El artículo muestra cómo implementar el manejo y el registro de errores sobre la base del principio "Hecho y olvidado" en Go. El método está diseñado para microservicios en Go, trabajando en un contenedor Docker y construido de conformidad con los principios de la arquitectura limpia.
Este artículo es una versión detallada de un informe de la reciente reunión de Go en Kazan . Si está interesado en Go y vive en Kazan, Innopolis, la hermosa Yoshkar-Ola o en otra ciudad cercana, debe visitar la página de la comunidad: golangkazan.imtqy.com .
En la reunión, nuestro equipo en dos informes mostró cómo estamos desarrollando microservicios en Go, qué principios seguimos y cómo simplificamos nuestras vidas. Este artículo se centra en nuestro concepto de manejo de errores, que ahora extendemos a todos nuestros nuevos microservicios.
Acuerdos de estructura de microservicios
Antes de tocar las reglas para el manejo de errores, vale la pena decidir qué restricciones observamos al diseñar y codificar. Para hacer esto, vale la pena decir cómo son nuestros microservicios.
En primer lugar, respetamos la arquitectura limpia. Dividimos el código en tres niveles y observamos la regla de dependencia: los paquetes en un nivel más profundo son independientes de los paquetes externos y no hay dependencias cíclicas. Afortunadamente, las dependencias directas de paquetes por turnos están prohibidas en Go. Las dependencias indirectas a través de la terminología de préstamo, las suposiciones sobre el comportamiento o la conversión a un tipo aún pueden aparecer, deben evitarse.
Así es como se ven nuestros niveles:
- El nivel de dominio contiene reglas de lógica de negocios dictadas por el área temática.
- a veces lo hacemos sin dominio si la tarea es simple
- regla: el código a nivel de dominio depende solo de las capacidades de Go, la biblioteca Go estándar y las bibliotecas seleccionadas que amplían el idioma Go
- La capa de aplicación contiene reglas de lógica empresarial dictadas por las tareas de la aplicación.
- regla: el código en el nivel de la aplicación puede depender del dominio
- El nivel de infraestructura contiene código de infraestructura que conecta la aplicación con diversas tecnologías de almacenamiento (MySQL, Redis), transporte (GRPC, HTTP), interacción con el entorno externo y con otros servicios.
- regla: el código a nivel de infraestructura puede depender del dominio y la aplicación
- regla: solo una tecnología por paquete Go
- El paquete principal crea todos los objetos: "singleton de por vida", los conecta y lanza corutinas de larga duración; por ejemplo, comienza a procesar solicitudes HTTP desde el puerto 8081
Así es como se ve el árbol del directorio de microservicios (la parte donde está el código Go):

Para cada uno de los contextos de aplicación (módulos), la estructura del paquete se ve así:
- el paquete de la aplicación declara una interfaz de Servicio que contiene todas las acciones posibles en un nivel dado que implementa la interfaz de estructura de servicio y la función
func NewService(...) Service - El aislamiento del trabajo con la base de datos se logra debido al hecho de que el paquete de dominio o aplicación declara la interfaz del Repositorio, que se implementa a nivel de infraestructura en el paquete con el nombre visual "mysql"
- el código de transporte se encuentra en el paquete de
infrastructure/transport
- utilizamos GRPC, por lo que los stubs del servidor se generan a partir del archivo proto (es decir, la interfaz del servidor, las estructuras de respuesta / solicitud y todo el código de interacción del cliente)
Todo esto se muestra en el diagrama:

Principios de manejo de errores
Aquí todo es simple:
- Creemos que se producen errores y pánicos al procesar solicitudes a la API, lo que significa que un error o pánico debería afectar solo una solicitud
- Creemos que los registros son necesarios solo para el análisis de incidentes (y hay un depurador para la depuración), por lo tanto, la información sobre las solicitudes se recibe en el registro y, en primer lugar, los errores inesperados al procesar las solicitudes
- Creemos que se construye una infraestructura completa para procesar registros (por ejemplo, basados en ELK), y el microservicio desempeña un papel pasivo en él, escribiendo registros en stderr
No nos centraremos en el pánico: simplemente no olvide manejar el pánico en cada rutina y durante el procesamiento de cada solicitud, cada mensaje, cada tarea asincrónica lanzada por la solicitud. Casi siempre, el pánico puede convertirse en un error para evitar que se complete toda la aplicación.
Errores de Idiom Sentinel
En el nivel de lógica de negocios, solo se procesan los errores esperados definidos por las reglas de negocios. Sentinel Errores lo ayudará a identificar dichos errores: utilizamos este modismo en lugar de escribir nuestros propios tipos de datos para errores. Un ejemplo:
package app import "errors" var ErrNoCake = errors.New("no cake found")
Aquí se declara una variable global que, por acuerdo de nuestro caballero, no deberíamos cambiar en ningún lado. Si no le gustan las variables globales y usa el linter para detectarlas, entonces puede sobrevivir con algunas constantes, como Dave Cheney sugiere en la publicación Errores constantes :
package app type Error string func (e Error) Error() string { return string(e) } const ErrNoCake = Error("no cake found")
Si le gusta este enfoque, es posible que desee agregar el tipo ConstError a su biblioteca corporativa de idiomas Go.
Composición de errores
La principal ventaja de Sentinel Errores es la capacidad de componer errores fácilmente. En particular, al crear un error o recibir un error desde el exterior, sería bueno agregar stacktrace. Para tales fines, hay dos soluciones populares.
- paquete xerrors, que en Go 1.13 se incluirá en la biblioteca estándar como un experimento
- Paquete github.com/pkg/errors por Dave Cheney
- el paquete está congelado y no se expande, pero no obstante es bueno
Nuestro equipo todavía usa github.com/pkg/errors y los errors.WithStack Funciones con errors.WithStack (cuando no tenemos nada que agregar, excepto stacktrace) o errors.Wrap . errors.Wrap (cuando tenemos algo que decir sobre este error). Ambas funciones aceptan un error en la entrada y devuelven un nuevo error, pero con stacktrace. Ejemplo de la capa de infraestructura:
package mysql import "github.com/pkg/errors" func (r *repository) FindOne(...) { row := r.client.QueryRow(sql, params...) switch err := row.Scan(...) { case sql.ErrNoRows:
Recomendamos que cada error se envuelva solo una vez. Esto es fácil de hacer si sigue las reglas:
- cualquier error externo se envuelve una vez en uno de los paquetes de infraestructura
- cualquier error generado por las reglas de lógica de negocios se complementa con stacktrace en el momento de la creación
Causa raíz del error
Todos los errores se dividen en esperados e inesperados. Para manejar el error esperado, debe deshacerse de los efectos de la composición. Los paquetes xerrors y github.com/pkg/errors tienen todo lo que necesita: en particular, el paquete de errores tiene los errors.Cause Función de errors.Cause , que devuelve la causa raíz del error. Esta función en un bucle, uno tras otro, recupera errores anteriores mientras que el siguiente error extraído tiene el método de Cause() error .
Un ejemplo al cual extraemos la causa raíz y la comparamos directamente con el error centinela:
func (s *service) SaveCake(...) error { state, err := s.repo.FindOne(...) if errors.Cause(err) == ErrNoCake { err = nil
Error al manejar en aplazar
Quizás esté utilizando linter, lo que le hace verificar manualmente todos los errores. En este caso, probablemente se enfurezca cuando linter le pida que verifique si hay errores con los métodos .Close() y otros métodos a los que solo defer . ¿Alguna vez ha tratado de manejar correctamente el error en aplazamiento, especialmente si hubo otro error antes? Y hemos intentado y tenemos prisa por compartir la receta.
Imagine que tenemos todo el trabajo con la base de datos es estrictamente a través de transacciones. De acuerdo con la regla de dependencia, los niveles de aplicación y dominio no deberían depender directa o indirectamente de la infraestructura y la tecnología SQL. Esto significa que en los niveles de aplicación y dominio no hay palabra "transacción" .
La solución más simple es reemplazar la palabra "transacción" con algo abstracto; así nace el patrón de la Unidad de Trabajo. En nuestra implementación, el servicio en el paquete de la aplicación recibe la fábrica a través de la interfaz UnitOfWorkFactory, y durante cada operación crea un objeto UnitOfWork que oculta la transacción. El objeto UnitOfWork le permite obtener un repositorio.
Más información sobre UnitOfWorkPara comprender mejor el uso de la Unidad de trabajo, eche un vistazo al diagrama:
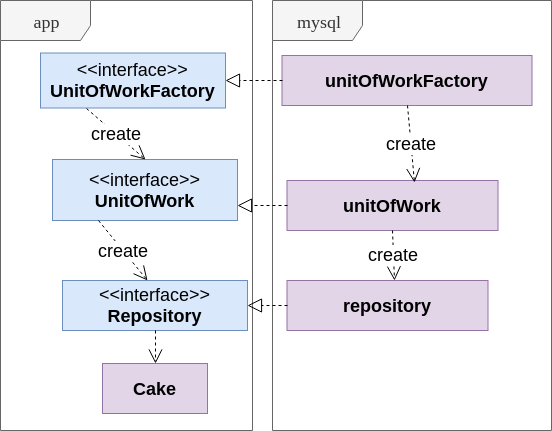
- El repositorio representa una colección abstracta persistente de objetos (por ejemplo, agregados a nivel de dominio) de un tipo definido
- UnitOfWork oculta la transacción y crea objetos de repositorio
- UnitOfWorkFactory simplemente permite que el servicio cree nuevas transacciones sin saber nada sobre las transacciones.
¿No es excesivo crear una transacción para cada operación, incluso inicialmente atómica? Depende de usted; Creemos que mantener la independencia de la lógica empresarial es más importante que ahorrar en la creación de una transacción.
¿Es posible combinar UnitOfWork y Repository? Es posible, pero creemos que esto viola el principio de responsabilidad única.
Así es como se ve la interfaz:
type UnitOfWork interface { Repository() Repository Complete(err *error) }
La interfaz UnitOfWork proporciona el método Completo, que toma un parámetro de entrada y salida: un puntero a la interfaz de error. Sí, es el puntero, y es el parámetro de entrada-salida; en cualquier otro caso, el código en el lado de la llamada será mucho más complicado.
Ejemplo de operación con unitOfWork:
Precaución: el error debe declararse como valor de retorno con nombre. Si en lugar del valor de retorno nombrado err usa la variable local err, ¡entonces no puede usarla en diferido! Y ni una sola linter detectará esto todavía - ver go-critical # 801
func (s *service) CookCake() (err error) { unitOfWork, err := s.unitOfWorkFactory.New() if err != nil { return err } defer unitOfWork.Complete(&err) repo := unitOfWork.Repository() }
Entonces la realización se realiza transacciones UnitOfWork:
func (u *unitOfWork) Complete(err *error) { if *err == nil {
La función mergeErrors combina dos errores, pero procesa nulo sin problemas en lugar de uno o ambos errores. Al mismo tiempo, creemos que ambos errores ocurrieron durante la ejecución de una operación en diferentes etapas, y el primer error es más importante; por lo tanto, cuando ambos errores no son nulos, guardamos el primero, y del segundo error guardamos solo el mensaje:
package errors func mergeErrors(err error, nextErr error) error { if err == nil { err = nextErr } else if nextErr != nil { err = errors.Wrap(err, nextErr.Error()) } return err }
Tal vez debería agregar la función mergeErrors a su biblioteca corporativa para Go.
Subsistema de registro
Lista de verificación del artículo : lo que tenía que hacer antes de iniciar microservicios en prod informa:
- los registros se escriben en stderr
- los registros deben estar en JSON, un objeto JSON compacto por línea
- Debe haber un conjunto estándar de campos:
- marca de tiempo - hora del evento en milisegundos , preferiblemente en formato RFC 3339 (ejemplo: "1985-04-12T23: 20: 50.52Z")
- nivel: nivel de importancia, por ejemplo, "información" o "error"
- nombre_aplicación: nombre de la aplicación
- y otros campos
Preferimos agregar dos campos más a los mensajes de error: "error" y "stacktrace" .
Hay muchas bibliotecas de registro de calidad para el lenguaje Golang, por ejemplo, sirupsen / logrus , que utilizamos. Pero no usamos la biblioteca directamente. En primer lugar, en nuestro paquete de log reducimos la interfaz de biblioteca demasiado extensa a una interfaz de Logger:
package log type Logger interface { WithField(string, interface{}) Logger WithFields(Fields) Logger Debug(...interface{}) Info(...interface{}) Error(error, ...interface{}) }
Si el programador quiere escribir registros, debe obtener la interfaz Logger desde el exterior, y esto debe hacerse en el nivel de infraestructura, no en la aplicación o el dominio. La interfaz del registrador es concisa:
- reduce el número de niveles de gravedad para depuración, información y error, como aconseja el artículo. Hablemos sobre el registro.
- introduce reglas especiales para el método de error: el método siempre acepta un objeto de error
Este rigor nos permite dirigir a los programadores en la dirección correcta: si alguien quiere mejorar el sistema de registro en sí, debe hacerlo teniendo en cuenta toda la infraestructura de su recolección y procesamiento, que solo comienza en el microservicio (y generalmente termina en algún lugar de Kibana y Zabbix).
Sin embargo, en el paquete de registro hay otra interfaz que le permite interrumpir el programa cuando ocurre un error fatal y, por lo tanto, solo se puede usar en el paquete principal:
package log type MainLogger interface { Logger FatalError(error, ...interface{}) }
Paquete Jsonlog
Implementa la interfaz Logger en nuestro paquete jsonlog , que configura la biblioteca logrus y abstrae el trabajo con ella. Esquemáticamente se ve así:

Un paquete patentado le permite conectar las necesidades de un microservicio (expresado por la interfaz log.Logger ), las capacidades de la biblioteca logrus y las características de su infraestructura, el registro.
Por ejemplo, usamos ELK (Elastic Search, Logstash, Kibana) y, por lo tanto, en el paquete jsonlog:
- establecer el formato
logrus.JSONFormatter para logrus.JSONFormatter
- al mismo tiempo, configuramos la opción FieldMap, con la que convertimos el campo
"time" en "@timestamp" y el campo "msg" en "message"
- seleccione nivel de registro
- agregue un gancho que extraiga stacktrace del objeto de
Error(error, ...interface{}) pasado al método Error(error, ...interface{})
El microservicio inicializa el registrador en la función principal:
func initLogger(config Config) (log.MainLogger, error) { logLevel, err := jsonlog.ParseLevel(config.LogLevel) if err != nil { return nil, errors.Wrap(err, "failed to parse log level") } return jsonlog.NewLogger(&jsonlog.Config{ Level: logLevel, AppName: "cookingservice" }), nil }
Manejo y registro de errores con middleware
Estamos cambiando a GRPC en nuestros microservicios en Go. Pero incluso si usa la API HTTP, los principios generales son para usted.
En primer lugar, el manejo y el registro de errores deben ocurrir a nivel de infrastructure en el paquete responsable del transporte, porque es él quien combina el conocimiento de las reglas del protocolo de transporte y el conocimiento de la aplicación. app.Service interfaz de servicio. Recuerde cómo se ve la relación del paquete:

Es conveniente procesar errores y mantener registros utilizando el patrón Middleware (Middleware es el nombre del patrón Decorator en el mundo de Golang y Node.js):
¿Dónde agregar Middleware? ¿Cuántos debería haber?
Hay diferentes opciones para agregar Middleware, usted elige:
- Puede decorar la
app.Service Interfaz de servicio, pero no recomendamos hacerlo porque esta interfaz no recibe información de la capa de transporte, como la IP del cliente - Con GRPC puede colgar un controlador en todas las solicitudes (más precisamente, dos: unario y steam), pero luego todos los métodos API se registrarán en el mismo estilo con el mismo conjunto de campos
- Con GRPC, el generador de código crea para nosotros una interfaz de servidor en la que llamamos a la
app.Service Método de servicio: decoramos esta interfaz porque tiene información de nivel de transporte y la capacidad de registrar diferentes métodos API de diferentes maneras
Esquemáticamente se ve así:

Puede crear diferentes Middlewares para el manejo de errores (y el pánico) y para el registro. Puedes cruzar todo en uno. Consideraremos un ejemplo en el que todo se cruza en un Middleware, que se crea así:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService { server := &errorHandlingMiddleware{ next: next, logger: logger, } return server }
Obtenemos la interfaz api.BackendService como api.BackendService y la decoramos, devolviendo nuestra implementación de la interfaz api.BackendService como api.BackendService .
Un método API arbitrario en Middleware se implementa de la siguiente manera:
func (m *errorHandlingMiddleware) ListCakes( ctx context.Context, req *api.ListCakesRequest) (*api.ListCakesResponse, error) { start := time.Now() res, err := m.next.ListCakes(ctx, req) m.logCall(start, err, "ListCakes", log.Fields{ "cookIDs": req.CookIDs, }) return res, translateError(err) }
Aquí realizamos tres tareas:
- Llame al método ListCakes del objeto decorado
- Llamamos
logCall método logCall , pasando toda la información importante, incluido un conjunto de campos seleccionados individualmente que se incluyen en el registro. - Al final, reemplazamos el error llamando a translateError.
La traducción del error se discutirá más adelante. Y el logCall se realiza mediante el método logCall , que simplemente llama al método de interfaz Logger correcto:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) { fields["duration"] = fmt.Sprintf("%v", time.Since(start)) fields["method"] = method logger := m.logger.WithFields(fields) if err != nil { logger.Error(err, "call failed") } else { logger.Info("call finished") } }
Traducción de error
Debemos obtener la causa raíz del error y convertirlo en un error que sea comprensible a nivel de transporte y documentado en la API de su servicio.
En GRPC, es simple: use la función status.Errorf para crear un error con un código de estado. Si tiene una API HTTP (REST API), puede crear su propio tipo de error que la aplicación y los niveles de dominio no deben conocer.
En una primera aproximación, la traducción del error se ve así:
Al validar los argumentos de entrada, la interfaz decorada puede devolver un error del estado. status.Status el status.Status con un código de estado, y la primera versión de translateError perderá este código de estado.
Hagamos una versión mejorada al transmitir a un tipo de interfaz (¡viva la escritura de pato!):
type statusError interface { GRPCStatus() *status.Status } func isGrpcStatusError(er error) bool { _, ok := err.(statusError) return ok } func translateError(err error) error { if isGrpcStatusError(err) { return err } switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err }
La función translateError se crea individualmente para cada contexto (módulo independiente) en su microservicio y traduce los errores de lógica empresarial en errores de nivel de transporte.
Para resumir
Le ofrecemos varias reglas para manejar errores y trabajar con registros. Si seguirlos o no depende de usted.
- Siga los principios de la arquitectura limpia, no rompa directa o indirectamente la regla de las dependencias. La lógica empresarial debe depender solo de un lenguaje de programación, y no de tecnologías externas.
- Use un paquete que ofrezca composición de errores y creación de seguimiento de pila. Por ejemplo, "github.com/pkg/errors" o el paquete xerrors, que pronto formará parte de la biblioteca estándar Go.
- No utilice bibliotecas de registro de terceros en el microservicio: cree su propia biblioteca con los paquetes log y jsonlog, que ocultarán los detalles de la implementación del registro
- Use el patrón de Middleware para manejar errores y escribir registros en la dirección de transporte del nivel de infraestructura del programa
Aquí no dijimos nada sobre tecnologías de rastreo de consultas (por ejemplo, OpenTracing), monitoreo de métricas (por ejemplo, rendimiento de consultas de bases de datos) y otras cosas como el registro. Usted mismo se ocupará de esto, creemos en usted.