(primera parte aquí: https://habr.com/en/post/456446/ )
Ceph
Introduccion
Dado que la red es uno de los elementos clave de Ceph, y es un poco específica en nuestra empresa, primero le contaremos un poco al respecto.
Habrá muchas menos descripciones de Ceph, principalmente una infraestructura de red. Solo se describirán los servidores Ceph y algunas características de los servidores de virtualización Proxmox.
Entonces: la topología de la red en sí está construida como Leaf-Spine. La arquitectura clásica de tres niveles es una red donde hay Core (enrutadores centrales), Agregación (enrutadores de agregación) y directamente conectados con clientes de Access (enrutadores de acceso):
Esquema de tres niveles
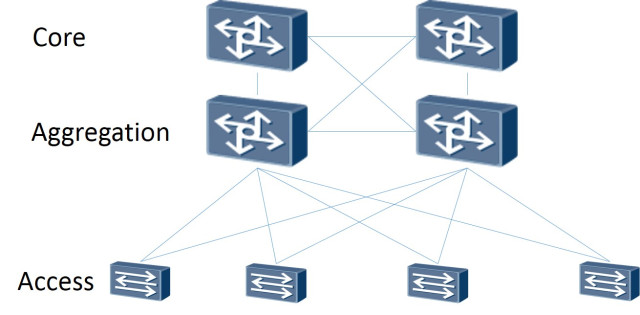
La topología Leaf-Spine consta de dos niveles: Spine (aproximadamente el enrutador principal) y Leaf (ramas).
Esquema de dos niveles

Todo el enrutamiento interno y externo se basa en BGP. El sistema principal que se ocupa del control de acceso, anuncios y más es XCloud.
Los servidores para la reserva de canales (y también para su expansión) están conectados a dos conmutadores L3 (la mayoría de los servidores están conectados a conmutadores Leaf, pero algunos servidores con mayor carga de red están conectados directamente a la columna vertebral del conmutador), y a través de BGP anuncian su dirección de unidifusión, así como cualquier dirección de difusión para el servicio si varios servidores sirven el tráfico del servicio y el equilibrio ECMP es suficiente para ellos. Una característica separada de este esquema, que nos permitió ahorrar en direcciones, pero también requería que los ingenieros se familiarizaran con el mundo IPv6, fue el uso del estándar BGP sin numerar basado en RFC 5549. Durante algún tiempo, Quagga se usó para servidores en BGP para este esquema para servidores y periódicamente hubo problemas con la pérdida de fiestas y conectividad. Pero después de cambiar a FRRouting (cuyos contribuyentes activos son nuestros proveedores de equipos de red: Cumulus y XCloudNetworks), ya no observamos tales problemas.
Por conveniencia, llamamos a todo este esquema general una "fábrica".
Busca un camino
Opciones de configuración de red de clúster:
1) Segunda red en BGP
2) La segunda red en dos conmutadores apilados separados con LACP
3) Segunda red en dos conmutadores aislados separados con OSPF
Pruebas
Las pruebas se llevaron a cabo en dos tipos:
a) red utilizando las utilidades iperf, qperf, nuttcp
b) pruebas internas Ceph ceph-gobench, rados bench, creó rbd y las probó usando dd en uno o varios hilos, usando fio
Todas las pruebas se llevaron a cabo en máquinas de prueba con discos SAS. Las cifras en el rendimiento de rbd no se analizaron mucho, solo se usaron para comparar. Interesado en cambios dependiendo del tipo de conexión.
Primera opción
Las tarjetas de red están conectadas a la fábrica, configuradas BGP.
El uso de este esquema para la red interna no se consideró la mejor opción:
En primer lugar, el exceso de elementos intermedios en forma de interruptores que dan latencia adicional (esta fue la razón principal).
En segundo lugar, inicialmente, para emitir estadísticas a través de s3, utilizaron cualquier dirección emitida en varias máquinas con radosgateway. Esto resultó en el hecho de que el tráfico de las máquinas de front-end a RGW no se distribuyó de manera uniforme, sino que pasó por la ruta más corta, es decir, Nginx de front-end siempre giraba hacia el mismo nodo con RGW que estaba conectado a la hoja compartida con él (esto, por supuesto, era no es el argumento principal: simplemente nos negamos posteriormente de las direcciones anycast para devolver estática). Pero por la pureza del experimento, decidieron realizar pruebas en dicho esquema para tener datos para comparar.
Teníamos miedo de ejecutar pruebas para todo el ancho de banda, ya que la fábrica es utilizada por servidores de producción, y si bloqueamos los enlaces entre la hoja y la columna vertebral, esto perjudicaría algunas de las ventas.
En realidad, esta fue otra razón para rechazar tal esquema.
Las pruebas Iperf con un límite de BW de 3 Gbps de 1, 10 y 100 flujos se utilizaron para comparar con otros esquemas.
Las pruebas mostraron los siguientes resultados:
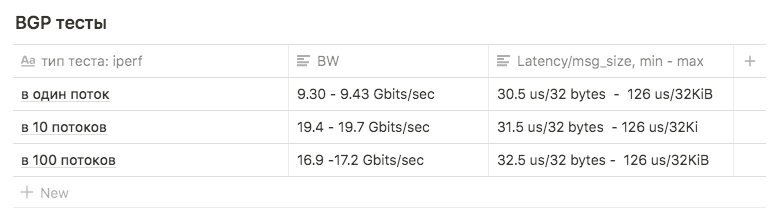
en 1 flujo, aproximadamente 9.30 - 9.43 Gbits / seg (en este caso, el número de retransmisiones crece fuertemente, a 39148 ). La cifra resultó estar cerca del máximo de una interfaz sugiere que se use una de las dos. El número de retransmisiones es de aproximadamente 500-600.
10 transmisiones de 9.63 Gbits / seg por interfaz, mientras que el número de retransmisiones creció a un promedio de 17045.
en 100 hilos, el resultado fue peor que en 10 , mientras que el número de retransmisiones es menor: el valor promedio es 3354
Segunda opción
Lacp
Había dos interruptores Juniper EX4500. Los recogieron en la pila, conectaron el servidor con los primeros enlaces a un conmutador, el segundo al segundo.
La configuración inicial de la unión fue la siguiente:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
Las pruebas iperf y qperf mostraron Bw de hasta 16 Gbits / seg. Decidimos comparar diferentes tipos de mod:
rr, balance-xor y 802.3ad. También comparamos diferentes tipos de hash layer2 + 3 y layer3 + 4 (con la esperanza de obtener una ventaja en la computación hash).
También comparamos los resultados para diferentes valores sysctl de la variable net.ipv4.fib_multipath_hash_policy, (bueno, jugamos un poco con net.ipv4.tcp_congestion_control , aunque no tiene nada que ver con la vinculación . Hay un buen artículo en ValdikSS para esta variable)).
Pero en todas las pruebas, no funcionó para superar el umbral de 18 Gbits / seg (esta cifra se logró usando balance-xor y 802.3ad , no hubo mucha diferencia entre los resultados de la prueba) y este valor se logró "en salto" por ráfagas.
Tercera opción
OSPF
Para configurar esta opción, se eliminó LACP de los conmutadores (se dejó el apilamiento, pero solo se usó para la administración). En cada conmutador, recopilaron un vlan separado para un grupo de puertos (con miras al futuro de que tanto los servidores QA como PROD se atascarán en los mismos conmutadores).
Configurado dos redes privadas planas para cada vlan (una interfaz por conmutador). Encima de estas direcciones está el anuncio de otra dirección de la tercera red privada, que es la red de clúster para CEPH.
Como la red pública (a través de la cual usamos SSH) funciona en BGP, usamos frr para configurar OSPF, que ya está en el sistema.
10.10.10.0/24 y 20.20.20.0/24 : dos redes planas en los conmutadores
172.16.1.0/24 - red para anuncio
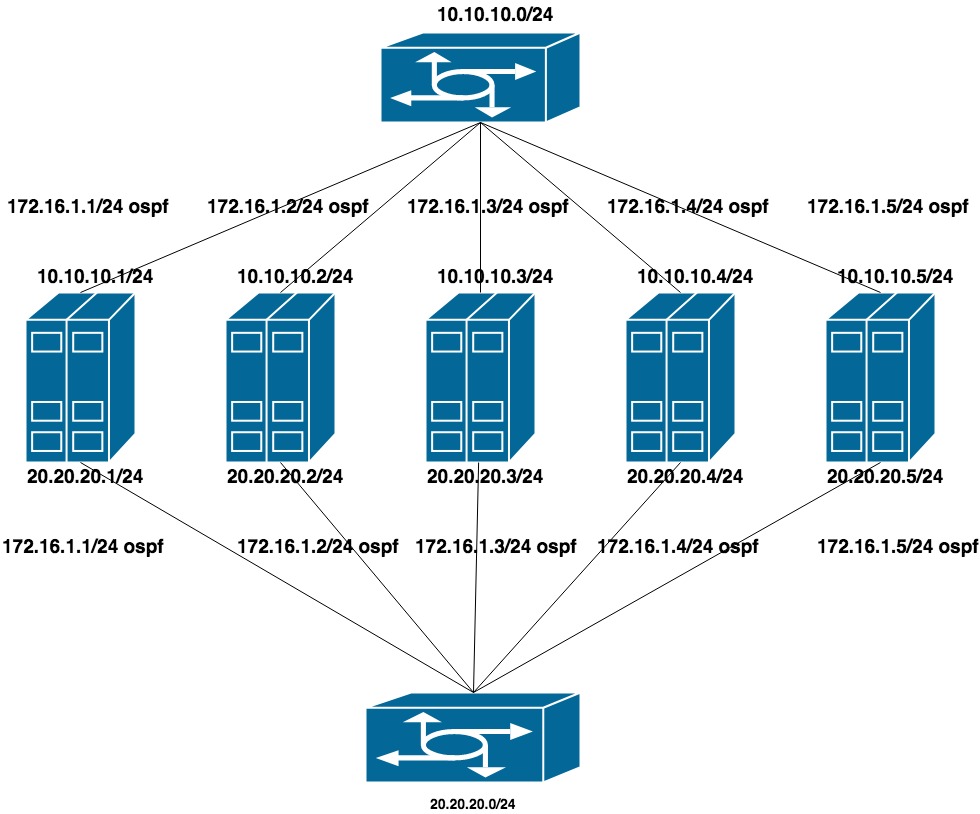
Configuración de la máquina:
interfaces ens1f0 ens1f1 observan una red privada
interfaces ens4f0 ens4f1 mira la red pública
La configuración de red en la máquina se ve así:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
Las configuraciones de Frr se ven así:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
En estas configuraciones, las pruebas de red iperf, qperf, etc. mostró la máxima utilización de ambos canales a 19.8 Gbit / seg, mientras que la latencia se redujo a 20us
Campo Bgp router-id: se utiliza para identificar el nodo al procesar información de enrutamiento y construir rutas. Si no se especifica en la configuración, se selecciona una de las direcciones IP del host. Los diferentes fabricantes de hardware y software pueden tener algoritmos diferentes, en nuestro caso FRR utilizó la dirección IP de bucle invertido más grande. Esto condujo a dos problemas:
1) Si tratamos de colgar otra dirección (por ejemplo, privada de la red 172.16.0.0) más que la actual, esto condujo a un cambio en la identificación del enrutador y, en consecuencia, a reinstalar las sesiones actuales. Esto significa un breve descanso y pérdida de conectividad de red.
2) Si intentamos colgar cualquier dirección de difusión compartida por varias máquinas y se seleccionó como una identificación de enrutador, aparecerían dos nodos con la misma identificación de enrutador en la red .
Parte 2
Después de probar QA, comenzamos a mejorar el combate Ceph.
RED
Pasando de una red a dos
El parámetro de red del clúster es uno de los que no se puede cambiar sobre la marcha especificando el OSD a través de ceph tell osd. * Injectargs. Cambiarlo en la configuración y reiniciar todo el clúster es una solución tolerable, pero realmente no quería tener ni siquiera un pequeño tiempo de inactividad. También es imposible reiniciar un OSD con un nuevo parámetro de red; en algún momento habríamos tenido dos medios clústeres: OSD antiguos en la red anterior, nuevos en el nuevo. Afortunadamente, el parámetro de red del clúster (así como public_network, por cierto) es una lista, es decir, puede especificar varios valores. Decidimos movernos gradualmente: primero agreguemos una nueva red a las configuraciones y luego eliminemos la anterior. Ceph revisa la lista de redes secuencialmente: OSD comienza a trabajar primero con la red que aparece primero.
La dificultad era que la primera red funcionaba a través de bgp y estaba conectada a un conmutador, y la segunda, a ospf y conectada a otras que no estaban físicamente conectadas a la primera. En el momento de la transición, era necesario tener acceso temporal a la red entre las dos redes. La peculiaridad de configurar nuestra fábrica fue que las ACL no se pueden configurar en la red si no está en la lista de las anunciadas (en este caso es "externa" y las ACL solo se pueden crear externamente. Se creó en spains, pero no llegó en hojas).
La solución fue una muleta, complicada, pero funcionó: anunciar la red interna a través de bgp, simultáneamente con ospf.
La secuencia de transición es la siguiente:
1) Configure la red de clúster para ceph en dos redes: a través de bgp y a través de ospf
En configuraciones frr no era necesario cambiar nada, una línea
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
no nos limita en las direcciones anunciadas, la dirección de la red interna en sí se muestra en la interfaz de bucle invertido, fue suficiente para configurar la recepción del anuncio de esta dirección en los enrutadores.
2) Agregue una nueva red a la configuración ceph.conf
cluster network = 172.16.1.0/24, 55.66.77.88/27
y comience a reiniciar el OSD de uno en uno hasta que todos cambien a la red 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3) Luego eliminamos el exceso de red de la configuración
cluster network = 172.16.1.0/24
y repita el procedimiento.
Eso es todo, nos mudamos sin problemas a una nueva red.
Referencias
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench