Los principales problemas de trabajar con la base de datos están relacionados con las características del dispositivo del sistema operativo en el que funciona la base de datos. Linux es ahora el principal sistema operativo para bases de datos. Solaris, Microsoft e incluso HPUX todavía se utilizan en la empresa, pero nunca ocuparán el primer lugar, incluso combinados. Linux está ganando terreno con confianza porque cada vez hay más bases de datos de código abierto. Por lo tanto, el problema de la interacción de la base de datos con el sistema operativo es obviamente sobre las bases de datos Linux. Esto se superpone al eterno problema de DB: el rendimiento de IO. Es bueno que en los últimos años Linux haya sufrido una importante revisión de la pila de E / S y hay esperanza para la iluminación.
Ilya Kosmodemyansky (
hydrobiont ) trabaja para Data Egret, una compañía que
consulta y apoya PostgreSQL, y sabe mucho sobre la interacción entre el sistema operativo y las bases de datos. En un informe sobre HighLoad ++, Ilya habló sobre la interacción de IO y las bases de datos utilizando el ejemplo de PostgreSQL, pero también mostró cómo funcionan otras bases de datos con IO. Observé la pila de Linux IO, qué cosas nuevas y buenas aparecían en ella y por qué todo no es como era hace un par de años. Como recordatorio útil: una lista de verificación de la configuración de PostgreSQL y Linux para obtener el máximo rendimiento del subsistema IO en los nuevos núcleos.
El video del informe contiene mucho inglés, la mayoría de los cuales tradujimos en el artículo.¿Por qué hablar de IO?
La E / S rápida es lo más importante para los administradores de bases de datos . Todos saben lo que se puede cambiar al trabajar con la CPU, esa memoria se puede expandir, pero la E / S puede arruinar todo. Si está mal con los discos, y demasiadas E / S, entonces la base de datos gemirá. IO se convertirá en un cuello de botella.
Para que todo funcione bien, debe configurarlo todo.
No solo la base de datos o solo el hardware, eso es todo. Incluso el Oracle de alto nivel, que en sí mismo es un sistema operativo en algunos lugares, requiere configuración. Leemos las instrucciones en la "Guía de instalación" de Oracle: cambie dichos parámetros del kernel, cambie otros, hay muchas configuraciones. Además del hecho de que en Unbreakable Kernel, mucho ya está conectado por defecto a Oracle Linux.
Para PostgreSQL y MySQL, se requieren aún más cambios. Esto se debe a que estas tecnologías dependen de los mecanismos del sistema operativo. Un DBA que funciona con PostgreSQL, MySQL o NoSQL moderno debe ser un ingeniero de operaciones de Linux y modificar diferentes tuercas del sistema operativo.
Todos los que quieran lidiar con la configuración del núcleo,
recurren a
LWN . El recurso es ingenioso, minimalista, contiene mucha información útil, pero fue
escrito por desarrolladores de kernel para desarrolladores de kernel . ¿Qué escriben bien los desarrolladores de kernel? El núcleo, no el artículo, cómo usarlo. Por lo tanto, intentaré explicarte todo a los desarrolladores y dejar que escriban el núcleo.
Todo se complica muchas veces por el hecho de que inicialmente el desarrollo del kernel de Linux y el procesamiento de su stack se retrasaron, y en los últimos años han ido muy rápido. Ni el hierro ni los desarrolladores con artículos detrás de él se mantienen al día.
Base de datos típica
Comencemos con los ejemplos de PostgreSQL: aquí hay E / S almacenadas en búfer. Tiene memoria compartida, que se asigna en el
espacio del
usuario desde el punto de vista del sistema operativo, y tiene la misma caché en el caché del núcleo en el
espacio del núcleo .
 La tarea principal de una base de datos moderna
La tarea principal de una base de datos moderna :
- recoger páginas del disco en la memoria;
- cuando ocurra un cambio, marque las páginas como sucias;
- escribir en el registro de escritura anticipada;
- luego sincronice la memoria para que sea consistente con el disco.
En una situación de PostgreSQL, este es un viaje de ida y vuelta constante: desde la memoria compartida que PostgreSQL controla hasta el núcleo de la caché de página y luego al disco a través de toda la pila de Linux. Si usa una base de datos en un sistema de archivos, funcionará en este algoritmo con cualquier sistema similar a UNIX y con cualquier base de datos. Las diferencias son, pero insignificantes.
Usar Oracle ASM será diferente: Oracle mismo interactúa con el disco. Pero el principio es el mismo: con Direct IO o con Page Cache, pero la tarea es
dibujar páginas a través de toda la pila de E / S lo más rápido posible , sea lo que sea. Y pueden surgir problemas en cada etapa.
Dos problemas de IO
Si bien todo es de
solo lectura , no hay problemas. Leen y, si hay suficiente memoria, todos los datos que deben leerse se colocan en la RAM. El hecho de que en el caso de PostgreSQL en
Buffer Cache sea el mismo, no estamos muy preocupados.
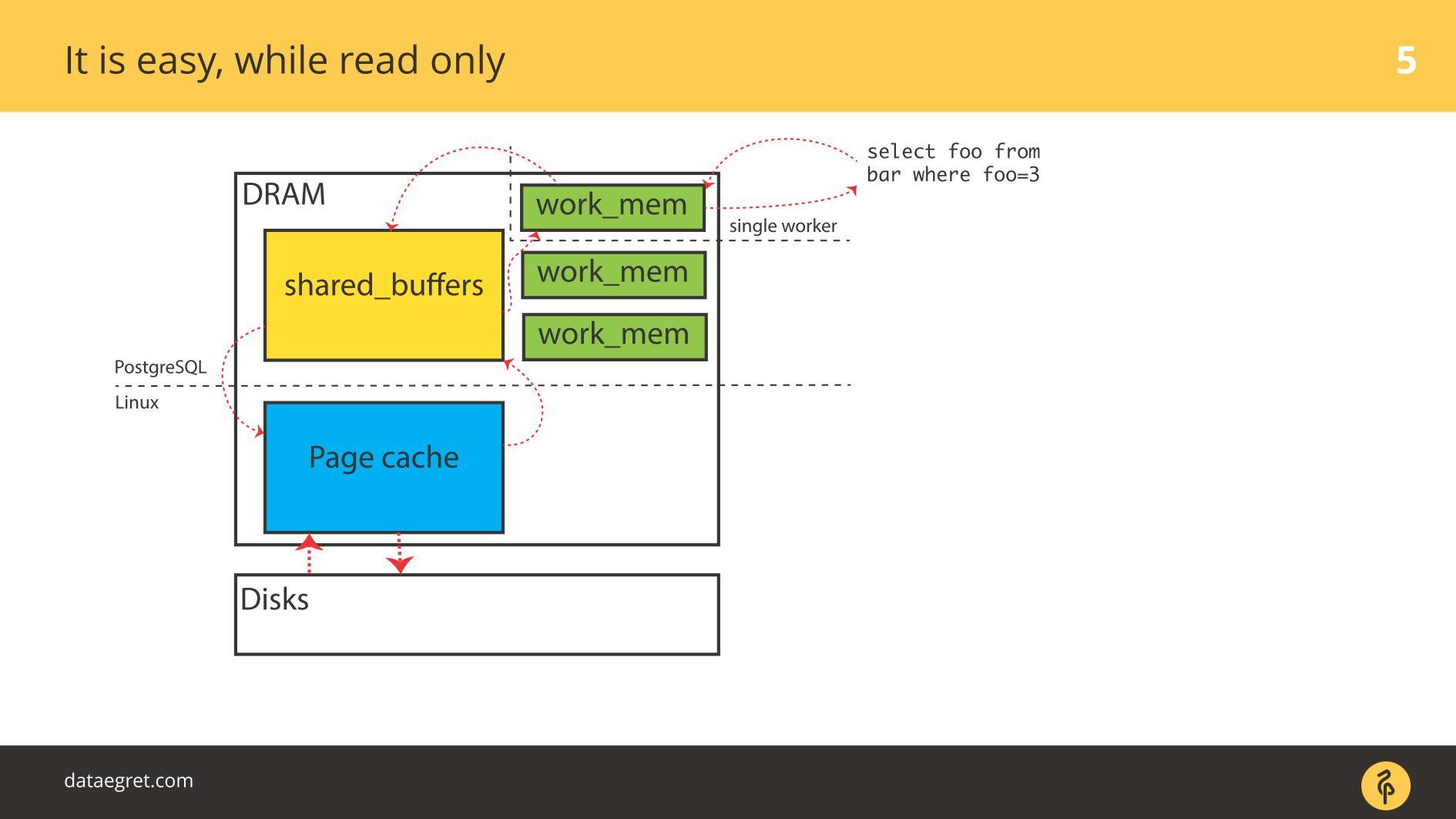 El primer problema con IO es la sincronización de caché.
El primer problema con IO es la sincronización de caché. Se produce cuando se requiere la grabación. En este caso, tendrá que conducir hacia adelante y hacia atrás con mucha más memoria.
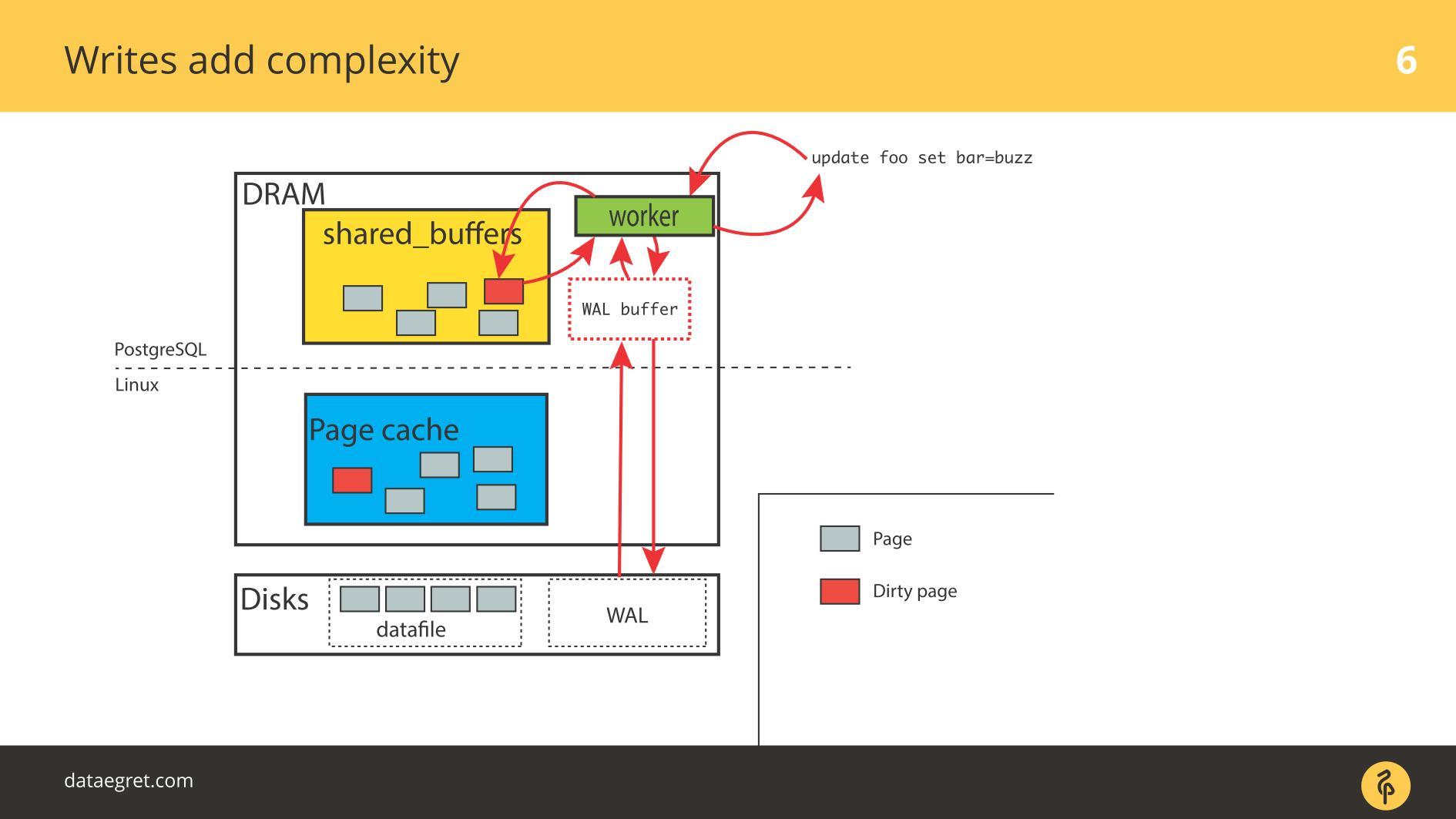
En consecuencia, debe configurar PostgreSQL o MySQL para que todo llegue al disco desde la memoria compartida. En el caso de PostgreSQL, aún necesita ajustar la trampa de fondo de páginas sucias en Linux para enviar todo al disco.
El segundo problema común es el error de escritura del registro de escritura anticipada . Aparece cuando la carga es tan poderosa que incluso un registro grabado secuencialmente descansa en el disco. En esta situación, también debe registrarse rápidamente.
La situación no es muy diferente de la
sincronización de caché . En PostgreSQL, trabajamos con una gran cantidad de buffers compartidos, la base de datos tiene mecanismos para la grabación eficiente del registro de escritura anticipada, está optimizada al límite. Lo único que se puede hacer para que el registro sea más eficiente es cambiar la configuración de Linux.
Los principales problemas de trabajar con la base de datos.
El segmento de memoria compartida puede ser muy grande . Empecé a hablar de esto en conferencias en 2012. Luego dije que la memoria ha bajado de precio, incluso hay servidores con 32 GB de RAM. En 2019, es posible que ya haya más en las computadoras portátiles, cada vez más a menudo en los servidores 128, 256, etc.
Realmente mucha memoria . La grabación banal requiere tiempo y recursos, y las
tecnologías que utilizamos para esto son conservadoras . Las bases de datos son antiguas, se han desarrollado durante mucho tiempo, evolucionan lentamente. Los mecanismos en las bases de datos no son exactamente correctos con la última tecnología.
La sincronización de páginas en la memoria con el disco da como resultado enormes operaciones de E / S. Cuando sincronizamos cachés, surge un gran flujo de E / S y surge otro problema:
no podemos torcer algo y observar el efecto. En un experimento científico, los investigadores cambian un parámetro: obtener el efecto, el segundo, obtener el efecto, el tercero. No tendremos éxito. Retorcemos algunos parámetros en PostgreSQL, configuramos puntos de control; no vimos el efecto. Luego, nuevamente configure toda la pila para capturar al menos algún resultado. El parámetro Twist one no funciona: nos vemos obligados a configurar todo de una vez.
La mayoría de las IO de PostgreSQL generan sincronización de páginas: puntos de control y otros mecanismos de sincronización. Si trabajó con PostgreSQL, es posible que haya visto picos de puntos de control cuando aparece periódicamente una "sierra" en los gráficos. Anteriormente, muchos enfrentaban este problema, pero ahora hay manuales sobre cómo solucionarlo, se ha vuelto más fácil.
Los SSD hoy en día salvan enormemente la situación. En PostgreSQL, algo rara vez descansa directamente en el registro de valor. Todo depende de la sincronización: cuando se produce un punto de control, se llama a fsync y hay una especie de "golpear" un punto de control sobre otro. Demasiado IO. Un punto de control aún no ha finalizado, no ha completado todos sus fsyncs, pero ya ha ganado otro punto de control, ¡y comenzó!
PostgreSQL tiene una característica única:
autovacuum . Esta es una larga historia de muletas para la arquitectura de bases de datos. Si el autovacío falla, generalmente lo configuran para que funcione de manera agresiva y no interfiera con el resto: hay muchos trabajadores de autovacío, tropiezos frecuentes, procesan las tablas rápidamente. De lo contrario, habrá problemas con DDL y con los bloqueos.
Pero cuando Autovacuum es agresivo, comienza a masticar IO.
Si el vacío automático se superpone en los puntos de control, la mayoría de las veces los discos se reciclan casi al 100%, y esta es la fuente de los problemas.
Curiosamente, hay un problema de
recarga de caché . Ella es generalmente menos conocida por DBA. Un ejemplo típico: la base de datos se inició y, por algún tiempo, todo se ralentiza tristemente. Por lo tanto, incluso si tiene mucha RAM, compre buenos discos para que la pila caliente el caché.
Todo esto afecta seriamente el rendimiento. Los problemas comienzan no inmediatamente después de reiniciar la base de datos, sino más tarde. Por ejemplo, el punto de control pasó y muchas páginas están sucias en toda la base de datos. Se copian en el disco porque necesita sincronizarlos. Luego, las solicitudes solicitan una nueva versión de las páginas del disco y la base de datos se hunde. Los gráficos mostrarán cómo la recarga de caché después de cada punto de control contribuye con un cierto porcentaje a la carga.
Lo más desagradable en la entrada / salida de la base de datos es
Worker IO. Cuando cada trabajador que solicita, comienza a generar su IO. En Oracle, es más fácil, pero en PostgreSQL es un problema.
Hay muchas razones para los problemas con
Worker IO : no hay suficiente caché para "publicar" nuevas páginas desde el disco. Por ejemplo, sucede que todos los buffers están compartidos, todos están sucios, los puntos de control aún no lo han estado. Para que el trabajador realice la selección más simple, debe tomar el caché de alguna parte. Para hacer esto, primero debe guardarlo todo en el disco. No tiene un proceso especializado de puntero de verificación, y el trabajador inicia fsync para liberarlo y llenarlo con algo nuevo.
Esto plantea un problema aún mayor: el trabajador es una cosa no especializada y todo el proceso no está optimizado en absoluto. Es posible optimizar en algún lugar a nivel de Linux, pero en PostgreSQL esta es una medida de emergencia.
Principal problema de E / S para DB
¿Qué problema resolvemos cuando configuramos algo? Queremos maximizar el viaje de páginas sucias entre el disco y la memoria.
Pero a menudo sucede que estas cosas no tocan directamente el disco. Un caso típico: ve un promedio de carga muy grande. Por qué Porque alguien está esperando el disco y todos los demás procesos también están esperando. Parece que no hay una utilización explícita del disco de los discos, simplemente algo bloqueó el disco allí, y el problema es con la entrada / salida de todos modos.
Los problemas de E / S de la base de datos no siempre se refieren solo a los discos.
Todo está involucrado en este problema: discos, memoria, CPU, IO Schedulers, sistemas de archivos y configuraciones de bases de datos. Ahora repasemos la pila, veamos qué hacer con ella y qué cosas buenas se han inventado en Linux para que todo funcione mejor.
Discos
Durante muchos años, los discos fueron terriblemente lentos y nadie estuvo involucrado en la latencia u optimización de las etapas de transición. Optimizar fsyncs no tenía sentido. El disco giraba, las cabezas se movían a lo largo de él como un disco de fonógrafo, y fsyncs era tan largo que no surgieron problemas.
El recuerdo
Es inútil mirar las consultas principales sin ajustar la base de datos. Configurará una cantidad suficiente de memoria compartida, etc., y tendrá una nueva consulta superior; deberá configurarla nuevamente. Aquí está la misma historia. Toda la pila de Linux se realizó a partir de este cálculo.
Ancho de banda y latencia
Maximizar el rendimiento de IO maximizando el rendimiento es fácil hasta cierto punto. Se inventó un proceso auxiliar de PageWriter en PostgreSQL que descargó el punto de control. El trabajo se ha vuelto paralelo, pero todavía hay bases para la adición de paralelismo. Y minimizar la latencia es la tarea de la última milla, para la cual se necesitan súper tecnologías.
Estas súper tecnologías son SSD. Cuando aparecieron, la latencia cayó bruscamente. Pero en todas las otras etapas de la pila, aparecieron problemas: tanto del lado de los fabricantes de la base de datos como de los fabricantes de Linux. Los problemas deben ser abordados.
El desarrollo de la base de datos se centró en maximizar el rendimiento, al igual que el desarrollo del kernel de Linux. Muchos métodos para optimizar la era de E / S de los discos giratorios no son tan buenos para los SSD.
En el medio, nos vimos obligados a realizar copias de seguridad de la infraestructura actual de Linux, pero con nuevos discos. Vimos las pruebas de rendimiento del fabricante con una gran cantidad de IOPS diferentes, y la base de datos no mejoró, porque la base de datos no es solo y no tanto sobre IOPS. A menudo sucede que podemos omitir 50,000 IOPS por segundo, lo cual es bueno. Pero si no conocemos la latencia, no sabemos su distribución, entonces no podemos decir nada sobre el rendimiento. En algún momento, la base de datos comenzará al punto de control y la latencia aumentará dramáticamente.
Durante mucho tiempo, como ahora, este ha sido un gran problema de rendimiento en las bases de datos de virtuala. Virtual IO se caracteriza por una latencia desigual, que, por supuesto, también conlleva problemas.
IO stack. Como era antes
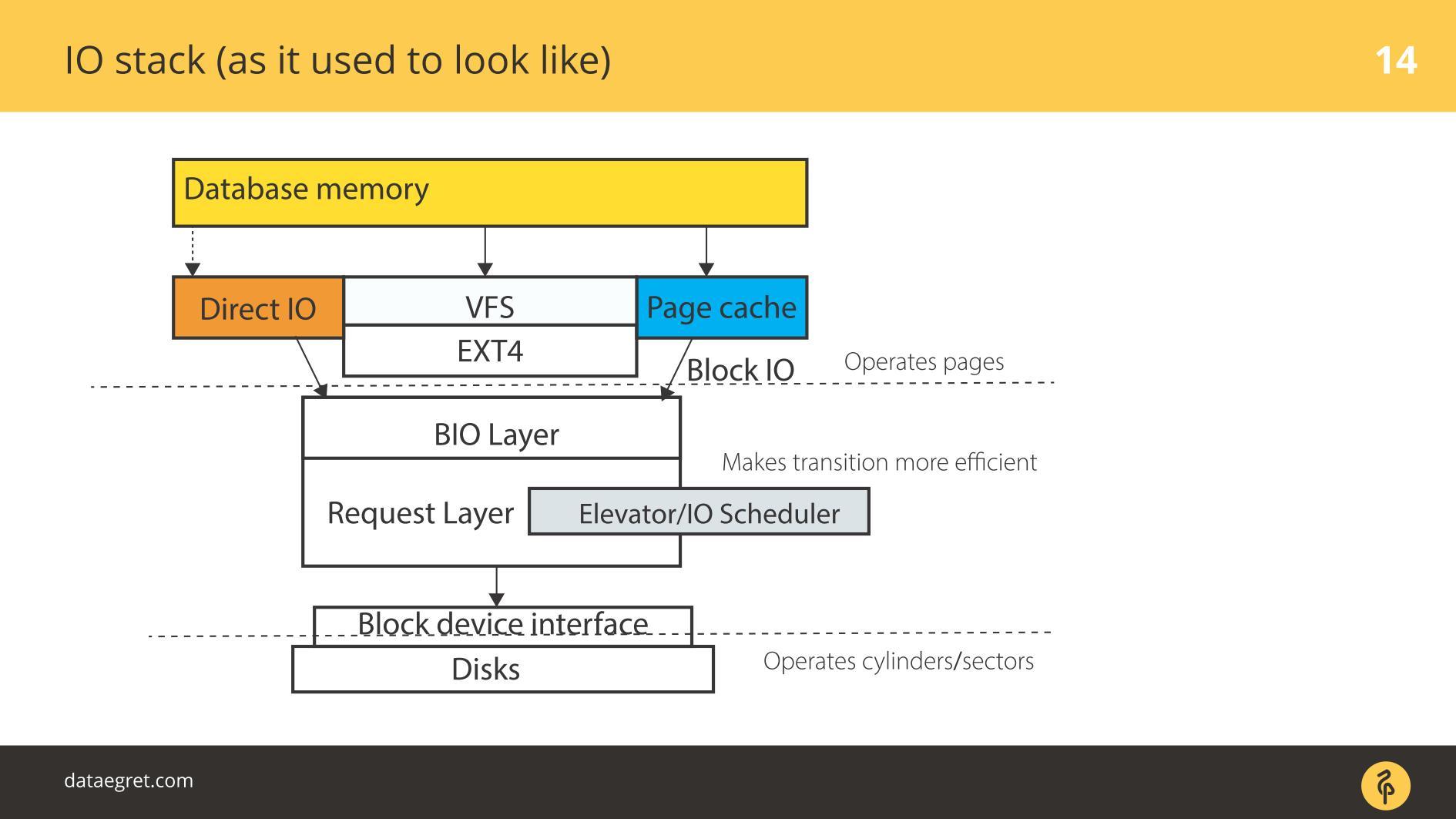
Hay espacio de usuario: esa memoria, que es administrada por la propia base de datos. En una base de datos configurada para que todo funcione como debería. Esto se puede hacer en un informe separado, y ni siquiera en uno. Luego, todo pasa inevitablemente a través de Caché de página o, a través de la interfaz Direct IO, ingresa a la
capa Bloquear entrada / salida .
Imagine una interfaz de sistema de archivos. Las páginas que estaban en el Buffer Cache, como estaban originalmente en la base de datos, es decir, bloques, salen de ella. La capa de bloque IO se ocupa de lo siguiente. Hay una estructura C que describe un bloque en el núcleo. La estructura toma estos bloques y recopila de ellos vectores (matrices) de solicitudes de entrada o salida. Debajo de la capa BIO está la capa solicitante. Los vectores se recopilan en esta capa e irán más allá.
Durante mucho tiempo, estas dos capas en Linux fueron afiladas para una grabación eficiente en discos magnéticos. Era imposible hacerlo sin una transición. Hay bloques que son convenientes para administrar desde la base de datos. Es necesario ensamblar estos bloques en vectores que se escriben convenientemente en el disco para que queden en algún lugar cercano. Para que esto funcione de manera efectiva, crearon Elevators, o Schedulers IO.
Ascensores
Los ascensores participaron principalmente en la combinación y clasificación de vectores. Todo para que el controlador SD de bloque, el controlador de cuasidisco, llegue a los bloques de grabación en el orden conveniente para él. El controlador tradujo de bloques a sus sectores y escribió en el disco.
El problema era que era necesario hacer varias transiciones, y en cada una implementar su propia lógica del proceso óptimo.
Ascensores: hasta el kernel 2.6
Antes del kernel 2.6, estaba Linus Elevator , el IO Scheduler más primitivo, escrito por usted adivina quién. Durante mucho tiempo fue considerado absolutamente inquebrantable y bueno, hasta que desarrollaron algo nuevo.
Linus Elevator tuvo muchos problemas.
Combinó y ordenó según cómo grabar de manera más eficiente . En el caso de los discos mecánicos rotativos, esto condujo a la aparición del "
hambre" : una situación en la que la eficiencia de grabación depende de la rotación del disco. Si de repente necesita leer con eficacia al mismo tiempo, pero ya se ha convertido en incorrecto, se lee mal desde dicho disco.
Poco a poco, se hizo evidente que esta es una forma ineficiente. Por lo tanto, comenzando con el kernel 2.6, comenzó a aparecer un zoológico completo de planificadores, que estaba destinado a diferentes tareas.
Ascensores: entre 2.6 y 3
Muchas personas confunden estos planificadores con los planificadores del sistema operativo porque tienen nombres similares.
CFQ: la cola completamente justa no es lo mismo que los planificadores del sistema operativo. Solo los nombres son similares. Fue acuñado como un planificador universal.
¿Qué es un planificador universal? ¿Crees que tienes una carga promedio o, por el contrario, una única? Las bases de datos tienen muy poca versatilidad. La carga universal se puede imaginar como una computadora portátil normal. Todo sucede allí: escuchamos música, jugamos, escribimos texto. Para esto, solo se escribieron planificadores universales.
La tarea principal del planificador universal: en el caso de Linux, para cada terminal virtual y proceso, crear una cola de solicitud. Cuando queremos escuchar música en un reproductor de audio, IO para el reproductor toma una cola. Si queremos hacer una copia de seguridad de algo usando el comando cp, hay algo más involucrado.
En el caso de las bases de datos, se produce un problema. Como regla general, una base de datos es un proceso que comenzó y, durante la operación, surgieron procesos paralelos que siempre terminan en la misma cola de E / S. La razón es que esta es la misma aplicación, el mismo proceso padre. Para cargas muy pequeñas, tal programación era adecuada, para el resto no tenía sentido. Fue más fácil apagarlo y no usarlo si es posible.
Gradualmente, apareció el
planificador de fecha límite : funciona de manera más astuta, pero básicamente es fusionar y ordenar discos giratorios. Dado el diseño de un subsistema de disco específico, recopilamos vectores de bloques para escribirlos de la manera óptima. Tenía menos problemas con el
hambre , pero estaban allí.
Por lo tanto, más cerca del tercer núcleo de Linux apareció
noop o
none , que funcionó mucho mejor con la propagación de SSD. Incluyendo el programador noop, en realidad deshabilitamos la programación: no hay clasificaciones, fusiones y cosas similares que hicieron CFQ y la fecha límite.
Esto funciona mejor con los SSD, porque los SSD son inherentemente paralelos: tiene celdas de memoria. Cuantos más elementos tenga en una placa PCIe, más eficiente funcionará.
Programador de algunos de sus otros mundos, desde el punto de vista de SSD, consideraciones, recoge algunos vectores y los envía a alguna parte. Todo termina con un embudo. Así que matamos la concurrencia de los SSD, no los usemos al máximo. Por lo tanto, un apagado simple, cuando los vectores van al azar sin ninguna clasificación, funcionó mejor en términos de rendimiento. Debido a esto, se cree que las lecturas aleatorias, la escritura aleatoria son mejores en SSD.
Ascensores: 3.13 en adelante
Comenzando con el kernel 3.13,
apareció blk-mq . Un poco antes había un prototipo, pero en 3.13 apareció por primera vez una versión funcional.
Blk-mq comenzó como un planificador, pero es difícil llamarlo planificador, ya que está solo arquitectónicamente. Este es un reemplazo para la capa de solicitud en el núcleo. Poco a poco, el desarrollo de blk-mq condujo a una revisión importante de toda la pila de E / S de Linux.
La idea es esta: usemos la capacidad nativa de los SSD para hacer concurrencia eficiente para E / S. Dependiendo de cuántas secuencias de E / S paralelas puede usar, hay colas honestas a través de las cuales simplemente escribimos tal como están en el SSD. Cada CPU tiene su propia cola para grabar.
Actualmente
blk-mq se está desarrollando y trabajando activamente. No hay razón para no usarlo. En los núcleos modernos, desde 4 y superiores, desde
blk-mq, la ganancia es notable, no 5-10%, pero significativamente más.
blk-mq es probablemente la mejor opción para trabajar con SSD.
En su forma actual,
blk-mq está directamente vinculado al controlador
NVMe Linux. No solo hay un controlador para Linux, sino también un controlador para Microsoft. Pero la idea de hacer
blk-mq y el controlador NVMe es el procesamiento mismo de la pila de Linux, de la cual las bases de datos se han beneficiado enormemente.
Un consorcio de varias compañías decidió hacer una especificación, este mismo protocolo. Ahora ya en versión de producción funciona bien para SSD PCIe locales. Solución casi lista para arreglos de discos que están conectados a través de la óptica.
El controlador blk-mq y NVMe son más que un programador. El sistema tiene como objetivo reemplazar todo el nivel de solicitudes.
Vamos a sumergirnos en él para entender lo que es. La especificación NVMe es grande, por lo que no consideraremos todos los detalles, sino que los revisaremos.
Viejo acercamiento a los ascensores

El caso más simple: hay una CPU, es su turno, y de alguna manera vamos al disco.
Los ascensores más avanzados funcionaron de manera diferente. Hay varias CPU y varias colas. De alguna manera, por ejemplo, dependiendo del proceso principal que los trabajadores de la base de datos separaron, IO se pone en cola en los discos.
Un nuevo enfoque para ascensores
blk-mq es un enfoque completamente nuevo. Cada CPU, cada zona NUMA agrega su propia entrada / salida a su vez. Además, los datos recaen en los discos, sin importar qué tan conectados estén, porque el controlador es nuevo. No hay un controlador SD que funcione con los conceptos de cilindros, bloques.
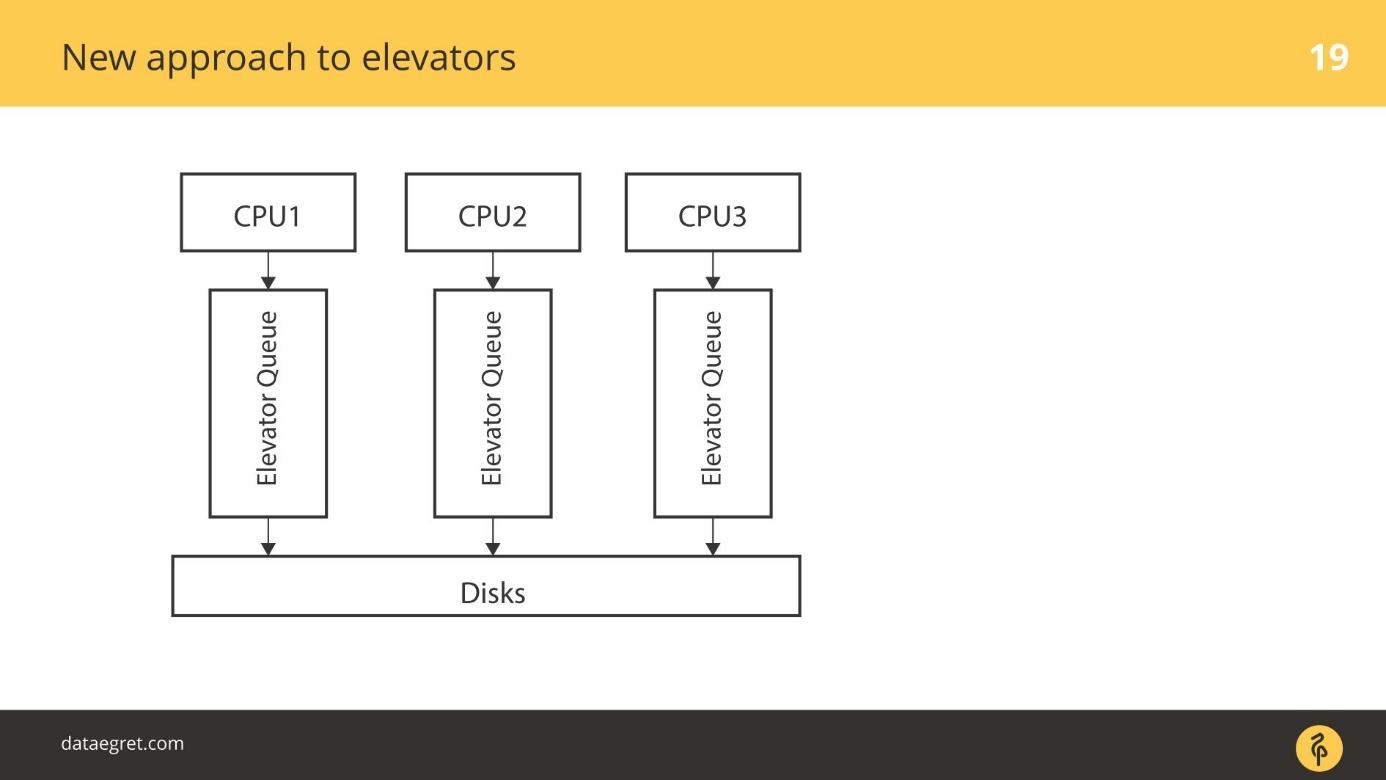
Hubo un período de transición. En algún momento, todos los proveedores de matrices RAID comenzaron a vender complementos que les permitieron omitir la caché RAID. Si los SSD están conectados, escriba directamente allí. Desactivaron el uso del controlador SD para sus productos, como blq-mq.
Nueva pila con blk-mq
Así es como se ve la pila en una nueva forma.

Desde arriba todo permanece también. Por ejemplo, las bases de datos están muy por detrás. La E / S de la base de datos, como antes, cae en la capa Block IO. Existe el muy
blk-mq que reemplaza la capa de consulta, no el planificador.
En el kernel 3.13, toda la optimización terminó aproximadamente al respecto, pero se utilizan nuevas tecnologías en los núcleos modernos. Comenzaron a aparecer planificadores especiales para
blk-mq , diseñados para un paralelismo más fuerte. Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
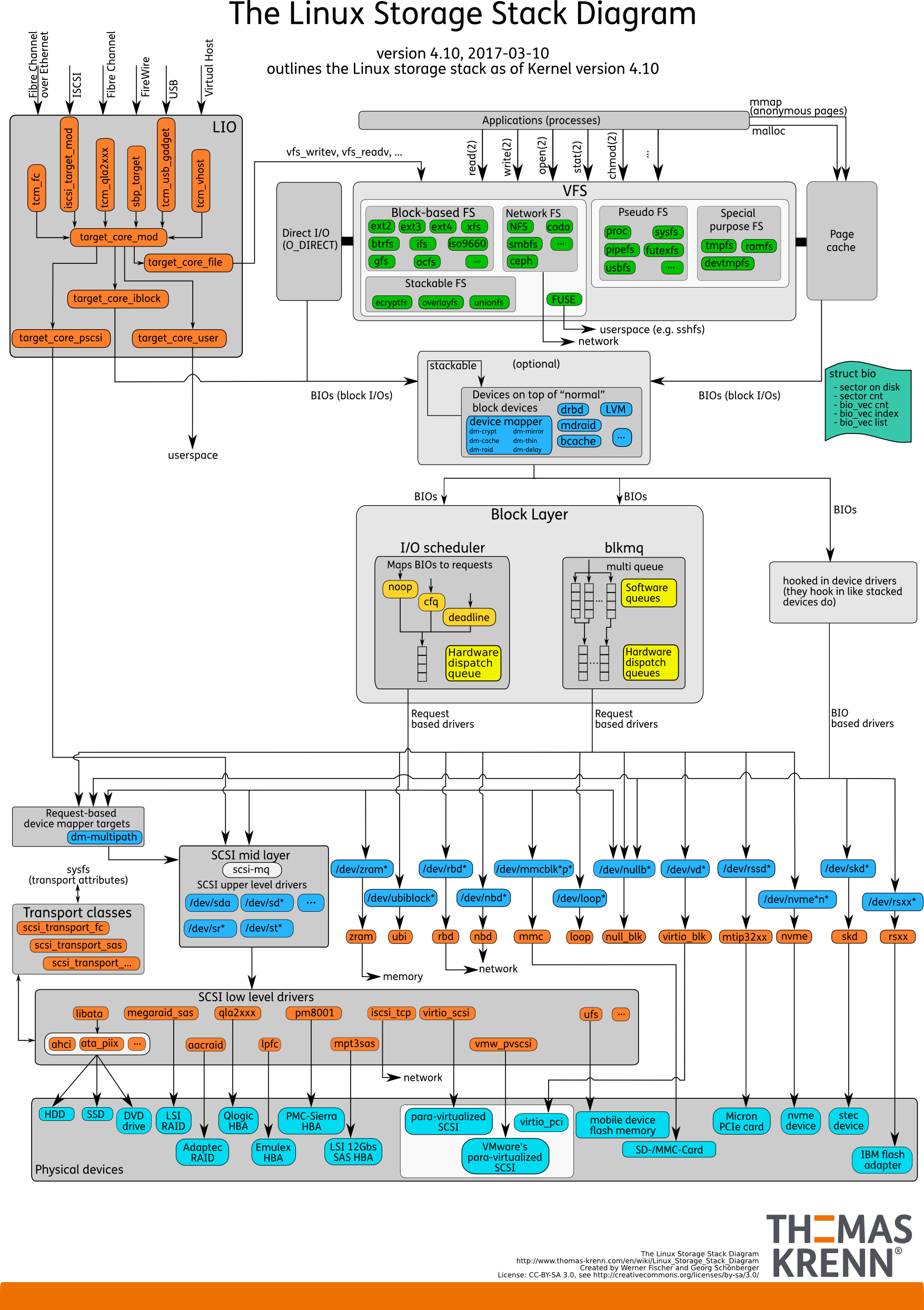
, , , Elevators, .
, , .
NVM Express
NVM Express NVMe — , , SSD. Linux. Linux — .
. 20 / SSD , NVMe , , —
32 / . SD , , .
, , .
Una vez que las bases de datos se escribieron para discos giratorios y se orientaron a ellas, tienen índices en forma de árbol B, por ejemplo. Surge la pregunta: ¿
están las bases de datos listas para NVMe ? ¿Son las bases de datos capaces de masticar tal carga?
Todavía no, pero se están adaptando. La lista de correo de PostgreSQL recientemente tuvo un par de
pwrite() y cosas similares. Los desarrolladores de PostgreSQL y MySQL interactúan con los desarrolladores del kernel. Por supuesto, me gustaría más interacción.
Desarrollos recientes
Durante el último año y medio, NVMe ha agregado
encuestas IO .
Al principio había discos giratorios con alta latencia. Luego vinieron los SSD, que son mucho más rápidos. Pero había una jamba: fsync continúa, comienza la grabación y, a un nivel muy bajo, en el controlador, se envía una solicitud directamente al hardware, escríbala.
El mecanismo era simple: lo enviaron y esperamos hasta que se procese la interrupción. Esperar el procesamiento de interrupción no es un problema en comparación con escribir en un disco giratorio. Tomó tanto tiempo esperar que tan pronto como terminó la grabación, la interrupción funcionó.
Dado que el SSD escribe muy rápidamente, ha aparecido forzadamente un mecanismo para sondear la pieza de hardware sobre la grabación. En las primeras versiones, el aumento en la velocidad de E / S alcanzó el 50% debido al hecho de que no estamos esperando una interrupción, pero estamos preguntando activamente al disco sobre el registro.
Este mecanismo se llama sondeo IO .
Fue introducido en versiones recientes. En la versión 4.12, aparecieron los
planificadores IO , especialmente afinados para trabajar con
blk-mq y NVMe, sobre lo que dije
Kyber y BFQ . Ya están oficialmente en el núcleo, se pueden usar.
Ahora en una forma utilizable existe el llamado
etiquetado IO . La mayoría de los fabricantes de nubes y máquinas virtuales contribuirán a este desarrollo. En términos generales, la entrada de una aplicación específica se puede agregar y darle prioridad. Las bases de datos aún no están listas para esto, pero estén atentos. Creo que pronto será la corriente principal.
Notas directas de E / S
PostgreSQL no es compatible con Direct IO, y hay una serie de problemas que dificultan la compatibilidad . Ahora esto solo es compatible con el valor, y solo si la replicación no está habilitada. Es necesario
escribir una gran cantidad de código específico del sistema operativo , y por ahora todos se abstienen de esto.
A pesar de que Linux confía mucho en la idea de Direct IO y cómo se implementa, todas las bases de datos van allí. En Oracle y MySQL, Direct IO es muy utilizado. PostgreSQL es la única base de datos que Direct IO no tolera.
Lista de verificación
Cómo protegerse de las sorpresas de fsync en PostgreSQL:
- Configure los puntos de control para que sean menos frecuentes y más grandes.
- Configure el escritor de fondo para ayudar al punto de control.
- Tire Autovacuum para que no haya E / S espurias innecesarias.
Según la tradición, en noviembre estamos esperando desarrolladores profesionales de servicios altamente cargados en Skolkovo en HighLoad ++ . Todavía hay un mes para solicitar un informe, pero ya hemos aceptado los primeros informes al programa . Suscríbase a nuestro boletín y conozca los nuevos temas de primera mano.