Cada sistema de monitoreo enfrenta tres tipos de problemas de rendimiento.
En primer lugar, un buen sistema de monitoreo debería recibir, procesar y registrar rápidamente los datos provenientes del exterior. La cuenta va a microsegundos. Por casualidad, esto puede parecer poco obvio, pero cuando el sistema se vuelve lo suficientemente grande, todas estas fracciones de segundos se resumen, convirtiéndose en demoras claramente notables.

La segunda tarea es proporcionar un acceso conveniente a grandes conjuntos de métricas recopiladas previamente (en otras palabras, a datos históricos). Los datos históricos se utilizan en una amplia variedad de contextos. Por ejemplo, se generan informes y gráficos a partir de ellos, se crean controles agregados sobre ellos, los desencadenantes dependen de ellos. Si hay retrasos en el acceso al historial, esto afecta inmediatamente la velocidad de todo el sistema en su conjunto.
En tercer lugar, los datos históricos ocupan mucho espacio. Incluso las configuraciones de monitoreo relativamente modestas adquieren rápidamente un historial sólido. Pero casi nadie quiere tener a mano el historial de carga del procesador de cinco años de antigüedad, por lo que el sistema de monitoreo debería poder no solo grabar bien, sino también borrar bien el historial (en Zabbix este proceso se llama "limpieza"). La eliminación de datos antiguos no tiene que ser tan eficiente como la recopilación y el análisis de datos nuevos, pero las operaciones de eliminación intensivas se basan en recursos valiosos de DBMS y pueden ralentizar las operaciones más críticas.
Los dos primeros problemas se resuelven mediante el almacenamiento en caché. Zabbix admite varias cachés especializadas para acelerar las operaciones de lectura y escritura de datos. Los mecanismos DBMS en sí mismos no son adecuados aquí, porque incluso el algoritmo de almacenamiento en caché de propósito general más avanzado no sabrá qué estructuras de datos requieren acceso instantáneo en un momento dado.
Monitoreo y datos de series temporales
Todo está bien siempre que los datos estén en la memoria del servidor Zabbix. Pero la memoria no es infinita y en algún momento los datos deben escribirse (o leerse) en la base de datos. Y si el rendimiento de la base de datos está muy por detrás de la velocidad de recopilación de métricas, incluso los algoritmos de almacenamiento en caché especiales más avanzados no ayudarán durante mucho tiempo.
El tercer problema también se reduce al rendimiento de la base de datos. Para resolverlo, debe elegir una estrategia de eliminación confiable que no interfiera con otras operaciones de la base de datos. Por defecto, Zabbix elimina datos históricos en lotes de varios miles de registros por hora. Puede configurar períodos de mantenimiento más largos o paquetes de mayor tamaño si la velocidad de la recopilación de datos y el lugar en la base de datos lo permiten. Pero con una gran cantidad de métricas y / o una alta frecuencia de recopilación, la configuración adecuada de limpieza puede ser una tarea desalentadora, ya que un programa de eliminación de datos puede no mantenerse al ritmo de la grabación de nuevos.
Resumiendo, el sistema de monitoreo resuelve problemas de rendimiento en tres direcciones: recolectando datos nuevos y escribiéndolos en la base de datos usando consultas SQL INSERT, accediendo a datos usando consultas SELECT y eliminando datos usando DELETE. Veamos cómo se ejecuta una consulta SQL típica:
- El DBMS analiza la consulta y verifica si hay errores de sintaxis. Si la solicitud es sintácticamente correcta, el motor construye un árbol de sintaxis para su posterior procesamiento.
- El planificador de consultas analiza el árbol de sintaxis y calcula las diversas formas (rutas) para ejecutar la solicitud.
- El planificador calcula la forma más barata. En el proceso, tiene en cuenta muchas cosas: qué tan grandes son las tablas, si es necesario ordenar los resultados, si hay índices aplicables a la consulta, etc.
- Cuando se encuentra la ruta óptima, el motor ejecuta la consulta accediendo a los bloques de datos deseados (usando índices o escaneo secuencial), aplica los criterios de clasificación y filtrado, recopila el resultado y lo devuelve al cliente.
- Para insertar, modificar y eliminar consultas, el motor también debe actualizar los índices para las tablas correspondientes. Para tablas grandes, esta operación puede llevar más tiempo que trabajar con los datos en sí.
- Lo más probable es que el DBMS también actualice las estadísticas internas del uso de datos para llamadas posteriores al programador de consultas.
En general, hay mucho trabajo. La mayoría de los DBMS proporcionan una gran cantidad de configuraciones para la optimización de consultas, pero generalmente se centran en algunos flujos de trabajo promedio en los que la inserción y eliminación de registros ocurre aproximadamente con la misma frecuencia que el cambio.
Sin embargo, como se mencionó anteriormente, para los sistemas de monitoreo, las operaciones más típicas son agregar y eliminar periódicamente en modo por lotes. El cambio de datos agregados anteriormente casi nunca ocurre, y el acceso a los datos implica el uso de funciones agregadas. Además, generalmente los valores de las métricas agregadas se ordenan por tiempo. Tales datos se conocen comúnmente como
series de tiempo :
La serie temporal es una serie de puntos de datos indexados (o listados o graffiti) en un orden temporal.
Desde el punto de vista de la base de datos, las series temporales tienen las siguientes propiedades:
- Las series de tiempo pueden ubicarse en un disco como una secuencia de bloques ordenados por tiempo.
- Las tablas de series de tiempo se pueden indexar utilizando una columna de tiempo.
- La mayoría de las consultas SQL SELECT usarán las cláusulas WHERE, GROUP BY u ORDER BY en una columna que indica el tiempo.
- Por lo general, los datos de series temporales tienen una "fecha de vencimiento" después de la cual se pueden eliminar.
Obviamente, las bases de datos SQL tradicionales no son adecuadas para almacenar dichos datos, ya que las optimizaciones de uso general no tienen en cuenta estas cualidades. Por lo tanto, en los últimos años, han aparecido bastantes DBMS nuevos orientados al tiempo, como, por ejemplo, InfluxDB. Pero todos los DBMS populares para series temporales tienen un inconveniente significativo: la falta de soporte SQL completo. Además, la mayoría de ellos ni siquiera son CRUD (Crear, Leer, Actualizar, Eliminar).
¿Puede Zabbix usar estos DBMS de alguna manera? Uno de los enfoques posibles es transferir datos históricos para el almacenamiento a una base de datos externa especializada en las series de tiempo. Dado que la arquitectura Zabbix admite backends externos para almacenar datos históricos (por ejemplo, el soporte Elasticsearch se implementa en Zabbix), a primera vista, esta opción parece muy razonable. Pero si admitiéramos uno o varios DBMS para series temporales como servidores externos, los usuarios tendrían que tener en cuenta los siguientes puntos:
- Otro sistema que necesita ser explorado, configurado y mantenido. Otro lugar para realizar un seguimiento de la configuración, el espacio en disco, las políticas de almacenamiento, el rendimiento, etc.
- Reducción de la tolerancia a fallas del sistema de monitoreo, como aparece un nuevo enlace en la cadena de componentes relacionados.
Para algunos usuarios, los beneficios del almacenamiento dedicado dedicado para datos históricos pueden ser mayores que las molestias de tener que preocuparse por otro sistema. Pero para muchos, esta es una complicación innecesaria. También vale la pena recordar que, dado que la mayoría de estas soluciones especializadas tienen sus propias API, la complejidad de la capa universal para trabajar con bases de datos Zabbix aumentará notablemente. Y, idealmente, preferimos crear nuevas funciones, en lugar de luchar contra otras API.
Surge la pregunta: ¿hay alguna forma de aprovechar el DBMS para series temporales, pero sin perder la flexibilidad y las ventajas de SQL? Naturalmente, no existe una respuesta universal, pero una solución específica se acercó mucho a la respuesta:
TimescaleDB .
¿Qué es TimescaleDB?
TimescaleDB (TSDB) es una extensión de PostgreSQL que optimiza el trabajo con series temporales en una base de datos PostgreSQL (PG) normal. Aunque, como se mencionó anteriormente, no hay escasez de soluciones de series temporales bien escalables en el mercado, una característica única de TimescaleDB es su capacidad para funcionar bien con series temporales sin sacrificar la compatibilidad y los beneficios de las bases de datos relacionales CRUD tradicionales. En la práctica, esto significa que obtenemos lo mejor de ambos mundos. La base de datos sabe qué tablas deben considerarse como series de tiempo (y aplica todas las optimizaciones necesarias), pero puede trabajar con ellas de la misma manera que con las tablas normales. ¡Además, no se requiere que las aplicaciones sepan que TSDB controla los datos!
Para marcar una tabla como una tabla de series de tiempo (en TSDB esto se llama hipertable), simplemente llame al procedimiento create_ hypertable () TSDB. Bajo el capó, TSDB divide esta tabla en los llamados fragmentos (el término en inglés es fragmentado) de acuerdo con las condiciones especificadas. Los fragmentos se pueden representar como secciones controladas automáticamente de una tabla. Cada fragmento tiene un rango de tiempo correspondiente. Para cada fragmento, TSDB también establece índices especiales para que trabajar con un rango de datos no afecte el acceso a otros.
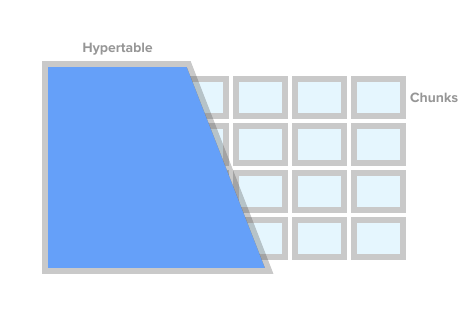 Imagen Hipertable de timescaledb.com
Imagen Hipertable de timescaledb.comCuando la aplicación agrega un nuevo valor para la serie temporal, la extensión dirige este valor al fragmento deseado. Si el rango para el tiempo del nuevo valor no está definido, TSDB creará un nuevo fragmento, le asignará el rango deseado e insertará el valor allí. Si una aplicación solicita datos de un hipertable, antes de ejecutar la solicitud, la extensión verifica qué fragmentos están asociados con esta solicitud.
Pero eso no es todo. TSDB complementa el robusto y probado ecosistema PostgreSQL con una gran cantidad de cambios de rendimiento y escalabilidad. Estos incluyen la adición rápida de nuevos registros, consultas rápidas y eliminaciones por lotes prácticamente gratuitas.
Como se señaló anteriormente, para controlar el tamaño de la base de datos y cumplir con las políticas de retención (es decir, no almacenar datos por más tiempo del necesario), una buena solución de monitoreo debería eliminar efectivamente una gran cantidad de datos históricos. Con TSDB, podemos eliminar la historia deseada simplemente eliminando ciertos fragmentos del hipertable. En este caso, la aplicación no necesita rastrear fragmentos por nombre o cualquier otro enlace, TSDB eliminará todos los fragmentos necesarios de acuerdo con la condición de tiempo especificada.
Particionamiento TimescaleDB y PostgreSQL
A primera vista, puede parecer que TSDB es un buen envoltorio alrededor de la partición estándar de tablas PG (
partición declarativa , como se llama oficialmente en PG10). De hecho, para almacenar datos históricos, puede usar la partición estándar PG10. Pero si nos fijamos bien, los fragmentos de la sección TSDB y PG10 están lejos de ser conceptos idénticos.
Para comenzar, la configuración de la partición en PG requiere una comprensión más profunda de los detalles, lo que la aplicación misma o el DBMS deberían hacer de una buena manera. Primero, debe planificar su jerarquía de secciones y decidir si usar particiones anidadas. En segundo lugar, debe crear un esquema de nomenclatura de sección y, de alguna manera, transferirlo a los scripts para crear el esquema. Lo más probable es que el esquema de nomenclatura incluya la fecha y / o la hora, y dichos nombres deberán automatizarse de alguna manera.
A continuación, debe pensar en cómo eliminar los datos caducados. En TSDB, simplemente puede llamar al comando drop_chunks (), que determina los fragmentos que se eliminarán durante un período de tiempo determinado. En PG10, si necesita eliminar un cierto rango de valores de las secciones PG estándar, tendrá que calcular la lista de nombres de sección para este rango usted mismo. Si el esquema de partición seleccionado involucra secciones anidadas, esto complica aún más la eliminación.
Otro problema que debe abordarse es qué hacer con los datos que van más allá de los rangos de tiempo actuales. Por ejemplo, los datos pueden provenir de un futuro para el que aún no se han creado secciones. O del pasado para secciones ya eliminadas. Por defecto en PG10, agregar un registro de este tipo no funcionará y simplemente perderemos los datos. En PG11, puede definir una sección predeterminada para dichos datos, pero esto solo enmascara temporalmente el problema y no lo resuelve.
Por supuesto, todos los problemas anteriores se pueden resolver de una forma u otra. Puedes colgar la base con disparadores, cron-jabs y rociar generosamente con scripts. Será feo, pero funcional. No hay duda de que las secciones de PG son mejores que las tablas monolíticas gigantes, pero lo que definitivamente no se resuelve a través de scripts y desencadenantes son las mejoras de series temporales que PG no tiene.
Es decir En comparación con las secciones PG, las hipertables TSDB se distinguen favorablemente no solo por salvar los nervios de los administradores de bases de datos, sino también por optimizar tanto el acceso a los datos como agregar nuevos. Por ejemplo, los fragmentos en TSDB son siempre una matriz unidimensional. Esto simplifica la gestión de fragmentos y acelera las inserciones y selecciones. Para agregar nuevos datos, TSDB usa su propio algoritmo de enrutamiento en el fragmento deseado, que, a diferencia del PG estándar, no abre de inmediato todas las secciones. Con una gran cantidad de secciones, la diferencia en el rendimiento puede variar significativamente. Los detalles técnicos sobre la diferencia entre la partición estándar en PG y TSDB se pueden encontrar en
este artículo .
Zabbix y TimescaleDB
De todas las opciones, TimescaleDB parece ser la opción más segura para Zabbix y sus usuarios:
- TSDB está diseñado como una extensión PostgreSQL, y no como un sistema independiente. Por lo tanto, no requiere hardware adicional, máquinas virtuales ni ningún otro cambio en la infraestructura. Los usuarios pueden continuar usando sus herramientas elegidas para PostgreSQL.
- TSDB le permite guardar casi todo el código para trabajar con la base de datos en Zabbix sin cambios.
- TSDB mejora significativamente el rendimiento del historiador y ama de llaves.
- Umbral de entrada bajo: los conceptos básicos de TSDB son simples y directos.
- La fácil instalación y configuración de la extensión en sí y de Zabbix será de gran ayuda para los usuarios de sistemas pequeños y medianos.
Veamos qué hay que hacer para iniciar TSDB con un Zabbix recién instalado. Después de instalar Zabbix y ejecutar los scripts de creación de bases de datos PostgreSQL, debe descargar e instalar TSDB en la plataforma deseada. Consulte las instrucciones de instalación
aquí . Después de instalar la extensión, debe habilitarla para la base de Zabbix y luego ejecutar el script timecaledb.sql que viene con Zabbix. Se encuentra en la base de datos / postgresql / timecaledb.sql si la instalación es desde el origen, o en /usr/share/zabbix/database/timecaledb.sql.gz si la instalación es desde paquetes. Eso es todo! Ahora puede iniciar el servidor Zabbix y funcionará con TSDB.
El script timescaledb.sql es trivial. Todo lo que hace es convertir las tablas históricas normales de Zabbix en hipertables TSDB y cambiar la configuración predeterminada: establece los parámetros Anular período de historial de elementos y Anular período de tendencia de elementos. Ahora (versión 4.2) las siguientes tablas de Zabbix funcionan bajo el control de TSDB: history, history_uint, history_str, history_log, history_text, trends y trends_uint. Se puede utilizar el mismo script para migrar estas tablas (tenga en cuenta que el parámetro migrate_data está establecido en verdadero). Debe tenerse en cuenta que la migración de datos es un proceso muy largo y puede llevar varias horas.
El parámetro chunk_time_interval => 86400 también puede requerir cambios antes de ejecutar timecaledb.sql. Chunk_time_interval es el intervalo que limita el tiempo de los valores que caen en este fragmento. Por ejemplo, si establece el intervalo chunk_time_interval en 3 horas, los datos para todo el día se distribuirán en 8 fragmentos, con el primer fragmento No. 1 cubriendo las primeras 3 horas (0: 00-2: 59), el segundo fragmento No. 2 - las segundas 3 horas ( 3: 00-5: 59), etc. El último fragmento No. 8 contendrá valores con un tiempo de 21: 00-23: 59. 86400 segundos (1 día) es el valor predeterminado promedio, pero los usuarios de sistemas cargados pueden querer reducirlo.
Para estimar aproximadamente los requisitos de memoria, es importante comprender cuánto espacio puede ocupar una pieza en promedio. El principio general es que el sistema debe tener suficiente memoria para organizar al menos un fragmento de cada hipertable. En este caso, por supuesto, la suma de los tamaños de los fragmentos no solo debe caber en la memoria con un margen, sino que también debe ser menor que el valor del parámetro shared_buffers de postgresql.conf. Puede encontrar más información sobre este tema en la documentación de TimescaleDB.
Por ejemplo, si tiene un sistema que recopila principalmente métricas enteras y decide dividir la tabla history_uint en fragmentos de 2 horas y dividir el resto de las tablas en fragmentos de un día, entonces necesita cambiar esta fila en timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
Después de que se haya acumulado una cierta cantidad de datos históricos, puede verificar los tamaños de fragmento para la tabla history_uint llamando a chunk_relation_size ():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
Esta llamada se puede repetir para encontrar los tamaños de fragmento para todas las hipertables. Si, por ejemplo, se descubrió que el tamaño del fragmento de history_uint es de 13 MB, los fragmentos para otras tablas de historial, digamos 20 MB y para las tablas de tendencias de 10 MB, entonces el requisito de memoria total es 13 + 4 x 20 + 2 x 10 = 113 MB. También debemos dejar espacio desde shared_buffers para almacenar otros datos, digamos 20%. Luego, el valor de shared_buffers debe establecerse en 113MB / 0.8 = ~ 140MB.
Para un ajuste más fino de TSDB, recientemente apareció la utilidad timecaledb-tune. Analiza postgresql.conf, lo correlaciona con la configuración del sistema (memoria y procesador), y luego da recomendaciones sobre la configuración de parámetros de memoria, parámetros para procesamiento paralelo, WAL. La utilidad cambia el archivo postgresql.conf, pero puede ejecutarlo con el parámetro -dry-run y verificar los cambios propuestos.
Nos detendremos en los parámetros de Zabbix. Anular período de historial de artículo y Período de tendencia de artículo de anulación (disponible en Administración -> General -> Mantenimiento). Se necesitan para eliminar datos históricos como fragmentos enteros de hipertables TSDB, no registros.
El hecho es que Zabbix le permite establecer el período de limpieza para cada elemento de datos (métrica) individualmente. Sin embargo, esta flexibilidad se logra escaneando la lista de elementos y calculando períodos individuales en cada iteración de la limpieza. Si el sistema tiene períodos de limpieza individuales para elementos individuales, entonces el sistema obviamente no puede tener un único punto de corte para todas las métricas juntas y Zabbix no podrá dar el comando correcto para eliminar los fragmentos necesarios. Por lo tanto, al desactivar el historial de anulación para las métricas, Zabbix perderá la capacidad de eliminar el historial rápidamente llamando al procedimiento drop_chunks () para las tablas history_ * y, en consecuencia, al desactivar las tendencias de anulación se perderá la misma función para las tablas de tendencias_ *.
En otras palabras, para aprovechar al máximo el nuevo sistema de limpieza, debe hacer que ambas opciones sean globales. En este caso, el proceso de limpieza no leerá la configuración de los elementos de datos.
Rendimiento con TimescaleDB
Es hora de verificar si todo lo anterior realmente funciona en la práctica. Nuestro banco de pruebas es Zabbix 4.2rc1 con PostgreSQL 10.7 y TimescaleDB 1.2.1 para Debian 9. La máquina de prueba es un Intel Xeon de 10 núcleos con 16 GB de RAM y 60 GB de espacio de almacenamiento en el SSD. Según los estándares actuales, esta es una configuración muy modesta, pero nuestro objetivo es descubrir qué tan efectiva es la TSDB en la vida real. En configuraciones con un presupuesto ilimitado, simplemente puede insertar 128-256 GB de RAM y colocar la mayoría (si no toda) de la base de datos en la memoria.
Nuestra configuración de prueba consta de 32 agentes Zabbix activos que transfieren datos directamente al servidor Zabbix. Cada agente sirve 10,000 artículos. El caché histórico de Zabbix está configurado en 256 MB, y shared_buffers PG está configurado en 2 GB. Esta configuración proporciona una carga suficiente en la base de datos, pero al mismo tiempo no crea una carga grande en los procesos del servidor Zabbix. Para reducir el número de partes móviles entre las fuentes de datos y la base de datos, no utilizamos el Proxy Zabbix.
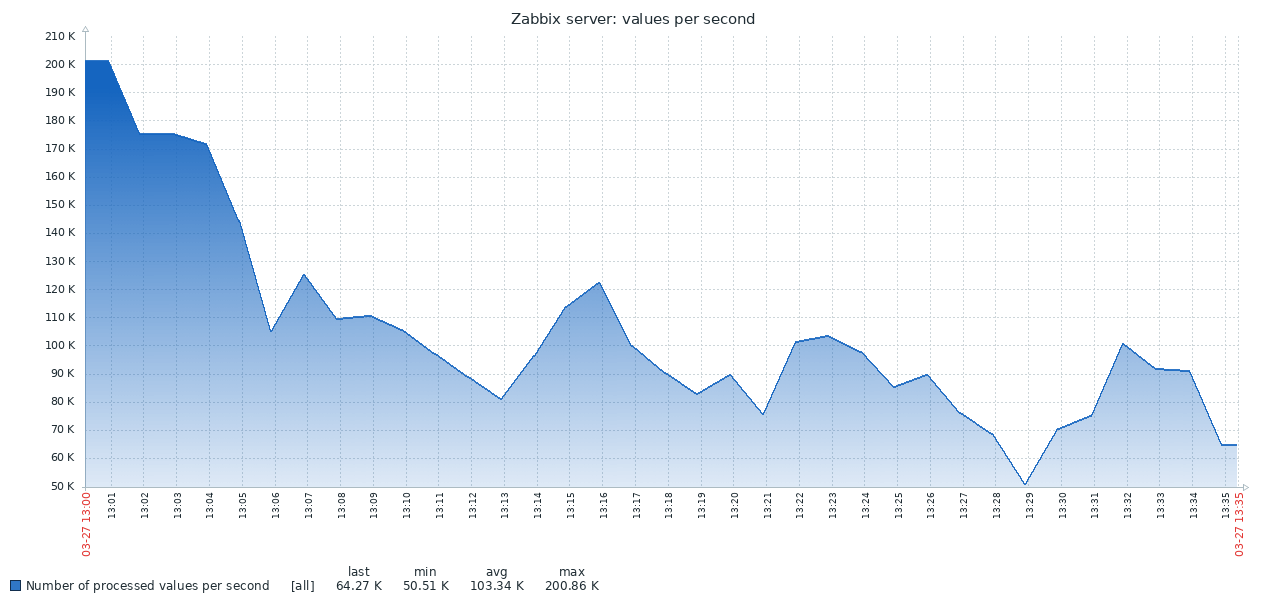
Aquí está el primer resultado obtenido del sistema PG estándar:
El resultado de TSDB es completamente diferente:

El siguiente gráfico combina ambos resultados. El trabajo comienza con valores NVPS bastante altos en 170-200K, porque Lleva algún tiempo llenar el caché del historial antes de que comience la sincronización con la base de datos.
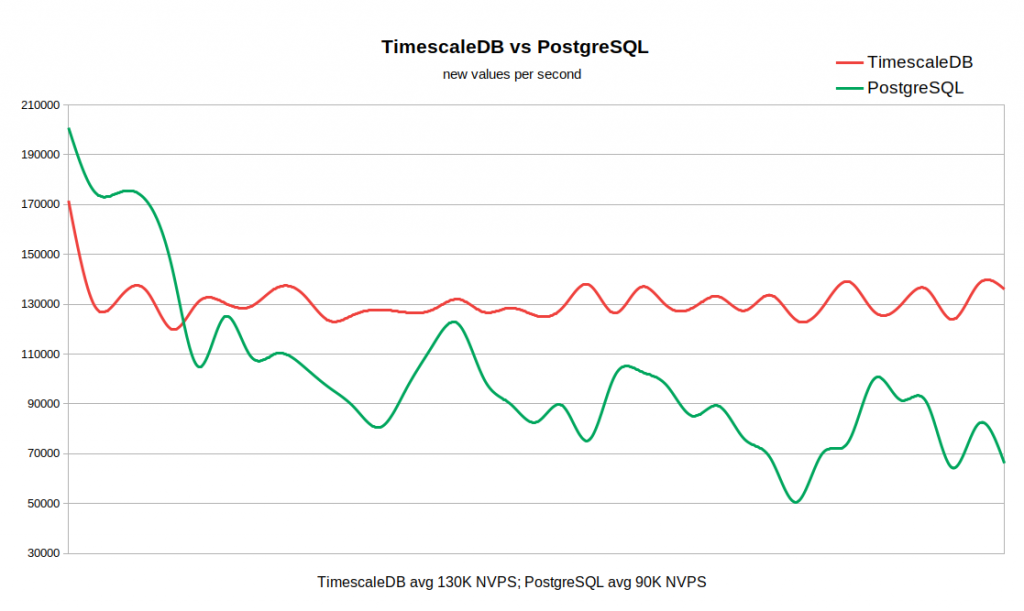
Cuando la tabla de historial está vacía, la velocidad de escritura en TSDB es comparable a la velocidad de escritura en PG, e incluso con un pequeño margen de este último. Tan pronto como el número de registros en la historia alcanza 50-60 millones, el rendimiento de PG cae a 110K NVPS, pero, lo que es más desagradable, continúa cambiando inversamente con el número de registros acumulados en la tabla histórica. Al mismo tiempo, TSDB mantiene una velocidad estable de 130K NVPS durante toda la prueba de 0 a 300 millones de registros.
En total, en nuestro ejemplo, la diferencia en el rendimiento promedio es bastante significativa (130K versus 90K sin tener en cuenta el pico inicial). También se ve que la tasa de inserción en PG estándar varía en un amplio rango. Por lo tanto, si un flujo de trabajo requiere almacenar decenas o cientos de millones de registros en la historia, pero no hay recursos para estrategias de almacenamiento en caché muy agresivas, entonces TSDB es un fuerte candidato para reemplazar el PG estándar.
La ventaja de TSDB ya es obvia para este sistema relativamente modesto, pero lo más probable es que la diferencia sea aún más notable en grandes conjuntos de datos históricos. Por otro lado, esta prueba no es en modo alguno una generalización de todos los escenarios posibles de trabajar con Zabbix. Naturalmente, hay muchos factores que influyen en los resultados, como las configuraciones de hardware, la configuración del sistema operativo, la configuración del servidor Zabbix y la carga adicional de otros servicios que se ejecutan en segundo plano. Es decir, su kilometraje puede variar.
Conclusión
TimescaleDB es una tecnología muy prometedora. Ya ha sido operado con éxito en entornos de producción serios. TSDB funciona bien con Zabbix y ofrece ventajas significativas sobre la base de datos PostgreSQL estándar.
¿Tiene TSDB alguna falla o razón para posponer su uso? Desde un punto de vista técnico, no vemos ningún argumento en contra. Pero debe tenerse en cuenta que la tecnología aún es nueva, con un ciclo de lanzamiento inestable y una estrategia poco clara para el desarrollo de la funcionalidad. En particular, se lanzan nuevas versiones con cambios significativos cada mes o dos. Algunas funciones pueden eliminarse, como, por ejemplo, sucedió con fragmentación adaptativa. Por separado, como otro factor de incertidumbre, vale la pena mencionar la política de licencias. Es muy confuso ya que hay tres niveles de licencia. El kernel TSDB está hecho bajo la licencia Apache, algunas funciones se lanzan bajo su propia licencia Timescale, pero también hay una versión cerrada de Enterprise.
Si usa Zabbix con PostgreSQL, entonces no hay razón al menos para no probar TimescaleDB. Quizás esto te sorprenda gratamente :) Solo ten en cuenta que el soporte para TimescaleDB en Zabbix sigue siendo experimental, por un tiempo, mientras recopilamos reseñas de usuarios y ganamos experiencia.