
Expresar lo que las palabras no pueden transmitir; Siente las emociones más diversas entrelazadas en un huracán de sentimientos; separarse de la tierra, el cielo e incluso el Universo mismo, emprender un viaje donde no hay mapas, ni carreteras, ni señales; inventar, contar y revivir una historia completa que siempre será única e inimitable. Todo esto le permite hacer música, un arte que ha existido durante miles de años y deleita nuestros oídos y corazones.
Sin embargo, la música, o más bien la música, puede servir no solo para el placer estético, sino también para transmitir información codificada en ellos, destinada a cualquier dispositivo e invisible para el oyente. Hoy nos reuniremos con usted en un estudio muy inusual, en el que los estudiantes graduados de la Escuela Técnica Superior Suiza de Zúrich pudieron insertar imperceptiblemente ciertos datos en obras musicales para el oído humano, debido a que la música en sí misma se convierte en un canal de transmisión de datos. ¿Cómo se dieron cuenta exactamente de su tecnología, son las melodías muy diferentes con y sin datos integrados, y qué muestran las pruebas prácticas? Aprendemos sobre esto del informe de los investigadores. Vamos
Base de estudio
Los investigadores llaman a su tecnología una técnica de transmisión de datos acústica. Cuando el hablante reproduce la melodía cambiada, una persona la percibe como de costumbre, pero, por ejemplo, un teléfono inteligente puede leer información codificada entre líneas, más precisamente entre notas, si puedo decirlo. El aspecto más importante en la implementación de este método de transferencia de datos, los científicos (el hecho de que estos muchachos aún sean estudiantes graduados no les impide ser científicos) llaman a la velocidad y la confiabilidad de la transmisión mientras mantienen el nivel de estos parámetros, independientemente del archivo de audio seleccionado. La psicoacústica, que estudia los aspectos psicológicos y fisiológicos de la percepción humana de los sonidos, ayuda a hacer frente a esta tarea.
El núcleo de la transmisión de datos acústicos se puede llamar OFDM (multiplexación por división de frecuencia ortogonal), que, junto con la adaptación de las subportadoras a la música original a lo largo del tiempo, permitió maximizar el uso del espectro de frecuencia transmitido para transmitir información. Gracias a esto, fue posible alcanzar una velocidad de transmisión de 412 bit / s en una distancia de 24 metros (tasa de error <10%). Experimentos prácticos en los que participaron 40 voluntarios confirmaron el hecho de que es casi imposible escuchar la diferencia entre la melodía original y aquella en la que se insertó la información.
¿Dónde se puede aplicar esta tecnología en la práctica? Los investigadores tienen su propia respuesta: casi todos los teléfonos inteligentes modernos, computadoras portátiles y otros dispositivos portátiles están equipados con micrófonos, y en muchos lugares públicos (cafeterías, restaurantes, centros comerciales, etc.) hay altavoces con música de fondo. Por ejemplo, los datos para conectarse a una red Wi-Fi pueden integrarse en esta melodía de fondo sin la necesidad de realizar acciones adicionales.
Las características generales de la transmisión acústica de datos nos han quedado claras, ahora pasamos a un estudio detallado de la estructura de este sistema.
Descripción del sistema
La incorporación de datos en una melodía se produce debido al enmascaramiento de frecuencia. En intervalos de tiempo, se identifican las frecuencias de enmascaramiento y las subportadoras OFDM cercanas a estos elementos de enmascaramiento se rellenan con datos.
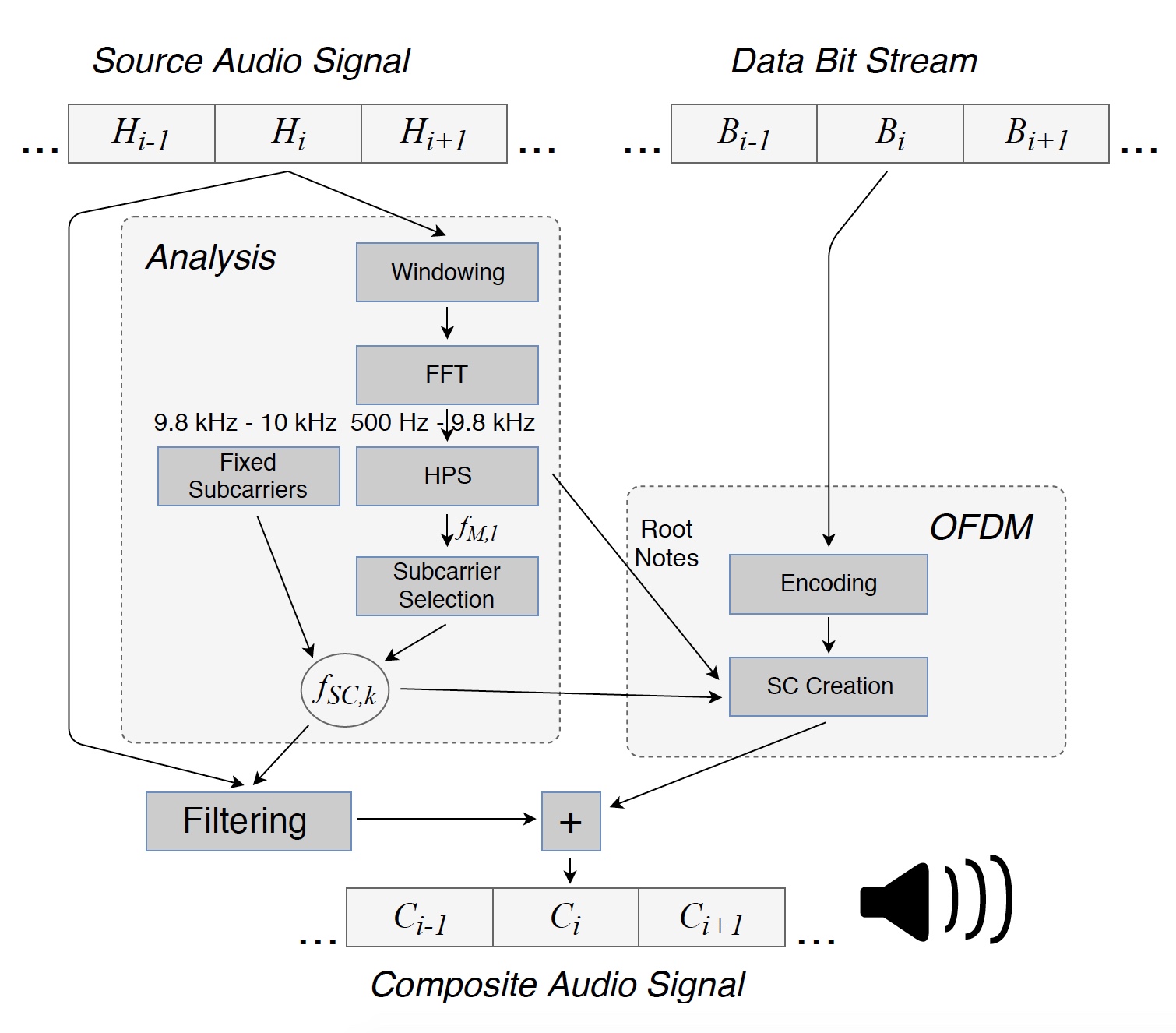 Imagen n. ° 1: Convierta el archivo fuente en una señal compuesta (melodía + datos) transmitida a través de los altavoces.
Imagen n. ° 1: Convierta el archivo fuente en una señal compuesta (melodía + datos) transmitida a través de los altavoces.Para empezar, la señal de audio original se divide en segmentos consecutivos para su análisis. Cada uno de estos segmentos (H
i ) de L = 8820 muestras, igual a 200 ms, se multiplica por una
ventana * para minimizar los efectos de límite.
Window * es la función de peso utilizada para controlar los efectos debido a la presencia de lóbulos laterales en las estimaciones espectrales.
Luego, las frecuencias dominantes de la señal inicial se encontraron en el rango de 500 Hz a 9.8 kHz, lo que permitió obtener frecuencias de enmascaramiento f
M, l para este segmento. Además, los datos se transmitieron en el rango pequeño de 9.8 a 10 kHz para determinar la ubicación de las subportadoras en el receptor. El límite superior del rango de frecuencia utilizado se estableció en 10 kHz debido a la baja sensibilidad del micrófono del teléfono inteligente a altas frecuencias.
Las frecuencias de enmascaramiento se determinaron individualmente para cada segmento analizado. Usando el método HPS (espectro armónico de productos), se establecieron tres frecuencias dominantes, después de lo cual se redondearon a las notas más cercanas de la escala cromática armónica. Así se obtuvieron las notas principales f
F, i = 1 ... 3, situadas entre las teclas C0 (16,35 Hz) y B0 (30,87 Hz). Basado en el hecho de que las notas principales son demasiado bajas para su uso en la transmisión de datos, en el rango de 500 Hz ... 9.8 kHz se calcularon sus octavas más altas 2
k f
F. Muchas de estas frecuencias (f
O, l 1 ) fueron más pronunciadas debido a la naturaleza de HPS.
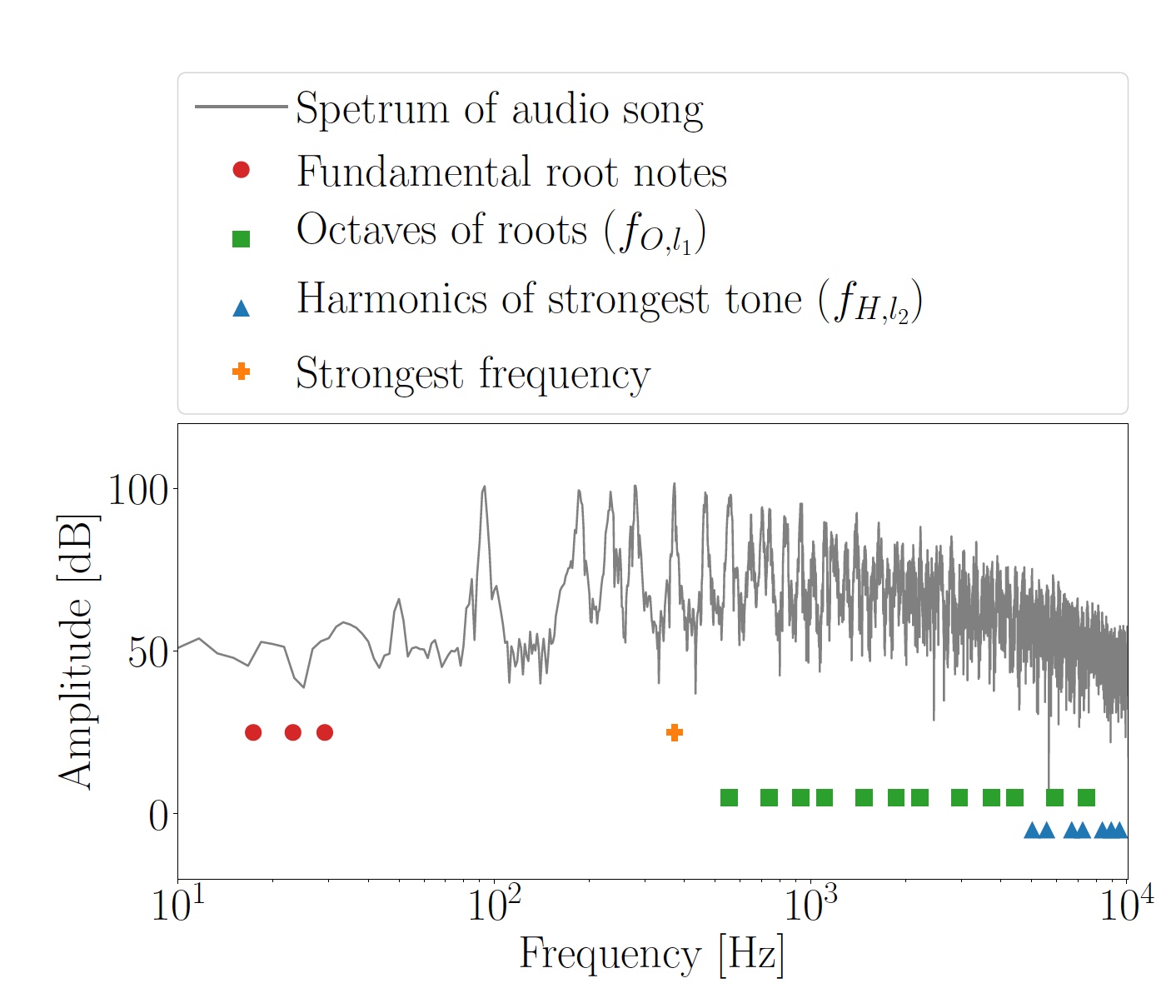 Imagen No. 2: octavas calculadas f O, l 1 para las notas principales y armónicos f H, l 2 del tono más fuerte.
Imagen No. 2: octavas calculadas f O, l 1 para las notas principales y armónicos f H, l 2 del tono más fuerte.La totalidad de octavas y armónicos se utilizó como frecuencias de enmascaramiento, en base a las cuales se obtuvieron las frecuencias OFDM de la subportadora f
SC, k . Por debajo y por encima de cada frecuencia de enmascaramiento, se insertaron dos subportadoras.
Luego, el espectro del segmento de audio H
i se filtró en las frecuencias de subportadora f
SC, k . Luego, en base a los bits de información en Bi, se creó un símbolo OFDM, debido al cual el segmento compuesto C
i podría transmitirse a través del altavoz. Los valores y las fases de las subportadoras deben seleccionarse para que el receptor pueda recuperar los datos transmitidos, mientras que el oyente no nota cambios en la melodía.
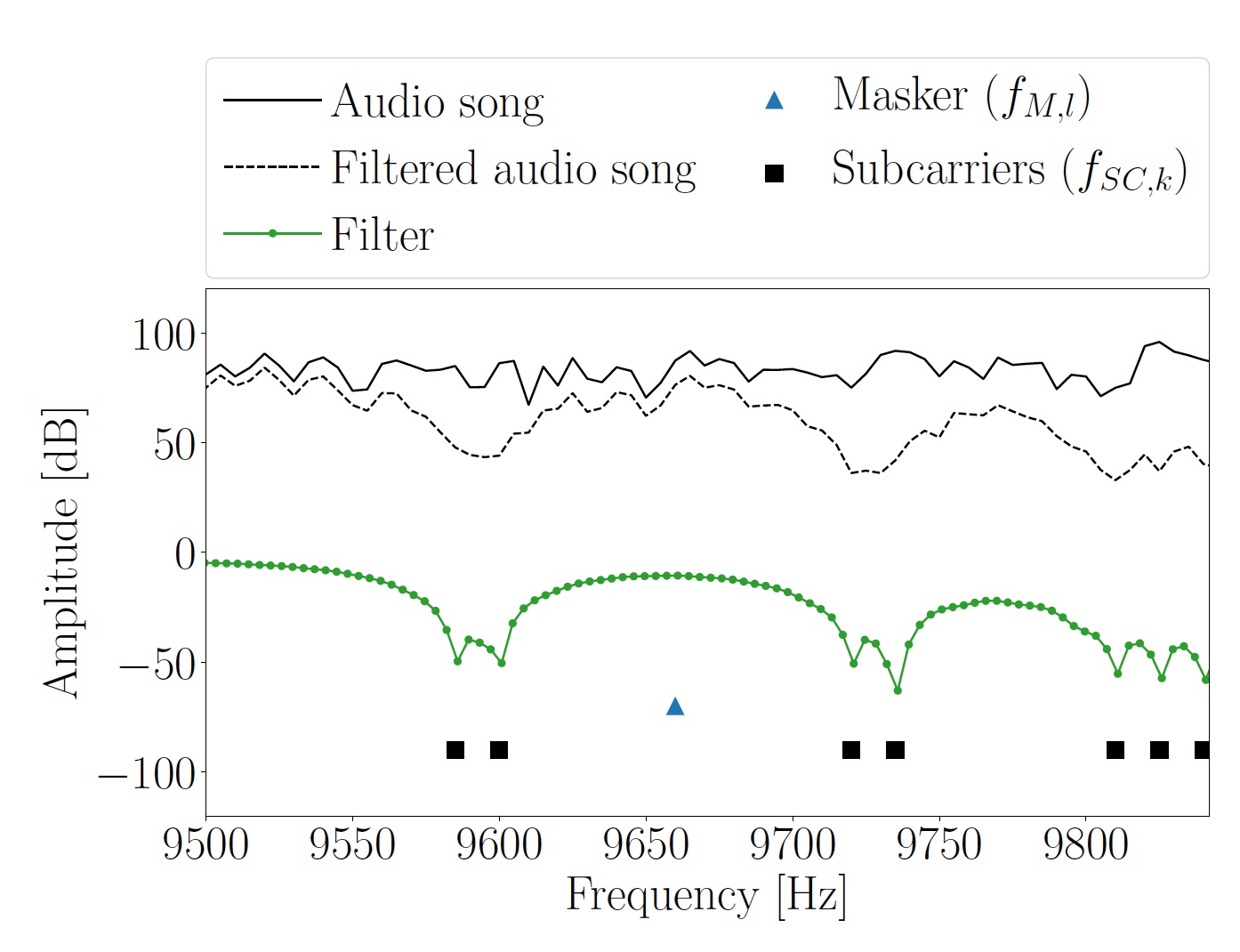 Imagen 3: gráfico del espectro y frecuencia de las subportadoras del segmento Hi de la melodía original.
Imagen 3: gráfico del espectro y frecuencia de las subportadoras del segmento Hi de la melodía original.Cuando una señal de audio con la información codificada se reproduce a través de los altavoces, el micrófono del dispositivo receptor la graba. Para encontrar las posiciones iniciales de los símbolos OFDM incrustados, primero se deben omitir las entradas mediante el filtrado de paso de banda. De esta manera, el rango de frecuencia superior se extrae donde no hay señal de interferencia musical entre las subportadoras. Puede encontrar el comienzo de los símbolos OFDM utilizando un prefijo cíclico.
Después de detectar el comienzo de los símbolos OFDM, el receptor obtiene información sobre las notas más dominantes decodificando el dominio de frecuencia superior. Además, OFDM es suficientemente robusto contra las fuentes de interferencia de banda estrecha, ya que afectan solo a algunas de las subportadoras.
Pruebas prácticas
El altavoz KRK Rokit 8 actuó como la fuente de las melodías cambiadas, y el teléfono inteligente Nexus 5X jugó en el lado del host.
 Imagen 4: La diferencia entre las manifestaciones reales de OFDM y los picos de correlación medidos en interiores a una distancia de 5 m entre el altavoz y el micrófono.
Imagen 4: La diferencia entre las manifestaciones reales de OFDM y los picos de correlación medidos en interiores a una distancia de 5 m entre el altavoz y el micrófono.La mayoría de los puntos OFDM varían de 0 a 25 ms, por lo que puede encontrar un inicio válido dentro del prefijo cíclico de 66,6 ms. Los investigadores señalan que el receptor (en este experimento, un teléfono inteligente) tiene en cuenta que los símbolos OFDM se reproducen periódicamente, lo que mejora su detección.
Lo primero que se comprobó fue el efecto de la distancia en la tasa de error de bit (BER). Para hacer esto, se realizaron tres pruebas en diferentes tipos de habitaciones: un pasillo con alfombra, una oficina con linóleo en el piso y una audiencia con piso de madera.
La canción "And The Cradle Will Rock" de Van Halen fue elegida como "sujeto de prueba".El volumen del sonido se ajustó para que el nivel de sonido medido por el teléfono inteligente a una distancia de 2 m del altavoz fuera de 63 dB.
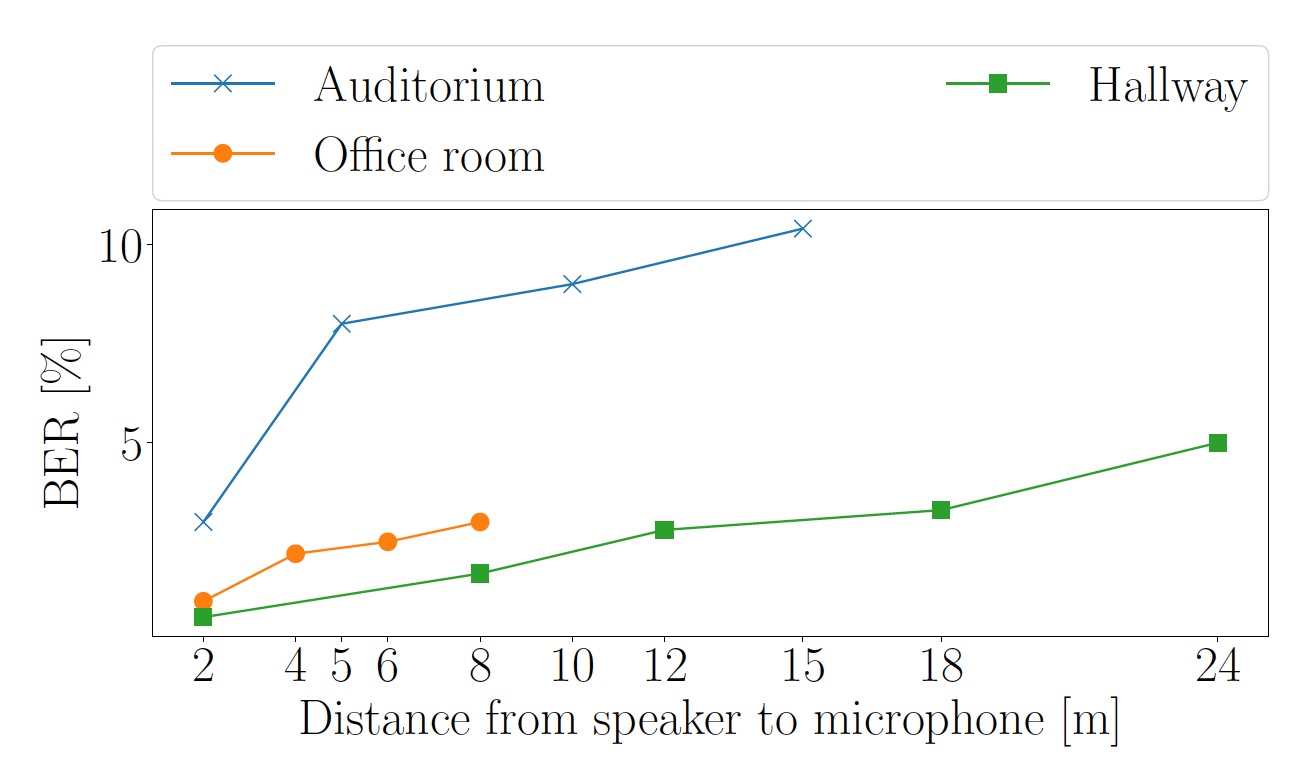 Imagen No. 5: Indicadores BER dependiendo de la distancia entre el altavoz y el micrófono (línea azul - audiencia, verde - pasillo, naranja - oficina).
Imagen No. 5: Indicadores BER dependiendo de la distancia entre el altavoz y el micrófono (línea azul - audiencia, verde - pasillo, naranja - oficina).En el pasillo, un teléfono inteligente captó un sonido de 40 dB a una distancia de hasta 24 metros del altavoz. En la audiencia a una distancia de 15 m, el sonido era de 55 dB, y en la oficina a una distancia de 8 metros, el nivel de sonido percibido por el teléfono inteligente alcanzó los 57 dB.
Debido al hecho de que la audiencia y la oficina son más reverberantes, los ecos del símbolo OFDM tardío exceden la longitud del prefijo cíclico y aumentan la BER.
Reverb * : una disminución gradual de la intensidad del sonido debido a su reflejo múltiple.
Además, los investigadores demostraron la versatilidad de su sistema al aplicarlo a 6 canciones diferentes de tres géneros (tabla a continuación).
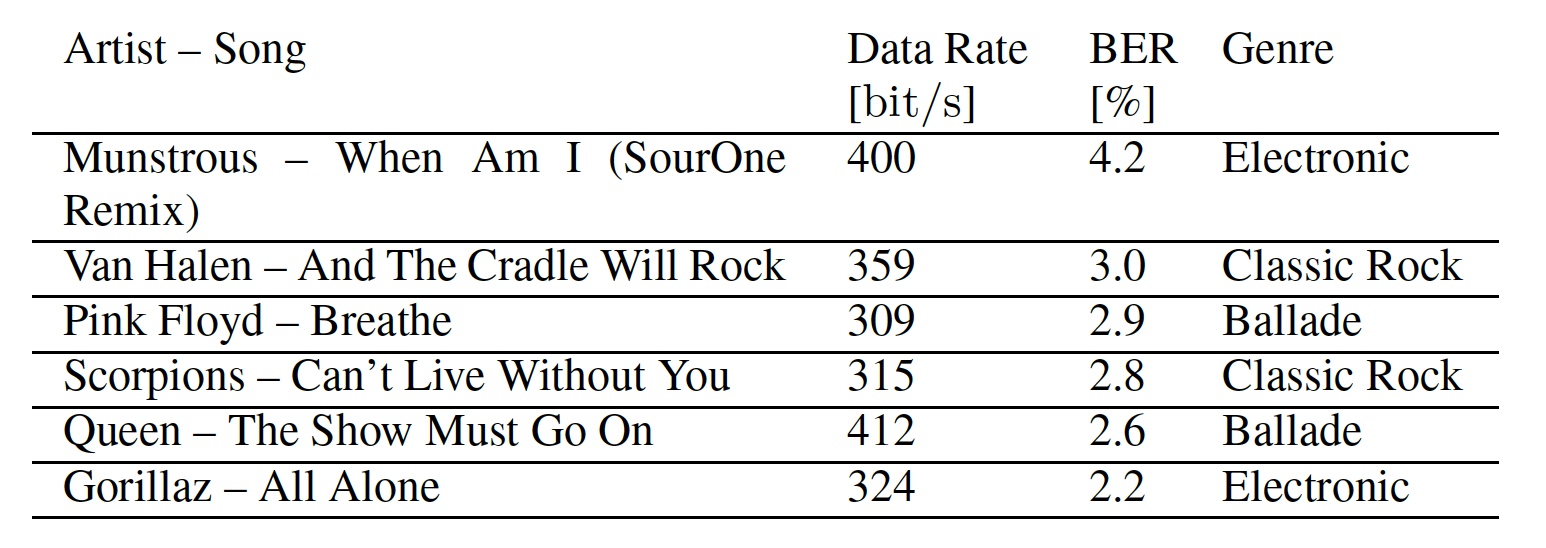 Tabla No. 1: canciones usadas en pruebas.
Tabla No. 1: canciones usadas en pruebas.Además, a través de los datos en la tabla, podemos ver la tasa de bits y las tasas de error de bits para cada canción. La velocidad de transferencia de datos es diferente porque el BPSK diferencial (modulación por desplazamiento de fase) funciona mejor cuando se usan las mismas subportadoras. Y esto es posible cuando los segmentos adyacentes contienen los mismos elementos de enmascaramiento. Las canciones con volumen continuo proporcionan una base óptima para ocultar datos, ya que las frecuencias de enmascaramiento son más pronunciadas en un amplio rango de frecuencias. La música que cambia rápidamente puede enmascarar los símbolos OFDM solo parcialmente debido a la longitud fija de la ventana de análisis.
A continuación, las personas comenzaron a probar el sistema, que supuestamente debían determinar qué melodía era original y cuál fue modificada por la información incluida. Para esto, se publicaron extractos de 12 segundos de canciones de la tabla No. 1 en un sitio especial.
En el primer experimento (E1), cada participante recibió un fragmento modificado u original para escuchar, y tuvo que decidir si este fragmento era original o si había cambiado. En el segundo experimento (E2), los participantes pudieron escuchar ambas opciones tantas veces como quisieran y luego decidir cuál es original y cuál se cambia.
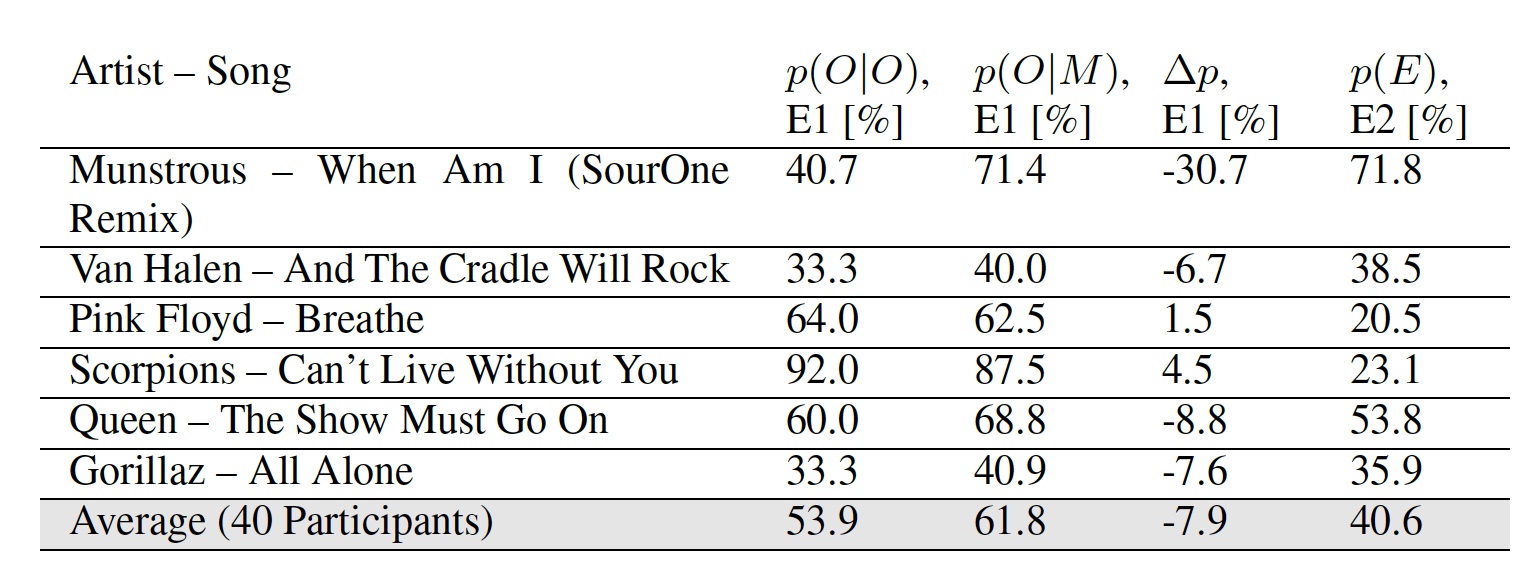 Tabla No. 2: resultados de los experimentos E1 y E2.
Tabla No. 2: resultados de los experimentos E1 y E2.Los resultados del primer experimento tienen dos indicadores: p ( | ) - porcentaje de participantes que marcaron correctamente la melodía original y p ( | ) - porcentaje de participantes que marcaron la versión modificada de la melodía como original.
Es curioso que algunos participantes, según los investigadores, consideraron que ciertas melodías modificadas son más originales que el original. El indicador promedio de ambos experimentos sugiere que el oyente promedio no notará la diferencia entre una melodía regular y aquella en la que se insertaron los datos.
Naturalmente, los conocedores de la música y los músicos podrán detectar algunas imprecisiones y elementos sospechosos en las melodías cambiadas, pero estos elementos no son tan importantes como para causar molestias.
Y ahora nosotros mismos podemos participar en el experimento. A continuación hay dos opciones para la misma melodía: original y modificada. ¿Escuchas la diferencia?
La versión original de la melodía.vs
Versión modificada de la melodía.Para una familiarización más detallada con los matices del estudio, le recomiendo que consulte el
informe del grupo de investigación.
También puede descargar el archivo ZIP de archivos de audio de las melodías originales y modificadas utilizadas en el estudio en
este enlace .
Epílogo
En este trabajo, los estudiantes graduados de la Escuela Técnica Superior Suiza de Zurich describieron un sorprendente sistema de transferencia de datos dentro de la música. Para hacer esto, utilizaron el enmascaramiento de frecuencia, que permitió incrustar datos en una melodía reproducida por el hablante. Esta melodía es percibida por el micrófono del dispositivo, que reconoce los datos ocultos y los decodifica, mientras que el oyente promedio ni siquiera nota la diferencia. En el futuro, los chicos planean desarrollar su sistema, eligiendo métodos más avanzados para incrustar datos en audio.
Cuando a alguien se le ocurre algo inusual y, lo más importante, trabajando, siempre estamos contentos. Pero aún más alegría es que este invento fue creado por jóvenes. La ciencia no tiene restricciones de edad. Y si los jóvenes consideran que la ciencia es aburrida, entonces se presenta en un ángulo incorrecto, por así decirlo. Después de todo, como sabemos, la ciencia es un mundo increíble que nunca deja de sorprender.
Viernes off-top:
Como estamos hablando de música, y más específicamente de música rock, aquí hay un maravilloso viaje a través de las extensiones de rock.
Reina, Radio Ga Ga (1984).
¡Gracias por su atención, sigan curiosos y tengan un gran fin de semana a todos, muchachos! :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
cómo construir infraestructura clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?