Ahora, el marco de Vision es capaz de reconocer texto real, y no como antes. Esperamos con ansias cuándo podemos aplicar esto a Dodo IS. Mientras tanto, una traducción de un artículo sobre el reconocimiento de cartas del juego de mesa Magic The Gathering y la extracción de información textual de ellas.
El marco Vision se presentó por primera vez al público en general en WWDC en 2017, junto con iOS 11.
Vision se creó para ayudar a los desarrolladores a clasificar e identificar objetos, planos horizontales, códigos de barras, expresiones faciales y texto.
Sin embargo, hubo un problema con el reconocimiento de texto: Vision pudo encontrar el lugar donde se encuentra el texto, pero el reconocimiento de texto real no ocurrió. Por supuesto, fue agradable ver el cuadro delimitador alrededor de fragmentos de texto individuales, pero luego tuvieron que extraerse y reconocerse de forma independiente.
Este problema se resolvió en la actualización de Vision, que se incluyó en iOS 13. Ahora, el marco de Vision proporciona reconocimiento de texto verdadero.
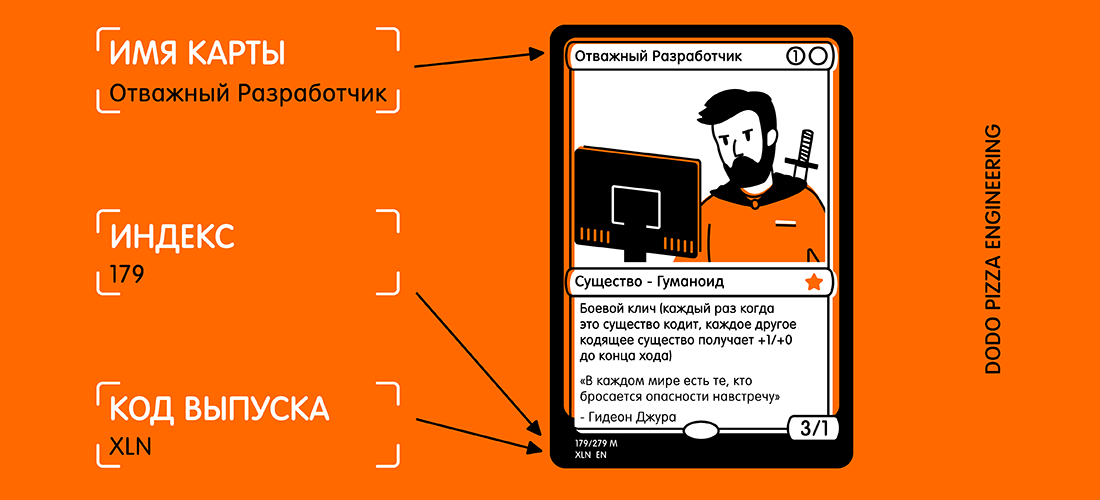
Para probar esto, creé una aplicación muy simple que puede reconocer una tarjeta del juego de mesa Magic The Gathering y extraer información de texto de ella:
- nombre de la tarjeta;
- código de lanzamiento;
- número de colección (también conocido como código postal).
Aquí hay un ejemplo de un mapa y texto seleccionado que me gustaría recibir.

Al mirar la tarjeta, podría pensar: "Este texto es bastante pequeño, además de que hay muchos otros textos en la tarjeta que pueden interferir". Pero para Vision, esto no es un problema.
Primero necesitamos crear un
VNRecognizeTextRequest . En esencia, esta es una descripción de lo que esperamos reconocer, más una configuración de idioma de reconocimiento y un nivel de precisión:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
El bloque de finalización tiene el formato
handleDetectedText(request: VNRequest?, error: Error?) . Lo pasamos al constructor
VNRecognizeTextRequest y luego establecemos las propiedades restantes.
Hay dos niveles de precisión de reconocimiento disponibles:
.fast y
.accurate . Como nuestra tarjeta tiene un texto bastante pequeño en la parte inferior, elegí una mayor precisión. La opción más rápida probablemente sea más adecuada para grandes volúmenes de texto.
Limité el reconocimiento al inglés británico, ya que todas mis tarjetas están en él. Puede especificar varios idiomas, pero debe comprender que el escaneo y el reconocimiento pueden tomar un poco más de tiempo para cada idioma adicional.
Hay dos propiedades más que vale la pena mencionar:
customWords : puede agregar una serie de cadenas para usar encima del léxico incorporado. Esto es útil si hay palabras inusuales en su texto. No utilicé la opción para este proyecto. Pero si tuviera que hacer la aplicación comercial de reconocimiento de tarjetas Magic The Gathering, agregaría algunas de las tarjetas más complejas (por ejemplo, Fblthp, the Lost ) para evitar problemas.minimumTextHeight : este es un valor flotante. Indica el tamaño relativo a la altura de la imagen a la que ya no se debe reconocer el texto. Si creé este escáner solo para obtener el nombre del mapa, sería útil eliminar el resto del texto que no es necesario. Pero necesito los fragmentos de texto más pequeños, así que por ahora he ignorado esta propiedad. Obviamente, si ignora los textos pequeños, la velocidad de reconocimiento será mayor.
Ahora que tenemos nuestra solicitud, debemos pasarla junto con la imagen al controlador de solicitudes:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
Utilizo la imagen directamente de la cámara, convirtiéndola de
UIImage a
CGImage . Esto se usa en
VNImageRequestHandler junto con el indicador de orientación para ayudar al controlador a comprender qué texto debe reconocer.
Como parte de esta demostración, uso el teléfono solo en orientación vertical. Entonces, naturalmente, agrego la orientación
.right . Entonces padaji!
Resulta que la orientación de la cámara en su dispositivo está completamente separada de la rotación del dispositivo y siempre se considera a la izquierda (como era predeterminado en 2009, que para tomar fotos necesita mantener el teléfono en orientación horizontal). Por supuesto, los tiempos han cambiado, y básicamente tomamos fotos y videos en formato vertical, pero la cámara todavía está alineada a la izquierda.
Tan pronto como se configura nuestro controlador, entramos en la secuencia con la prioridad
.userInitiated e intentamos cumplir con nuestras solicitudes. Puede notar que se trata de una serie de consultas. Esto sucede porque puede intentar extraer varios datos en una sola pasada (es decir, identificar caras y texto de la misma imagen). Si no hay errores, la devolución de llamada creada con nuestra solicitud se llamará después de que se detecte el texto:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
Nuestro controlador devuelve nuestra consulta, que ahora tiene la propiedad de resultados. Cada resultado es un
VNRecognizedTextObservation , que para nosotros tiene varias opciones para el resultado (en adelante, los candidatos).
Puede obtener hasta 10 candidatos para cada unidad de texto reconocido, y se ordenan en orden descendente de confianza. Esto puede ser útil si tiene cierta terminología que el analizador reconoce incorrectamente en el primer intento. Pero determina correctamente más tarde, incluso si tiene menos confianza en la exactitud del resultado.
En este ejemplo, solo necesitamos el primer resultado, por lo que recorrimos la
observation.topCandidates(1) y extraemos texto y confianza. Si bien el candidato mismo tiene un texto y una confianza diferentes,
.boundingBox sigue siendo el mismo.
.boundingBox usa un sistema de coordenadas normalizado con el origen en la esquina inferior izquierda, por lo que si se va a usar en UIKit en el futuro, para su comodidad, debe convertirse.
Eso es casi todo lo que necesitas. Si ejecuto una
foto de la tarjeta a través de esto, obtengo el siguiente resultado en menos de 0.5 segundos en el iPhone XS Max:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
¡Esto es increíble! Cada fragmento de texto fue reconocido, colocado en su propio cuadro delimitador y devuelto como resultado con una calificación de confianza de 1.0.
Incluso un derecho de autor muy pequeño es mayormente correcto. Todo esto se hizo en una imagen de 3024x4032 con un peso de 3.1 MB. El proceso sería aún más rápido si primero redujera la imagen. También vale la pena señalar que este proceso es mucho más rápido en los nuevos chips biónicos A12, que tienen un motor neuronal especial.
Cuando se reconoce el texto, lo último que se debe hacer es extraer la información que necesito. No pondré todo el código aquí, pero la lógica clave es
.boundingBox sobre cada
.boundingBox determinar la ubicación, de modo que pueda seleccionar el texto en la esquina inferior izquierda y en la esquina superior izquierda, ignorando cualquier cosa más a la derecha.
El resultado final es una aplicación de tarjeta de escaneo y me devuelve el resultado en menos de un segundo.
PD De hecho, solo necesito un código de lanzamiento y un número de colección (es un índice). Luego se pueden usar en la API del servicio Scryfall para obtener toda la información posible sobre este mapa, incluidas las reglas del juego y el costo.
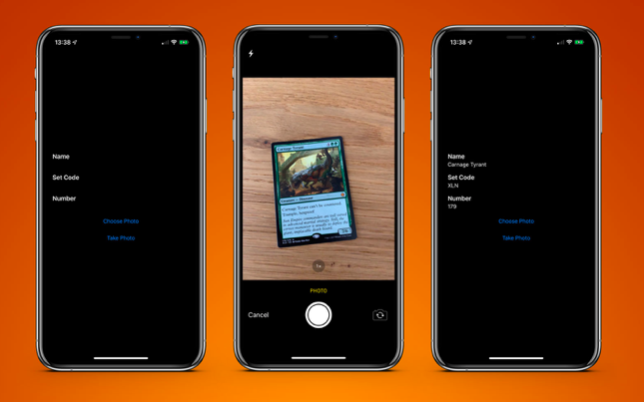
Una aplicación de muestra está disponible en
GitHub .