Toloka es la mayor fuente de datos etiquetados por máquina para tareas de aprendizaje automático. Todos los días en Tolok, decenas de miles de artistas producen más de 5 millones de calificaciones. Para cualquier investigación y experimento relacionado con el aprendizaje automático, se necesitan grandes volúmenes de datos de calidad. Por lo tanto, estamos comenzando a publicar conjuntos de datos abiertos para la investigación académica en diversas áreas temáticas.
Hoy compartiremos enlaces a los primeros conjuntos de datos públicos y hablaremos sobre cómo se ensamblaron. También le mostraremos dónde poner el estrés en el nombre de nuestra plataforma.
Un hecho interesante: cuanto más compleja es la tecnología de la inteligencia artificial, más necesita la ayuda humana. Las personas clasifican las imágenes para entrenar la visión por computadora; La gente califica la relevancia de las páginas para las consultas de búsqueda. las personas convierten el habla en texto para que el asistente de voz aprenda a entender y hablar. La máquina necesita evaluaciones humanas para que funcione aún más sin personas y mejor que las personas.
Anteriormente, muchas compañías recolectaban tales evaluaciones exclusivamente con la ayuda de empleados especialmente capacitados: asesores. Pero con el tiempo, hubo demasiadas tareas en el campo del aprendizaje automático, y en su mayor parte las tareas mismas dejaron de requerir un conocimiento y experiencia especiales. Así que hubo una demanda de ayuda de la "multitud" (multitud). Pero por sí solos, no todos pueden encontrar una gran cantidad de artistas aleatorios y trabajar con ellos. Las plataformas de crowdsourcing resuelven este problema.
Yandex.Toloka (correctamente pronunciado de esa manera, con énfasis en la última sílaba) es una de las plataformas de crowdsourcing más grandes del mundo. Tenemos más de 4 millones de usuarios registrados. Más de 500 proyectos recopilan evaluaciones con nuestra ayuda todos los días. Dato agradable: este año en la sección de Etiquetado de datos en la conferencia Data Fest, los seis oradores de diferentes compañías mencionaron a Toloka como una fuente de margen para sus proyectos.
Mucho se ha dicho sobre el uso de Toloka en los negocios. Hoy hablaremos de nuestra otra área, que consideramos no menos útil.
La investigación en Tolok
El crowdsourcing y, en general, la tarea de reunir marcas humanas, son casi lo mismo que la aplicación industrial del aprendizaje automático. Esta es un área en la que todas las empresas de tecnología gastan mucho dinero. Pero al mismo tiempo, por alguna razón, es ella quien está muy poco invertida en términos de investigación: en trabajar con la multitud, en contraste con otras áreas de LD, relativamente pocos estudios y artículos serios.
Nos gustaría cambiar eso. Nuestro equipo ve a Toloka no solo como una herramienta para resolver problemas aplicados, sino también como una plataforma para la investigación científica en diversas áreas temáticas.
Conjuntos de datos públicos de Toloka
Queremos apoyar a la comunidad científica y atraer investigadores a Toloka, por lo que estamos comenzando a publicar conjuntos de datos con fines académicos y no comerciales. Pueden ser de interés para los investigadores de diferentes direcciones: aquí hay chat bots y datos para probar modelos de agregación de veredictos de peaje, para investigación lingüística, para problemas de visión por computadora. Hablemos de ellos:
Toloka Persona Chat RusUn conjunto de datos de 10 mil diálogos ayudará a los investigadores de sistemas de diálogo a desarrollar enfoques para la capacitación de bots de chat. Lo preparamos junto con
iPavlov , un proyecto del Laboratorio de Sistemas Neurales y Aprendizaje Profundo en MIPT, que realiza investigaciones en el campo de la inteligencia artificial conversacional y desarrolla
DeepPavlov , una biblioteca abierta para crear asistentes interactivos. El conjunto de datos Persona Chat Rus contiene perfiles que describen la personalidad de una persona y los diálogos entre los participantes del estudio.
Cómo se recopilaron los datosEn la primera etapa, con la ayuda de los usuarios de Toloka, recopilamos perfiles que contenían información sobre una persona, sus pasatiempos, profesión, familia y eventos de la vida, y seleccionamos aquellos que son adecuados para los diálogos.
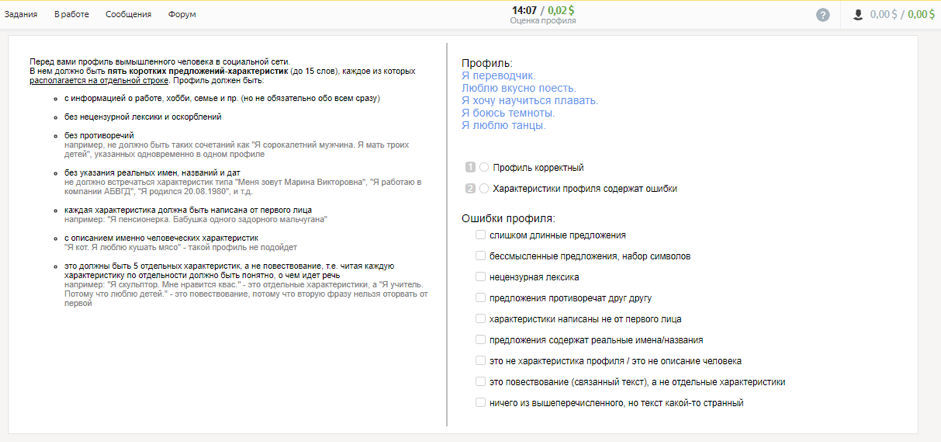
En la segunda etapa, invitamos a los participantes a desempeñar el papel de la persona descrita por uno de estos perfiles y comunicarse entre sí en el messenger. El propósito del diálogo es aprender más sobre el interlocutor y hablar sobre usted. Los cuadros de diálogo resultantes fueron verificados por otros artistas.

Relevancia de agregación de Toloka 2El conjunto de datos le permite explorar métodos de control de calidad en crowdsourcing. Contiene casi medio millón de evaluaciones anónimas de artistas reunidos en el proyecto "Relevancia (2 gradaciones)" en 2016. Aquí encontrará tanto evaluaciones anónimas de tolokers como evaluaciones de referencia que ayudarán a medir la calidad de las respuestas. El estudio de estos datos nos permitirá rastrear cómo la opinión de los artistas intérpretes o ejecutantes afecta la calidad de la evaluación final, qué métodos de agregación de resultados se utilizan mejor y cuántas opiniones se deben recopilar para obtener una respuesta confiable.
Cómo se recopilaron los datosAl contratista se le ofreció la solicitud y la región del usuario que lo configuró, una captura de pantalla del documento y un enlace al mismo, la capacidad de usar motores de búsqueda y opciones de respuesta: "Relevante", "No relevante", "No se muestra".
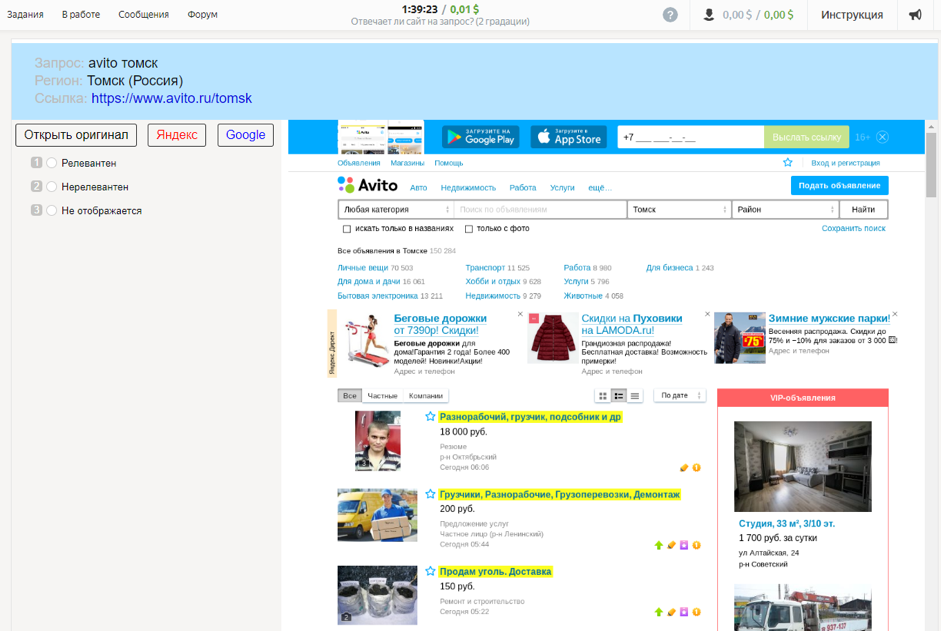
Relevancia de agregación de Toloka 5Este conjunto de datos es el mismo que el anterior, solo las estimaciones aquí se recopilaron no en un binario, sino en una escala de cinco puntos en el proyecto "Relevancia (5 gradaciones)". El conjunto de datos contiene más de un millón de calificaciones.
Cómo se recopilaron los datosLa evaluación de documentos para cinco grados es más compleja y requiere más calificaciones. Al contratista se le ofreció la solicitud y la región del usuario que lo configuró, una captura de pantalla del documento y un enlace al mismo, botones para usar motores de búsqueda y cinco opciones de respuesta: "Vital", "Útil", "Relevante +", "Relevante -", "Irrelevante".

El principal indicador de calidad es la precisión de las respuestas agregadas, estimadas en función de las tareas de control (goldensets). Algunas tareas en el conjunto de datos no tienen una, sino varias respuestas correctas. Cualquiera de estas respuestas se considera correcta. Precisión de los principales métodos de agregación:
● La opinión mayoritaria es del 89,92%.
● Dawid-Skene - 90.72%.
● GLAD - 90.16%.
Relaciones léxicas de la sabiduría de la multitud (LRWC)El conjunto de datos contiene las opiniones de hablantes nativos de la lengua rusa sobre la relación género-especie entre las palabras: la conexión entre lo general (hiperónimo) y lo privado (hipónimo). Recogido por el investigador Dmitry Ustalov en 2017.
Cómo se recopilaron los datosPara el estudio, se tomaron 300 de los sustantivos rusos más utilizados en la actualidad. Utilizando tesauros (RuTez, RuWordNet) y métodos automatizados para la formación de hiperónimos (Watset, Hyperstar), se obtuvieron 10.600 pares de géneros-especies (del tipo "gatito" - "mamífero"). Los participantes en el estudio necesitaban responder a la pregunta: "¿Es cierto que un gatito es una especie de mamífero?" Para formular correctamente la pregunta, se colocaron hiperónimos en el caso genitivo utilizando un analizador morfológico y un generador de pymorphy2.
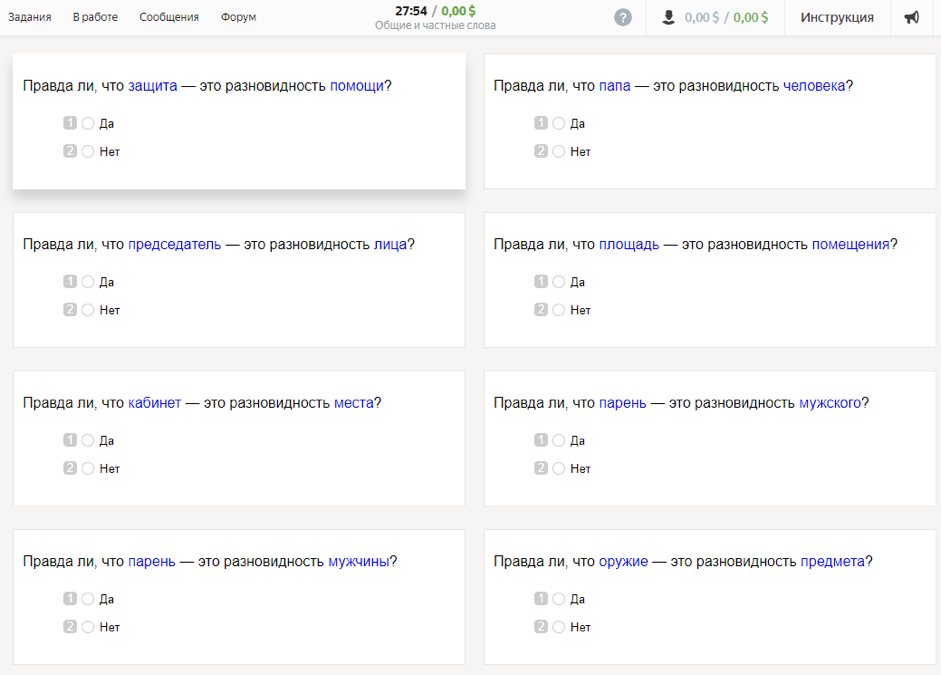
Cada pareja fue marcada por siete artistas de habla rusa mayores de 20 años. Según los resultados obtenidos después de la agregación de todas las estimaciones, 4576 pares de palabras recibieron respuestas positivas y 6024 negativas. Curiosamente, los participantes del estudio fueron más unánimes al elegir una respuesta negativa que una positiva.
Contextos de palabras desambiguadas con sentido anotado por humanos para rusoEl conjunto de datos contiene 2562 significados contextuales de 20 palabras que representan la mayor variedad de significados semánticos. El estudio fue realizado por Dmitry Ustalov en 2017.
Cómo se recopilaron los datosA los participantes del estudio se les mostró la palabra y un ejemplo de su uso en el habla. Era necesario determinar el significado de la palabra en el contexto del enunciado y elegir una de las opciones de respuesta.

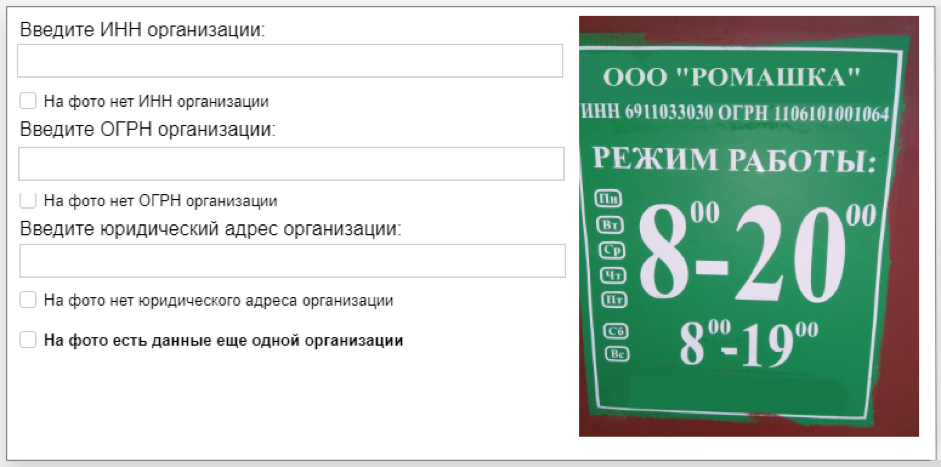
Reconocimiento de identificación comercial de TolokaPara este conjunto de datos, preparamos 10 mil fotografías de placas informativas de organizaciones y un archivo de texto con números (TIN y PSRN), que se indicaron en la placa. Después de aprender de estos datos, el modelo de visión por computadora podrá reconocer la secuencia de números en la imagen. El conjunto de datos es proporcionado por el servicio Yandex.Directory.
Cómo se recopilaron los datosPrimero, lanzamos la tarea en la aplicación móvil Toloka: se invitó a los artistas intérpretes o ejecutantes a ir a la dirección marcada en el mapa, encontrar la organización y tomar una fotografía de su placa de información. Esta y otras tareas de campo ayudan a mantener la información actualizada en Yandex.Directory.
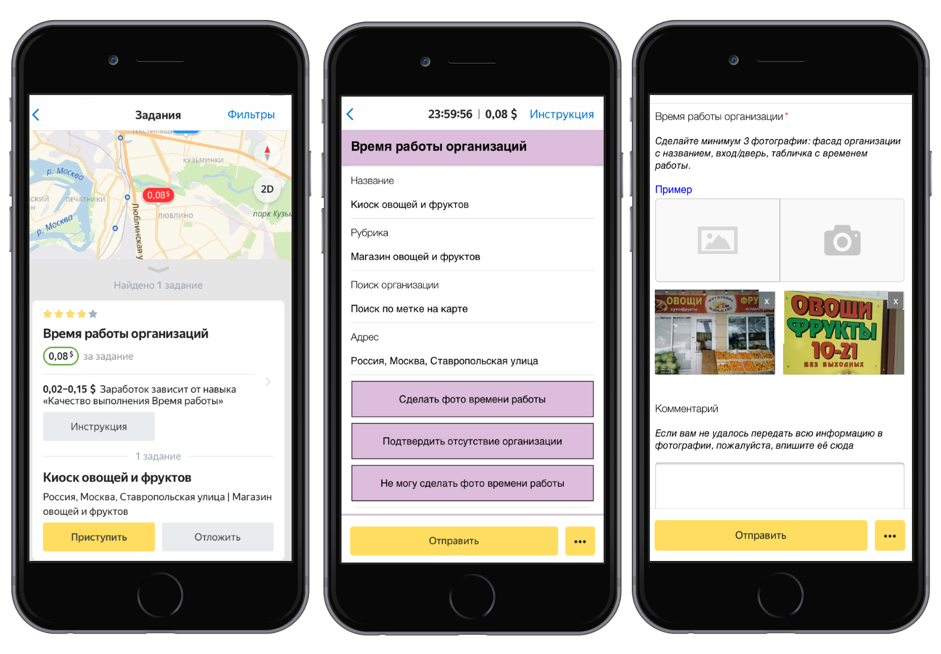
Luego, la calidad de las tareas completadas fue verificada por otros artistas. Enviamos las fotos con TIN y PSRN para descifrarlas. Tolokers reimprimió estos números de las fotos, luego de lo cual procesamos los resultados y formamos un conjunto de datos.
Características de agregación de TolokaEl conjunto de datos contiene alrededor de 60 mil clasificaciones en 1 mil tareas con las respuestas correctas para casi todas las tareas. Los artistas clasificaron los sitios en cinco categorías según la disponibilidad de contenido para adultos. Además de cada tarea, se adjuntan 52 indicadores de valor real que se pueden usar para predecir la categoría.
Puede seleccionar y descargar conjuntos de datos desde el enlace:
https://toloka.yandex.ru/datasets/ . No planeamos detenernos en esto e instar a los investigadores a prestar atención al crowdsourcing y hablar sobre sus proyectos.