En este artículo hablaré sobre cómo el proyecto en el que trabajo pasó de ser un gran monolito a un conjunto de microservicios.
El proyecto comenzó su historia hace mucho tiempo, a principios de 2000. Las primeras versiones se escribieron en Visual Basic 6. Con el tiempo, quedó claro que el desarrollo de este lenguaje en el futuro sería difícil de soportar, ya que el IDE y el lenguaje en sí están poco desarrollados. A fines de la década de 2000, se decidió cambiar a un C # más prometedor. La nueva versión fue escrita en paralelo con el refinamiento de la anterior, gradualmente más y más código estaba en .NET. El backend en C # se centró inicialmente en la arquitectura del servicio, sin embargo, durante el desarrollo, se usaron bibliotecas compartidas con lógica y los servicios se lanzaron en un solo proceso. Resultó la aplicación, que llamamos el "servicio monolito".
Una de las pocas ventajas de este paquete era la capacidad de los servicios de llamarse entre sí a través de una API externa. Había requisitos previos obvios para la transición a un servicio más correcto y, en el futuro, la arquitectura de microservicios.
Comenzamos nuestro trabajo de descomposición alrededor de 2015. Todavía no hemos alcanzado un estado ideal: hay partes de un gran proyecto que son difíciles de llamar monolitos, pero tampoco parecen microservicios. Sin embargo, el progreso es sustancial.
Hablaré de él en el artículo.
Contenido
Arquitectura y problemas de la solución existente.
Inicialmente, la arquitectura tenía el siguiente aspecto: la interfaz de usuario es una aplicación separada, la parte monolítica está escrita en Visual Basic 6, la aplicación en .NET era un conjunto de servicios relacionados que funciona con una base de datos bastante grande.
Desventajas de la solución anterior.Punto único de fallaTuvimos un solo punto de falla: la aplicación .NET se ejecutó en un proceso. Si alguno de los módulos fallaba, la aplicación completa fallaba y tenía que reiniciarlo. Dado que estamos automatizando una gran cantidad de procesos para diferentes usuarios, debido a una falla en uno de ellos, algunos no pudieron funcionar por algún tiempo. Y con un error de software, la redundancia tampoco ayudó.
La alineación de mejorasEste defecto es más bien organizativo. Nuestra aplicación tiene muchos clientes y todos quieren finalizarla lo antes posible. Anteriormente, era imposible hacer esto en paralelo, y todos los clientes hacían cola. Este proceso causó un efecto negativo en el negocio, ya que tenían que demostrar que su tarea era valiosa. Y el equipo de desarrollo pasó tiempo organizando esta alineación. Esto tomó mucho tiempo y esfuerzo, y el producto como resultado no pudo cambiar tan rápido como hubiera sido de él.
Uso inapropiado de los recursos.Cuando colocamos servicios en un solo proceso, siempre copiamos completamente la configuración de un servidor a otro. Queríamos colocar los servicios más cargados por separado para no desperdiciar recursos y obtener una administración más flexible de nuestro esquema de implementación.
Es difícil introducir tecnología modernaUn problema familiar para todos los desarrolladores: existe el deseo de introducir tecnologías modernas en el proyecto, pero no hay posibilidad. Con una gran solución monolítica, cualquier actualización de la biblioteca actual, sin mencionar la transición a una nueva, se convierte en una tarea bastante trivial. Lleva mucho tiempo demostrar al líder del equipo que traerá más bonificaciones que nervios gastados.
La complejidad de emitir cambiosEste fue el problema más grave: emitimos lanzamientos cada dos meses.
Cada lanzamiento se convirtió en un verdadero desastre para el banco, a pesar de las pruebas y los esfuerzos de los desarrolladores. Business entendió que al comienzo de la semana algunas de las funcionalidades no funcionarían para él. Y los desarrolladores entendieron que estaban esperando una semana de incidentes graves.
Todos tenían el deseo de cambiar la situación.
Expectativas de microservicio
Entrega de componentes según disponibilidad. Entrega de componentes a medida que están disponibles debido a la descomposición de la solución y la separación de varios procesos.
Pequeños equipos de comida. Esto es importante porque un gran equipo que trabajaba en un viejo monolito era difícil de manejar. Tal equipo se vio obligado a trabajar de acuerdo con un proceso estricto, pero quería más creatividad e independencia. Solo pequeños equipos pueden permitírselo.
Aislamiento de servicios en procesos separados. Idealmente, quería aislar en contenedores, pero una gran cantidad de servicios escritos en .NET Framework se ejecutan solo en Windows. Ahora hay servicios en .NET Core, pero hasta ahora son pocos.
Implementación Flexibilidad. Me gustaría combinar los servicios que necesitamos, y no como las fuerzas del código.
Uso de nuevas tecnologías. Esto es interesante para cualquier programador.
Problemas de transición
Por supuesto, si fuera simple dividir un monolito en microservicios, no tendría que hablar de ello en conferencias y escribir artículos. En este proceso, hay muchas trampas, describiré las principales que interfirieron con nosotros.
El primer problema es típico de la mayoría de los monolitos: la coherencia de la lógica empresarial. Cuando escribimos un monolito, queremos reutilizar nuestras clases para no escribir código adicional. Y al cambiar a microservicios, esto se convierte en un problema: todo el código está muy bien conectado y es difícil separar los servicios.
En el momento del inicio del trabajo, el repositorio tenía más de 500 proyectos y más de 700 mil líneas de código. Esta es una solución bastante grande y el
segundo problema . No fue posible simplemente tomarlo y dividirlo en microservicios.
El tercer problema es la falta de infraestructura necesaria. De hecho, participamos en la copia manual del código fuente a los servidores.
Cómo cambiar de monolito a microservicios
Asignación de microserviciosPrimero, determinamos de inmediato por nosotros mismos que la separación de microservicios es un proceso iterativo. Siempre se nos ha requerido llevar a cabo el desarrollo de tareas comerciales en paralelo. Cómo llevaremos a cabo esto técnicamente ya es nuestro problema. Por lo tanto, nos estábamos preparando para el proceso iterativo. No funcionará de manera diferente si tiene una aplicación grande, y no está lista para ser reescrita desde el principio.
¿Qué métodos utilizamos para aislar microservicios?
La primera forma es portar módulos existentes como servicios. En este sentido, tuvimos suerte: ya había servicios formalizados que funcionaban en el protocolo WCF. Fueron publicados en asambleas separadas. Los movimos por separado, agregando un pequeño lanzador a cada ensamblaje. Fue escrito usando la maravillosa biblioteca Topshelf, que le permite ejecutar la aplicación como un servicio y como una consola. Esto es conveniente para la depuración, ya que no se requieren proyectos adicionales en la solución.
Los servicios se conectaron de acuerdo con la lógica empresarial, ya que utilizaron conjuntos comunes y trabajaron con una base de datos común. Era difícil llamarlos microservicios en su forma pura. Sin embargo, podríamos emitir estos servicios por separado, en diferentes procesos. Esto ya permitió reducir su influencia mutua, reduciendo el problema con el desarrollo paralelo y un único punto de falla.
Construir con un host es solo una línea de código en la clase Program. Escondimos a Topshelf en una clase auxiliar.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
La segunda forma de aislar microservicios: crearlos para resolver nuevos problemas. Si el monolito no crece al mismo tiempo, esto ya es excelente, lo que significa que nos estamos moviendo en la dirección correcta. Para resolver nuevos problemas, tratamos de hacer servicios separados. Si existiera esa oportunidad, entonces creamos más servicios "canónicos" que controlan completamente su modelo de datos, una base de datos separada.
Nosotros, como muchos, comenzamos con los servicios de autenticación y autorización. Son perfectos para esto. Son independientes, por regla general, tienen un modelo de datos separado. Ellos mismos no interactúan con el monolito, solo él recurre a ellos para resolver algunos problemas. En estos servicios, puede comenzar la transición a una nueva arquitectura, depurar la infraestructura en ellos, probar algunos enfoques relacionados con las bibliotecas de red, etc. En nuestra organización, no hay equipos que no puedan hacer un servicio de autenticación.
La tercera forma de aislar los microservicios que utilizamos es un poco específica para nosotros. Esto está sacando la lógica empresarial de la capa de interfaz de usuario. Tenemos la aplicación de IU de escritorio principal, como el backend, está escrita en C #. Los desarrolladores periódicamente cometieron errores y llevaron a cabo en la UI partes de la lógica que debería haber existido en el backend y reutilizado.
Si observa un ejemplo real del código de la parte de la interfaz de usuario, puede ver que la mayor parte de esta solución contiene lógica comercial real, que es útil en otros procesos, no solo para crear un formulario de interfaz de usuario.
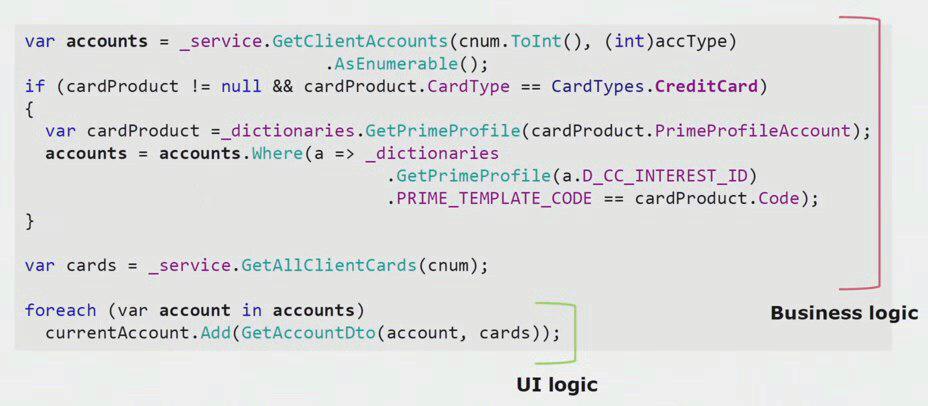
La lógica de la interfaz de usuario real es solo el último par de líneas. Lo transferimos al servidor para poder reutilizarlo, reduciendo así la interfaz de usuario y logrando la arquitectura correcta.
La cuarta forma más importante de aislar microservicios , que le permite reducir el monolito, es eliminar los servicios existentes con procesamiento. Cuando sacamos los módulos existentes tal cual, el resultado no siempre es agradable para los desarrolladores, y el proceso comercial desde el momento en que se creó la funcionalidad podría quedar desactualizado. Gracias a la refactorización, podemos respaldar un nuevo proceso comercial porque los requisitos comerciales cambian constantemente. Podemos mejorar el código fuente, eliminar defectos conocidos, crear un mejor modelo de datos. Hay muchas ventajas.
El departamento de servicios de procesamiento está inextricablemente vinculado al concepto de un contexto limitado. Este es un concepto de diseño orientado a temas. Significa una sección de modelo de dominio en la que todos los términos de un solo idioma se definen de manera única. Considere el contexto de seguros y facturas como un ejemplo. Tenemos una aplicación monolítica, y es necesario trabajar con la cuenta en el seguro. Esperamos que el desarrollador encuentre la clase "Cuenta" existente en otro ensamblado, haga un enlace desde la clase "Seguro", y obtendremos un código de trabajo. Se respetará el principio DRY, la tarea mediante el uso del código existente se realizará más rápido.
Como resultado, resulta que los contextos de cuentas y seguros están conectados. Cuando surgen nuevos requisitos, esta conexión interferirá con el desarrollo, aumentando la complejidad de una lógica empresarial ya compleja. Para resolver este problema, debe encontrar los límites entre los contextos en el código y eliminar sus violaciones. Por ejemplo, en el contexto del seguro, es bastante posible que el número de cuenta de 20 dígitos del Banco Central y la fecha de apertura de la cuenta sean suficientes.
Para separar estos contextos limitados entre sí y comenzar el proceso de extracción de microservicios de una solución monolítica, utilizamos un enfoque como la creación de API externas dentro de la aplicación. Si supiéramos que algún módulo debería convertirse en un microservicio, de alguna manera cambiar dentro del proceso, entonces inmediatamente realizamos llamadas a la lógica, que pertenece a otro contexto limitado, a través de llamadas externas. Por ejemplo, a través de REST o WCF.
Decidimos por nosotros mismos que no evitaríamos el código que requeriría transacciones distribuidas. En nuestro caso, resultó ser bastante fácil seguir esta regla. Todavía no nos hemos encontrado con situaciones en las que realmente se necesitan transacciones distribuidas de forma rígida: la consistencia final entre los módulos es suficiente.
Considere un ejemplo específico. Tenemos el concepto de una orquesta - transportadora, que procesa la esencia de la "aplicación". Se turna para crear un cliente, una cuenta y una tarjeta bancaria. Si el cliente y la cuenta se crearon con éxito, y la creación de la tarjeta falló, la aplicación no pasa al estado "con éxito" y permanece en el estado "tarjeta no creada". En el futuro, la actividad en segundo plano lo recogerá y terminará. El sistema está en un estado de inconsistencia durante algún tiempo, pero esto, en general, nos conviene.
Sin embargo, si surge una situación en la que será necesario guardar consistentemente parte de los datos, lo más probable es que ampliemos el servicio para procesar esto en un solo proceso.
Consideremos un ejemplo de asignación de microservicios. ¿Cómo se puede llevar de manera relativamente segura a producción? En este ejemplo, tenemos una parte separada del sistema: el módulo de servicio de salario, una de las secciones del código del que nos gustaría hacer microservicios.
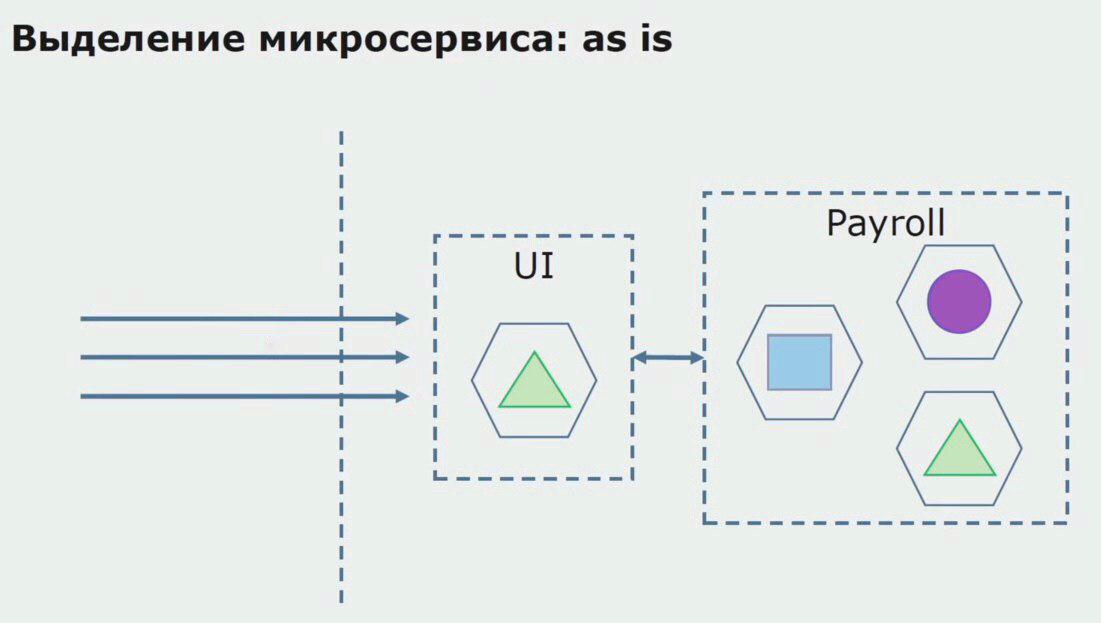
En primer lugar, creamos un microservicio reescribiendo el código. Mejoramos algunos puntos que no nos convenían. Nos damos cuenta de los nuevos requisitos comerciales del cliente. Agregamos al paquete entre la interfaz de usuario y el back-end API de Gateway, que proporcionará el desvío de llamadas.
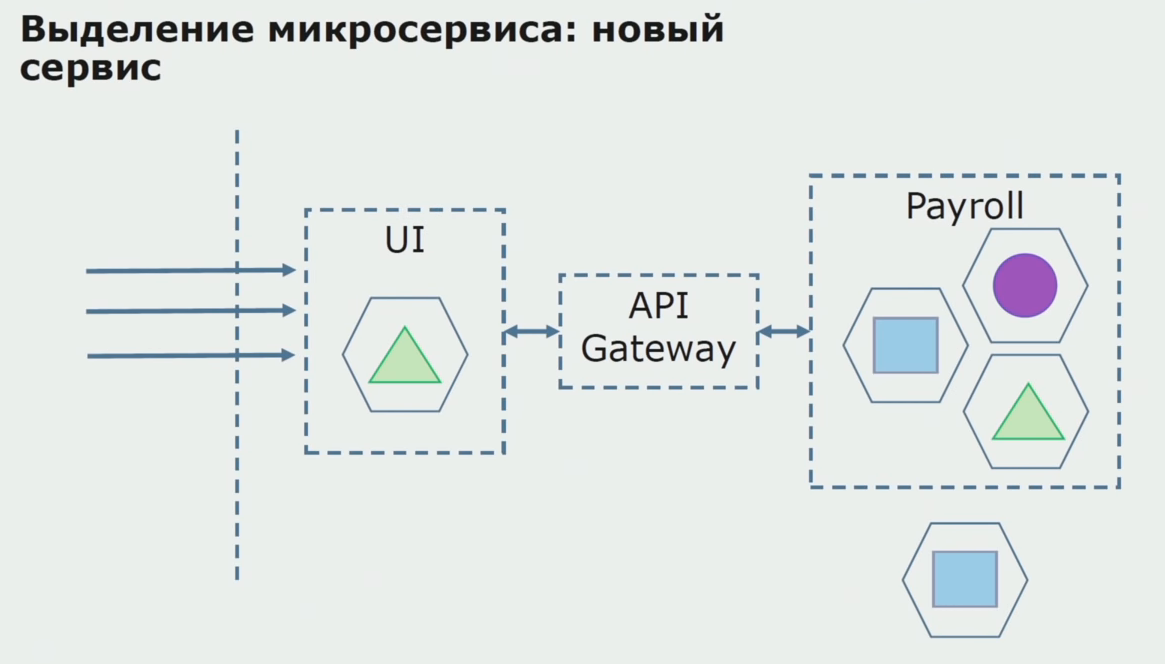
A continuación, lanzamos esta configuración en funcionamiento, pero en el estado del piloto. La mayoría de nuestros usuarios aún trabajan con procesos comerciales antiguos. Para los nuevos usuarios, estamos desarrollando una nueva versión de una aplicación monolítica que este proceso ya no contiene. De hecho, tenemos un montón de monolitos y microservicios trabajando en forma de piloto.
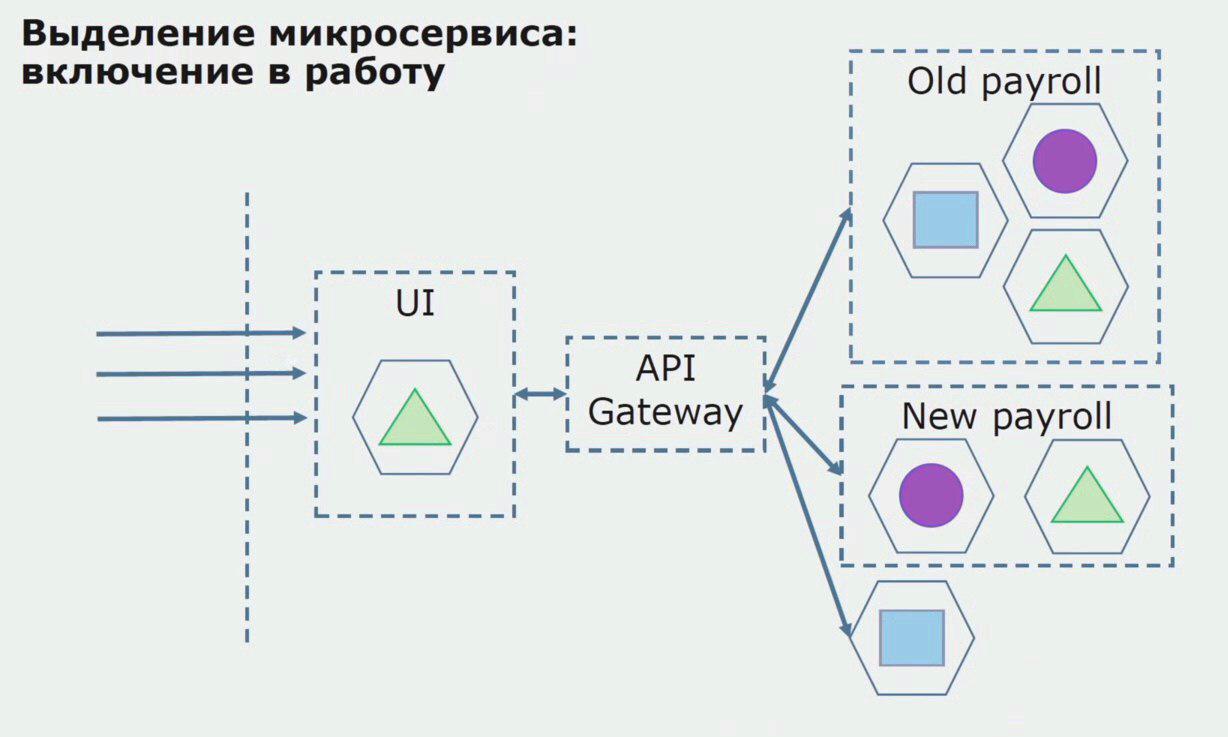
Con un piloto exitoso, entendemos que la nueva configuración es realmente operativa, podemos eliminar el viejo monolito de la ecuación y dejar la nueva configuración en el lugar de la solución anterior.
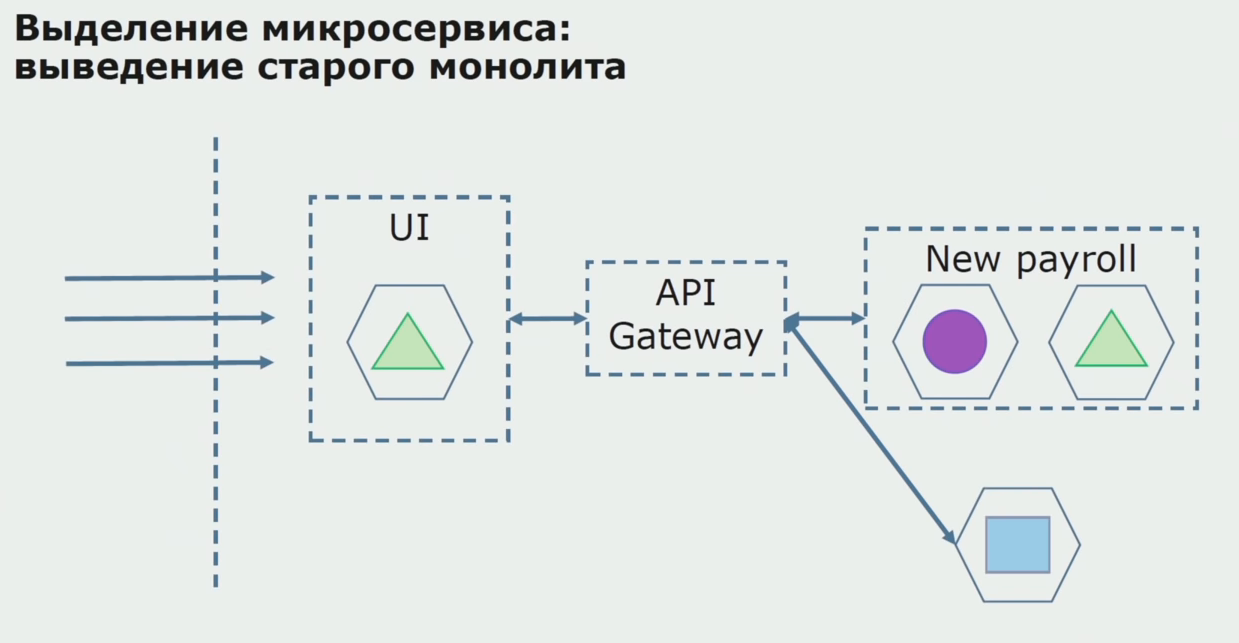
En total, utilizamos casi todos los métodos existentes para separar el código fuente de un monolito. Todos ellos nos permiten reducir el tamaño de partes de la aplicación y transferirlas a nuevas bibliotecas, mejorando el código fuente.
Trabajar con un DB
La base de datos se puede dividir peor que el código fuente, ya que contiene no solo el esquema actual, sino también los datos históricos acumulados.
Nuestra base de datos, como muchas otras, tenía otro inconveniente importante: su gran tamaño. Esta base de datos fue diseñada de acuerdo con la intrincada lógica de negocios del monolito, y se han acumulado enlaces entre tablas de varios contextos limitados.
En nuestro caso, además de todos los problemas (una gran base de datos, muchas relaciones, a veces fronteras incomprensibles entre tablas), surgió un problema en muchos proyectos grandes: el uso de la plantilla de base de datos compartida. Los datos se tomaron de las tablas a través de la vista, a través de la replicación, y se enviaron a otros sistemas donde se necesita esta replicación. Como resultado, no pudimos eliminar las tablas en un esquema separado, porque se usaron activamente.
La separación nos ayuda a dividirnos en contextos limitados en el código. Por lo general, nos da una idea bastante buena de cómo dividimos los datos a nivel de la base de datos. Entendemos qué tablas se relacionan con un contexto limitado y cuáles se relacionan con otro.
Aplicamos dos formas globales de particionar la base de datos: particionando las tablas existentes y particionando con el procesamiento.
La separación de las tablas existentes es un método que es bueno usar si la estructura de datos es de alta calidad, satisface los requisitos comerciales y se adapta a todos. En este caso, podemos seleccionar tablas existentes en un esquema separado.
Se necesita un departamento de procesamiento cuando el modelo de negocio ha cambiado mucho y las tablas ya no nos satisfacen por completo.
Separa las tablas existentes. Necesitamos determinar qué separaremos. Sin este conocimiento, nada saldrá de ello, y aquí la separación de contextos limitados en el código nos ayudará. Como regla general, si puede comprender los límites de los contextos en el código fuente, queda claro qué tablas deben incluirse en la lista para la separación.
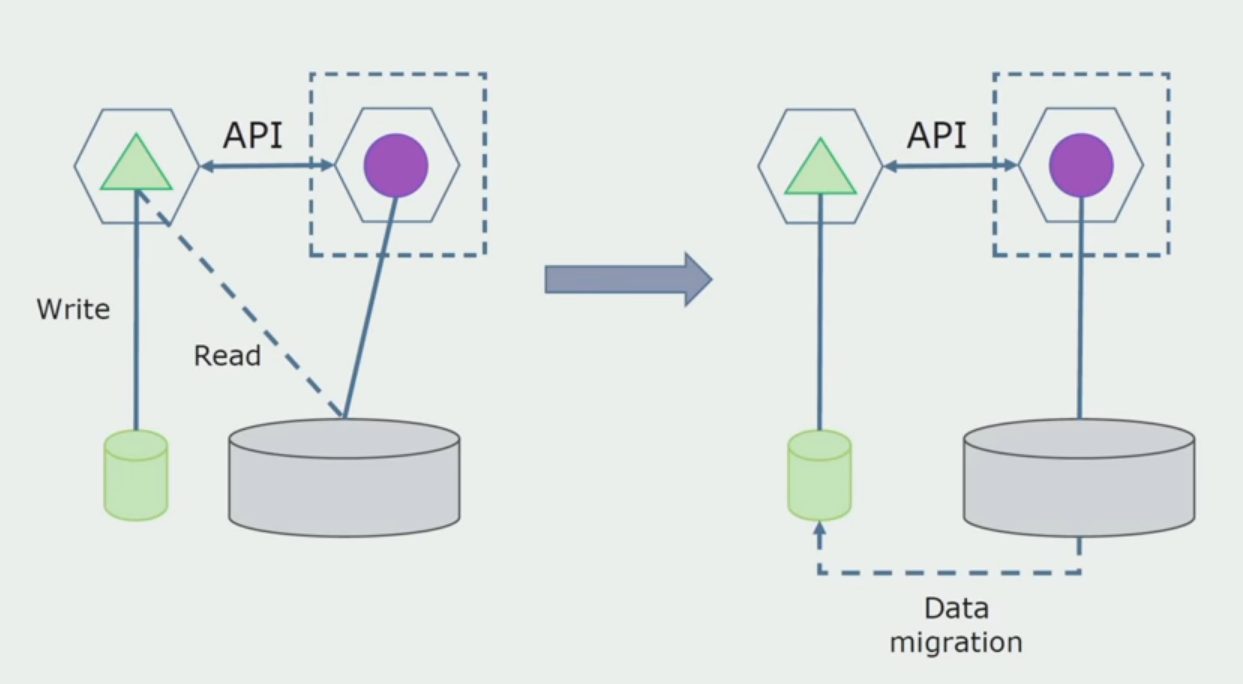
Imagine que tenemos una solución en la que dos módulos monolíticos interactúan con una base de datos. Necesitamos asegurarnos de que solo un módulo interactúe con la parte de las tablas separadas, y el otro comience a interactuar con él a través de la API. Para empezar, es suficiente que solo se haga una entrada a través de la API. Esta es una condición necesaria para que podamos hablar sobre la independencia de los microservicios. Los enlaces de lectura pueden permanecer hasta que haya un gran problema.

Como siguiente paso, ya podemos seleccionar una sección de código que funcione con tablas separables con o sin procesamiento en un microservicio separado y ejecutarlo en un proceso separado, contenedor. Este será un servicio separado con comunicación con la base de datos monolítica y aquellas tablas que no están directamente relacionadas con ella. El monolito aún interactúa con la parte desmontable para leer.

Más adelante eliminaremos esta conexión, es decir, leer los datos de la aplicación monolítica de las tablas separadas también se transferirá a la API.
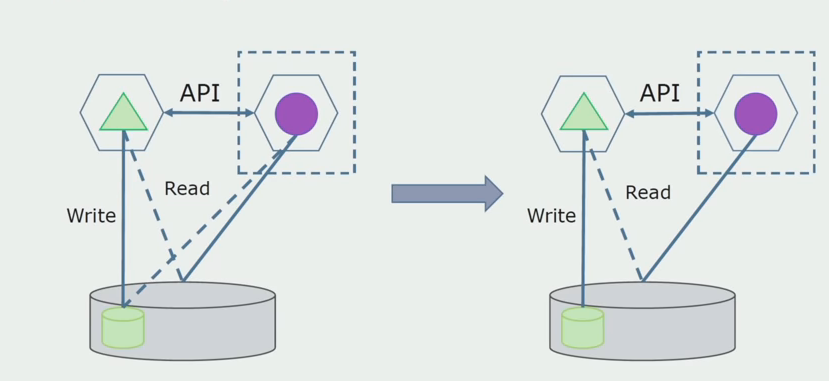
A continuación, seleccionamos de la base de datos general las tablas con las que solo funciona el nuevo microservicio. Podemos colocar tablas en un esquema separado o incluso en una base de datos física separada. Hubo una conexión para la lectura entre el microservicio y la base de datos de monolitos, pero no hay nada de qué preocuparse, en esta configuración puede vivir durante mucho tiempo.
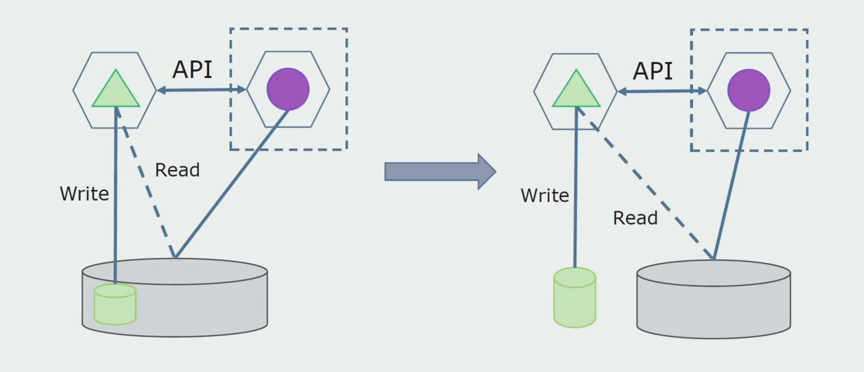
El último paso es eliminar completamente todas las conexiones. En este caso, es posible que necesitemos migrar datos de la base de datos principal. A veces queremos reutilizar en varias bases de datos algunos datos o directorios que se replican desde sistemas externos. Periódicamente nos encontramos con esto.
 Departamento de procesamiento.
Departamento de procesamiento. Este método es muy similar al primero, solo va en el orden inverso. Inmediatamente tenemos una nueva base de datos y un nuevo microservicio que interactúa con el monolito a través de la API. Pero al mismo tiempo, queda un conjunto de tablas de bases de datos que queremos eliminar en el futuro. Ya no lo necesitaremos, en el nuevo modelo lo reemplazamos.
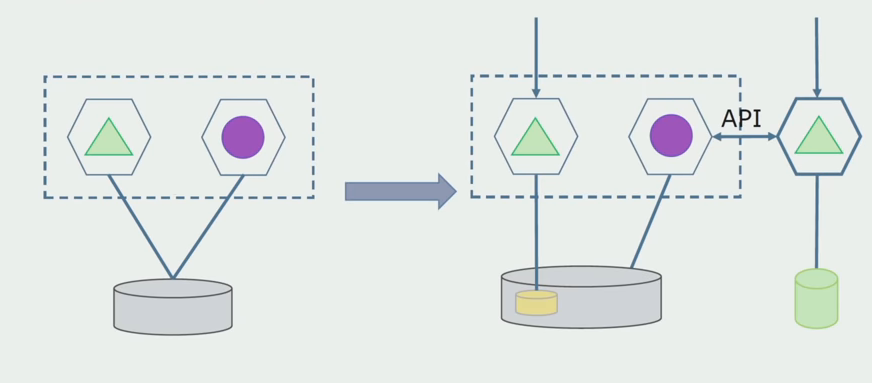
Para que este esquema funcione, lo más probable es que necesitemos un período de transición.
Hay dos enfoques posibles.
Primero : duplicamos todos los datos en las bases de datos nuevas y antiguas. En este caso, tenemos redundancia de datos, puede haber problemas con la sincronización. Pero luego podemos tomar dos clientes diferentes. Uno funcionará con la nueva versión, el otro con la antigua.
Segundo : compartimos datos de acuerdo con algunas características comerciales. Por ejemplo, en nuestro sistema había 5 productos almacenados en la base de datos anterior. El sexto como parte de una nueva tarea comercial, colocamos una nueva base de datos. Pero necesitamos la API de Gateway, que sincroniza estos datos y muestra al cliente dónde y qué llevar.
Ambos enfoques están funcionando, elija según la situación.
Después de asegurarnos de que todo funciona, la parte del monolito que funciona con las antiguas estructuras de bases de datos puede deshabilitarse.
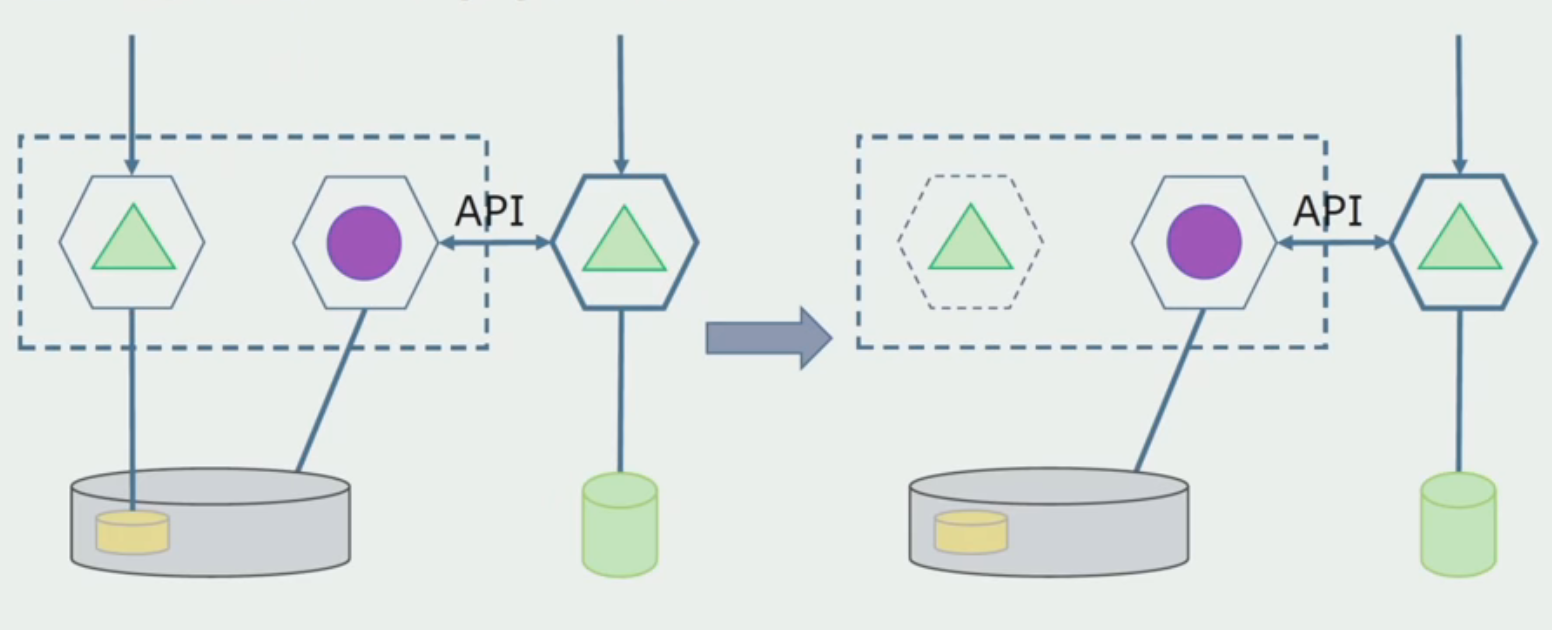
El último paso es eliminar las viejas estructuras de datos.

En resumen, podemos decir que tenemos problemas con la base de datos: es difícil trabajar con ella en comparación con el código fuente, es más difícil de separar, pero esto puede y debe hacerse. Encontramos algunas formas que permiten que esto se haga con bastante seguridad, sin embargo, es más fácil cometer un error con los datos que con el código fuente.
Trabajando con código fuente
Así era el diagrama del código fuente cuando comenzamos a analizar un proyecto monolítico.

Se puede dividir condicionalmente en tres capas. Esta es una capa de módulos lanzados, complementos, servicios y actividades individuales. De hecho, estos fueron los puntos de entrada dentro de la solución monolítica. Todos ellos estaban fuertemente unidos con una capa común. Tenía una lógica de negocios que se compartía entre servicios y muchas conexiones. Cada servicio y complemento utilizaba hasta 10 o más conjuntos comunes, dependiendo de su tamaño y la conciencia de los desarrolladores.
Tuvimos suerte, teníamos bibliotecas de infraestructura que podían usarse por separado.
Algunas veces surgió una situación en la que algunos de los objetos comunes no pertenecían a esta capa, sino que eran bibliotecas de infraestructura. Esto se decidió cambiando el nombre.
Más preocupado por contextos limitados. Solía ser que 3-4 contextos se mezclaron en un ensamblaje común y se usaron entre sí dentro de las mismas funciones comerciales. Era necesario comprender dónde se puede dividir esto y en qué límites, y qué hacer a continuación con el mapeo de esta separación en ensambles de código fuente.
Hemos formulado varias reglas para el proceso de separación de código.
Primero : ya no queríamos compartir la lógica empresarial entre servicios, actividades y complementos. Querían hacer que la lógica de negocios sea independiente en el marco de los microservicios. Por otro lado, los microservicios, en el caso ideal, se perciben como servicios que existen de manera completamente independiente. Creo que este enfoque es algo derrochador y es difícil lograrlo, porque, por ejemplo, los servicios en C # en cualquier caso estarán conectados por una biblioteca estándar. Nuestro sistema está escrito en C #, otras tecnologías aún no se han utilizado. Por lo tanto, decidimos que podemos permitirnos usar conjuntos técnicos comunes. Lo principal es que no tienen ningún fragmento de lógica empresarial. Si tiene un contenedor conveniente sobre el ORM que usa, copiarlo de un servicio a otro es muy costoso.
Nuestro equipo es fanático del diseño orientado a temas, por lo que la "arquitectura de cebolla" es perfecta para nosotros. La base de nuestros servicios no era una capa de acceso a datos, sino un ensamblaje con lógica de dominio, que contiene solo lógica de negocios y carece de conexiones de infraestructura. Al mismo tiempo, podemos modificar independientemente el ensamblado del dominio para resolver los problemas asociados con los marcos.
En esta etapa, nos encontramos con el primer problema grave. Se suponía que el servicio se refería a un ensamblaje de dominio, queríamos hacer que la lógica fuera independiente, y aquí el principio DRY interfirió fuertemente con nosotros. Para evitar la duplicación, los desarrolladores querían reutilizar las clases de los ensamblados vecinos y, como resultado, los dominios comenzaron a comunicarse entre sí nuevamente. Analizamos los resultados y decidimos que quizás el problema también se encuentre en el área del dispositivo de almacenamiento del código fuente. Teníamos un gran repositorio en el que yacían todos los códigos fuente. La solución para todo el proyecto fue muy difícil de ensamblar en una máquina local. Por lo tanto, se crearon pequeñas soluciones separadas para las partes del proyecto, y nadie prohibió agregarles ningún conjunto Común o de dominio y reutilizarlas. La única herramienta que no nos permitió hacer esto fue el código de revisión. Pero a veces también se estrellaba.
Luego comenzamos a cambiar a un modelo con repositorios separados. La lógica empresarial ha dejado de fluir de un servicio a otro, los dominios se han vuelto verdaderamente independientes. Los contextos limitados son más claros. ¿Cómo reutilizamos las bibliotecas de infraestructura? Los asignamos a un repositorio separado, luego los colocamos en los paquetes Nuget que colocamos en Artifactory. Con cualquier cambio, el montaje y la publicación se producen automáticamente.
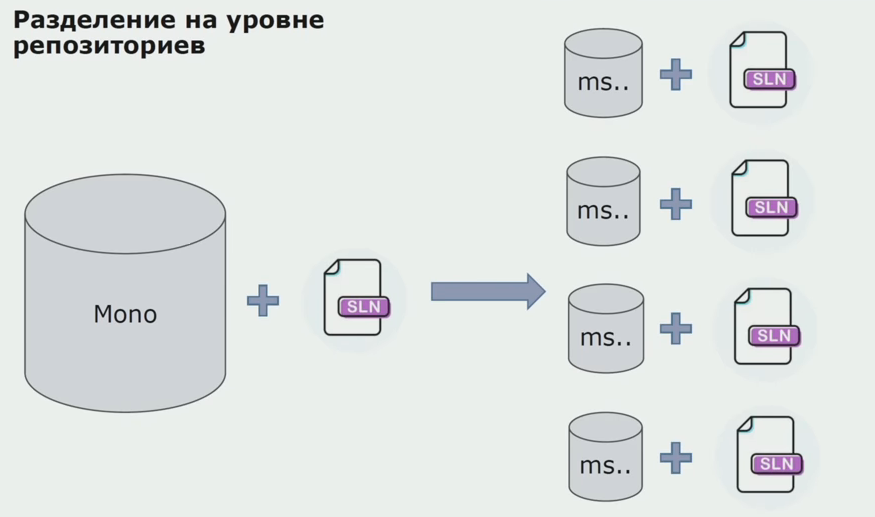
Nuestros servicios comenzaron a referirse a los paquetes de infraestructura interna de la misma manera que a los externos. Descargamos bibliotecas externas de Nuget. Para trabajar con Artifactory, donde colocamos estos paquetes, utilizamos dos administradores de paquetes. En repositorios pequeños, también usamos Nuget. En repositorios con varios servicios, utilizamos Paket, que proporciona más consistencia de versión entre módulos.
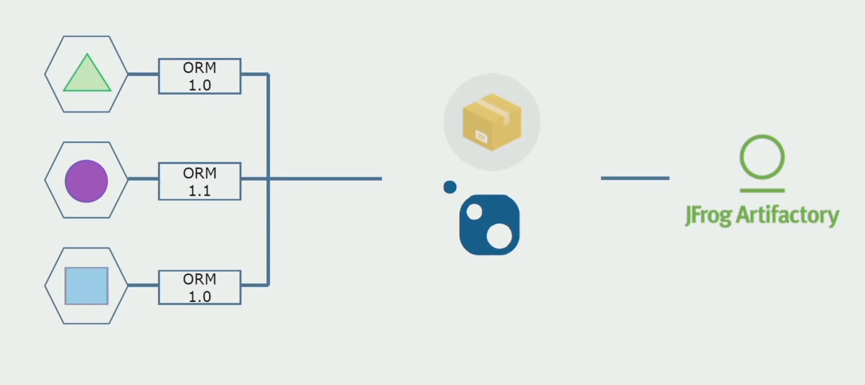
Por lo tanto, trabajando en el código fuente, cambiando ligeramente la arquitectura y compartiendo repositorios, hacemos que nuestros servicios sean más independientes.
Problemas de infraestructura
La mayoría de las desventajas de cambiar a microservicios están relacionadas con la infraestructura. Necesitará una implementación automatizada, necesitará nuevas bibliotecas para la infraestructura.
Instalación manual en ambientes.Inicialmente, instalamos la solución en el entorno manualmente. Para automatizar este proceso, creamos una tubería de CI / CD. Elegimos el proceso de entrega continua, porque la implementación continua para nosotros aún no es aceptable desde el punto de vista de los procesos comerciales. Por lo tanto, el envío a la operación se lleva a cabo mediante el botón y para la prueba, automáticamente.
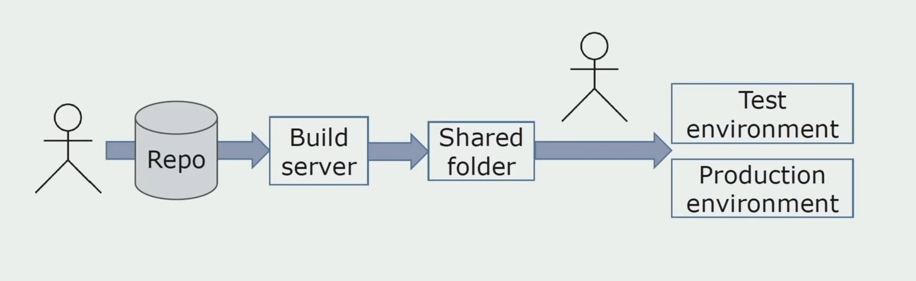
Usamos Atlassian, Bitbucket para almacenar el código fuente y Bamboo para el ensamblaje. Nos gusta escribir scripts de ensamblaje en Cake porque es el mismo C #. Los paquetes preparados llegan a Artifactory, y Ansible llega automáticamente a los servidores de prueba, después de lo cual se pueden probar de inmediato.
Registro separado
En un momento, una de las ideas del monolito era la provisión de tala conjunta. También necesitábamos comprender qué hacer con los registros individuales que se encuentran en los discos. Los registros se nos escriben en archivos de texto. Decidimos usar la pila ELK estándar. No escribimos directamente al ELK a través de proveedores, pero decidimos que finalizaríamos los registros de texto y anotábamos la ID de rastreo en ellos como un identificador, agregando el nombre del servicio para que estos registros pudieran analizarse.

Usando Filebeat tenemos la oportunidad de recopilar nuestros registros de los servidores, luego convertirlos, usando Kibana para crear solicitudes en la interfaz de usuario y ver cómo transcurrió la llamada entre los servicios. La identificación de rastreo ayuda mucho en esto.
Prueba y depuración de servicios relacionados
Inicialmente, no entendíamos completamente cómo depurar los servicios desarrollados. Todo era simple con el monolito, lo ejecutamos en la máquina local. Al principio, intentaron hacer lo mismo con los microservicios, pero a veces para iniciar completamente un microservicio, debe iniciar varios otros, lo cual es inconveniente. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.