En los viejos tiempos, teníamos solo unos pocos servicios, y poner en un día una actualización de más de uno de ellos en producción fue un gran
éxito . Luego, el mundo se aceleró, el sistema se volvió más complejo y nos transformamos en una organización con arquitectura de microservicios. Ahora tenemos alrededor de un centenar de servicios, y con el aumento en su número, la frecuencia de los lanzamientos también aumenta: hay más de 250 por semana.
Y si se prueban nuevas características dentro de los equipos de productos, entonces la tarea del equipo de pruebas de integración es verificar que los cambios incluidos en la versión no rompan la funcionalidad del componente, el sistema y otras características.

Trabajo como ingeniero de automatización de pruebas en Yandex.Money.
En este artículo hablaré sobre la evolución de las pruebas de integración de los servicios web, así como sobre la adaptación del proceso para aumentar el número de componentes del sistema y aumentar la frecuencia de los lanzamientos.
Acerca de los cambios en el ciclo de lanzamiento y el desarrollo del mecanismo de cálculo fueron descritos por ops y dev en
uno de los artículos anteriores . Te contaré sobre el historial de cambios en los procesos de prueba durante esta transformación.
Ahora tenemos unos 30 equipos de desarrollo. El equipo generalmente incluye al gerente de producto, gerente de proyecto, desarrolladores y probadores de front-end y back-end. Están unidos por el trabajo en tareas para un producto específico. En general, el servicio es responsable del servicio, que a menudo realiza cambios en él.
Pruebas de aceptación de extremo a extremo
No hace mucho tiempo, con el lanzamiento de cada componente, solo se ejecutaban pruebas de unidades y componentes, y después de eso, solo algunos de los scripts de extremo a extremo más importantes se ejecutaban en un entorno de prueba completo antes de poner el servicio en producción. Junto con el aumento en el número de componentes, el número de conexiones entre ellos comenzó a crecer exponencialmente. A menudo, conexiones completamente no triviales. Recuerdo cómo la falta de disponibilidad del servicio para emitir datos de marketing rompió el registro del usuario por completo (por supuesto, por un corto tiempo).
Este enfoque para verificar los cambios comenzó a fallar cada vez más a menudo: requería cubrir todos los escenarios empresariales críticos con pruebas automáticas y ejecutarlos en un entorno de prueba completo con una versión de componente lista para su lanzamiento.
Bien, han aparecido pruebas automáticas para escenarios críticos, pero ¿cómo ejecutarlas? Había una tarea para integrar en el ciclo de lanzamiento, afectando mínimamente su fiabilidad con falsas caídas de prueba. Por otro lado, quería llevar a cabo la etapa de prueba de integración lo más rápido posible. Entonces había una infraestructura para llevar a cabo pruebas de aceptación.
Intentamos aprovechar al máximo las herramientas ya utilizadas para llevar a cabo el componente en el ciclo de lanzamiento y las tareas de lanzamiento: Jira y Jenkins, respectivamente.
Ciclo de prueba de aceptación
Para realizar pruebas de aceptación, determinamos el siguiente ciclo:
- monitoreo de tareas entrantes para pruebas de aceptación de una versión,
- ejecutar el trabajo de Jenkins para instalar la compilación de lanzamiento en un entorno de prueba,
- comprobar que el servicio ha aumentado
- lanzar el trabajo de Jenkins con pruebas de integración,
- análisis de los resultados de la carrera,
- prueba repetida (si es necesario),
- actualizar el estado de la tarea: completada o interrumpida, indicando el motivo en el comentario.
El ciclo completo se realizó manualmente cada vez. Como resultado, ya en el décimo lanzamiento por día, quería jurar que realizaría las mismas tareas, en el mejor de los casos, por lo bajo, agarrándome la cabeza y exigiendo
cerveza de valeriana.
Monitor Bot
Nos dimos cuenta de que el seguimiento y la notificación de nuevas tareas en Jira son procesos importantes que son rápidos y fáciles de automatizar. Entonces había un bot que hace esto.
Los datos para generar alertas vienen en forma de notificaciones push de Jira. Después de iniciar el bot, dejamos de actualizar la página del tablero con las tareas de aceptación, y el ancho de la sonrisa del autómata aumentó ligeramente.
Pinger
Decidimos simplificar la verificación de que durante la implementación en el entorno de prueba no se produjeron errores de ensamblaje o instalación y que se levantó la versión deseada del componente, y no otra. El componente proporciona su versión y estado a través de HTTP. Y comprobar que el servicio devuelve la versión correcta sería simple y comprensible si no se escribieran diferentes componentes en diferentes idiomas, algunos en Node.js, otros en C #. Además, nuestros servicios más populares en Java también dieron la versión en un formato diferente.
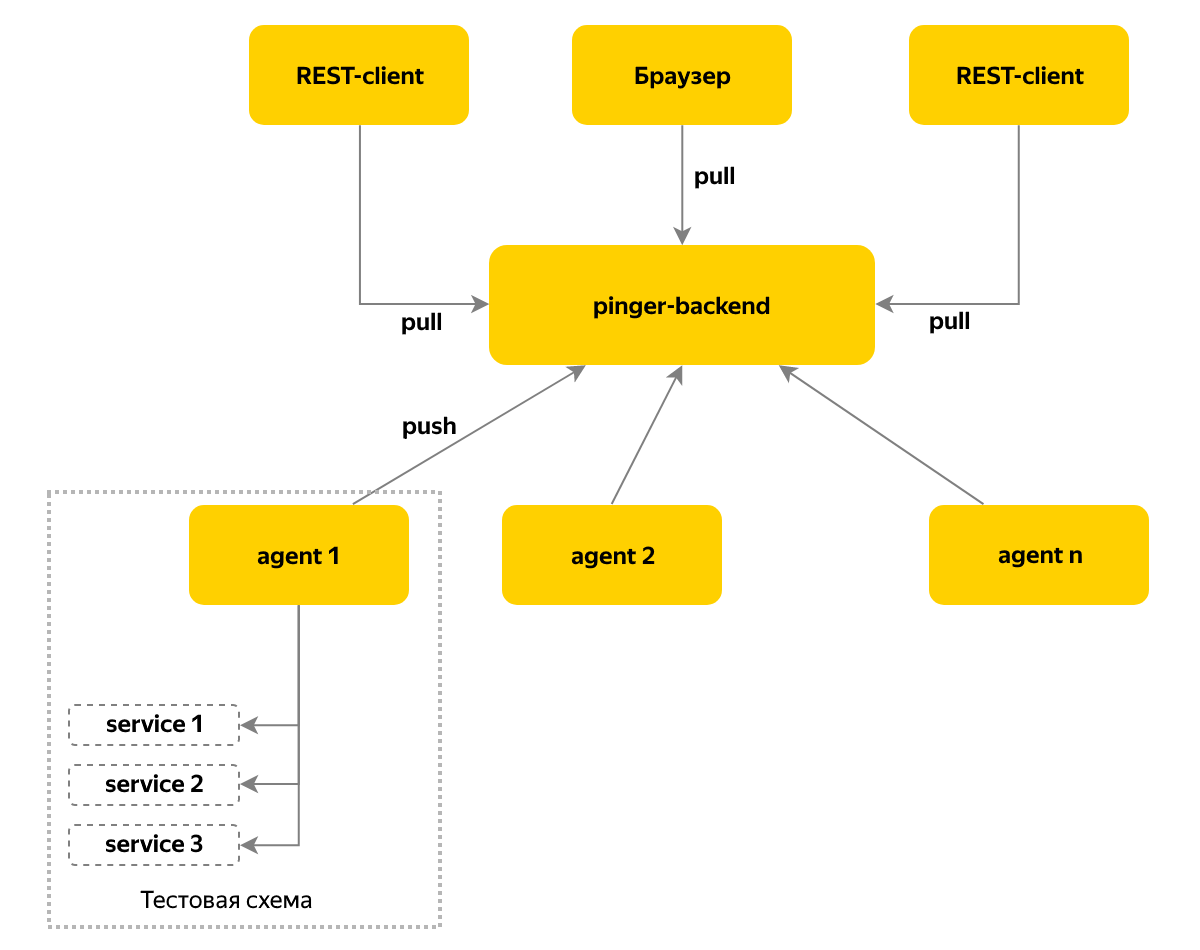
Además, quería tener información y notificaciones en tiempo real no solo sobre los cambios de versión, sino también sobre los cambios en la disponibilidad de componentes en el sistema. Para resolver este problema, apareció el servicio Pinger, que recopila información sobre el estado y la versión de los componentes sondeándolos cíclicamente.
Utilizamos un modelo de envío de mensajes push: se implementa un agente en cada instancia del entorno de prueba, que recopila información sobre los componentes de este entorno y almacena los datos en un nodo central cada 10 segundos. Accedemos a este nodo para conocer el estado actual: este enfoque nos permite admitir más de cien bancos de pruebas.
Taquilla
Ha llegado el momento de realizar tareas más complejas: actualización automática de componentes y ejecución de pruebas. En ese momento, nuestro equipo ya tenía 3 bancos de pruebas en OpenStack para las pruebas de aceptación, y primero era necesario resolver el problema de administrar los recursos de los bancos de pruebas: sería desagradable si la actualización de la próxima versión "se ejecuta" cuando se ejecutan pruebas en el sistema. También sucede que el banco de pruebas está depurado, y luego no debe usarlo para su aceptación.
Quería poder ver el estado del empleo y, si es necesario, bloquear manualmente el soporte durante el análisis de las pruebas caídas o hasta la finalización de otro trabajo.
Por todo esto, ha aparecido el servicio Locker. Mantiene el estado del banco de pruebas durante mucho tiempo ("ocupado" / "libre"), le permite especificar un comentario sobre "ocupado", para que quede claro que ahora estamos depurando, volviendo a crear una copia del entorno de prueba o ejecutando pruebas para la próxima versión. También comenzamos a bloquear stands en la noche; en ellos, los administradores realizan el trabajo en un horario, como copias de seguridad y sincronización de bases de datos.
Cuando se bloquea, siempre se establece el tiempo después del cual expira la cerradura; ahora las personas no necesitan participar en el regreso de los stands al grupo disponible, y la máquina hace todo.
Deber
Para distribuir equitativamente la carga entre los miembros del equipo para analizar los resultados de las pruebas, elaboramos turnos diarios. El asistente trabaja con las tareas de pruebas de aceptación de versiones, analiza las pruebas automáticas caídas e informa de errores. Si el asistente comprende que no está haciendo frente al flujo de tareas, puede pedir ayuda al equipo. En este momento, el resto del equipo está involucrado en tareas que no están relacionadas con los lanzamientos.
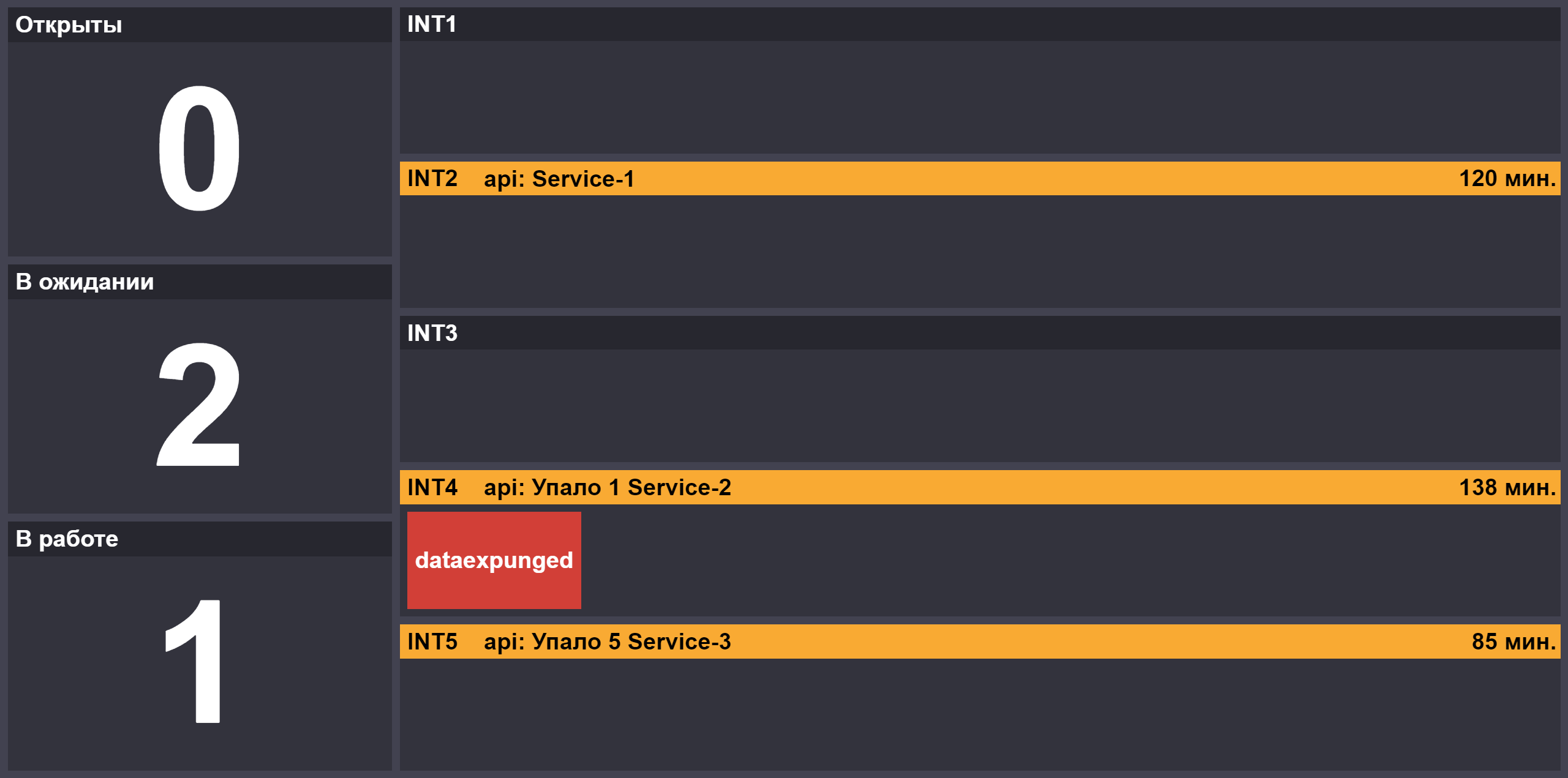
Con el aumento en el número de lanzamientos, apareció la función del segundo asistente, que se conecta con el principal si hay bloqueos o hay lanzamientos críticos en la cola. Para proporcionar información sobre el progreso de las versiones de prueba, creamos una página con el número de tareas en los estados "abierto" / "en ejecución" / "esperando una respuesta del deber", el estado de los bancos de prueba bloqueados y los componentes inaccesibles en los bancos:
El trabajo del oficial de servicio requiere concentración, por lo que tiene un moño: el día de servicio, puede elegir un lugar para almorzar para todo el equipo cerca de la oficina. Los sobornos de servicio en el estilo se ven especialmente divertidos: "déjame ayudarte a resolver las tareas, y hoy iremos a
mi lugar favorito" =)
Reportero
Una de las tareas que encontramos cuando presentamos el reloj fue la necesidad de transferir el conocimiento de un oficial a otro, por ejemplo, sobre las pruebas que caen en una nueva versión o los detalles de la actualización de un componente.
Además, tenemos nuevas características de trabajo.
- Hubo una categoría de pruebas que caen con una frecuencia mayor o menor debido a problemas con los bancos de prueba. Las caídas pueden ocurrir debido al mayor tiempo de respuesta de uno de los servicios o la larga carga de recursos en el navegador. No quiero apagar las pruebas; se han agotado los medios razonables para aumentar su fiabilidad.
- Tuvimos un segundo proyecto experimental con pruebas automáticas, y surgió la necesidad de analizar las ejecuciones de dos proyectos a la vez, mirando los informes de Allure.
- Una ejecución de prueba puede demorar hasta 20 minutos, y desea comenzar a analizar los resultados inmediatamente después del inicio de las primeras gotas. Especialmente si la tarea es crítica y los miembros del equipo responsable de la liberación están parados detrás de usted
, sosteniendo el cuchillo en la garganta con ojos lastimosos.
Así es como surgió el servicio Reporter. En él, empujamos los resultados de la ejecución de la prueba en tiempo real durante el proceso de prueba. El servicio tiene una base de datos de problemas o errores conocidos que están vinculados a una prueba específica. Además, se publicó una publicación en el portal wiki de la compañía de un informe resumido sobre los resultados de la ejecución del reportero. Esto es conveniente para los gerentes que no desean sumergirse en los detalles técnicos con los que abunda la interfaz Reporter o Allure.
Si la prueba falla, puede buscar en el Reporter una lista de errores relacionados o corregir tareas. Dicha información acorta el tiempo de análisis y facilita el intercambio de conocimientos sobre problemas entre los miembros de nuestro equipo. Los registros de las tareas completadas se archivan, pero si es necesario, puede "espiarlos" en una lista separada. Para no cargar servicios internos durante el horario comercial, entrevistamos a Jira por la noche y archivamos entradas para problemas con el estado final.
Una ventaja adicional de la introducción de Reporter fue la aparición de una base de datos de ejecución, en la que puede analizar la frecuencia de caídas, clasificar las pruebas por su nivel de estabilidad o "utilidad" en términos de la cantidad de errores encontrados.
Autorun
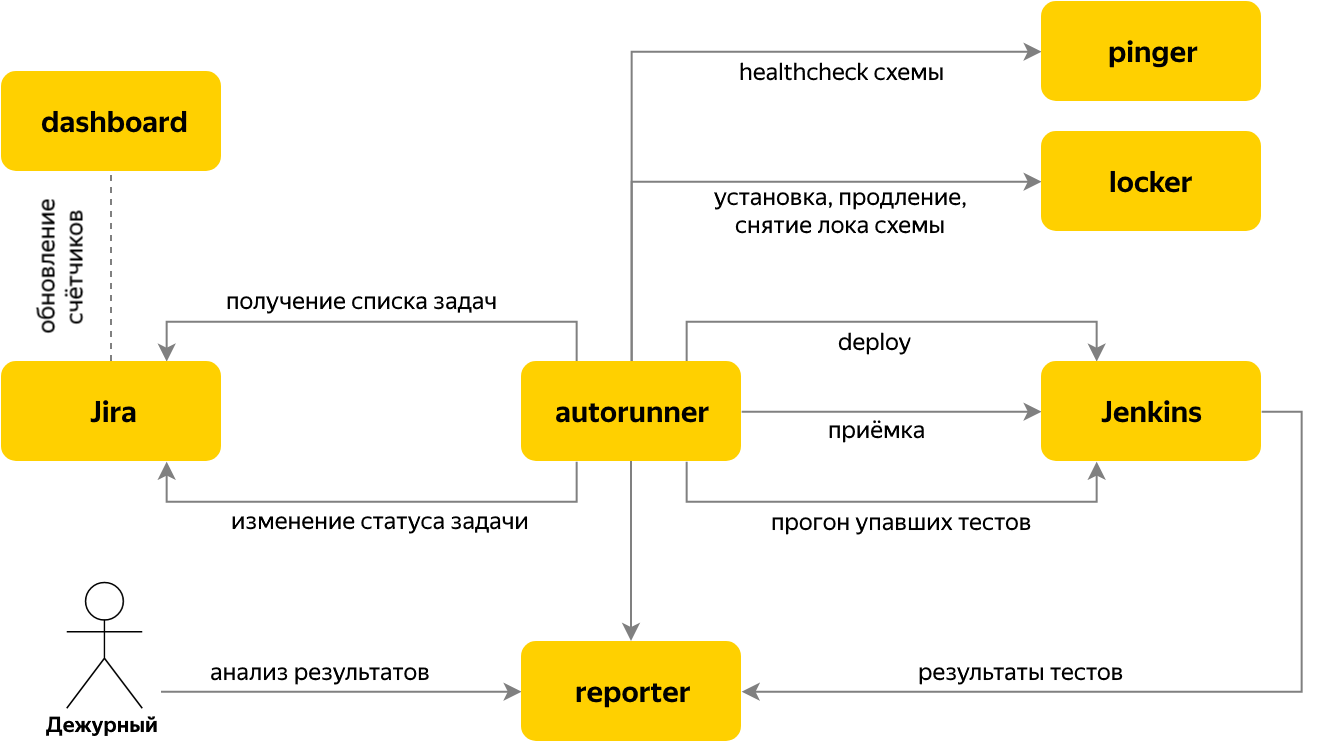
A continuación, pasamos a automatizar el lanzamiento de las pruebas cuando el tema de las pruebas de aceptación del lanzamiento llega al rastreador de problemas. Para este propósito, se escribió el servicio Autorun, que verifica si hay nuevas tareas de aceptación en Jira, y si es así, determina el nombre del componente y su versión en función del contenido de la tarea.
Para la tarea, se realizan varios pasos:
- tome la cerradura de uno de los bancos de prueba gratuitos en el servicio Locker,
- comience la instalación del componente necesario en Jenkins, espere a que el componente se genere con la versión requerida,
- ejecutar pruebas
- espere a que se complete la ejecución de la prueba, en el proceso de ejecución todos los resultados se envían a Reporter,
- le pedimos a Reporter la cantidad de pruebas fallidas, excluyendo las que cayeron debido a problemas conocidos,
- si 0 ha caído, transferimos la tarea para la prueba de aceptación a "Finalizar" y terminamos de trabajar con ella. Todo está listo =)
- si hay pruebas "rojas", traducimos la tarea a "En espera" y vamos a Reporter para analizarlas.
El cambio entre etapas está organizado por el principio de una máquina de estados finitos. Cada etapa en sí misma conoce las condiciones para la transición a la siguiente. Los resultados de la etapa se almacenan en el contexto de la tarea, que es común para las etapas de una tarea.
Todo esto le permite transferir automáticamente versiones a lo largo de la tubería de implementación, de acuerdo con las cuales el 100 por ciento de las pruebas son verdes. Pero, ¿qué pasa con la inestabilidad causada no por problemas en el componente, sino por las características "naturales" de las pruebas de IU o por el aumento de los retrasos de la red en el banco de pruebas?
Para hacer esto, hemos implementado un mecanismo de reintento, que muchas personas usan, pero pocos lo reconocen. Las retransmisiones se organizan como una ejecución secuencial de pruebas en la tubería de Jenkins.
Después de la ejecución, solicitamos una lista de pruebas fallidas de Reporter de Jenkins, y reiniciamos solo las fallidas. Además, reducimos el número de subprocesos al inicio. Si el número de pruebas descartadas no ha disminuido en comparación con la ejecución anterior, finalizamos inmediatamente Job. En nuestro caso, este enfoque para reiniciar nos permite aumentar el éxito de las pruebas de aceptación aproximadamente 2 veces.
Bloqueo rápido
El sistema de pruebas de aceptación resultante nos permitió realizar más del 60% de las emisiones sin intervención humana. ¿Pero qué hacer con el resto? Si es necesario, el asistente crea un informe de error en el componente bajo prueba o la tarea de arreglar las pruebas al equipo de desarrollo. A veces: elabora un error de la configuración del banco de pruebas para el departamento de operaciones.
Las tareas para corregir las pruebas a menudo bloquean el paso correcto de las pruebas automáticas, ya que las pruebas irrelevantes siempre serán "rojas". Los evaluadores de los equipos de desarrollo son responsables de escribir nuevas pruebas y actualizar las existentes, haciendo cambios a través de solicitudes de extracción al proyecto con pruebas automáticas. Estas ediciones están sujetas a una revisión obligatoria, que requiere un tiempo del revisor y del autor, y quiero bloquear temporalmente las pruebas irrelevantes hasta que la tarea se traduzca a su estado final.
Primero, implementamos un mecanismo de apagado basado en anotaciones de métodos de prueba. Posteriormente, resultó que debido a la presencia de una revisión obligatoria del código, el bloqueo del código no siempre es conveniente y puede llevar más tiempo del que quisiéramos.
Por lo tanto, trasladamos la lista de tareas que bloquean las pruebas a un nuevo servicio con una página web: bloqueo rápido. Por lo tanto, los miembros del equipo responsable del componente pueden bloquear rápidamente la prueba. Antes de la ejecución, vamos a este servicio y obtenemos una lista de pruebas en cuarentena, que traducimos al estado omitido.
Resumen
Hemos pasado de la aceptación de lanzamientos en modo manual a un proceso casi completamente automático, que puede realizarse a través de pruebas de aceptación de más de 50 lanzamientos por día. Esto ayuda a la compañía a reducir el tiempo que lleva publicar los cambios, y nuestro equipo puede encontrar recursos para experimentar y desarrollar herramientas de prueba.
En el futuro, planeamos aumentar la confiabilidad del proceso, por ejemplo, mediante la distribución de solicitudes entre un par de instancias de cada servicio de la lista anterior. Esto le permitirá actualizar las herramientas sin tiempo de inactividad e incluir nuevas funciones solo para parte de las pruebas de aceptación. Además, prestamos atención a estabilizar las pruebas en sí. En desarrollo, un generador de tickets para refactorizar pruebas con la tasa de éxito más baja.
Mejorar la confiabilidad de las pruebas no solo aumentará la confianza en ellas, sino que también acelerará las pruebas de lanzamientos debido a la falta de reinicios de scripts caídos.