Durante la sesión de capacitación (mayo-junio y diciembre-enero), los usuarios nos solicitan que verifiquemos préstamos de hasta 500 documentos por minuto. Los documentos vienen en archivos de varios formatos, la complejidad de trabajar con cada uno de ellos es diferente. Para verificar si un documento está prestado, primero debemos extraer su texto del archivo y, al mismo tiempo, tratar con el formato. La tarea es implementar una extracción de alta calidad de medio millar de textos con formato por minuto, mientras que caen con poca frecuencia (o mejor, no caen en absoluto), consumen pocos recursos y no pagan la mitad del presupuesto galáctico para el desarrollo y operación de la creación final.
Sí, sí, por supuesto, sabemos que de tres cosas, de forma rápida, económica y eficiente, debe elegir dos. Pero lo más desagradable es que en nuestro caso no podemos eliminar nada. La pregunta es qué tan bien lo hicimos ...

Fuente de la imagen: Wikipedia
A menudo se nos dice que el destino de las personas depende de la calidad de nuestro trabajo. Por lo tanto, tienes que educar en ti mismo perfeccionistas. Por supuesto, estamos mejorando constantemente la calidad del sistema (en todos los aspectos), ya que los autores sin escrúpulos encuentran nuevas formas de evitarlo. Y espero que esté cerca el día en que la complejidad del engaño, por un lado, y la sensación de satisfacción de un trabajo bien hecho, por otro lado, incite a la gran mayoría de los estudiantes a abandonar su amado deseo de perder el tiempo. Al mismo tiempo, entendemos que el precio del error puede ser el posible sufrimiento de personas inocentes si de repente lo fingimos.
¿Por qué soy yo? Si fuéramos perfeccionistas, nos acercaríamos cuidadosamente a escribir una serie de artículos sobre el trabajo del sistema antiplagio . Formularíamos minuciosamente un plan de publicación para indicar todo de la manera más lógica y esperada para el lector:
- Primero, hablaríamos sobre cómo está estructurado nuestro Sistema (la quinta publicación sobre Habré), y describiríamos las tres etapas principales del procesamiento de un documento cuando se verifica su préstamo:
- Extraiga el texto del documento (¡está aquí!);
- Busque préstamos (las piezas ya están en varios de nuestros artículos );
- Elaboración de un informe sobre el documento (en planes).
- Además, comenzaríamos a dedicar al lector al dispositivo de mecanismos auxiliares interesantes, como la búsqueda de préstamos transferibles ( primer artículo ), la definición de paráfrasis ( cuarto ) y la clasificación temática ( segundo ).
- Y finalmente, llegamos al motor de búsqueda: el índice de herpes zóster ( séptimo artículo ).
Un lector atento debe haber notado que todavía no sufrimos un perfeccionismo excesivo, por lo que es hora de pasar a la primera etapa: extraer texto y formatear documentos. Esto es lo que haremos hoy, en el camino pensando en la fragilidad del ser y en la luz al final del túnel, en la inexistencia de algo ideal y en la búsqueda de la excelencia, en tener un plan y seguirlo y en los compromisos a los que la vida siempre nos inclina.
Al principio era la palabra
Al principio, extrajimos de los documentos solo lo más necesario para verificar su préstamo: el texto de los documentos mismos. Se admitieron los formatos principales: docx, doc, txt, pdf, rtf, html. Luego se agregaron los ppt, pptx, odt, epub, fb2, djvu menos comunes, sin embargo, fue necesario negarse a trabajar con la mayoría de ellos en el futuro . Cada uno de ellos fue procesado a su manera, en algún lugar de una biblioteca separada, en algún lugar de su propio analizador. En promedio, la extracción de texto duró aproximadamente cientos de milisegundos. Parecería que la principal y casi la única dificultad para extraer texto es el "análisis" del formato en sí, lo que es especialmente cierto para los formatos binarios pdf y doc (y la naturaleza propietaria de este último hace que trabajar con él sea aún más problemático). Sin embargo, ya en esta etapa, cuando nuestros deseos se limitaban solo a extraer el texto, quedó claro que cualquier forma de leer los formatos que necesitábamos conlleva una serie de características desagradables. El más significativo de ellos:
- Las excepciones son incluso cuando se procesan algunos documentos válidos, sin mencionar el procesamiento de documentos "rotos" formados incorrectamente. Lo que crea aún más problemas es que el código nativo puede caerse, y manejar tales situaciones en código .net es difícil;
- Consumo de memoria excesivamente alto, que puede dañar tanto los procesos vecinos como el actual que procesa el documento "problemático" (sin memoria en el código administrado o no administrado);
- Procesamiento demasiado largo de un documento, que se ve exacerbado por la falta de mecanismos de cancelación para la mayoría de las bibliotecas, y a veces por la complejidad (léase: casi imposible) de cancelar una llamada de código no administrada desde una administrada;
- "Extracción de texto de documentos". Generar el texto de un documento pdf (y este formato es la clave para nosotros), cuyo análisis ya se ha realizado, en contra de lo esperado, es una tarea no trivial. El hecho es que el formato pdf se desarrolló originalmente principalmente para la presentación electrónica de materiales de impresión. El texto en PDF es un conjunto de bloques de texto ubicados en las páginas de un documento. Además, el bloque puede ser un párrafo de texto o un solo carácter. La tarea de restaurar el texto en su forma original de este conjunto de bloques recae en la biblioteca (código / programa) que lee el documento. Sí, el formato, que comienza con una determinada versión, proporciona la capacidad de especificar el orden de los bloques, pero, desafortunadamente, los documentos con una secuencia marcada de bloques de texto son raros. Por lo tanto, las bibliotecas de lectura de texto en PDF contienen una serie de heurísticas (bueno, aquí es estándar: aprendizaje automático,
bigdata, blockchain , ...) que le permiten restaurar el texto en la forma correcta en un grado u otro, y, como se esperaba, el resultado obtenido difiere de una biblioteca a otra. .

Fuente de la imagen inferior: artículo
Fuente de la imagen superior: Hmm ...
¡Necesito más datos!
Si, para analizar un documento para préstamo, el fondo textual del documento fue suficiente para nosotros, entonces la implementación de una serie de nuevas características es imposible o muy difícil sin extraer datos adicionales del documento. Hoy, además del fondo del texto, también extraemos el formato del documento y renderizamos las imágenes de la página. Utilizamos este último para el reconocimiento óptico de texto ( OCR ), así como para identificar algunos tipos de derivaciones.
El formateo de un documento incluye la disposición geométrica de todas las palabras y caracteres en las páginas, así como el tamaño de fuente de todos los caracteres. Esta información nos permite:
- Muestre maravillosamente el informe de verificación del documento, dibujando los préstamos detectados directamente en el documento original;

- Para determinar los bloques de documentos (página de título, bibliografía ) con mayor precisión y recuperar sus metadatos (autores, título del trabajo, año y lugar de trabajo, etc.);
- Detectar intentos de derivación del sistema.
Para unificar el procesamiento de documentos y un conjunto de datos extraídos, convertimos documentos de todos los formatos admitidos por nosotros a pdf. Por lo tanto, el procedimiento para extraer datos del documento se lleva a cabo en dos etapas:
- Convierte un documento a pdf;
- Extraer datos de pdf.
Convierte a pdf. Selección de biblioteca
Dado que no es tan fácil tomar y convertir un documento a pdf, decidimos no reinventar la rueda y explorar soluciones ya preparadas, eligiendo la más adecuada para nosotros. Fue en 2017.
Criterios para seleccionar candidatos:
- Biblioteca en .net, idealmente .net core y multiplataforma
Spoiler!Como resultado, en ese momento, el ideal era inalcanzable
- Soporte para formatos requeridos - doc, docx, rtf, odf, ppt, pptx
- Estabilidad
- Rendimiento
- Calidad de soporte técnico
- Precio de emisión
Analizamos las soluciones disponibles, seleccionando entre ellas las 6 más adecuadas para nuestras tareas:
MS Word Interop, Neevia Document Converter Pro y DynamicPdf requieren la instalación de MS Office en producción, lo que finalmente podría e irrevocablemente vincularnos con Windows. Por lo tanto, ya no consideramos estas opciones.
Por lo tanto, nos quedan tres candidatos principales, y solo uno de ellos es totalmente compatible con todos los formatos que necesitamos. Bueno, es hora de ver de lo que son capaces.
Para probar las bibliotecas, formamos una muestra de 120 mil documentos de usuarios reales, la proporción de los formatos en los que corresponde aproximadamente a lo que vemos todos los días en producción.
Entonces la primera ronda. Veamos qué proporción de documentos se puede convertir con éxito en bibliotecas pdf en consideración. Con éxito, en nuestro caso, no es lanzar una excepción, cumplir con el tiempo de espera de 3 minutos y devolver un texto no vacío.
Syncfusion se destacó de inmediato, que no solo pudo procesar con éxito la menor cantidad de documentos, sino que también descargó todo el proceso en algunos documentos (generando excepciones como OutOfMemoryException o excepciones del código nativo que no se detectaron sin bailar con una pandereta).
GroupDocs no pudo procesar aproximadamente 5,5 veces más documentos que DevExpress (todo se puede ver en la placa de arriba). Esto a pesar del hecho de que una sola licencia de desarrollador de GroupDocs es aproximadamente 9 veces más costosa que una sola licencia de desarrollador de DevExpress. Esto es así, por cierto.
La segunda prueba seria es el tiempo de conversión, los mismos 120 mil documentos:
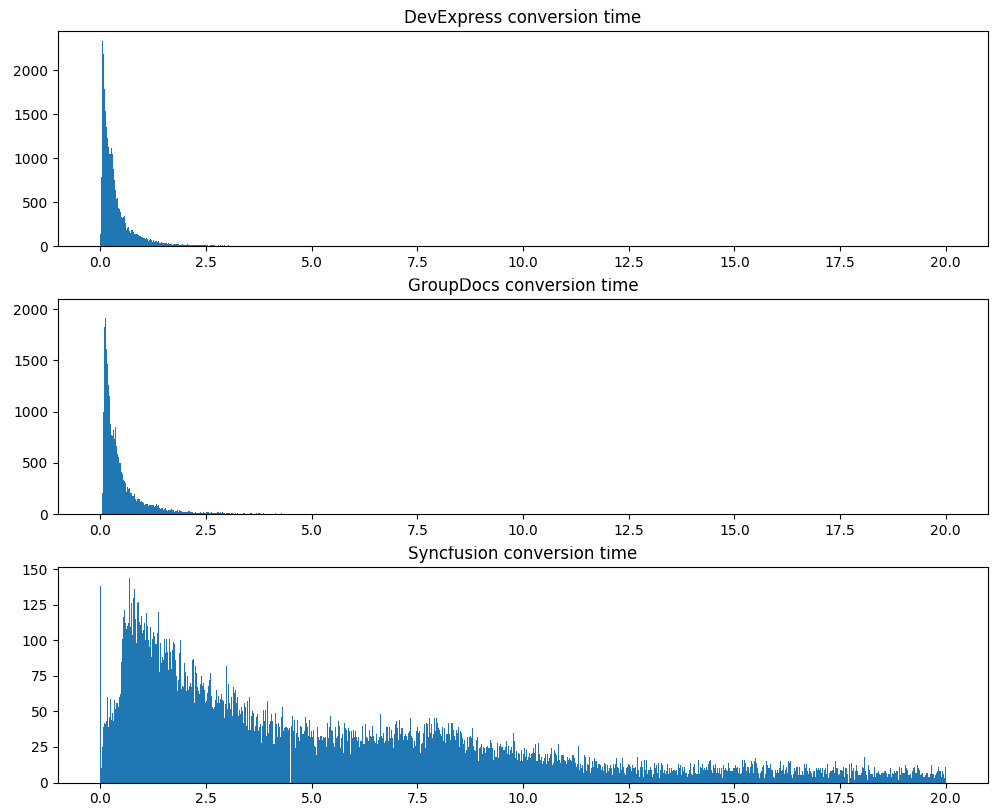
Tenga en cuenta que DevExpress no solo procesa documentos más rápido en promedio, sino que también muestra un tiempo de procesamiento mucho más estable.
Pero la estabilidad y la velocidad de procesamiento no significan nada si el resultado es un pdf incorrecto. ¿Quizás DevExpress se salta la mitad del texto? Lo comprobamos Entonces, los mismos 120 mil documentos, esta vez calcularemos el volumen total del texto extraído y la participación promedio de las palabras del diccionario (mientras más palabras extraídas sean diccionario, menos basura / texto extraído incorrectamente):
En parte, la suposición era correcta. Resultó que GroupDocs, a diferencia de DevExpress, puede trabajar con notas al pie. DevExpress simplemente los omite al convertir un documento a pdf. Por cierto, sí, el texto del pdf'ok recibido en todos los casos se extrae usando DevExpress'a.
Entonces, estudiamos la velocidad y la estabilidad de las bibliotecas en cuestión, ahora evaluamos cuidadosamente la calidad de la conversión de documentos pdf. Para hacer esto, analizaremos no solo el volumen del texto que se extraerá y la proporción de palabras del diccionario, sino que compararemos los textos extraídos de los archivos PDF recibidos con los textos PDF obtenidos con MS Word. Aceptamos el resultado de convertir un documento usando MS Word como pdf de referencia . Se prepararon alrededor de 4.500 pares de " documento, referencia pdf'ka " para esta prueba.
Para cada par " pdf de referencia, resultado de conversión ", calculamos la similitud en la longitud del texto extraído y en las frecuencias de las palabras extraídas. Naturalmente, estas métricas se obtuvieron solo en aquellos casos en que la conversión fue exitosa. Por lo tanto, no consideramos los resultados de Syncfusion aquí. DevExpress y GroupDocs mostraron aproximadamente el mismo rendimiento. En el lado de DevExpress, hay un porcentaje significativamente mayor de conversiones exitosas, en el lado de GD, trabajo correcto con notas al pie.
Dados los resultados, la elección era obvia. Hasta el día de hoy, estamos utilizando la solución de DevExpress y pronto planearemos actualizar a su versión 19.
Hay un pdf, extrae el texto con formato
Entonces, podemos convertir documentos a pdf. Ahora tenemos otra tarea: usar DevExpress para extraer el texto, conociendo cada palabra toda la información que necesitamos. A saber:
- En qué página está la palabra;
- La ubicación de la palabra en la página (enmarcando un rectángulo);
- El tamaño de fuente de la palabra (caracteres de palabras).
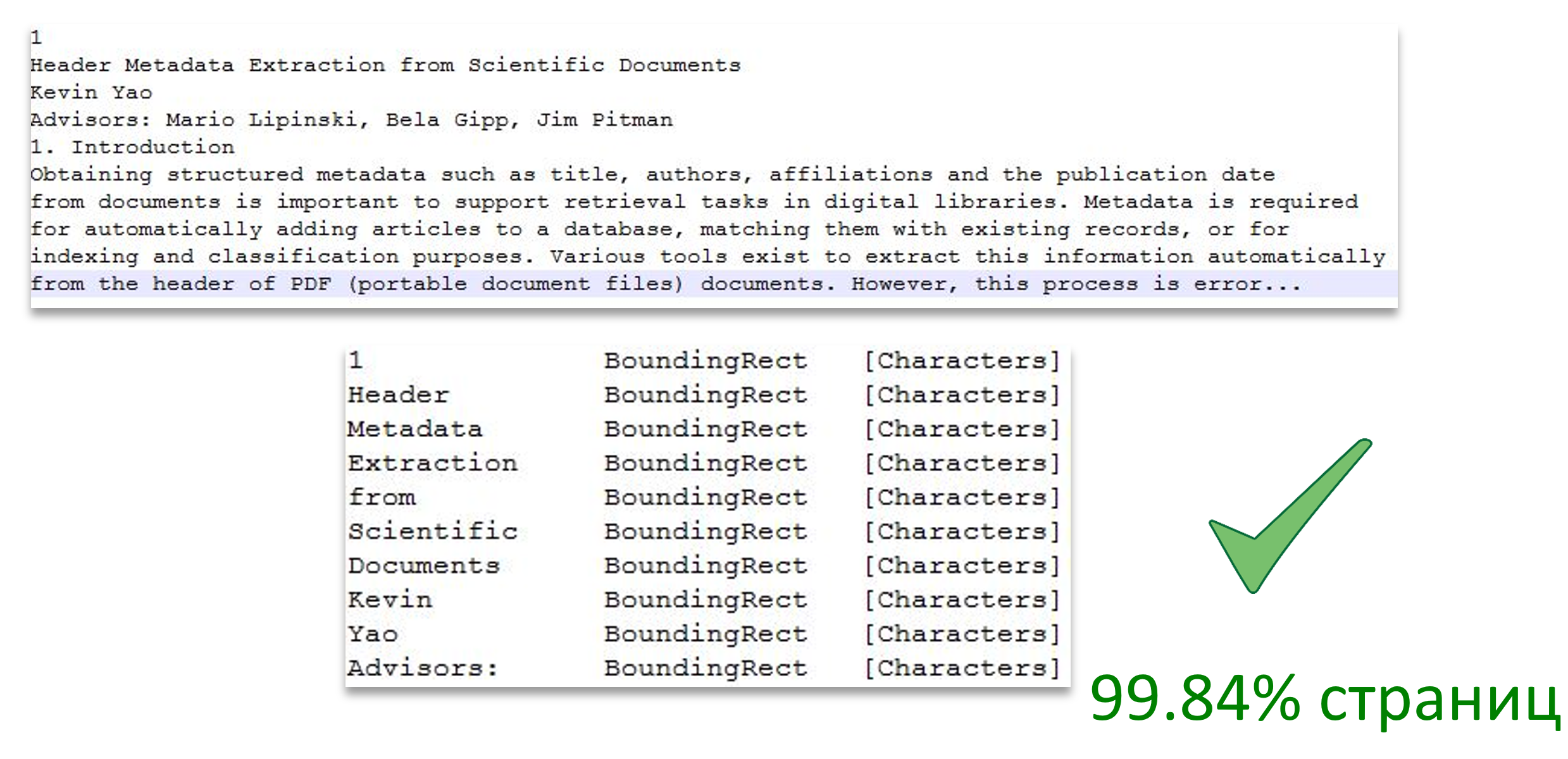
La imagen muestra el desglose del texto en páginas, y también muestra la correspondencia de una palabra de texto con el área de la página.

Fuente de la imagen: Extracción de metadatos de encabezado de documentos científicos
Parece que todo debería ser simple. Miramos lo que API DevExpress nos proporciona:
- Tenemos un método que devuelve el texto de todo el documento. Cadena simple;
- Tenemos la capacidad de iterar de acuerdo con el documento. Por cada palabra podemos obtener:
- Texto de la palabra;
- La página en la que se encuentra la palabra;
- El rectángulo enmarcado de la palabra;
- Información sobre los caracteres individuales de la palabra (el significado del carácter que enmarca el rectángulo, el tamaño de fuente, ...).
Bien, todo parece estar ahí. Solo aquí se explica cómo obtener los datos necesarios para cada palabra en el texto del documento que devuelve DevExpress. Realmente no queremos recopilar el texto del documento a partir de las palabras, ya que, por ejemplo, no tenemos información sobre el espacio entre las palabras y dónde se encuentra el avance de línea. Tendremos que proponer heurísticas basadas en la ubicación de las palabras ... El texto está aquí, antes de nosotros, ya ensamblado.

Fuente de la imagen: Eureka!
La solución obvia es unir las palabras con el texto del documento. Observamos, de hecho, en el texto del documento, las palabras están ordenadas en el mismo orden en que son devueltas por el iterador de acuerdo con las palabras del documento.
Implementamos rápidamente un algoritmo simple para unir palabras con el texto del documento, agregamos controles para que todo coincida correctamente, comenzamos ...
De hecho, todo funciona correctamente en la gran mayoría de las páginas, pero, desafortunadamente, no en todas las páginas.

Fuente de la imagen superior: ¿Estás seguro?
Por parte de los documentos, vemos que las palabras en el texto no están en el orden en que van al iterar sobre las palabras del documento. Además, se puede ver que el corchete de apertura en el texto en la lista de palabras se representa como el corchete de cierre y está en otra "palabra". La visualización correcta de este fragmento de texto se puede ver abriendo el documento en MS Word. Lo que es más interesante, si no convierte el documento a pdf, pero extrae directamente el texto del documento, obtenemos la tercera versión del fragmento de texto que no coincide con el orden correcto ni con los otros dos pedidos recibidos de la biblioteca. En este fragmento, como en la mayoría del resto, en el que surge un problema similar, el punto está en los caracteres invisibles "RTL", que cambian el orden de los caracteres / palabras adyacentes.
Aquí vale la pena recordar que llamamos a la calidad del soporte técnico importante al elegir una biblioteca. Como la práctica ha demostrado, en este aspecto, la interacción con DevExpress es bastante efectiva. El problema con el documento enviado se solucionó rápidamente después de que creamos el ticket correspondiente. También se solucionaron otros problemas relacionados con excepciones / alto consumo de memoria / procesamiento de documentos largos.
Sin embargo, aunque DevExpress no proporciona una forma directa de obtener el texto con la información necesaria para cada palabra, seguimos comparando a veces incomparable. Si no podemos construir una coincidencia exacta entre palabras y texto, usamos una serie de heurísticas que permiten pequeñas permutaciones de palabras. Si nada ayuda, el documento permanece sin formatear. Raramente, pero esto sucede.
Adios :)