
Cómo Dailymotion usa Kubernetes: implementación de aplicaciones
Nosotros en Dailymotion comenzamos a usar Kubernetes en producción hace 3 años. Sin embargo, implementar aplicaciones en varios clústeres sigue siendo un placer, por lo que en los últimos años hemos intentado mejorar nuestras herramientas y flujos de trabajo.
Donde empezó
Aquí mostramos cómo implementamos nuestras aplicaciones en varios clústeres de Kubernetes en todo el mundo.
Para implementar varios objetos de Kubernetes a la vez, utilizamos Helm , y todos nuestros gráficos se almacenan en un repositorio de git. Para implementar la pila completa de aplicaciones de varios servicios, utilizamos el llamado gráfico generalizado. En esencia, este es un gráfico que declara dependencias y le permite inicializar la API y sus servicios con un solo comando.
También escribimos un pequeño script de Python sobre Helm para hacer comprobaciones, crear gráficos, agregar secretos e implementar aplicaciones. Todas estas tareas se realizan en la plataforma central de CI utilizando la imagen acoplable.
Vayamos al grano.
Nota Cuando lees esto, el primer candidato de lanzamiento de Helm 3 ya ha sido anunciado. La versión principal contiene un conjunto completo de mejoras diseñadas para resolver algunos de los problemas que hemos encontrado en el pasado.
Flujo de trabajo de desarrollo de gráficos
Para las aplicaciones, utilizamos la ramificación y decidimos aplicar el mismo enfoque a los gráficos.
- La rama de desarrollo se usa para crear gráficos que se probarán en clústeres de desarrollo.
- Cuando la solicitud del grupo se transfiere al maestro , se verifican en la preparación.
- Finalmente, creamos una solicitud de grupo para enviar los cambios a la rama de producción y aplicarlos en la producción.
Cada entorno tiene su propio repositorio privado que almacena nuestros gráficos, y utilizamos el Chartmuseum con API muy útiles. Por lo tanto, garantizamos un aislamiento estricto entre los entornos y verificamos los gráficos en condiciones reales antes de usarlos en la producción.
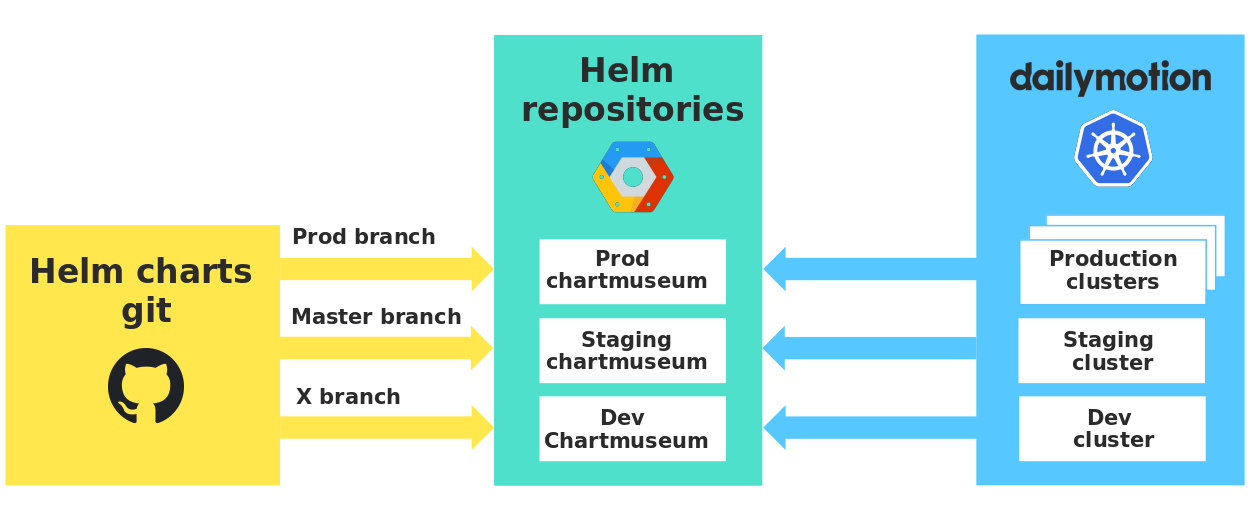
Repositorios de gráficos en diferentes entornos.
Vale la pena señalar que cuando los desarrolladores envían la rama de desarrollo, una versión de su gráfico se envía automáticamente al dev Chartmuseum. Por lo tanto, todos los desarrolladores usan el mismo repositorio de desarrollo, y debe indicar cuidadosamente su versión del gráfico para no usar accidentalmente los cambios de otra persona.
Además, nuestro pequeño script Python comprueba los objetos de Kubernetes contra las especificaciones de Openuber de Kubernetes usando Kubeval antes de publicarlos en Chartmusem.
Flujo de trabajo general de desarrollo de gráficos
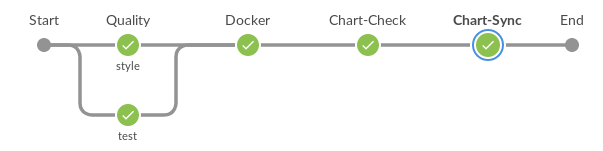
- Configurar la tarea de canalización de acuerdo con la especificación gazr.io para el control de calidad (pelusa, prueba unitaria).
- Enviar una imagen de Docker con las herramientas de Python que implementan nuestras aplicaciones.
- Configuración del entorno por el nombre de la sucursal.
- Verifique los archivos de yaml Kubernetes con Kubeval.
- Aumente automáticamente la versión del gráfico y sus gráficos principales (gráficos que dependen del gráfico que se cambia).
- Enviar un gráfico al Chartmuseum que coincida con su entorno
Gestión de diferencia de clúster
Federación de clúster
Hubo un momento en que utilizamos Kubernetes Cluster Federation , donde se podían declarar objetos Kubernetes desde un punto final API. Pero hubo problemas. Por ejemplo, algunos objetos de Kubernetes no se pudieron crear en el punto final de la federación, por lo que fue difícil mantener los objetos combinados y otros objetos para grupos individuales.
Para resolver el problema, comenzamos a administrar clústeres de forma independiente, lo que simplificó enormemente el proceso (utilizamos la primera versión de federación; en la segunda, algo podría cambiar).
Ahora nuestra plataforma se distribuye en 6 regiones: 3 a nivel local y 3 en la nube.
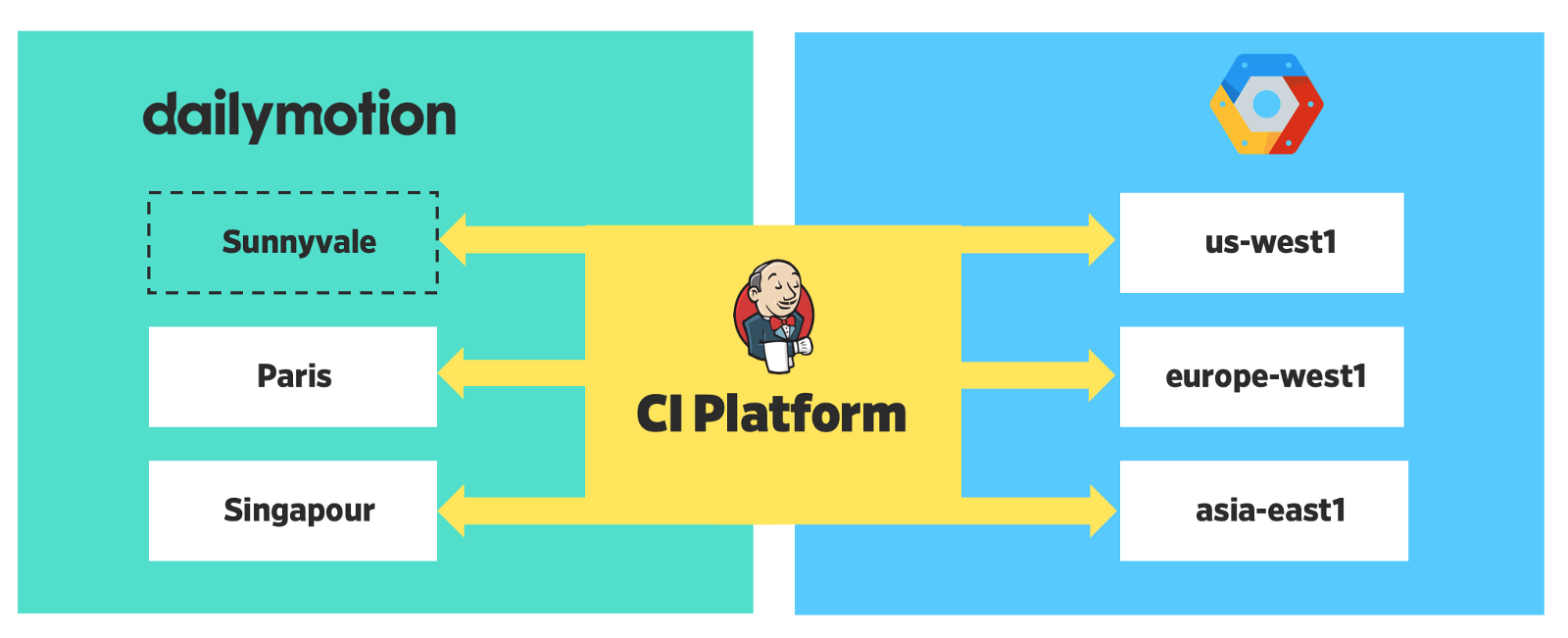
Despliegue distribuido
Valores globales de timón
4 valores globales de Helm le permiten determinar las diferencias entre los clústeres. Para todos nuestros gráficos, hay valores predeterminados mínimos.
global: cloud: True env: staging region: us-central1 clusterName: staging-us-central1
Valores globales
Estos valores ayudan a determinar el contexto de nuestras aplicaciones y se utilizan para diferentes tareas: monitoreo, rastreo, registro, llamadas externas, escalado, etc.
- "Cloud": tenemos una plataforma híbrida Kubernetes. Por ejemplo, nuestra API se implementa en zonas GCP y en nuestros centros de datos.
- “Env”: algunos valores pueden variar para entornos que no funcionan. Por ejemplo, definiciones de recursos y configuraciones de escalado automático.
- “Región”: esta información ayuda a determinar la ubicación del clúster y puede usarse para determinar los puntos finales más cercanos para servicios externos.
- "ClusterName": si y cuando queremos determinar el valor de un clúster individual.
Aquí hay un ejemplo concreto:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}} {{- define "graphql.hpaReplicas" -}} {{- if eq .Values.global.env "prod" }} {{- if eq .Values.global.region "europe-west1" }} minReplicas: 40 {{- else }} minReplicas: 150 {{- end }} maxReplicas: 1400 {{- else }} minReplicas: 4 maxReplicas: 20 {{- end }} {{- end -}}
Ejemplo de plantilla de timón
Esta lógica se define en la plantilla auxiliar para no obstruir Kubernetes YAML.
Anuncio de solicitud
Nuestras herramientas de implementación se basan en varios archivos YAML. El siguiente es un ejemplo de cómo declaramos un servicio y su topología de escala (número de réplicas) en un clúster.
releases: - foo.world foo.world: # Release name services: # List of dailymotion's apps/projects foobar: chart_name: foo-foobar repo: git@github.com:dailymotion/foobar contexts: prod-europe-west1: deployments: - name: foo-bar-baz replicas: 18 - name: another-deployment replicas: 3
Definición de servicio
Este es un diagrama de todos los pasos que definen nuestro flujo de trabajo de implementación. El paso final implementa la aplicación en múltiples grupos de trabajo simultáneamente.
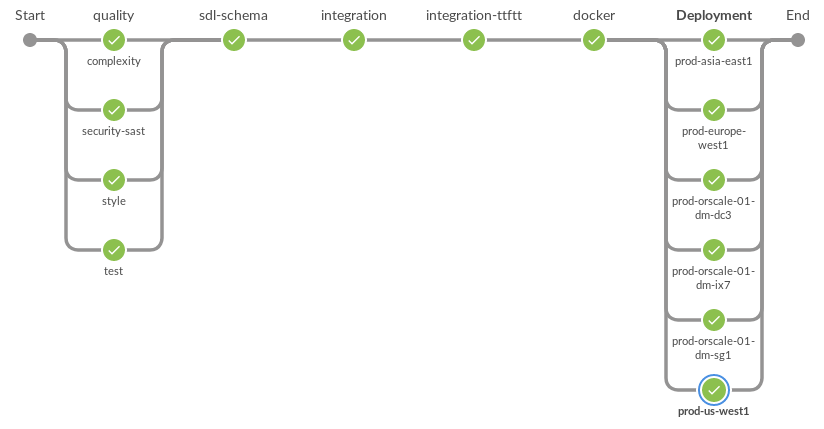
Pasos de implementación de Jenkins
¿Qué hay de los secretos?
En términos de seguridad, hacemos un seguimiento de todos los secretos de varios lugares y los almacenamos en el depósito exclusivo de Vault en París.
Nuestras herramientas de implementación extraen los valores de los secretos de Vault y, cuando llega el momento de la implementación, los insertan en Helm.
Para hacer esto, determinamos la asignación entre los secretos de Vault y los secretos que necesitan nuestras aplicaciones:
secrets: - secret_id: "stack1-app1-password" contexts: - name: "default" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password" - name: "cluster1" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password"
- Hemos identificado las reglas generales que debe seguir al escribir secretos en Vault.
- Si el secreto se refiere a un contexto o clúster específico , debe agregar una entrada específica. (Aquí, el contexto de cluster1 tiene su propio valor para la contraseña secreta stack-app1).
- De lo contrario, se utiliza el valor predeterminado .
- Para cada elemento de esta lista, se inserta un par clave-valor en el secreto de Kubernetes . Por lo tanto, el patrón secreto en nuestros gráficos es muy simple.
apiVersion: v1 data: {{- range $key,$value := .Values.secrets }} {{ $key }}: {{ $value | b64enc | quote }} {{ end }} kind: Secret metadata: name: "{{ .Chart.Name }}" labels: chartVersion: "{{ .Chart.Version }}" tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}" type: Opaque
Problemas y limitaciones.
Trabaja con múltiples repositorios
Ahora compartimos el desarrollo de gráficos y aplicaciones. Esto significa que los desarrolladores tienen que trabajar en dos repositorios git: uno para la aplicación y el segundo para determinar su implementación en Kubernetes. 2 repositorios de git son 2 flujos de trabajo y es fácil para un novato confundirse.
Administrar gráficos resumidos es problemático
Como ya dijimos, los gráficos genéricos son muy convenientes para definir dependencias y desplegar rápidamente múltiples aplicaciones. Pero usamos --reuse-values para evitar pasar todos los valores cada vez que implementamos la aplicación incluida en este gráfico generalizado.
En el flujo de trabajo de entrega continua, solo tenemos dos valores que cambian regularmente: el número de réplicas y la etiqueta de imagen (versión). Otros valores más estables se cambian manualmente, y esto es bastante complicado. Además, un error en la implementación de un gráfico generalizado puede conducir a fallas graves, como hemos visto por nuestra propia experiencia.
Actualización de múltiples archivos de configuración
Cuando un desarrollador agrega una nueva aplicación, tiene que cambiar varios archivos: declarar la aplicación, una lista de secretos, agregar la aplicación dependiendo de si está en el gráfico generalizado.
Permisos de Jenkins demasiado extendidos en Vault
Ahora tenemos una AppRole que lee todos los secretos de Vault.
El proceso de reversión no está automatizado
Para retroceder, debe ejecutar el comando en varios clústeres, y esto está lleno de errores. Realizamos esta operación manualmente para garantizar que se especifique el identificador de versión correcto.
Nos estamos moviendo hacia GitOps
Nuestro objetivo
Queremos devolver el gráfico al repositorio de la aplicación que implementa.
El flujo de trabajo será el mismo que para el desarrollo. Por ejemplo, cuando se envía una rama al asistente, la implementación comenzará automáticamente. La principal diferencia entre este enfoque y el flujo de trabajo actual será que todo se administrará en git (la aplicación en sí y la forma en que se implementa en Kubernetes).
Hay varias ventajas:
- Mucho más claro para el desarrollador. Es más fácil aprender cómo aplicar cambios al gráfico local.
- Se puede especificar una definición de implementación de servicio donde está el código de servicio.
- Gestión de la eliminación de gráficos generalizados . El servicio tendrá su propio lanzamiento de Helm. Esto le permitirá administrar el ciclo de vida de la aplicación (reversión, actualización) en el nivel más pequeño, para no afectar otros servicios.
- Los beneficios de git para administrar gráficos son: deshacer cambios, seguimiento de auditoría, etc. Si necesita deshacer un cambio en un gráfico, puede hacerlo con git. La implementación comienza automáticamente.
- Puede considerar mejorar su flujo de trabajo de desarrollo con herramientas como Skaffold , con las cuales los desarrolladores pueden probar los cambios en un contexto similar a la producción.
Migración en dos etapas.
Nuestros desarrolladores han estado utilizando este flujo de trabajo durante 2 años, por lo que necesitamos la migración más sencilla. Por lo tanto, decidimos agregar una etapa intermedia en el camino hacia la meta.
El primer paso es simple:
- Mantenemos una estructura similar para configurar la implementación de la aplicación, pero en el mismo objeto llamado DailymotionRelease.
apiVersion: "v1" kind: "DailymotionRelease" metadata: name: "app1.ns1" environment: "dev" branch: "mybranch" spec: slack_channel: "#admin" chart_name: "app1" scaling: - context: "dev-us-central1-0" replicas: - name: "hermes" count: 2 - context: "dev-europe-west1-0" replicas: - name: "app1-deploy" count: 2 secrets: - secret_id: "app1" contexts: - name: "default" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password" - name: "dev-europe-west1-0" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password"
- 1 lanzamiento por aplicación (sin gráficos generalizados).
- Gráficos en el repositorio de aplicaciones git.
Hablamos con todos los desarrolladores, por lo que el proceso de migración ya ha comenzado. La primera fase aún se controla utilizando la plataforma CI. Pronto escribiré otra publicación sobre la segunda etapa: cómo cambiamos al flujo de trabajo de GitOps con Flux . Te diré cómo nos configuramos y qué dificultades encontramos (varios repositorios, secretos, etc.). Sigue las noticias.
Aquí, tratamos de describir nuestro progreso en el flujo de trabajo de implementación de aplicaciones en los últimos años, lo que nos llevó a reflexionar sobre el enfoque de GitOps. No hemos alcanzado el objetivo e informaremos sobre los resultados, pero ahora estamos convencidos de que lo hicimos bien cuando decidimos simplificar todo y acercarlo a los hábitos de los desarrolladores.