En la
versión anterior, describí el marco de automatización de red. Según las revisiones de algunas personas, incluso este primer enfoque del problema ya ha planteado algunas preguntas en los estantes. Y esto me hace muy feliz, porque nuestro objetivo en el ciclo no es cubrir el ansible con scripts de Python, sino construir un sistema.
El mismo marco establece el orden en el que trataremos la cuestión.
Y la virtualización de la red, a la que está dedicado este problema, no encaja realmente en el tema ADSM, donde analizamos la automatización.
Pero veámoslo desde un ángulo diferente.
Durante mucho tiempo, muchos servicios utilizan una sola red. En el caso de un operador, estos son 2G, 3G, LTE, banda ancha y B2B, por ejemplo. En el caso de DC: conectividad para diferentes clientes, Internet, almacenamiento en bloque, almacenamiento de objetos.
Y todos los servicios requieren aislamiento unos de otros. Entonces aparecieron redes superpuestas.
Y todos los servicios no quieren esperar a que una persona los configure manualmente. Entonces aparecieron los orquestadores y SDN.
El primer enfoque para la automatización sistemática de la red, o más bien, partes de ella, se ha tomado durante mucho tiempo y se ha implementado en muchos lugares: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Aquí tratamos con él hoy.

Contenido
- Razones
- Terminología
- Underlay - Red física
- Superposición - red virtual
- Superposición con ToR
- Superposición del host
- Caso de estudio de tela de tungsteno
- Comunicación dentro de una máquina física
- Comunicación entre máquinas virtuales ubicadas en diferentes máquinas físicas
- Salir al mundo exterior
- FAQ
- Conclusión
- Enlaces utiles
Razones
Y dado que hablamos de esto, vale la pena mencionar los requisitos previos para la virtualización de la red. De hecho, este proceso no comenzó ayer.
Probablemente haya escuchado más de una vez que la red siempre ha sido la parte más inerte de cualquier sistema. Y esto es cierto en todos los sentidos. Una red es la base en la que se basa todo, y hacer cambios en ella es bastante difícil: los servicios no toleran cuando la red se encuentra. A menudo, el desmantelamiento de un solo nodo puede sumar la mayoría de las aplicaciones y afectar a muchos clientes. Esta es en parte la razón por la cual el equipo de la red puede resistir cualquier cambio, porque ahora de alguna manera funciona (
puede que ni siquiera sepamos cómo ), pero aquí necesitamos configurar algo nuevo, y no se sabe cómo afectará a la red.
Para no esperar a que los proveedores de red pasen VLAN y no registren ningún servicio en cada nodo de red, las personas decidieron usar superposiciones, redes superpuestas, de las cuales hay una gran variedad: GRE, IPinIP, MPLS, MPLS L2 / L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE, etc.
Su atractivo radica en dos cosas simples:
- Solo se configuran los nodos finales; no es necesario que toque los nodos de tránsito. Esto acelera significativamente el proceso y, a veces, incluso le permite excluir al departamento de infraestructura de red del proceso de introducción de nuevos servicios.
- La carga está oculta en el fondo de los encabezados: los nodos de tránsito no necesitan saber nada sobre el direccionamiento en los hosts, las rutas de la red impuesta. Y esto significa que necesita almacenar menos información en las tablas, así que tome un dispositivo más simple / más barato.
En este tema no tan completo, no planeo analizar todas las tecnologías posibles, sino describir el marco para la operación de redes superpuestas en DC.
La serie completa describirá un centro de datos, que consta de filas de bastidores similares en los que está instalado el mismo equipo de servidor.
Este equipo ejecuta máquinas virtuales / contenedores / sin servidor que implementan servicios.

Terminología
En el ciclo, llamaré al
servidor un programa que implementa el lado del servidor de comunicación cliente-servidor.
Las máquinas físicas en bastidores
no se llamarán servidores.
La máquina física es una computadora montada en rack x86. Muy a menudo usamos el término
host . Entonces lo llamaremos "
máquina " o
host .
Un hipervisor es una aplicación que se ejecuta en una máquina física que emula los recursos físicos en los que se ejecutan las máquinas virtuales. A veces, en la literatura y en la red, la palabra "hipervisor" se usa como sinónimo de "host".
Una máquina virtual es un sistema operativo que se ejecuta en una máquina física encima de un hipervisor. Para nosotros, en el marco de este ciclo, no es tan importante si es realmente una máquina virtual o simplemente un contenedor. Lo llamaremos "
VM "
Inquilino es un concepto amplio que definiré en este artículo como un servicio separado o un cliente separado.
Multicliente o multicliente: el uso de la misma aplicación por diferentes clientes / servicios. Al mismo tiempo, el aislamiento de los clientes entre sí se logra debido a la arquitectura de la aplicación y no a instancias que se ejecutan por separado.
ToR - Interruptor superior del bastidor : un interruptor montado en bastidor al que están conectadas todas las máquinas físicas.
Además de la topología de ToR, diferentes proveedores practican End of Row (EoR) o Middle of Row (aunque esta última es una rareza despectiva y no he visto las abreviaturas MoR).
Red subyacente o
red subyacente o subyacente: infraestructura de red física: conmutadores, enrutadores, cables.
Red superpuesta o
red superpuesta o superpuesta: una red virtual de túneles que se ejecuta sobre una física.
L3-factory o IP-factory es una tremenda invención de la humanidad, que permite que las entrevistas no repitan STP y no aprendan TRILL. Un concepto en el que toda la red hasta el nivel de acceso es exclusivamente L3, sin VLAN y, en consecuencia, grandes dominios de difusión extendidos. ¿De dónde viene la palabra "fábrica" en la siguiente parte?
SDN - Red definida por software. Apenas necesita una introducción. Un enfoque para la administración de la red cuando los cambios en la red no los realiza una persona, sino un programa. Por lo general, significa mover el plano de control más allá de los dispositivos de red finales al controlador.
NFV : virtualización de funciones de red: virtualización de dispositivos de red, que supone que parte de las funciones de red se pueden lanzar en forma de máquinas virtuales o contenedores para acelerar la implementación de nuevos servicios, organizar el encadenamiento de servicios y una escalabilidad horizontal más fácil.
VNF - Función de red virtual. Dispositivo virtual específico: enrutador, conmutador, firewall, NAT, IPS / IDS, etc.
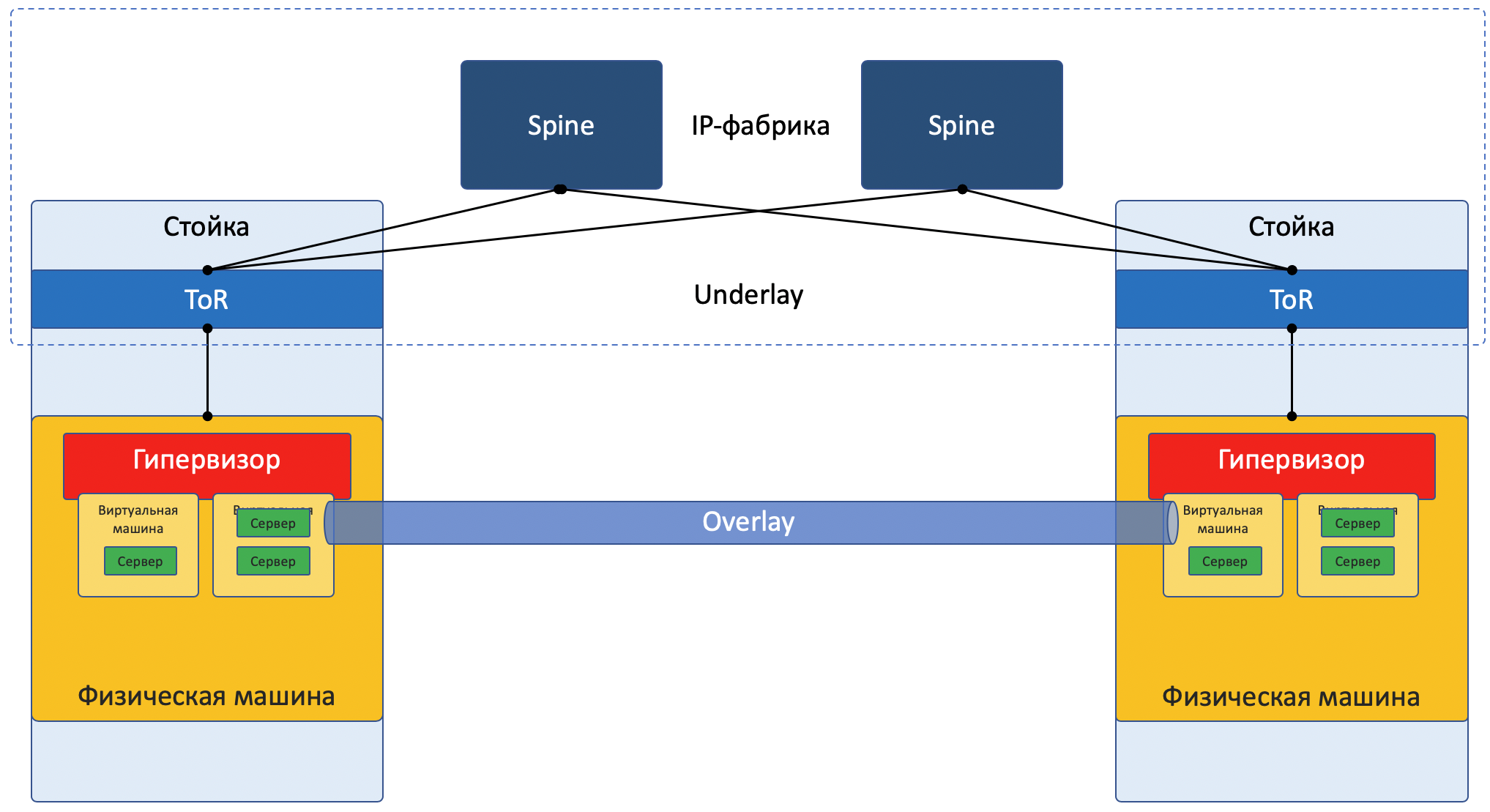
Ahora estoy simplificando deliberadamente la descripción a una implementación específica para no confundir demasiado al lector. Para una lectura más reflexiva, envíela a la sección Enlaces . Además, Roma Gorge, quien critica este artículo por inexactitudes, promete escribir un tema separado sobre las tecnologías de virtualización de servidores y redes, más profundo y más atento a los detalles.
La mayoría de las redes actuales se pueden dividir claramente en dos partes:
Underlay : una red física con una configuración estable.
Superposición : abstracción sobre la
superposición para aislar a los inquilinos.
Esto es cierto tanto para el caso de DC (que analizaremos en este artículo) como para ISP (que no analizaremos, porque ya estaba en
SDSM ). Con las redes empresariales, por supuesto, la situación es algo diferente.
Imagen de enfoque de red:

Underlay
Underlay es una red física: conmutadores y cables de hardware. Los dispositivos en el subsuelo saben cómo llegar a las máquinas físicas.
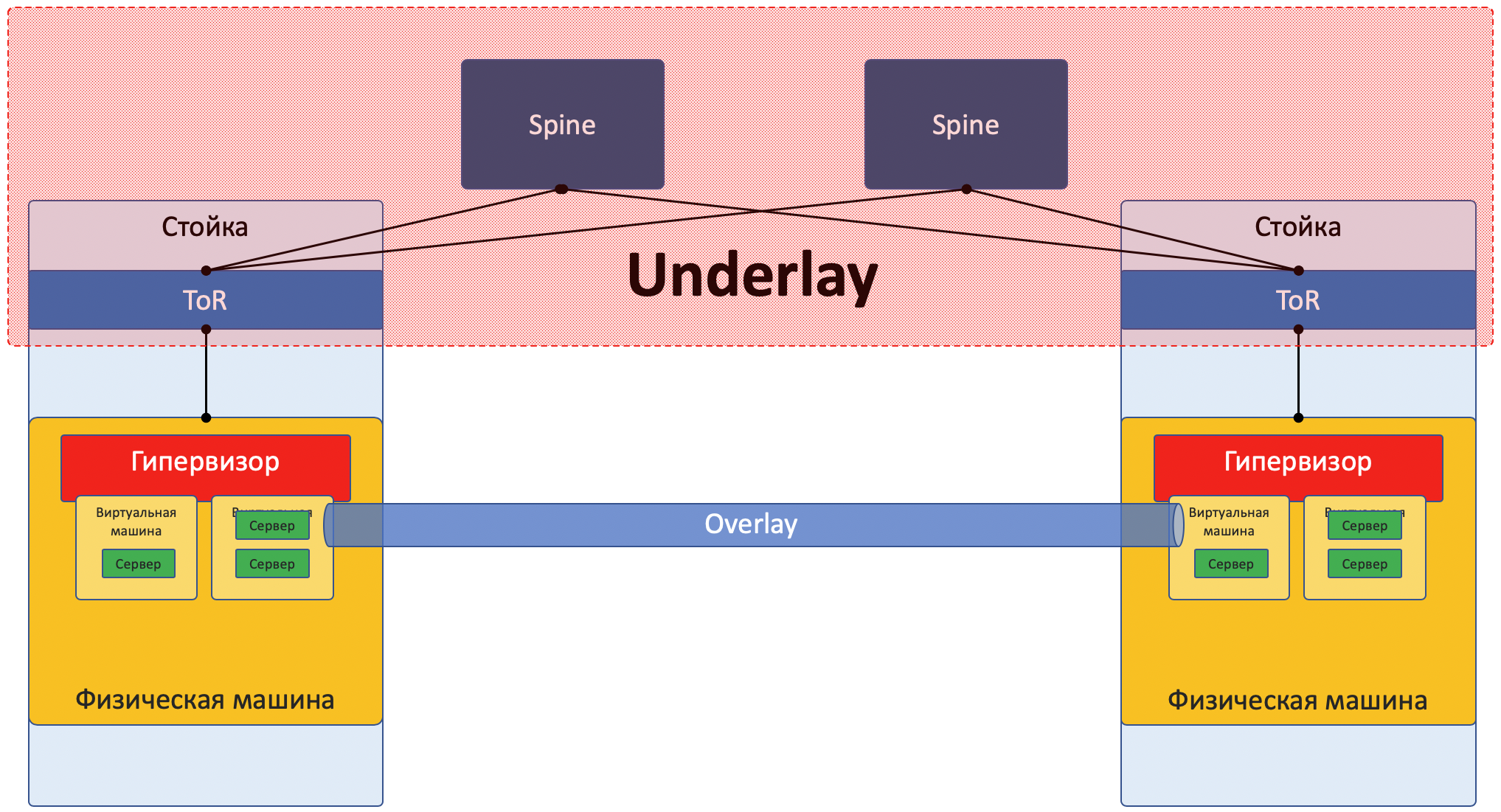
Se basa en protocolos y tecnologías estándar. No menos importante porque los dispositivos de hardware todavía funcionan en software propietario que no permite la programación de chips o la implementación de sus protocolos, respectivamente, se necesita compatibilidad con otros proveedores y estandarización.
Pero alguien como Google puede permitirse desarrollar sus propios interruptores y abandonar los protocolos generalmente aceptados. Pero LAN_DC no es Google.
La capa subyacente rara vez se cambia, porque su tarea es la conectividad IP básica entre máquinas físicas. Underlay no sabe nada sobre los servicios que se ejecutan sobre él, clientes, inquilinos, solo necesita entregar un paquete de una máquina a otra.
Underlay puede ser así:
- IPv4 + OSPF
- IPv6 + ISIS + BGP + L3VPN
- L2 + TRILL
- L2 + STP
La red subyacente se configura de la manera clásica: CLI / GUI / NETCONF.
Manualmente, scripts, utilidades propietarias.
Con más detalle, el próximo artículo de la serie estará dedicado a la base.
Superposición
Overlay: una red de túnel virtual extendida sobre Underlay, permite que las máquinas virtuales de un cliente se comuniquen entre sí, al tiempo que proporciona aislamiento de otros clientes.
Los datos del cliente se encapsulan en cualquier encabezado de túnel para su transmisión a través de una red compartida.

Por lo tanto, las máquinas virtuales de un cliente (un servicio) pueden comunicarse entre sí a través de Overlay, sin siquiera saber a qué se dirige el paquete.
La superposición puede ser, por ejemplo, la misma que mencioné anteriormente:
- Túnel GRE
- VXLAN
- EVPN
- L3VPN
- GENEVE
Una red superpuesta generalmente se configura y mantiene a través de un controlador central. Desde allí, la configuración, el plano de control y el plano de datos se entregan a los dispositivos que enrutan y encapsulan el tráfico del cliente.
A continuación analizaremos esto con ejemplos.
Sí, esto es SDN puro.Existen dos enfoques fundamentalmente diferentes para organizar una red Overlay:
- Superposición con ToR
- Superposición del host
Superposición con ToR
La superposición puede comenzar en un interruptor de acceso montado en bastidor (ToR), como es el caso, por ejemplo, en el caso de una fábrica de VXLAN.
Este es un mecanismo probado en el tiempo en las redes ISP y todos los proveedores de equipos de red lo admiten.
Sin embargo, en este caso, el conmutador ToR debe poder compartir diferentes servicios, respectivamente, y el administrador de la red debe cooperar en cierta medida con los administradores de las máquinas virtuales y realizar cambios (aunque automáticamente) en la configuración del dispositivo.
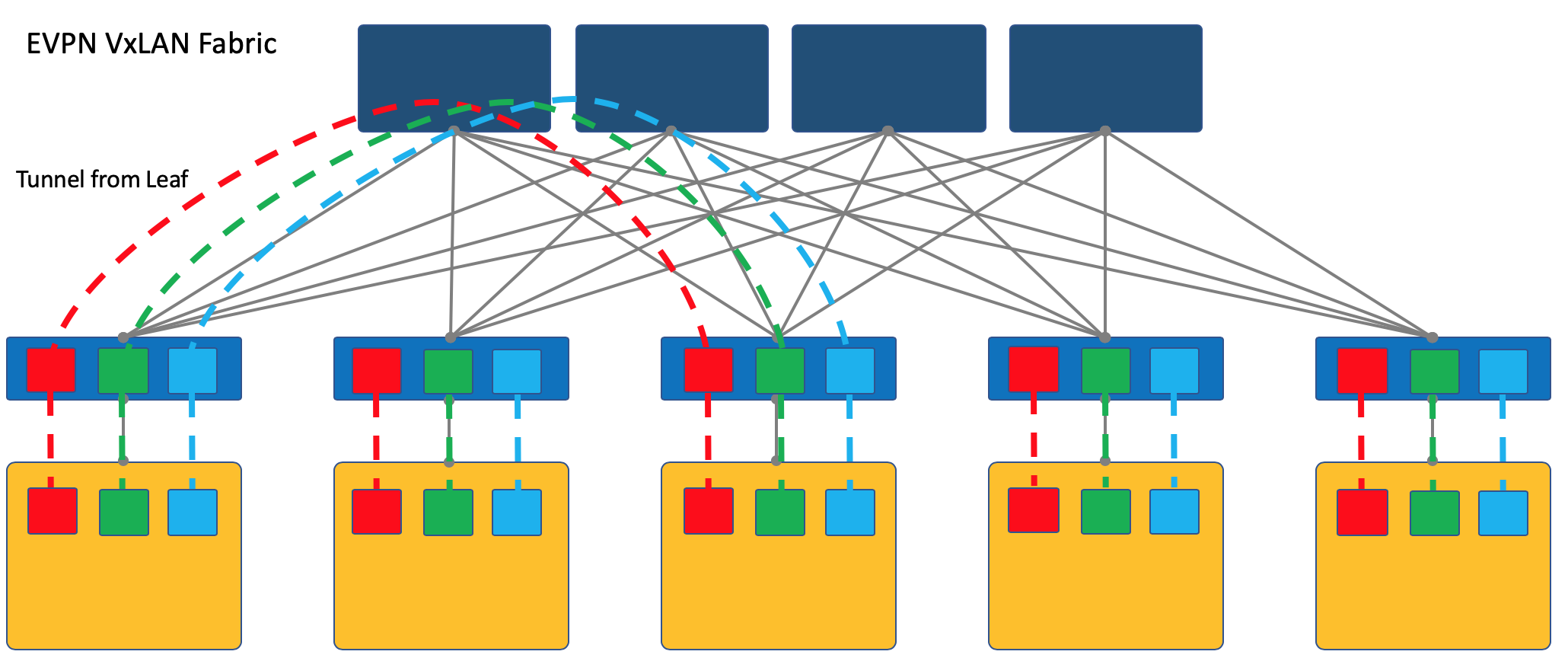
Aquí
remitiré al lector a un artículo sobre
VxLAN en el centro de nuestro viejo amigo
@bormoglotx .
En esta
presentación con ENOG , se describen en detalle los enfoques para la construcción de una red DC con una fábrica de EVPN VXLAN.
Y para una inmersión más completa en las realidades, puede leer el libro
Un tejido moderno, abierto y escalable: VXLAN EVPN .
Observo que VXLAN es solo un método de encapsulación y la terminación del túnel puede ocurrir no en ToR, sino en el host, como es el caso de OpenStack, por ejemplo.
Sin embargo, la fábrica de VXLAN donde comienza la superposición en ToR es uno de los diseños de red de superposición bien establecidos.
Superposición del host
Otro enfoque es iniciar y terminar túneles en los hosts finales.
En este caso, la red (Underlay) permanece tan simple y estática como sea posible.
Y el propio host hace toda la encapsulación necesaria.
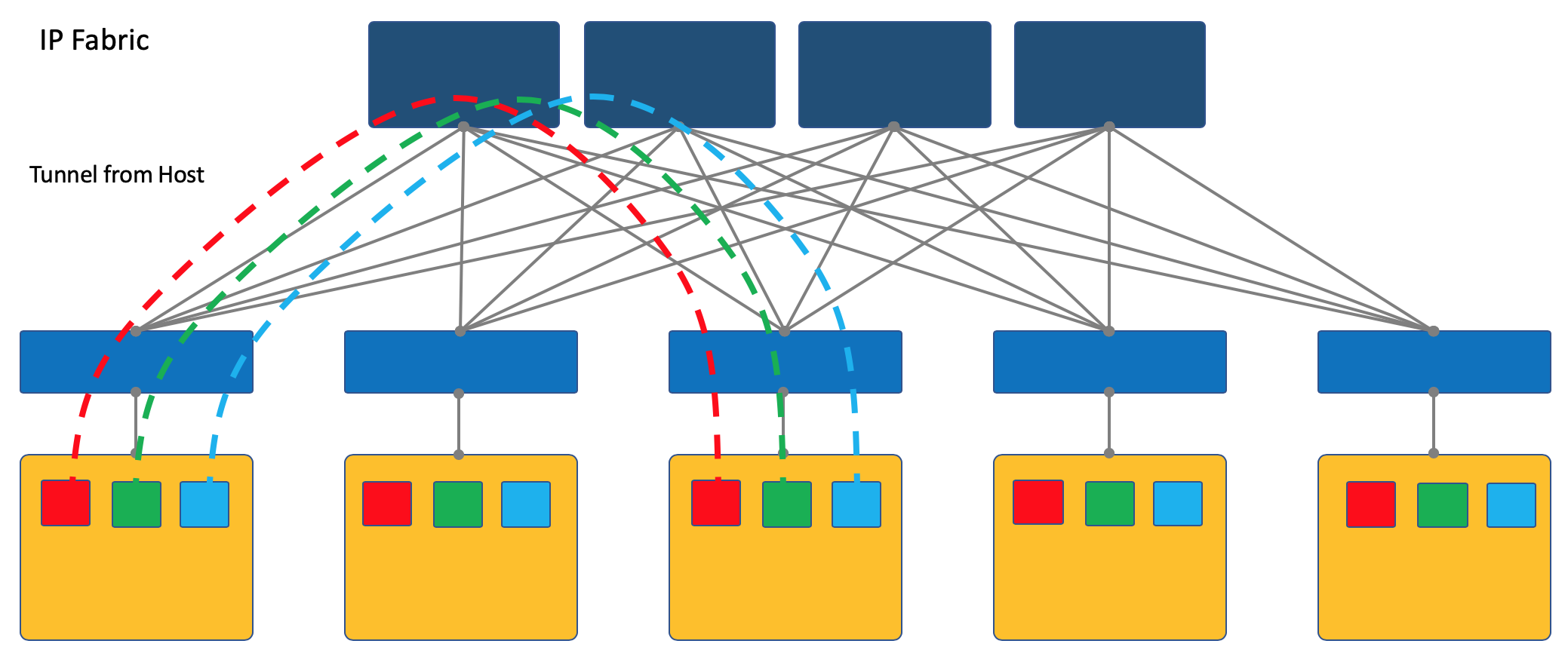
Para hacer esto, seguramente necesitará ejecutar una aplicación especial en los hosts, pero vale la pena.
En primer lugar, ejecutar un cliente en una máquina Linux es más simple o, digamos, generalmente posible, mientras está en el switch, lo más probable es que tenga que recurrir a soluciones SDN patentadas por el momento, lo que mata la idea de múltiples proveedores.
En segundo lugar, el interruptor ToR en este caso puede dejarse lo más simple posible, tanto desde el punto de vista del Plano de Control como del Plano de Datos. De hecho, entonces no necesita comunicarse con el controlador SDN y almacenar las redes / ARP de todos los clientes conectados, también, solo conozca la dirección IP de la máquina física, lo que simplifica enormemente las tablas de conmutación / enrutamiento.
En la serie ADSM, elijo el enfoque de superposición del host, luego solo hablamos de ello y no volveremos a la fábrica de VXLAN.
La forma más fácil de considerar los ejemplos. Y como sujeto de prueba, tomaremos la plataforma OpenSource SDN OpenContrail, ahora conocida como
Tungsten Fabric .
Al final del artículo, reflexionaré sobre la analogía con OpenFlow y OpenvSwitch.
Caso de estudio de tela de tungsteno
Cada máquina física tiene un
vRouter , un enrutador virtual que conoce las redes conectadas y a qué clientes pertenecen, de hecho, un enrutador PE. Para cada cliente, mantiene una tabla de enrutamiento aislada (lea VRF). Y en realidad, vRouter hace un túnel de superposición.
Un poco más sobre vRouter se encuentra al final del artículo.
Cada VM ubicada en el hipervisor está conectada al vRouter de esta máquina a través de la
interfaz TAP .
TAP - Terminal Access Point - una interfaz virtual en el kernel de Linux que permite la creación de redes.

Si hay varias redes detrás del vRouter, se crea una interfaz virtual para cada una de ellas, a la que se le asigna una dirección IP: será la dirección de puerta de enlace predeterminada.
Todas las redes de un cliente se colocan en un
VRF (una tabla), diferente, en diferente.
Haré una reserva aquí que no es tan simple, y enviaré al lector curioso al final del artículo .
Para que vRouter'y se comunique entre sí y, en consecuencia, las máquinas virtuales ubicadas detrás de ellas, intercambian información de enrutamiento a través de un
controlador SDN .
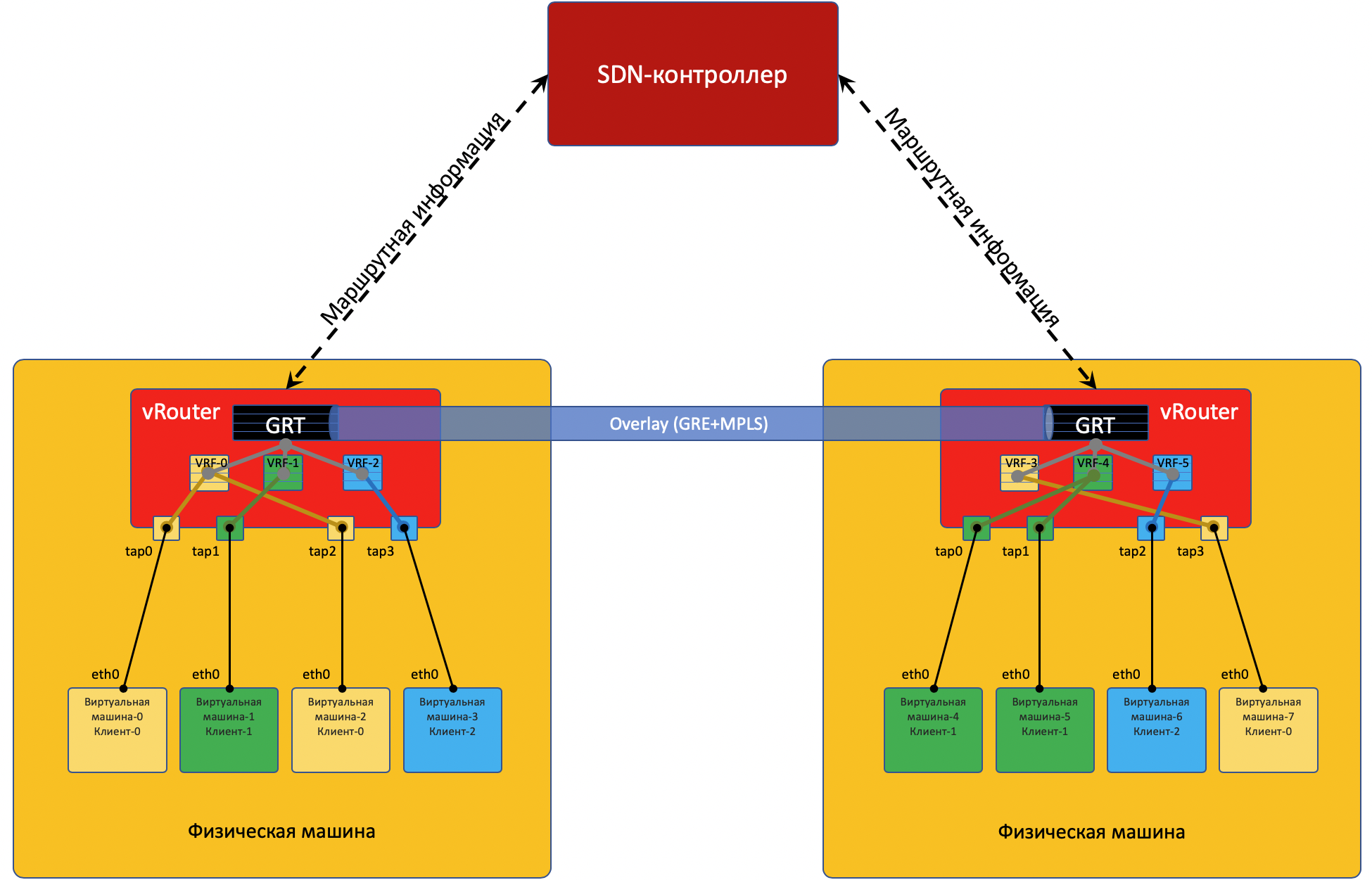
Para ingresar al mundo exterior, hay un punto de salida de la matriz: la puerta de enlace de red virtual
VNGW : Virtual Network GateWay (
mi término ).
Ahora considere los ejemplos de comunicaciones, y habrá claridad.
Comunicación dentro de una máquina física
VM0 quiere enviar un paquete a VM2. Supongamos por ahora que esta es una VM de cliente único.
Plano de datos
- VM-0 tiene una ruta predeterminada en su interfaz eth0. El paquete se envía allí.
Esta interfaz eth0 está realmente conectada virtualmente al enrutador virtual vRouter a través de la interfaz tap0 TAP. - vRouter analiza a qué interfaz llegó el paquete, es decir, a qué cliente (VRF) pertenece, verifica la dirección del destinatario con la tabla de enrutamiento de este cliente.
- Después de descubrir que el receptor en la misma máquina está detrás de un puerto diferente, vRouter simplemente le envía el paquete sin encabezados adicionales; en este caso, el vRouter ya tiene un registro ARP.
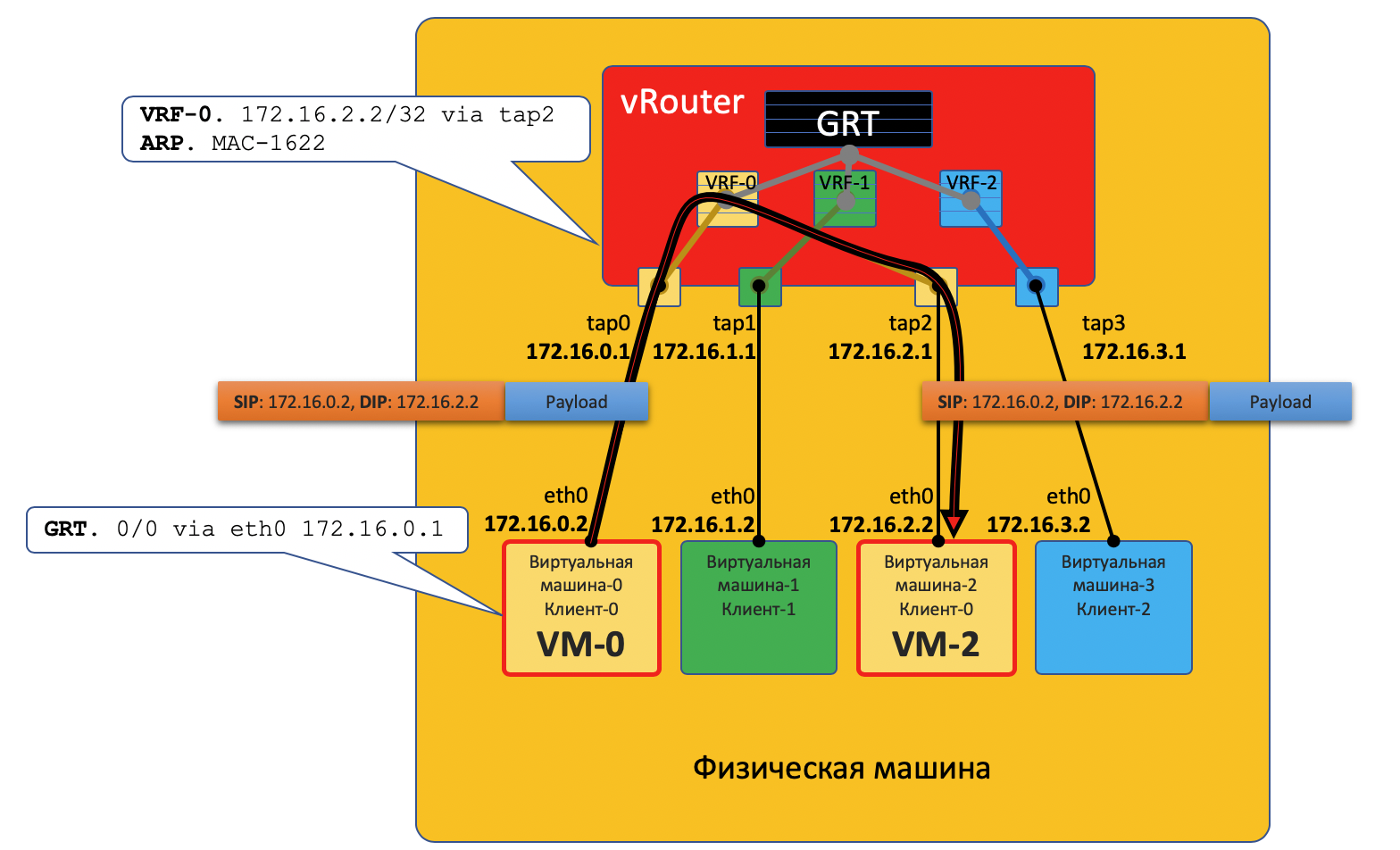
El paquete en este caso no ingresa a la red física, se enruta dentro de vRouter.
Plano de control
Cuando se inicia la máquina virtual, el hipervisor le dice:
- Su propia dirección IP.
- La ruta predeterminada es a través de la dirección IP del vRouter en esta red.
A través de una API especial, el hipervisor informa a vRouter:
- Lo que necesitas para crear una interfaz virtual.
- Cuál (VM) necesita crear una red virtual.
- A qué VRF vincularlo (VN).
- El registro ARP estático para esta VM es qué interfaz tiene su dirección IP y a qué dirección MAC está conectada.
Y nuevamente, el procedimiento de interacción real se simplifica para complacer el concepto.

Por lo tanto, todas las máquinas virtuales de un cliente en una máquina determinada, vRouter ve como redes conectadas directamente y puede enrutar entre ellas.
Pero VM0 y VM1 pertenecen a diferentes clientes, respectivamente, están en diferentes tablas vRouter'a.
El hecho de que puedan comunicarse entre sí depende directamente de la configuración de vRouter y del diseño de la red.
Por ejemplo, si las máquinas virtuales de ambos clientes usan direcciones públicas, o se produce NAT en el vRouter, entonces también se puede hacer un enrutamiento directo a vRouter.
En la situación opuesta, es posible cruzar espacios de direcciones (debe pasar por un servidor NAT para obtener una dirección pública), esto es similar al acceso a redes externas, que se describen a continuación.
Comunicación entre máquinas virtuales ubicadas en diferentes máquinas físicas
Plano de datos
- El comienzo es exactamente el mismo: VM-0 envía un paquete con el destino VM-7 (172.17.3.2) de forma predeterminada.
- vRouter lo recibe y esta vez ve que el destino está en otra máquina y es accesible a través del túnel Tunnel0.
- Primero, cuelga la etiqueta MPLS que identifica la interfaz remota, para que en la parte posterior de vRouter pueda determinar dónde colocar este paquete sin ganchos adicionales.

- Tunnel0 tiene una fuente de 10.0.0.2, el receptor: 10.0.1.2.
vRouter agrega encabezados GRE (o UDP) y una nueva IP al paquete original. - La tabla de enrutamiento vRouter tiene una ruta predeterminada a través de la dirección ToR1 10.0.0.1. Ahí y envía.
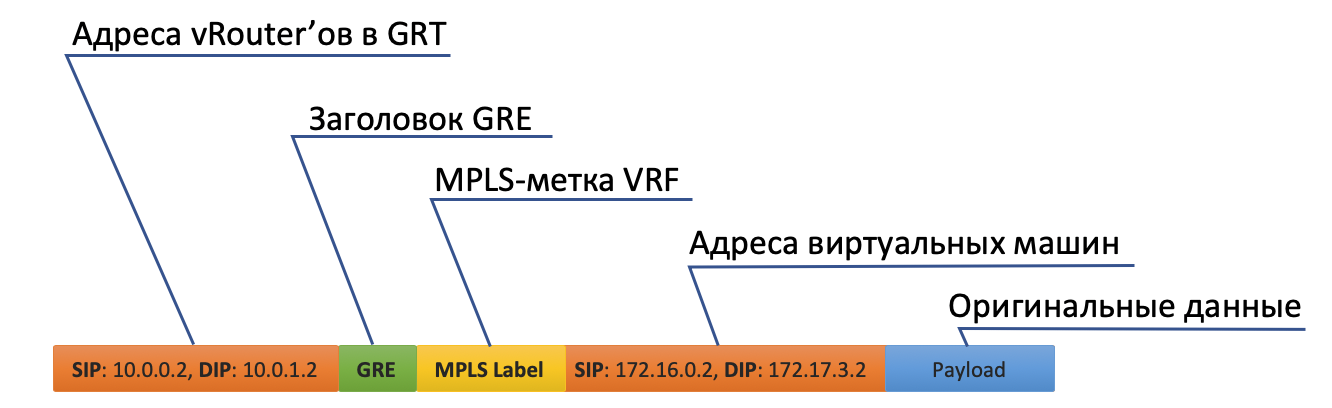
- ToR1 como miembro de la red Underlay sabe (por ejemplo, a través de OSPF) cómo llegar a 10.0.1.2 y envía un paquete a lo largo de la ruta. Tenga en cuenta que aquí se incluye ECMP. En la ilustración, hay dos nexsthops, y se mostrarán diferentes flujos por hash. En el caso de una fábrica real, probablemente habrá 4 nextops.
Al mismo tiempo, no necesita saber qué hay debajo del encabezado IP externo. Es decir, de hecho, bajo IP puede haber un emparedado de IPv6 sobre MPLS sobre Ethernet sobre MPLS sobre GRE sobre sobre griego. - En consecuencia, en el lado receptor, vRouter elimina GRE y, utilizando la etiqueta MPLS, comprende a qué interfaz se debe transmitir este paquete, lo despoja y lo envía al destinatario en su forma original.
Plano de control
Cuando enciende la máquina, todo lo que sucede se describe arriba.
Y más lo siguiente:
- Para cada cliente, vRouter asigna una etiqueta MPLS. Esta es la etiqueta de servicio L3VPN donde los clientes se dividirán en la misma máquina física.
De hecho, la etiqueta MPLS siempre es asignada por vRouter'om siempre, porque no se sabe de antemano que la máquina solo interactuará con otras máquinas detrás de la misma vRouter'om y esto probablemente no sea el caso.
- vRouter establece una conexión con el controlador SDN a través de BGP (o similar, en el caso de TF, esto es XMPP 0_o).
- A través de esta sesión, vRouter le dice al controlador SDN las rutas a las redes conectadas:
- Dirección de red
- Método de encapsulación (MPLSoGRE, MPLSoUDP, VXLAN)
- Etiqueta MPLS del cliente
- Tu dirección IP como nexthop
- El controlador SDN recibe tales rutas de todos los vRouter'ov conectados y los refleja a los demás. Es decir, él actúa como un reflector de ruta.
Lo mismo sucede en la dirección opuesta.

La superposición puede cambiar al menos cada minuto. Algo así ocurre en las nubes públicas, cuando los clientes inician y apagan sus máquinas virtuales con regularidad.
El controlador central asume todas las dificultades de mantener la configuración y controlar las tablas de conmutación / enrutamiento en vRouter.
En términos generales, el controlador se apaga con todos los vRouter a través de BGP (o un protocolo similar) y simplemente transmite información de enrutamiento. BGP, por ejemplo, ya tiene una familia de direcciones para transmitir el método de encapsulación
MPLS-in-GRE o
MPLS-in-UDP .
Al mismo tiempo, la configuración de la red Underlay no cambia de ninguna manera, lo que, por cierto, es mucho más difícil de automatizar y es más fácil romper con un movimiento incómodo.
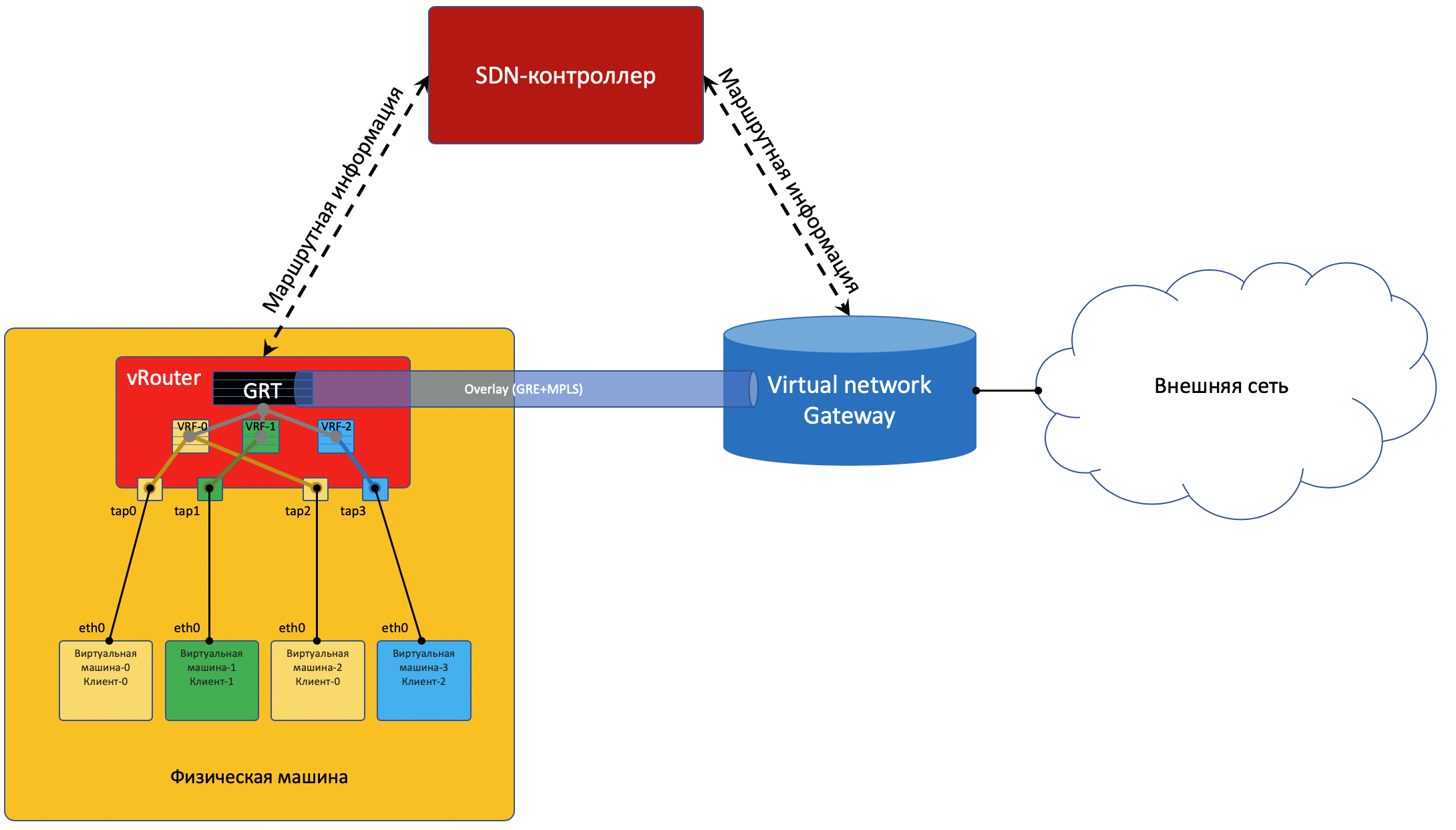
Salir al mundo exterior
En algún lugar, la simulación debería terminar, y desde el mundo virtual debes entrar en el mundo real. Y necesitas una pasarela de
teléfono público .
Se practican dos enfoques:
- Se instala un enrutador de hardware.
- Se lanza un dispositivo que implementa las funciones de un enrutador (sí, nos enfrentamos a VNF después de SDN). Llamémoslo una puerta de enlace virtual.
— — . , , , , , , , , , .
, , , , ( ). , - , , — .
Con un pie, la puerta de enlace mira hacia la red virtual Overlay, como una máquina virtual normal, y puede interactuar con todas las otras máquinas virtuales. Al mismo tiempo, puede terminar en sí mismo las redes de todos los clientes y, en consecuencia, realizar el enrutamiento entre ellos.Con el otro pie, la puerta de enlace ya está mirando la red troncal y sabe cómo llegar a Internet.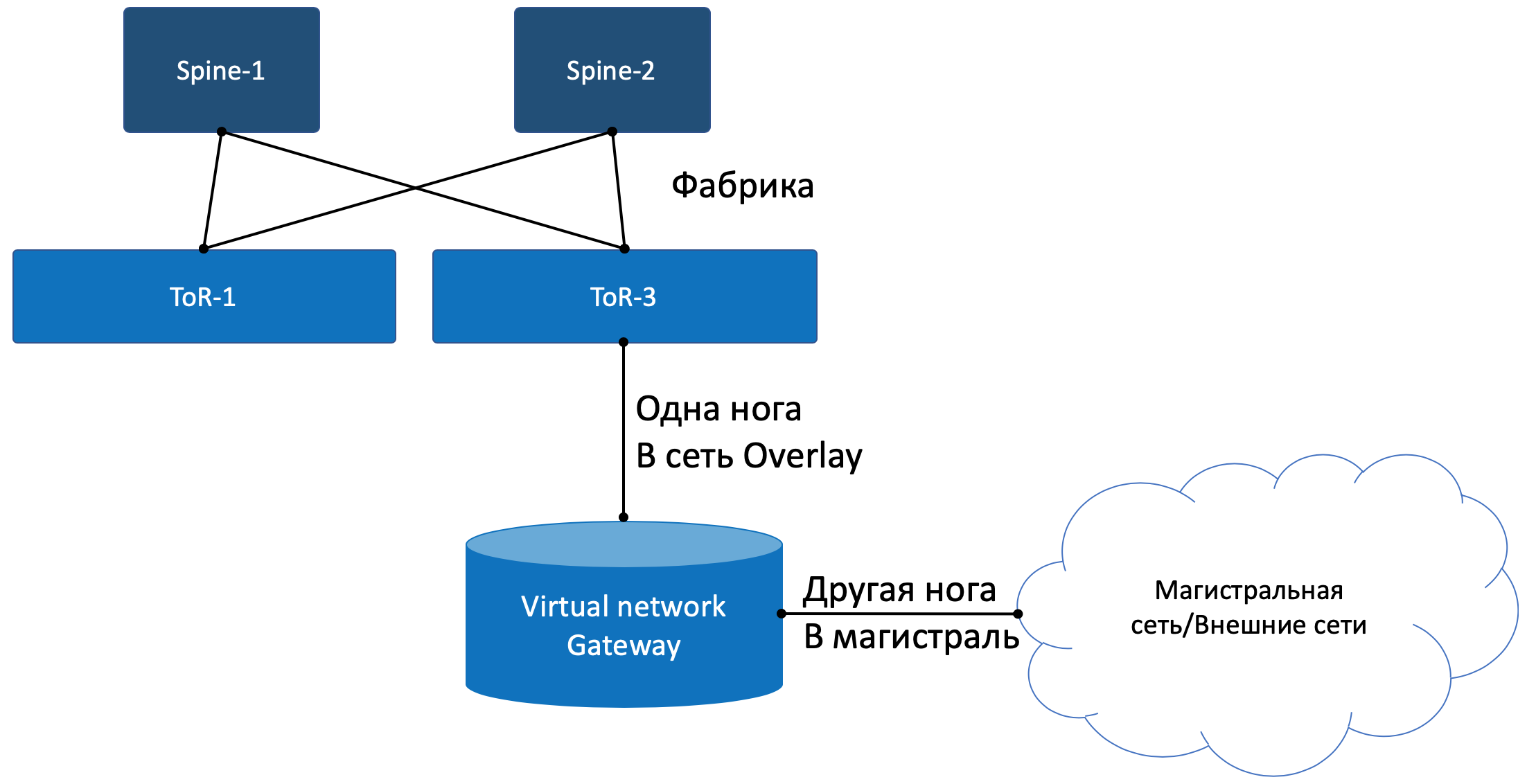
Plano de datos
Es decir, el proceso se ve así:- VM-0, que tiene todos los valores predeterminados en el mismo vRouter, envía un paquete con un destino en el mundo exterior (185.147.83.177) a la interfaz eth0.
- vRouter recibe este paquete y realiza una búsqueda de dirección de destino en la tabla de enrutamiento: encuentra la ruta predeterminada a través de la puerta de enlace VNGW1 a través del túnel 1.
También ve que este es un túnel GRE con SIP 10.0.0.2 y DIP 10.0.255.2, y aún necesita colgar MPLS primero La etiqueta de este cliente que VNGW1 espera.
- vRouter empaqueta el paquete original en MPLS, GRE y nuevos encabezados IP y lo envía a ToR1 10.0.0.1 de forma predeterminada.
- Una red subyacente entrega el paquete a la puerta de enlace VNGW1.
- La puerta de enlace VNGW1 elimina los encabezados de túnel GRE y MPLS, ve la dirección de destino, consulta su tabla de enrutamiento y entiende que está dirigida a Internet, esto significa a través de Vista completa o Predeterminado. Si es necesario, realiza la traducción NAT.
- Desde VNGW hasta la frontera, puede haber una red IP normal, lo cual es poco probable.
Puede ser una red MPLS clásica (IGP + LDP / RSVP TE), puede ser una fábrica con BGP LU o un túnel GRE desde VNGW hasta el borde a través de la red IP.
Sea como fuere, VNGW1 realiza las encapsulaciones necesarias y envía el paquete original hacia el borde.
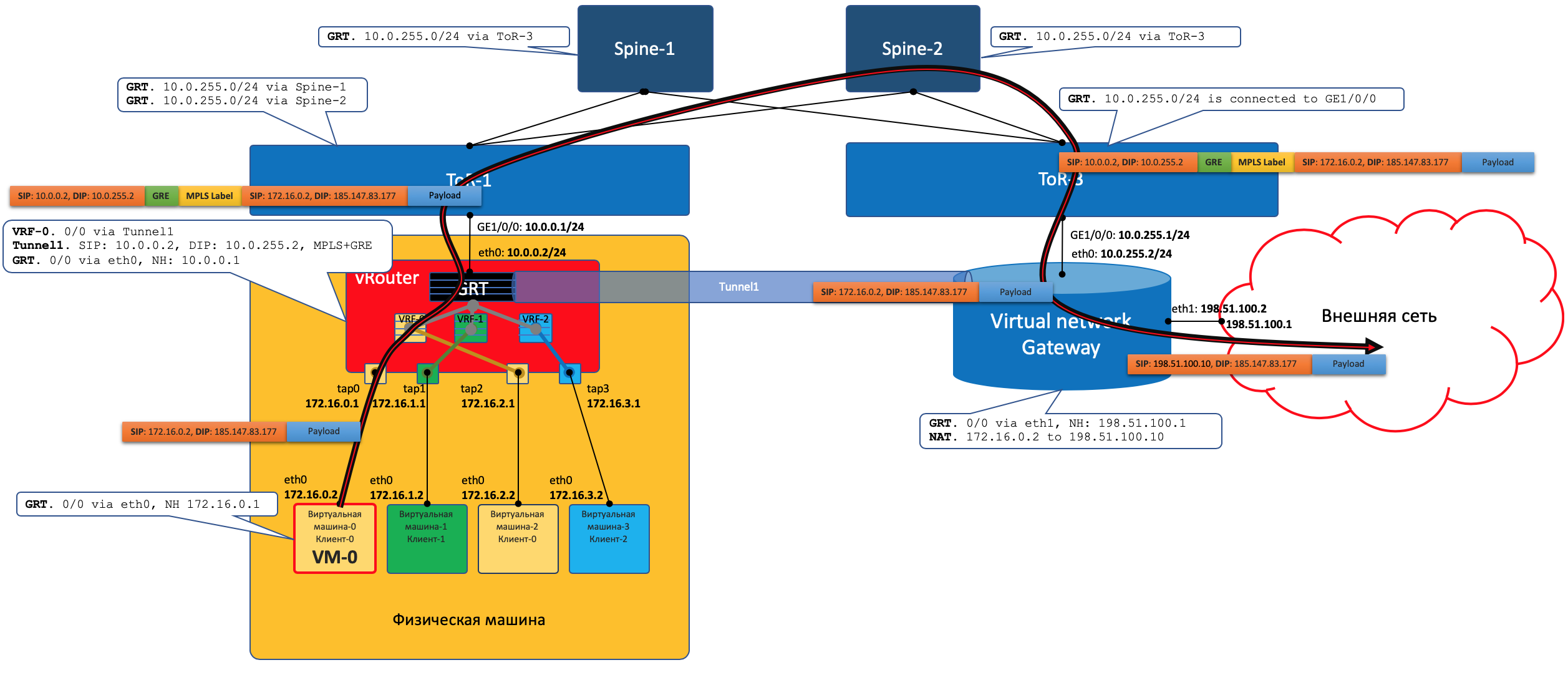 El tráfico en la dirección opuesta pasa por los mismos pasos en el orden opuesto.
El tráfico en la dirección opuesta pasa por los mismos pasos en el orden opuesto.- VNGW1
- , , Tunnel1 (MPLSoGRE MPLSoUDP).
- , MPLS, GRE/UDP IP ToR3 10.0.255.1.
— IP- vRouter', — 10.0.0.2. - vRouter'.
- vRouter GRE/UDP, MPLS- IP- TAP-, eth0 .

Control Plane
VNGW1 establece una vecindad BGP con el controlador SDN, desde el cual recibe toda la información de enrutamiento sobre los clientes: qué dirección IP (vRouter) se utiliza para identificar qué cliente y con qué etiqueta MPLS se identifica.Del mismo modo, él mismo le dice al controlador SDN la ruta predeterminada con la etiqueta de este cliente, indicándose a sí mismo como nexthop. Y luego este valor predeterminado llega a vRouter'y.Los VNGW suelen enrutar agregación o traducción NAT.Y en la dirección opuesta, da exactamente esta ruta agregada a una sesión con internos o Reflectores de ruta. Y de ellos recibe una ruta predeterminada o vista completa, o algo más.En términos de encapsulación e intercambio de tráfico, VNGW no es diferente de vRouter.Si expande un poco el área, puede agregar otros dispositivos de red a VNGW y vRouter, como firewalls, granjas de enriquecimiento o purificación de tráfico, IPS, etc.Y con la ayuda de la creación sucesiva de VRF y el anuncio correcto de rutas, puede hacer que el tráfico se repita como desee, lo que se denomina encadenamiento de servicios.Es decir, aquí el controlador SDN actúa como un reflector de ruta entre VNGW, vRouter'ami y otros dispositivos de red.Pero, de hecho, el controlador también publica información sobre ACL y PBR (enrutamiento basado en políticas), lo que obliga a los flujos de tráfico individuales a ir de manera diferente a lo que la ruta les indica.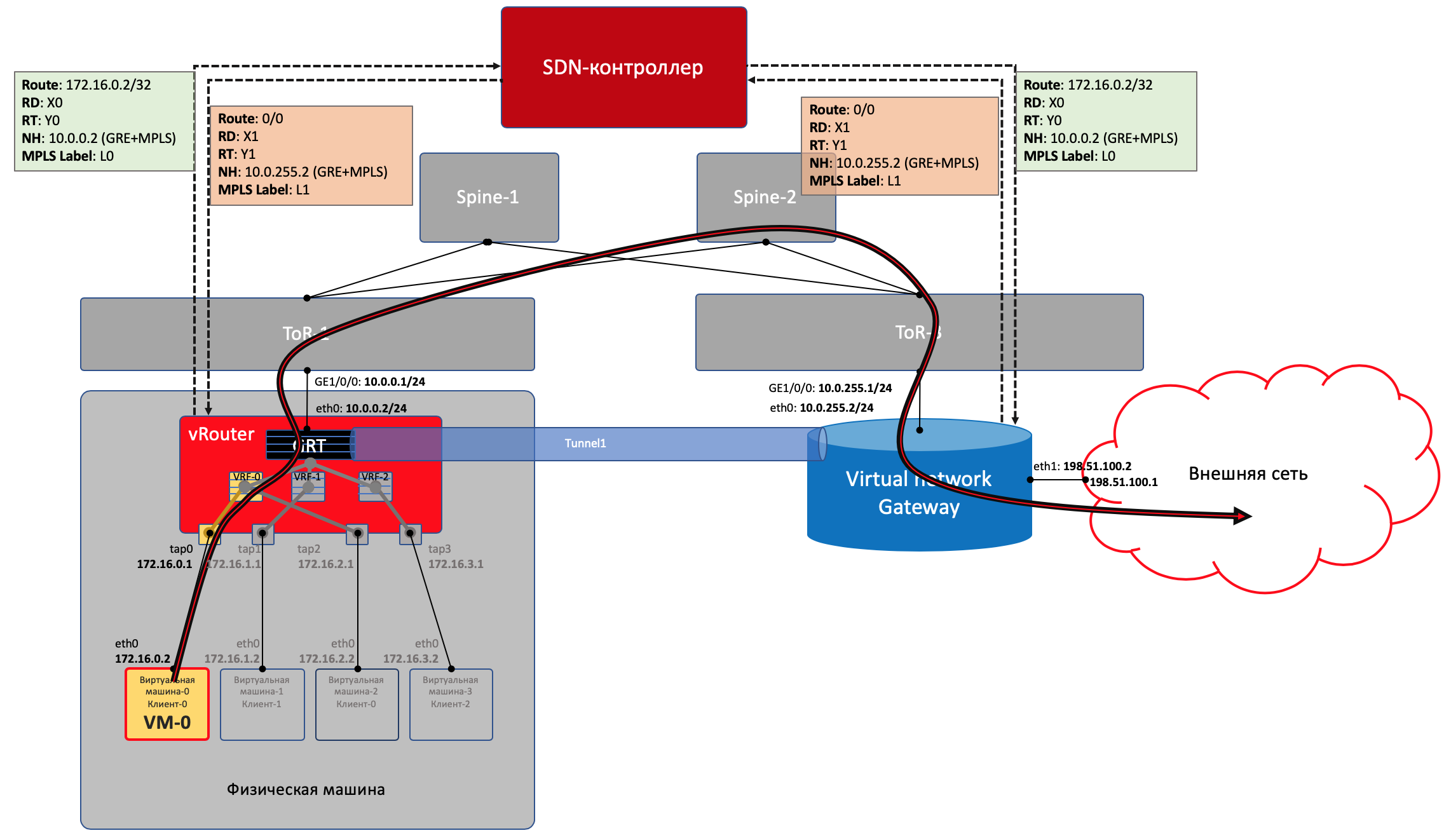
FAQ
¿Por qué siempre haces un comentario GRE / UDP?Bueno, en general, se puede decir que es específico de Tungsten Fabric; puede ignorarlo por completo.Pero si lo toma, entonces el propio TF, aunque todavía es un OpenContrail, admite ambas encapsulaciones: MPLS en GRE y MPLS en UDP.UDP es bueno porque en el puerto de origen en su encabezado es muy fácil codificar una función hash del IP + Proto + Port original, lo que permitirá el equilibrio.En el caso de GRE, por desgracia, solo hay encabezados externos de IP y GRE que son iguales para todo el tráfico encapsulado y no se habla de equilibrio: pocas personas pueden mirar tan profundamente dentro del paquete.Hasta hace algún tiempo, los enrutadores, si sabían cómo usar túneles dinámicos, solo en MPLSoGRE, y solo muy recientemente, aprendieron en MPLSoUDP. Por lo tanto, siempre debe hacer un comentario sobre la posibilidad de dos encapsulaciones diferentes.Para ser justos, vale la pena señalar que TF es totalmente compatible con la conectividad L2 utilizando VXLAN.Prometiste establecer paralelismos con OpenFlow.Realmente mendigan. vSwitch en el mismo OpenStack hace cosas muy similares usando VXLAN, que, por cierto, también tiene un encabezado UDP.En Data Plane funcionan aproximadamente igual, Control Plane difiere significativamente. Tungsten Fabric utiliza XMPP para entregar información de ruta a vRouter, mientras que Openflow funciona en OpenStack.¿Puedo tener un poco más sobre vRouter?Se divide en dos partes: vRouter Agent y vRouter Forwarder.El primero se inicia en el espacio de usuario del sistema operativo host y se comunica con el controlador SDN, intercambiando información sobre rutas, VRF y ACL.El segundo implementa Data Plane, generalmente en Kernel Space, pero también se puede iniciar en SmartNIC, tarjetas de red con una CPU y un chip de conmutación programable por separado, que le permite eliminar la carga de la CPU de la máquina host y hacer que la red sea más rápida y más predecible.Otro escenario es posible cuando vRouter es una aplicación DPDK en User Space.vRouter Agent elimina la configuración en vRouter Forwarder.¿Qué es la red virtual?Mencioné al comienzo del artículo sobre VRF que cada inquilino está conectado a su VRF. Y si esto fue suficiente para una comprensión superficial del trabajo de la red superpuesta, entonces ya en la próxima iteración es necesario hacer aclaraciones.Por lo general, en los mecanismos de virtualización, la entidad de red virtual (puede tomarlo como un nombre propio) se introduce por separado de los clientes / inquilinos / máquinas virtuales: es algo bastante independiente. Y esta red virtual a través de las interfaces ya se puede conectar en un inquilino, en el otro, en dos, pero al menos donde. Entonces, por ejemplo, se implementa el Encadenamiento de servicios, cuando el tráfico necesita pasar a través de ciertos nodos en la secuencia deseada, simplemente creando e invocando Redes virtuales en la secuencia correcta.Por lo tanto, como tal, no hay correspondencia directa entre la Red Virtual y el inquilino.
Conclusión
Esta es una descripción muy superficial del funcionamiento de una red virtual con una superposición del host y el controlador SDN. Pero no importa qué plataforma de virtualización tome hoy, funcionará de manera similar, ya sea VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric o Juniper Contrail. Diferirán en los tipos de encapsulación y encabezados, protocolos para entregar información a dispositivos de red finales, pero el principio de una red superpuesta sintonizada por software que funcione sobre una red subyacente relativamente simple y estática seguirá siendo la misma.Podemos decir que las áreas de creación de una nube privada hasta la fecha, el SDN basado en la red superpuesta ha ganado. Sin embargo, esto no significa que Openflow no tenga lugar en el mundo moderno: se usa en OpenStacke y en el mismo VMWare NSX, hasta donde yo sé, Google lo usa para configurar la red subyacente.A continuación, proporcioné enlaces a materiales más detallados, si desea estudiar el tema más profundamente.¿Y cuál es nuestra base?Pero en general, nada. No cambió todo el camino. Todo lo que necesita hacer en caso de una superposición del host es actualizar las rutas y los ARP a medida que aparece y desaparece vRouter / VNGW y arrastra los paquetes entre ellos.Formulemos una lista de requisitos para una red Underlay.- Para poder algún protocolo de enrutamiento, en nuestra situación - BGP.
- , , - .
- ECMP — .
- QoS, , ECN.
- NETCONF — .
Underlay- . , , Overlay .
, , , IP- .
, , , . , , .
. .
Enlaces utiles
Gracias
- Roman Gorge , antiguo anfitrión principal del podcast linkmeup, y ahora experto en el campo de las plataformas en la nube. Para comentarios y ediciones. Bueno, esperamos un artículo más profundo sobre virtualización en el futuro cercano.
- Alexander Shalimov , mi colega y experto en el desarrollo de redes virtuales. Para comentarios y ediciones.
- Valentina Sinitsyna , mi colega y experta en telas de tungsteno. Para comentarios y ediciones.
- Artyom Chernobay - ilustrador linkmeup. Para KDPV
- Alexander Limonov. Para el meme "automato".