Publico el artículo original sobre Habr, cuya traducción se publica en el blog Codingsight .Sigo creando una versión de texto de mi charla en la reunión de subprocesos múltiples. La primera parte se puede encontrar
aquí o
aquí , allí se trataba más sobre el conjunto básico de herramientas para iniciar un hilo o tarea, formas de ver su estado y algunas pequeñas cosas dulces como PLinq. En este artículo, quiero centrarme más en los problemas que pueden surgir en un entorno multiproceso y en algunas formas de resolverlos.
Contenido
Acerca de los recursos compartidos
Es imposible escribir un programa que funcione en múltiples hilos, pero al mismo tiempo no tendría un solo recurso compartido: incluso si funciona en su nivel de abstracción, al bajar uno o más niveles por debajo resulta que todavía hay un recurso común. Daré algunos ejemplos:
Ejemplo # 1:Temiendo posibles problemas, hizo que los hilos funcionen con diferentes archivos. Por archivo a transmitir. Le parece que el programa no tiene un solo recurso común.
Después de haber bajado varios niveles a continuación, entendemos que solo hay un disco duro, y su controlador o sistema operativo tendrá que resolver los problemas para garantizar el acceso a él.
Ejemplo # 2:Después de leer el
ejemplo 1, decidió colocar los archivos en dos máquinas remotas diferentes con dos piezas de hierro y sistemas operativos físicamente diferentes. Mantenemos 2 conexiones diferentes a través de FTP o NFS.
Habiendo bajado varios niveles a continuación, entendemos que nada ha cambiado, y el controlador de la tarjeta de red o el sistema operativo de la máquina en la que se ejecuta el programa tendrá que resolver el problema del acceso competitivo.
Ejemplo # 3:Después de haber perdido una parte considerable de su cabello en un intento de probar la posibilidad de escribir un programa multiproceso, rechaza completamente los archivos y descompone los cálculos en dos objetos diferentes, los enlaces a cada uno de los cuales están disponibles solo para una secuencia.
Clavo la última docena de clavos en el ataúd de esta idea: un tiempo de ejecución y un recolector de basura, un programador de subprocesos, físicamente una RAM y memoria, un procesador todavía son recursos compartidos.
Entonces, descubrimos que es imposible escribir un programa multiproceso sin un único recurso compartido en todos los niveles de abstracción en todo el ancho de la pila de tecnología completa. Afortunadamente, cada uno de los niveles de abstracción, por regla general, resuelve parcial o completamente los problemas de acceso competitivo o simplemente lo prohíbe (por ejemplo: cualquier marco de UI prohíbe trabajar con elementos de diferentes hilos), por lo tanto, los problemas surgen con mayor frecuencia con recursos compartidos en Su nivel de abstracción. Para resolverlos, introduzca el concepto de sincronización.
Posibles problemas al trabajar en un entorno multiproceso
Los errores en el software se pueden dividir en varios grupos:
- El programa no produce un resultado. Se bloquea o se congela.
- El programa devuelve un resultado incorrecto.
- El programa produce el resultado correcto, pero no satisface uno u otro requisito no funcional. Corre demasiado tiempo o consume demasiados recursos.
En un entorno multiproceso, los dos problemas principales que causan los errores 1 y 2 son el
punto muerto y la
condición de carrera .
Punto muerto
Punto muerto - punto muerto. Hay muchas variaciones diferentes. Los más comunes son los siguientes:
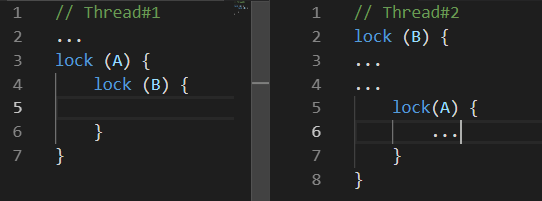
Mientras el
Hilo # 1 estaba haciendo algo, el
Hilo # 2 bloqueó el recurso
B , un poco más tarde el
Hilo # 1 bloqueó el recurso
A e intenta bloquear el recurso
B , desafortunadamente esto nunca sucederá, porque
El subproceso # 2 liberará el recurso
B solo después de bloquear el recurso
A.Condición de carrera
Condición de carrera: condición de carrera. La situación en la que el comportamiento y el resultado de los cálculos realizados por el programa dependen del trabajo del planificador de subprocesos en tiempo de ejecución.
Lo desagradable de esta situación radica precisamente en el hecho de que su programa puede no funcionar solo una vez de cada cien o incluso de un millón.
La situación se ve agravada por el hecho de que los problemas pueden ir juntos, por ejemplo: con un cierto comportamiento del planificador de subprocesos, se produce un punto muerto.
Además de estos dos problemas que conducen a errores obvios en el programa, también existen aquellos que pueden no conducir a un resultado de cálculo incorrecto, pero se gastará más tiempo o potencia de procesamiento para obtenerlo. Dos de estos problemas son:
Busy Wait y
Thread Starvation .
Ocupado-espera
Busy-Wait es un problema en el que el programa consume recursos del procesador no para realizar cálculos, sino para esperar.
A menudo, este problema en el código se parece a esto:
while(!hasSomethingHappened) ;
Este es un ejemplo de código extremadamente malo ya que Tal código ocupa completamente un núcleo de su procesador sin hacer absolutamente nada útil. Puede justificarse si y solo si es críticamente importante procesar un cambio en algún valor en otro hilo. Y hablando rápido, estoy hablando del caso cuando no puedes esperar ni siquiera unos pocos nanosegundos. En otros casos, es decir, en todo lo que puede producir un cerebro sano, es más razonable usar las variedades ResetEvent y sus versiones Slim. Sobre ellos a continuación.
Quizás uno de los lectores propondrá resolver el problema de cargar completamente un núcleo con una espera inútil agregando construcciones como Thread.Sleep (1) al bucle. Esto realmente resolverá el problema, pero creará otro: el tiempo de respuesta al cambio será en promedio de medio milisegundo, lo que puede no ser mucho, pero catastróficamente más de lo que podría usar las primitivas de sincronización de la familia ResetEvent.
Hilo de hambre
Thread-Starvation es un problema en el que el programa tiene demasiados hilos trabajando simultáneamente. ¿Qué significa exactamente esos flujos que están ocupados con los cálculos, y no solo esperando una respuesta de cualquier IO? Con este problema, se pierde toda la ganancia de rendimiento posible del uso de subprocesos, porque El procesador pasa mucho tiempo cambiando de contexto.
Es conveniente buscar tales problemas usando varios perfiladores, a continuación se muestra un ejemplo de una captura de pantalla del perfilador
dotTrace lanzado en modo Timeline.
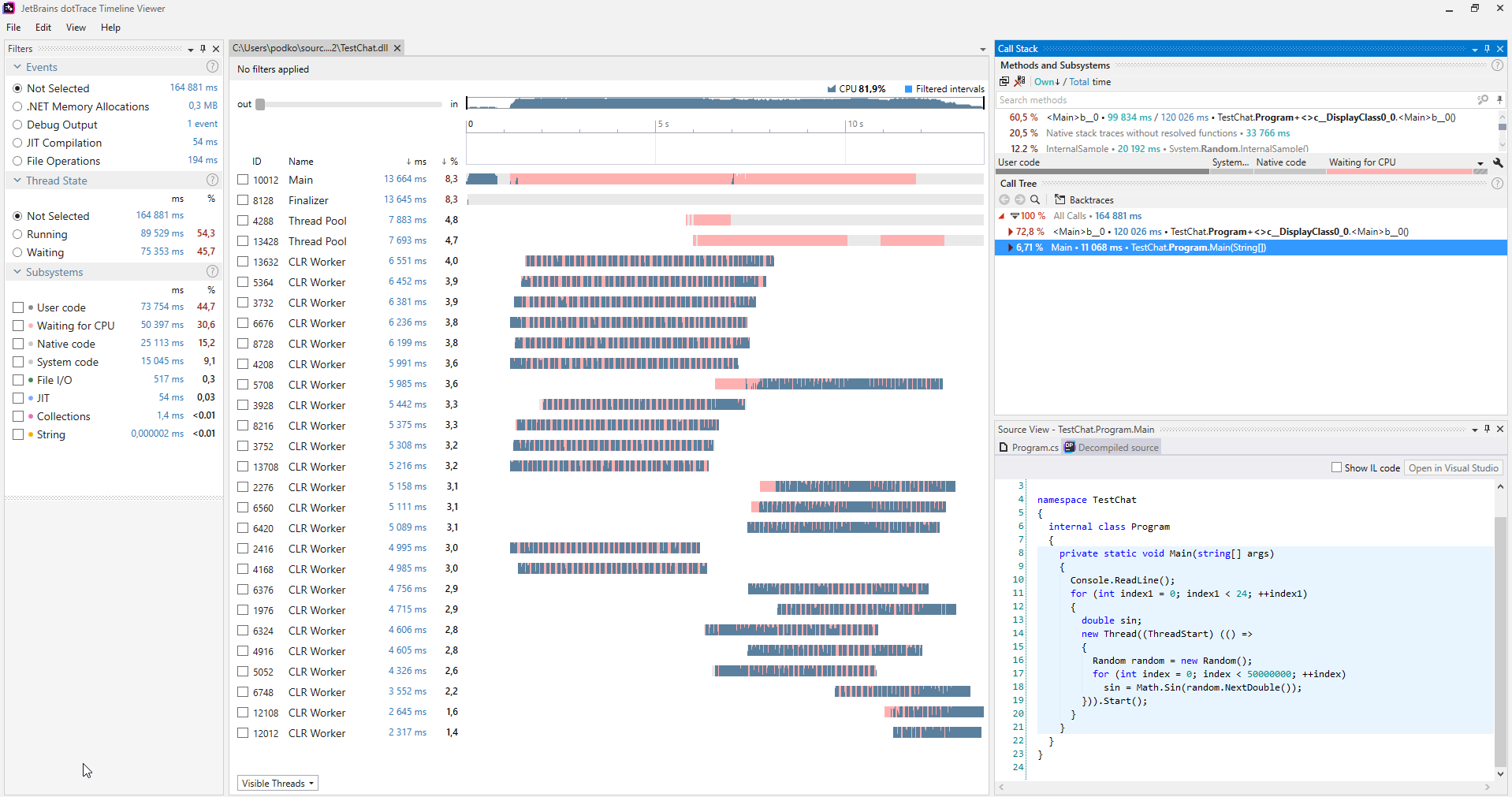 (Se puede hacer clic en la imagen)
(Se puede hacer clic en la imagen)En el programa que no sufre de hambre de transmisión, no habrá color rosa en los gráficos que reflejan las transmisiones. Además, en la categoría Subsistemas, está claro que el 30,6% del programa estaba esperando a la CPU.
Cuando se diagnostica un problema de este tipo, se resuelve de manera bastante simple: comenzó demasiados hilos a la vez, comenzó menos o no todos a la vez.
Herramientas de sincronización
Enclavado
Esta es quizás la forma más ligera de sincronizar. Interlocked es una colección de operaciones atómicas simples. Una operación atómica se llama operación en el momento en que nada puede suceder. En .NET, Interlocked está representado por la clase estática del mismo nombre con varios métodos, cada uno de los cuales implementa una operación atómica.
Para darse cuenta del horror de las operaciones no atómicas, intente escribir un programa que comience 10 hilos, cada uno de los cuales haga un millón de incrementos de la misma variable, y al final de su trabajo imprima el valor de esta variable; desafortunadamente será muy diferente de 10 millones, además Cada vez que se inicia el programa, será diferente. Esto sucede porque incluso una operación tan simple como un incremento no es atómica, sino que implica extraer un valor de la memoria, calcular uno nuevo y escribir de nuevo. Por lo tanto, dos subprocesos pueden realizar simultáneamente cada una de estas operaciones, en cuyo caso se perderá el incremento.
La clase Interlocked proporciona métodos de aumento / disminución; es fácil adivinar lo que hacen. Son convenientes de usar si está procesando datos en múltiples hilos y considera algo. Dicho código funcionará mucho más rápido que el bloqueo clásico. Si Interlocked se usa para la situación descrita en el último párrafo, el programa dará 10 millones de forma estable en cualquier situación.
El método CompareExchange realiza, a primera vista, una función bastante obvia, pero toda su presencia le permite implementar muchos algoritmos interesantes, especialmente la familia sin bloqueo.
public static int CompareExchange (ref int location1, int value, int comparand);
El método toma tres valores: el primero se pasa por referencia y este es el valor que se cambiará al segundo, si en el momento de la comparación location1 coincide con comparand, entonces se devolverá el valor original de location1. Suena bastante confuso, porque es más fácil escribir código que realice las mismas operaciones que CompareExchange:
var original = location1; if (location1 == comparand) location1 = value; return original;
Solo una implementación en la clase Interlocked será atómica. Es decir, si escribimos ese código nosotros mismos, podría haber ocurrido una situación cuando la condición location1 == comparand ya se había cumplido, pero para cuando se ejecutó la expresión location1 = value, otro subproceso había cambiado el valor de location1 y se perdería.
Podemos encontrar un buen ejemplo de uso de este método en el código que genera el compilador para cualquier evento de C #.
Escribamos una clase simple con un evento MyEvent:
class MyClass { public event EventHandler MyEvent; }
Construyamos el proyecto en la configuración de lanzamiento y abramos el ensamblaje usando
dotPeek con la opción Mostrar código generado por el compilador activada:
[CompilerGenerated] private EventHandler MyEvent; public event EventHandler MyEvent { [CompilerGenerated] add { EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler; eventHandler = Interlocked.CompareExchange<EventHandler>(ref this.MyEvent, (EventHandler) Delegate.Combine((Delegate) comparand, (Delegate) value), comparand); } while (eventHandler != comparand); } [CompilerGenerated] remove {
Aquí puede ver que detrás de escena, el compilador generó un algoritmo bastante sofisticado. Este algoritmo protege contra la situación de perder una suscripción a un evento cuando varios hilos se suscriben a este evento simultáneamente. Escribamos el método add con más detalle, recordando lo que hace el método CompareExchange detrás de escena
EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler;
Esto ya está un poco más claro, aunque probablemente todavía necesite una explicación. En palabras, describiría este algoritmo de la siguiente manera:
Si MyEvent sigue igual que en el momento en que comenzamos a ejecutar Delegate.Combine, escriba en él lo que Delegate.Combine devuelve, y si no, no importa, intentemos nuevamente y repita hasta que salga.
Por lo tanto, no se perderá ninguna suscripción al evento. Tendrá que resolver un problema similar si de repente desea implementar una matriz dinámica libre de bloqueos segura para subprocesos. Si varias secuencias se apresuran a agregarle elementos, entonces es importante que todas se agreguen al final.
Monitor.Enter, Monitor.Exit, lock
Estas son las construcciones más utilizadas para la sincronización de subprocesos. Implementan la idea de una sección crítica: es decir, el código escrito entre llamadas a Monitor.Enter, Monitor.Exit en un recurso puede ejecutarse al mismo tiempo en un solo hilo. La declaración de bloqueo es azúcar sintáctica alrededor de las llamadas de entrada / salida envueltas en try-finally. Una buena característica de implementar una sección crítica en .NET es la capacidad de volver a ingresarla para la misma secuencia. Esto significa que dicho código se ejecutará sin problemas:
lock(a) { lock (a) { ... } }
Es poco probable, por supuesto, que alguien escriba de esta manera, pero si difunde este código en varios métodos en profundidad, esta función puede ahorrarle algunos errores. Para hacer posible este truco, los desarrolladores de .NET tuvieron que agregar una restricción: solo se puede usar una instancia de un tipo de referencia como objeto de sincronización, y se agregan implícitamente varios bytes a cada objeto donde se escribirá el identificador de flujo.
Esta característica de la sección crítica en c # impone una limitación interesante en el funcionamiento de la declaración de bloqueo: no puede usar la declaración de espera dentro de la declaración de bloqueo. Al principio, me sorprendió, porque se compila una construcción similar de Try-finally Monitor.Enter / Exit. Cual es el problema Aquí es necesario volver a leer cuidadosamente el último párrafo una vez más, y luego agregarle algún conocimiento sobre el principio de async / wait: el código después de wait no necesariamente se ejecutará en el mismo hilo que el código antes de wait, depende del contexto de sincronización y la presencia o sin llamada a ConfigureAwait. De ello se deduce que Monitor.Exit puede ejecutarse en un subproceso que no sea Monitor.Enter, que generará una
SynchronizationLockException . Si no lo cree, puede ejecutar el siguiente código en una aplicación de consola: arrojará una SynchronizationLockException.
var syncObject = new Object(); Monitor.Enter(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId); await Task.Delay(1000); Monitor.Exit(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
Es de destacar que en WinForms o una aplicación WPF, este código funcionará correctamente si se llama desde el hilo principal. Habrá un contexto de sincronización que implementa un retorno al UI-Thread después de esperar. En cualquier caso, no debe jugar con la sección crítica en el contexto del código que contiene el operador de espera. En estos casos, es mejor usar primitivas de sincronización, que se discutirán más adelante.
Hablando sobre el trabajo de la sección crítica en .NET, vale la pena mencionar otra característica de su implementación. La sección crítica en .NET opera en dos modos: modo spin-wait y modo kernel. El algoritmo spin-wait se representa convenientemente como el siguiente pseudocódigo:
while(!TryEnter(syncObject)) ;
Esta optimización está dirigida a la captura más rápida de la sección crítica en poco tiempo, sobre la base de la suposición de que si el recurso está ocupado ahora, está a punto de liberarse ahora. Si esto no sucede en un corto período de tiempo, el subproceso va a esperar en modo kernel, lo que, como volver de él, lleva tiempo. Los desarrolladores de .NET han optimizado el escenario de bloqueo corto tanto como sea posible, desafortunadamente, si muchos hilos comienzan a romper la sección crítica, esto puede conducir a una carga de CPU alta y repentina.
SpinLock, SpinWait
Como mencioné el algoritmo spin-wait, vale la pena mencionar las estructuras BCL SpinLock y SpinWait. Deben usarse si hay razones para creer que siempre habrá una oportunidad de bloquear rápidamente. Por otro lado, apenas vale la pena recordarlos antes de que los resultados de la creación de perfiles muestren que el uso de otras primitivas de sincronización es el cuello de botella de su programa.
Monitor.Wait, Monitor.Pulse [Todos]
Este par de métodos se deben considerar juntos. Con su ayuda, se pueden implementar varios escenarios Productor-Consumidor.
Productor-Consumidor: un patrón de diseño multiproceso / multiproceso que supone la presencia de uno o más subprocesos / procesos que producen datos y uno o más procesos / subprocesos que procesan estos datos. Usualmente usa una colección compartida.Ambos métodos solo se pueden invocar si el hilo que los está causando tiene un bloqueo en este momento. El método de espera libera el bloqueo y se cuelga hasta que otro hilo llama a Pulse.
Para demostrar el trabajo, escribí un pequeño ejemplo:
object syncObject = new object(); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
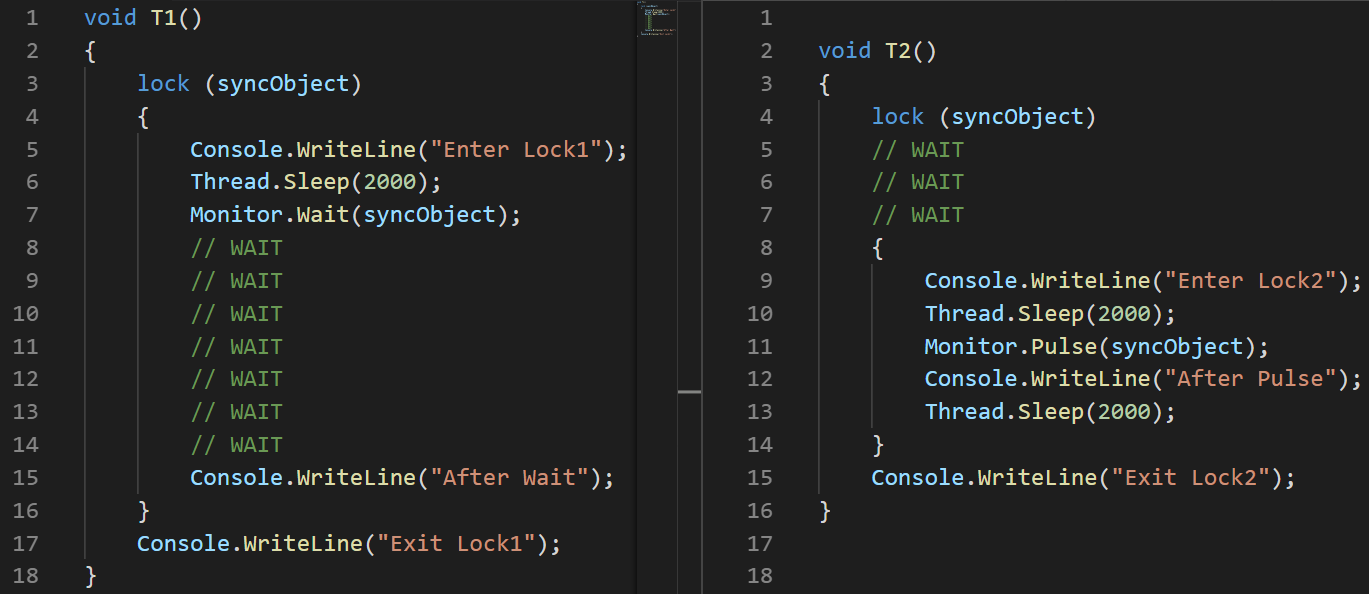 (Usé la imagen, no el texto, para mostrar visualmente el orden de ejecución de las instrucciones)Parse: establezca
(Usé la imagen, no el texto, para mostrar visualmente el orden de ejecución de las instrucciones)Parse: establezca un retraso de 100 ms al comienzo de la segunda transmisión, específicamente para garantizar que su ejecución comience más tarde.
- T1: comienza la transmisión de la línea n. ° 2
- T1: la línea # 3 ingresa a la sección crítica
- T1: Línea # 6 la corriente se queda dormida
- T2: comienza la transmisión de la línea n. ° 3
- T2: la línea 4 se congela mientras espera una sección crítica
- T1: la línea # 7 libera la sección crítica y se congela mientras espera que Pulse salga
- T2: la línea # 8 ingresa a la sección crítica
- T2: la línea # 11 notifica a T1 utilizando el método Pulse
- T2: la línea # 14 sale de la sección crítica. Hasta entonces, T1 no puede continuar la ejecución.
- T1: la línea # 15 se despierta
- T1: la línea # 16 deja la sección crítica
MSDN tiene una observación importante con respecto al uso de los métodos Pulse / Wait, a saber: El monitor no almacena información de estado, lo que significa que si se llama al método Pulse antes de que se llame al método Wait, puede llegar a un punto muerto. Si esta situación es posible, entonces es mejor usar una de las clases de la familia ResetEvent.El ejemplo anterior demuestra claramente cómo funcionan los métodos Wait / Pulse de la clase Monitor, pero aún deja dudas sobre cuándo se debe usar. Un buen ejemplo sería una implementación de BlockingQueue <T>, por otro lado, la implementación de BlockingCollection <T> de System.Collections.Concurrent usa SemaphoreSlim para la sincronización.
ReaderWriterLockSlim
Esta es mi primitiva de sincronización amada, representada por la clase de espacio de nombres System.Threading del mismo nombre. Me parece que muchos programas funcionarían mejor si sus desarrolladores usaran esta clase en lugar del bloqueo habitual.
Idea: muchos hilos pueden leer, solo uno escribe. Tan pronto como la transmisión declara su deseo de escribir, no se pueden iniciar nuevas lecturas, pero esperarán a que se complete la grabación. También existe el concepto de bloqueo de lectura actualizable, que se puede utilizar si comprende durante el proceso de lectura que necesita escribir algo, dicho bloqueo se convertirá en bloqueo de escritura en una operación atómica.También hay una clase ReadWriteLock en el espacio de nombres System.Threading, pero es muy recomendable para nuevos desarrollos. La versión delgada permitirá evitar una serie de casos que conducen a puntos muertos, además de que le permite capturar rápidamente el bloqueo, porque admite sincronización en modo de espera de giro antes de salir para el modo kernel.Si en el momento de leer este artículo aún no conocía esta clase, creo que ha recordado muchos ejemplos del código escrito recientemente, donde tal enfoque de bloqueo permitiría que el programa funcione de manera eficiente.
La interfaz de la clase ReaderWriterLockSlim es simple y directa, pero su uso difícilmente puede llamarse conveniente:
var @lock = new ReaderWriterLockSlim(); @lock.EnterReadLock(); try {
Me gusta envolver su uso en una clase, lo que hace que usarlo sea mucho más conveniente.
Idea: para hacer métodos de lectura / escritura de bloqueo que devuelven un objeto con el método de eliminación, esto permitirá que se usen en el uso y por el número de líneas difícilmente diferirá del bloqueo habitual.
class RWLock : IDisposable { public struct WriteLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public WriteLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterWriteLock(); } public void Dispose() => @lock.ExitWriteLock(); } public struct ReadLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public ReadLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterReadLock(); } public void Dispose() => @lock.ExitReadLock(); } private readonly ReaderWriterLockSlim @lock = new ReaderWriterLockSlim(); public ReadLockToken ReadLock() => new ReadLockToken(@lock); public WriteLockToken WriteLock() => new WriteLockToken(@lock); public void Dispose() => @lock.Dispose(); }
Tal truco te permite simplemente escribir más:
var rwLock = new RWLock();
ResetEvent Family
Incluyo las clases ManualResetEvent, ManualResetEventSlim, AutoResetEvent para esta familia.
Las clases ManualResetEvent, su versión Slim y la clase AutoResetEvent pueden estar en dos estados:
- Sin señalizar, en este estado, todos los hilos que llamaron a WaitOne se cuelgan hasta que el evento pase al estado señalado.
- El estado bajado (indicado), en este estado se liberan todos los flujos que cuelgan de la llamada WaitOne. Todas las nuevas llamadas WaitOne en un evento en desuso pasan condicionalmente al instante.
La clase AutoResetEvent difiere de la clase ManualResetEvent en que ingresa automáticamente en un estado activado después de liberar exactamente un subproceso. Si varios subprocesos se cuelgan esperando AutoResetEvent, entonces la llamada Set liberará solo un arbitrario, a diferencia de ManualResetEvent. ManualResetEvent lanzará todos los hilos.
Veamos un ejemplo de cómo funciona AutoResetEvent:
AutoResetEvent evt = new AutoResetEvent(false); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
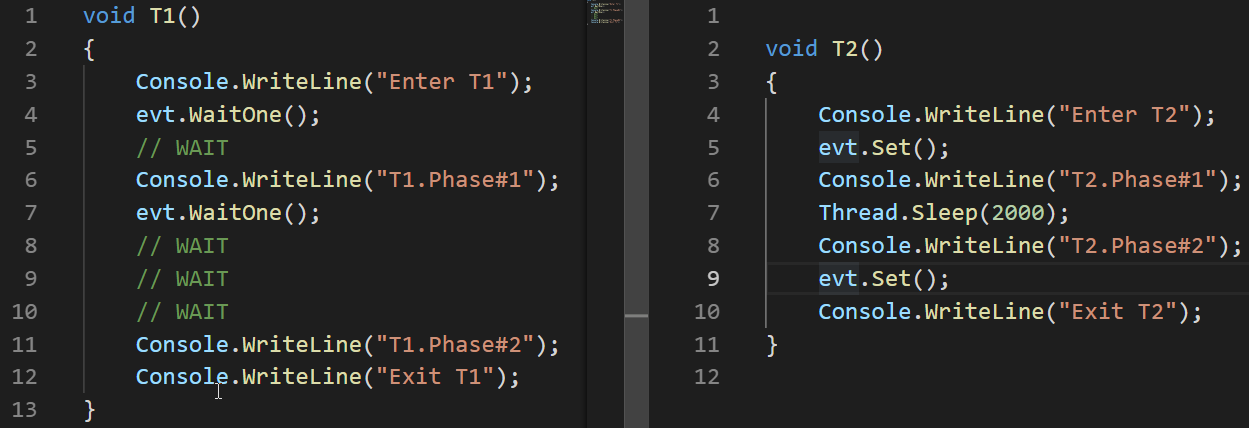
El ejemplo muestra que el evento entra en un estado de armado (sin señalización) automáticamente solo al soltar el hilo que cuelga en la llamada WaitOne.
La clase ManualResetEvent, a diferencia de ReaderWriterLock, no está marcada como obsoleta y no se recomienda su uso después de la aparición de su versión Slim. La versión delgada de esta clase se usa eficientemente para expectativas cortas, ya que Sucede en el modo Spin-Wait, la versión normal es adecuada para los largos.
Además de las clases ManualResetEvent y AutoResetEvent, también existe la clase CountdownEvent. Esta clase es conveniente para la implementación de algoritmos, donde la parte que logró ser paralela es seguida por la parte de reunir los resultados. Este enfoque se conoce como
fork-join . Un excelente
artículo está dedicado al trabajo de esta clase, por lo tanto, no lo analizaré en detalle aquí.
Conclusiones
- Cuando se trabaja con subprocesos, dos problemas que resultan en resultados incorrectos o faltantes son condición de carrera y punto muerto
- Los problemas que hacen que el programa gaste más tiempo o recursos: hambruna de hilos y espera ocupada
- .NET es rico en sincronización de hilos
- Hay 2 modos de espera de bloqueo: Spin Wait, Core Wait. Algunas primitivas de sincronización de hilos .NET usan ambos
- Interlocked es un conjunto de operaciones atómicas, utilizado en algoritmos sin bloqueo, es la primitiva de sincronización más rápida
- El operador de bloqueo y Monitor.Enter / Exit implementan la idea de una sección crítica: un código que solo puede ejecutarse por un hilo a la vez
- Los métodos Monitor.Pulse / Wait son convenientes para implementar scripts Productor-Consumidor
- ReaderWriterLockSlim puede ser más eficiente que el bloqueo regular en scripts donde la lectura paralela es aceptable
- La familia de clases ResetEvent puede ser útil para la sincronización de subprocesos.