En los últimos 3 años, más de mil incidentes de diversos grados de épica ocurrieron en Contour. Las razones son diferentes: por ejemplo, el 36% es causado por una liberación de baja calidad y el 14%, debido al mantenimiento de hierro en el centro de datos. ¿De dónde vienen las estadísticas? Después de cada incidente, se escribe un informe - post mortem. Están escritos por los ingenieros de servicio que respondieron a la notificación del accidente y fueron los primeros en comprender sus causas. Las autopsias se analizan, identifican y eliminan las causas de los incidentes, de modo que en el futuro no se produzcan. Pero ese no fue siempre el caso.
Alexey Kirpichnikov (
BeeVee ) ha estado programando en Yandex desde 2008. Los embotellamientos, trabajé en proyectos deportivos especiales, fue el líder del equipo del backend Yandex.Taxi. Desde 2014, se ha dedicado a DevOps e infraestructura en
Kontur ; ha estado desarrollando herramientas que facilitan la vida de los desarrolladores de los equipos de productos. La idea de escribir y analizar temas post-mortem apareció hace cinco años, y durante este tiempo los temas post-mortem estaban cubiertos de plantillas, un glosario, notas, capturas de pantalla y análisis. Pero esto no es lo más difícil:
fue más difícil superar la inercia, los temores y la incomprensión del significado de los informes de incidentes entre los ingenieros . Lo que finalmente sucedió y el beneficio irreparable que puede hacer la "analítica del sofá" es descifrar el informe de Alexey.
 Tenga en cuenta: debajo de las patas de la mesa de diferentes longitudes hay libros "Métricas", "Pruebas" y "Implementar".
Tenga en cuenta: debajo de las patas de la mesa de diferentes longitudes hay libros "Métricas", "Pruebas" y "Implementar".En Kontur, después de contratar, entregan un conjunto de recuerdos: un bolígrafo, una taza, un cuaderno. Llegué a SKB Kontur a un nuevo equipo de infraestructura hace 5 años, cuando la compañía cumplió 25 años.

El contorno de aquellos tiempos, y ahora también, es una compañía de productos en la que varias docenas de productos desarrollaron el mismo número de equipos, independientes entre sí en cuanto a la elección de tecnologías y herramientas.
En ese momento, leí por primera vez “Proyecto '' Phoenix ''” y me inspiré en las ideas novedosas de las prácticas DevOps. Comencé a escribir mis ideas para mejoras en un cuaderno, y ahora es un artefacto con manchas de café y registros históricos.
- “ ¡Monitoreo! Pongamos Grafana, recopilemos métricas y creemos gráficos. Entenderemos mejor lo que está sucediendo en la producción ". Para 2014, esta es una idea bastante nueva, fresca y una práctica sólida de DevOps ”.
- "¡ Choque automático!" ¿Cuántos archivos zip se pueden cargar en la carpeta compartida, descomprimirlos en el servidor y ejecutar exe en el programador de tareas en Windows? "¡Presentemos un sistema de implementación industrial y publiquemos versiones a través de él, CI!"
- “¡ Post-mortem ! Si hay algún tipo de accidente en la producción, averigüemos cuál fue, encontremos la razón, escribamos un informe y cambiemos nuestros procesos de desarrollo, pruebas y CI para que no haya tales incidentes en el futuro ”
Durante 5 años hemos dado un paso adelante en todas estas áreas. Tenemos nuestro propio sistema de alerta
Moira , sistema de orquestación de aplicaciones y un montón de herramientas. Pero de todo lo anterior,
escribir informes de incidentes resultó ser la práctica de ingeniería más difícil de implementar . Los ingenieros adoran todo tipo de herramientas: fijan algún tipo de sistema de alojamiento o CI, escriben algo, automatizan y no les gusta escribir informes, aunque esta práctica es de gran utilidad.
Le diré cómo implementamos los sistemas post-mortem y qué beneficios obtenemos. Quizás nuestro rastrillo ayudará a avanzar más rápido y llenar menos conos. Antes de comenzar a hablar sobre la autopsia, entenderemos la definición.
¿Qué es un incidente?
¿Cuál de estos es el incidente?
- Ejemplo no 1. En una plataforma de blog con un millón de usuarios, como resultado de algún tipo de error, se pierden todas las entradas de un usuario.
- Ejemplo No. 2. El servicio para empleados de oficina funciona de lunes a viernes de 9 a 6, y en otras ocasiones no hay usuarios. El servicio no estuvo disponible en la noche del sábado al domingo durante dos horas consecutivas, nadie lo notó.
- Ejemplo no 3. Grafana con métricas de producción cayó 15 minutos. En producción, nada se rompió, pero los gráficos no estaban disponibles.
Para entender qué pasa con este fakapy, recurrimos a la experiencia de los gurús: Google, Atlassian, PagerDuty. Los gurús saben cómo preparar turnos, ingenieros de guardia y cómo escribir informes para comprenderlos. Sus guías en línea tienen definiciones de incidentes.
Definición de PagerDuty.
Un incidente es cualquier interrupción o degradación no planificada de un servicio que afecta la disponibilidad del servicio para los usuarios. Un incidente grave es aquel que requiere una respuesta coordinada de varios equipos.
Suena lógico, pero la definición es vaga. En la práctica, ayuda poco entender qué es un incidente y qué no.
El libro de
Ingeniería de confiabilidad del
sitio de Google tiene criterios claros:
- Los usuarios notaron la degradación del servicio.
- Cualquier información se perdió.
- Tomó la intervención del ingeniero de servicio, por ejemplo, para revertir manualmente la liberación.
- Resolver el problema tomó demasiado tiempo. Si un problema se resolvió en 2 horas, y luego se pasó una semana en él, este es un incidente que requiere investigación.
- El monitoreo no funcionó. Por ejemplo, aprendiste sobre un problema de los usuarios.
Contour no tiene una definición publicada de fakap, pero hemos formulado nuestros propios criterios para determinar qué constituye un incidente.
Los usuarios externos o internos han notado una degradación del servicio . Ejemplo No. 3 con Grafana, que yace, es un incidente claro. La producción no se interrumpió y los usuarios externos no lo notaron, pero a pesar de esto, para Contour es un fakap, ya que las herramientas internas no funcionaron.
Suerte En el ejemplo No. 2, el servicio para los trabajadores de oficina permaneció durante 2 horas por la noche; fue una suerte que cayera por la noche. La próxima vez, puede ser desafortunado y, por lo tanto, el incidente nocturno también requiere juicio, como si sucediera durante el día.
El incidente concierne a varios equipos . Tomamos esta definición de PagerDuty. Analizar un incidente es una buena razón para que varios equipos trabajen juntos. La cultura "Por nuestra parte, la bala salió volando, pero algo se rompió para ti, es tu culpa" es erradicada por un análisis conjunto.
Al menos un ingeniero considera esto un incidente . La definición más vaga, pero también la más importante. Una regla simple: si el ingeniero cree que vale la pena el informe, entonces vale la pena el informe. Si te asusta que los ingenieros empiecen a escribir informes para alguien y llamen a cualquier pequeña cosa un accidente, esto no es así.
Los ingenieros son personas razonables, confía en ellos.Con la definición y los diferentes tipos de daños resueltos. Pasemos a cómo beneficiarnos de los incidentes.
¿De qué sirve fakap?
Las sencillas instrucciones que te daré más adelante, puedes solicitarlas por ti mismo, sin siquiera pasar por el artículo hasta el final. Pero aún así leer hasta el final.
Instrucción clásica
Encuentra a los culpables primero. Luego haga el trabajo "educativo" con los ingenieros.
- Pide tener más cuidado la próxima vez.
- Si no ayuda, envíelo a cursos de reciclaje. Quizás aprendan a ser más cuidadosos allí.
- Si esto no ayuda, elimine a los perpetradores de trabajar con partes críticas del sistema. Deje de permitir que los desarrolladores entren en producción si lo arruinan.
- Si nada ayuda, despide a los malos y contrata a los competentes.
Si la instrucción te molesta, esta es una buena noticia.
Este enfoque se considera tradicional para las corporaciones clásicas orientadas verticalmente con un jefe que regaña a todos y puede despedirlo. Una de las bases del movimiento DevOps y la ideología de DevOps es la salida de las organizaciones integradas verticalmente a las horizontales, con mayor confianza en los empleados.
Ilustraré este cambio de paradigma con
instrucciones de John Alspaw, uno de los líderes del movimiento DevOps, que anteriormente trabajó para CTO en Etsy. La instrucción está tomada de su artículo canónico de 2013, Blameless Post Mortem and a Just Culture.
Pregunta a los ingenieros:
- qué eventos observaron;
- cuándo y qué acciones se tomaron;
- qué resultado se esperaba de estas acciones;
- de qué supuestos provienen;
- tal como se entiende por la secuencia de eventos que ocurrieron.
Se debe preguntar a los ingenieros sin amenaza de castigo.
Esto es lo principal en la recomendación de John.
La amenaza del castigo: el reciclaje, la eliminación de la producción o el despido motivan a las personas a mentir. Y la verdad es importante para nosotros. Informe de incidentes: este es el vínculo de retroalimentación que falta en el proceso de desarrollo y puesta en funcionamiento de las funciones.
En el viejo paradigma, los desarrolladores desarrollaron, arrojaron la nave por encima de la cerca a los ingenieros de operaciones, y de alguna manera intentan que funcione. Les molesta cualquier actualización, porque puede romperlo todo, y los ingenieros comenzaron todo con tanta dificultad.
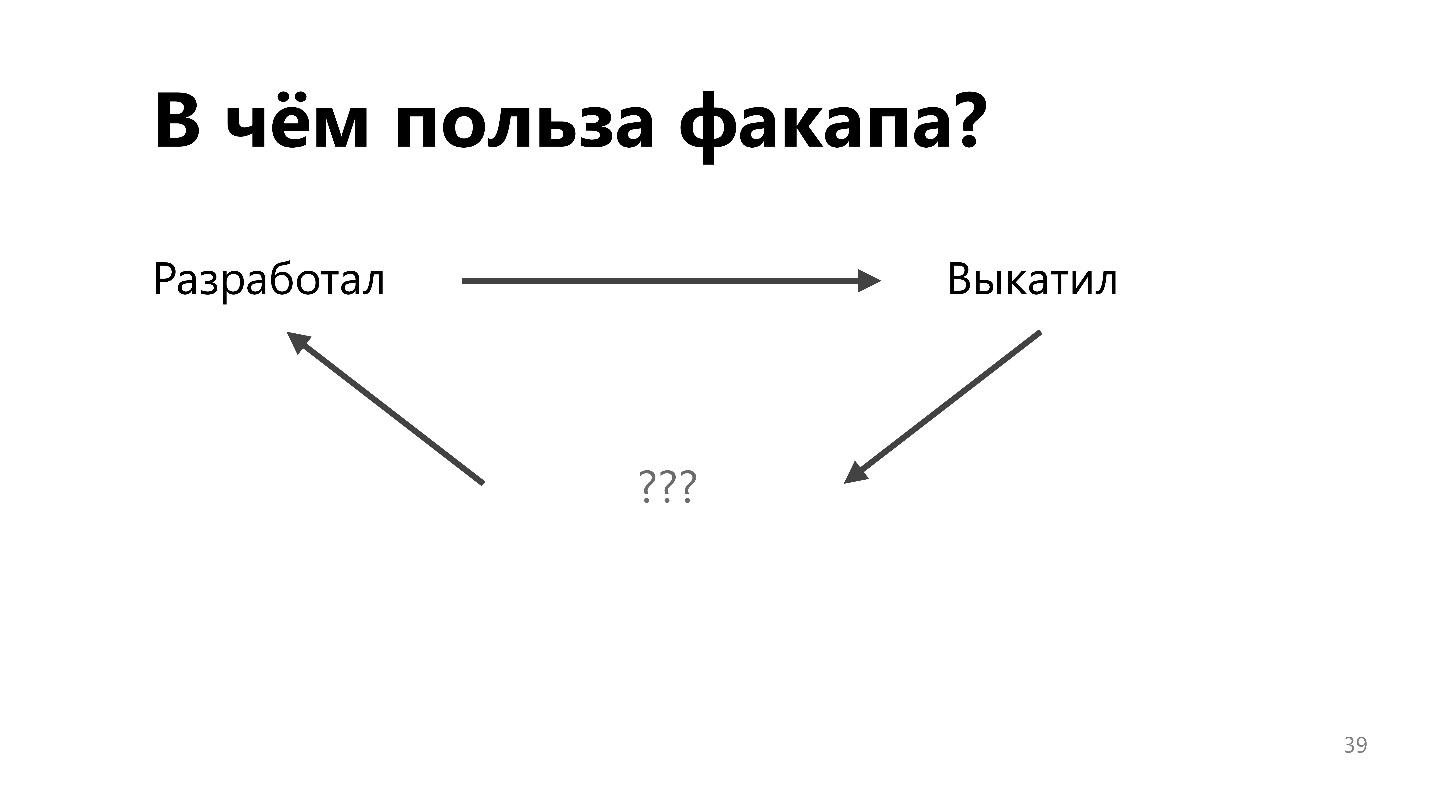
El proceso de retroalimentación ayuda a cambiar el proceso, la infraestructura, las herramientas y el enfoque de desarrollo para que haya menos fallas en la producción.
Esto convencerá a los líderes de equipo y gerentes de desarrollo de la utilidad de la autopsia. Pero el problema es que es difícil lograr que los ingenieros hagan lo que piensan que no tiene sentido e inútil. Tenemos una cultura de ingeniería en nuestra empresa, y no puedo ir, saludar el decreto del CEO y exigir que todos escriban post mortem. Necesito convencer a los ingenieros de esto.
¿Cómo "vender" la idea de ingenieros post mortem a ingenieros? Para sortear las objeciones, mostrar por qué la autopsia es genial, demostrar el beneficio de los informes, que esto no es solo una cancelación de suscripción, si solo el jefe está detrás.
Objeción No. 1: Una vez
Este es el primer problema del ingeniero que desmonta el fakap: la guerra terminará, ¡entonces hablaremos! Cuando ocurre un fakap, quiero solucionarlo rápidamente, pero no quiero escribir informes incomprensibles y aburridos.
Para resolver el problema, hay un truco de vida, cómo escribir algo correctamente durante un accidente. Fue popularizado por Artemy Lebedev:
"Hay una manera simple de organizar el tiempo: el método" jeepeg progresivo ". En cualquier momento, cualquier proyecto está 100% listo, aunque puede estar un 4% más desarrollado. Dependiendo del tiempo disponible, el proyecto se puede calcular hasta un píxel, o se puede dejar en la etapa de dibujo conceptual ".
Ilustraré el método progresivo de jeepeg usando una imagen. En una Internet lenta, una imagen no se descarga inmediatamente, sino por etapas.

Durante un incendio, no necesita escribir un informe fresco y largo. Es suficiente para ti en la esquina superior izquierda. Es suficiente marcar esas cosas que serán difíciles de recuperar de la memoria. No intente escribir un texto literario coherente en un momento en que todo se rompe en la producción.
Realice una acción simple: escriba la cronología de los eventos.
Cronograma
La línea de tiempo es muy difícil de restaurar, si no se registra de inmediato. Un ejemplo de una grabación de una autopsia real en el circuito.
15.01.18 17:25 YEKT PrefixSearch 50 . , .
Esta es una observación corta y simple con sello de tiempo. Según esta cronología, más tarde es fácil restaurar la secuencia de eventos y encontrar la causa del colapso. Pero si no registra nada directamente durante un incendio, será difícil o imposible restaurar los eventos más adelante.
Capturas de pantalla
Una cosa útil, especialmente cuando se trabaja con un sitio web o una aplicación de escritorio. La situación a veces es difícil de describir con palabras, y una captura de pantalla es solo un clic de una tecla de acceso rápido.
La primera objeción funcionó. Al registrar información mínima, un pequeño informe durante el incidente no es difícil y no requiere tiempo valioso. Cuando todo termina, debe completarse y ejecutarse en un documento comprensible y coherente.
Objeción No. 2: Pereza
No dormiste durante dos días y arreglaste un accidente grave, quedando muy rezagado en todas las tareas que ibas a realizar esta semana. Pero resulta que hay que hacer algo más, ¡pero el fuego ya se ha extinguido! En este momento, la pereza inimaginable se pone al día.
Para vencer por completo el problema no funcionará. Pero puede facilitar su trabajo por adelantado.
Patrón
Este es el primero y más importante. Existe un gran temor a un documento vacío que debe completarse con texto significativo. Es mucho más fácil si la plantilla está preparada. Por lo general, consta de secciones y preguntas en ellos. Ingresamos las respuestas a las preguntas en cada sección, y la plantilla se completa.
Las plantillas de informes de incidentes son grandes. Lea sobre ellos en detalle con el gurú. Todos los documentos y libros a los que me refiero contienen patrones de incidentes que utilizan las empresas. En nuestra experiencia, puedo agregar lo siguiente.
Crea una nota con ejemplos
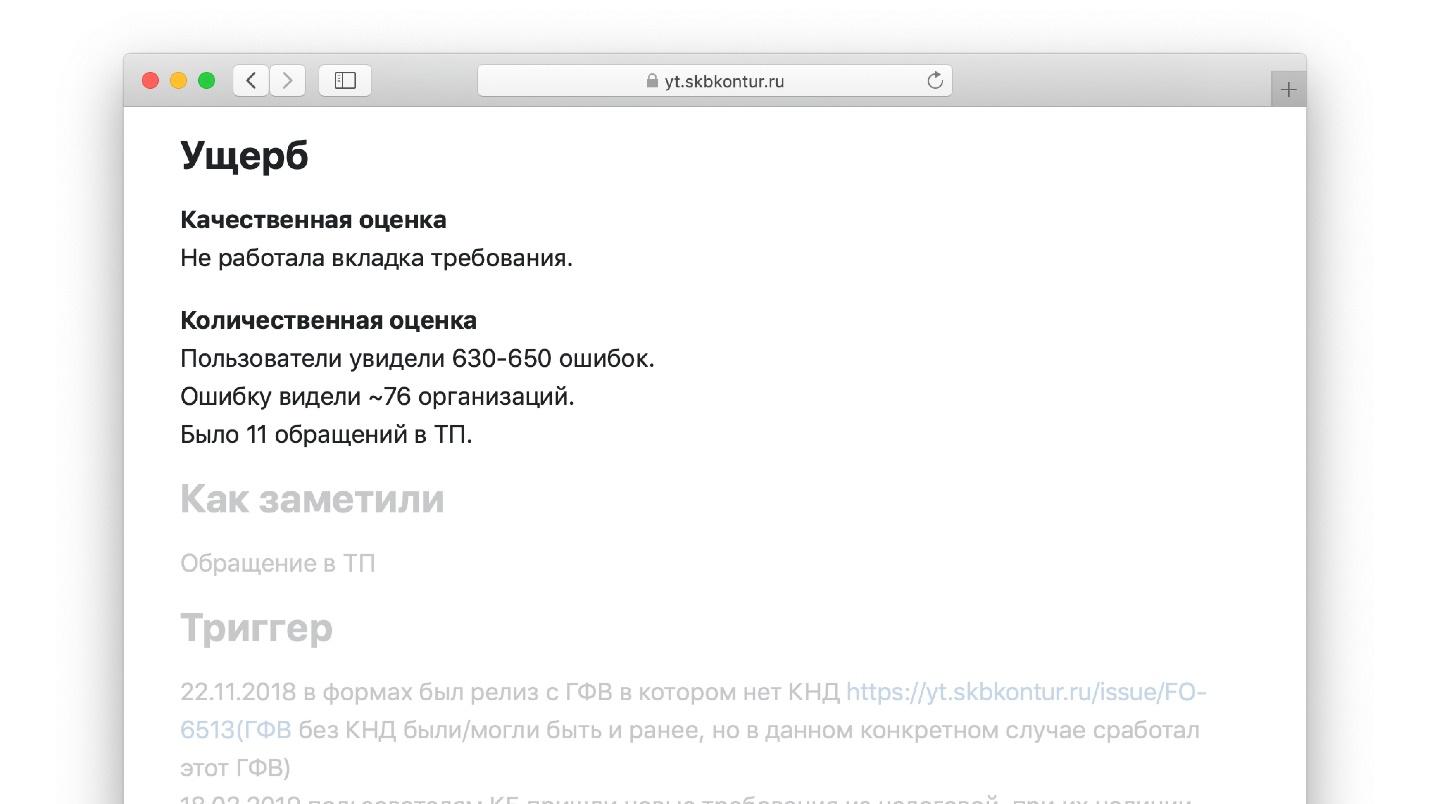
Nuestra plantilla tiene una sección de "Daño" con subsecciones.
Sección "Evaluación cualitativa". Describe lo que el ingeniero ve frente a él cuando llena esta parte de la plantilla:
- qué funcionalidad no funcionó, cuánto tiempo y para quién;
- si hubo una pérdida o corrupción de datos.
Al llegar a este lugar en la plantilla, el ingeniero escribe: "Hay un millón de usuarios en nuestra plataforma de blog, perdimos todas las entradas de uno de ellos". Esto es mucho más fácil que escribir un ensayo desde cero, como en una lección de literatura.
Sección "Cuantificación":- cuántas solicitudes han desaparecido;
- cuánta latencia ha crecido en las métricas de aplicaciones y aplicaciones de clientes;
- cuántas llamadas se pierden;
- El tamaño de la cola para el soporte técnico del usuario para el problema.
Un conjunto de tales preguntas es el patrón.
Un ejemplo de una de las plantillas completadas.
Agregar un glosario
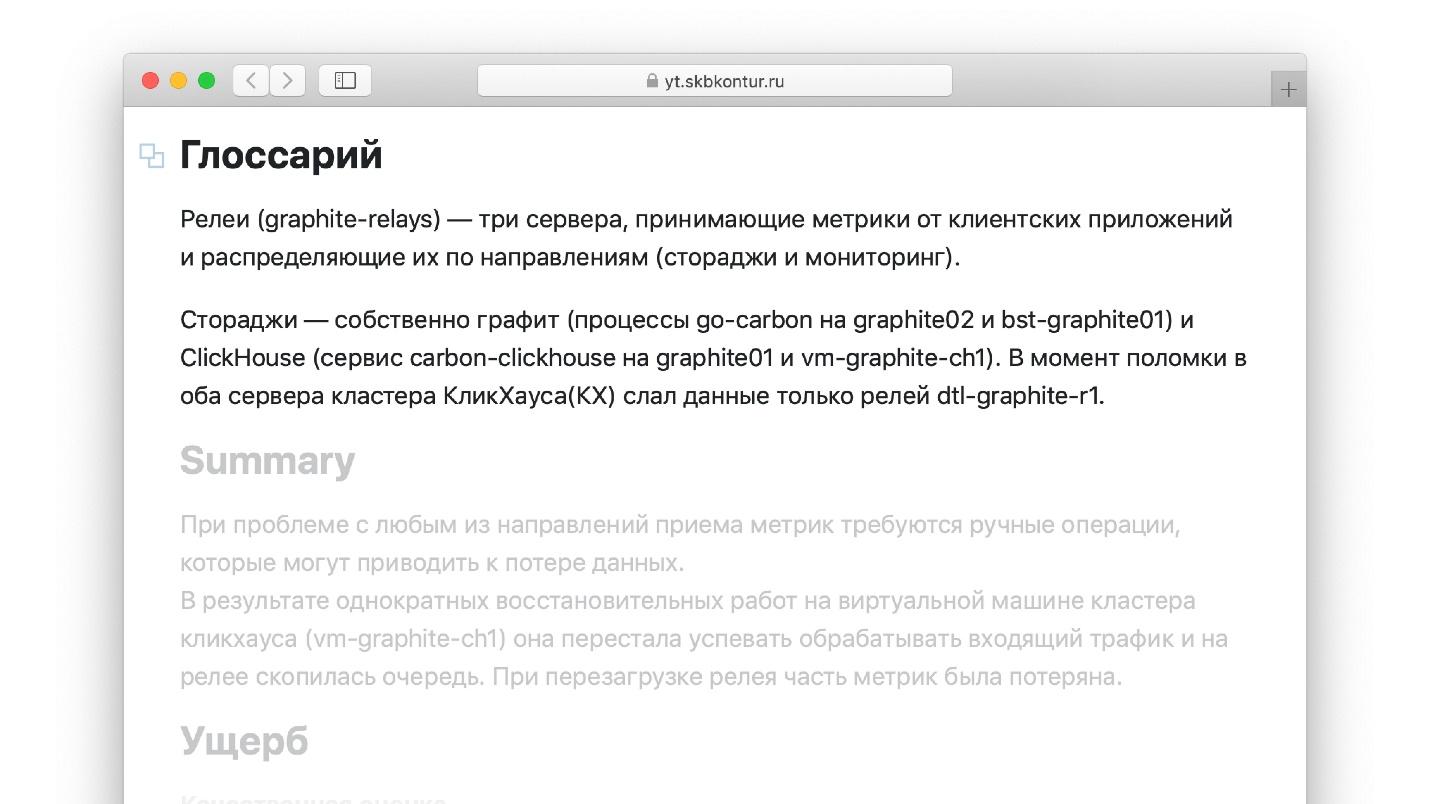
Otro truco de vida para informes de accidentes, que no vi en el libro con el gurú. Al escribir un informe, es conveniente utilizar términos que conozca bien. Por ejemplo, si trabajo con Graphite, en el que se almacenan las métricas, sé muy bien qué es "retransmisión". Pero el ingeniero que leerá el informe en un año puede no estar familiarizado con el término. Es poco probable que pueda leer el informe, que consiste en palabras desconocidas. Por otro lado, si cada término y definición se mastica constantemente dentro del informe, la pereza simplemente lo asustará y el informe no se completará.
Escriba un pequeño glosario que describa todos los términos utilizados en el informe.
Copia todos los artefactos
Si adjunta artefactos al informe: instantáneas en Grafana, el historial de mensajes en el chat, en el que se analizó el incidente con otros ingenieros, haga copias. Las métricas tienen la capacidad de "pudrirse" y los chats cambian. Hace un año estabas en Slack, ahora en Telegram: el enlace de chat está desactualizado y no funciona, y las métricas de retención se caerán, se almacenan durante un año.
Copie artefactos: este truco de vida facilita la tarea de completar informes.
Objeción No. 3: Nadie leerá
La pregunta más grande e incomprensible que hacen los ingenieros es: "¿Quién leerá estos informes?" Supongamos que vencí la pereza y escribí una cronología de los acontecimientos durante el accidente. Luego reunió fuerzas y agregó un informe de varias páginas sobre lo que sucedió y las causas del accidente. Pero si no se comprende quién leerá todo esto y quién se beneficiará, entonces no hay deseo de completar informes.
La autopsia es una retroalimentación en el proceso de mejora continua de los procesos de desarrollo.
En cualquier libro de gurú, por ejemplo, en el
Manual de incidentes de Atlassian , está escrito que de acuerdo con los resultados de cada autopsia, se requiere:
- formular tareas en desarrollo;
- cree tareas en el rastreador de errores desde el cual las tomarán sus desarrolladores;
- poner enlaces de post-mortem a estas tareas.
La retroalimentación está cerrada : aquí hay una autopsia, aquí hay
elementos de acción : tareas que deben completarse para que el accidente no vuelva a suceder. Las tareas caen en el trabajo atrasado del equipo, el equipo las desarrolla, despliega, nuevamente el fakap y la autopsia. La rueda del samsara se ha cerrado.
En esto convergen todos los gurús. No hay nada que discutir: los beneficios son obvios.
Un ejemplo de tareas de elementos de acción de una autopsia real.
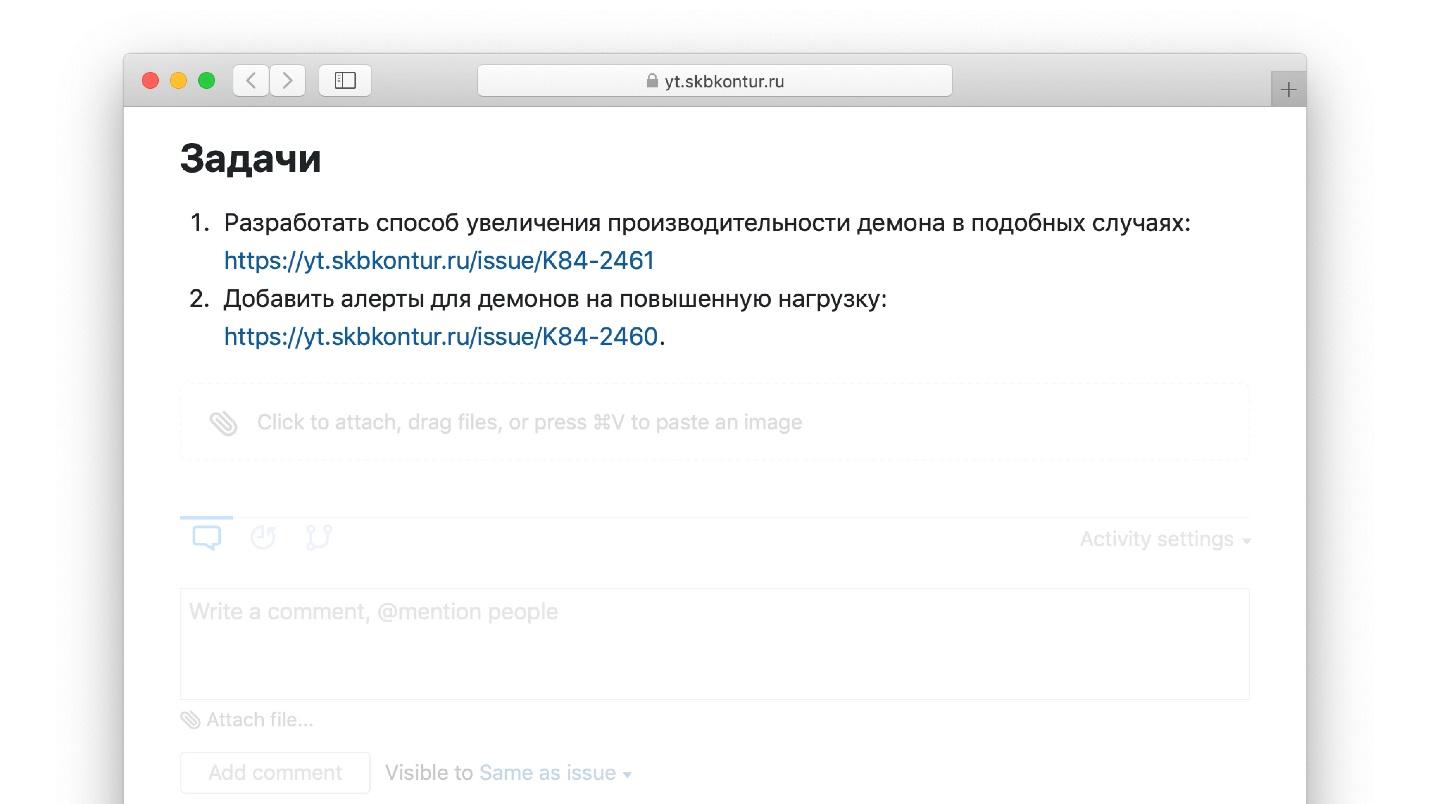
Pero nosotros en Kontur agregamos un analista a esto.
Analítica de sofás
Solíamos analizar el incidente de forma aislada. El fallo se produjo por sí solo en un equipo, en un sistema de alojamiento; algo se rompió, lo arreglamos.
Pero hay muchos incidentes. En los últimos tres años, se han acumulado más de 1,000 informes de incidentes en el circuito. Me gustaría saber si es posible beneficiarse de toda la masa de informes acumulados, y no solo de cada uno individualmente. ¿Es posible sobre la base de calcular las estadísticas del sistema y ver qué mejorar en el sistema en su conjunto.
Un equipo de infraestructura especial trabaja en Kontur, que se dedica al análisis post-mortem y publica los resultados y conclusiones basados en la masa total de informes acumulados. Llamamos a esto "análisis de sofá". Daré fragmentos de uno de los artículos del equipo, que se publica en nuestra red interna para empleados.
¿Qué analizamos en el análisis de sofás?
Duración de Fakap
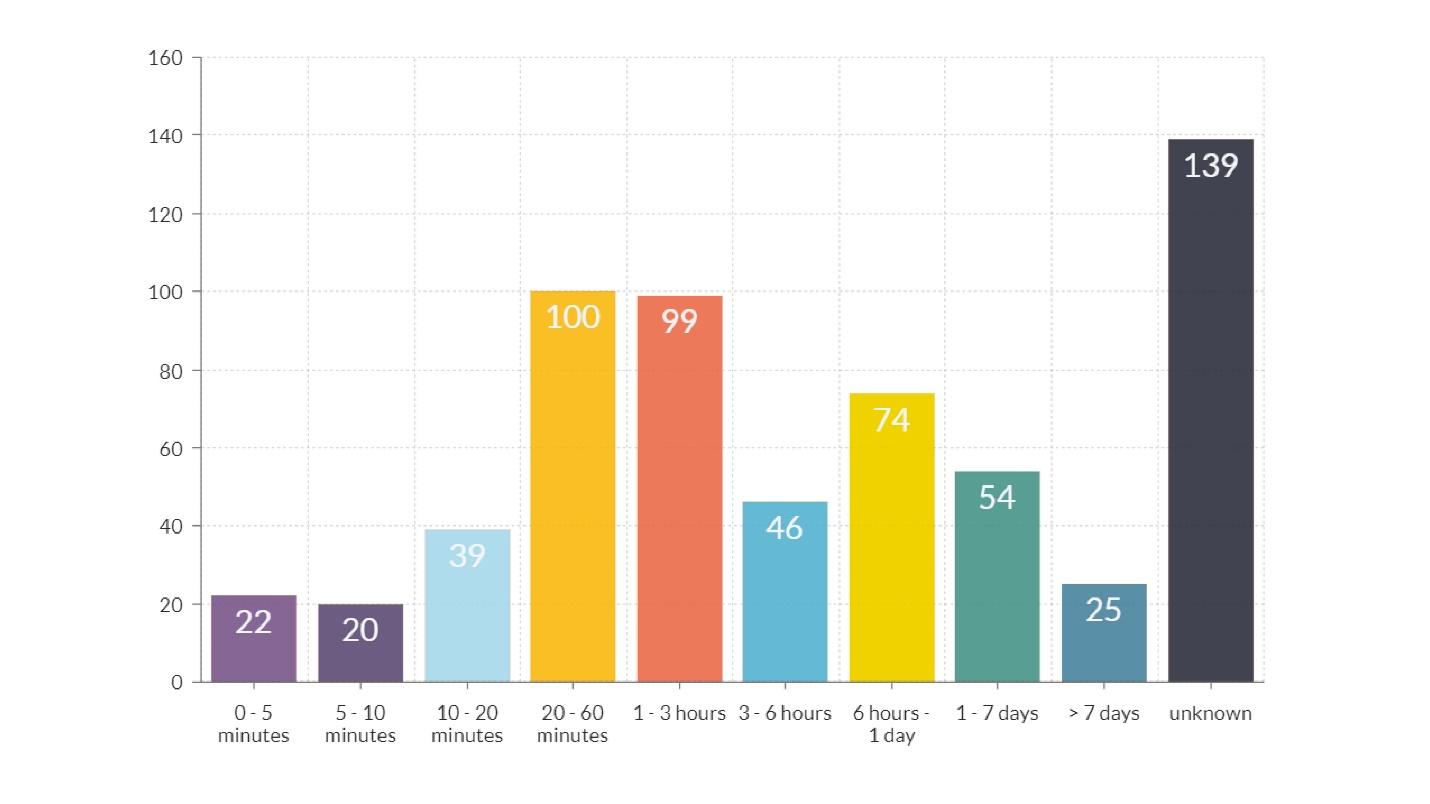 En el diagrama, además de la última columna, donde se desconoce el tiempo, hay dos picos más obvios.Duración del orden de una hora
En el diagrama, además de la última columna, donde se desconoce el tiempo, hay dos picos más obvios.Duración del orden de una hora : barras anaranjadas y rojas. La mayor parte de este tiempo se pasó transmitiendo información sobre lo sucedido, desde el ingeniero que notó el accidente hasta el ingeniero que sabe cómo solucionarlo.
El problema es la comunicación .
Si arreglamos nuestras herramientas para que el ingeniero que soluciona el problema reciba información más rápido, la duración de los fakaps y el daño de ellos se reducirá considerablemente. Esto es algo que no reconoceríamos al mirar cualquier fakap individualmente.
Duración aproximadamente 12 horas : una columna amarilla. La explicación del hecho de que hay muchos fakaps que duran más de 12 horas es simple: lanzaron el lanzamiento por la tarde, y por la mañana llegaron los usuarios, y todo se rompió. La conclusión de qué hacer para reducir el número de tales fakaps es obvia.
Daño de calidad

El daño cualitativo se divide en varias categorías. Top 3 incluye:
- inaccesibilidad, errores;
- frenos, mayor latencia;
- Comportamiento incorrecto visible.
Según los análisis, la gran mayoría de estos errores. Por un lado, estas son buenas noticias. Los tres tipos de errores más comunes son fáciles de detectar: ajustamos las métricas a la latencia y la cantidad de errores, y notamos rápidamente tales cosas.
La mala noticia es que hay la mayoría de estos errores. Estos son errores técnicos simples, lo que significa que podríamos mejorar algo en las pruebas de tuberías, realizar más pruebas de estrés y mejorar el sistema de monitoreo.
Disparadores
Esto es lo que condujo directamente al colapso, es decir, no la causa raíz del accidente, sino la "gota que colmó el vaso": los registros llenaron el disco y debido a esto, todo se rompió, se puso en libertad, todo explotó.

En primer lugar es la "instalación de actualización". Esta razón nos permite comprender en qué debemos invertir, como equipo de infraestructura. Por ejemplo, para mejorar el sistema de implementación e introducir una implementación canaria. Este es el punto de esfuerzo que tendrá el mayor impacto en la calidad de nuestros sistemas.
Este es el punto de todos los análisis: comprender dónde debe invertir un pequeño equipo de infraestructura en este momento en condiciones de recursos limitados.
¿Qué mejorar: alerta o despliegue? ¿Qué hacer: hosting o la belleza de los gráficos?
Aquí hay otra buena idea. En segundo lugar está "la causa es desconocida". Este es un indicador de informes deficientes de informes de incidentes.
Posibles "pastillas"
Eso permite una solución técnica simple para reducir el número de accidentes de cierto tipo. Por ejemplo, sabemos que las cosas más importantes que reducen el número de fakaps son las notificaciones del sistema de monitoreo. Si hubiera más alertas en el monitoreo de estos eventos, ¿cuántos incidentes podríamos prevenir? El porcentaje indica cuánto:
- en la cantidad de errores HTTP del cliente - 10%;
- en la aparición de nuevos tipos de errores en los registros: instalación, configuración de notificaciones - 8%;
- en recursos del sistema: CPU, memoria, disco, hilos, GC - 6%.
Si la alerta se configuró correctamente y el ingeniero deseado recibió una notificación a tiempo, el 24% de los incidentes no ocurrirían o tendrían una duración mucho más corta. Esta conclusión puede hacerse sobre la base del análisis de toda la masa de incidentes.
Aquí anunciaré nuevamente nuestro sistema de alerta
Moira , que se encuentra en Código Abierto.
Si tiene Graphite, puede descargarlo y usarlo. Espero que haya menos incidentes.
Recomendaciones
Recomendaciones organizacionales que el equipo puede seguir, y también reducir la cantidad de accidentes. Nuestro top 3.
- La similitud de los sitios de prueba y combate . El 5% de los incidentes ocurrieron debido al hecho de que el sitio de prueba no era lo suficientemente similar al de combate.
- Compatibilidad con versiones anteriores en versiones . El lanzamiento se desinfló, no era compatible con la versión anterior, surgieron migraciones de datos: 4% de los errores.
- Denegación de liberaciones nocturnas . Si deja de difundir lanzamientos que se rompen, en la noche, otro 4% de los incidentes desaparecerán.
Insisto en que esto no es una instrucción, sino una historia sobre cómo recopilamos análisis. Su análisis puede ser diferente.
Como escribir
Si te das cuenta de que el análisis de incidentes es algo genial y necesitas escribir informes, te diré cómo hacerlo.
Post-mortem y tareas en un rastreador de errores
En el rastreador de errores, a diferencia de Google Docs o Wiki, hay campos fijos para los que puede establecer un conjunto de valores. Esto facilita el análisis de estadísticas gráficas más adelante.
En el libro SRE, Google proporciona una plantilla en Google Docs en la que escriben informes en su documento interno. No puedo imaginar cómo podemos recopilar los análisis que recopilamos de documentos de Google no estructurados.
Escribimos informes en el mismo rastreador de errores que las tareas principales, porque podemos conectar la tarea con la autopsia. Echemos un vistazo a la autopsia e inmediatamente veamos qué tareas están cerradas, cuáles no y cuáles quedan por hacer.
Crea campos especiales
Ya hablé de campos especiales. Tenemos lo siguiente
- El principio y el final del fakap se pueden analizar automáticamente. Si coloca marcas de tiempo legibles por máquina, puede trazar la duración del fakap.
- El comienzo y el final de la investigación.
- Disparador Configure una lista desplegable de disparadores, es más conveniente.
- Como se señaló.
- Daño cuantitativo y cualitativo.
- Equipos y servicios afectados.
Todos los datos de campos especiales le permiten comprender cómo funciona su infraestructura.
Un ejemplo de nuestro informe de incidentes completo.

Los campos de la columna derecha se completan mediante la selección de las listas desplegables.
Reúna un equipo de ingenieros que se preocupe por la calidad.
Para obtener informes que lo ayuden a comprender cómo desarrollar su infraestructura, necesitará personas que se preocupen por la calidad de sus servicios. No necesariamente serán los ingenieros los que se dediquen al análisis a tiempo completo de la autopsia solamente. Es importante que estas personas estén muy preocupadas por lo que está sucediendo. De vez en cuando se reunirán, analizarán toda la masa de incidentes, escribirán artículos grandes y traerán beneficios, cierren el círculo de comentarios.
Nuestro equipo se llama Q-team, de la palabra "Calidad". Cuenta con 3 personas, uno de los ingenieros más talentosos de la empresa que trabajan en infraestructura.
Total
Lea el gurú: el artículo de John Allspaw y los libros de gestión de incidentes:
Ingeniería de confiabilidad del sitio ,
PagerDuty Post-Mortem Process ,
Atlassian Incident Handbook .
Y cuando vengas a trabajar mañana, solo da
los primeros pasos :
- inicie un proyecto para fakaps en el rastreador de errores en el que realiza tareas;
- tome cualquier plantilla: no intente escribir la suya, tomar la nuestra o de Google en SRE;
- cuando algo explota, solo escribe.
En ese momento, cuando escriba el primer, segundo y tercer informe, no tendrá análisis hermosos con columnas multicolores. Pero después de un año o dos, cuando los datos se han acumulado, miras hacia atrás y te agradeces por el primer paso.
Esperamos, entonces recordarás y agradecerás a Alexei por la historia de tal experiencia. Y, a su vez, intentaremos recopilar nuevos informes útiles en el programa DevOpsConf , recomendaciones desde las cuales puede ir y aplicar. La conferencia se llevará a cabo del 30 al 1 de septiembre de 2019 , hasta el 20 de agosto todavía estamos esperando las solicitudes de los partidarios de DevOps, pero 12 ya han sido aprobados, es decir, la competencia será más cercana a la fecha límite.
Si desea compartir su experiencia, decídase y envíe sus resúmenes . Si desea recibir noticias del programa, suscríbase a nuestro boletín y canal de telegramas .