Hola a todos En este artículo, hablaré sobre nuestra experiencia en participar en la competencia de análisis de datos de
Data Mining Cup 2019 (DMC) y cómo logramos ingresar a los 10 mejores equipos y participar en las finales de campeonato en persona en Berlín.

Narraré en nombre de nuestro equipo, al que entro (Alexander Perevalov), así como a mi colega Sergey Bobkov. Somos estudiantes graduados de la
Universidad Politécnica de Perm , en nuestro tiempo libre del trabajo y estudio estamos comprometidos a resolver concursos de ciencia de datos.
¿Qué es DMC y cómo nos enteramos?
La Data Mining Cup es un campeonato mundial de análisis de datos estudiantiles que se celebra una vez al año. Su historia comenzó hace 20 años, mucho antes de
Kaggle , se puede decir que el
DMC celebró concursos de análisis de datos antes de que se generalizara .
DMC es
alojado por la compañía alemana
PrudSys , una compañía de
inteligencia minorista . Anteriormente, solo se permitía la participación con una sola mano en el campeonato, luego a los participantes se les permitía unirse en equipos de la universidad, por cierto, el número máximo de equipos de la universidad es solo 2. La membresía en la universidad también está estrictamente controlada, para la participación es necesario tener correo con el dominio de su estudiante instituciones, así como enviar una copia de su tarjeta de estudiante.
Hoy, si comparamos el nivel de participantes en DMC y Kaggle, por supuesto, el nivel de Kaggle es mucho más alto. Esto se debe a la restricción de estudiantes en el DMC y la popularidad de Kaggle. Una característica distintiva del DMC es la
ausencia de una tabla de clasificación , lo que elimina los problemas de instalación.
Me enteré de la Data Mining Cup en el momento en que fuimos con un grupo de nuestra universidad a realizar una pasantía en Alemania, a mi llegada a casa, mi amigo y compañero de equipo me invitaron a participar, fue a mediados de abril. Honestamente, era escéptico de esta idea, sin embargo, después de haber aprendido que este año los datos y la tarea son bastante simples, aún comenzamos a resolverlo.
Cómo resolvimos la tarea
En 2019, la tarea recaía en el campo de la detección de fraude de autopago. Seguramente ya se ha encontrado con mostradores de autoservicio en supermercados. Estos dispositivos funcionan tanto bajo la supervisión de un empleado de la tienda como de forma totalmente automática. Las cajas registradoras de autoservicio le permiten optimizar los costos de personal y minimizar las colas en los supermercados. Sin embargo, hay un problema, la naturaleza humana es tal que, de una forma u otra, existe el deseo de "no romper" los productos que queremos ver en nuestro refrigerador. Para evitar esto, el control es necesario, pero de tal manera que no avergüence ni moleste a los clientes.
Por lo tanto, en base a los datos etiquetados en las transacciones de autopago, es necesario desarrollar un modelo matemático que clasifique automáticamente una transacción particular como fraudulenta o no fraudulenta. Entonces, resolvemos el problema de clasificación binaria.
Los datos fueron los siguientes:

El tamaño de la muestra de entrenamiento fue de solo ~ 1800 ejemplos, mientras que la muestra de prueba fue de 499000 ejemplos. Además, la
muestra de capacitación
no estaba equilibrada : solo el 4% de las transacciones fueron fraudulentas, es obvio que la
precisión (la proporción de respuestas correctas) es inútil aquí. Sorprendentemente, no faltaron valores en los datos, y algunos de los atributos se distribuyeron de manera uniforme. En base a esto, podemos concluir que los
datos se generan artificialmente.Además, los organizadores propusieron su métrica en forma de una matriz de confusión, que se mide en unidades monetarias:
Después de analizarlo, nos quedó claro que la precisión es más importante en este caso, porque
asumimos la pérdida máxima si por error llamamos a un comprador honesto un estafador.El curso de nuestra solución consistió en etapas clásicas:
- Análisis de datos básicos.
- Análisis de signos, sus estadísticas descriptivas y distribuciones.
- Eliminación de valores atípicos
- Generación de personajes
- Crear un modelo y establecer parámetros
- Validación y Pronóstico Final
Las diapositivas con el contenido de nuestra solución se pueden encontrar en:
www.docdroid.net/2XEDfYg/dmc-2019-1.pdfEl repositorio en GitHub está aquí:
github.com/Perevalov/dmc2019 (todo está disperso en diferentes ramas, hasta que hubo tiempo de poner todo en orden)
Finales Organizacionales
Después de enviar la decisión final a principios de mayo, comenzamos a esperar resultados. Las condiciones de los organizadores son tales que los
10 mejores equipos están invitados a una final en persona en Berlín , que se lleva a cabo como parte de la conferencia Cumbre de inteligencia de Retail 2019: Decisiones inteligentes para Smart Retail.
Como referencia,
en 2019, 149 equipos de 114 universidades ubicadas en 28 países participaron en el DMC.Para ser sincero, ni siquiera esperábamos llegar a la final , pero ahora, a fines de mayo, llega esa carta de invitación. Además, a todos los finalistas se les pidió que pagaran gastos de hasta 500 euros, y también ofrecieron alojamiento en un hotel por una noche, donde se celebró el evento.
Sin dudarlo, compramos boletos para Berlín y fuimos a obtener visas. Al ser estudiantes pobres, la cantidad de gastos para un viaje de 2 días resultó ser bastante grande para nosotros. Los costos de los boletos Perm-Berlin-Perm y el procesamiento de visas ascendieron a aproximadamente 40,000 rublos. por persona, esto es un poco más de 500 euros.
Como representamos a nuestra universidad en el evento, decidimos obtener apoyo material de ella. Además, la Universidad Politécnica de Perm implementa un programa para el desarrollo de las relaciones ruso-alemanas y apoya firmemente a los estudiantes de iniciativa (nos pareció que sí). Con la aprobación y firma del jefe del departamento en el que estudiamos, fuimos al departamento de ciencia e innovación. Comenzó una epopeya burocrática de un mes, que terminó con lo siguiente:
"No hay dinero, pero espera" . Por supuesto, estábamos un poco molestos, pero no nos desanimamos. Ahora es ridículo leer varias declaraciones de la alta dirección de nuestra universidad sobre la "necesidad de apoyar a los científicos jóvenes" y otras tonterías. Bueno, es una digresión.
Tenemos visas en solo 2 semanas. Durante el mismo tiempo, preparamos un informe para el discurso y el 2 de julio por la tarde fuimos al aeropuerto.
Rendimiento en la final de la Data Mining Cup y premiación
Al llegar a Berlín el 3 de julio por la mañana, fuimos al hotel nHow, donde se celebró la conferencia. El nivel de organización, por supuesto, es alto. De hecho, el costo de participación fue de 1000 euros por persona (para nosotros es gratis). Y así es como se ve el hotel:

Nuestra actuación estaba programada para las 16:30. Tuvo lugar en la sala de conferencias principal, naturalmente en inglés. Por cierto, el rendimiento en sí no se tuvo en cuenta en la calificación final, se calculó solo en función de la tasa final, de la que solo los organizadores tenían datos.
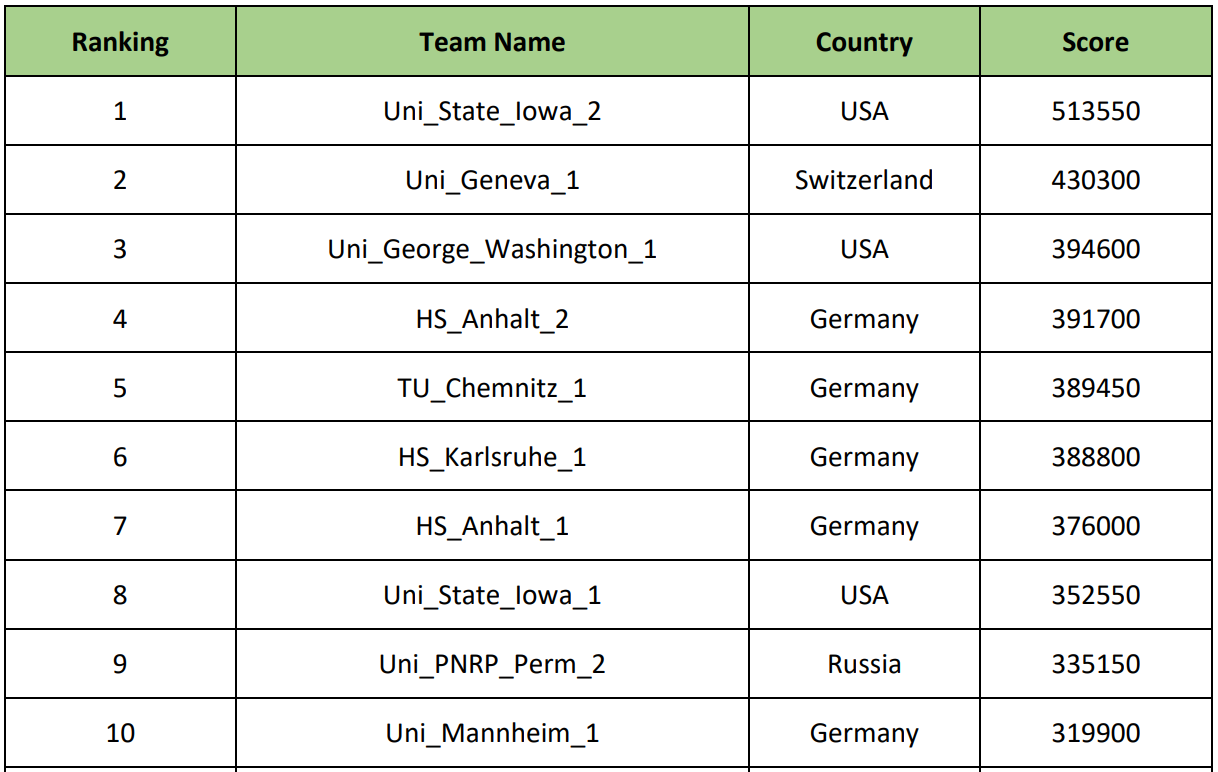
Entre los primeros 10 equipos se encontraban universidades como: la Universidad George Washington (EE. UU.), La Universidad de Ginebra (Suiza), la Universidad Tecnológica de Chemnitz (Alemania), la Universidad de Iowa (EE. UU.), Etc. Y, por supuesto, nuestra Universidad Politécnica de Investigación Nacional Perm.
Parecía una sala de conferencias:

Una pequeña vergüenza fue el hecho de que tenía que hablar no con diapositivas, sino con un póster en la pantalla. Por lo tanto, las actuaciones de los participantes no fueron suficientemente informativas. Sin embargo, hubo una oportunidad para acercarse y ver el póster en papel de cada uno de los participantes en la sala de conferencias. Básicamente, la mayoría de las personas usaban el
apilamiento, la combinación y el ensamblaje (nosotros estamos entre ellos), también, algunos participantes usaron un
umbral aumentado para los modelos de clasificación, un par de equipos lograron no generar características y construyeron el modelo en la fuente.
Por cierto, éramos el equipo más pequeño: solo 2 personas.
Después de las actuaciones, comenzó una cena de gala y gratificante. Esperábamos premios, pero nos dimos cuenta de que esto era poco probable, por lo que nuestro deseo mundano era "al menos no ser 10". Resultó exactamente como queríamos: tomamos el honorable noveno lugar. Naturalmente, fue un poco molesto, pero el hecho de que estuviéramos en la final entre universidades tan serias ya dice mucho. Los ganadores fueron participantes de la Universidad de Iowa (EE. UU.), Aunque no se puede decir que vinieron de los Estados Unidos (ver foto):
 Los premios para el 1 °, 2 ° y 3 ° lugar fueron de 2,000, 1,000 y 500 euros, respectivamente.
Los premios para el 1 °, 2 ° y 3 ° lugar fueron de 2,000, 1,000 y 500 euros, respectivamente. La calificación final es la siguiente:
Conclusiones
No nos arrepentimos de cuánto participamos en esta competencia. Como mínimo, este es un logro de +1 en la cartera, en los contactos más útiles con las personas y la oportunidad de representar a nuestra ciudad y país en un evento internacional.
Aconsejo a todos los científicos que participen en tales eventos, ¡es genial!