Hola queridos lectores! En este artículo quiero hablar sobre la arquitectura de mi proyecto, que refactoré 4 veces en su lanzamiento, ya que no estaba satisfecho con el resultado. Hablaré sobre las desventajas de los enfoques populares y mostraré los míos.
Quiero decir de inmediato que este es mi primer artículo, no estoy diciendo qué hacer como yo, correcto. Solo quiero mostrar lo que hice, decir cómo llegué al resultado final y, lo más importante, obtener las opiniones de los demás.
Trabajé en varias campañas y vi un montón de todo lo que hubiera hecho de manera diferente.
Por ejemplo, a menudo veo la arquitectura de N-Layer, hay una capa para trabajar con datos (DA), hay una capa con lógica de negocios (BL) que funciona usando DA y posiblemente otros servicios, y también hay una vista de capa \ API en la que Se recibe una solicitud, procesada con BL. Parece conveniente, pero mirando el código veo esta situación:
- [DA] extrae \ escribe \ cambia datos, incluso si se trata de una consulta compleja - OK
- [BL] 80% llama a 1 método y obtiene el resultado anterior. ¿Por qué esta capa vacía?
- [Ver] 80% de llamadas 1 método BL arroja el resultado anterior - ¿Por qué esta capa en blanco?
Además, está de moda incluir interfaces para que luego pueda bloquear y probar, ¡guau, simplemente guau!
- ¿Por qué mojarse?
- Bueno, para reducir los efectos secundarios durante la duración de las pruebas.
- Es decir, vamos a protestar sin efectos secundarios, pero ¿en el golpe con ellos?
...
Esto es algo básico que no me gustó en esta arquitectura, porque resolver un problema como: "Listar los me gusta de los usuarios" es un gran proceso, pero en realidad 1 consulta en la base de datos y posiblemente mapeo.
Solución de muestra1) [DA] Agregar solicitud a DA
2) [BL] Reenviar respuesta DA
3) [Ver] Reenviar resultado BA, puede promover
No olvide que todos estos métodos aún deben agregarse a la interfaz, estamos escribiendo un proyecto para mojarnos y no como una solución.
En otro lugar, vi una implementación de API con un enfoque CQRS.
La solución no se veía mal, 1 carpeta - 1 función. Un desarrollador que crea una función se encuentra en su carpeta y casi siempre puede olvidarse de la influencia de su código en otras funciones, pero había tantos archivos que fue una pesadilla. Modelos de solicitud / respuesta, validadores, ayudantes, lógica en sí misma. La búsqueda en el estudio prácticamente se negó a funcionar, se pusieron extensiones para encontrar las cosas necesarias en el código.
Hay mucho más que decir, pero destaqué las principales razones que me hicieron rechazarlo.
Y finalmente a mi proyecto
Como dije, refactoré mi proyecto varias veces, en ese momento tuve una "depresión del programador", simplemente no estaba contento con mi código y lo refactoricé, una y otra vez, al final comencé a ver un video sobre la arquitectura de la aplicación para ver cómo otros lo hacen Me encontré con los informes de Anton Moldovan sobre DDD y la programación funcional, y pensé: "¡Aquí está, necesito F #!".
Después de pasar un par de días en F #, me di cuenta de que, en principio, haría lo mismo en C # y nada peor. El video mostró:
- Aquí está el código C #, es una mierda
- Aquí está F # cool, menos escrito - super.
Pero el truco es que la solución en F # se implementó de manera diferente, y contra esto mostraron una implementación deficiente en C #. El principio principal era que BL no es una cosa que llama a los servicios de DA y hace todo el trabajo, pero es una función pura .
Por supuesto, F # es bueno, me gustaron algunas características, pero, como C #, esta es solo una herramienta que se puede usar de diferentes maneras.
Y volví a C # y comencé a crear.
Creé tales proyectos en la solución:
- API
- Núcleo
- Servicios
- Pruebas
También utilicé las características de C # 8, especialmente el tipo de referencia anulable, mostraré su aplicación.
Brevemente sobre las tareas de las capas que les di.
API
1) Recepción de solicitudes, modelos de solicitud + validación, restricciones
2) Funciones de llamada desde Core y Servicios
Más detalles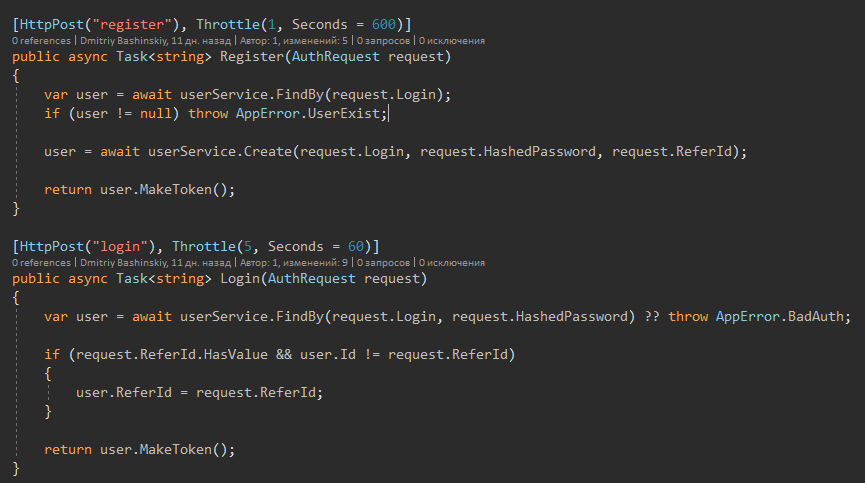
Aquí vemos un código simple y legible, creo que todos entenderán lo que está escrito aquí.
Patrón claro observado
1) Obtener datos
2) Proceso, modificación, etc. - Esta parte necesita ser probada.
3) Guardar.
3) Mapeo, si es necesario
4) Manejo de errores (registro + respuesta humana)
Más detallesEsta clase contiene todos los posibles errores de aplicación a los que responde el controlador de excepciones.
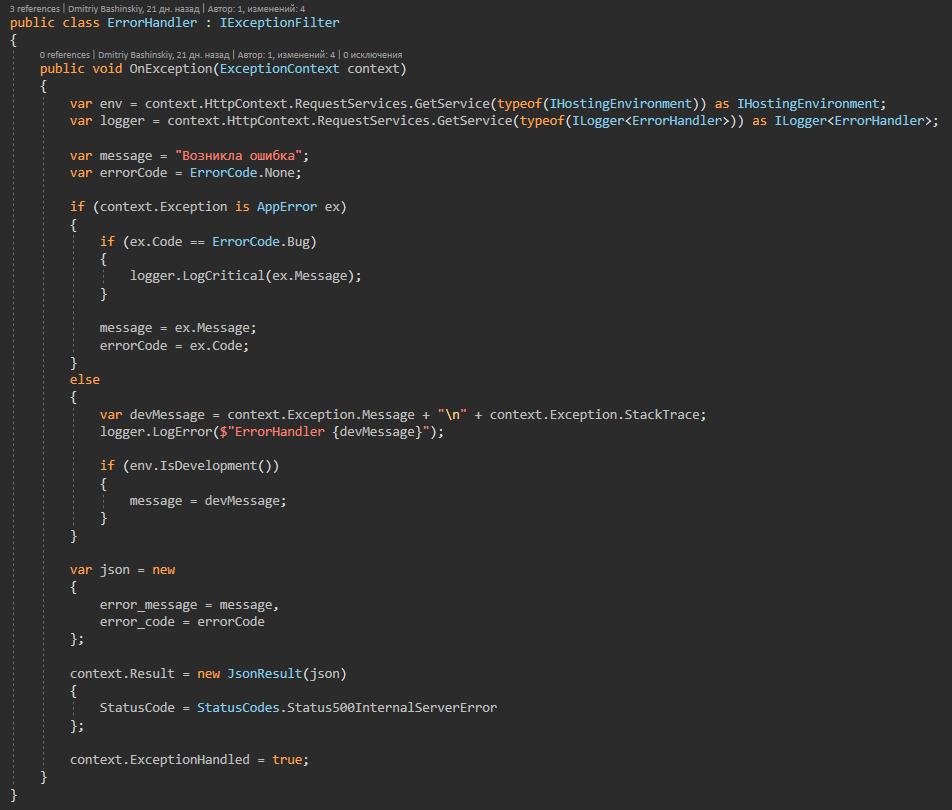
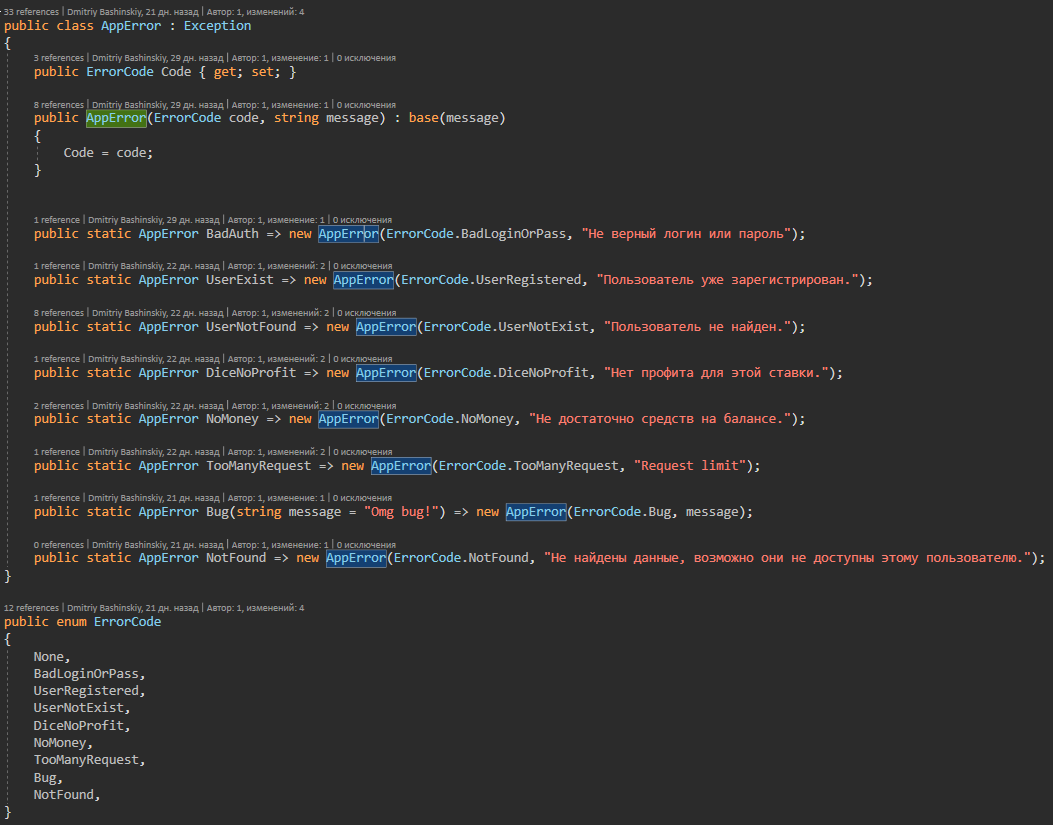
Resulta que la aplicación funciona o da un error específico, y no los errores procesados son un efecto secundario o un error, el registro de tales errores me llega de inmediato en telegramas en un chat con el bot.
Tengo AppError.Bug este error para un caso poco claro.
Tengo un CallBack de otro servicio, tendrá un ID de usuario en mi sistema, y si no encuentro un usuario con esta ID, algo le sucedió al usuario o no está claro en absoluto, tal error me vuela como CRÍTICO, en teoría no debería surgir, pero si lo hace, requiere mi intervención.
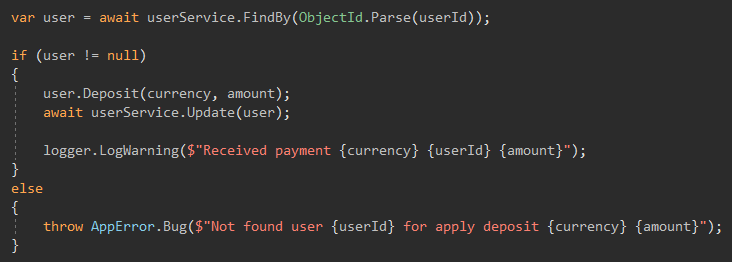
Core, lo más interesante
Siempre tuve en cuenta que los BL son solo funciones que dan el mismo resultado con la misma entrada. La complejidad del código en esta capa estaba en el nivel del trabajo de laboratorio, no en grandes funciones que claramente y sin errores hacen su trabajo. Y era importante que no hubiera efectos secundarios dentro de las funciones, todo lo que la función necesitaba era su parámetro.
Si la función necesita un saldo de usuario, entonces OBTENEMOS el saldo, y lo transferimos a la función, y NO empujamos el servicio de usuario a BL.
1) Acciones básicas de entidades
Más detalles
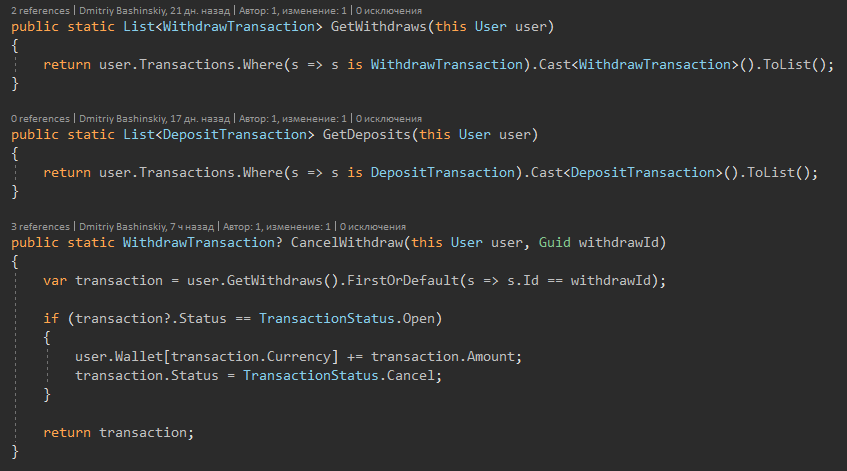
Se me ocurrieron métodos como métodos de extensión para que la clase no se hinche y la funcionalidad se pueda agrupar por características.
Considero que una buena construcción de modelos de entidad es un tema igualmente importante.
Por ejemplo, tengo un usuario, el usuario tiene saldos en varias monedas. Una de las decisiones típicas que tomé sin dudar es la esencia de "Balance" y simplemente poner una serie de saldos en el usuario. Pero, ¿qué tipo de conveniencia trajo tal decisión?
1) Agregar / eliminar monedas. Esta tarea significa inmediatamente para nosotros no solo escribir código nuevo, sino también migración, con completar / eliminar todos los usuarios existentes, y esta es la opción más fácil. Dios no lo quiera, para agregar una nueva moneda, tendría que hacer un botón para el usuario, en el que hace clic e inicia la creación de una nueva billetera para algún tipo de proceso comercial. Como resultado, solo fue necesario expandir la enumeración para la nueva moneda, y escribieron otra función para crear billeteras con un botón, lanzaron otra tarea al frente.
2) En el código, constantes FirstOrDefault (s => s.Currency == currency) y comprobación de nulo
Mi decision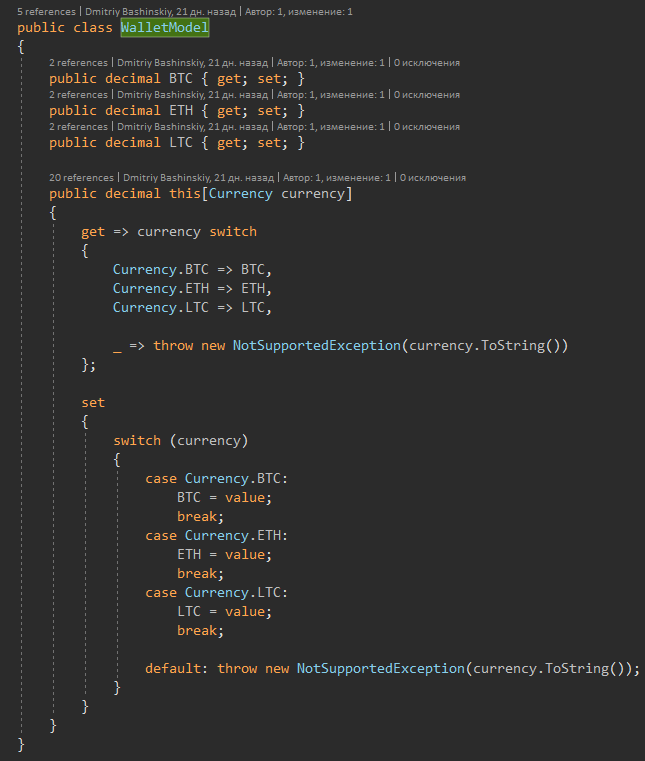
Por el modelo en sí, me garantizo que no habrá saldo nulo, y al crear el operador del indexador simplifiqué mi código en todos los lugares de interacción con el saldo.
Servicios
Esta capa me proporciona herramientas convenientes para trabajar con varios servicios.
En mi proyecto utilizo MongoDB y para trabajar convenientemente con él, envolví las colecciones en dicho repositorio.
Más detallesRepositorio en sí
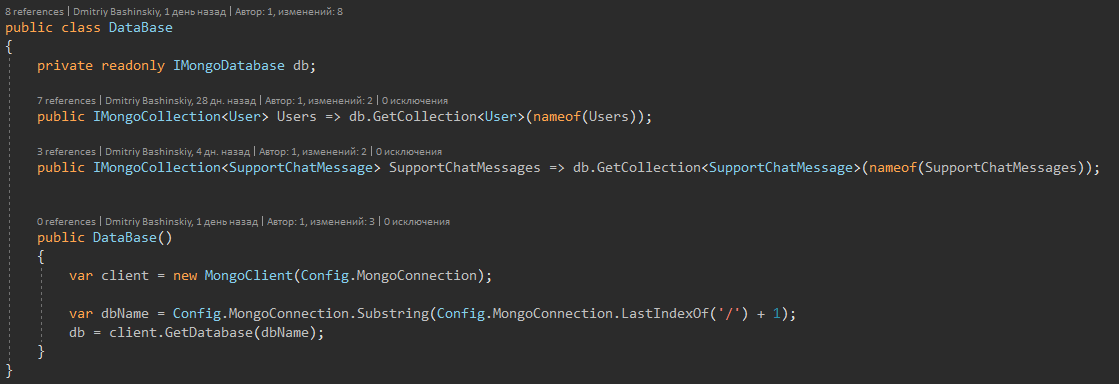
Monga bloquea el documento al momento de trabajar con él, respectivamente, esto nos ayudará a resolver problemas en la competencia de solicitudes. Y en el mong hay métodos para buscar una entidad + que actúa sobre ella, por ejemplo: "Encuentra un usuario con id y agrega 10 a su saldo actual"
Y ahora sobre la característica de C # 8.
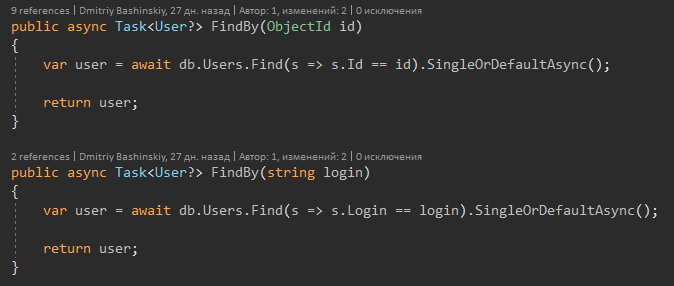
La firma del método me dice que el Usuario puede regresar, y tal vez Nulo, respectivamente, cuando veo Usuario? Inmediatamente recibo una advertencia del compilador y hago una comprobación nula.
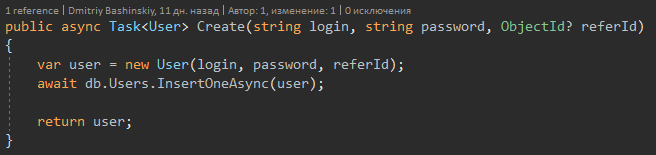
Cuando el método devuelve Usuario, trabajo con confianza.
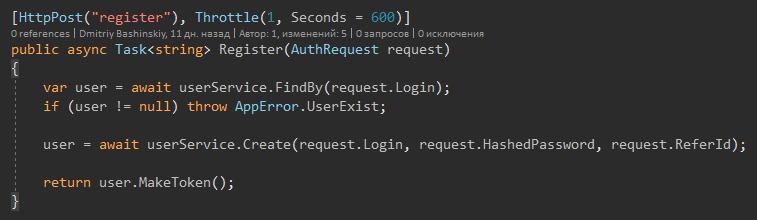
También quiero llamar la atención sobre el hecho de que no hay prueba de captura porque las excepciones solo pueden ser de "situaciones extrañas" y datos incorrectos que no deberían llegar aquí porque hay validación. Tampoco hay prueba de captura en la capa API, solo hay un controlador de excepción global.
Solo hay un método que lanza Exception es el método Update.
Implementa protección contra la pérdida de datos en modo multiproceso.
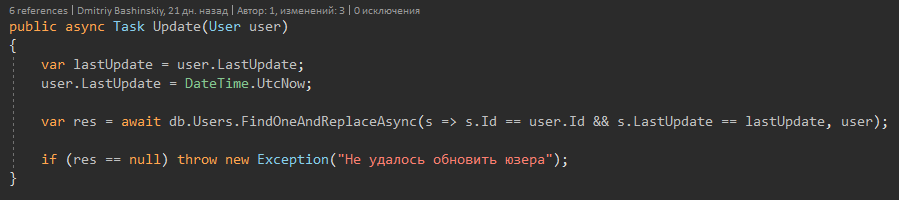
¿Por qué no usaste los métodos monga mencionados anteriormente?
Hay lugares en los que todavía no sé con certeza si puedo trabajar con el usuario, tal vez no tenga dinero para esta acción, así que al principio saco al usuario y lo reviso, luego lo muto y lo guardo.
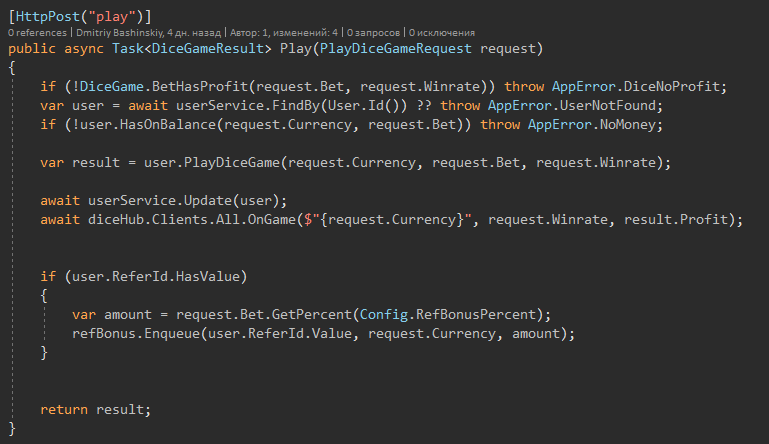
En teoría, mi aplicación cambiará el saldo del usuario más de 1 vez por segundo, ya que estos serán juegos rápidos.
Pero el modelo del usuario en sí mismo, es claramente visible que la referencia del usuario es opcional, y puede trabajar con todo lo demás sin pensar en nulo.
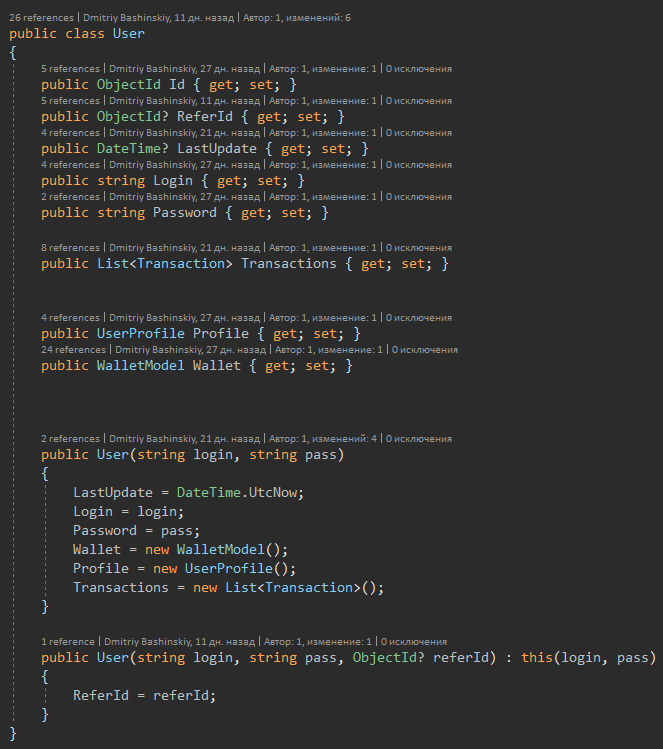
Finalmente pruebas
Como dije, solo necesitas probar la lógica, y la lógica de nuestra función no tiene efectos secundarios.
Por lo tanto, podemos ejecutar nuestras pruebas muy rápidamente y con diferentes parámetros.
Más detallesDescargué nuget FSCheck que genera datos entrantes al azar y permite muchos casos diferentes.
Solo necesito crear varios usuarios, alimentar su prueba y verificar los cambios.
Existe un pequeño generador para crear dichos usuarios, pero es fácil de expandir.

Y aquí están las pruebas mismas
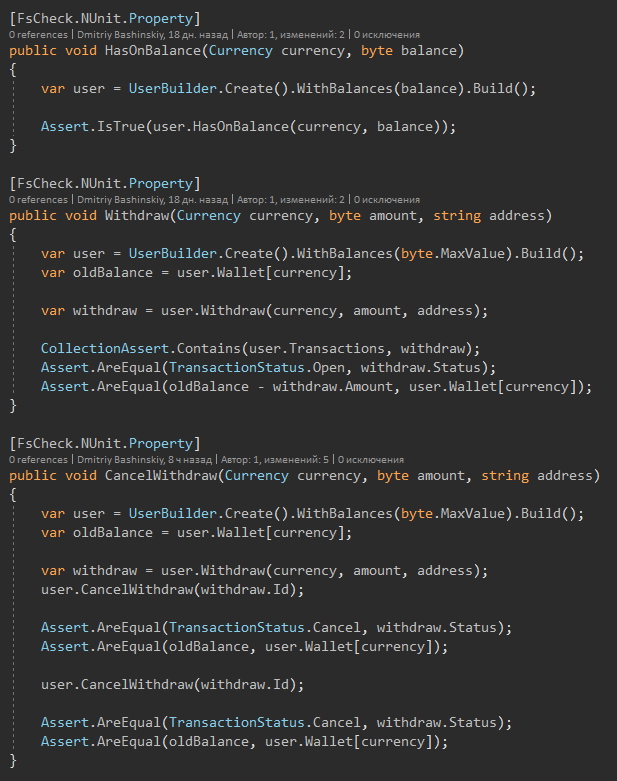
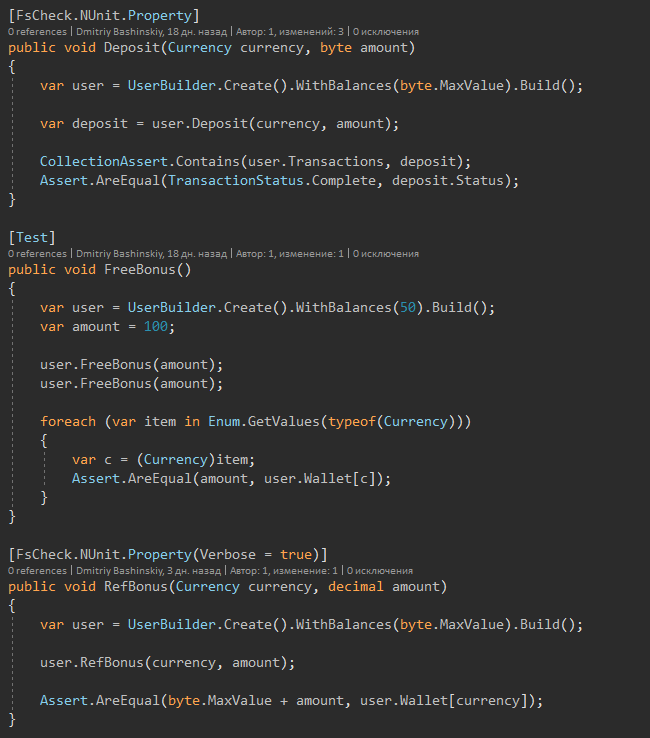
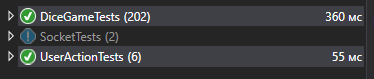
Después de algunos cambios, ejecuto las pruebas, después de 1-2 segundos veo que todo está en orden.
También está en los planes escribir pruebas E2E para verificar la API completa desde el exterior y asegurarse de que funcione como debería, desde la solicitud hasta la respuesta.
Papas fritas
Cosas geniales que puedas necesitarCada una de mis solicitudes se duplica, cuando ocurre un error, encuentro requestId y puedo reproducir fácilmente el error repitiendo la solicitud, porque mi API no tiene un estado, y cada solicitud depende solo de los parámetros de la solicitud.
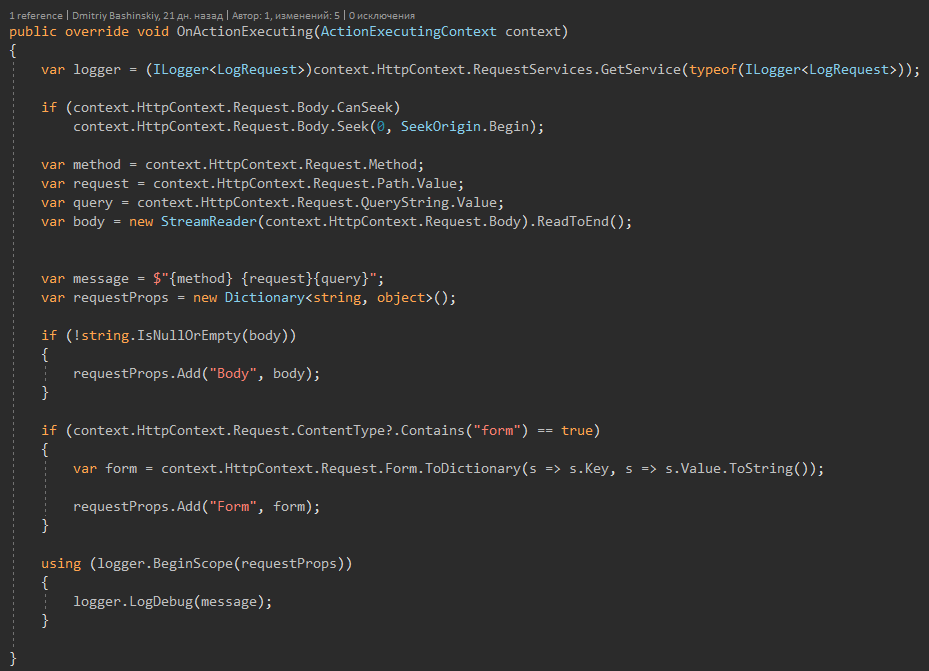
Para resumir.
Realmente escribimos una solución, y no un marco en el que un montón de abstracciones adicionales, así como mok. Cometimos errores en un solo lugar y deberían ocurrir muy raramente. Separamos BL y los efectos secundarios, ahora BL es solo una lógica local que se puede reutilizar. No escribimos funciones adicionales que simplemente reenvíen la llamada a otras funciones. Leeré activamente los comentarios y completaré el artículo, ¡gracias!