Recientemente, el lenguaje Scala ha sido ampliamente utilizado por Data Science. Ganó popularidad principalmente debido a la llegada de Spark, que está escrito en Scala. En la práctica, a menudo en la etapa de investigación, el análisis y la creación de modelos se realizan en Python y luego se implementan en Scala, ya que este lenguaje es más adecuado para la producción.
Hemos preparado una descripción detallada de las bibliotecas más interesantes utilizadas para implementar tareas de aprendizaje automático y ciencia de datos en Scala. Algunos de ellos se utilizan en nuestro programa educativo " Análisis de datos en Scala ".
Por conveniencia, todas las bibliotecas presentadas en la clasificación se dividieron en 5 grupos: análisis de datos y matemáticas, PNL, visualización, aprendizaje automático y más.
Análisis de datos y matemáticas
No 1. Brisa (Compromisos: 3316, Colaboradores: 84)
La biblioteca Breeze es conocida como la biblioteca científica principal para Scala. Tiene cosas similares de MATLAB (en términos de estructuras de datos) y de Python, clases NumPy. Breeze proporciona una manipulación rápida y eficiente de las matrices de datos y le permite realizar muchas otras operaciones, incluidas las siguientes:
- Operaciones matriciales y vectoriales para crear, transponer, realizar operaciones con elementos, inversión, calcular determinantes y muchas otras cosas.
- Funciones probabilísticas y estadísticas: desde distribuciones estadísticas y el cálculo de estadísticas descriptivas (como media, varianza y desviación estándar) hasta modelos de cadena de Markov. Los paquetes principales de estadísticas son breeze.stats y breeze.stats.distributions.
- Optimización, que implica examinar una función para un mínimo local o global. Los métodos de optimización se almacenan en el paquete breeze.optimize.
- Álgebra lineal: todas las operaciones básicas se basan en la biblioteca netlib-java, lo que hace que Breeze sea extremadamente rápido para la computación algebraica.
- Operaciones de procesamiento de señales. Ejemplos de tales operaciones en Breeze son la convolución y la transformación de Fourier, que divide esta función en la suma de los componentes del seno y el coseno.
Vale la pena señalar que Breeze también le permite crear gráficos, pero hablaremos de esto más adelante.
No 2. Silla de montar (Compromisos: 184, Contribuyentes: 10)
Otra herramienta de datos para Scala es Saddle. Este es un análogo de Pandas en Python, pero solo para Scala. Al igual que los marcos de datos en Pandas o R, Saddle se basa en una estructura de marco (matriz indexada bidimensional).
Hay cinco estructuras de datos básicas en total, a saber:
Marco (matriz indexada en 2D)
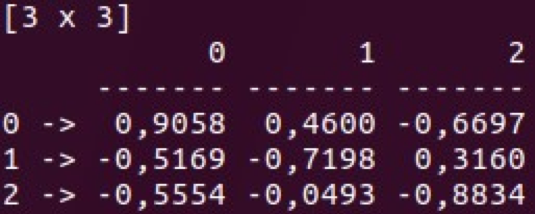
- Índice (como hashmap)
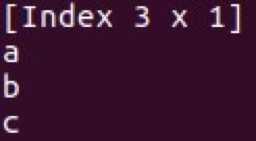
Las clases Vec y Mat se encuentran en Series y Frame. Puede realizar varias manipulaciones con estas estructuras de datos y usarlas para el análisis básico de datos. Otra gran característica de Saddle es su resistencia a la falta de datos.
Número 3. ScalaLab (Compromisos: 23, Colaboradores: 1)
ScalaLab es una especie de MATLAB en Scala. Además, ScalaLab puede llamar directamente y acceder a los resultados del script MATLAB.
La principal diferencia con las bibliotecas informáticas anteriores es que ScalaLab utiliza su propio lenguaje específico de dominio llamado ScalaSci. Scalalab es conveniente porque accede a muchas bibliotecas científicas de Java y Scala, por lo que puede importar fácilmente sus datos y luego usar varios métodos para realizar manipulaciones y cálculos. La mayoría de las cosas son similares a Breeze y Saddle. Además, como en Breeze, hay gráficos que le permiten interpretar más los datos.
Nlp
Numero 4. Epic (Compromisos: 1790, Colaboradores: 15) y Puck (Compromisos: 536, Colaboradores: 1)
Scala tiene algunas buenas bibliotecas de procesamiento de lenguaje natural como parte de ScalaNLP, incluidas Epic y Puck. Estas bibliotecas se utilizan principalmente como herramientas de análisis de texto. Al mismo tiempo, Puck es más conveniente si necesita analizar miles de ofertas debido a su alta velocidad y al uso de una GPU. Epic también se conoce como un marco de pronóstico que utiliza pronósticos estructurados para construir sistemas complejos.
Visualización
No 5. Breeze-viz (Compromisos: 29, Colaboradores: 3)
Como su nombre indica, Breeze-viz es una biblioteca de visualización desarrollada por Breeze para Scala. Se basa en la conocida biblioteca Java JFreeChart y los gráficos son algo similares a MATLAB. Aunque Breeze-viz tiene muchas menos características que MATLAB, matplotlib en Python o R, es útil para crear modelos y analizar datos.
No 6. Vegas (Compromisos: 210, Contribuyentes: 14)
Otra biblioteca de visualización de datos Scala es Vegas. Es mucho más funcional que Breeze-viz, y le permite realizar algunas transformaciones que son útiles para los gráficos: filtrado, transformaciones y agregaciones. En general, la biblioteca es similar a Bokeh y Plotly en Python.
Vegas le permite escribir código en un estilo declarativo, lo que le permite enfocarse principalmente en determinar qué debe hacerse con los datos y realizar un análisis adicional de las visualizaciones sin preocuparse por implementar el código.

Aprendizaje automático
Número 7. Sonríe (se compromete: 1019, contribuyentes: 21)
El motor estadístico de inteligencia artificial y aprendizaje, o simplemente Smile, es una prometedora biblioteca moderna de aprendizaje automático, algo similar a scikit-learn en Python. Está desarrollado en Java, pero también tiene una API para Scala. La biblioteca es bastante rápida y productiva: uso eficiente de la memoria, un gran conjunto de algoritmos de aprendizaje automático para clasificación, regresión, NNS, selección de funciones, etc.

Numero 8. Spark ML
Una biblioteca de aprendizaje automático que funciona de fábrica en Apache Spark. Spark está escrito en Scala y tiene una API apropiada para todas sus bibliotecas.
Spark ML: a diferencia de Spark MLlib (una biblioteca más antigua), funciona con marcos de datos. También hace posible construir tuberías de varias transformaciones en sus datos. Esto puede considerarse como una secuencia de etapas, donde cada etapa es un Transformador que convierte un marco de datos en otro, o un Estimador, por ejemplo, un algoritmo de aprendizaje automático que se entrena en un marco de datos.
No 9. DeepLearning.scala (Compromisos: 1647, Colaboradores: 14)
DeepLearning.scala es una herramienta alternativa de aprendizaje automático que le permite crear modelos de aprendizaje profundo. La biblioteca utiliza fórmulas matemáticas para crear redes neuronales dinámicas complejas a través de una combinación de programación orientada a objetos y funcional. Utiliza una amplia gama de tipos, así como clases de tipos aplicativos. Este último le permite iniciar múltiples cálculos al mismo tiempo, lo que mejora la productividad.
No 10. Summing Bird (Compromisos: 1772, Colaboradores: 31)
Summingbird es un marco de procesamiento de datos que permite el uso de cálculos MapReduce por lotes y en tiempo real. El principal catalizador para el desarrollo del lenguaje fueron los desarrolladores de Twitter, que a menudo escribieron el mismo código dos veces: primero para el procesamiento por lotes, luego nuevamente para la transmisión.
Summingbird usa y genera dos tipos de datos: flujos (secuencias infinitas de tuplas) e instantáneas, que en un determinado momento se consideran el estado completo del conjunto de datos. Finalmente, Summingbird proporciona una plataforma para Storm, Scalding y un motor de memoria para fines de prueba.
No 11. PredictionIO (Compromisos: 4343, Contribuyentes: 125)
También vale la pena mencionar el servicio de aprendizaje automático para crear e implementar mecanismos predictivos llamados PredictionIO. Está construido en Apache Spark MLlib y HBase e incluso ha sido calificado en Github como el producto de aprendizaje automático más popular basado en Apache Spark. Le permite crear, evaluar e implementar servicios de manera fácil y eficiente, implementar sus propios modelos de aprendizaje automático e incorporarlos a su servicio.
Otros
No 12. Akka (se compromete: 21430, contribuyentes: 467)
Desarrollado por Scala, Akka es un entorno paralelo para construir aplicaciones JVM distribuidas. Utiliza un modelo basado en actores, donde un actor es un objeto que recibe mensajes y realiza las acciones apropiadas.
La principal diferencia es la capa adicional entre los actores y el marco, que solo requiere que los actores procesen los mensajes, mientras que el marco se encarga de todo lo demás. Todos los actores están organizados jerárquicamente, esto ayuda a los actores a interactuar más efectivamente entre sí y a resolver problemas complejos, dividiéndolos en tareas más pequeñas.
No 13. Slick (Compromisos: 1940, Contribuyentes: 92)
La última biblioteca es Slick, lo que significa el kit de conexión Scala Language-Integrated. Esta es una biblioteca para crear y ejecutar consultas de bases de datos: H2, MySQL, PostgreSQL, etc. Algunas bases de datos están disponibles a través de extensiones slick.
Para construir consultas, Slick proporciona un potente DSL que hace que el código sea como si estuviera usando colecciones Scala. Slick admite consultas SQL simples y uniones fuertemente tipadas de varias tablas. Además, se pueden usar subconsultas simples para crear otras más complejas.
Conclusión
En este artículo, hemos identificado y descrito brevemente algunas bibliotecas de Scala que pueden ser muy útiles para realizar tareas básicas de procesamiento de datos.
Si tiene experiencia trabajando con otras bibliotecas o plataformas Scala útiles que vale la pena agregar a esta lista, no dude en compartirlas en los comentarios.