
En una determinada etapa de madurez de la seguridad de la información, muchas empresas comienzan a pensar en cómo obtener y usar información sobre las amenazas cibernéticas que les son relevantes. Dependiendo de los detalles específicos de la industria de la organización, los diferentes tipos de amenazas pueden causar interés. El enfoque para el uso de dicha información fue formado por Lockheed Martin en la
defensa material
impulsada por la inteligencia .
Afortunadamente, los servicios de seguridad de la información tienen muchas fuentes para obtenerlos, e incluso una clase separada de soluciones: Threat Intelligence Platform (TIP), que le permite administrar los procesos de recepción, generación e integración en herramientas de seguridad.
Como centro para monitorear y responder a incidentes de seguridad de la información, es extremadamente importante para nosotros que la información sobre las ciberamenazas que recibimos y generamos sea relevante, aplicable y, lo que es más importante, manejable. Después de todo, la seguridad de las organizaciones que nos han confiado la protección de su infraestructura depende de esto.
Decidimos compartir nuestra visión de TI en Jet CSIRT y hablar sobre tratar de adaptar varios enfoques potencialmente útiles para gestionar la inteligencia de amenazas cibernéticas.
En el campo de la ciberseguridad, poco funciona sobre el principio de set'n'forget. El cortafuegos no bloqueará los paquetes hasta que los filtros estén configurados, IPS no encuentre signos de actividad maliciosa en el tráfico, hasta que se descarguen las firmas y SIEM comience a escribir independientemente las reglas de correlación y determine los falsos positivos. La inteligencia de amenazas no es una excepción.
La complejidad de implementar una solución que realmente refleje el concepto de Inteligencia de amenazas reside en su propia definición.
Threat Intelligence es un proceso de investigación y análisis de
ciertas fuentes de información para obtener y acumular
información sobre las amenazas cibernéticas actuales con el fin de llevar a cabo medidas para mejorar la seguridad cibernética y aumentar la conciencia de seguridad de la información de una
determinada comunidad de seguridad de la información .
Ciertas fuentes pueden incluir:
- Fuentes abiertas de información. Todo lo que se puede encontrar usando Google, Yandex, Bing y herramientas más especializadas como Shodan, Censys, nmap. El proceso de análisis de estas fuentes se llama Inteligencia de código abierto (OSINT). Cabe señalar que la información obtenida a través de OSINT proviene de fuentes abiertas (sin clasificar). Si se paga la fuente, esto puede no hacerlo secreto, lo que significa que el análisis de dicha fuente también es OSINT.
- Los medios de comunicación. Todo lo que se puede encontrar en los medios y en las plataformas sociales Sosial Media Intelligence (SOCMINT). Este tipo de adquisición de datos es esencialmente una parte integral de OSINT.
- Sedes y foros cerrados que discuten los detalles de los próximos delitos cibernéticos (deepweb, darknet). Principalmente en las áreas sombreadas puede obtener información sobre los ataques DDoS o sobre la creación de un nuevo malware que los piratas informáticos están tratando de vender allí.
- Personas con acceso a la información. Los "colegas" y las personas que sucumben a los métodos de ingeniería social también son fuentes que pueden compartir información.
Hay métodos más serios disponibles solo para servicios especializados. En este caso, los datos pueden provenir de agentes que trabajan encubiertos en un entorno de cibercrimen o de personas involucradas en el cibercrimen y que colaboran con la investigación. En una palabra, todo esto se llama Inteligencia HUMANA (HUMINT). Por supuesto, no practicamos HUMINT en Jet CSIRT.
Poner todos estos procesos en una "caja" que funcionará de forma autónoma es imposible. Por lo tanto, cuando se trata de la solución de TI, lo más probable es que su principal propuesta de valor para el consumidor sea la
información sobre las amenazas cibernéticas y cómo gestionarlas, el acceso al cual de una forma u otra obtiene la
comunidad del IB .
Información sobre amenazas cibernéticas
En 2015, MWR Infosecurity, junto con CERT y el Centro Nacional de Protección de Infraestructura de Gran Bretaña, publicó un
folleto informativo que destacaba 4 categorías de información resultantes del proceso de TI. Esta clasificación ahora se aplica universalmente:
- Operativo Información sobre ciberataques futuros y en curso, obtenidos, por regla general, por servicios especiales como resultado del proceso HUMINT o mediante escuchas telefónicas de los canales de comunicación de los atacantes.
- Estratégico Información relacionada con la evaluación de riesgos para que una organización sea víctima de un ciberataque. No contienen ninguna información técnica y de ninguna manera se pueden utilizar en equipos de protección.
- Táctico Información sobre las técnicas, tácticas, procedimientos (TTP) y herramientas que los ciberdelincuentes usan como parte de una campaña maliciosa.
Case in Point - LockerGoga recientemente abierto- Herramienta : cmd.exe.
- Técnica : se lanza un bloqueador de cifrado, que cifra todos los archivos en la computadora de la víctima (incluidos los archivos del kernel de Windows) utilizando el algoritmo AES en modo de cifrado de bloque (CTR) con una longitud de clave de 128 bits. La clave de archivo y el vector de inicialización (IV) se encriptan usando el algoritmo RSA-1024 usando la función de generación de máscara MGF1 (SHA-1). A su vez, para aumentar la fuerza criptográfica de esta función, se utiliza el esquema de llenado OAEP. Las claves cifradas del archivo y IV se almacenan en el encabezado del archivo cifrado.
- Procedimiento : Además, el malware inicia varios procesos secundarios paralelos, cifrando solo cada 80,000 bytes de cada archivo, omitiendo los siguientes 80,000 bytes para acelerar el cifrado.
- Tácticas : luego se requiere un rescate en bitcoins para que la clave descifre los archivos.
Lee más
aquí .
Dicha información aparece como resultado de una investigación exhaustiva de una campaña maliciosa, que puede llevar bastante tiempo. Los resultados de estos estudios son boletines e informes de empresas comerciales como Cisco Talos, FireEye, Symantec, Group-IB, Kaspersky GREAT, organizaciones gubernamentales y reguladores (FinCERT, NCCCI, US-CERT, FS-ISAC), así como investigadores independientes.
La información táctica puede y debe usarse en equipos de seguridad y al construir una arquitectura de red.
- Técnica Información sobre los signos y esencias de la actividad maliciosa o sobre cómo identificarlos.
Por ejemplo, al analizar malware, se descubrió que se propaga como un archivo .pdf con los siguientes parámetros:
- llamado price_december.pdf ,
- iniciando el proceso pureevil.exe ,
- con un hash MD5 de 81a284a2b84dde3230ff339415b0112a ,
- que intenta establecer conexiones con el servidor C&C en 123.45.67.89 en el puerto TCP 1337 .
En este ejemplo, las entidades son los nombres de archivo y proceso, el valor hash, la dirección del servidor y el número de puerto. Los signos son la interacción de estas entidades entre ellos y los componentes de la infraestructura: inicio del proceso, interacción de red saliente con el servidor, cambio de claves de registro, etc.
Esta información está estrechamente relacionada con el concepto de Indicador de compromiso (IoC). Técnicamente, mientras la entidad no se encuentre en la infraestructura, todavía no dice nada. Pero si, por ejemplo, encuentra en la red el hecho de intentos de conectar el host al servidor C&C en
123.45.67.89:1337 o el inicio del proceso
pureevil.exe , e incluso con la suma MD5
81a284a2b84dde3230ff339415b0112a , entonces esto ya es un indicador de compromiso.
Es decir, el indicador de compromiso es una combinación de ciertas entidades, signos de actividad maliciosa e información contextual que requiere la respuesta de los servicios de seguridad de la información.
Al mismo tiempo, en el ámbito de la seguridad de la información, es habitual llamar a los indicadores de compromiso solo entidades que fueron notadas por alguien en actividad maliciosa (direcciones IP, nombres de dominio, sumas hash, URL, nombres de archivos, claves de registro, etc.).
La detección de un indicador de compromiso solo indica que se debe prestar atención a este hecho y analizarlo para determinar acciones adicionales. No se recomienda categóricamente bloquear inmediatamente el indicador en el SZI sin aclarar todas las circunstancias. Pero hablaremos más sobre esto.
Los indicadores de compromiso también se dividen convenientemente en:
- Atómico Contienen solo una característica que no se puede dividir más, por ejemplo:
- Dirección IP del servidor C y C - 123.45.67.89
- La cantidad de hash es 81a284a2b84dde3230ff339415b0112a
- Compuesto Contienen dos o más entidades vistas en actividades maliciosas, por ejemplo:
- Zócalo - 123.45.67.89:5900
- El archivo price_december.pdf generará el proceso pureevil.exe con un hash de 81a284a2b84dde3230ff339415b0112a
Obviamente, la detección de un indicador compuesto probablemente indicará un compromiso del sistema.
La información técnica también puede incluir varias entidades para detectar y bloquear indicadores de compromiso, por ejemplo, reglas de Yara, reglas de correlación para SIEM, varias firmas para detectar ataques y malware. Por lo tanto, la información técnica puede aplicarse claramente a los equipos de protección.
Problemas de uso eficiente de la información técnica de TI
Más rápidamente, los proveedores de servicios de TI pueden obtener exactamente la información técnica sobre las amenazas cibernéticas, y la forma de aplicarlas es totalmente una pregunta para el consumidor. Aquí es donde se encuentran la mayoría de los problemas.
Por ejemplo, los indicadores de compromiso se pueden aplicar en varias etapas de respuesta a un incidente de IS:
- en la etapa de preparación (Preparación), bloqueando proactivamente el indicador en el SIS (por supuesto, después de la excepción de falso positivo);
- en la etapa de detección, rastrear el funcionamiento de las reglas para identificar el indicador en tiempo real mediante herramientas de monitoreo (SIEM, SIM, LM);
- en la etapa de investigación del incidente, utilizando el indicador en verificaciones retrospectivas;
- en la etapa de un análisis más profundo de los activos afectados, por ejemplo, al analizar el código fuente de una muestra maliciosa.
Mientras más trabajo manual esté involucrado en una etapa u otra, se necesitarán más análisis (enriqueciendo la esencia del indicador con información contextual) de los proveedores de indicadores de compromiso. En este caso, estamos hablando de información contextual externa, es decir, de lo que otros ya saben sobre este indicador.
Por lo general, los indicadores de compromiso se entregan en forma de los llamados
feeds de amenazas o
feeds . Esta es una lista estructurada de datos de amenazas en varios formatos.
Por ejemplo, el siguiente es un feed hash malicioso en formato json:

Este es un ejemplo de un buen feed rico en contexto:
- contiene un enlace al análisis de amenazas;
- nombre, tipo y categoría de amenaza;
- marca de tiempo de publicación.
Todo esto le permite administrar los indicadores de compromiso de este feed cuando se carga en herramientas de protección y monitoreo de la información, y también reduce el tiempo para analizar los incidentes que han funcionado en ellos.
Pero hay otros feeds de calidad (generalmente de código abierto). Por ejemplo, el siguiente es un ejemplo de las direcciones de servidores supuestamente C&C de una fuente abierta:

Como puede ver, la información contextual está completamente ausente aquí. Cualquiera de estas direcciones IP puede alojar un servicio legítimo, algunos de los cuales pueden ser rastreadores Yandex o Google que indexan sitios. No podemos decir nada sobre esta lista.
La ausencia o insuficiencia de contexto en las fuentes de amenazas es uno de los principales problemas para los consumidores de información técnica. Sin contexto, la entidad del feed no es aplicable y, de hecho, no es un indicador de compromiso. En otras palabras, el bloqueo de cualquier dirección IP en SZI, así como la carga de esta fuente en las herramientas de monitoreo, puede generar una gran cantidad de falsos positivos (falso positivo - FP).
Si consideramos el uso de indicadores de compromiso desde el punto de vista de la detección en las herramientas de monitoreo, entonces este proceso simplificado es una secuencia:
- integración de indicadores en herramientas de monitoreo;
- desencadenar la regla de detección del indicador;
- Servicio de análisis de respuesta IS.
Debido a la presencia de un recurso humano en esta secuencia, estamos interesados en analizar solo aquellos casos de identificación de indicadores que realmente indican una amenaza para la organización y reducen el número de PF.
Básicamente, los falsos positivos se desencadenan al detectar la esencia de los recursos populares (Google, Microsoft, Yandex, Adobe, etc.) como potencialmente maliciosos.
Un ejemplo simple: examina el malware que ha llegado al host. Se descubre que comprueba el acceso a Internet mediante el sondeo
update.googleapis.com . El activo
update.googleapis.com aparece en el feed de amenazas como un indicador de compromiso y llama a FP. De manera similar, la suma hash de una biblioteca o archivo legítimo utilizado por malware, direcciones DNS públicas, direcciones de varios rastreadores y arañas, recursos para verificar CRL (Lista de revocación de certificados) y abreviaturas de URL (bit.ly, goo) pueden ingresar al feed. gl, etc.).
Probar este tipo de respuesta, no enriquecido en un contexto externo, puede llevar una cantidad de tiempo bastante grande para el analista, durante el cual puede perderse un incidente real.
Por cierto, hay feeds de indicadores que pueden desencadenar FP. Un ejemplo de ello es el
recurso misp-warninglist .
Priorización de indicadores de compromiso
Otro problema es la priorización de las respuestas. En términos relativos, qué tipo de SLA tendremos al detectar un indicador particular de compromiso. De hecho, los proveedores de feeds de amenazas no priorizan las entidades que contienen. Para ayudar a los consumidores, pueden agregar un grado de confianza en la nocividad de una entidad, como se hace en los feeds de Kaspersky Lab:

Sin embargo, priorizar los eventos de identificación de indicadores es tarea del consumidor.
Para abordar este problema en Jet CSIRT, adaptamos el
enfoque descrito por Ryan Kazanciyan en COUNTERMEASURE 2016. Su esencia es que todos los indicadores de compromiso que se pueden encontrar en la infraestructura se consideran desde el punto de vista de pertenencia a
dominios de sistema y
dominios de datos. .
Los dominios de datos están en 3 categorías:
- Actividad en tiempo real en la fuente (lo que almacena actualmente en la memoria; detectado mediante el análisis de eventos de seguridad de la información en tiempo real):
- iniciar procesos, cambiar claves de registro, crear archivos;
- actividad de red, conexiones activas;
- Otros eventos recién generados.
Si se detecta un indicador de esta categoría, el tiempo de respuesta de los servicios IS es mínimo .
- Actividad histórica (lo que ya sucedió; revelado durante los controles retrospectivos):
- registros históricos;
- telemetría
- alertas activadas
Si se detecta un indicador de esta categoría, el tiempo de reacción de los servicios de SI está limitado de manera permisible .
- Datos en reposo (lo que ya era antes de conectar la fuente a la supervisión; se revela como parte de las comprobaciones retrospectivas de fuentes no utilizadas durante mucho tiempo):
- archivos que han sido almacenados durante mucho tiempo en la fuente;
- claves de registro;
- Otros objetos no utilizados.
Si se detecta un indicador de esta categoría, el tiempo de reacción de los servicios de SI está limitado por la duración de la investigación completa del incidente .
Por lo general, los informes detallados y los boletines se compilan sobre la base de tales investigaciones con un desglose de las acciones de los atacantes, pero la relevancia de dichos datos es relativamente pequeña.
Es decir
, los dominios de datos son el estado de los datos analizados en los que se detectó un indicador de compromiso.
Los dominios del sistema son la afiliación de la fuente del indicador de compromiso a uno de los subsistemas de infraestructura:
- Estaciones de trabajo Fuentes utilizadas directamente por el usuario para realizar el trabajo diario: estaciones de trabajo, computadoras portátiles, tabletas, teléfonos inteligentes, terminales (VoIP, VKS, IM), programas de aplicación (CRM, ERP, etc.).
- Servidores Esto se refiere a otros dispositivos que sirven a la infraestructura, es decir dispositivos para la operación del complejo de TI: SZI (FW, IDS / IPS, AV, EDR, DLP), dispositivos de red, servidores de archivos / web / proxy, sistemas de almacenamiento, ACS, control ambiental. medio ambiente etc.

Combinando esta información con la composición de los signos de un indicador de compromiso
(átomo, compuesto) , dependiendo del tiempo de reacción aceptable, puede formular la prioridad del incidente cuando se detecta:
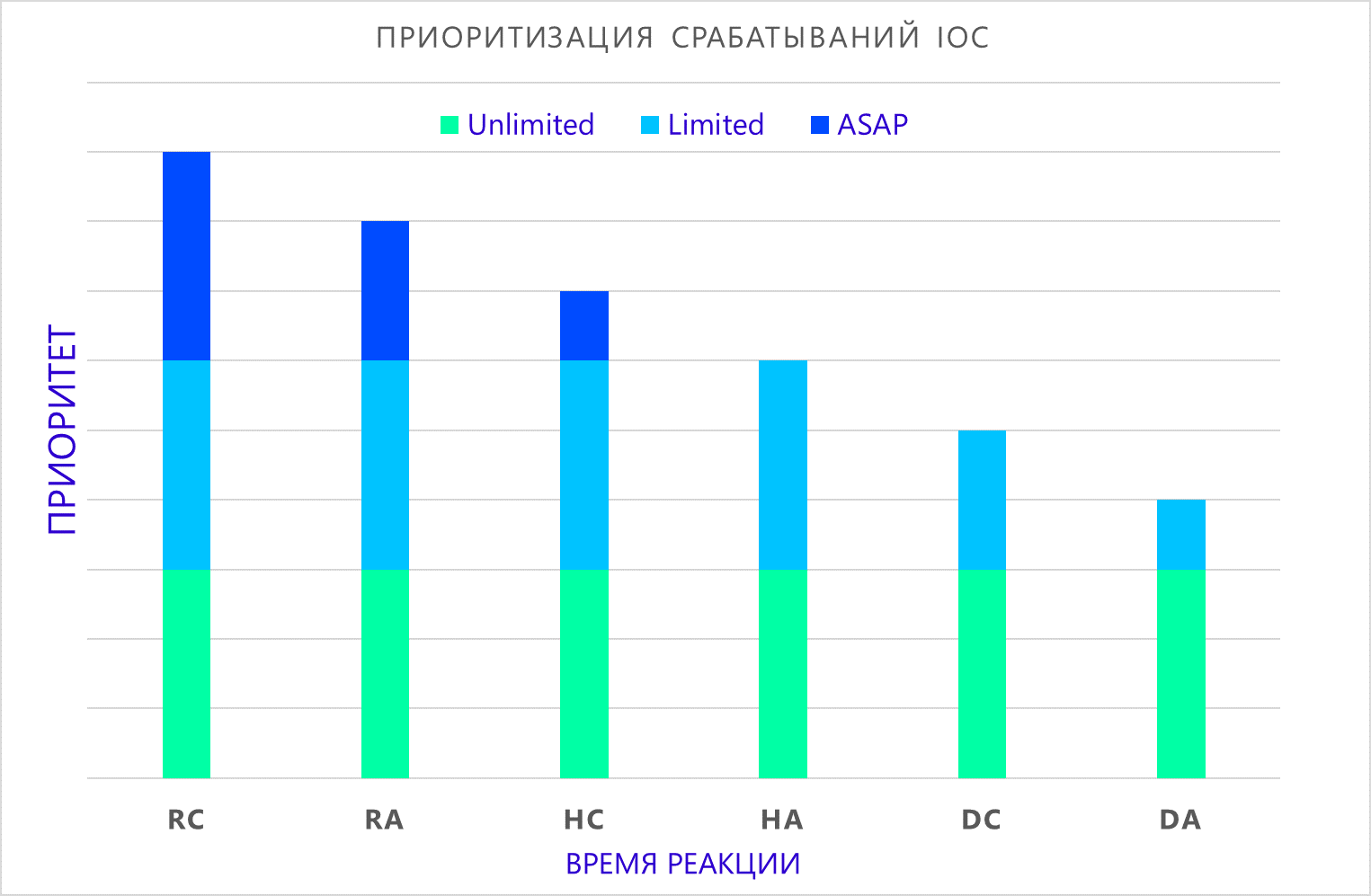
- Lo antes posible La detección de un indicador requiere una respuesta inmediata del equipo de respuesta.
- Limitada La detección del indicador requiere un análisis adicional para aclarar las circunstancias del incidente y decidir sobre acciones adicionales.
- Ilimitado La detección del indicador requiere una investigación exhaustiva y la preparación de un informe sobre las actividades de los atacantes. Por lo general, estos hallazgos se investigan en el marco de la investigación forense, que puede durar años.
Donde:
- RC - detección de indicador compuesto en tiempo real;
- RA: detección de un indicador atómico en tiempo real;
- HC - detección de un indicador compuesto como parte de una verificación retrospectiva;
- HA - detección de un indicador atómico como parte de una verificación retrospectiva;
- DC - detección de un indicador compuesto en fuentes largas no utilizadas;
- DA: detección de un indicador atómico en fuentes no utilizadas durante mucho tiempo.
Debo decir que la prioridad no resta importancia a la detección de un indicador, sino que muestra el tiempo aproximado que tenemos para evitar un posible compromiso de la infraestructura.
También es justo señalar que este enfoque no se puede utilizar de forma aislada de la infraestructura observada, volveremos a esto.
Monitorear la vida de los indicadores de compromiso
Hay algunas entidades maliciosas que dejan el indicador de compromiso para siempre. No se recomienda eliminar dicha información, incluso después de un largo período de tiempo. Esto a menudo se vuelve relevante en auditorías retrospectivas
(NA / HA) y cuando se verifican fuentes no utilizadas durante mucho tiempo
(DC / DA) .
Algunos centros de monitoreo y proveedores de indicadores de compromiso consideran innecesario controlar el tiempo de vida de todos los indicadores en general. Sin embargo, en la práctica este enfoque se vuelve ineficaz. De hecho, indicadores de compromiso como, por ejemplo, hash de archivos maliciosos, claves de registro generadas por malware y URL a través de los cuales se infecta un nodo, nunca se convertirán en entidades legítimas, es decir. Su validez no es limitada.Caso en cuestión: análisis SHA-256 de la suma de un archivo RAT Vermin con un protocolo SOAP encapsulado para intercambiar datos con un servidor C&C. El análisis muestra que el archivo fue creado en 2015. Recientemente, lo encontramos en uno de los servidores de archivos de nuestros clientes.
De hecho, indicadores de compromiso como, por ejemplo, hash de archivos maliciosos, claves de registro generadas por malware y URL a través de los cuales se infecta un nodo, nunca se convertirán en entidades legítimas, es decir. Su validez no es limitada.Caso en cuestión: análisis SHA-256 de la suma de un archivo RAT Vermin con un protocolo SOAP encapsulado para intercambiar datos con un servidor C&C. El análisis muestra que el archivo fue creado en 2015. Recientemente, lo encontramos en uno de los servidores de archivos de nuestros clientes.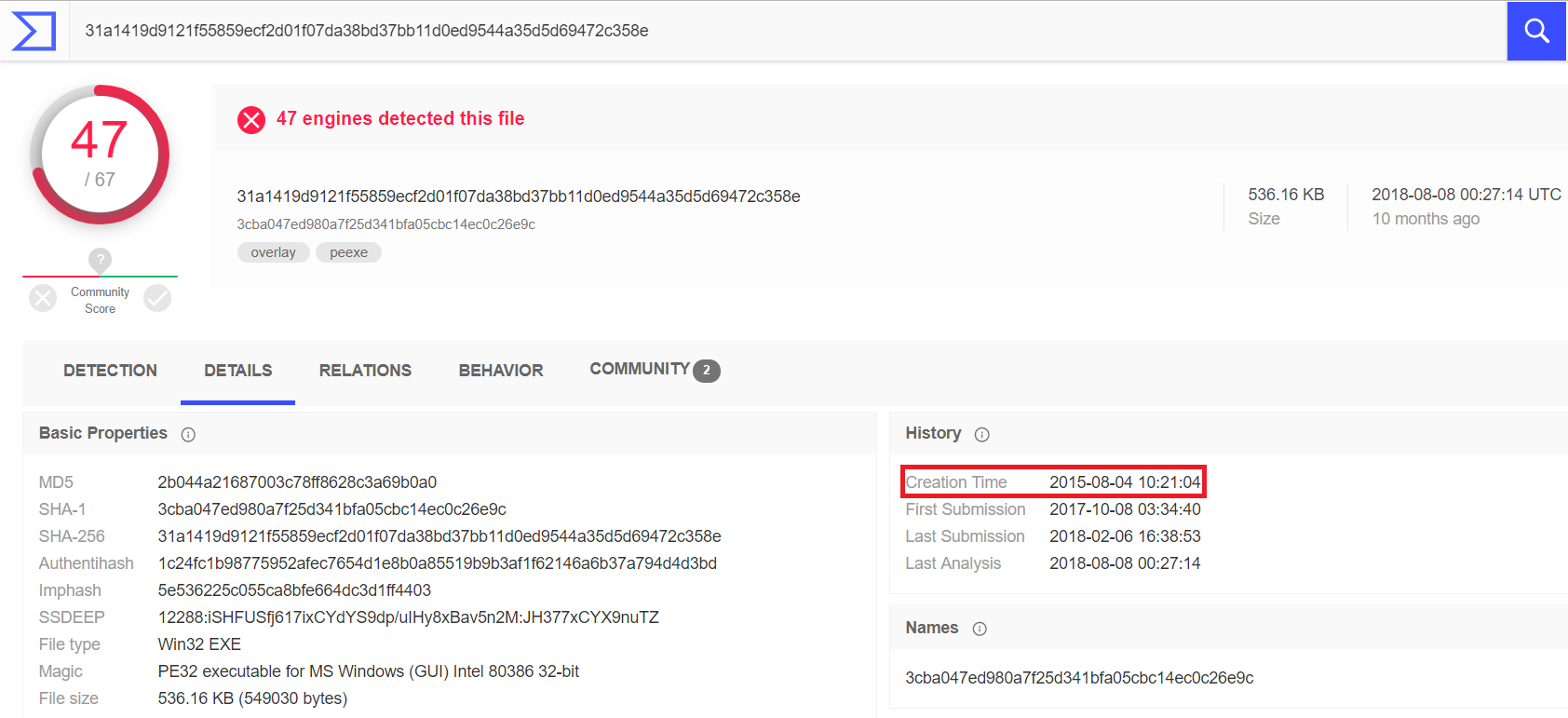 Sin embargo, una imagen completamente diferente será con el tipo de entidades que fueron creadas o "prestadas" por un tiempo para una campaña maliciosa. Es decir, de hecho, son puntos finales bajo el control de intrusos.Dichas entidades pueden volver a ser legítimas después de que sus propietarios eliminen los nodos comprometidos o cuando los atacantes dejen de usar la siguiente infraestructura.Teniendo en cuenta estos factores, es posible construir una tabla aproximada de indicadores de compromiso con referencia a los dominios de datos, el período de su relevancia y la necesidad de controlar su ciclo de vida:
Sin embargo, una imagen completamente diferente será con el tipo de entidades que fueron creadas o "prestadas" por un tiempo para una campaña maliciosa. Es decir, de hecho, son puntos finales bajo el control de intrusos.Dichas entidades pueden volver a ser legítimas después de que sus propietarios eliminen los nodos comprometidos o cuando los atacantes dejen de usar la siguiente infraestructura.Teniendo en cuenta estos factores, es posible construir una tabla aproximada de indicadores de compromiso con referencia a los dominios de datos, el período de su relevancia y la necesidad de controlar su ciclo de vida: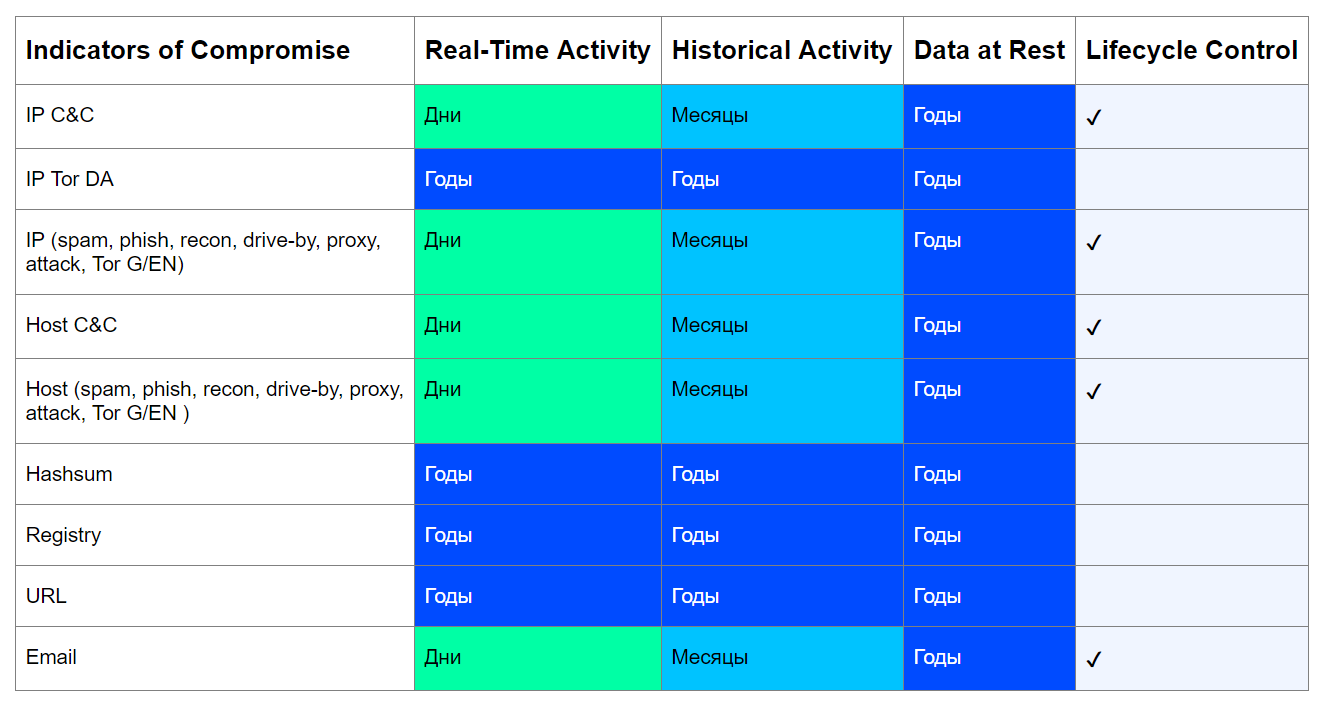 el objetivo de esta tabla es responder tres preguntas:
el objetivo de esta tabla es responder tres preguntas:- ¿Puede este indicador volverse legítimo con el tiempo?
- ¿Cuál es el período mínimo de relevancia de un indicador dependiendo del estado de los datos analizados?
- ¿Necesito controlar la vida de este indicador?
Considere este enfoque utilizando el ejemplo de un servidor IP C&C. Hoy en día, los atacantes prefieren crear una infraestructura distribuida, a menudo cambiando direcciones para pasar desapercibidos y evitar posibles bloqueos del proveedor. Al mismo tiempo, C&C a menudo se implementa en nodos pirateados, como, por ejemplo, en el caso de Emotet . Sin embargo, las botnets se están eliminando, los villanos están siendo atrapados, por lo tanto, un indicador como la dirección IP del servidor C&C puede convertirse en una entidad legítima, lo que significa que su vida útil puede controlarse.Si encontramos llamadas al servidor IP C & C en tiempo real (RA / RC), el período de su relevancia para nosotros se calculará en días. Después de todo, es poco probable que el día después del descubrimiento esta dirección ya no aloje C&C.La detección de dicho indicador en controles retrospectivos (HA / HC), que generalmente tienen intervalos más largos (una vez cada pocas semanas / meses), también indicará un período mínimo de relevancia igual al intervalo correspondiente. Al mismo tiempo, es posible que C&C ya no esté activo, pero si encontramos un hecho de circulación en nuestra infraestructura, entonces el indicador será relevante para nosotros.La misma lógica se aplica a otros tipos de indicadores. Las excepciones son cantidades hash, claves de registro, nodos de red Tor de la Autoridad de directorio (DA) y URL.Con valores hash y de registro, todo es simple: no se pueden eliminar de la naturaleza, por lo que no tiene sentido controlar su vida útil. Pero las URL maliciosas se pueden eliminar, por supuesto, no serán legítimas, pero estarán inactivas. Sin embargo, también son únicos y se crean específicamente para una campaña maliciosa, por lo que no pueden convertirse en legítimos.Las direcciones IP de los nodos DA de la red Tor son bien conocidas y no cambian, su vida útil está limitada solo por la vida útil de la red Tor, por lo tanto, tales indicadores son siempre relevantes.Como puede ver, para la mayoría de los tipos de indicadores de la tabla, es necesario controlar su vida útil.En Jet CSIRT abogamos por este enfoque por las siguientes razones.- , - , - , , , .
, Microsoft 99 , APT35. - Microsoft .
IP- , -. , IP- «», , . - , .
, , , . - .
, . 1 MS Office, -, . , , , .
Es por eso que consideramos importante ahora esforzarnos por adaptar los procesos y desarrollar enfoques para controlar la vida útil de los indicadores que están integrados en los medios de protección.Uno de estos enfoques se describe en los Indicadores de Compromiso en descomposición del Centro de Respuesta a Emergencias Informáticas de Luxemburgo (CIRCL), cuyo personal creó una plataforma para intercambiar información sobre las amenazas de PSIM . Es en MISP que se planea aplicar ideas de este material. Para hacer esto, básicamente los repositorios del proyecto ya han abierto la rama apropiada , lo que una vez más demuestra la relevancia de este problema para la comunidad de seguridad de la información.Este enfoque supone que la vida útil de algunos indicadores no es homogénea y puede cambiar a medida que:- los atacantes dejan de usar su infraestructura en ciberataques;
- él aprende sobre el ataque cibernético cada vez más especialistas en seguridad de la información y pone indicadores en el bloque en SZI, obligando a los atacantes a cambiar los elementos utilizados.
Por lo tanto, la vida útil de dichos indicadores puede describirse en forma de una determinada función que caracteriza la tasa de salida de la fecha de vencimiento de cada indicador a lo largo del tiempo.Los colegas de CIRCL construyen su modelo usando las condiciones usadas en MISP, sin embargo, la idea general del modelo puede usarse fuera de su producto:- Al indicador de compromiso (a) se le asigna una determinada evaluación básica (
En el material de CIRCL, se tiene en cuenta la fiabilidad / confianza en el proveedor del indicador y las taxonomías relacionadas. Al mismo tiempo, tras la detección repetida del indicador, la evaluación básica puede cambiar, aumentar o disminuir, según los algoritmos del proveedor.- Hora ingresada
- Se introduce el concepto de la tasa de salida de la tasa de vencimiento del indicador (tasa de decaimiento).
- Marcas de tiempo ingresadas
Dadas todas las condiciones anteriores, los colegas de CIRCL dan la siguiente fórmula para calcular el puntaje general (1):
DondeParámetropropone ser considerado como ,donde,- tiempo de la primera detección del indicador;- tiempo de la última detección del indicador;.
El material CIRCL da un ejemplo del llamado tiempo de gracia, un tiempo fijo para la corrección, que el proveedor le da al propietario del recurso, notado en actividades sospechosas, antes de desconectar el recurso. Pero para la mayoría de los tipos de indicadoresPor lo tanto, tratamos de vincular cada tipo de indicador, para el cual es posible el monitoreo del ciclo de vida, con su tasa de vencimiento (tasa de descomposición), el tipo de infraestructura observada y su nivel de madurez de seguridad de la información.Al hacer un inventario de la infraestructura protegida específica, descubrir la antigüedad del software y el equipo que utiliza, determinamos la tasa de caída para cada tipo de indicador de compromiso. Se puede presentar un resultado aproximado de dicho trabajo en forma de tabla: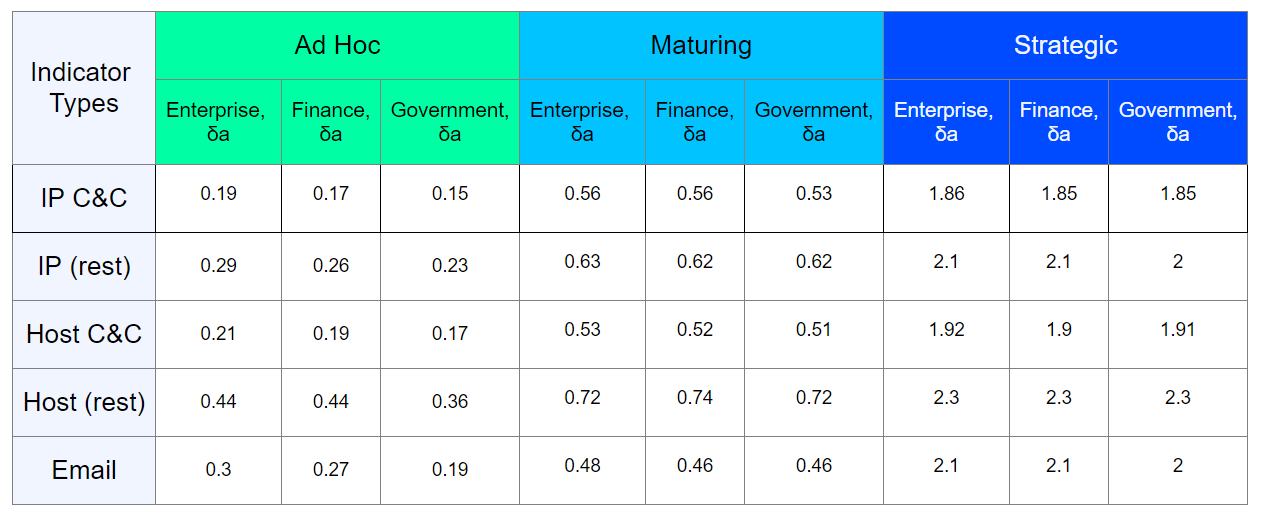 una vez más, enfatizo que el resultado en la tabla es aproximado, en realidad, la evaluación debe realizarse individualmente para una infraestructura específica.Con el advenimiento de las fechas de vencimiento de cada indicador, podemos determinar el tiempo aproximado en que se pueden cancelar. También vale la pena señalar que el cálculo del tiempo de amortización debe llevarse a cabo solo cuando hay una tendencia a disminuir en la puntuación del indicador base.Por ejemplo, considere un indicador con una calificación base de 80, tiempo
una vez más, enfatizo que el resultado en la tabla es aproximado, en realidad, la evaluación debe realizarse individualmente para una infraestructura específica.Con el advenimiento de las fechas de vencimiento de cada indicador, podemos determinar el tiempo aproximado en que se pueden cancelar. También vale la pena señalar que el cálculo del tiempo de amortización debe llevarse a cabo solo cuando hay una tendencia a disminuir en la puntuación del indicador base.Por ejemplo, considere un indicador con una calificación base de 80, tiempo )
 Como se puede ver en los gráficos, al determinar el límite de criticidad aproximado de la evaluación (en nuestro caso - 20, con una evaluación inicial de 80), podemos establecer el tiempo para verificar la relevancia de este indicador. Cuanto más decay_rate, más rápido llega esta vez. Por ejemplo, con decay_rate = 3 y un límite de evaluación = 20, se podría verificar este indicador durante aproximadamente 50 días de su funcionamiento en el SZI.El enfoque descrito es bastante difícil de implementar, pero su encanto es que podemos realizar pruebas sin afectar los procesos establecidos de seguridad de la información y la infraestructura de los clientes. Ahora estamos ejecutando el algoritmo para monitorear la vida útil de una determinada muestra de indicadores, que hipotéticamente pueden caer en desmantelamiento. Sin embargo, de hecho, estos indicadores permanecen en funcionamiento en el SZI. Relativamente hablando, tomamos una muestra de indicadores, los consideramos
Como se puede ver en los gráficos, al determinar el límite de criticidad aproximado de la evaluación (en nuestro caso - 20, con una evaluación inicial de 80), podemos establecer el tiempo para verificar la relevancia de este indicador. Cuanto más decay_rate, más rápido llega esta vez. Por ejemplo, con decay_rate = 3 y un límite de evaluación = 20, se podría verificar este indicador durante aproximadamente 50 días de su funcionamiento en el SZI.El enfoque descrito es bastante difícil de implementar, pero su encanto es que podemos realizar pruebas sin afectar los procesos establecidos de seguridad de la información y la infraestructura de los clientes. Ahora estamos ejecutando el algoritmo para monitorear la vida útil de una determinada muestra de indicadores, que hipotéticamente pueden caer en desmantelamiento. Sin embargo, de hecho, estos indicadores permanecen en funcionamiento en el SZI. Relativamente hablando, tomamos una muestra de indicadores, los consideramosConclusión
Treat Intelligence es, por supuesto, un concepto de seguridad de la información necesario y útil que puede mejorar significativamente la seguridad de la infraestructura de la empresa. Para lograr un uso efectivo de TI, debe comprender cómo podemos utilizar la información variada obtenida a través de este proceso.Hablando de la información técnica de la Inteligencia de amenazas, como las fuentes de amenazas e indicadores de compromiso, debemos recordar que el método de su uso no debe basarse en listas negras ciegas. En apariencia, el algoritmo simple para detectar y posteriormente bloquear la amenaza en realidad tiene muchas "trampas", por lo tanto, para el uso efectivo de la información técnica, es necesario evaluar correctamente su calidad, determinar la prioridad de las detecciones y también controlar su tiempo de vida para reducir la carga en el SPI.Sin embargo, confíe únicamente en el conocimiento técnico de Threat Intelligence. Es mucho más importante adaptar la información táctica a los procesos de defensa. Después de todo, es mucho más difícil para los atacantes cambiar tácticas, técnicas y herramientas, en lugar de hacernos perseguir otra parte de los indicadores de compromiso, que se descubrió después de un ataque de piratas informáticos. Pero hablaremos de esto en nuestros próximos artículos.Autor: Alexander Akhremchik, experto en el Centro de Monitoreo y Respuesta de Jet Infosystems Jet Infrastructure Jet, Jet CSIRT