Nota perev. : Después de la publicación reciente de material sobre métodos pull y push en GitOps, vimos interés en este modelo en su conjunto, sin embargo, había muy pocas publicaciones en ruso sobre este tema (simplemente no están en el centro). Por lo tanto, nos complace presentarle una traducción de otro artículo, ¡aunque hace casi un año! - de la empresa Weaveworks, cuyo jefe acuñó el término "GitOps". El texto explica la esencia del enfoque y las diferencias clave de los existentes.
Hace un año,
publicamos una
introducción a GitOps . Luego hablamos sobre cómo el equipo de Weaveworks lanzó SaaS basado en Kubernetes y desarrolló un conjunto de mejores prácticas prescriptivas para implementar, administrar y monitorear en un entorno nativo en la nube.
El artículo resultó ser popular. Otras personas comenzaron a hablar sobre GitOps, comenzaron a publicar nuevas herramientas para
git push ,
desarrollo ,
secretos ,
funciones ,
integración continua , etc. Una
gran cantidad de publicaciones y casos de uso de GitOps han aparecido en nuestro sitio. Pero algunas personas todavía tienen preguntas. ¿En qué se diferencia el modelo de la
infraestructura tradicional
como código y entrega continua? ¿Es obligatorio usar Kubernetes?
Pronto, nos dimos cuenta de que se necesitaba una nueva descripción, que ofreciera:
- Una gran cantidad de ejemplos e historias;
- La definición específica de GitOps;
- Comparación con la entrega continua tradicional.
En este artículo, tratamos de cubrir todos estos temas. En él encontrará una introducción actualizada a GitOps y una mirada desde el lado de los desarrolladores y CI / CD. Nos centramos principalmente en Kubernetes, aunque el modelo puede generalizarse.
Conoce a GitOps
Imagina a Alice. Dirige Family Insurance, una compañía que ofrece pólizas de seguro de salud, automóvil, bienes raíces y viajes para personas que están demasiado ocupadas para comprender los matices de sus contratos por su cuenta. Su negocio comenzó como un proyecto paralelo cuando Alice trabajó en el banco como científica de datos. Una vez que se dio cuenta de que podía usar algoritmos informáticos avanzados para analizar de manera más eficiente los datos y formar paquetes de seguros. Los inversores financiaron el proyecto, y ahora su compañía aporta más de $ 20 millones al año y está creciendo rápidamente. Actualmente, 180 personas trabajan en varios puestos en el mismo. Entre ellos, un equipo de tecnología que desarrolla, mantiene un sitio, una base de datos y analiza la base de clientes. Bob, el director técnico de la compañía, dirige un equipo de 60 personas.
El equipo de Bob está implementando sistemas de producción en la nube. Sus principales aplicaciones se ejecutan en GKE, aprovechando Kubernetes en Google Cloud. Además, utilizan varias herramientas para trabajar con datos y análisis en su trabajo.
Family Insurance no iba a usar contenedores, pero estaba infectado con entusiasmo por Docker. Pronto, los expertos de la compañía descubrieron que GKE facilita y facilita la implementación de clústeres para probar nuevas características. Se agregaron Jenkins para CI y Quay para organizar el registro de contenedores, se escribieron scripts para Jenkins que empujan o nuevos contenedores y configuraciones en GKE.
Ha pasado un tiempo Alice y Bob estaban decepcionados con el desempeño del enfoque elegido y su impacto en el negocio. La introducción de contenedores no aumentó la productividad tanto como el equipo esperaba. A veces, los despliegues se rompieron, y no estaba claro si los cambios en el código eran los culpables. También resultó ser difícil rastrear los cambios en las configuraciones. A menudo era necesario crear un nuevo clúster y mover aplicaciones a él, ya que era la forma más fácil de eliminar el desorden en el que se convirtió el sistema. Alice temía que la situación empeorara a medida que se desarrollaba la aplicación (además, se estaba gestando un nuevo proyecto basado en el aprendizaje automático). Bob automatizó la mayor parte del trabajo y no entendió por qué la tubería aún es inestable, no se escala bien y requiere intervención manual de vez en cuando.
Luego se enteraron de GitOps. Esta decisión resultó ser exactamente lo que necesitaban para avanzar con confianza.Alice y Bob han escuchado sobre los flujos de trabajo basados en Git, DevOps e infraestructura como código durante años. La singularidad de GitOps es que aporta una serie de mejores prácticas, categóricas y normativas, para implementar estas ideas en el contexto de Kubernetes. Este tema
se ha planteado repetidamente , incluso
en el blog de Weaveworks .
Family Insurance decide implementar GitOps. La compañía ahora tiene un modelo operativo automatizado compatible con Kubernetes que combina
velocidad con
estabilidad , ya que:
- descubrió que el equipo ha duplicado la productividad y nadie se está volviendo loco;
- dejó de dar servicio a los guiones. En cambio, ahora pueden concentrarse en nuevas características y mejorar los métodos de ingeniería, por ejemplo, introducir despliegues de canarios y mejorar las pruebas;
- proceso de implementación mejorado: ahora rara vez se rompe;
- tuvo la oportunidad de recuperar implementaciones después de fallas parciales sin intervención manual;
- ganó mayor confianza en los sistemas de suministro. Alice y Bob descubrieron que el equipo puede dividirse en grupos que trabajan en microservicios y trabajan en paralelo;
- puede hacer 30-50 cambios en el proyecto todos los días gracias a los esfuerzos de cada grupo y probar nuevas técnicas;
- son fácilmente atraídos por el proyecto por nuevos desarrolladores que tienen la capacidad de lanzar actualizaciones en producción mediante solicitudes de extracción en unas pocas horas;
- fácilmente auditado dentro de SOC2 (para el cumplimiento de los proveedores de servicios con los requisitos para la gestión segura de datos; lea más, por ejemplo, aquí - aprox. traducción) .
Que paso
GitOps son dos cosas:
- Modelo de operación para Kubernetes y cloud native. Proporciona un conjunto de mejores prácticas para implementar, administrar y monitorear clústeres y aplicaciones en contenedores. Definición elegante en una sola diapositiva de Luis Faceira :

- El camino para crear un entorno orientado al desarrollador para administrar aplicaciones. Aplicamos el flujo de trabajo de Git tanto a la explotación como al desarrollo. Tenga en cuenta que esto no se trata solo de Git push, sino de organizar todo el conjunto de herramientas CI / CD y UI / UX.
Algunas palabras sobre Git
Si no está familiarizado con los sistemas de control de versiones y el flujo de trabajo basado en Git, le recomendamos que los estudie. Al principio, trabajar con ramas y solicitudes de extracción puede parecer magia negra, pero los profesionales merecen la pena. Aquí hay un
buen artículo para comenzar.
Cómo funciona Kubernetes
En nuestra historia, Alice y Bob recurrieron a GitOps después de trabajar con Kubernetes por un tiempo. De hecho, GitOps está estrechamente relacionado con Kubernetes: es un modelo operativo para la infraestructura y las aplicaciones basadas en Kubernetes.
¿Qué les da Kubernetes a los usuarios?
Aquí hay algunas características clave:
- En el modelo de Kubernetes, todo se puede describir en forma declarativa.
- El servidor API de Kubernetes acepta dicha declaración como entrada, y luego intenta constantemente llevar el clúster al estado descrito en la declaración.
- Las declaraciones son suficientes para describir y administrar una amplia variedad de cargas de trabajo: "aplicaciones".
- Como resultado, los cambios en la aplicación y el clúster se deben a:
- cambios a las imágenes del contenedor;
- cambios a la especificación declarativa;
- errores en el entorno, por ejemplo, bloqueos de contenedores.
Las grandes habilidades de convergencia de Kubernetes
Cuando un administrador realiza cambios de configuración, el orquestador de Kubernetes los aplicará al clúster hasta que su estado se
acerque a la nueva configuración . Este modelo funciona para cualquier recurso de Kubernetes y se extiende con las Definiciones de recursos personalizadas (CRD). Por lo tanto, las implementaciones de Kubernetes tienen las siguientes propiedades maravillosas:
- Automatización : las actualizaciones de Kubernetes proporcionan un mecanismo para automatizar el proceso de aplicación de cambios de manera correcta y oportuna.
- Convergencia : Kubernetes continuará intentando actualizaciones hasta el éxito.
- Idempotencia : las aplicaciones repetidas de convergencia producen el mismo resultado.
- Determinismo : con suficientes recursos, el estado del clúster actualizado depende solo del estado deseado.
Cómo funciona GitOps
Hemos aprendido lo suficiente sobre Kubernetes para explicar cómo funciona GitOps.
Volvamos a los equipos de Family Insurance relacionados con microservicios. ¿Qué suelen hacer? Mire la lista a continuación (si algún punto parece extraño o desconocido, posponga las críticas y quédese con nosotros). Estos son solo ejemplos de flujos de trabajo basados en Jenkins. Existen muchos otros procesos cuando se trabaja con otras herramientas.
Lo principal es que vemos que cada actualización termina con cambios en los archivos de configuración y repositorios de Git. Estos cambios en Git provocan que la "instrucción GitOps" actualice el clúster:
1. Flujo de trabajo: "
Jenkins Build - rama maestra ".
La lista de tareas:
- Jenkins empuja imágenes etiquetadas en Quay;
- Jenkins push'it config y Helm charts al cubo de almacenamiento maestro;
- La función de nube copia la configuración y los gráficos del depósito de almacenamiento maestro al repositorio git maestro;
- La instrucción GitOps actualiza el clúster.
2.
Jenkins build - lanzamiento o ramificación de revisión :
- Jenkins empuja imágenes sin etiquetar en Quay;
- Jenkins empuja los gráficos de configuración y Helm al depósito de almacenamiento provisional;
- La función en la nube copia la configuración y los gráficos del depósito del almacenamiento provisional en la disposición del repositorio Git;
- La instrucción GitOps actualiza el clúster.
3.
Jenkins build - desarrollar o presentar una rama :
- Jenkins empuja imágenes sin etiquetar en Quay;
- Jenkins empuja los gráficos de configuración y Helm al cubo de almacenamiento de desarrollo;
- La función en la nube copia la configuración y los gráficos desde el depósito de almacenamiento de desarrollo al repositorio de desarrollo de git;
- La instrucción GitOps actualiza el clúster.
4.
Agregar un nuevo cliente :
- Un gerente o administrador (LCM / ops) llama a Gradle para implementar y configurar inicialmente los equilibradores de carga de red (NLB);
- LCM / ops confirma una nueva configuración para preparar la implementación de actualizaciones;
- La instrucción GitOps actualiza el clúster.
Breve descripción de GitOps
- Describa el estado deseado de todo el sistema utilizando especificaciones declarativas para cada entorno (en nuestra historia, el equipo de Bob define la configuración completa del sistema en Git).
- El repositorio de git es la única fuente de verdad sobre el estado deseado de todo el sistema.
- Todos los cambios en el estado deseado se realizan a través de confirmaciones en Git.
- Todos los parámetros deseados del clúster también son observables en el propio clúster. Por lo tanto, podemos determinar si los estados deseados y observados coinciden (convergen, convergen ) o difieren ( divergen , divergen ).
- Si los estados deseados y observados son diferentes, entonces:
- Existe un mecanismo de convergencia que tarde o temprano sincroniza automáticamente los estados objetivo y observado. Dentro del grupo, Kubernetes hace esto.
- El proceso comienza inmediatamente con una notificación de "cambio comprometido".
- Después de un período de tiempo configurable, se puede enviar una alerta de diferencia si los estados son diferentes.
- Por lo tanto, todas las confirmaciones en Git desencadenan actualizaciones verificables e idempotentes en el clúster.
- La reversión es una convergencia a un estado previamente deseado.
- La convergencia es final. Sobre su inicio testificar:
- Falta de alertas "diff" por un cierto período de tiempo.
- Una alerta convergente (por ejemplo, webhook, evento de reescritura de Git).
¿Qué es la divergencia?
Repetimos nuevamente:
todas las propiedades deseadas del clúster deben ser observables en el mismo clúster .
Algunos ejemplos de divergencia:
- Cambio en el archivo de configuración debido a la fusión de ramas en Git.
- Un cambio en el archivo de configuración debido a una confirmación en Git realizada por el cliente GUI.
- Múltiples cambios en el estado deseado debido a PR en Git con el posterior ensamblaje de la imagen del contenedor y cambios en la configuración.
- Cambio de estado del clúster debido a un error, conflicto de recursos que conduce a un "mal comportamiento", o simplemente una desviación accidental del estado original.
¿Qué es un mecanismo de convergencia?
Algunos ejemplos
- Para contenedores y clusters, el mecanismo de convergencia proporciona Kubernetes.
- Se puede usar el mismo mecanismo para administrar aplicaciones y diseños basados en Kubernetes (por ejemplo, Istio y Kubeflow).
- El mecanismo para gestionar la interacción de trabajo entre Kubernetes, repositorios de imágenes y Git lo proporciona el operador Weave Flux GitOps , que forma parte de Weave Cloud .
- Para las máquinas base, el mecanismo de convergencia debe ser declarativo y autónomo. Desde nuestra propia experiencia, podemos decir que Terraform está más cerca de esta definición, pero aún requiere control humano. En este sentido, GitOps extiende la tradición de Infraestructura como Código.
GitOps combina Git con el excelente motor de convergencia de Kubernetes, ofreciendo un modelo para la operación.
GitOps nos permite declarar que
solo aquellos sistemas que pueden describirse y observarse pueden automatizarse y controlarse .
GitOps es para toda la pila nativa de la nube (por ejemplo, Terraform, etc.)
GitOps no es solo Kubernetes. Queremos que todo el sistema se gestione de forma declarativa y que utilice la convergencia. Por todo un sistema nos referimos a un conjunto de entornos que trabajan con Kubernetes, por ejemplo, "dev cluster 1", "production", etc. Cada entorno incluye máquinas, clusters, aplicaciones, así como interfaces para servicios externos que proporcionan datos, monitoreo y etc.
Observe cómo Terraform es importante en este caso para el problema de arranque. Kubernetes necesita implementarse en algún lugar, y el uso de Terraform significa que podemos usar los mismos flujos de trabajo de GitOps para crear la capa de control que subyace a Kubernetes y las aplicaciones. Esta es una buena práctica recomendada.
Se presta mucha atención a la aplicación de conceptos de GitOps a capas sobre Kubernetes. Actualmente existen soluciones de tipo GitOps para Istio, Helm, Ksonnet, OpenFaaS y Kubeflow, así como, por ejemplo, Pulumi, que crean una capa para desarrollar aplicaciones para la nube nativa.
Kubernetes CI / CD: comparación de GitOps con otros enfoques
Como se dijo, GitOps son dos cosas:
- El modelo operativo para Kubernetes y la nube nativa descritos anteriormente.
- El camino para organizar un entorno de gestión de aplicaciones centrado en el desarrollador.
Para muchos, GitOps es principalmente un flujo de trabajo basado en Git push. A nosotros también nos gusta. Pero esto no es todo: veamos ahora las canalizaciones de CI / CD.
GitOps proporciona implementación continua (CD) para Kubernetes
GitOps ofrece un mecanismo de implementación continua que elimina la necesidad de "sistemas de administración de implementación" separados. Kubernetes hace todo el trabajo por ti.
- La actualización de la aplicación requiere una actualización en Git. Esta es una actualización transaccional al estado deseado. El "despliegue" se lleva a cabo dentro del clúster por Kubernetes basado en una descripción actualizada.
- Debido a los detalles de Kubernetes, estas actualizaciones son convergentes. Esto proporciona un mecanismo para la implementación continua en la que todas las actualizaciones son atómicas.
- Nota: Weave Cloud ofrece un operador GitOps que integra Git y Kubernetes y le permite ejecutar un CD haciendo coincidir el estado deseado y actual del clúster.
Sin kubectl y scripts
Evite usar Kubectl para actualizar el clúster, y especialmente los scripts para agrupar comandos de kubectl. En cambio, con una canalización de GitOps, un usuario puede actualizar su clúster de Kubernetes a través de Git.
Los beneficios incluyen:
- Corrección Se puede aplicar, converger y finalmente validar un grupo de actualizaciones, lo que nos acerca al objetivo del despliegue atómico. Por el contrario, el uso de scripts no ofrece ninguna garantía de convergencia (más sobre esto a continuación).
- Seguridad Citando a Kelsey Hightower: "Limite el acceso al clúster de Kubernetes a las herramientas de automatización y a los administradores responsables de la depuración o el mantenimiento". Consulte también mi publicación sobre seguridad y cumplimiento, así como un artículo sobre la piratería de Homebrew robando credenciales de un script Jenkins escrito descuidadamente.
- Experiencia del usuario Kubectl expone la mecánica del modelo de objetos de Kubernetes, que es bastante complejo. Idealmente, los usuarios deberían interactuar con el sistema a un nivel más alto de abstracción. Aquí nuevamente me referiré a Kelsey y recomendaré mirar tal currículum .
La diferencia entre CI y CD
GitOps mejora los modelos existentes de CI / CD.
El servidor CI moderno es un instrumento para la orquestación. En particular, es un instrumento para orquestar tuberías de CI. Incluyen compilación, prueba, fusión a troncal, etc. Los servidores CI automatizan la gestión de tuberías complejas de varios pasos. Una tentación común es crear un script para el conjunto de actualizaciones de Kubernetes y ejecutarlo como un elemento de canalización para impulsar los cambios en el clúster. De hecho, esto es lo que hacen muchos expertos. Sin embargo, esto no es óptimo, y he aquí por qué.
CI debe usarse para realizar actualizaciones en el enlace troncal, y el clúster de Kubernetes debe cambiarse en función de estas actualizaciones para poder administrar el CD "internamente". Llamamos a esto el
modelo pull para el CD , a diferencia del modelo push de CI. El CD es parte de una
orquestación de tiempo de
ejecución .
Por qué los servidores CI no deberían hacer CD a través de actualizaciones directas en Kubernetes
No utilice el servidor de CI para organizar actualizaciones directas en Kubernetes como un conjunto de tareas de CI. Este es el antipatrón del que ya hablamos en nuestro blog.Volvamos a Alice y Bob.
¿Qué problemas encontraron? El servidor CI de Bob aplica los cambios al clúster, pero si cae en el proceso, Bob no sabrá en qué estado está (o debería estar) el clúster y cómo solucionarlo. Lo mismo es cierto si tiene éxito.
Supongamos que el equipo de Bob creó una nueva imagen y luego parcheó sus implementaciones para implementar la imagen (todo desde el canal de CI).
Si la imagen se construye normalmente, pero la tubería se cae, el equipo tendrá que averiguar:
- ¿Se ha implementado la actualización?
- ¿Estamos comenzando una nueva construcción? — ?
- , ?
- ? ( )?
Git' , . - push' , - ; --., CI- CD:
Helm'e: Helm, GitOps-, Flux-Helm . . Helm , .GitOps Continuous Delivery Kubernetes
GitOps , , . , , . , , GitOps .
Kubernetes
. Git :
- , Git .
- Runtime GitOps, . Git .
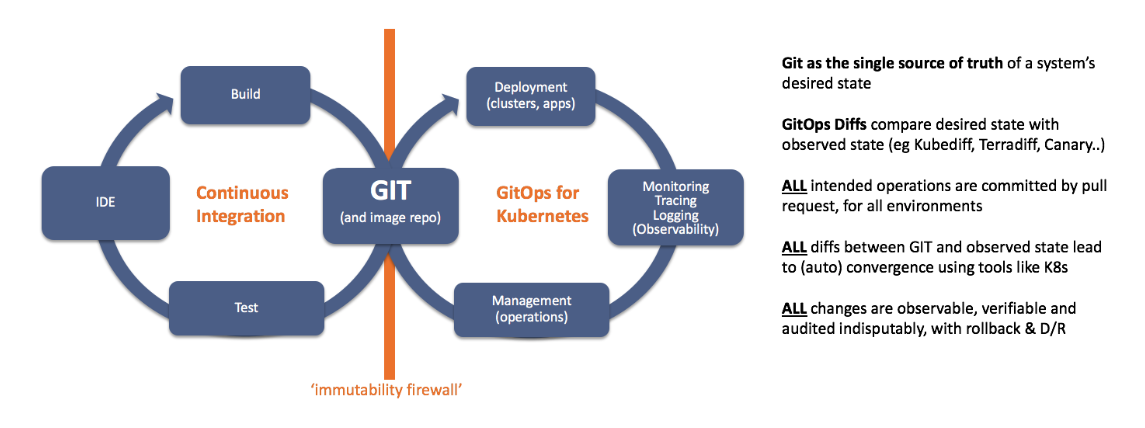
?
- : , , Git . , CI runtime-. « » (immutability firewall) , . 72-87 .
- CI- Git- : GitOps . CI- Git-, . Continuous Delivery CI-/Git- . cloud native. GitOps .
- : Git , Weave Flux ( Weave Cloud) runtime. , Kubernetes , Git . GitOps, .

Conclusión
GitOps , CI/CD:
, cloud native.
- , runbook' ( — . .) , deployment'.
- cloud native- , .
, . GitOps - .
PD del traductor
Lea también en nuestro blog: