Al usar nginx para equilibrar el tráfico HTTP en el nivel L7, es posible enviar una solicitud de cliente al siguiente servidor de aplicaciones si el destino no devuelve una respuesta positiva. Una prueba del mecanismo de verificación pasiva del estado de salud del servidor de aplicaciones mostró la ambigüedad de la documentación y la especificidad de los algoritmos para excluir al servidor del grupo de servidores de producción.
Resumen del equilibrio del tráfico HTTP
Hay varias formas de equilibrar el tráfico HTTP. Según los niveles del modelo OSI,
existen tecnologías de equilibrio en los niveles de red, transporte y aplicación.
Se pueden usar combinaciones dependiendo del tamaño de la aplicación.
La tecnología de equilibrio de tráfico produce efectos positivos en la aplicación y su mantenimiento. Estas son algunas de ellas. Escalado horizontal de la aplicación, en el que la
carga se distribuye entre varios nodos . Desmantelamiento planificado del servidor de aplicaciones eliminando el flujo de solicitudes del cliente. Implementación de la estrategia de prueba A / B para la funcionalidad modificada de la aplicación. Mejora de la tolerancia a fallas de la aplicación
enviando solicitudes a servidores de aplicaciones que funcionan bien .
La última función se implementa en dos modos. En modo pasivo, el equilibrador en el tráfico del cliente evalúa las respuestas del servidor de aplicaciones de destino y, bajo ciertas condiciones, lo excluye del grupo de servidores de producción. En modo activo, el equilibrador envía periódicamente solicitudes de forma independiente al servidor de aplicaciones en el URI especificado, y para ciertos signos de respuesta decide excluirlo del grupo de servidores de producción. Posteriormente, el equilibrador, bajo ciertas condiciones, devuelve el servidor de aplicaciones al grupo de servidores de producción.
Verificación pasiva del servidor de aplicaciones y su exclusión del grupo de servidores de producción.
Echemos un vistazo más de cerca a la verificación pasiva del servidor de aplicaciones en la edición gratuita de nginx / 1.17.0. Los servidores de aplicaciones son seleccionados a su vez por el algoritmo Round Robin, sus pesos son los mismos.
El diagrama de tres pasos muestra una sección de tiempo que comienza con el envío de una solicitud de cliente al servidor de aplicaciones No. 2. Un indicador brillante caracteriza las solicitudes / respuestas entre el cliente y el equilibrador. Indicador oscuro: solicitudes / respuestas entre nginx y servidores de aplicaciones.
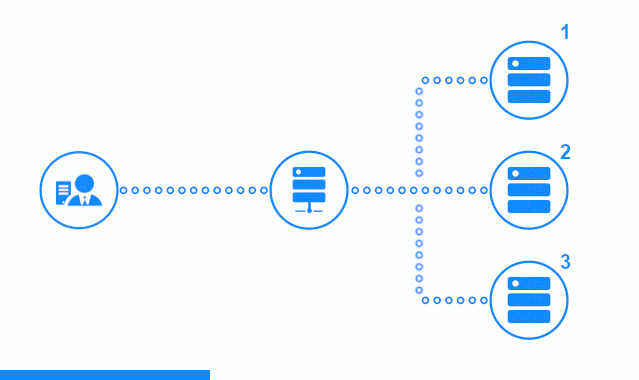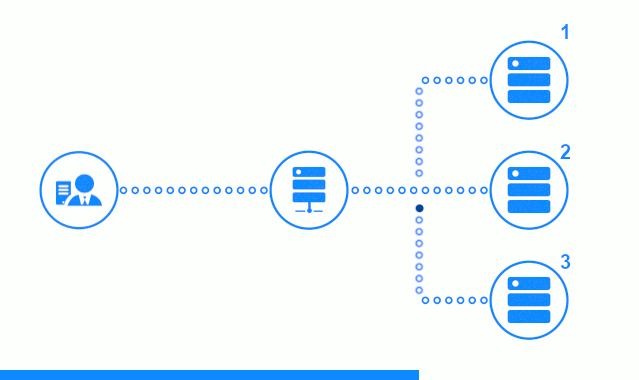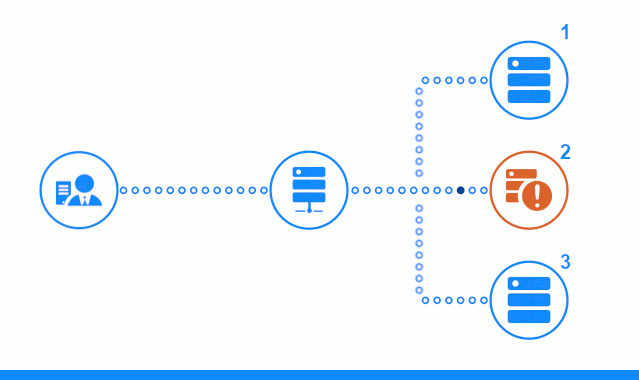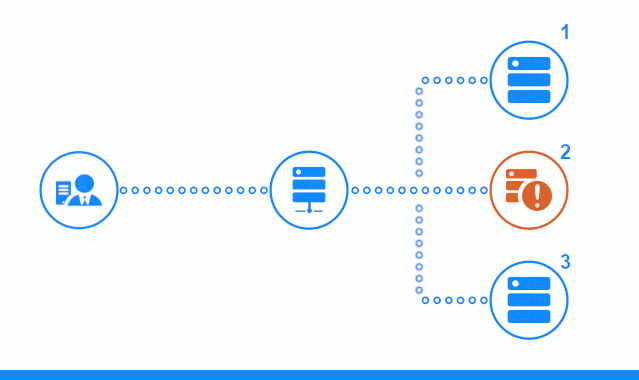
El tercer paso del diagrama muestra cómo el equilibrador redirige la solicitud del cliente al siguiente servidor de aplicaciones, en caso de que el servidor de destino haya dado una respuesta de error o no haya respondido en absoluto.
La lista de errores HTTP y TCP en los que el servidor usa el siguiente servidor se especifica en la directiva
proxy_next_upstream .
Por defecto, nginx redirige solo las
solicitudes con métodos HTTP idempotentes al siguiente servidor de aplicaciones.
¿Qué obtiene el cliente? Por un lado, la capacidad de redirigir una solicitud al siguiente servidor de aplicaciones aumenta las posibilidades de proporcionar una respuesta satisfactoria al cliente cuando falla el servidor de destino. Por otro lado, es obvio que una llamada secuencial primero al servidor de destino y luego al siguiente aumenta el tiempo de respuesta total al cliente.
Al final,
la respuesta del servidor de aplicaciones se devuelve al cliente
, donde termina el contador de intentos permitidos proxy_next_upstream_tries .
Al usar la función de redireccionamiento al siguiente servidor de trabajo, debe armonizar adicionalmente los tiempos de espera en el equilibrador y los servidores de aplicaciones. El límite superior del tiempo para una solicitud de "viaje" entre los servidores de aplicaciones y el equilibrador es el tiempo de espera del cliente o el tiempo de espera especificado por la empresa. Al calcular los tiempos de espera, también es necesario tener en cuenta el margen para eventos de red (retrasos / pérdidas durante la entrega de paquetes). Si el cliente finaliza cada vez la sesión por tiempo de espera mientras el equilibrador obtiene una respuesta garantizada, la buena intención de hacer que la aplicación sea confiable será inútil.

La verificación pasiva del estado de los servidores de aplicaciones está controlada por directivas, por ejemplo, con las siguientes opciones para sus valores:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
A partir del 2 de julio de
2019 , la documentación
estableció que el parámetro
max_fails establece el número de intentos fallidos de trabajar con el servidor que deberían ocurrir dentro del tiempo especificado por el parámetro
fail_timeout .
El parámetro
fail_timeout establece el tiempo durante el cual el número especificado de intentos fallidos de trabajar con el servidor debe ocurrir para que el servidor se considere no disponible; y el tiempo durante el cual el servidor se considerará no disponible.
En el ejemplo dado, parte del archivo de configuración, el equilibrador está configurado para capturar 5 llamadas fallidas en 100 segundos.
Devolver el servidor de aplicaciones al grupo de servidores de producción
Como se deduce de la documentación, el equilibrador después de
fail_timeout no puede considerar que el servidor no esté operativo. Pero, desafortunadamente, la documentación no establece explícitamente cómo se evalúa el rendimiento del servidor.
Sin un experimento, uno solo puede suponer que el mecanismo para verificar el estado es similar al descrito anteriormente.
Expectativas y realidad
En la configuración presentada, se espera el siguiente comportamiento del equilibrador:
- Hasta que el equilibrador excluya el servidor de aplicaciones n. ° 2 del grupo de servidores de producción, se le enviarán solicitudes de clientes.
- Las solicitudes devueltas con un error 500 del servidor de aplicaciones n. ° 2 se enviarán al siguiente servidor de aplicaciones y el cliente recibirá respuestas positivas.
- Tan pronto como el equilibrador reciba 5 respuestas con el código 500 en 100 segundos, excluirá el servidor de aplicaciones No. 2 del grupo de servidores de producción. Todas las solicitudes después de una ventana de 100 segundos se enviarán inmediatamente a los servidores de aplicaciones de trabajo restantes sin tiempo adicional.
- Después de 100 segundos, de alguna manera, el equilibrador debe evaluar el rendimiento del servidor de aplicaciones y devolverlo al grupo de servidores de producción.
Después de realizar pruebas en especie, según las revistas del equilibrador, se estableció que la declaración No. 3 no funciona. El equilibrador excluye un servidor inactivo tan pronto como se
cumpla la condición en el parámetro
max_fails . Por lo tanto, un servidor fallido se excluye del servicio sin esperar el lapso de 100 segundos. El parámetro
fail_timeout juega el papel de solo el límite superior del tiempo de acumulación de errores.
Como parte de la afirmación No. 4, resulta que nginx verifica la funcionalidad de una aplicación que anteriormente estaba excluida del mantenimiento del servidor con solo una solicitud. Y si el servidor aún responde con un error, la siguiente comprobación
fallará después de
fail_timeout .
Lo que falta
- Es posible que el algoritmo implementado en nginx / 1.17.0 no sea la forma más justa de verificar el rendimiento del servidor antes de devolverlo al grupo de servidores en funcionamiento. Al menos, de acuerdo con la documentación actual, no se espera 1 solicitud, sino la cantidad especificada en max_fails .
- El algoritmo de verificación de estado no tiene en cuenta la velocidad de las solicitudes. Cuanto más grande es, más fuerte se desplaza el espectro con intentos fallidos hacia la izquierda, y el servidor de aplicaciones abandona el grupo de servidores de trabajo demasiado rápido. Supongo que esto puede afectar negativamente a las aplicaciones que se permiten producir errores "coágulos cortos de tiempo". Por ejemplo, al recoger basura.

Quería preguntarle si hay algún beneficio práctico del algoritmo de comprobación del estado del servidor, que mide la velocidad de los intentos fallidos.