aparecerá un nuevo subvolumen (instantánea) en el sistema de archivos con exactamente el mismo contenido que el subvolumen original. El proceso de creación de una instantánea es casi instantáneo: los datos del archivo en sí no se copian. En su lugar, se crean metadatos adicionales y una instantánea junto con el subvolumen principal se convierte en el propietario del archivo. De hecho, solo había un archivo en el disco, pero ahora pertenece tanto al subvolumen como a la instantánea.
Si ahora cambia el archivo en el subvolumen, los cambios no afectarán el archivo en la instantánea. Si el indicador de solo lectura no se configuró al crear la instantánea, entonces el archivo en la instantánea también se puede modificar.
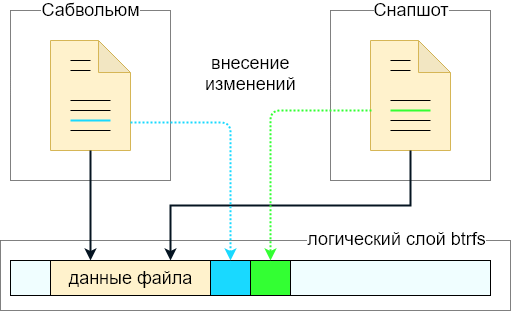
Técnicamente, cuando se cambia un archivo, solo se registran estos cambios. Por lo tanto, el archivo fuente se almacenará en el disco más algún delta que distinga el archivo original del modificado. Si elimina uno de los subvolúmenes (por el segundo me refiero a una instantánea), el exceso de datos que ya no es utilizado por nadie se borrará del disco, y solo la versión actual del archivo permanecerá en el disco (desde el punto de vista del subvolumen restante).
Una breve nota : al extraerlo, el subwoofer desaparecerá de los ojos del usuario al instante y la utilidad devolverá el control al terminal; sin embargo, el proceso en segundo plano limpiará los datos del disco durante un tiempo. Es decir, a diferencia de la eliminación de un directorio normal, no es necesario esperar a que finalice la operación de eliminación. Si necesita sincronizarse con este proceso y esperar a que se complete, puede especificar el interruptor
--commit-after llamar al
eliminar . El
comando btrfs subvolume list ,
invocado con el
modificador -d , muestra una lista de subvolúmenes que el usuario ha eliminado y que actualmente se encuentran en proceso de eliminación del disco.
Además, btrfs le permite clonar archivos en el sistema de archivos sin recurrir a instantáneas. Esto se hace copiando regularmente con la
--reflink :
cp -ax --reflink=always /original/file /copied/file
La clave
reflink=always le dice al sistema de archivos que queremos usar el mecanismo CoW al copiar. Después de copiar, los archivos se pueden cambiar independientemente uno del otro, para que tengamos el mismo comportamiento que después de crear una instantánea. Entonces, ¿por qué necesitamos subbolums?
Los subtolums en btrfs desempeñan el papel de una herramienta de control de alto nivel para conjuntos de datos completos: en primer lugar, es la eliminación de instantáneas atómicas de todos los datos de un subvolumen (en el caso de - la atomicidad de enlace solo está en el nivel de archivo), y en segundo lugar es posible ver de quién se hereda o "revierta" rápidamente el conjunto de datos a una versión anterior, etc.
Por lo tanto, btrfs proporciona la capacidad de capturar estados de archivos en los puntos de tiempo deseados, utilizando subvolúmenes como un medio de alto nivel para administrar estos estados.
Recuperación de subvolumen
En las vastas extensiones, a menudo surge la pregunta: "Tengo un subwoofer, tengo una instantánea, ¿cómo hacer un reverso?" Este enfoque no es aplicable a btrfs, porque no hay oportunidad de "hacer retroceder el subwolly". En cambio, btrfs ofrece una estrategia para reemplazar el subwolly con su instantánea. De hecho, por qué revertir algo, si la instantánea en sí es este objeto que queremos obtener con revertir.
Imagine este escenario: en btrfs hay un subvolumen en el que se encuentran los archivos de una base de datos (bueno, u otros datos importantes). Las instantáneas se eliminan periódicamente de este subvolumen y, en algún momento, es necesario revertir los datos. En este caso, simplemente nos deshacemos del subwolum y, en su lugar, comenzamos a usar la instantánea tomada de él o, si no queremos estropear también estos datos, eliminamos otra instantánea de la instantánea. Si el submundo original no se montó y se usó como un directorio normal, entonces se debe eliminar o mover / renombrar, y se debe colocar una instantánea en su lugar.
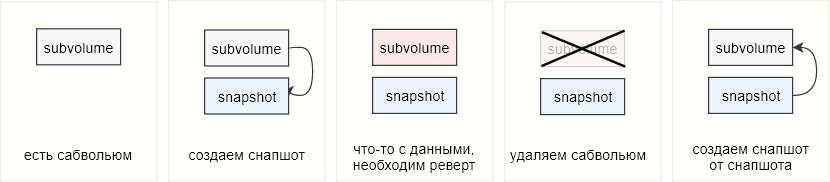
En la consola, podría verse así:
Si el subvolumen se montó y usó a través del punto de montaje, entonces es suficiente desmontar el subvolumen y montar una instantánea en su lugar.

Para completar, lo intentaré de nuevo y un poco diferente. El subvolumen en el que ocurren los cambios es la rama
principal .
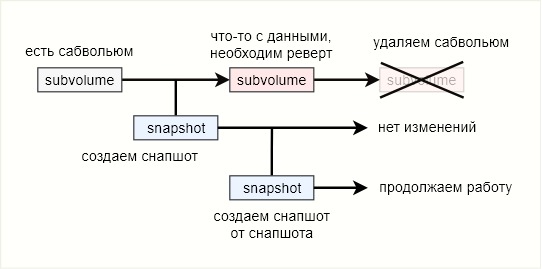
Al crear una instantánea, el estado de los archivos en el disco es fijo. De ahora en adelante, una instantánea es un brunch de la rama
principal . Todos los cambios posteriores a
main no afectarán la instantánea de ninguna manera. Volver a la instantánea significa detener el uso de la rama
principal y cambiar completamente al brunch. La rama
principal se puede eliminar como innecesaria. Por lo tanto, btrfs es prácticamente un sistema de control de versiones, pero sin la capacidad de fusionar las ramas.
Árbol del sistema de archivos
Uno de los puntos no obvios asociados con el uso de btrfs es cómo dividir los datos del sistema en subvolúmenes. Por supuesto, no existe un enfoque "correcto" para este problema. Pero hay 3 formas de organizar la estructura del subvolumen: una estructura plana, anidada y mixta.
Una estructura plana significa que el subvolumen se coloca en una lista plana en el subvolumen raíz. Por ejemplo, puede seleccionar la raíz del sistema de archivos (llamémosla
raíz ), el directorio de
inicio del usuario, el directorio con el sitio
/ var / www y la base de datos ubicada, por ejemplo, en
/ var / database como subvolúmenes separados.
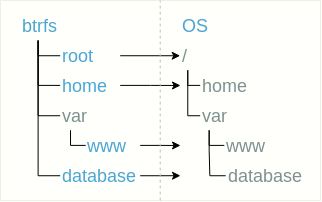
Por conveniencia, se puede colocar algún subvolumen en directorios, como, por ejemplo, en el caso del subvolumen
var / www .
Con este enfoque, todos los subvolúmenes deben montarse. La
raíz raíz debe tener un punto de montaje /, y en su interior debe contener los directorios
home y
var .
Después de montar la raíz en el / home debe estar instalado sabvolyum casa , y en el directorio / var / www y / var / databas un e - sabvolyumy var / www y la base de datos , respectivamente.Por lo tanto, el árbol de btrfs-subvolume se puede mostrar arbitrariamente en el sistema de archivos virtual del sistema operativo, y ya hay suficiente para eso.Pros:
- el usuario solo ve subvolumen montado,
- Es fácil reemplazar el subwoofer (desmontar uno, montar el otro),
- Subwoofer fácil de quitar.
Contras:
- es fácil confundirse sobre dónde instalarlo,
- para cada subvolumen debe haber una entrada en fstab, y si hay "retrocesos" en las instantáneas, entonces las entradas correspondientes en fstab también deben actualizarse.
La estructura anidada del subvolumen sugiere un uso simple del subvolumen en lugar de algunos directorios.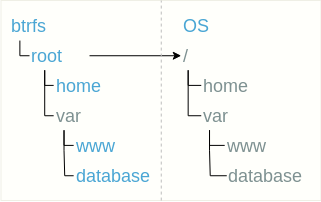 En este caso, además del subvolumen raíz, no se requiere nada más para ser montado.
En este caso, además del subvolumen raíz, no se requiere nada más para ser montado.Pros:
- todos los subvolúmenes son visibles, la estructura es fácil de percibir,
- no necesita volver a montar nada, todo es como un sistema de archivos "normal".
Contras:
- todos los subvolúmenes son visibles, tal vez a algunos les gustaría esconderse del usuario,
- es difícil eliminar / reemplazar el subwolum (la razón de esto es subwolves anidados).
Bueno, el tercer enfoque es mixto. Implica una combinación de los dos primeros para maximizar los beneficios de ambos. Sin embargo, es posible que este enfoque en particular conduzca a una estructura compleja, difícil de cambiar y confusa con una gran cantidad de entradas en fstab. Todo depende de la sobriedad del administrador del sistema.
Agregar / quitar disco, saldo
btrfs cuenta con una excelente funcionalidad: la capacidad de "agregar dispositivos de bloqueo activos" directamente durante el funcionamiento del sistema de archivos: btrfs device add /path/to/device /path/to/btrfs
O eliminar: btrfs device remove /path/to/device /path/to/btrfs
Por cierto, en una llamada de agregar / eliminar puede especificar varios discos.Nuevamente, la ruta especificada es la ruta a cualquier subvolumen de ese btrfs al que se aplicará el comando.Veamos cuántos y qué dispositivos de bloque están bajo control de btrfs: btrfs filesystem show /path/to/btrfs Label: none uuid: 52961dda-df84-4e2d-9727-e93e7738df81 Total devices 2 FS bytes used 192.00KiB devid 1 size 20.00GiB used 132.00MiB path /dev/sdc devid 2 size 50.00GiB used 0.00B path /dev/sdd
0.00B en el campo usado nos dice que el disco agregado está vacío. Para llenarlo con datos de acuerdo con el perfil de grabación, debe equilibrar: btrfs balance start /path/to/btrfs
El comando balance redistribuye los datos en los discos de acuerdo con el perfil de grabación seleccionado. Por ejemplo, en el caso de RAID1, el saldo conducirá a la clonación de datos del dispositivo original, en el caso de RAID0, conducirá a una distribución más uniforme de los datos en dos discos, etc.Como resultado del balance, si antes había vacíos en el disco, entonces los datos en el disco se escribirán de una manera más densa, es decir. La desfragmentación resultará. Sin embargo, es importante entender que esto no es exactamente "esa" desfragmentación. En este caso, el comando de equilibrio no mira el contenido lógico, sino que opera solo en bloques de datos. Ella no presta atención al hecho de que cualquier archivo está extendido en el disco. En cambio, el saldo transfiere bloques de datos de un lugar a otro. Es decir
un archivo fragmentado para equilibrar permanecerá fragmentado después de él. Pero! La fragmentación a nivel de bloques de datos seguirá disminuyendo, y esto se puede usar.Para evitar confusiones, digamos esto: la operación de equilibrio reduce la fragmentación a nivel de bloques de datos, pero no afecta la fragmentación de archivos.Además, el comando de equilibrio proporciona la capacidad de cambiar el perfil de grabación. Por ejemplo, el perfil DUP se utilizó en el disco y, después de agregar el disco, decidieron crear RAID1 completo. Para hacer esto, use el filtro convert: btrfs balance start -dconvert=raid1 -mconvert=raid1 /path/to/btrfs
Usando las opciones -dconverty, -mconvertse configuran nuevos perfiles de registro para datos y metadatos, respectivamente. También existe la opción -sconvert, que está diseñada para cambiar el perfil de escritura de datos del sistema, sin embargo, también deberá agregar el modificador -f (--force) para forzar la operación.En general, el objetivo principal de los filtros es establecer las reglas para la operación de equilibrio: qué bloques procesar y cuáles no tocar. Entonces, por ejemplo, puede afectar solo los bloques grabados con un perfil de grabación específico (perfiles de filtro), o bloques ocupados por encima de un cierto porcentaje (filtro de uso), o afectar solo a grupos de bloques relacionados con un disco específico (filtro devid), etc. Por cierto, todavía se pueden combinar. En general, las capacidades de los filtros son muy amplias y son principalmente necesarias para realizar un balance selectivo de datos.Fragmentación
Desafortunadamente, btrfs, debido a su arquitectura, es extremadamente susceptible a un fenómeno como la fragmentación. El hecho es que los datos siempre se escriben en una nueva ubicación en el disco. Incluso si lee el archivo, no haga nada con los datos y vuelva a escribirlos en el mismo archivo, los datos irán a una nueva área en el disco. Lo mismo sucede si actualiza los datos en el archivo solo parcialmente: los cambios se escriben en una nueva área del disco. Por lo tanto, los cambios frecuentes fragmentan los archivos con mucha fuerza, lo que aumenta la "dispersión" de los fragmentos, en el caso general, en varios discos. Esto conduce a una mayor carga en la CPU y al consumo innecesario de memoria. Las más fragmentadas son las bases de datos y las imágenes de máquinas virtuales.Puede evaluar la fragmentación de archivos con la utilidad filefrag (no incluido en btrfs-progs). filefrag /path/to/your/file
Muestra la cantidad de extensiones utilizadas para almacenar el archivo. En pocas palabras: cuanto menos implicados, menos fragmentado está el archivo.Hay dos métodos para combatir la fragmentación en btrfs: la desfragmentación y la bandera nocow.La desfragmentación se puede aplicar a un solo archivo o a un subvolumen / directorio, incluso de forma recursiva. El comando es el siguiente: btrfs filesystem defragment /path/to/file/or/dir
Debo decir que este equipo no siempre conduce a los resultados esperados. Los archivos pequeños y ligeramente fragmentados (10-20 extensiones) después de la desfragmentación se pueden dividir en más partes. Además, la desfragmentación de btrfs en algunas versiones del núcleo interrumpe la deduplicación de archivos, convirtiéndolos en copias físicas reales. Es decir
las instantáneas a nivel físico se convertirán en copias completas.La segunda forma de combatir la fragmentación es con un atributo de archivo nocow. chattr +C /path/to/file
El atributo nocowsolo se puede establecer en un archivo nuevo o vacío. Deshabilita el mecanismo de copia en escritura , por lo que btrfs siempre funcionará con un área de disco fija al actualizar el contenido de un archivo, escribiendo datos sobre los existentes (a nivel físico). De los inconvenientes de nocow , también deshabilita la comprobación de la suma de comprobación para este archivo. En otras palabras, no hay vaca, no hay suma de control.Por supuesto, establezca manualmente el atributonocowCada archivo es una tarea ingrata. Si se establece este indicador del directorio / subvolumen, todos los archivos nuevos creados en él heredarán el indicador automáticamente. Lo mismo se aplica a los directorios anidados creados. Si en el momento en que se activó el atributo, los datos ya estaban en el directorio, esto no los afectará de ninguna manera; el atributo nocowsolo se puede establecer en un archivo nuevo o vacío.Y otra forma de configurar el indicador automáticamente nocowes montar el sistema de archivos con la opción nodatacow: mount -o subvol=path/to/subvol,nodatacow /dev/sdXX /path/to/mountpoint
Esta opción hará que la opción se conecte automáticamente nodatasum, de modo que para los archivos recién creados, no se calcularán las sumas de verificación.Como de costumbre, hay un matiz: no puede montar solo un subwoofer con una opción nocow. O todos los subvolúmenes tendrán una opción nocowo ninguna. Todo se decide por el primer subvolumen montado: si tenía una opción especificada nodatacow, todos los montajes posteriores irán con esta opción automáticamente.Un momento no obvio surge si coloca una bandera en un archivo nocowy elimina la instantánea del subvolumen en el que se encuentra este archivo. En este caso, btrfs ignora el indicador nocowsi más de un subvolumen se refiere al bloque de datos actualizado. Por lo tanto, a pesar de la banderanocow(por cierto, el archivo también lo heredará en la instantánea), los cambios en cualquiera de los archivos irán a una nueva área en el disco y el archivo nuevamente se fragmentará. Si el bloque de datos en el archivo se actualiza varias veces, entonces la primera vez caerá en una nueva área en el disco, y con las entradas posteriores se actualizará en esta nueva área "en su lugar".Trucos y Fallos
Cuando use btrfs-progs, puede omitir el nombre completo del comando: btrfs sub cre = btrfs subvolume create
Es suficiente solo la coincidencia de los primeros caracteres, que determinan de manera única el comando: su = subvolume, fi = filesystem, ba = balance, de = device;
Creo que el principio es claro.Por desgracia, btrfs no puede crear una instantánea del directorio, pero hay una solución alternativa:No nocowpuede establecer el atributo en un archivo de datos existente. Sin embargo, puede seguir el siguiente camino:Si btrfs se queda sin espacio, incluso eliminar un archivo puede causar un error "No queda espacio en el dispositivo" . Para la solución, se recomienda conectar una unidad temporal con tamaños de preferiblemente al menos 1 GB a btrfs. Luego limpie los datos. Luego retire la unidad temporal.La operación de equilibrio , invocada sin especificar perfiles de escritura, los cambia implícitamente de dup a raid1 . Lo que, por cierto, está escrito en la página de Gotchas . Esto sucede después de agregar el disco a btrfs, que usa el perfil de escritura dup . Recuerde que formatear una sola unidad en btrfs usa el perfil dup predeterminado para metadatos y datos del sistema.Quizás lo más importante
Evite crear clones de bajo nivel de dispositivos de bloque con btrfs. Al ser un sistema de archivos "inteligente", para algunas operaciones (la mayoría de las veces, durante el montaje) btrfs vuelve a leer los datos del sistema en dispositivos de bloque para encontrar todas las partes del sistema de archivos. Si se encuentran dos dispositivos de bloque con los mismos UUID en el proceso de búsqueda, btrfs los aceptará como parte de la misma instancia. Si al mismo tiempo estos dos dispositivos resultan ser el original y su clon, luego de montar el controlador solo sabrá cómo funcionará el sistema de archivos, pero está claro que esto no terminará con nada bueno. En el peor de los casos, provocará una corrupción irreversible de los datos.Si realmente desea clonar discos con btrfs de una manera de bajo nivel, debe tener mucho cuidado. En general, un clon no debe ser visible para el núcleo del sistema operativo como un dispositivo de bloque mientras el original está presente en el sistema, y viceversa. Proporcionando esta condición, puede cambiar el UUID del clon (bueno, o el original, aquí opcional). La utilidad btrfstune que viene con el paquete btrfs-progs ayudará a : btrfstune -u /path/to/device
Y de nuevo: btrfstune , al ser una utilidad "inteligente", cambiará el UUID no solo en el disco, sino en todo el sistema de archivos. Esto significa que cuando se le llame, leerá todos los dispositivos de bloque para reemplazar el UUID en todos los dispositivos relacionados con el sistema de archivos.En lugar de una conclusión
Si en este momento no comprende nada, esto es normal. Btrfs no es trivial y puede no sucumbir de inmediato. Cada vez que me parecía que ahora la entendía, ella lanzaba una sorpresa y la hacía repensar las cosas existentes. No puedo decir que entendí todo en el momento actual: en el proceso de escritura encontré algo nuevo, aunque ya escribí sobre la base de mi experiencia.Compararía el proceso de dominar btrfs con la transición de un estilo de programación procesal a uno orientado a objetos. La primera impresión es "wow, qué asombroso", pero luego continúas persistentemente escribiendo código procesal envuelto en clases.En el artículo, intenté no verter agua, escribir todo sobre el caso. A pesar de esto, resultó bastante voluminoso. Pero lejos de todo era posible decir: aún puede escribir y escribir sobre btrfs. Este artículo es solo la punta del iceberg. El principio es entender su filosofía y comenzar a usarla. Y ahora es tiempo de terminar.Gracias por leer hasta el final. Espero no estar cansado. Escriba en los comentarios sobre qué más le interesaría saber.Haga copias de seguridad, caballeros. Y que nunca sean útiles.