GitHub aloja más de 300 lenguajes de programación, desde lenguajes de uso común como Python, Java y Javascript hasta lenguajes esotéricos como
Befunge , solo conocidos por comunidades muy pequeñas.
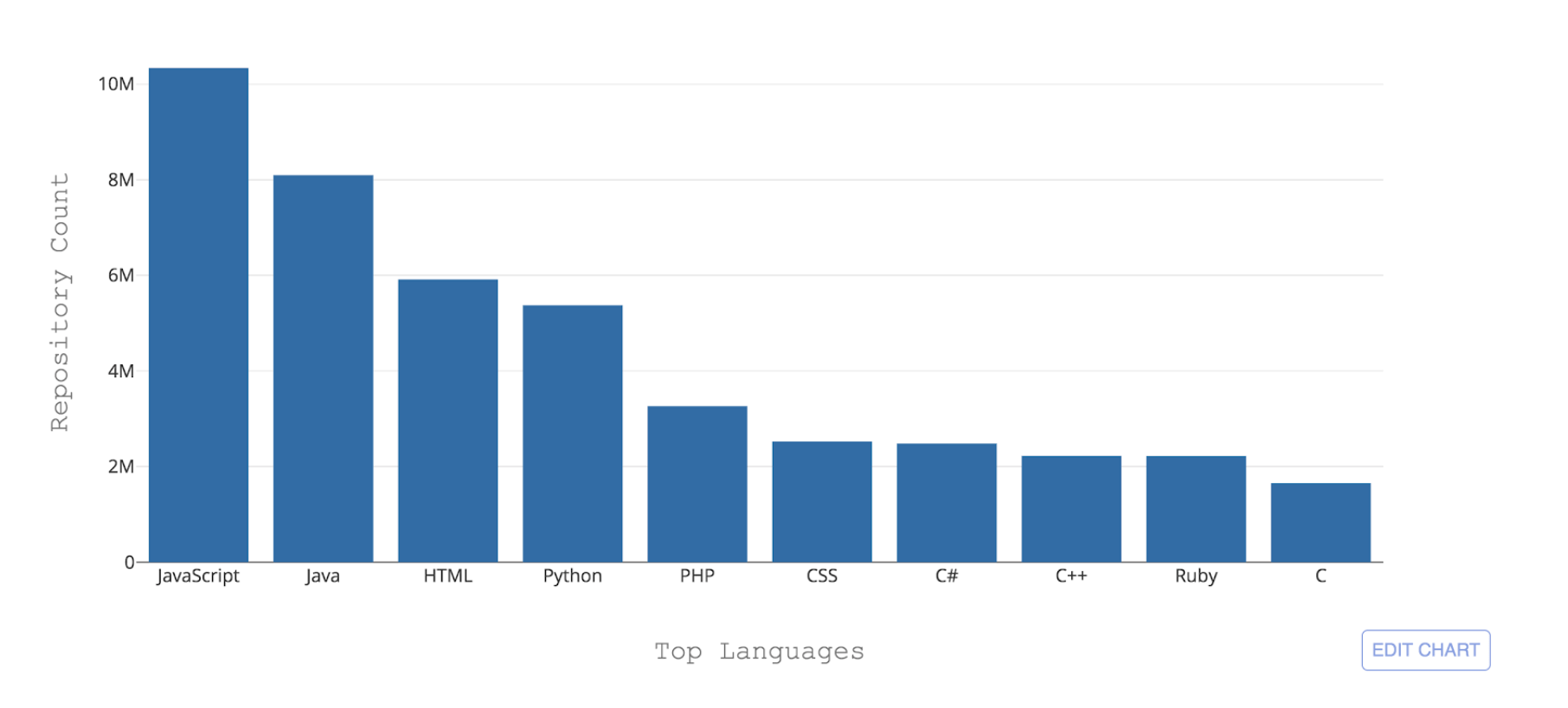 Figura 1: Los 10 principales lenguajes de programación alojados por GitHub por recuento de repositorio
Figura 1: Los 10 principales lenguajes de programación alojados por GitHub por recuento de repositorioUno de los desafíos necesarios que enfrenta GitHub es poder reconocer estos diferentes idiomas. Cuando se envía un código a un repositorio, es importante reconocer el tipo de código que se agregó para fines de búsqueda, alerta de vulnerabilidad de seguridad y resaltado de sintaxis, y mostrar la distribución de contenido del repositorio a los usuarios.
Linguist es la herramienta que actualmente utilizamos para detectar lenguajes de codificación en GitHub. Linguist, una aplicación basada en Ruby que utiliza diversas estrategias para la detección del lenguaje, aprovechando las convenciones de nomenclatura y las extensiones de archivo y también teniendo en cuenta las modelos de Vim o Emacs, así como el contenido en la parte superior del archivo (shebang). Linguist maneja la desambiguación del lenguaje a través de la heurística y, en su defecto, a través de un clasificador Naive Bayes capacitado en una pequeña muestra de datos.
Aunque Linguist hace un buen trabajo al hacer predicciones de lenguaje a nivel de archivo (84% de precisión), su rendimiento disminuye significativamente cuando los archivos usan convenciones de nomenclatura inesperadas y, crucialmente, cuando no se proporciona una extensión de archivo. Esto hace que Linguist no sea adecuado para contenido como GitHub Gists o fragmentos de código dentro de README, problemas y solicitudes de extracción.
Con el fin de hacer que la detección del lenguaje sea más robusta y mantenible a largo plazo, desarrollamos un clasificador de aprendizaje automático llamado Octo Lingua basado en una arquitectura de red neuronal artificial (ANN) que puede manejar predicciones del lenguaje en escenarios difíciles. La versión actual del modelo puede hacer predicciones para los 50 idiomas principales alojados por GitHub y supera a Linguist en precisión y rendimiento.
Las tuercas y tornillos detrás de OctoLingua
OctoLingua se creó desde cero utilizando Python, Keras con el backend TensorFlow, y está diseñado para ser preciso, robusto y fácil de mantener. En esta sección, describimos nuestras fuentes de datos, arquitectura de modelo y referencia de rendimiento para OctoLingua. También describimos lo que se necesita para agregar soporte para un nuevo idioma.
Fuentes de datos
La versión actual de OctoLingua se capacitó en los archivos recuperados del
Código Rosetta y de un conjunto de repositorios de calidad de colaboración interna. Limitamos nuestro conjunto de idiomas a los 50 idiomas principales alojados en GitHub.
Rosetta Code fue un excelente conjunto de datos de inicio, ya que contenía código fuente para la misma tarea expresada en diferentes lenguajes de programación. Por ejemplo, la tarea de generar una
secuencia de Fibonacci se expresa en C, C ++, CoffeeScript, D, Java, Julia y más. Sin embargo, la cobertura en todos los idiomas no fue uniforme donde algunos idiomas solo tienen un puñado de archivos y algunos archivos estaban escasamente poblados. Por lo tanto, era necesario aumentar nuestro conjunto de capacitación con algunas fuentes adicionales y mejorar sustancialmente la cobertura y el rendimiento del idioma.
Nuestro proceso para agregar un nuevo idioma ahora está completamente automatizado. Recopilamos programáticamente el código fuente de repositorios públicos en GitHub. Elegimos repositorios que cumplen con un criterio mínimo de calificación, como tener un número mínimo de horquillas, cubrir el idioma de destino y cubrir extensiones de archivo específicas. Para esta etapa de recopilación de datos, determinamos el idioma principal de un repositorio utilizando la clasificación de Linguist.
Características: aprovechando el conocimiento previo
Tradicionalmente, para problemas de clasificación de texto con redes neuronales, a menudo se emplean arquitecturas basadas en memoria como las redes neuronales recurrentes (RNN) y las redes de memoria a largo plazo (LSTM). Sin embargo, dado que los lenguajes de programación tienen diferencias en vocabulario, estilo de comentario, extensiones de archivo, estructura, estilo de importación de bibliotecas y otras diferencias menores, optamos por un enfoque más simple que aprovecha toda esta información mediante la extracción de algunas características relevantes en forma de tabla para alimentarlas. nuestro clasificador Las características extraídas actualmente son las siguientes:
- Los cinco caracteres especiales principales por archivo
- Top 20 tokens por archivo
- Extensión de archivo
- Presencia de ciertos caracteres especiales comúnmente utilizados en archivos de código fuente, como dos puntos, llaves y puntos y comas
El modelo de red neuronal artificial (ANN)
Utilizamos las características anteriores como entrada a una red neuronal artificial de dos capas construida usando Keras con el backend Tensorflow.
El siguiente diagrama muestra que el paso de extracción de características produce una entrada tabular n-dimensional para nuestro clasificador. A medida que la información se mueve a lo largo de las capas de nuestra red, se regulariza por abandono y finalmente produce una salida de 51 dimensiones que representa la probabilidad predicha de que el código dado se escriba en cada uno de los 50 idiomas principales de GitHub más la probabilidad de que no sea escrito en cualquiera de esos.
Figura 2: La Estructura ANN de nuestro modelo inicial (50 idiomas + 1 para "otro")Utilizamos el 90% de nuestro conjunto de datos para el entrenamiento en aproximadamente ocho épocas. Además, eliminamos un porcentaje de extensiones de archivo de nuestros datos de entrenamiento en el paso de entrenamiento, para alentar al modelo a aprender del vocabulario de los archivos y no sobreajustar en la función de extensión de archivo, que es altamente predictiva.
Punto de referencia de rendimiento
OctoLingua vs. LingüistaEn la Figura 3, mostramos la
Puntuación F1 (media armónica entre precisión y recuperación) de OctoLingua y Linguist calculada en el mismo conjunto de prueba (10% de nuestra fuente de datos inicial).
Aquí mostramos tres pruebas. La primera prueba es con el conjunto de prueba sin tocar de ninguna manera. La segunda prueba usa el mismo conjunto de archivos de prueba con la información de extensión de archivo eliminada y la tercera prueba también usa el mismo conjunto de archivos, pero esta vez con extensiones de archivo codificadas para confundir a los clasificadores (por ejemplo, un archivo Java puede tener un ". La extensión txt "y un archivo Python pueden tener una extensión" .java ").
La intuición detrás de codificar o eliminar las extensiones de archivo en nuestro conjunto de pruebas es evaluar la solidez de OctoLingua en la clasificación de archivos cuando se elimina una característica clave o es engañosa. Un clasificador que no dependa en gran medida de la extensión sería extremadamente útil para clasificar lo esencial y los fragmentos, ya que en esos casos es común que las personas no proporcionen información de extensión precisa (por ejemplo, muchas claves relacionadas con el código tienen una extensión .txt).
La tabla a continuación muestra cómo OctoLingua mantiene un buen rendimiento en diversas condiciones, lo que sugiere que el modelo aprende principalmente del vocabulario del código, en lugar de la metainformación (es decir, la extensión de archivo), mientras que Linguist falla tan pronto como la información sobre las extensiones de archivo es alterado
Figura 3: Rendimiento de OctoLingua vs. Lingüista en el mismo conjunto de pruebaEfecto de eliminar la extensión del archivo durante el tiempo de entrenamientoComo se mencionó anteriormente, durante el tiempo de entrenamiento eliminamos un porcentaje de extensiones de archivo de nuestros datos de entrenamiento para alentar al modelo a aprender del vocabulario de los archivos. La siguiente tabla muestra el rendimiento de nuestro modelo con diferentes fracciones de extensiones de archivo eliminadas durante el tiempo de entrenamiento.
 Figura 4: Rendimiento de OctoLingua con diferentes porcentajes de extensiones de archivo eliminados en nuestras tres variaciones de prueba
Figura 4: Rendimiento de OctoLingua con diferentes porcentajes de extensiones de archivo eliminados en nuestras tres variaciones de pruebaTenga en cuenta que sin la eliminación de la extensión de archivo durante el tiempo de entrenamiento, el rendimiento de OctoLingua en archivos de prueba sin extensiones y extensiones aleatorias disminuye significativamente de eso en los datos de prueba regulares. Por otro lado, cuando el modelo se entrena en un conjunto de datos donde se eliminan algunas extensiones de archivo, el rendimiento del modelo no disminuye mucho en el conjunto de prueba modificado. Esto confirma que eliminar la extensión de archivo de una fracción de archivos en el momento del entrenamiento induce a nuestro clasificador a aprender más del vocabulario. También muestra que la función de extensión de archivo, aunque altamente predictiva, tenía una tendencia a dominar y evitaba que se asignaran más pesos a las funciones de contenido.
Apoyando un nuevo idioma
Agregar un nuevo idioma en OctoLingua es bastante sencillo. Comienza con la obtención de una gran cantidad de archivos en el nuevo idioma (podemos hacer esto mediante programación como se describe en las fuentes de datos). Estos archivos se dividen en un conjunto de entrenamiento y prueba y luego se ejecutan a través de nuestro preprocesador y extractor de funciones. Este nuevo conjunto de trenes y pruebas se agrega a nuestro grupo existente de datos de capacitación y pruebas. El nuevo conjunto de pruebas nos permite verificar que la precisión de nuestro modelo sigue siendo aceptable.
Figura 5: Agregar un nuevo idioma con OctoLinguaNuestros planes
A partir de ahora, OctoLingua se encuentra en la "etapa avanzada de creación de prototipos". Nuestro motor de clasificación de idiomas ya es robusto y confiable, pero aún no admite todos los idiomas de codificación en nuestra plataforma. Además de ampliar el soporte de idiomas, lo que sería bastante sencillo, nuestro objetivo es permitir la detección de idiomas en varios niveles de granularidad. Nuestra implementación actual ya nos permite, con una pequeña modificación en nuestro motor de aprendizaje automático, clasificar fragmentos de código. No sería demasiado descabellado llevar el modelo al escenario donde pueda detectar y clasificar de manera confiable los lenguajes incrustados.
También estamos contemplando la posibilidad de un código abierto de nuestro modelo y nos encantaría saber de la comunidad si está interesado.
Resumen
Con OctoLingua, nuestro objetivo es proporcionar un servicio que permita la detección robusta y confiable del lenguaje de código fuente en múltiples niveles de granularidad, desde el nivel de archivo o nivel de fragmento hasta la detección y clasificación de lenguaje de nivel de línea potencial. Eventualmente, este servicio puede admitir, entre otros, la búsqueda de código, el intercambio de código, el resaltado de idioma y la representación diferencial, todo esto destinado a apoyar a los desarrolladores en su trabajo de desarrollo diario, además de ayudarlos a escribir código de calidad. Si está interesado en aprovechar o contribuir a nuestro trabajo, ¡no dude en ponerse en contacto en Twitter
@github !