Mi nombre es Stas Kirillov, soy un desarrollador líder en el grupo de plataformas ML en Yandex. Estamos desarrollando herramientas de aprendizaje automático, apoyando y desarrollando infraestructura para ellos. A continuación se muestra mi reciente charla sobre cómo funciona la biblioteca CatBoost. En el informe, hablé sobre los puntos de entrada y las características del código para aquellos que quieran entenderlo o convertirse en nuestro colaborador.
- CatBoost vive en GitHub bajo la licencia Apache 2.0, es decir, es abierto y gratuito para todos. El proyecto se está desarrollando activamente, ahora nuestro repositorio tiene más de cuatro mil estrellas. CatBoost está escrito en C ++, es una biblioteca para aumentar el gradiente en los árboles de decisión. Admite varios tipos de árboles, incluidos los llamados árboles "simétricos", que se utilizan en la biblioteca de forma predeterminada.
¿Cuál es el beneficio de nuestros árboles ajenos? Aprenden rápidamente, aplican rápidamente y ayudan a aprender a ser más resistentes a los parámetros cambiantes en términos de cambios en la calidad final del modelo, lo que reduce en gran medida la necesidad de seleccionar parámetros. Nuestra biblioteca se trata de facilitar su uso en la producción, aprender rápido y obtener buena calidad de inmediato.

El aumento de gradiente es un algoritmo en el que construimos predictores simples que mejoran nuestra función objetivo. Es decir, en lugar de construir inmediatamente un modelo complejo, construimos muchos modelos pequeños a su vez.

¿Cómo es el proceso de aprendizaje en CatBoost? Te diré cómo funciona en términos de código. Primero, analizamos los parámetros de entrenamiento que pasa el usuario, los validamos y luego vemos si necesitamos cargar los datos. Debido a que los datos ya se pueden cargar, por ejemplo, en Python o R. A continuación, cargamos los datos y construimos una cuadrícula desde los bordes para cuantificar las características numéricas. Esto es necesario para que el aprendizaje sea rápido.
Las características categóricas las procesamos de manera un poco diferente. Clasificamos las características desde el principio, y luego renumeramos los valores hash de cero al número de valores únicos de la característica categórica para poder leer rápidamente las combinaciones de características categóricas.
Luego lanzamos el ciclo de capacitación directamente, el ciclo principal de nuestro aprendizaje automático, donde construimos árboles de forma iterativa. Después de este ciclo, el modelo se exporta.
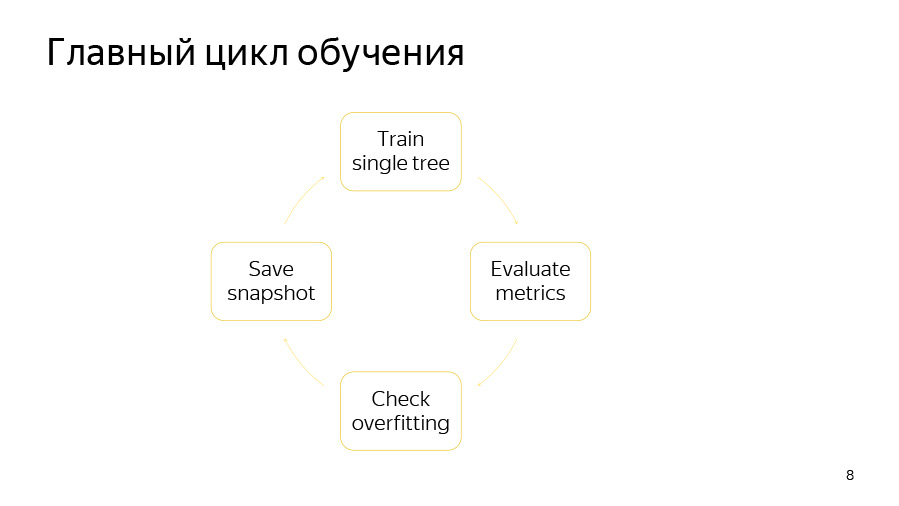
El ciclo de entrenamiento en sí consta de cuatro puntos. Primero, estamos tratando de construir un árbol. Luego observamos qué tipo de aumento o disminución de la calidad ofrece. Luego verificamos si nuestro detector de reentrenamiento ha funcionado. Luego, si es el momento adecuado, guardamos la instantánea.

Aprender un solo árbol es un ciclo a través de los niveles de los árboles. Al principio, seleccionamos al azar una permutación de datos si usamos el refuerzo ordenado o tenemos características categóricas. Luego contamos los contadores en esta permutación. Luego tratamos de elegir con avidez buenas divisiones en este árbol. Por divisiones entendemos simplemente ciertas condiciones binarias: tal y tal característica numérica es mayor que tal o cual valor, o tal y tal contador por característica categórica es mayor que tal y tal valor.
¿Cómo se organiza el ciclo de nivel del árbol codicioso? Al principio, se realiza el bootstrap: volvemos a pesar o muestreamos los objetos, después de lo cual solo los objetos seleccionados se utilizarán para construir el árbol. Bootstrap también se puede contar antes de seleccionar cada división si la opción de muestreo en cada nivel está habilitada.
Luego agregamos los derivados en histogramas, como lo hacemos para cada candidato dividido. Usando histogramas, tratamos de evaluar el cambio en la función objetivo que ocurrirá si seleccionamos este candidato dividido.
Seleccionamos al candidato con la mejor velocidad y lo agregamos al árbol. Luego calculamos las estadísticas usando este árbol seleccionado en las permutaciones restantes, actualizamos el valor en las hojas en estas permutaciones, calculamos los valores en las hojas para el modelo y procedemos a la siguiente iteración del bucle.

Es muy difícil seleccionar un lugar donde se lleva a cabo el entrenamiento, por lo que en esta diapositiva, puede usarlo como un punto de entrada, se enumeran los archivos principales que usamos para el entrenamiento. Esto es greedy_tensor_search, en el que vivimos el mismo procedimiento para la selección codiciosa de divisiones. Este es train.cpp, donde tenemos la fábrica principal de entrenamiento de CPU. Esto es aproximadamente_calcer, donde se encuentran las funciones de actualización de los valores en las hojas. Y también score_calcer: una función para evaluar a algún candidato.
Partes igualmente importantes son catboost.pyx y core.py. Este es el código del contenedor de Python, lo más probable es que muchos de ustedes incorporen algún tipo de cosas en el contenedor de Python. Nuestro contenedor de Python está escrito en Cython, Cython se traduce en C ++, por lo que este código debe ser rápido.
Nuestro R-wrapper se encuentra en la carpeta R-package. Quizás alguien tendrá que agregar o corregir algunas opciones, para las opciones tenemos una biblioteca separada: catboost / libs / options.
Vinimos de Arcadia a GitHub, por lo que tenemos muchos artefactos interesantes que encontrarás.


Comencemos con la estructura del repositorio. Tenemos una carpeta util donde las primitivas básicas son: vectores, mapas, sistemas de archivos, trabajo con cadenas, secuencias.
Tenemos una biblioteca donde se encuentran las bibliotecas compartidas utilizadas por Yandex, muchas, no solo CatBoost.
La carpeta CatBoost y contrib es el código de las bibliotecas de terceros a las que vinculamos.
Ahora hablemos de las primitivas de C ++ que encontrará. El primero son los punteros inteligentes. En Yandex, hemos usado THolder desde std :: unique_ptr, y MakeHolder se usa en lugar de std :: make_unique.

Tenemos nuestro propio SharedPtr. Además, existe en dos formas, SimpleSharedPtr y AtomicSharedPtr, que difieren en el tipo de contador. En un caso, es atómico, lo que significa que, como si varias corrientes pudieran poseer un objeto. Por lo tanto, será seguro desde el punto de vista de la transferencia entre flujos.
Una clase separada, IntrusivePtr, le permite poseer objetos heredados de la clase TRefCounted, es decir, clases que tienen un contador de referencia incorporado. Esto es para asignar tales objetos a la vez, sin asignar adicionalmente un bloque de control con un contador.
También tenemos nuestro propio sistema de entrada y salida. IInputStream e IOutputStream son interfaces para entrada y salida. Tienen métodos útiles, como ReadTo, ReadLine, ReadAll, en general, todo lo que se puede esperar de InputStreams. Y tenemos implementaciones de estos flujos para trabajar con la consola: Cin, Cout, Cerr y Endl por separado, que es similar a std :: endl, es decir, limpia el flujo.

También tenemos nuestras propias implementaciones de interfaz para archivos: TInputFile, TOutputFile. Esta es una lectura protegida. Implementan la lectura y la escritura en un archivo, para que pueda usarlas.
Util / system / fs.h tiene métodos NFs :: Exists y NFs :: Copy, si de repente necesitas copiar algo o comprobar que realmente existe algún archivo.

Tenemos nuestros propios contenedores. Pasaron a usar std :: vector hace bastante tiempo, es decir, simplemente heredan de std :: vector, std :: set y std :: map, pero también tenemos nuestro propio THashMap y THashSet, que en parte tienen interfaces compatibles con unordered_map y conjunto_desordenado Pero para algunas tareas resultaron ser más rápidas, por lo que aún las usamos.

Las referencias de matriz son análogas a std :: span de C ++. Es cierto que apareció con nosotros no en el vigésimo año, sino mucho antes. Lo usamos activamente para transferir referencias a matrices, como si estuvieran asignadas en buffers grandes, para no asignar buffers temporales cada vez. Supongamos que, para contar derivados o algunas aproximaciones, podemos asignar memoria en algún búfer grande preasignado y pasar solo TArrayRef a la función de conteo. Es muy conveniente y lo usamos mucho.

Arcadia utiliza su propio conjunto de clases para trabajar con cadenas. Esto es, en primer lugar, TStingBuf, un análogo de str :: string_view de C ++ 17.
TString no es en absoluto std :: sting, es una cadena CopyOnWrite, por lo que debe trabajar con bastante cuidado. Además, TUtf16String es el mismo TString, solo que su tipo base no es char, sino wchar de 16 bits.
Y tenemos herramientas para convertir de cadena en cadena. Este es ToString, que es un análogo de std :: to_string y FromString emparejado con TryFromString, que le permite convertir la cadena en el tipo que necesita.

Tenemos nuestra propia estructura de excepción, la excepción básica en las bibliotecas arcade es yexception, que hereda de std :: exception. Tenemos una macro ythrow que agrega información sobre el lugar donde se produjo la excepción en yexception, es solo un contenedor conveniente.
Hay un análogo de std :: current_exception - CurrentExceptionMessage, esta función arroja la excepción actual como una cadena.
Hay macros para afirmaciones y verificaciones: estas son Y_ASSERT e Y_VERIFY.

Y tenemos nuestra propia serialización incorporada, es binaria y no tiene la intención de transferir datos entre diferentes revisiones. Más bien, esta serialización es necesaria para transferir datos entre dos archivos binarios de la misma revisión, por ejemplo, en el aprendizaje distribuido.
Dio la casualidad de que tenemos dos versiones de serialización en CatBoost. La primera opción funciona a través de los métodos de interfaz Guardar y Cargar, que se serializan en la secuencia. Otra opción se utiliza en nuestra capacitación distribuida, utiliza una biblioteca BinSaver interna bastante antigua, conveniente para serializar objetos polimórficos que deben registrarse en una fábrica especial. Esto es necesario para la capacitación distribuida, de la cual es poco probable que tengamos tiempo para hablar aquí.

También tenemos nuestro propio analógico boost_optional o std :: optional - TMaybe. Análogo de std :: variante - TVariant. Necesitas usarlos.

Existe una cierta convención de que dentro del código CatBoost arrojamos una TCatBoostException en lugar de una yexception. Esta es la misma excepción y, solo se agrega el seguimiento de la pila cuando se lanza.
Y también usamos la macro CB_ENSURE para verificar convenientemente algunas cosas y lanzar excepciones si no se ejecutan. Por ejemplo, a menudo usamos esto para analizar opciones o analizar parámetros pasados por el usuario.

Enlaces de la diapositiva: primero , segundo
Antes de comenzar, le recomendamos que se familiarice con el estilo del código, que consta de dos partes. El primero es un estilo de código arcade general, que se encuentra directamente en la raíz del repositorio en el archivo CPP_STYLE_GUIDE.md. También en la raíz del repositorio hay una guía separada para nuestro equipo: catboost_command_style_guide_extension.md.
Estamos tratando de formatear el código Python usando PEP8. No siempre funciona, porque para el código Cython, la interfaz no funciona para nosotros, y a veces algo sucede con PEP8.

¿Cuáles son las características de nuestro ensamblaje? Originalmente, el ensamblaje de Arcadia tenía como objetivo recopilar las aplicaciones más herméticas, es decir, que habría un mínimo de dependencias externas debido a la vinculación estática. Esto le permite usar el mismo binario en diferentes versiones de Linux sin volver a compilar, lo cual es bastante conveniente. Los objetivos de ensamblaje se describen en los archivos ya.make. Un ejemplo de ya.make se puede ver en la siguiente diapositiva.

Si de repente desea agregar algún tipo de biblioteca, programa u otra cosa, puede, en primer lugar, simplemente mirar los archivos ya.make vecinos y, en segundo lugar, usar este ejemplo. Aquí hemos enumerado los elementos más importantes de ya.make. Al principio del archivo, decimos que queremos declarar una biblioteca, luego enumeramos las unidades de compilación que queremos poner en esta biblioteca. Aquí puede haber archivos cpp y, por ejemplo, archivos pyx para los que Cython se iniciará automáticamente, y luego el compilador. Las dependencias de la biblioteca se enumeran a través de la macro PEERDIR. Simplemente escribe las rutas a la carpeta con la biblioteca o con otro artefacto dentro, en relación con la raíz del repositorio.
Hay una cosa útil, GENERATE_ENUM_SERIALIZATION, necesaria para generar métodos ToString, FromString para clases de enumeración y enumeraciones descritas en algún archivo de encabezado que pase a esta macro.

Ahora sobre lo más importante: cómo compilar y ejecutar algún tipo de prueba. En la raíz del repositorio se encuentra el script ya, que descarga los kits de herramientas y herramientas necesarias, y tiene el comando ya make, el subcomando make, que le permite construir una versión -r con un modificador -d y una versión de depuración con el modificador -d. Los artefactos en él se pasan y se separan por un espacio.
Para construir Python, inmediatamente señalé las banderas aquí que podrían ser útiles. Estamos hablando de construir con el sistema Python, en este caso con Python 3. Si de repente tiene un CUDA Toolkit instalado en su computadora portátil o máquina de desarrollo, entonces para un ensamblaje más rápido, recomendamos especificar el indicador –d have_cuda no. CUDA se desarrolla durante bastante tiempo, especialmente en sistemas de 4 núcleos.

Ya ide ya debería funcionar. Esta es una herramienta que generará una solución clion o qt para usted. Y para aquellos que vinieron con Windows, tenemos una solución de Microsoft Visual Studio, que se encuentra en la carpeta msvs.
Oyente:
- ¿Tienes todas las pruebas a través del envoltorio de Python?
Stas:
- No, tenemos pruebas por separado que se encuentran en la carpeta pytest. Estas son pruebas de nuestra interfaz CLI, es decir, nuestra aplicación. Es cierto que funcionan a través de pytest, es decir, estas son funciones de Python en las que realizamos una llamada de verificación de subproceso y verificamos que el programa no se bloquee y funcione correctamente con algunos parámetros.
Oyente:
- ¿Qué pasa con las pruebas unitarias en C ++?
Stas:
- También tenemos pruebas unitarias en C ++. Por lo general, se encuentran en la carpeta lib en subcarpetas ut. Y están escritos así: prueba unitaria o prueba unitaria para. Hay ejemplos Hay macros especiales para declarar una clase de prueba unitaria y registros separados para la función de prueba unitaria.
Oyente:
- Para verificar que nada se ha roto, ¿es mejor lanzar esos y esos?
Stas:
- si. Lo único es que nuestras pruebas de código abierto son verdes solo en Linux. Por lo tanto, si compila, por ejemplo, en Mac, si fallan cinco pruebas, entonces no hay nada de qué preocuparse. Debido a la diferente implementación del expositor en diferentes plataformas o algunas otras diferencias menores, los resultados pueden ser muy diferentes.

Por ejemplo tomaremos una tarea. Me gustaría mostrar algún ejemplo. Tenemos un archivo con tareas: open_problems.md. Solucionemos el problema №4 de open_problems.md. Se formula de la siguiente manera: si el usuario establece la tasa de aprendizaje en cero, entonces debemos caer de TCatBoostException. Necesita agregar opciones de validación.
Primero, necesitamos crear una rama, clonar nuestra bifurcación, clonar origen, origen pop, ejecutar el origen en nuestra bifurcación y luego crear una rama y comenzar a trabajar en ella.
¿Cómo funcionan las opciones de análisis? Como dije, tenemos una importante carpeta catboost / libs / options donde se almacena el análisis de todas las opciones.

Tenemos todas las opciones almacenadas en el contenedor TOption, lo que nos permite comprender si el usuario ha anulado la opción. Si no fuera así, conserva algún valor predeterminado en sí mismo. En general, CatBoost analiza todas las opciones en forma de un gran diccionario JSON, que durante el análisis se convierte en diccionarios anidados y estructuras anidadas.

De alguna manera descubrimos, por ejemplo, al buscar con grep o leer el código, que tenemos la tasa de aprendizaje en TBoostingOptions. Intentemos escribir código que simplemente agregue CB_ENSURE que nuestra tasa de aprendizaje es más que std :: numeric_limits :: epsilon, que el usuario ha ingresado algo más o menos razonable.

Aquí solo usamos la macro CB_ENSURE, escribimos un código y ahora queremos agregar pruebas.

En este caso, agregamos una prueba en la interfaz de línea de comandos. En la carpeta pytest, tenemos el script test.py, donde ya hay bastantes ejemplos de prueba y puede elegir uno que se parezca a su tarea, copiarlo y cambiar los parámetros para que comience a caer o no, dependiendo de los parámetros que haya pasado. En este caso, simplemente tomamos y creamos un grupo simple de dos líneas. (Llamamos a los grupos de conjuntos de datos en Yandex. Esta es nuestra peculiaridad). Y luego verificamos que nuestro binario realmente cae si pasamos la tasa de aprendizaje 0.0.

También agregamos una prueba a python-package, que se encuentra en atBoost / python-package / ut / medium. También tenemos pruebas grandes y grandes que están relacionadas con pruebas para construir paquetes de ruedas de pitón.

Además tenemos claves para hacer make - -t y -A. -t ejecuta pruebas, -A obliga a todas las pruebas a ejecutarse independientemente de si tienen etiquetas grandes o medianas.
Aquí, por belleza, también utilicé un filtro llamado prueba. Se configura con la opción -F y el nombre de la prueba especificado más adelante, que pueden ser estrellas salvajes. En este caso, utilicé test.py::test_zero_learning_rate*, porque, mirando nuestras pruebas de paquete de Python, verá: casi todas las funciones toman un accesorio de tipo de tarea. Esto es para que, de acuerdo con el código, nuestras pruebas de paquete python tengan el mismo aspecto para el aprendizaje de CPU y GPU y se puedan usar para pruebas de GPU y entrenador de CPU.

Luego, confirme nuestros cambios y póngalos en nuestro repositorio bifurcado. Publicamos la solicitud de grupo. Ya se ha unido, todo está bien.