El 27 de abril, en la conferencia
Strike-2019 , en el marco de la sección DevOps, se realizó un informe titulado "Autoescalado y gestión de recursos en Kubernetes". Habla sobre cómo usar K8 para garantizar una alta disponibilidad de aplicaciones y garantizar su máximo rendimiento.

Por tradición, nos complace presentar un
video con un informe (44 minutos, mucho más informativo que el artículo) y el extracto principal en forma de texto. Vamos!
Analizaremos el tema del informe por palabras y comenzaremos desde el final.
Kubernetes
Tengamos contenedores Docker en el host. Por qué Para garantizar la repetibilidad y el aislamiento, que a su vez permite una implementación simple y buena, CI / CD. Tenemos muchas máquinas con contenedores.
¿Qué le da en este caso a Kubernetes?
- Dejamos de pensar en estas máquinas y comenzamos a trabajar con la "nube", un grupo de contenedores o pods (grupos de contenedores).
- Además, ni siquiera pensamos en pods individuales, sino que gestionamos grupos más grandes. Tales primitivas de alto nivel nos permiten decir que hay una plantilla para lanzar una determinada carga de trabajo, pero el número requerido de instancias para su lanzamiento. Si posteriormente cambiamos la plantilla, todas las instancias también cambiarán.
- Usando la API declarativa, en lugar de ejecutar una secuencia de comandos específicos, describimos el "dispositivo mundial" (en YAML) que crea Kubernetes. Y de nuevo: cuando la descripción cambia, su visualización real también cambiará.
Gestión de recursos
CPU
Ejecutemos nginx, php-fpm y mysql en el servidor. Estos servicios tendrán incluso más procesos en ejecución, cada uno de los cuales requiere recursos informáticos:
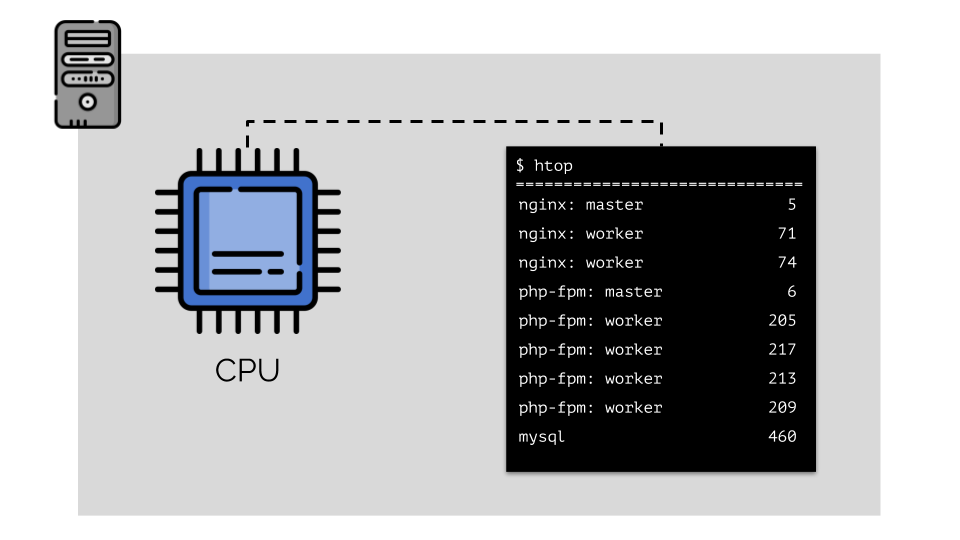 (los números en la diapositiva son "loros", la necesidad abstracta de cada proceso de potencia informática)
(los números en la diapositiva son "loros", la necesidad abstracta de cada proceso de potencia informática)Para que sea conveniente trabajar con esto, es lógico combinar procesos en grupos (por ejemplo, todos los procesos nginx en un grupo "nginx"). Una manera simple y obvia de hacer esto es colocar cada grupo en un contenedor:
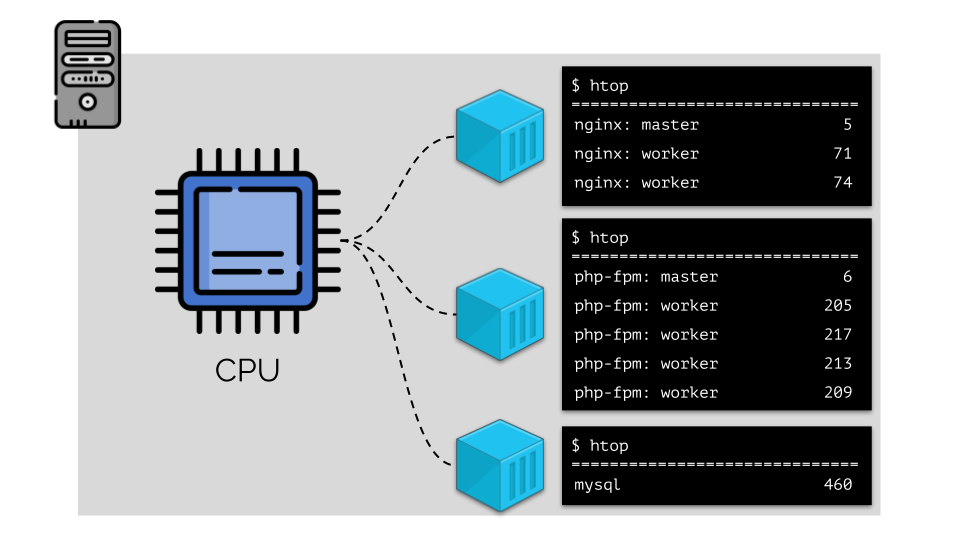
Para continuar, debe recordar qué es un contenedor (en Linux). Su aparición fue posible gracias a tres características clave en el núcleo, implementadas durante mucho tiempo:
capacidades ,
espacios de nombres y
cgroups . Y otras tecnologías (incluyendo "shells" convenientes como Docker) contribuyeron a un mayor desarrollo:
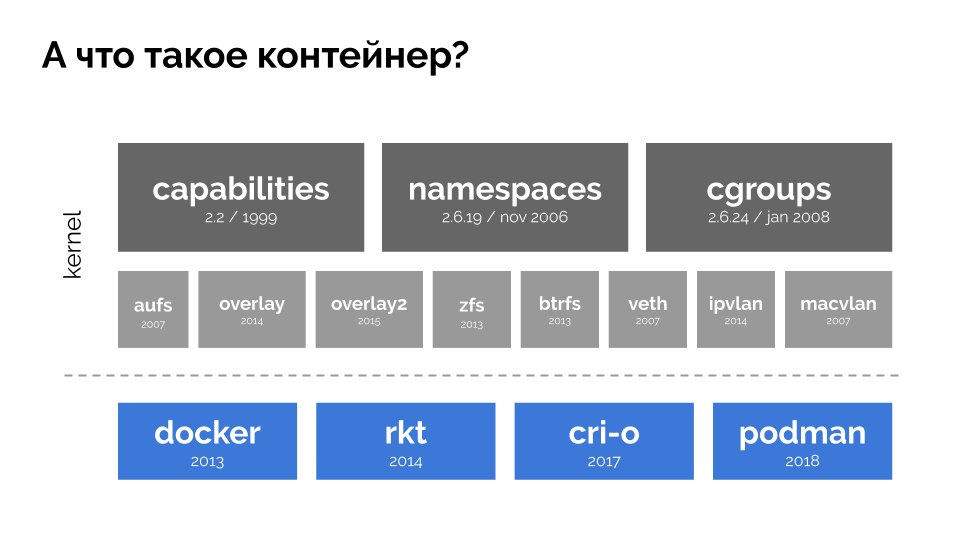
En el contexto del informe, solo estamos interesados en
cgroups , porque los grupos de control son parte de la funcionalidad de los contenedores (Docker, etc.) que implementa la gestión de recursos. Los procesos, unidos en grupos, como queríamos, son los grupos de control.
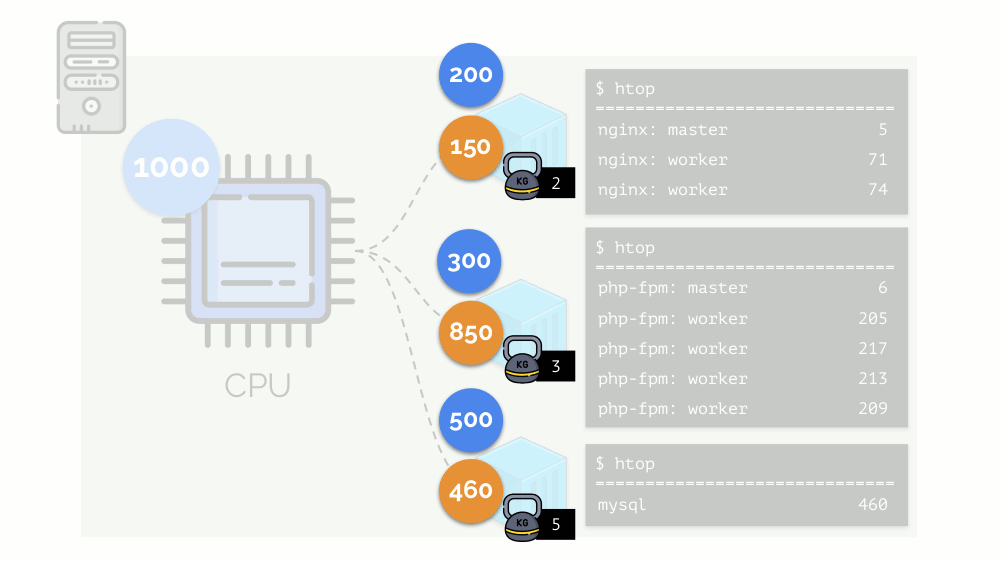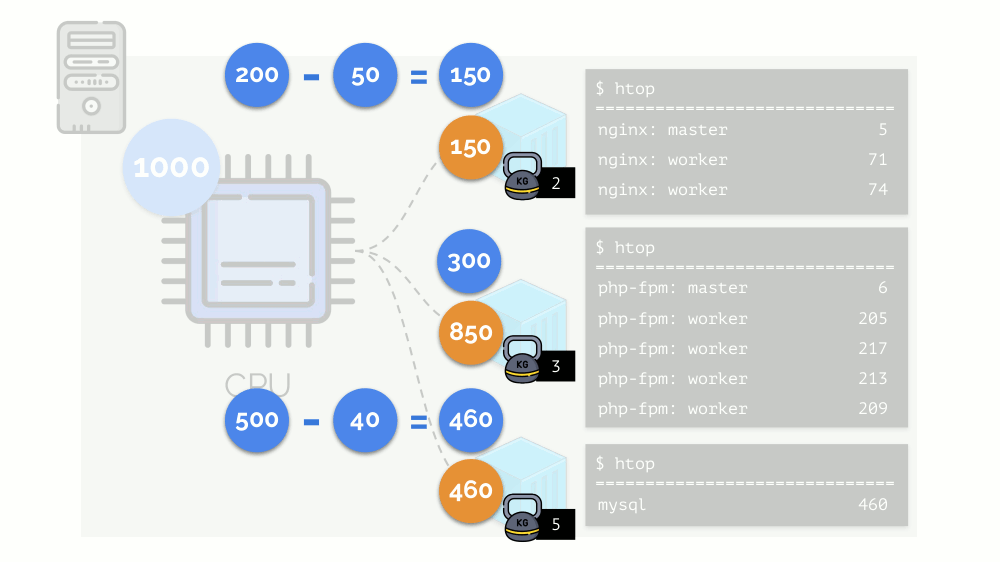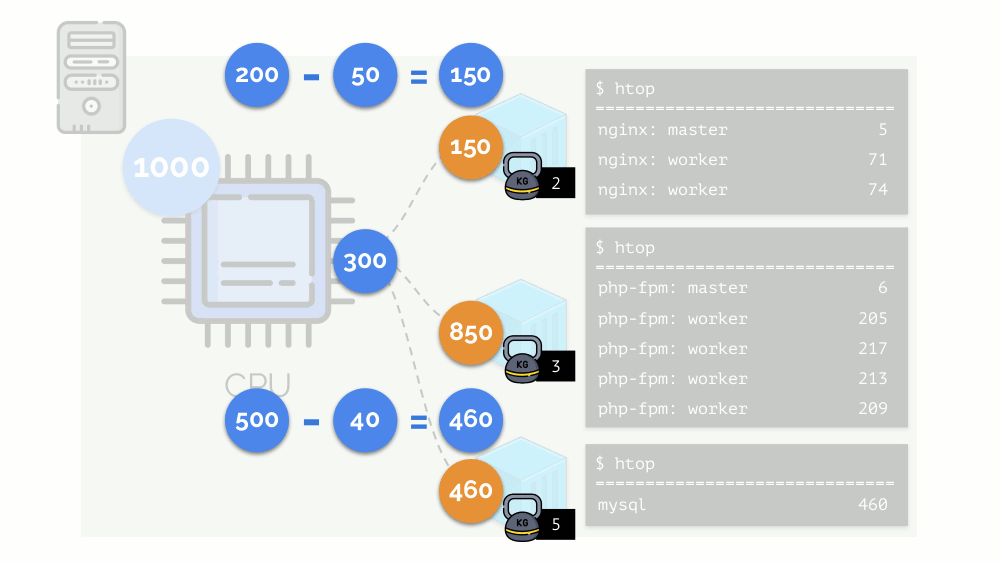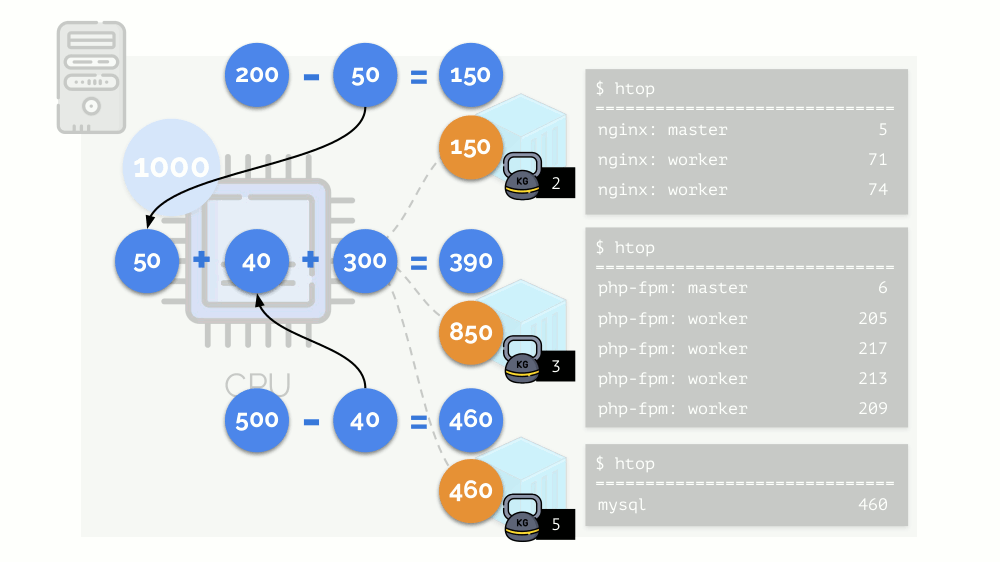
Volvamos a los requisitos de CPU para estos procesos, y ahora para los grupos de procesos:
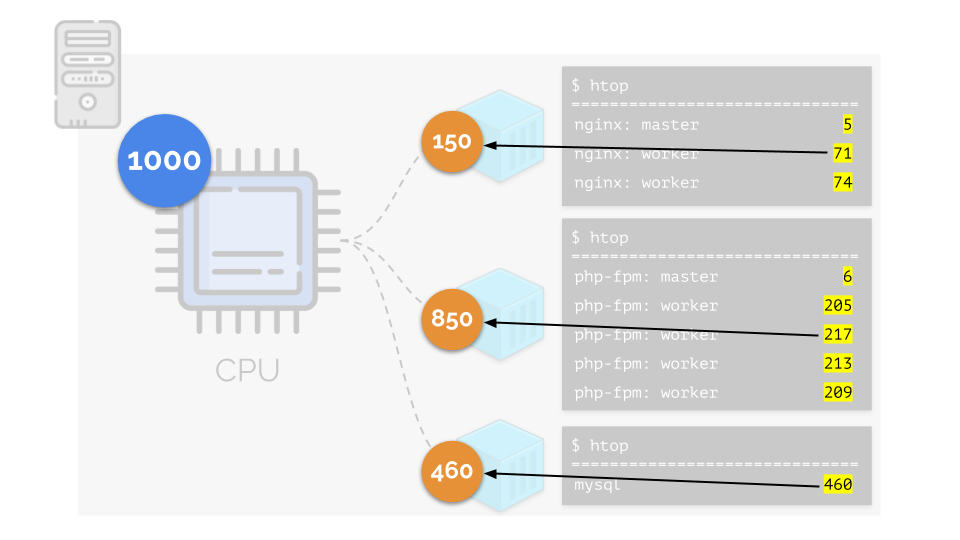 (Repito que todos los números son una expresión abstracta de los requisitos de recursos)
(Repito que todos los números son una expresión abstracta de los requisitos de recursos)Al mismo tiempo, la CPU en sí tiene un cierto recurso final
(en el ejemplo es 1000) , que puede no ser suficiente para todos (la suma de las necesidades de todos los grupos es 150 + 850 + 460 = 1460). ¿Qué pasará en este caso?
El núcleo comienza a distribuir recursos y lo hace "honestamente", dando la misma cantidad de recursos a cada grupo. Pero en el primer caso hay más de lo necesario (333> 150), por lo que el exceso (333-150 = 183) permanece en reserva, que también se distribuye por igual entre otros dos contenedores:
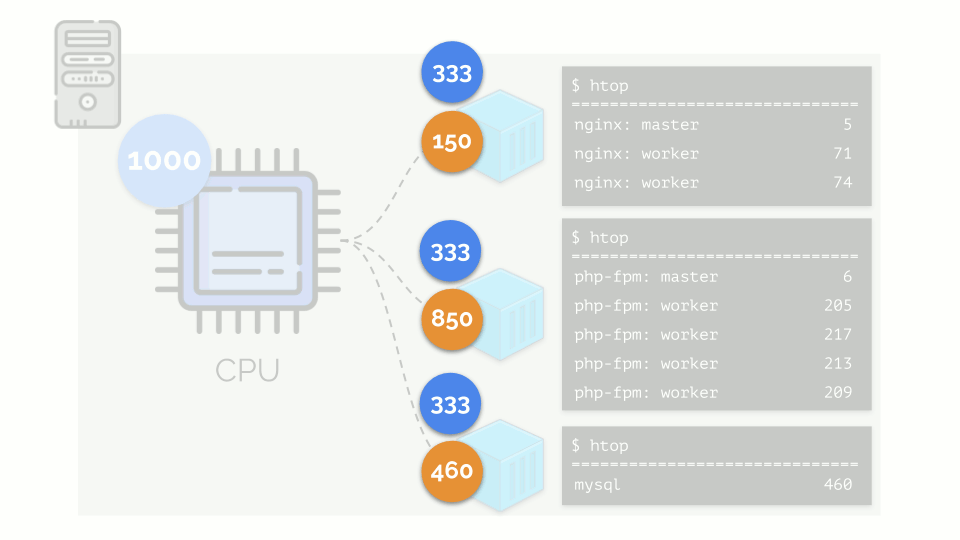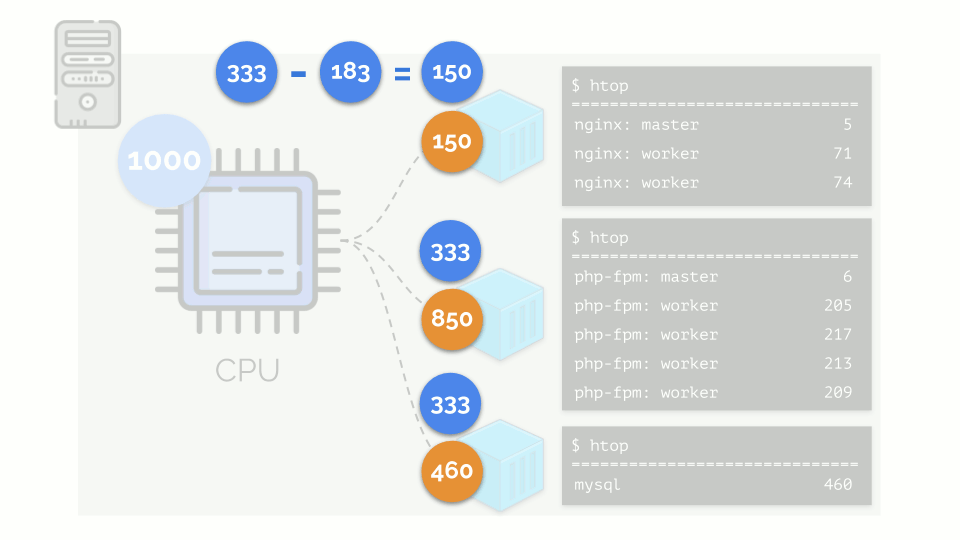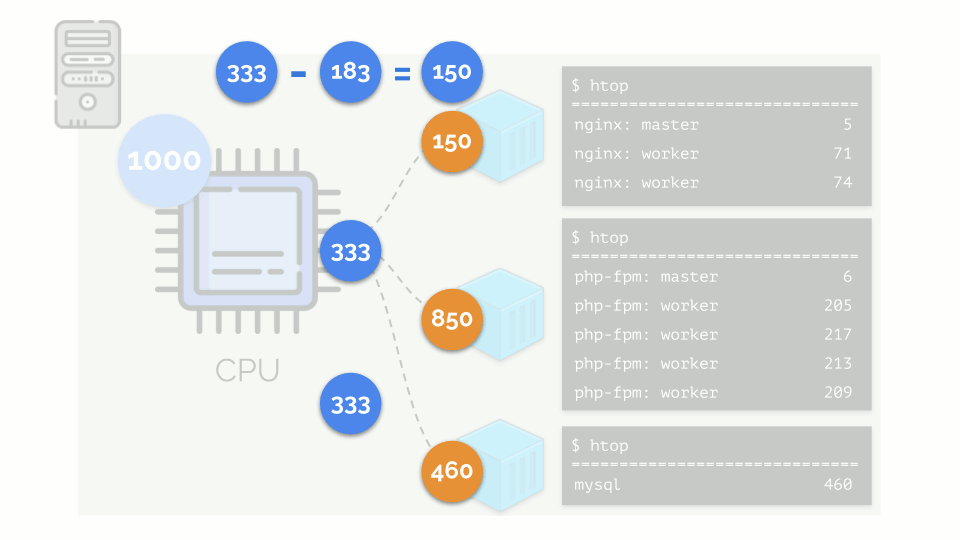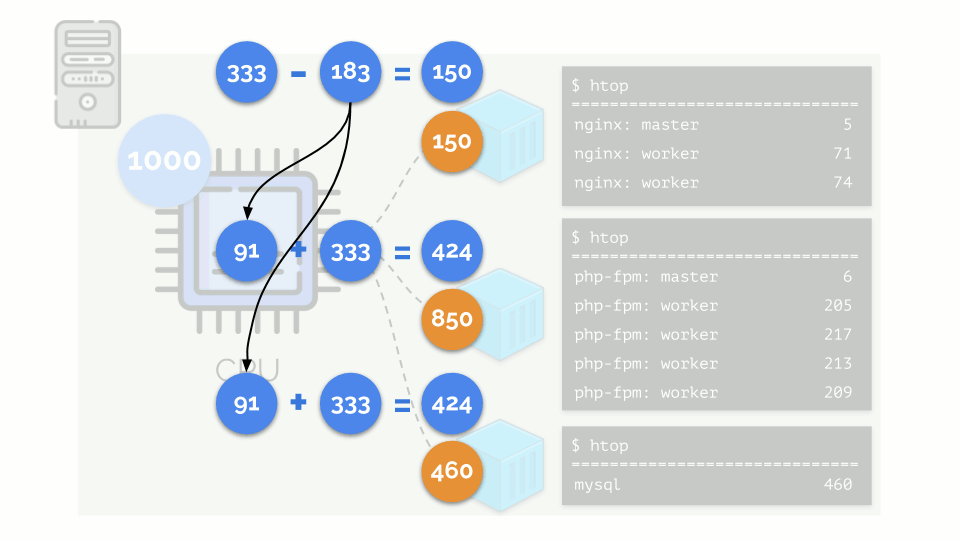
Como resultado: el primer contenedor tenía suficientes recursos, el segundo, no era suficiente, el tercero, no era suficiente. Este es el resultado del programador
"honesto" en Linux -
CFS . Su trabajo se puede regular asignando
peso a cada uno de los contenedores. Por ejemplo, así:
Veamos el caso de la falta de recursos en el segundo contenedor (php-fpm). Todos los recursos del contenedor se distribuyen entre los procesos por igual. Como resultado, el proceso maestro funciona bien y todos los trabajadores disminuyen la velocidad, recibiendo menos de la mitad de lo que se necesita:
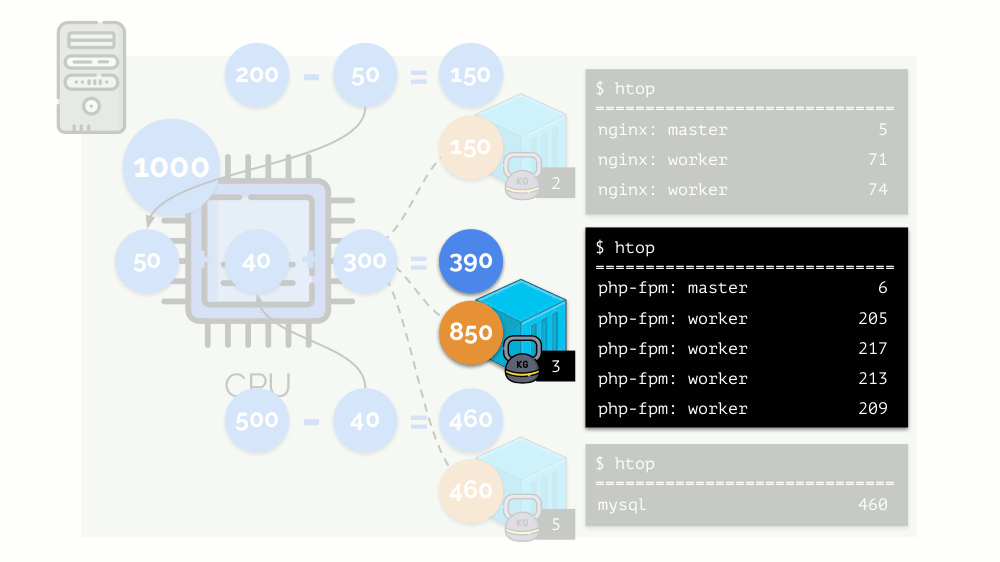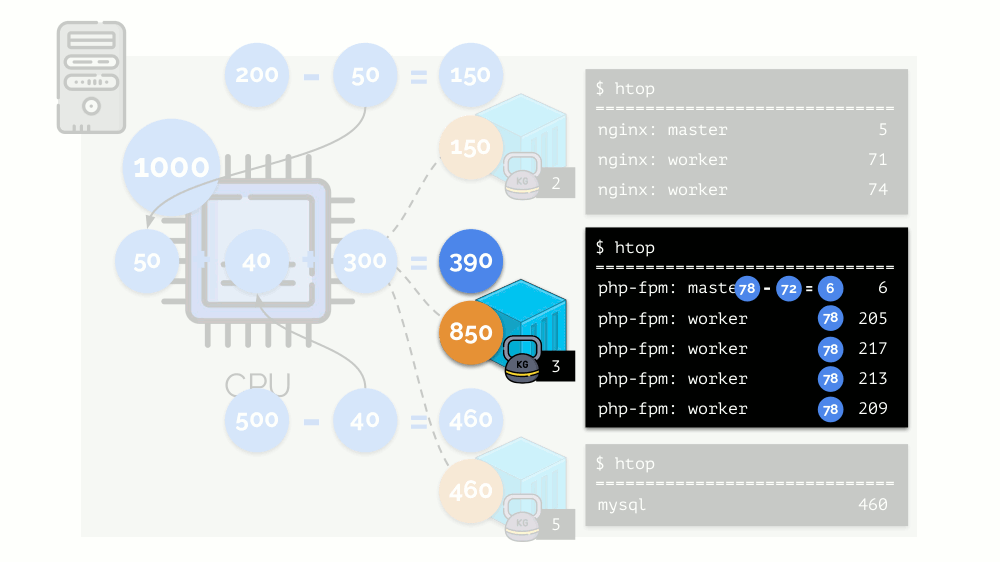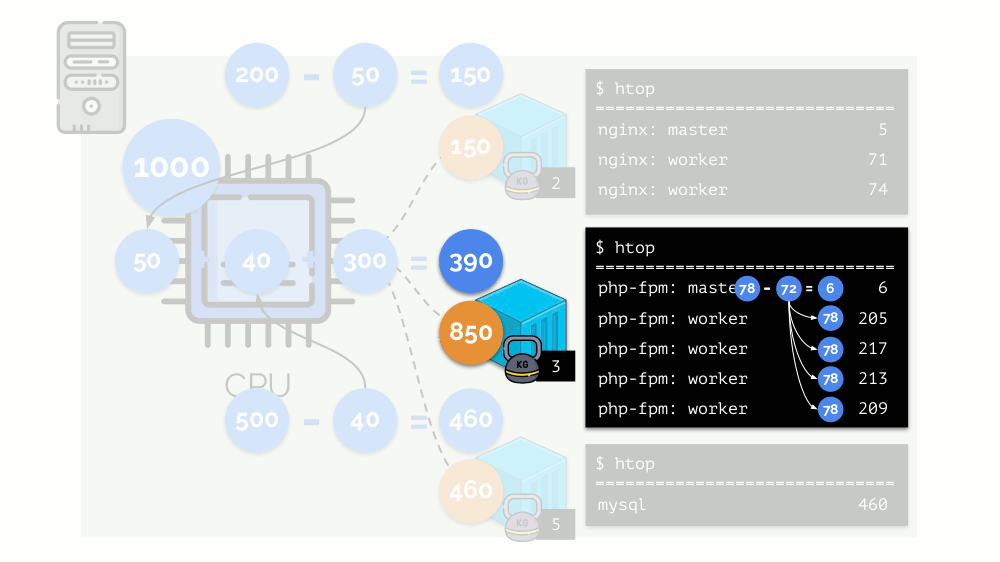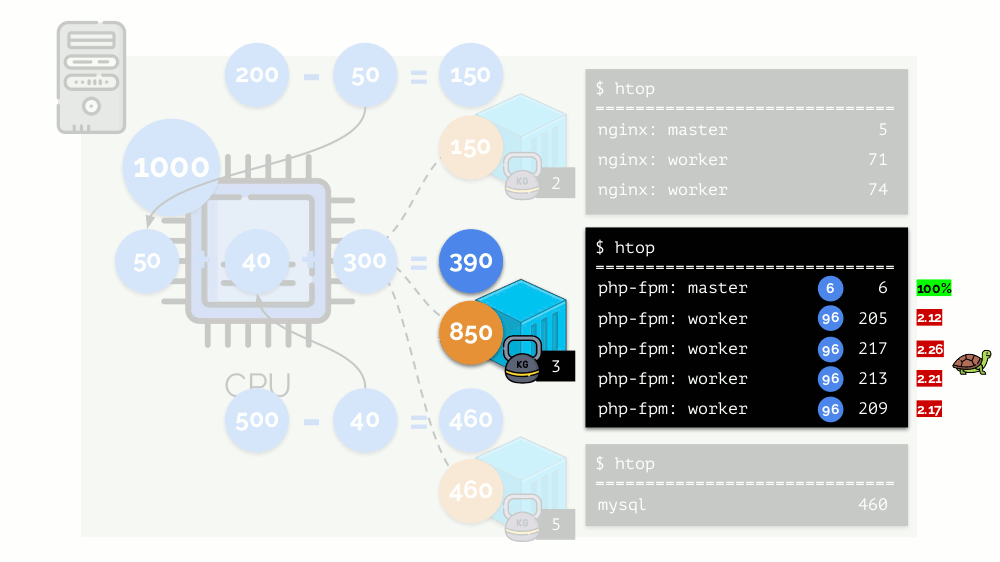
Así es como funciona el planificador CFS. Los pesos que asignamos a los contenedores se denominarán
solicitudes en el futuro. Por qué, ver a continuación.
Echemos un vistazo a toda la situación desde el otro lado. Como saben, todos los caminos conducen a Roma, y en el caso de una computadora a la CPU. Una CPU, muchas tareas: necesita un semáforo. La forma más fácil de administrar los recursos es "semáforo": le dan a un proceso un tiempo de acceso fijo a la CPU, luego al siguiente, etc.
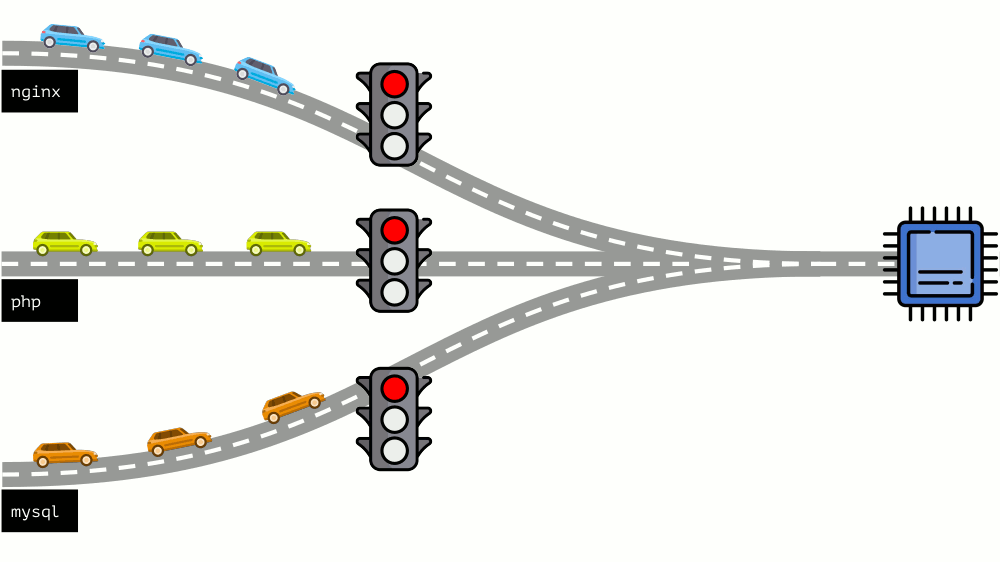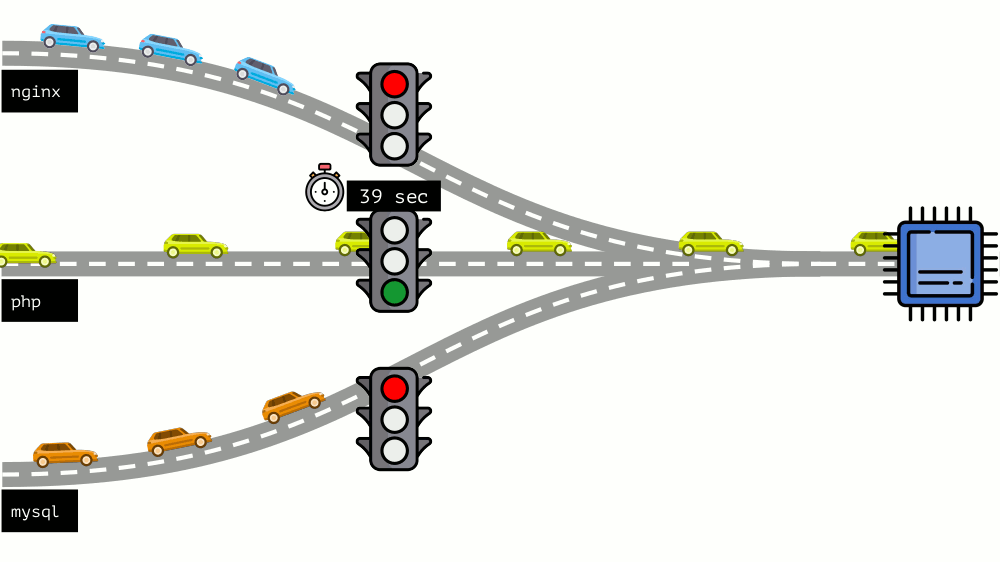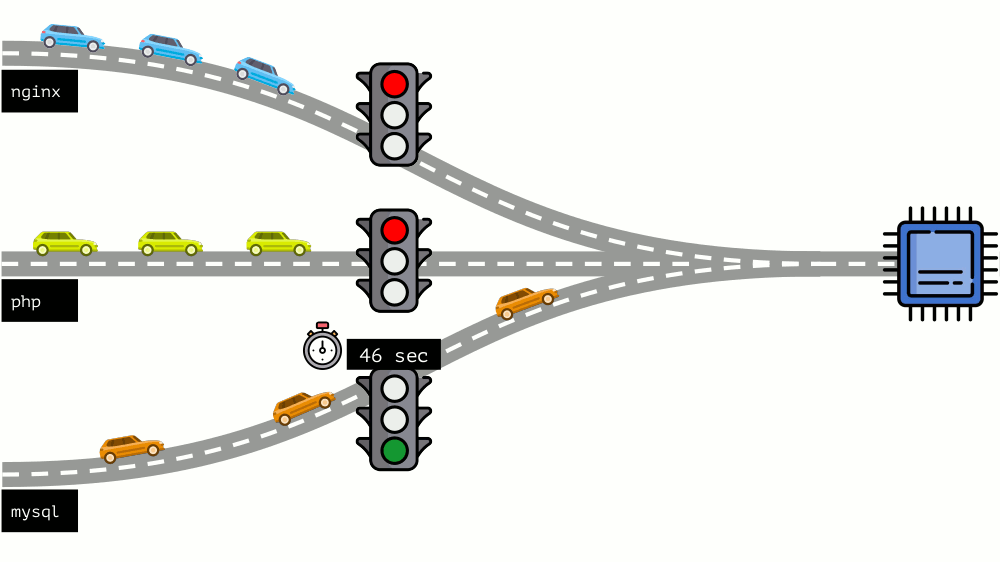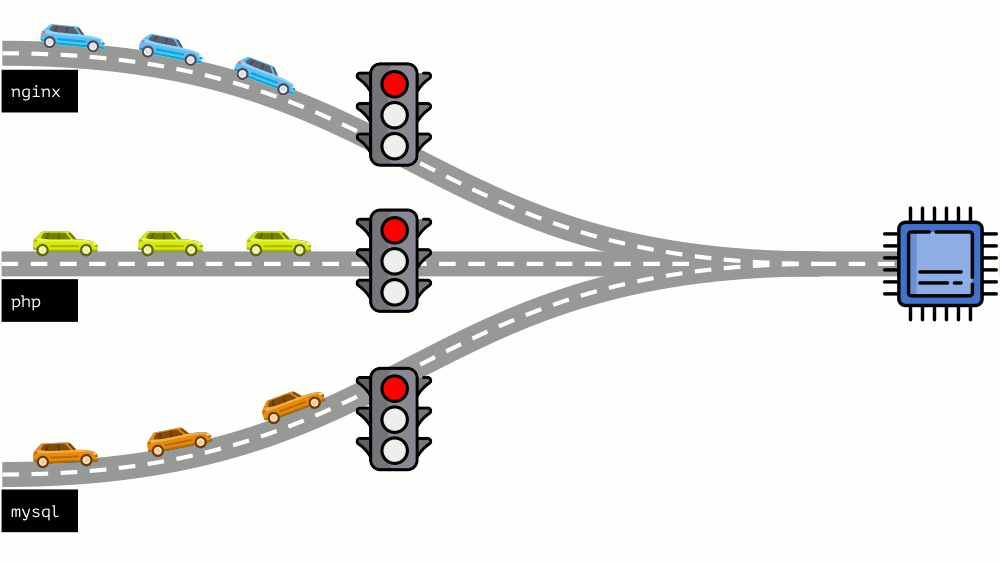
Este enfoque se llama
limitación dura . Recuérdalo solo como
límites . Sin embargo, si distribuye límites a todos los contenedores, surge un problema: mysql viajaba por el camino y en algún momento su necesidad de una CPU terminó, pero todos los demás procesos se vieron obligados a esperar mientras la CPU estaba
inactiva .
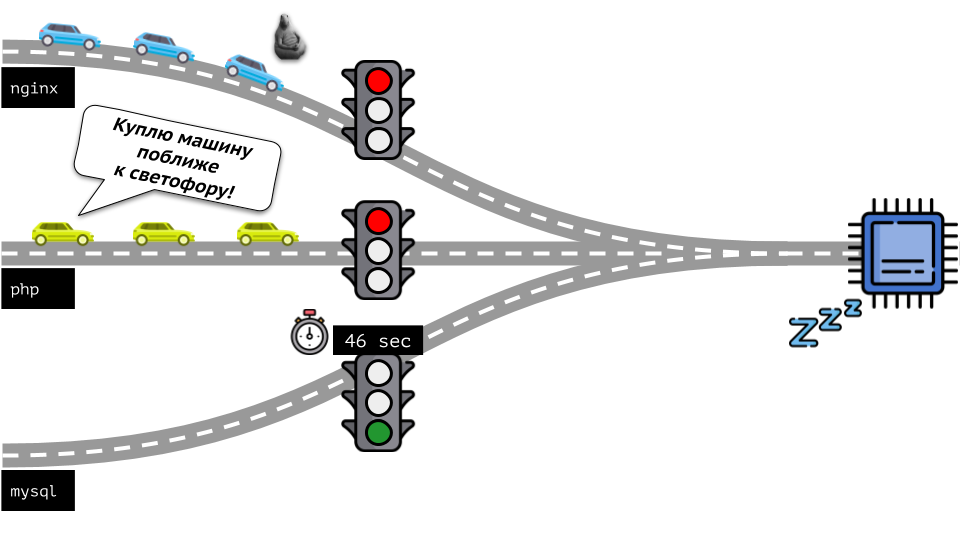
Volvamos al kernel de Linux y su interacción con la CPU: la imagen general es la siguiente:
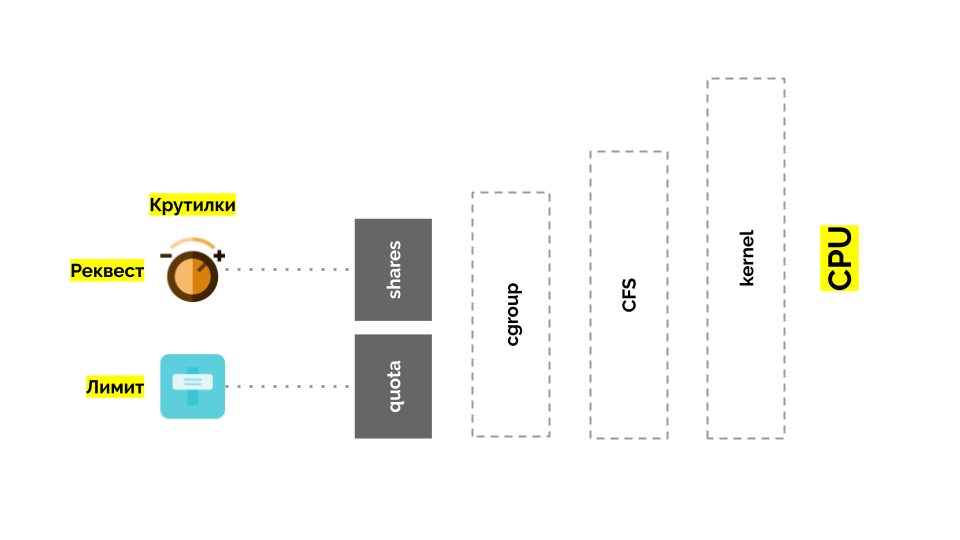
Cgroup tiene dos configuraciones: de hecho, estos son dos simples "giros" que le permiten determinar:
- el peso del contenedor (solicitud) es acciones ;
- un porcentaje del tiempo total de CPU para trabajar en tareas de contenedor (límites) es la cuota .
¿Cómo medir la CPU?
Hay diferentes formas:
- ¿Qué son los loros? Nadie lo sabe, cada vez que necesita estar de acuerdo.
- El interés es más claro, pero relativo: el 50% de un servidor con 4 núcleos y 20 núcleos son cosas completamente diferentes.
- Puede usar los pesos ya mencionados que Linux conoce, pero también son relativos.
- La opción más adecuada es medir los recursos informáticos en segundos . Es decir en segundos de tiempo de procesador en relación con segundos de tiempo real: dieron 1 segundo de tiempo de procesador en 1 segundo real; este es un núcleo de CPU completo.
Para hacerlo aún más fácil de decir, comenzaron a medir directamente en los
núcleos , lo que significa el tiempo de CPU en relación con el real. Dado que Linux comprende los pesos en lugar de los núcleos / tiempo del procesador, se necesitaba un mecanismo de traducción de uno a otro.
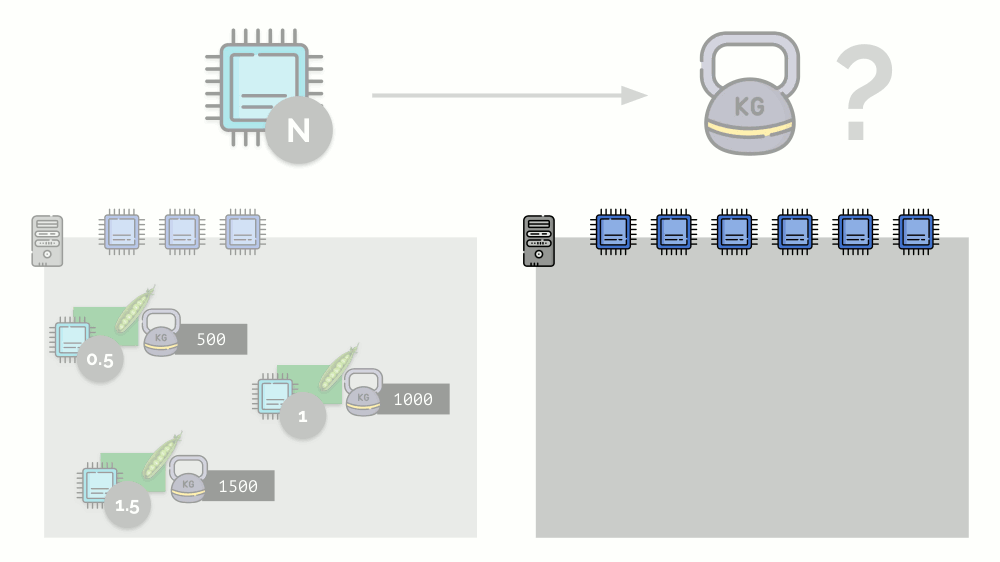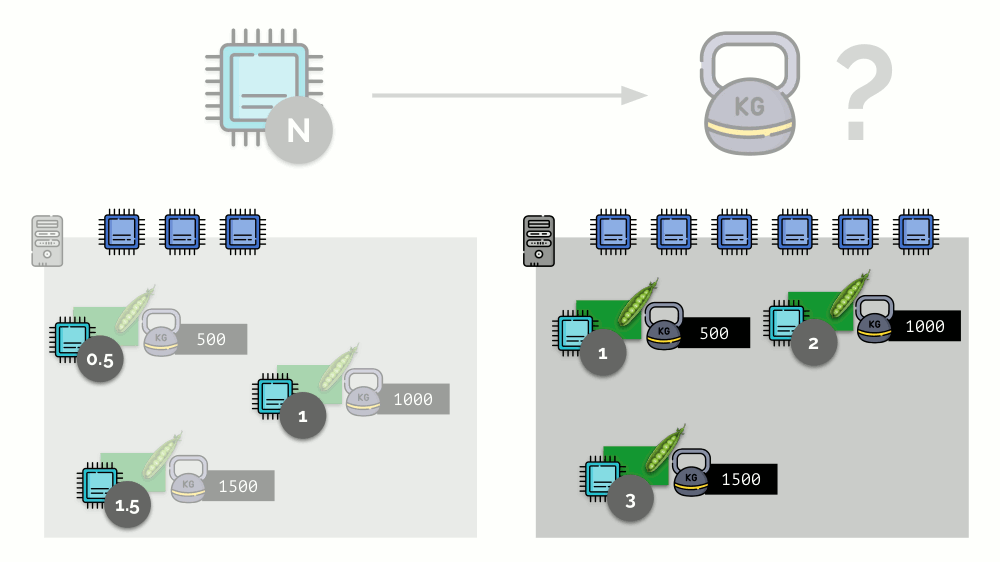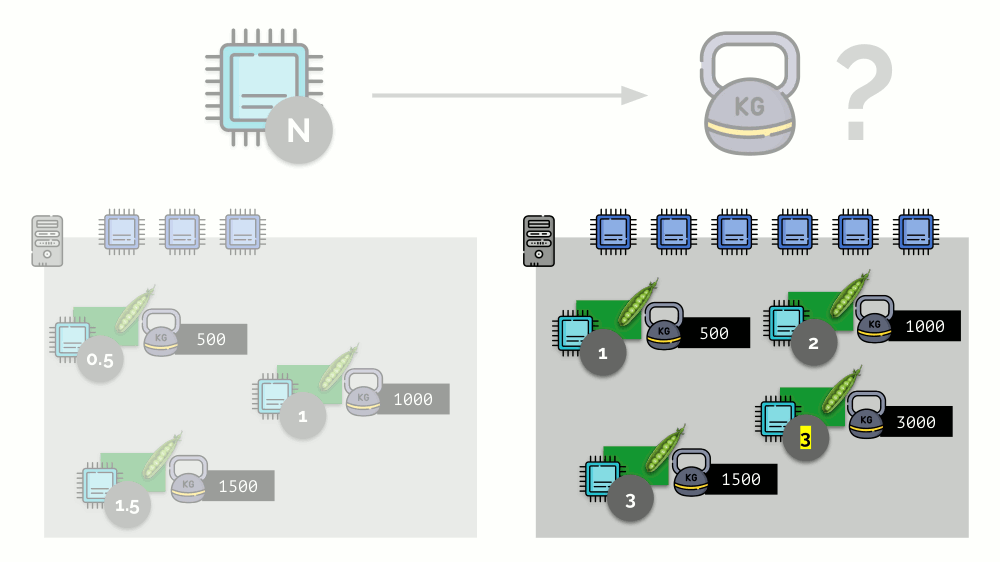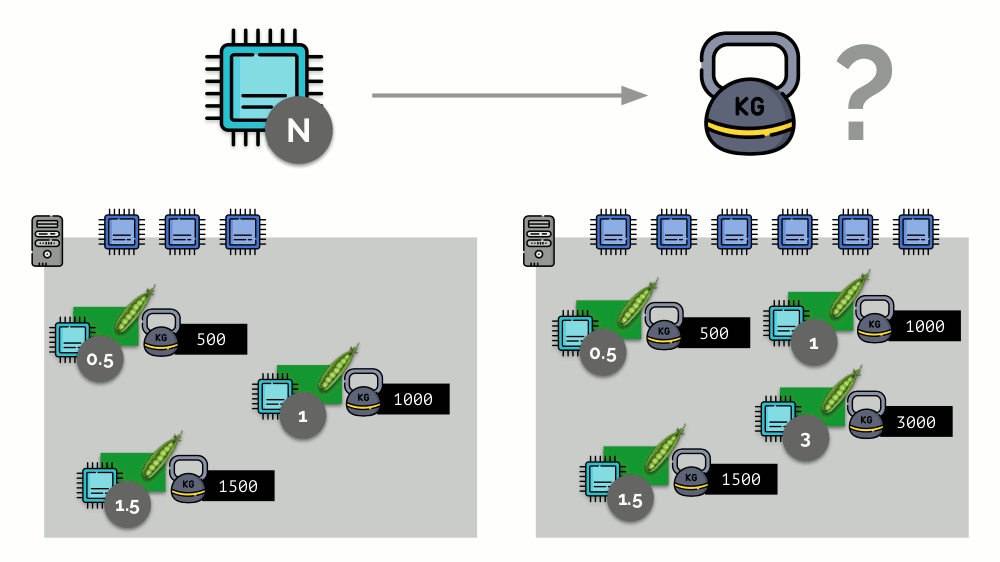
Considere un ejemplo simple con un servidor con 3 núcleos de CPU, donde tres pods seleccionarán pesos (500, 1000 y 1500) que se convertirán fácilmente a las partes correspondientes de los núcleos asignados a ellos (0.5, 1 y 1.5).
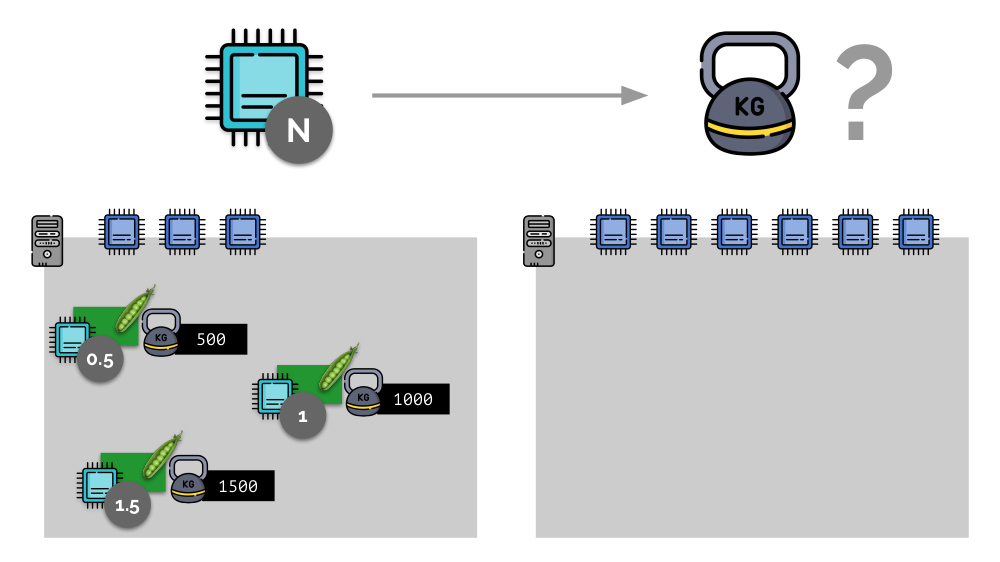
Si toma un segundo servidor, donde habrá el doble de núcleos (6), y coloca los mismos pods allí, la distribución de núcleos se puede calcular fácilmente simplemente multiplicando por 2 (1, 2 y 3, respectivamente). Pero ocurre un punto importante cuando aparece el cuarto módulo en este servidor, cuyo peso puede ser 3000 por conveniencia. Elimina algunos de los recursos de la CPU (la mitad de los núcleos), y el resto de los módulos los cuentan (reducir a la mitad):
Kubernetes y recursos de CPU
En Kubernetes, los recursos de la CPU generalmente se miden en
mili-núcleos , es decir. Se toman 0.001 granos como el peso base.
(Lo mismo en la terminología de Linux / cgroups se llama recurso compartido de CPU, aunque, para ser más precisos, 1000 CPU = 1024 recursos
compartidos de CPU). K8s se asegura de no colocar más pods en el servidor que recursos de CPU para la suma de pesos Todas las vainas.
¿Cómo va esto? Cuando se agrega un servidor a un clúster de Kubernetes, informa cuántos núcleos de CPU tiene disponibles. Y al crear un nuevo pod, el programador de Kubernetes sabe cuántos núcleos necesita este pod. Por lo tanto, el pod se definirá en el servidor, donde hay suficientes núcleos.
¿Qué sucederá si
no se especifica la solicitud (es decir, el pod no determina la cantidad de núcleos que necesita)? Veamos cómo Kubernetes generalmente cuenta los recursos.
El pod puede especificar tanto las solicitudes (planificador CFS) como los límites (¿recuerda el semáforo?):
- Si son iguales, la clase de QoS garantizada se asigna al pod. Tal cantidad de granos siempre disponibles para él está garantizada.
- Si la solicitud es inferior al límite, la clase de QoS es burstable . Es decir esperamos que el pod, por ejemplo, siempre use 1 núcleo, pero este valor no es una limitación: a veces el pod puede usar más (cuando hay recursos libres en el servidor para esto).
- También existe la clase de QoS de mejor esfuerzo : los pods para los que no se especifica la solicitud pertenecen a ella. Los recursos se les dan al final.
El recuerdo
La situación es similar con la memoria, pero un poco diferente: después de todo, la naturaleza de estos recursos es diferente. En general, la analogía es la siguiente:
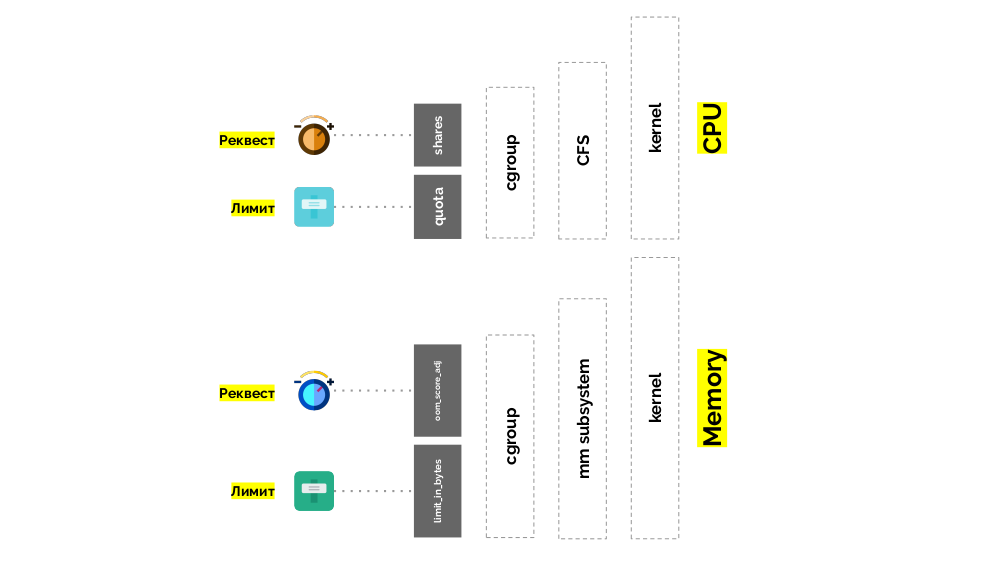
Veamos cómo se implementan las solicitudes en la memoria. Deje que los pods vivan en el servidor, cambiando la memoria consumida, hasta que uno de ellos se vuelva tan grande que la memoria se agote. En este caso, el asesino OOM aparece y mata el proceso más grande:
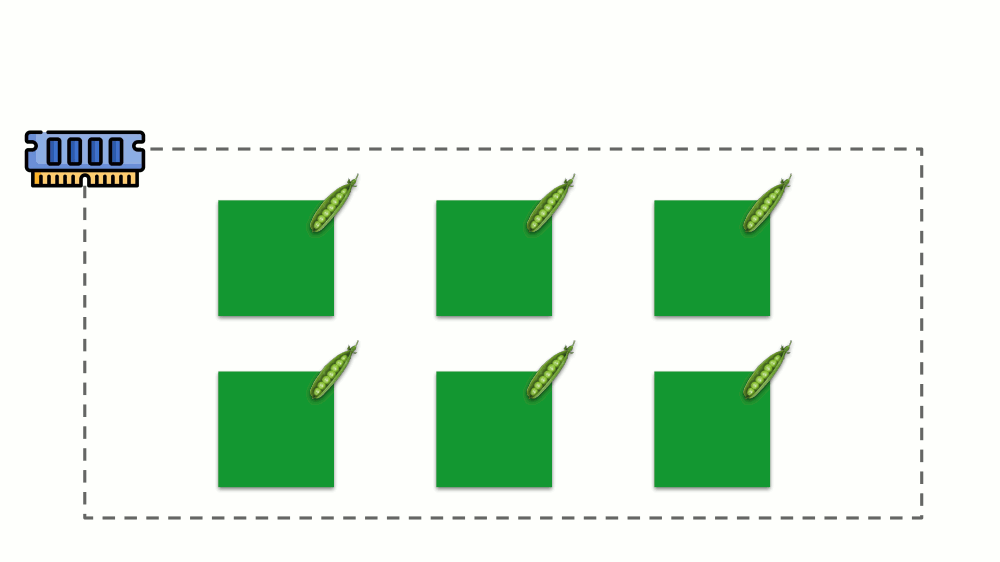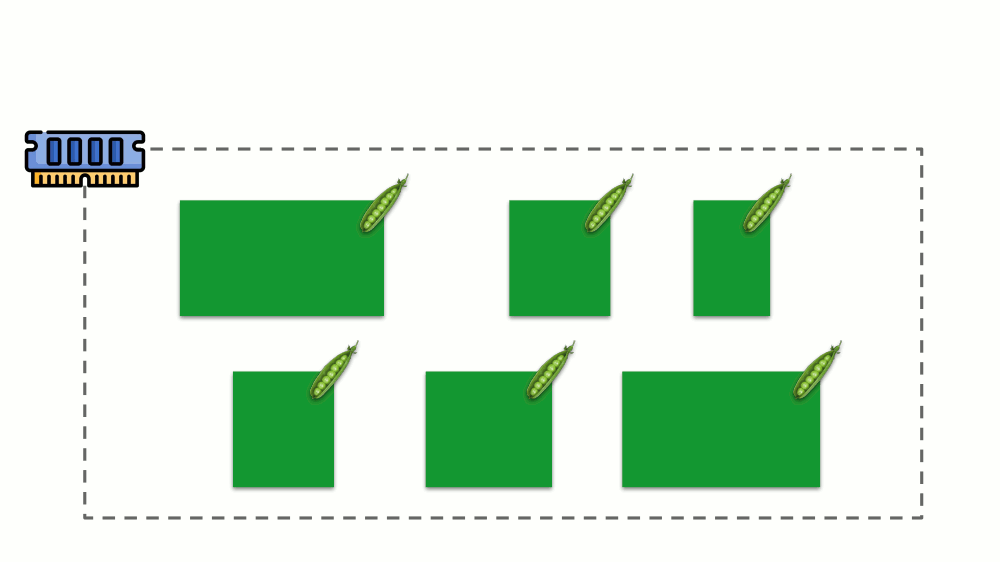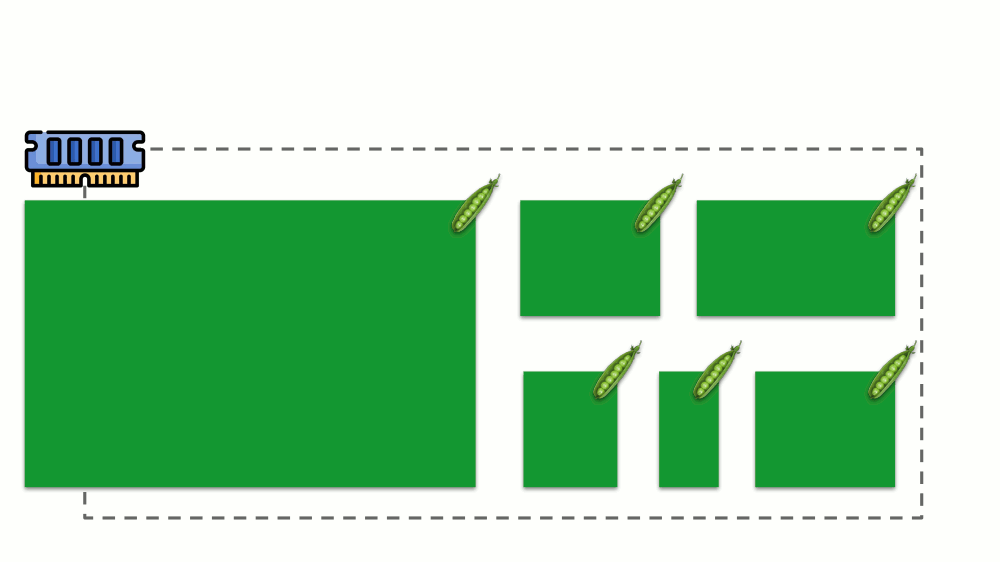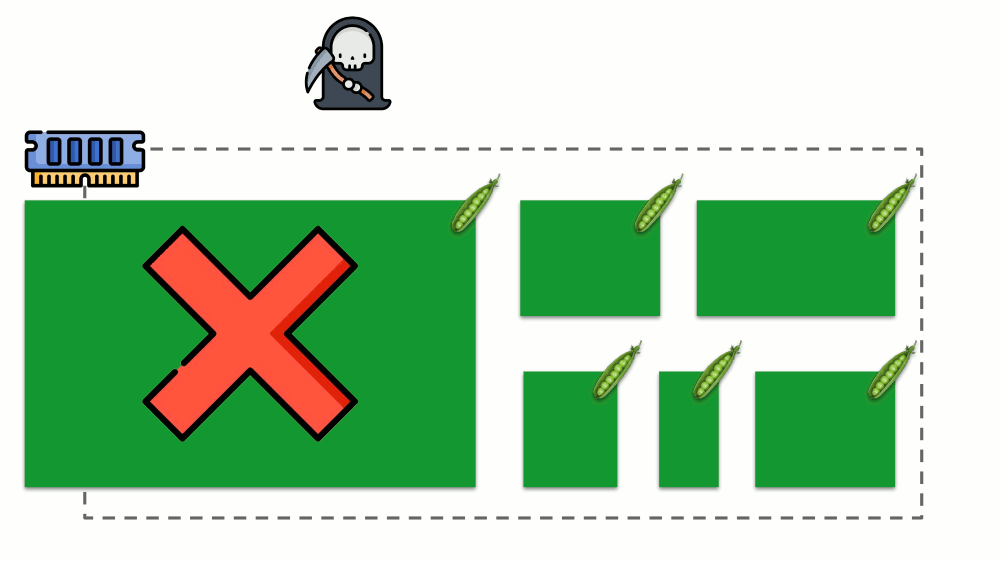
Esto no siempre nos conviene, por lo tanto, es posible regular qué procesos son importantes para nosotros y no deben ser eliminados. Para hacer esto, use el parámetro
oom_score_adj .
Volvamos a las clases de QoS de la CPU y dibujemos una analogía con los valores oom_score_adj, que determinan las prioridades de consumo de memoria para los pods:
- El valor más bajo de oom_score_adj de un pod es -998, lo que significa que dicho pod debería ser eliminado en último lugar, esto está garantizado .
- El más alto, 1000, es el mejor esfuerzo , esas cápsulas se matan antes que nadie.
- Para calcular el resto de los valores ( burstable ), hay una fórmula cuya esencia se reduce al hecho de que cuanto más pod ha solicitado recursos, menos posibilidades hay de que se elimine.

El segundo "giro" -
limit_in_bytes - para los límites. Todo es más simple: simplemente asignamos la cantidad máxima de memoria a emitir, y aquí (a diferencia de la CPU) no hay duda de en qué se mide (memoria).
Total
Se establecen solicitudes y
limits para cada pod en Kubernetes, ambos parámetros para la CPU y para la memoria:
- según las solicitudes, el planificador de Kubernetes funciona, que distribuye pods entre servidores;
- basado en todos los parámetros, se determina la clase QodS del pod;
- Los pesos relativos se calculan en función de las solicitudes de CPU;
- Según las solicitudes de la CPU, se configura un planificador CFS;
- Según las solicitudes de memoria, se configura el asesino OOM;
- Según los límites de la CPU, se configura un "semáforo";
- según los límites de memoria, se establece un límite en cgroup.
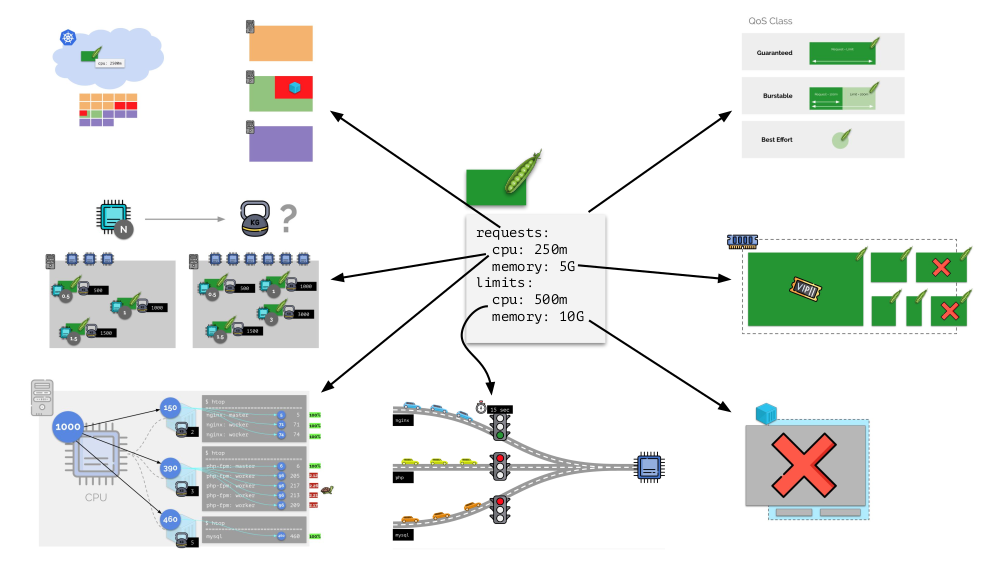
En general, esta imagen responde a todas las preguntas sobre cómo se lleva a cabo la parte principal de la gestión de recursos en Kubernetes.
Autoescalado
K8S Cluster-Autoscaler
Imagine que todo el clúster ya está ocupado y se debe crear un nuevo pod. Si bien el pod no puede aparecer, se cuelga en el estado
Pendiente . Para que parezca, podemos conectar un nuevo servidor al clúster o ... poner cluster-autoescaler, que lo hará por nosotros: pedir una máquina virtual al proveedor de la nube (por solicitud de la API) y conectarla al clúster, después de lo cual se agregará el pod .
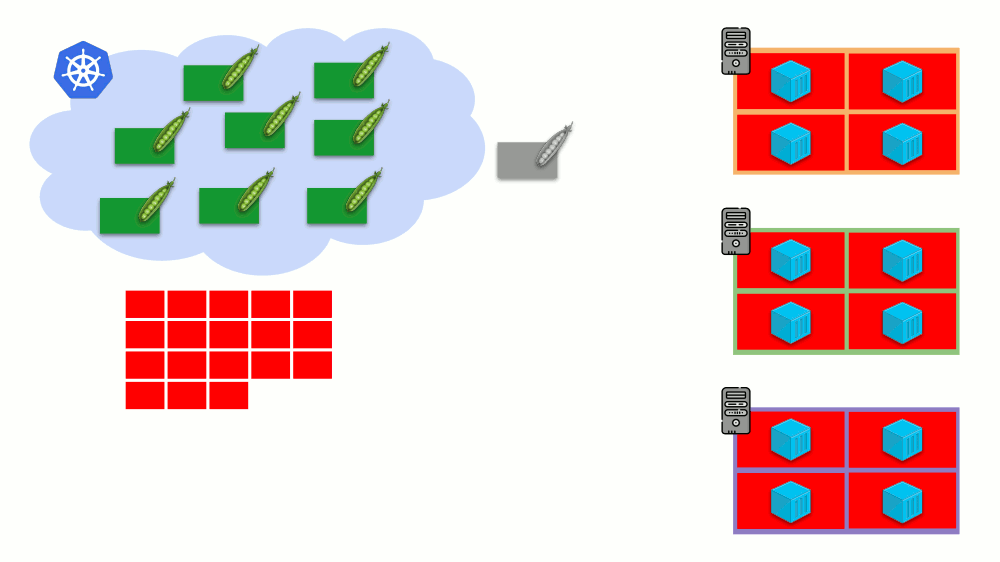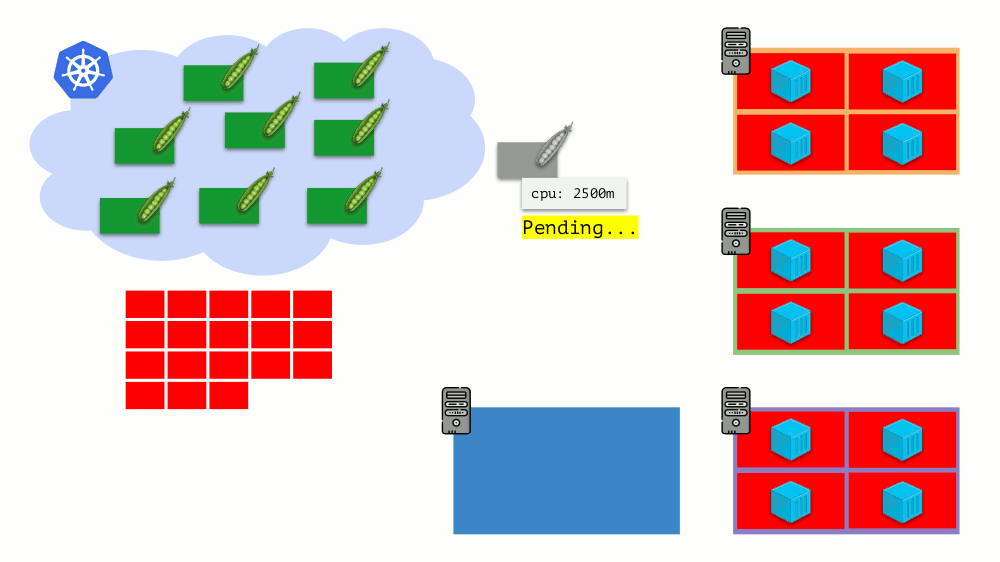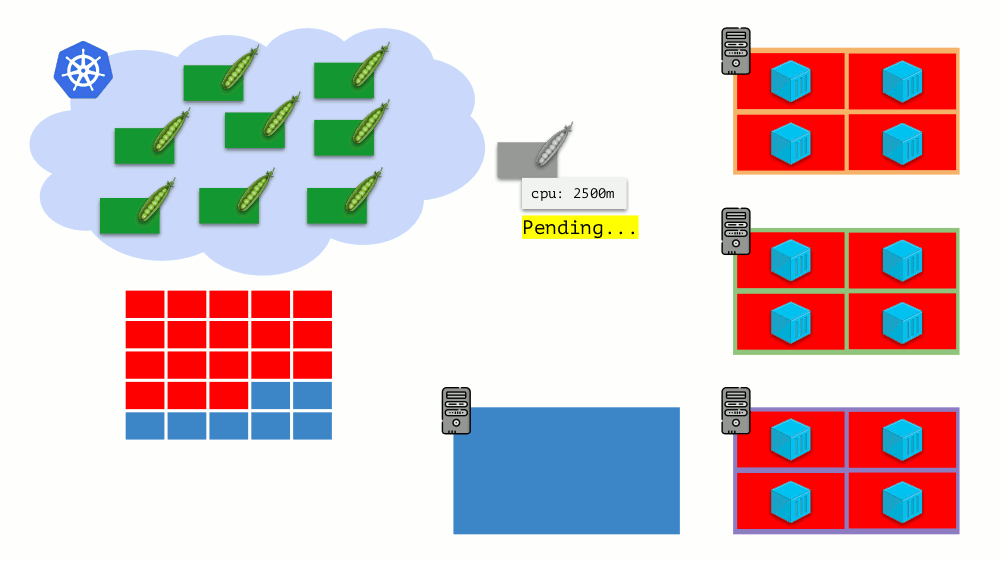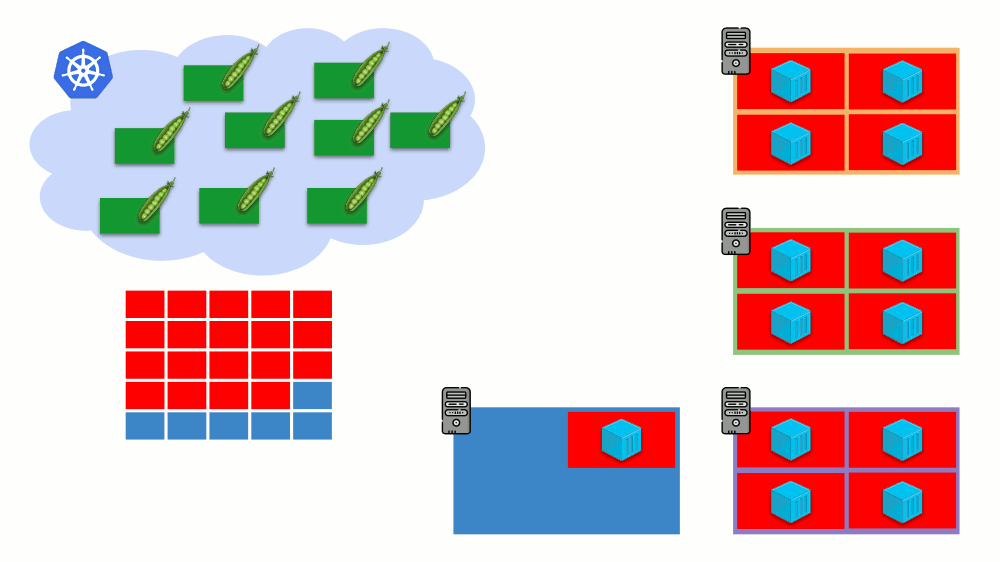
Esta es la escala automática del clúster de Kubernetes, que funciona muy bien (en nuestra experiencia). Sin embargo, como en otros lugares, hay algunos matices aquí ...
Mientras estábamos aumentando el tamaño del clúster, todo estaba bien, pero ¿qué sucede cuando el clúster
comenzó a liberarse ? El problema es que la migración de pods (a hosts libres) es técnicamente difícil y costosa en términos de recursos. Kubernetes tiene un enfoque completamente diferente.
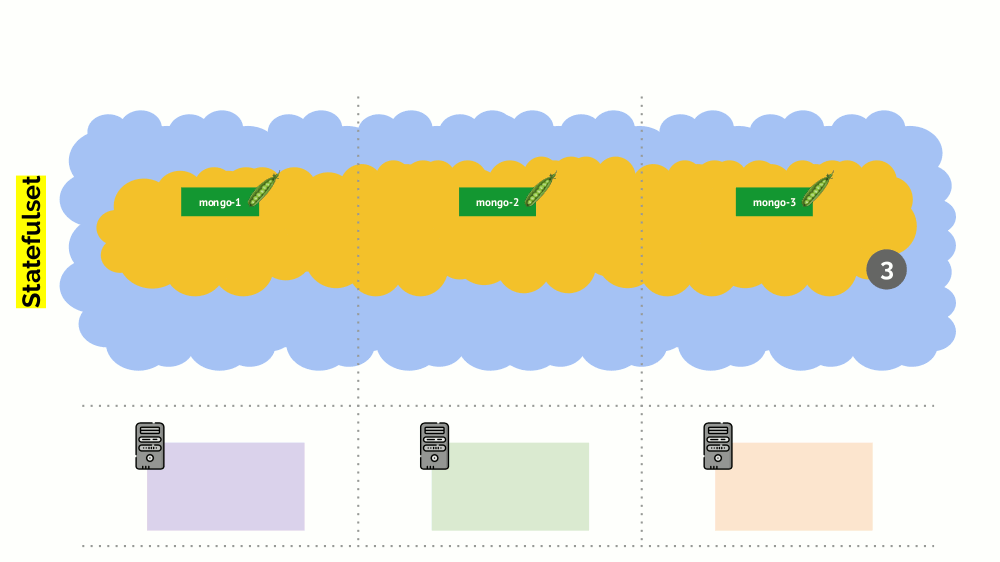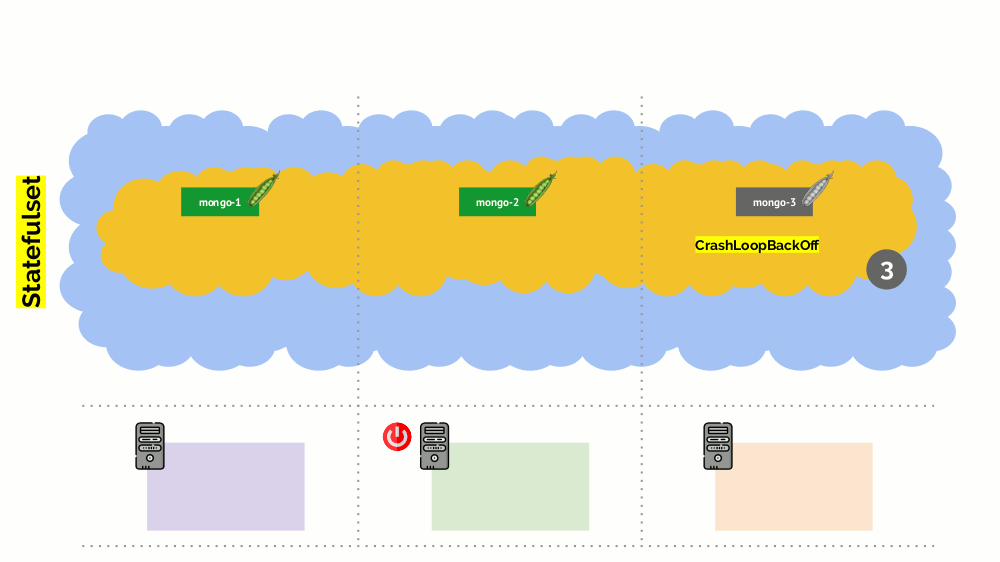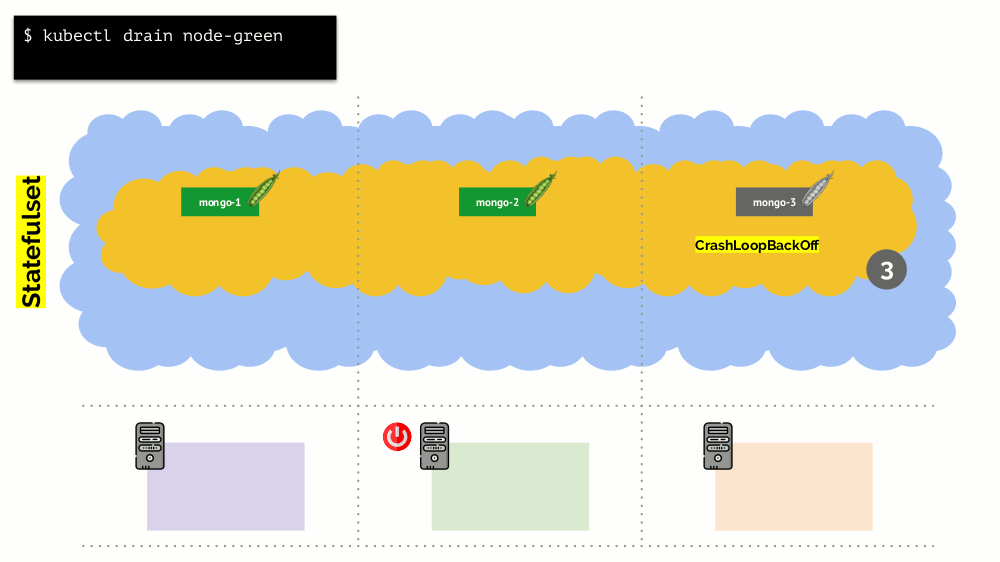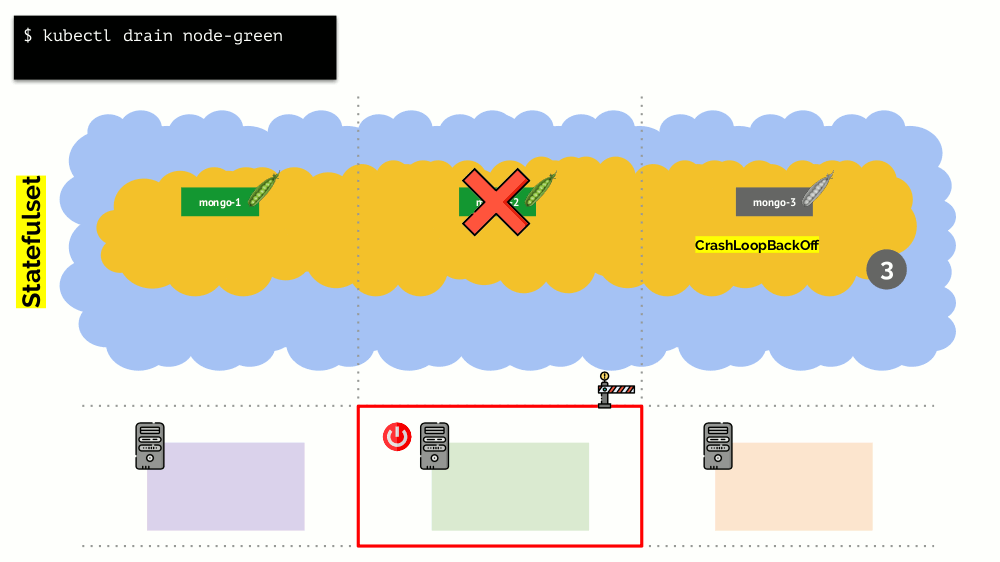
Considere un clúster de 3 servidores en el que hay implementación. Tiene 6 pods: ahora son 2 para cada servidor. Por alguna razón, queríamos apagar uno de los servidores. Para hacer esto, use el
kubectl drain , que:
- prohíbe enviar nuevos pods a este servidor;
- eliminar pods existentes en el servidor.
Como Kubernetes supervisa el mantenimiento del número de pods (6), simplemente los
recreará en otros nodos, pero no en el desconectado, ya que ya está marcado como inaccesible para alojar nuevos pods. Esta es la mecánica fundamental para Kubernetes.

Sin embargo, hay un matiz aquí. En una situación similar para StatefulSet (en lugar de Implementación) las acciones serán diferentes. Ahora ya tenemos una aplicación con estado, por ejemplo, tres pods con MongoDB, uno de los cuales tenía algún tipo de problema (los datos se volvieron incorrectos o algún otro error que impidió que el pod se iniciara correctamente). Y nuevamente decidimos desconectar un servidor. Que va a pasar
MongoDB
podría morir porque necesita un quórum: para un grupo de tres instalaciones, al menos dos deben funcionar. Sin embargo, esto
no sucede , gracias al
PodDisruptionBudget . Este parámetro determina el número mínimo requerido de pods de trabajo. Sabiendo que uno de los pods con MongoDB ya no funciona, y viendo que minAvailable está configurado para MongoDB en
minAvailable: 2 , Kubernetes no le permitirá eliminar el pod.
En pocas palabras: para mover correctamente (y volver a crear) pods cuando se libera el clúster, debe configurar PodDisruptionBudget.
Escala horizontal
Considera una situación diferente. Hay una aplicación que se ejecuta como Implementación en Kubernetes. El tráfico de usuarios llega a sus pods (por ejemplo, hay tres de ellos), y medimos un cierto indicador en ellos (por ejemplo, carga de CPU). Cuando aumenta la carga, lo arreglamos en el horario y aumentamos el número de pods para distribuir solicitudes.
Hoy en Kubernetes no necesita hacer esto manualmente: puede aumentar / disminuir automáticamente el número de pods según los valores de los indicadores de carga medidos.
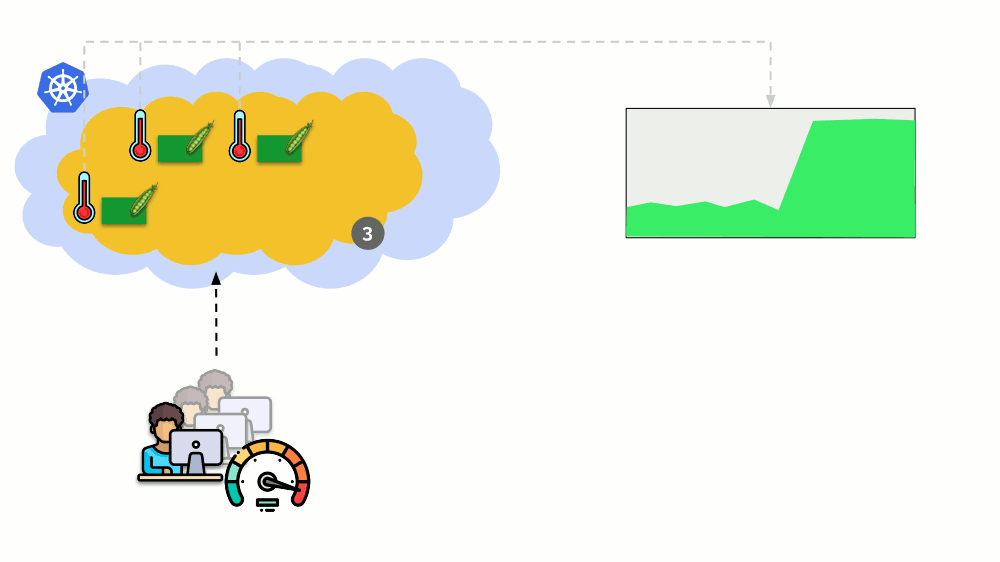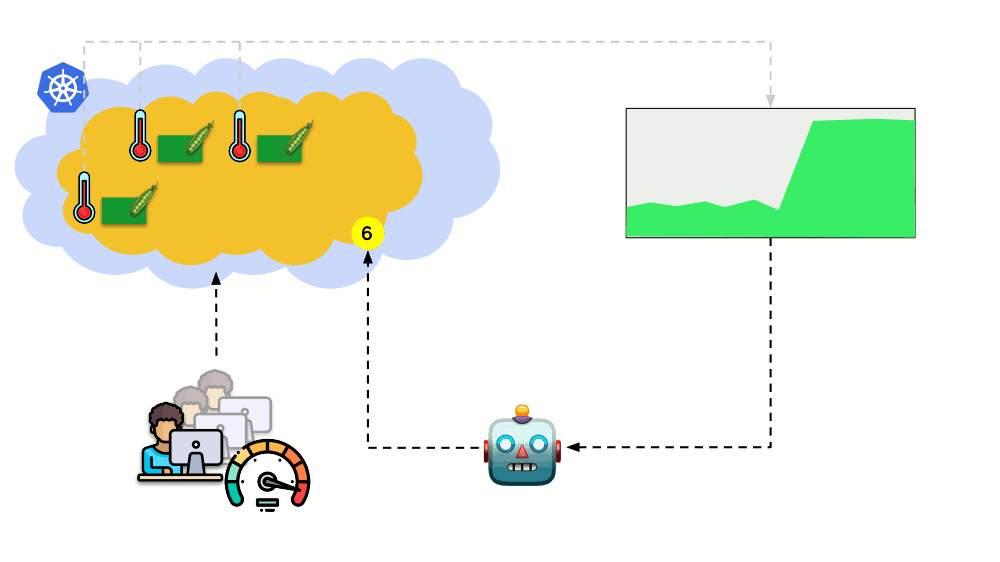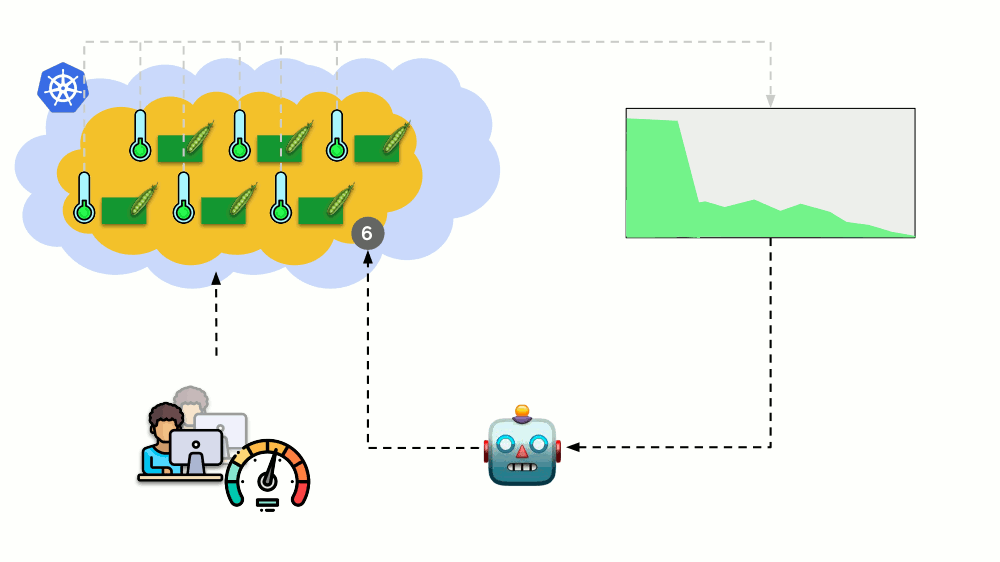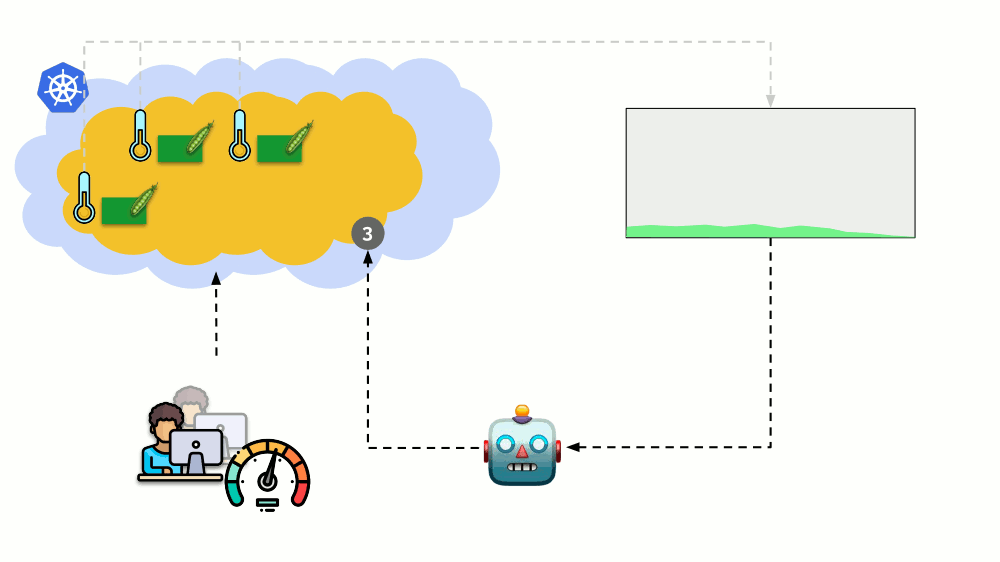
Las preguntas principales aquí son
qué medir exactamente y
cómo interpretar los valores obtenidos (para tomar la decisión de cambiar el número de pods). Puedes medir mucho:

Cómo hacerlo técnicamente: recopilar métricas, etc. - Hablé en detalle en el informe sobre
Monitoreo y Kubernetes . ¡Y el principal consejo para elegir los parámetros óptimos es
experimentar !
Existe
un método USE (Saturación de utilización y errores ), cuyo significado es el siguiente. ¿Sobre qué base tiene sentido escalar, por ejemplo, php-fpm? Basado en el hecho de que los trabajadores terminan, es la
utilización . Y si los trabajadores terminaron y no se aceptan nuevas conexiones, esto es
saturación . Ambos parámetros deben medirse y, según los valores, se debe llevar a cabo el escalado.
En lugar de una conclusión
El informe tiene una continuación: sobre el escalamiento vertical y sobre cómo elegir los recursos correctos. Hablaré de esto en futuros videos en
nuestro YouTube : ¡suscríbase para no perderse!
Videos y diapositivas
Video de la actuación (44 minutos):
Presentación del informe:
PS
Otros informes de Kubernetes en nuestro blog: