Hola a todos! El próximo lunes, las clases comenzarán en el nuevo grupo del curso
Python Developer , lo que significa que tenemos tiempo para publicar otro material interesante, que haremos ahora. Que tengas una buena lectura.

En 2003, Intel lanzó el nuevo procesador Pentium 4 "HT". Este procesador overclockeó a 3GHz y soportó tecnología hyper-threading.

En los años siguientes, Intel y AMD lucharon por lograr el mejor rendimiento de escritorio al aumentar la velocidad del bus, el tamaño de caché L2 y reducir el tamaño de la matriz para minimizar la latencia. En 2004, el modelo HT con una frecuencia de 3 GHz fue reemplazado por el modelo 580 Prescott con overclocking a 4 GHz.
Parecía que para avanzar solo era necesario aumentar la frecuencia del reloj, sin embargo, los nuevos procesadores sufrieron un alto consumo de energía y disipación de calor.
¿Su procesador de escritorio entrega 4 GHz hoy? Es poco probable, ya que el camino para mejorar el rendimiento finalmente radica en aumentar la velocidad del bus y aumentar el número de núcleos. En 2006, Intel Core 2 reemplazó al Pentium 4 y tenía una velocidad de reloj mucho menor.
Además de lanzar procesadores multi-core para una amplia audiencia de usuarios, algo más sucedió en 2006. ¡Python 2.5 finalmente vio la luz! Ya viene con una versión beta de la palabra clave with, que todos ustedes conocen y aman.
Python 2.5 tenía una limitación importante cuando se trataba de usar Intel Core 2 o AMD Athlon X2.
Fue un GIL.
¿Qué es un GIL?
GIL (Global Interpreter Lock) es un valor booleano en el intérprete de Python protegido por un mutex. El bloqueo se usa en el bucle de cálculo del código de bytes CPython principal para determinar qué hilo está ejecutando actualmente las instrucciones.
CPython admite el uso de varios subprocesos en un solo intérprete, pero los subprocesos deben solicitar acceso al GIL para realizar operaciones de bajo nivel. A su vez, esto significa que los desarrolladores de Python pueden usar código asincrónico, subprocesos múltiples y ya no tienen que preocuparse por bloquear ninguna variable o bloqueos en el nivel del procesador durante los puntos muertos.
GIL simplifica la programación multiproceso de Python.

GIL también nos dice que si bien CPython puede ser multiproceso, solo se puede ejecutar un subproceso a la vez. Esto significa que su procesador de cuatro núcleos hace algo como esto (con la excepción de la pantalla azul, con suerte).
La versión actual de GIL
se escribió en 2009 para admitir funciones asincrónicas y permaneció intacta incluso después de muchos intentos de eliminarla en principio o cambiar los requisitos para ello.
Cualquier sugerencia para eliminar el GIL estaba justificada por el hecho de que el bloqueo global del intérprete no debería degradar el rendimiento del código de subproceso único. Cualquiera que haya intentado habilitar hyperthreading en 2003 entenderá de lo
que estoy hablando .
Gil abandono en CPython
Si realmente quiere paralelizar el código en CPython, deberá usar varios procesos.
En CPython 2.6, el módulo de
multiprocesamiento se agregó a la biblioteca estándar. El multiprocesamiento enmascara la generación de procesos en CPython (cada proceso con su propio GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Se crean procesos, se les envían comandos mediante módulos compilados y funciones de Python, y luego se vuelven a unir al proceso principal.
El multiprocesamiento también admite el uso de variables a través de una cola o canal. Ella tiene un objeto de bloqueo, que se utiliza para bloquear objetos en el proceso principal y escribir desde otros procesos.
El multiprocesamiento tiene un gran inconveniente. Lleva una carga computacional significativa, que afecta tanto el tiempo de procesamiento como el uso de la memoria. El tiempo de inicio de CPython, incluso sin ningún sitio, es de 100-200 ms (consulte
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b para obtener más información).
Como resultado, puede tener código paralelo en CPython, pero aún necesita planificar cuidadosamente el trabajo de los procesos de larga duración que comparten varios objetos.
Otra alternativa puede ser usar un paquete de terceros como Twisted.
PEP554 y la muerte de GIL?
Entonces, permítanme recordarles que el subprocesamiento múltiple en CPython es simple, pero en realidad no es paralelización, sino que el multiprocesamiento es paralelo, pero conlleva una sobrecarga significativa.
¿Qué pasa si hay una mejor manera?La clave para evitar el GIL reside en el nombre, el bloqueo global del intérprete es parte del estado global del intérprete. Los procesos de CPython pueden tener varios intérpretes y, por lo tanto, varios bloqueos, sin embargo, esta función rara vez se usa, ya que el acceso a ella solo se realiza a través de la C-API.
Una de las características de CPython 3.8 es PEP554, una implementación de subinterpretadores y API con un nuevo módulo de
interpreters en la biblioteca estándar.
Esto le permite crear múltiples intérpretes desde Python en un solo proceso. Otra innovación de Python 3.8 es que todos los intérpretes tendrán su propio GIL.
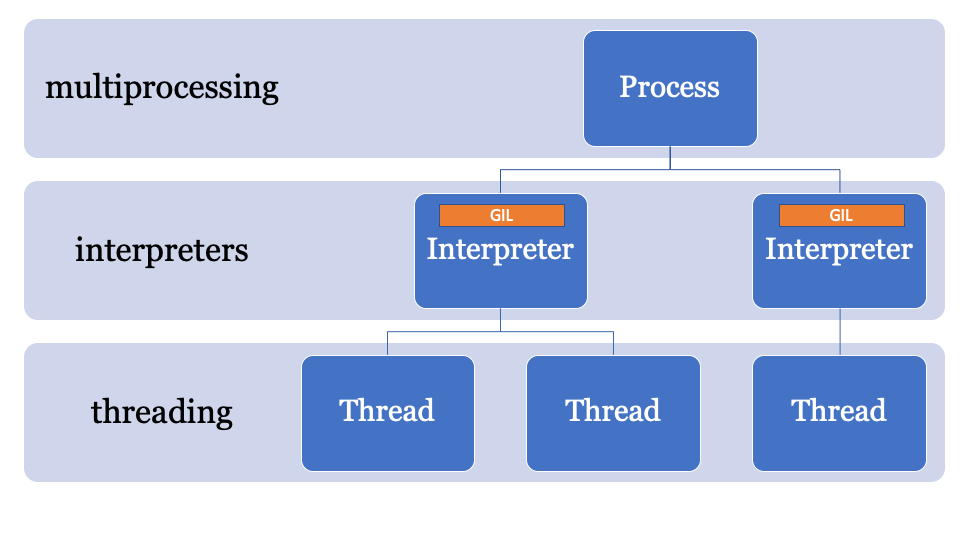
Dado que el estado del intérprete contiene una región asignada en la memoria, una colección de todos los punteros a objetos Python (locales y globales), los subinterpretadores en PEP554 no pueden acceder a las variables globales de otros intérpretes.
Al igual que el multiprocesamiento, los intérpretes que comparten objetos consisten en serializarlos y usar el formulario IPC (red, disco o memoria compartida). Hay muchas formas de serializar objetos en Python, por ejemplo, el módulo
marshal , el módulo de
pickle o métodos más estandarizados como
json o
simplexml . Cada uno de ellos tiene sus pros y sus contras, y todos dan una carga informática.
Sería mejor tener un espacio de memoria común que se pueda cambiar y controlar mediante un proceso específico. Por lo tanto, los objetos pueden ser enviados por el intérprete principal y recibidos por otro intérprete. Este será el espacio de memoria administrado para buscar punteros de PyObject, al que puede acceder cualquier intérprete, mientras que el proceso principal administrará los bloqueos.
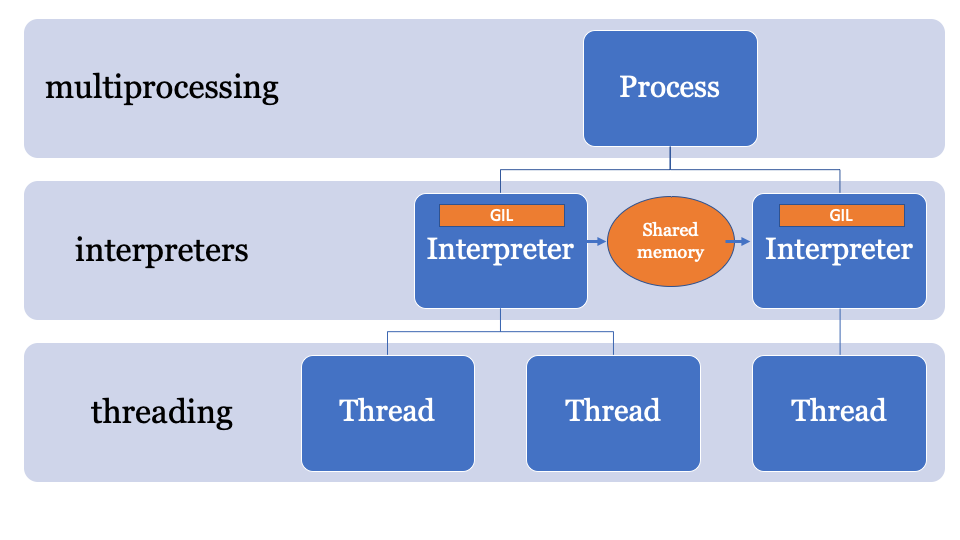
Todavía se está desarrollando una API para esto, pero probablemente se verá más o menos así:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal
Este ejemplo usa NumPy. La matriz numpy se envía a través del canal, se serializa utilizando el módulo
marshal , luego el subinterpretador procesa los datos (en un GIL separado), por lo que puede haber un problema de paralelización asociado con la CPU, que es ideal para los subinterpretadores.
Se ve ineficiente
El módulo
marshal funciona realmente rápido, pero no tan rápido como compartir objetos directamente desde la memoria.
PEP574 presenta un nuevo protocolo de
pickle (v5) que admite la capacidad de procesar buffers de memoria por separado del resto de la secuencia de pickle. Para objetos de datos grandes, serializarlos todos de una vez y deserializarlos desde un subinterpretador agregará una gran cantidad de sobrecarga.
La nueva API se puede implementar (puramente hipotéticamente) de la siguiente manera:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle
Se ve estampado
En esencia, este ejemplo se basa en el uso de la API de subinterpretadores de bajo nivel. Si no ha utilizado la biblioteca de
multiprocessing , algunos problemas le resultarán familiares. No es tan simple como el procesamiento de flujo, no puede simplemente, por ejemplo, ejecutar esta función con dicha lista de datos de entrada en intérpretes separados (por ahora).
Tan pronto como este PEP se fusione con otros, creo que veremos varias API nuevas en PyPi.
¿Cuánta sobrecarga tiene el subinterpretador?
Respuesta corta: más que una secuencia, menos que un proceso.
Respuesta larga: el intérprete tiene su propio estado, por lo que deberá clonar e inicializar lo siguiente, a pesar de que PEP554 simplifica la creación de subinterpretadores:
- Módulos en el
importlib __main__ e importlib ; - El contenido del diccionario
sys ; - Funciones incorporadas (
print() , assert , etc.); - Corrientes;
- Configuración del kernel.
La configuración del núcleo se puede clonar fácilmente desde la memoria, pero importar módulos no es tan simple. Importar módulos en Python es lento, por lo que si crear un subinterpretador significa importar módulos en un espacio de nombres diferente cada vez, los beneficios se reducen.
¿Qué hay de asyncio?
La implementación existente del
asyncio eventos
asyncio en la biblioteca estándar crea marcos de pila para la evaluación, y también
asyncio estado en el intérprete principal (y, por lo tanto, comparte el GIL).
Después de combinar PEP554, probablemente ya en Python 3.9, se puede usar una implementación alternativa del bucle de eventos (aunque nadie lo ha hecho todavía), que ejecuta métodos asincrónicos en subinterpretadores en paralelo.
Suena genial, ¡envuélveme también!
Bueno, en realidad no.
Dado que CPython se ha estado ejecutando en el mismo intérprete durante tanto tiempo, muchas partes de la base de código usan el "Estado de tiempo de ejecución" en lugar del "Estado del intérprete", por lo que si se introdujera PEP554 ahora, todavía habría muchos problemas.
Por ejemplo, el estado del recolector de basura (en las versiones 3.7 <) pertenece al tiempo de ejecución.
En los cambios durante los sprints de PyCon, el estado del recolector de basura
comenzó a moverse hacia el intérprete, de modo que cada subinterpretador tendría su propio recolector de basura (como debería ser).
Otro problema es que hay algunas variables "globales" que persisten en la base del código CPython junto con muchas extensiones en C. Por lo tanto, cuando la gente de repente comenzó a paralelizar su código correctamente, vimos algunos problemas.
Otro problema es que los descriptores de archivo pertenecen al proceso, por lo que si tiene un archivo abierto para escribir en un intérprete, el subinterpretador no podrá acceder a este archivo (sin más cambios en CPython).
En resumen, todavía hay muchos problemas que deben abordarse.
Conclusión: ¿GIL es verdad más?
GIL continuará siendo utilizado para aplicaciones de un solo hilo. Por lo tanto, incluso cuando sigue a PEP554, su código de subproceso único de repente no se volverá paralelo.
Si desea escribir código paralelo en Python 3.8, tendrá problemas de paralelización asociados con el procesador, ¡pero esto también es un boleto para el futuro!
Cuando
Pickle v5 y el uso compartido de memoria para multiprocesamiento probablemente estarán en Python 3.8 (octubre de 2019), y aparecerán subinterpretadores entre las versiones 3.8 y 3.9.
Si desea jugar con los ejemplos presentados, creé una rama separada con todo el código necesario:
https://github.com/tonybaloney/cpython/tree/subinterpreters.¿Qué opinas sobre esto? Escribe tus comentarios y nos vemos en el curso.