
Entrada
A lo largo de los años de desarrollo de proyectos de ML y DL, nuestro estudio ha acumulado una gran base de código, mucha experiencia e ideas y conclusiones interesantes. Al comenzar un nuevo proyecto, este conocimiento útil lo ayuda a comenzar una investigación con más confianza, reutilizar métodos útiles y obtener los primeros resultados más rápido.
Es muy importante que todos estos materiales no solo estén en la mente de los desarrolladores, sino también en forma legible en el disco. Esto permitirá una capacitación más efectiva de los nuevos empleados, actualizarlos y sumergirlos en el proyecto.
Por supuesto, este no fue siempre el caso. Nos enfrentamos a muchos problemas en las primeras etapas
- Cada proyecto se organizó de manera diferente, especialmente si fueron iniciados por diferentes personas.
- No hicieron un seguimiento de lo que estaba haciendo el código, cómo ejecutarlo y quién era el autor.
- No utilizaron la virtualización en el grado adecuado, a menudo impidiendo que sus colegas instalen bibliotecas existentes de una versión diferente.
- Se olvidaron las conclusiones extraídas de los cuadros que se asentaron y murieron en la montaña de cuadernos de jupyter.
- Informes perdidos sobre los resultados y el progreso en el proyecto.
Para resolver estos problemas de una vez por todas, decidimos que necesitamos trabajar tanto en una organización unificada y adecuada del proyecto, como en la virtualización, la abstracción de componentes individuales y la reutilización de código útil. Poco a poco, todo nuestro progreso en esta área se convirtió en un marco independiente: Ocean.
Cherry on the cake: los registros del proyecto, que se agregan y se convierten en un hermoso sitio, se recopilan automáticamente con un solo comando.
En el artículo, le diremos con un pequeño ejemplo artificial de en qué partes está compuesto Ocean y cómo usarlo.
¿Por qué océano?
En el mundo de ML, hay otras opciones que hemos considerado. En primer lugar, debemos mencionar cookiecutter-data-science (en adelante CDS) como un inspirador ideológico. Comencemos con lo bueno: CDS no solo ofrece una estructura de proyecto conveniente, sino que también explica cómo administrar el proyecto para que todo esté bien; por lo tanto, le recomendamos que se desvíe y mire las principales ideas clave de este enfoque en el artículo original de CDS .
Armados con CDS en el borrador de trabajo, de inmediato aportamos varias mejoras: agregamos un conveniente registrador de archivos, una clase coordinadora responsable de navegar el proyecto y un generador automático de documentación de Sphinx. Además, se enviaron varios comandos al Makefile, de modo que incluso un no iniciado en los detalles del gerente del proyecto fue conveniente para ejecutarlos.
Sin embargo, en el proceso, comenzaron a surgir los inconvenientes del enfoque de CDS:
- La carpeta de datos puede crecer, pero cuál de los scripts o cuadernos genera el siguiente archivo no está completamente claro. En una gran cantidad de archivos es fácil confundirse. No está claro si, en el marco de la implementación de la nueva funcionalidad, es necesario utilizar algunos de los archivos existentes, ya que no existe una descripción o documentación para su propósito en ningún lado.
- En los datos, no hay suficientes subcarpetas de características en las que pueda almacenar signos: estadísticas calculadas, vectores y otras características de las que se recopilarían diferentes representaciones finales de los datos. Esto ya se ha escrito notablemente en una publicación de blog.
- src es otra carpeta de problemas. Tiene funciones que son relevantes para todo el proyecto, por ejemplo, preparar y limpiar los datos del módulo src.data . Pero también está el módulo src.models , que contiene todos los modelos de todos los experimentos, y puede haber docenas de ellos. Como resultado, src se actualiza muy a menudo, expandiéndose con cambios muy pequeños, y de acuerdo con la filosofía de CDS, después de cada actualización, necesita reconstruir el proyecto, y este es también el momento ..., bueno, usted comprende.
- se presentan referencias , pero todavía hay una pregunta abierta: quién, cuándo y de qué forma debe llevar los materiales allí. Y puede decir mucho en el curso del proyecto: qué trabajo se ha llevado a cabo, cuál es su resultado, cuáles son los planes futuros.
Para resolver los problemas anteriores, se presenta la siguiente esencia en Ocean: experimento . Un experimento es un depósito de todos los datos involucrados en probar algunas hipótesis. Esto puede incluir: qué datos se usaron, qué datos (artefactos) resultaron, la versión del código, la hora de inicio y finalización del experimento, el archivo ejecutable, los parámetros, las métricas y los registros. Parte de esta información puede rastrearse utilizando utilidades especiales, por ejemplo, MLFlow. Sin embargo, la estructura de los experimentos presentados en Ocean es más rica y más flexible.
El módulo de un experimento es el siguiente:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
Compartimos la base del código: el código bueno reutilizable que es relevante en todo el proyecto permanece en el módulo src del nivel del proyecto. Rara vez se actualiza, por lo que con menos frecuencia debe crear un proyecto. Y el módulo de scripts de un experimento debe contener código que sea relevante solo para el experimento actual. Por lo tanto, se puede cambiar con frecuencia: no afecta el trabajo de colegas en otros experimentos.
Consideremos las posibilidades de nuestro marco utilizando el ejemplo de un proyecto abstracto ML / DL.
Flujo de trabajo del proyecto
Inicialización
Entonces, el cliente, la policía de Chicago, nos subió los datos y la tarea: analizar los crímenes cometidos en la ciudad durante 2011-2017 y sacar conclusiones.
¡Empecemos! Vamos a la terminal y ejecutamos el comando:
ocean project new -n Crimes
El marco ha creado la carpeta del proyecto de delitos correspondiente. Nos fijamos en su estructura:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
El coordinador del módulo del mismo nombre, que ya está escrito y listo, ayuda a navegar por todas estas carpetas. Para usarlo, el proyecto necesita ser ensamblado:
make package
Esto es un error : si los comandos make no quieren ejecutarse, entonces agrégueles el indicador -B, por ejemplo, "make -B package". Esto se aplica a todos los ejemplos adicionales.
Registros y experimentos
Comenzamos con el hecho de que los datos del cliente, en nuestro caso el archivo crime.csv , se colocan en la carpeta data / raw .
En el sitio web de Chicago hay mapas con divisiones de la ciudad en publicaciones ("latidos", la ubicación más pequeña para la que se asigna un patrullero), sectores ("sectores", que consisten en 3-5 publicaciones), secciones ("distritos", consisten en 3 sectores), distritos administrativos ("barrios") y, finalmente, áreas públicas ("área comunitaria"). Estos datos se pueden usar para visualización. Al mismo tiempo, los archivos json con las coordenadas de las secciones de polígono de cada tipo no son datos enviados por el cliente, por lo que los colocamos en datos / externos .
A continuación, debe presentar el concepto de experimento. Todo es simple: consideramos una tarea separada como un experimento separado. ¿Necesita analizar / bombear datos y prepararlos para su uso futuro? Vale la pena hacer un experimento. ¿Prepara mucha visualización e informes? Experimento separado. ¿Probar la hipótesis preparando un modelo? Bueno, entiendes el punto.
Para crear nuestro primer experimento desde la carpeta del proyecto, realizamos:
ocean exp new -n Parsing -a ivanov
Ahora, una nueva carpeta con el nombre exp-001-Parsing ha aparecido en la carpeta de delitos / experimentos , su estructura se da arriba.
Después de eso, debe mirar los datos. Para hacer esto, cree una computadora portátil en la carpeta correspondiente. En Surf, seguimos el nombre "número de computadora portátil - nombre", y la computadora portátil creada se llamará 001-Parse-data.ipynb . En el interior prepararemos datos para futuros trabajos.
Código de preparación de datos import numpy as np import pandas as pd pd.options.display.max_columns = 100
Para que sus colegas estén al tanto de lo que ha hecho y de si sus resultados pueden ser utilizados por ellos, debe comentarlo en el registro: el archivo log.md. La estructura del registro (que es esencialmente un archivo de reducción familiar) es la siguiente:

Las partes que se rellenan a mano se resaltan en color. El meta principal del experimento (color ciruela claro) es el autor y la explicación de su tarea, el resultado al que se dirige el experimento. Los enlaces a datos, tanto tomados como generados en el proceso (verde), ayudan a monitorear los archivos de datos y comprender quién, dentro de qué y por qué los usa. El registro en sí (color amarillo) indica el resultado del trabajo, conclusiones y razonamiento. Todos estos datos se convertirán más tarde en el contenido del sitio de registro del proyecto.
La siguiente es la etapa EDA ( Análisis de datos exploratorios - "análisis de datos de inteligencia" ). Quizás sea realizado por diferentes personas y, por supuesto, necesitaremos resultados en forma de informes y gráficos más adelante. Estos argumentos son una ocasión para crear un nuevo experimento. Realizamos:
ocean exp new -n Eda -a ivanov
En la carpeta de cuadernos del experimento, cree el cuaderno 001-EDA.ipynb . El código completo no tiene sentido, pero sus colegas no lo necesitan, por ejemplo. Pero necesitas gráficos y conclusiones. En el cuaderno sale mucho código y, por sí solo, no es lo que uno quiere mostrarle al cliente. Por lo tanto, registraremos nuestros hallazgos e ideas en el archivo log.md , y guardaremos las imágenes de los gráficos en referencias .
Aquí, por ejemplo, hay un mapa de las áreas seguras de Chicago, si el destino te lleva allí:
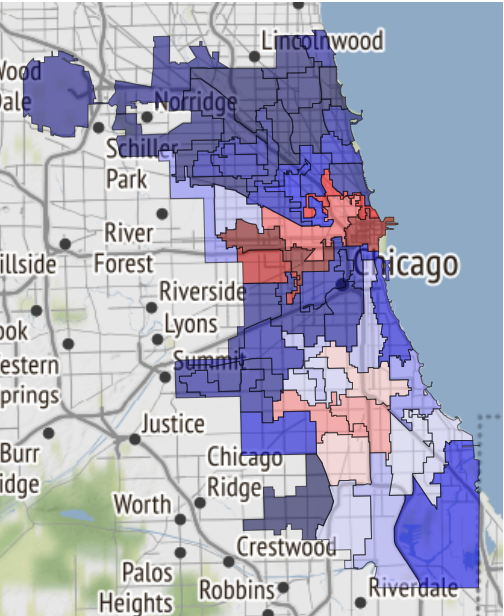
Fue recibido en un cuaderno y transferido a referencias .
Se ha agregado la siguiente entrada al registro:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
Tenga en cuenta: el gráfico está diseñado al igual que insertar una imagen en un archivo md. Y si deja un enlace al cuaderno, se convertirá a formato html y se guardará como una página separada en el sitio.
Para recopilarlo de los registros de experimentos, ejecutamos el siguiente comando a nivel de proyecto:
ocean log new
Después de eso, se crea la carpeta crime / project_log y index.html es el registro del proyecto.
Esto es un error : cuando se muestra en Jupyter, el sitio se implementa como un iframe para una mayor seguridad y, por lo tanto, las fuentes no se muestran correctamente. Por lo tanto, con Ocean, puede hacer inmediatamente un archivo con una copia del sitio para que sea conveniente descargarlo y abrirlo en una computadora local o enviarlo por correo. Así:
ocean log archive [-n NAME] [-p PASSWORD]
La documentación
Echemos un vistazo a la documentación de construcción con Sphinx. Cree una función en el archivo crime / my_cool_module.py y documente. Tenga en cuenta que Sphinx utiliza el formato de texto reestructurado (RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
Y luego todo es muy simple: a nivel de proyecto, ejecutamos el equipo de generación de documentación, y usted está listo:
ocean docs new
Pregunta de la audiencia : ¿Por qué, si recopilamos el proyecto a través de make , ¿tiene que recopilar documentación a través del ocean ?
Respuesta : el proceso de generación de documentación no es solo la ejecución del comando Sphinx, que se puede colocar en make . Ocean se hace cargo de escanear el catálogo de sus códigos fuente, crea un índice para Sphinx a partir de ellos, y solo entonces Sphinx se pone a trabajar.
La documentación html lista para usar le espera en el camino crime / docs / _build / html / index.html . Y nuestro módulo con comentarios ya apareció allí:

Modelos
El siguiente paso es construir el modelo. Realizamos:
ocean exp new -n Model -a ivanov
Y esta vez, eche un vistazo a lo que hay en la carpeta de scripts dentro del experimento. El archivo train.py está en blanco para el futuro proceso de capacitación. El archivo ya contiene el código repetitivo que hace varias cosas a la vez.
- La función de aprendizaje toma varias rutas de archivo:
- Al archivo de configuración, en el que es razonable transferir los parámetros del modelo, los parámetros de entrenamiento y otras opciones que son convenientes para controlar desde el exterior, sin profundizar en el código.
- Al archivo de datos.
- La ruta al directorio donde desea guardar el volcado del modelo final.
- Realiza un seguimiento de las métricas obtenidas en el proceso de aprendizaje en mlflow . Todo lo que se le solicite se puede ver a través de la interfaz de usuario mlflow ejecutando el comando
make dashboard en la carpeta del experimento. - Envía una alerta a su Telegram de que el proceso de aprendizaje se ha completado. Para implementar este mecanismo, se utilizó el bot Alarmerbot . Para que esto funcione, debe hacer bastante: enviar el comando / start al bot y luego transferir el token emitido por el bot al archivo crime / config / alarm_config.yml . La cadena puede verse así:
ivanov: a5081d-1b6de6-5f2762 - Se controla desde la consola.
¿Por qué administrar nuestro script desde la consola? Todo está organizado para que el proceso de aprendizaje u obtención de predicciones de cualquier modelo sea organizado fácilmente por un desarrollador externo que no esté familiarizado con los detalles de la implementación de su experimento. Para que todas las piezas del rompecabezas encajen , después del diseño de train.py, debes organizar el Makefile . Contiene un comando de tren en blanco, y solo tiene que establecer correctamente las rutas a los archivos de configuración necesarios enumerados anteriormente, y enumerar todos los que desean recibir alertas de Telegram en el valor del parámetro de nombre de usuario. En particular, el alias funciona, lo que enviará una alerta a todos los miembros del equipo.
Una vez que todo está listo, nuestro experimento comienza con el make train , simple y elegante.
En caso de que desee utilizar las redes neuronales de otras personas, los entornos virtuales ( venv ) le ayudarán. Crearlos y eliminarlos como parte de un experimento es muy fácil:
ocean env new creará un nuevo entorno. No solo está activo por defecto, sino que también crea un kernel adicional (kernel) para portátiles y para futuras investigaciones. Se llamará de la misma manera que el nombre del experimento.ocean env list muestra una lista de núcleos.ocean env delete entorno creado en el experimento.
Lo que falta
- Ocean no es amigo de conda (
porque no lo usamos ) - Plantilla de proyecto solo en inglés.
- El problema de localización aún se aplica al sitio: la construcción del registro del proyecto supone que todos los registros están en inglés.
Conclusión
El código fuente del proyecto se encuentra aquí .
Si estás interesado, ¡genial! Puede encontrar más información en el archivo README en el repositorio de Ocean .
Y como suelen decir en tales casos, las contribuciones son bienvenidas, solo estaremos felices si participa en la mejora del proyecto.