A finales de junio, un equipo de la Universidad Carnegie Mellon nos mostró XLNet, presentando de inmediato la
publicación , el
código y el modelo terminado (
XLNet-Large , con carcasa: 24 capas, 1024-ocultos, 16 cabezas). Este es un modelo pre-entrenado para resolver varios problemas de procesamiento del lenguaje natural.
En la publicación, inmediatamente indicaron una comparación de su modelo con el
BERT de Google. Escriben que XLNet es superior a BERT en una gran cantidad de tareas. Y muestra resultados en 18 tareas de vanguardia.
BERT, XLNet y transformadores
Una de las tendencias recientes en el aprendizaje profundo es el aprendizaje de transferencia. Entrenamos modelos para resolver problemas simples en una gran cantidad de datos, y luego usamos estos modelos previamente entrenados, pero ya para resolver otros problemas más específicos. BERT y XLNet son redes pre-entrenadas que pueden usarse para resolver problemas de procesamiento del lenguaje natural.
Estos modelos desarrollan la idea de los
transformadores , el enfoque actualmente dominante para construir modelos para trabajar con secuencias. Muy detallado y con ejemplos de código sobre transformadores y el mecanismo de atención (mecanismo de atención) está escrito en el artículo
El transformador anotado .
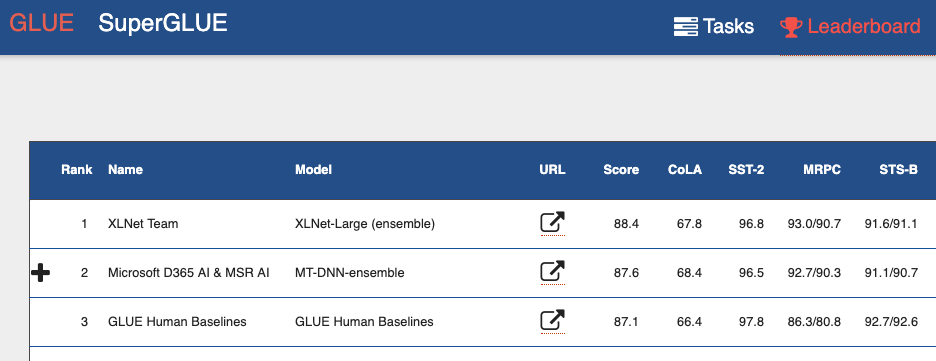
Si observa la tabla de
clasificación de evaluación de comprensión del lenguaje general (GLUE) , desde la parte superior puede ver muchos modelos basados en transformadores. Incluyendo ambos modelos que muestran mejores resultados que los humanos. Podemos decir que con los transformadores estamos presenciando una mini revolución en el procesamiento del lenguaje natural.
Desventajas BERT
BERT es un codificador automático (codificador automático, AE). Oculta y estropea algunas palabras en la secuencia e intenta restaurar la secuencia original de palabras del contexto.
Esto lleva a desventajas del modelo:
- Cada palabra oculta se predice individualmente. Perdemos información sobre las posibles relaciones entre palabras enmascaradas. El artículo proporciona un ejemplo llamado "Nueva York". Si intentamos predecir independientemente estas palabras en contexto, no tendremos en cuenta la relación entre ellas.
- Inconsistencia entre las fases de entrenamiento del modelo BERT y el uso del modelo BERT pre-entrenado. Cuando entrenamos el modelo, tenemos palabras ocultas (tokens [MASK]), cuando usamos el modelo pre-entrenado, ya no suministramos tales tokens a la entrada.
Y sin embargo, a pesar de estos problemas, BERT mostró resultados de vanguardia en muchas tareas de procesamiento del lenguaje natural.
Características de XLNet
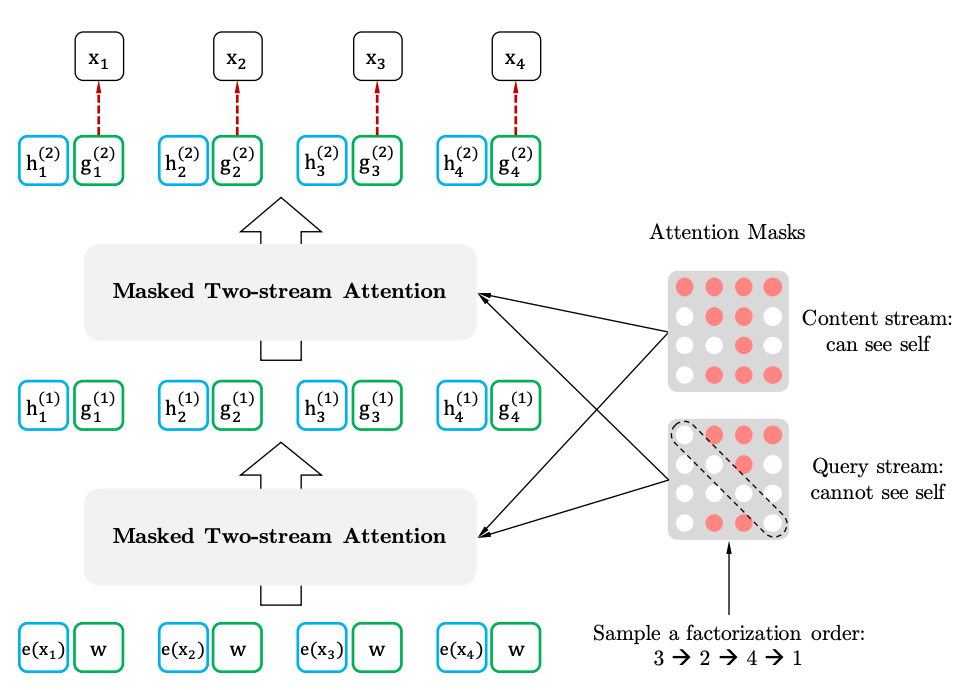
XLNet es un modelado de lenguaje autorregresivo, AR LM. Ella está tratando de predecir el siguiente token de la secuencia de los anteriores. En los modelos clásicos autorregresivos, esta secuencia contextual se toma independientemente de dos direcciones de la cadena original.
XLNet generaliza este método y forma el contexto desde diferentes lugares en la secuencia fuente. ¿Cómo lo hace? Toma todas las permutaciones posibles (en teoría) de la secuencia original y predice cada ficha en la secuencia de las anteriores.
Aquí hay un ejemplo del artículo sobre cómo se predice el token x3 de varias permutaciones de la secuencia original.
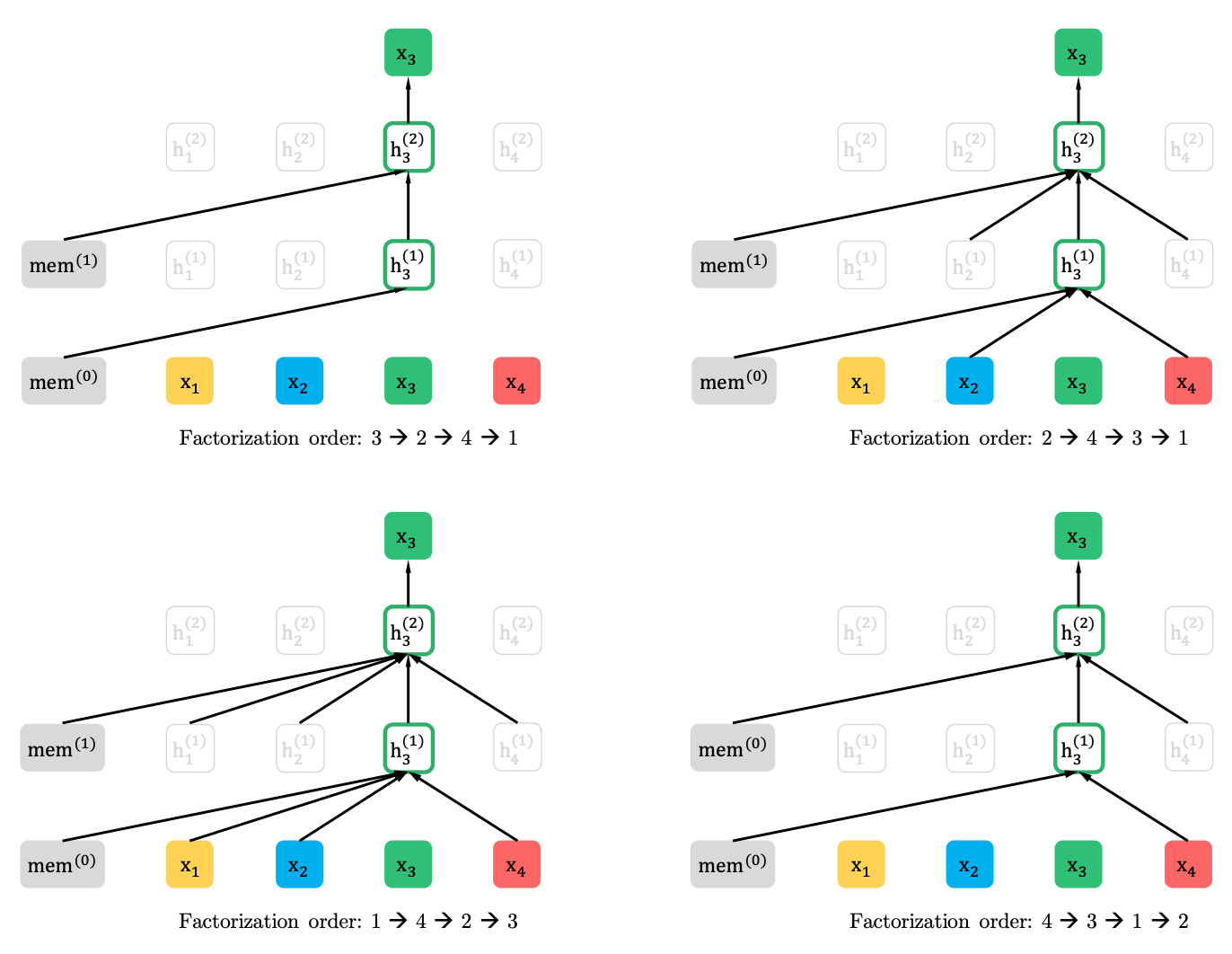
Además, el contexto no es una bolsa de palabras. La información sobre el orden inicial de los tokens también se proporciona al modelo.
Si dibujamos analogías con el BERT, resulta que no enmascaramos las fichas por adelantado, sino que usamos diferentes conjuntos de fichas ocultas para diferentes permutaciones. Al mismo tiempo, el segundo problema de BERT desaparece: la falta de tokens ocultos cuando se usa el modelo pre-entrenado. En el caso de XLNet, toda la secuencia, sin máscaras, ya está ingresada.
¿De dónde viene el XL en el nombre? XL: porque XLNet utiliza el mecanismo de atención e ideas del modelo Transformer-XL. Aunque los lenguajes malvados afirman que XL insinúa la cantidad de recursos necesarios para entrenar la red.
Y sobre los recursos. En Twitter, publicaron el
cálculo de lo que costaría capacitar a la red con los parámetros del artículo. Resultó 245,000 dólares. Es cierto, entonces vino un ingeniero de Google y
corrigió que el artículo menciona 512 chips de TPU, cuatro de los cuales están en el dispositivo. Es decir, el costo ya es de 62.440 dólares, o incluso 32.720 dólares, dados los 512 núcleos, que también se mencionan en el artículo.
XLNet vs BERT
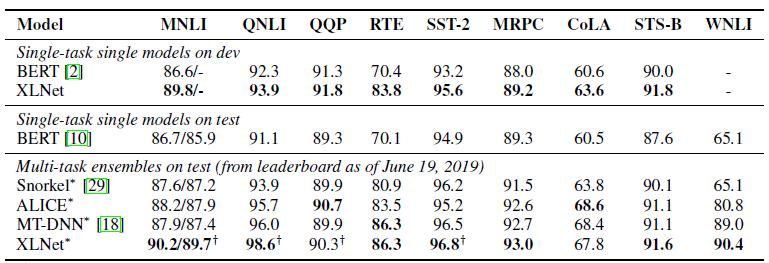
Hasta ahora, solo se ha presentado un modelo pre-entrenado para inglés para el artículo (XLNet-Large, Cased). Pero el artículo también menciona experimentos con modelos más pequeños. Y en muchas tareas, los modelos XLNet muestran mejores resultados en comparación con modelos BERT similares.
El advenimiento del BERT y especialmente los modelos pre-entrenados atrajeron mucha atención de los investigadores y condujeron a una gran cantidad de trabajos relacionados. Ahora aquí está XLNet. Es interesante ver si por algún tiempo se convertirá en el estándar de facto en PNL, o viceversa, estimulará a los investigadores en la búsqueda de nuevas arquitecturas y enfoques para procesar el lenguaje natural.