Continuamos hablando sobre la conferencia sobre estadísticas y aprendizaje automático AISTATS 2019. En esta publicación analizaremos artículos sobre modelos profundos de conjuntos de árboles, mezclaremos la regularización para obtener datos muy escasos y una aproximación eficiente de la validación cruzada.

Algoritmo de bosque profundo: una exploración de modelos profundos no NN basados en módulos no diferenciables
Zhi-Hua Zhou (Universidad de Nanjing)
→ Presentación
→ Artículo
Implementaciones - abajo
Un profesor de China habló sobre el conjunto de árboles, que los autores llaman la primera capacitación profunda sobre módulos no diferenciables. Esto puede parecer una declaración demasiado fuerte, pero este profesor y su índice H 95 son oradores invitados, este hecho nos permite tomar la declaración más en serio. La teoría básica de Deep Forest se ha desarrollado durante mucho tiempo, el artículo original ya es 2017 (casi 200 citas), pero los autores escriben bibliotecas y cada año mejoran el algoritmo en velocidad. Y ahora, al parecer, han llegado al punto en que esta hermosa teoría finalmente se puede poner en práctica.
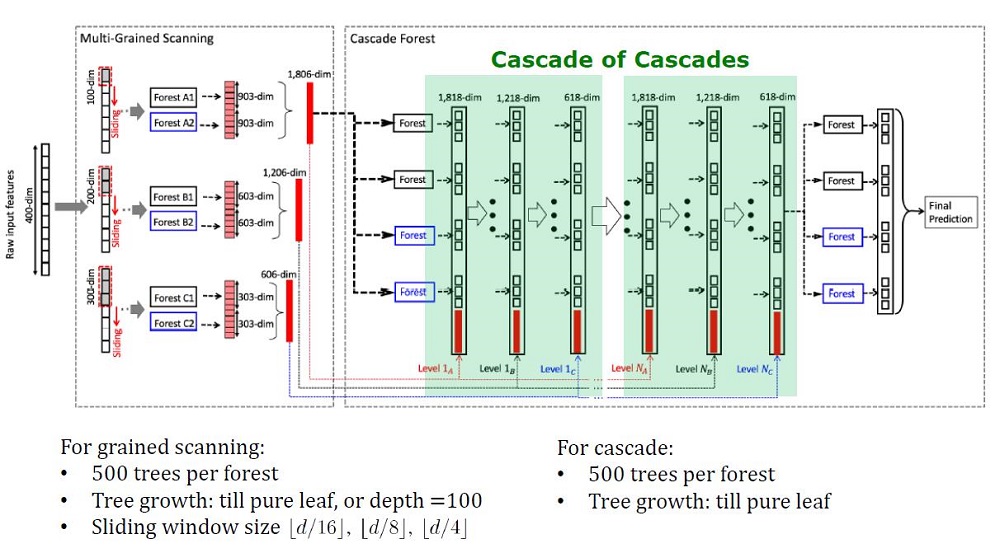
Vista general de la arquitectura de Deep Forest
Antecedentes
Los modelos profundos, que ahora se entienden como redes neuronales profundas, se utilizan para capturar dependencias de datos complejas. Además, resultó que aumentar el número de capas es más eficiente que aumentar el número de unidades en cada capa. Pero las redes neuronales tienen sus inconvenientes:
- Se necesitan muchos datos para no volver a entrenar,
- Se necesitan muchos recursos informáticos para aprender en un tiempo razonable,
- Demasiados hiperparámetros que son difíciles de configurar de manera óptima
Además, los elementos de las redes neuronales profundas son módulos diferenciables que no son necesariamente efectivos para cada tarea. A pesar de la complejidad de las redes neuronales, los algoritmos conceptualmente simples, como un bosque aleatorio, a menudo funcionan mejor o no mucho peor. Pero para tales algoritmos, debe diseñar características manualmente, lo que también es difícil de hacer de manera óptima.
Los investigadores ya han notado que los conjuntos en Kaggle: son "muy perfectos", e inspirados por las palabras de Scholl y Hinton de que la diferenciación es el lado más débil de Deep Learning, decidieron crear un conjunto de árboles con propiedades DL.
Diapositiva "Cómo hacer un buen conjunto"
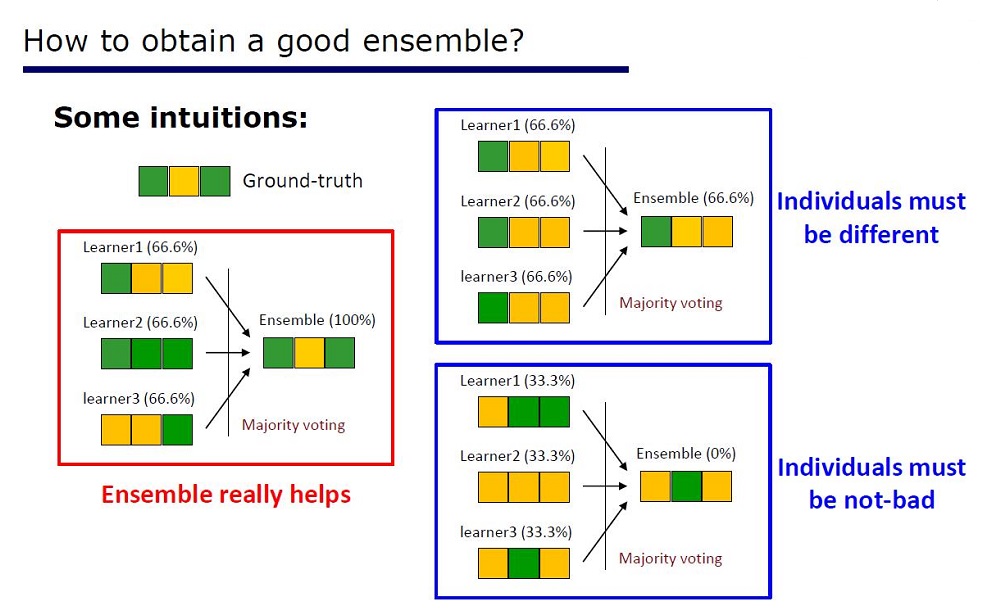
La arquitectura se dedujo de las propiedades de los conjuntos: los elementos de los conjuntos no deberían ser muy pobres en calidad y diferir.
GcForest consta de dos fases: Cascade Forest y Multi-Grained Scanning. Además, para que la cascada no se vuelva a entrenar, consta de 2 tipos de árboles, uno de los cuales es un árbol absolutamente aleatorio que se puede utilizar en datos no asignados. El número de capas se determina dentro del algoritmo de validación cruzada.
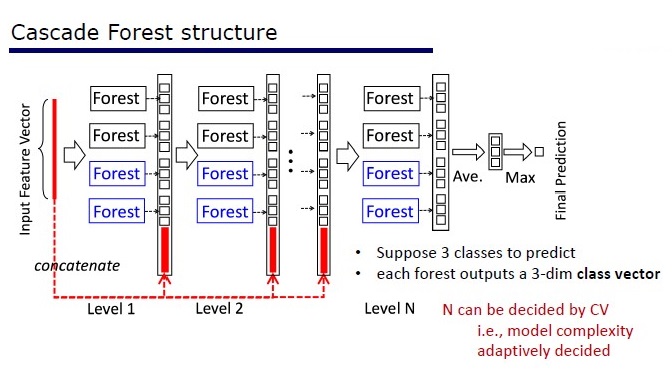
Dos tipos de arboles
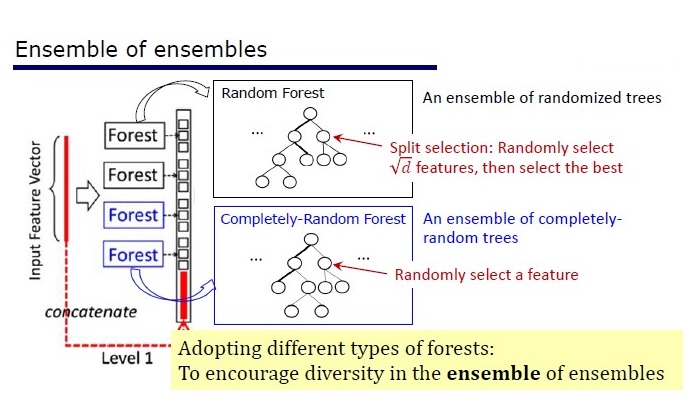
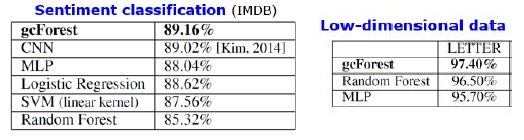
Resultados
Además de los resultados en conjuntos de datos estándar, los autores trataron de usar gcForest en las transacciones del sistema de pago chino para buscar fraudes y obtuvieron F1 y AUC mucho más altos que los de LR y DNN. Estos resultados solo están en la presentación, pero el código que se ejecuta en algunos conjuntos de datos estándar está en Git.
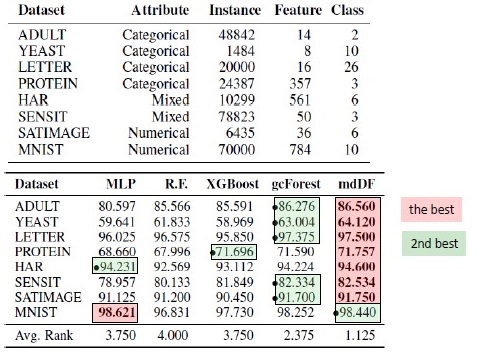
Resultados de sustitución de algoritmo. mdDF es óptimo Margen Distribution Deep Forest, una variante de gcForest
Pros:
- Pocos hiperparámetros, el número de capas se ajusta automáticamente dentro del algoritmo.
- La configuración predeterminada se elige para que funcione bien en muchas tareas.
- Complejidad adaptativa del modelo, en datos pequeños: un modelo pequeño
- No es necesario configurar funciones
- Funciona en calidad comparable a las redes neuronales profundas, y a veces mejor
Contras:
- No acelerado en GPU
- En las fotos pierde DNNs
Las redes neuronales tienen un problema de atenuación de gradiente, mientras que el bosque profundo tiene un problema de "desaparición de la diversidad". Como se trata de un conjunto, cuantos más elementos "diferentes" y "buenos" se utilicen, mayor será la calidad. El problema es que los autores ya han probado casi todos los enfoques clásicos (muestreo, aleatorización). Mientras no aparezca una nueva investigación básica sobre el tema de las "diferencias", será difícil mejorar la calidad de los bosques profundos. Pero ahora es posible mejorar la velocidad de la informática.
Reproducibilidad de resultados
XGBoost me intrigó con los datos tabulares, y quería reproducir el resultado. Tomé el conjunto de datos de Adultos y apliqué GcForestCS (una versión ligeramente acelerada de GcForest) con parámetros de los autores del artículo y XGBoost con parámetros predeterminados. En el ejemplo que tenían los autores, las características categóricas ya estaban preprocesadas de alguna manera, pero no se indicó cómo. Como resultado, utilicé CatBoostEncoder y otra métrica: ROC AUC. Los resultados fueron estadísticamente diferentes: XGBoost ganó. El tiempo de funcionamiento de XGBoost es insignificante, mientras que gcForestCS tiene 20 minutos de cada validación cruzada en 5 veces. Por otro lado, los autores probaron el algoritmo en diferentes conjuntos de datos y ajustaron los parámetros para este conjunto de datos a su preprocesamiento de características.
El código se puede encontrar aquí .
Implementaciones
→ El código oficial de los autores del artículo.
→ Modificación mejorada oficial, más rápido, pero sin documentación
→ La implementación es más simple
PcLasso: el lazo se encuentra con la regresión de componentes principales
J. Kenneth Tay, Jerome Friedman, Robert Tibshirani (Universidad de Stanford)
→ Artículo
→ Presentación
→ Ejemplo de uso
A principios de 2019, J. Kenneth Tay, Jerome Friedman y Robert Tibshirani de la Universidad de Stanford propusieron un nuevo método de enseñanza con un maestro, especialmente adecuado para datos escasos.
Los autores del artículo resolvieron el problema de analizar datos sobre estudios de expresión génica, que se describen en Zeng & Breesy (2016). El objetivo es el estado mutacional del gen p53, que regula la expresión génica en respuesta a diversas señales de estrés celular. El objetivo del estudio es identificar predictores que se correlacionan con el estado mutacional de p53. Los datos constan de 50 filas, 17 de las cuales se clasifican como normales y las 33 restantes tienen mutaciones en el gen p53. Según el análisis de Subramanian et al. (2005) 308 conjuntos de genes que están entre 15 y 500 se incluyen en este análisis. Estos kits de genes contienen un total de 4,301 genes y están disponibles en el paquete grpregOverlap R. Al expandir datos para procesar grupos superpuestos, se generan 13,237 columnas. Los autores del artículo utilizaron el método pcLasso, que ayudó a mejorar los resultados del modelo.
En la imagen vemos un aumento en AUC cuando se usa "pcLasso"

La esencia del método.
Método combina  -regularización con
-regularización con  , que reduce el vector de coeficientes a los componentes principales de la matriz de características. Llamaron al método propuesto "componentes centrales del lazo" ("pcLasso" disponible en R). El método puede ser especialmente poderoso si las variables se agrupan previamente (el usuario elige qué y cómo agrupar). En este caso, pcLasso comprime cada grupo y obtiene la solución en la dirección de los componentes principales de este grupo. En el proceso de resolución, también se realiza la selección de grupos significativos entre los disponibles.
, que reduce el vector de coeficientes a los componentes principales de la matriz de características. Llamaron al método propuesto "componentes centrales del lazo" ("pcLasso" disponible en R). El método puede ser especialmente poderoso si las variables se agrupan previamente (el usuario elige qué y cómo agrupar). En este caso, pcLasso comprime cada grupo y obtiene la solución en la dirección de los componentes principales de este grupo. En el proceso de resolución, también se realiza la selección de grupos significativos entre los disponibles.
Presentamos la matriz diagonal de la descomposición singular de una matriz centrada de características.  como sigue:
como sigue:
Representamos nuestra descomposición singular de la matriz centrada X (SVD) como  donde
donde  Es una matriz diagonal que consiste en valores singulares. En esta forma - La regularización puede ser representada:
Es una matriz diagonal que consiste en valores singulares. En esta forma - La regularización puede ser representada:
 donde
donde  - matriz diagonal que contiene la función de cuadrados de valores singulares:
- matriz diagonal que contiene la función de cuadrados de valores singulares: %2C%E2%80%A6%2CZ_%7B22%7D%3Df_2%20(d_1%5E2%2Cd_2%5E2%2C%E2%80%A6%2Cd_m%5E2%20)) .
.
En general, en -regularización  para todos
para todos  eso corresponde
eso corresponde  . Sugieren minimizar la siguiente funcionalidad:
. Sugieren minimizar la siguiente funcionalidad:
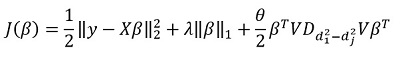
Aqui - matriz de diferencias de elementos diagonales  . En otras palabras, controlamos el vector
. En otras palabras, controlamos el vector  usando hiperparámetro también
usando hiperparámetro también  .
.
Transformando esta expresión, obtenemos la solución:
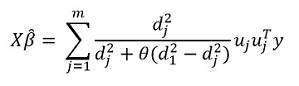
Pero la "característica" principal del método, por supuesto, es la capacidad de agrupar datos y, sobre la base de estos grupos, resaltar los componentes principales del grupo. Luego reescribimos nuestra solución en la forma:
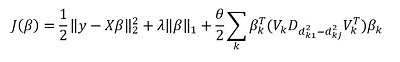
Aqui  - subvector vectorial
- subvector vectorial  correspondiente al grupo k,
correspondiente al grupo k, ) - valores singulares
- valores singulares  arreglado en orden descendente, y
arreglado en orden descendente, y  - matriz diagonal
- matriz diagonal 
Algunas notas sobre la solución del objetivo funcional:
La función objetivo es convexa, y el componente no liso es separable. Por lo tanto, se puede optimizar de manera efectiva utilizando el descenso de gradiente.
El enfoque es comprometer múltiples valores (incluido cero, respectivamente, obteniendo el estándar -regularización), y luego optimizar:  recogiendo
recogiendo  . En consecuencia, los parámetros y son seleccionados para validación cruzada.
. En consecuencia, los parámetros y son seleccionados para validación cruzada.
Parámetro Difícil de interpretar. En el software (paquete pcLasso), el usuario mismo establece el valor de este parámetro, que pertenece al intervalo [0,1], donde 1 corresponde a = 0 (lazo).
En la práctica, variando los valores = 0.25, 0.5, 0.75, 0.9, 0.95 y 1, puede cubrir una amplia gama de modelos.
El algoritmo en sí es el siguiente

Este algoritmo ya está escrito en R, si lo desea, ya puede usarlo. La biblioteca se llama 'pcLasso'.
Una navaja suiza Infinitesimal del ejército
Ryan Giordano (UC Berkeley); William Stephenson (MIT); Runjing Liu (UC Berkeley);
Michael Jordan (UC Berkeley); Tamara Broderick (MIT)
→ Artículo
→ Código
La calidad de los algoritmos de aprendizaje automático a menudo se mide mediante validación cruzada múltiple (validación cruzada o bootstrap). Estos métodos son potentes, pero lentos en grandes conjuntos de datos.
En este trabajo, los colegas usan una aproximación lineal de pesos, produciendo resultados que funcionan más rápido. Esta aproximación lineal se conoce en la literatura estadística como "navaja infinitesimal". Se utiliza principalmente como una herramienta teórica para probar resultados asintóticos. Los resultados del artículo son aplicables independientemente de si los pesos y los datos son estocásticos o deterministas. Como consecuencia, esta aproximación estima secuencialmente la verdadera validación cruzada para cualquier k fija.
Presentación del Premio de papel al autor del artículo.

La esencia del método.
Considere el problema de estimar un parámetro desconocido  donde
donde  Es compacto y el tamaño de nuestro conjunto de datos es
Es compacto y el tamaño de nuestro conjunto de datos es  . Nuestro análisis se llevará a cabo en un conjunto de datos fijo. Define nuestra calificación
. Nuestro análisis se llevará a cabo en un conjunto de datos fijo. Define nuestra calificación  como sigue:
como sigue:
- Para cada
 establecer
establecer  ( ) Es una función de
( ) Es una función de 
 Es un número real y
Es un número real y  Es un vector que consiste en
Es un vector que consiste en 
Entonces  se puede representar como:
se puede representar como:

Al resolver este problema de optimización mediante el método de gradiente, asumimos que las funciones son diferenciables y podemos calcular el Hessian. El principal problema que resolvemos es el costo computacional asociado con la evaluación. ) para todos
para todos  . La principal contribución de los autores del artículo consiste en calcular la estimación.
. La principal contribución de los autores del artículo consiste en calcular la estimación. ) donde
donde ) . En otras palabras, nuestra optimización dependerá solo de derivados
. En otras palabras, nuestra optimización dependerá solo de derivados ) que suponemos que existen y son de Hesse:
que suponemos que existen y son de Hesse:
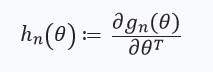
A continuación, definimos una ecuación con un punto fijo y su derivada:
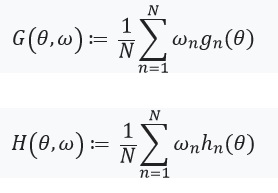
Aquí vale la pena prestar atención a que %2Cw)%3D0) desde
desde ) - solución para
- solución para %3D0) . También definimos:
. También definimos: ) , y la matriz de pesos como:
, y la matriz de pesos como:  . En el caso cuando
. En el caso cuando  tiene una matriz inversa, podemos usar el teorema de la función implícita y la 'regla de la cadena':
tiene una matriz inversa, podemos usar el teorema de la función implícita y la 'regla de la cadena':
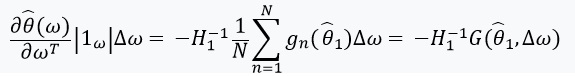
Esta derivada nos permite formar una aproximación lineal. a través de  que se ve así:
que se ve así:
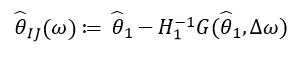
Desde  depende solo de y
depende solo de y  , y no de soluciones para otros valores , en consecuencia, no es necesario volver a calcular y encontrar nuevos valores de ω. En cambio, uno necesita resolver el SLE (sistema de ecuaciones lineales).
, y no de soluciones para otros valores , en consecuencia, no es necesario volver a calcular y encontrar nuevos valores de ω. En cambio, uno necesita resolver el SLE (sistema de ecuaciones lineales).
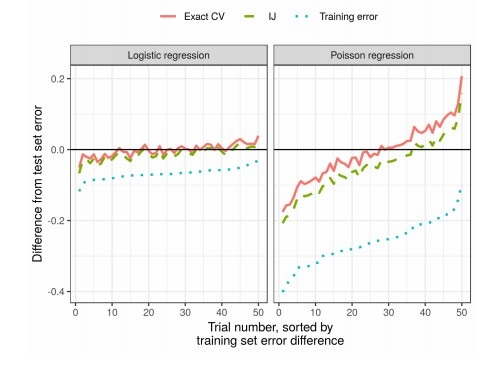
Resultados
En la práctica, esto reduce significativamente el tiempo en comparación con la validación cruzada: