Introduccion
Hace algún tiempo, necesitaba resolver el problema de segmentar puntos en una nube de puntos (las nubes de puntos son datos obtenidos de los lidares).
Datos de ejemplo y la tarea a resolver:
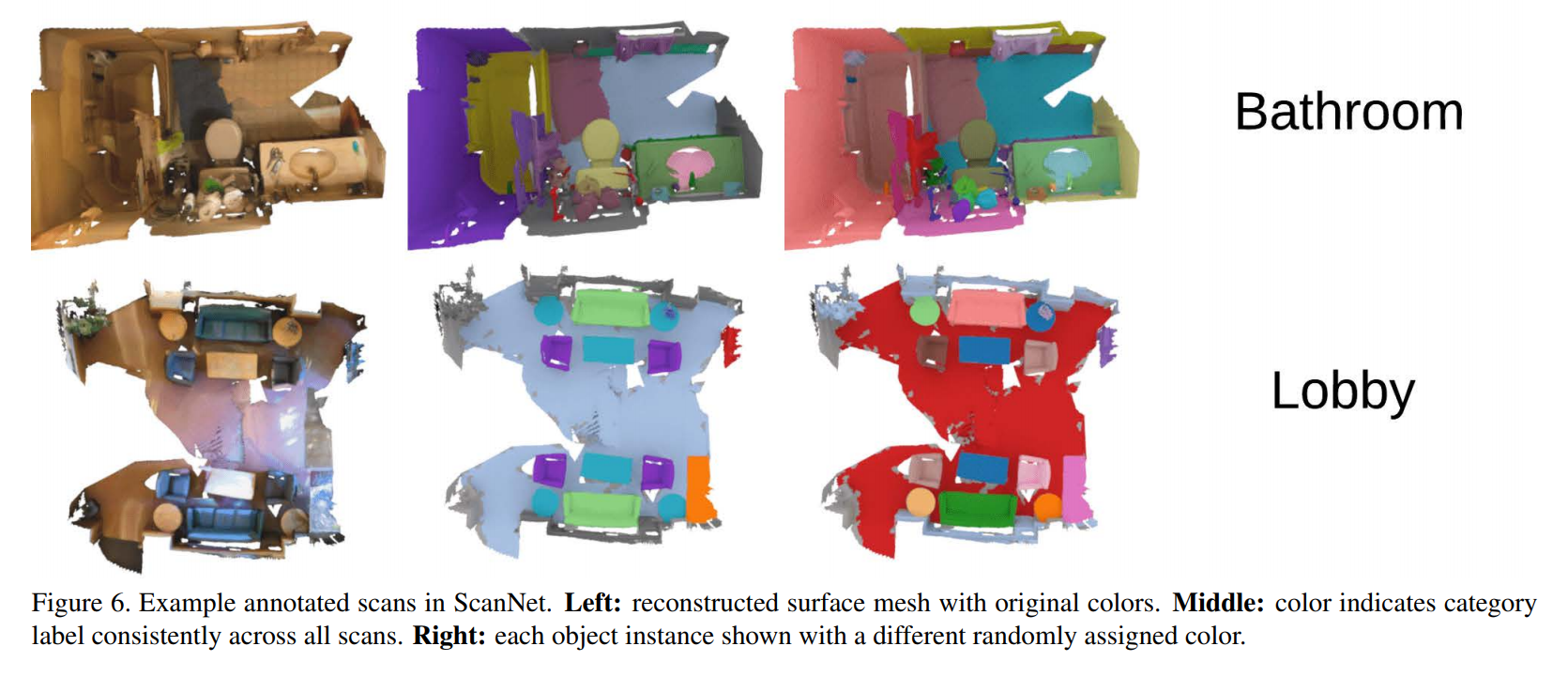
La búsqueda de una descripción general de los métodos existentes no tuvo éxito, por lo que tuve que recopilar información yo mismo. Puede ver el resultado: aquí se recopilan los artículos más importantes e interesantes (en mi opinión) de los últimos años. Todos los modelos considerados resuelven el problema de segmentar una nube de puntos (a qué clase pertenece cada punto).
Este artículo será útil para quienes estén familiarizados con las redes neuronales y quieran comprender cómo aplicarlas a datos no estructurados (por ejemplo, gráficos).
Conjuntos de datos existentes
Ahora en el dominio público existen los siguientes conjuntos de datos sobre este tema:
Características del trabajo con nubes de puntos
Las redes neuronales han llegado a esta área recientemente. Y las arquitecturas estándar como las redes totalmente conectadas y convolucionales no son aplicables para resolver este problema. Por qué
Porque el orden de los puntos no es importante aquí. Un objeto es un conjunto de puntos y no importa en qué orden se vean. Si cada píxel tiene su lugar en la imagen, podemos mezclar los puntos de manera segura y el objeto no cambia. El resultado de las redes neuronales estándar, por el contrario, depende de la ubicación de los datos. Si mezclas píxeles en la imagen, obtienes un nuevo objeto.
Ahora veamos cómo las redes neuronales se adaptaron para resolver este problema.
Artículos más importantes
No hay muchas arquitecturas básicas en esta área. Si tiene la intención de trabajar con gráficos o datos no estructurados, debe tener una idea de los siguientes modelos:
Consideremos con más detalle.
- PointNet: aprendizaje profundo en conjuntos de puntos para clasificación y segmentación 3D
Pioneros en trabajar con datos no estructurados.
- cómo deciden: El artículo describe dos modelos: para la segmentación de puntos y la clasificación de un objeto. La parte general consta de los siguientes bloques:
- una red para determinar la transformación (traducción del sistema de coordenadas), que luego se aplica a todos los puntos
- transformación aplicada a cada punto individualmente (perceptor regular)
- maxpooling, que combina información de diferentes puntos y crea un vector de características globales para todo el objeto.
- entonces comienzan las diferencias entre los modelos:
- modelo de clasificación: un vector de características globales va a la entrada de una capa totalmente conectada para determinar la clase de la nube de puntos completa
- modelo de segmentación: el vector de entidad global y las entidades calculadas para cada punto van a la entrada de la capa totalmente conectada que define la clase para cada punto.
- codigo



Artículos basados en PointNet y PointNet ++:
La mayoría de los artículos difieren en términos de conteo de errores o profundidad y complejidad de bloques complejos.
PointWise: una red de aprendizaje de características puntuales sin supervisión
Característica del trabajo: entrenamiento sin maestro
- cómo deciden: para cada punto, se entrena el vector de incrustaciones, por el cual luego se segmentan.
El postulado principal del artículo es que los objetos similares deben tener incrustaciones similares (por ejemplo, dos patas diferentes de una silla), a pesar de su lejanía. PointNet se utiliza como modelo base. La principal innovación es la función de error. Consta de dos partes: errores de reconstrucción y errores de suavidad.
El error de reconstrucción utiliza información de contexto puntual. Su tarea es hacer que las incrustaciones de puntos con el mismo contexto geométrico sean similares. Para calcularlo, en función del vector de incrustación para el punto seleccionado, se generan nuevos puntos cerca de él. Es decir, la descripción de la característica del punto debe contener información sobre la forma del objeto alrededor del punto. Luego, considere cuánto caen los puntos generados de la forma real del objeto.
El error de suavidad es necesario para que las incrustaciones sean similares en los puntos adyacentes y diferentes en los puntos distantes. Lo más hermoso aquí es la medición de la proximidad, no solo como la norma entre dos puntos en el espacio euclidiano, sino contando la distancia a través de los puntos del objeto. Para cada punto, se selecciona un punto entre k más cercano y desde k más lejos.
La incrustación actual debe estar más cerca del mínimo más cercano por un cierto margen que antes.
SGPN: Red de propuesta de grupo de similitud para la segmentación de instancias de nube de puntos 3D
- cómo deciden: como en PointWise, lo más interesante al calcular el error está aquí. PointNet ++ es la base, primero consideramos que el vector de características y el objeto pertenecen a cada punto individualmente, por analogía con PointNet ++.
A continuación, en función de las características, consideramos 3 matrices (similitud, confianza y segmentación).
El error de aprendizaje será la suma de tres errores calculados por las matrices correspondientes: L = L1 + L2 + L3
Sea N el número de puntos.
Matriz de similitud - cuadrada, tamaño N * N. El elemento en la intersección de la fila i-ésima y la columna j-ésima indica si estos puntos pertenecen al mismo objeto o no. Los puntos que pertenecen al mismo objeto deben tener vectores de características similares. Los elementos de la matriz pueden tomar uno de tres valores: los puntos i y j pertenecen a un objeto, los puntos pertenecen a una clase de objetos, pero a diferentes objetos (tanto esta como aquella silla, pero las sillas son diferentes), o generalmente son puntos de objetos de diferentes clases. Esta matriz se calcula de acuerdo con los valores verdaderos.

La matriz de confianza es un vector de longitud N. Para cada punto, se considera la intersección sobre la unión (IoU) entre el conjunto de puntos que pertenecen al objeto de acuerdo con el trabajo de nuestro algoritmo y el conjunto de puntos que realmente pertenecen al objeto con el punto actual. El error es simplemente la norma L2 entre la verdad y la matriz calculada. Es decir, la red está tratando de predecir qué tan segura está en la predicción de clase para los puntos en un objeto.
La matriz de segmentación tiene un tamaño: N * el número de clases. El error aquí se considera como entropía cruzada en el problema de clasificación multiclase. - codigo

- Sepa lo que hacen sus vecinos: segmentación semántica 3D de nubes de puntos
- cómo deciden: Al principio, consideran los signos durante mucho tiempo, más complicados que en PointNet, con un montón de conexiones residuales y cantidades, pero en general, lo mismo. Una ligera diferencia: cuentan los signos para cada punto en coordenadas globales y locales.
La principal diferencia aquí es el recuento de errores nuevamente. Esto no es crossentropía estándar, sino la suma de dos errores:
- pérdida de distancia por pares: los puntos de un objeto deben estar más cerca que τ_near y los puntos de diferentes objetos deben ser más largos que τ_far .
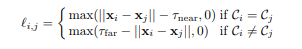
- pérdida de centroide: los puntos de un objeto deben estar cerca uno del otro
Artículos basados en DGCNN:
DGCNN se publicó recientemente (2018), por lo que hay pocos artículos basados en esta arquitectura. Quiero llamar su atención sobre una cosa:
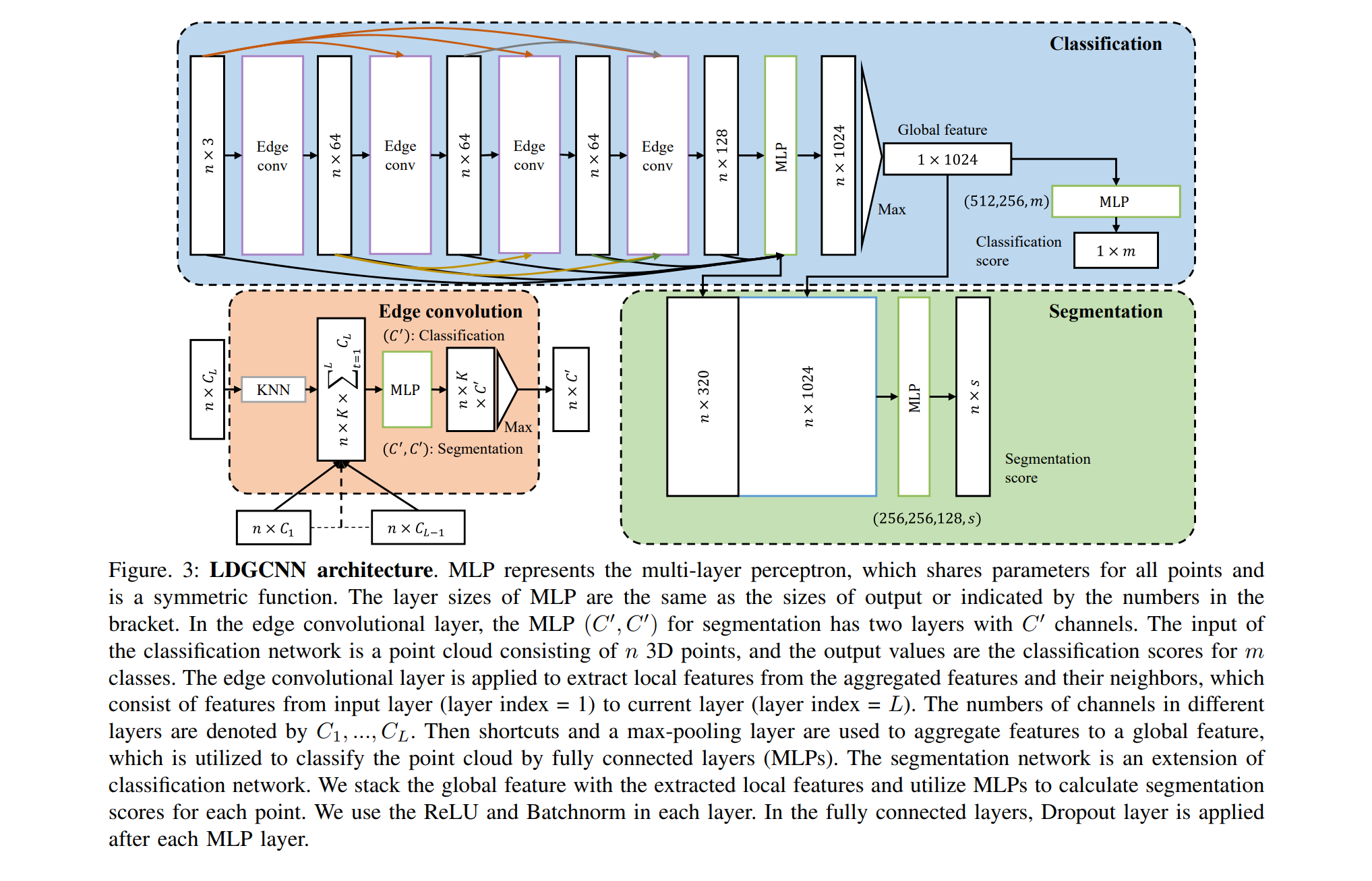
Conclusión
Aquí puede encontrar información breve sobre métodos modernos para resolver problemas de clasificación y segmentación en Nubes de puntos. Hay dos modelos principales (PointNet ++, DGCNN), cuyas modificaciones se utilizan ahora para resolver estos problemas. Muy a menudo, para la modificación, la función de error se cambia y estas arquitecturas se complican al agregar capas y enlaces.