En este artículo, veremos cómo construir un programa Go, como un compilador o un analizador estático, que interactúa con el marco de compilación LLVM utilizando el lenguaje ensamblador IR LLVM.
TL; DR escribimos una biblioteca para interactuar con LLVM IR en Go puro, ver enlaces a código y un proyecto de ejemplo.
Un ejemplo simple en LLVM IR
(Aquellos de ustedes que estén familiarizados con LLVM IR pueden pasar a la siguiente sección).
LLVM IR es la representación intermedia de bajo nivel utilizada por el marco de compilación LLVM. Puede pensar en LLVM IR como un ensamblador independiente de la plataforma con un número infinito de registros locales.
Al diseñar un compilador, existe una gran ventaja al compilar un lenguaje fuente en una representación intermedia (IR, representación intermedia) en lugar de compilarlo en una arquitectura de destino (por ejemplo, x86).
SpoilerLa idea de usar un lenguaje intermedio en compiladores está muy extendida. GCC usa GIMPLE, Roslyn usa CIL, LLVM usa LLVM IR.
Dado que muchas técnicas de optimización son comunes (por ejemplo, eliminar código no utilizado, distribuir constantes), estos pases de optimización se pueden realizar directamente en el nivel IR y se pueden usar en todas las plataformas de destino.
SpoilerEl uso de un lenguaje intermedio (IR) reduce así el número de combinaciones requeridas para n idiomas de origen ym arquitecturas de destino (backends) de n * ma n + m.
Por lo tanto, los compiladores a menudo constan de tres partes: frontend, middleland y backend, cada uno de ellos realiza su propia tarea, aceptando entradas y / o dando salida IR.
- Frontend: compila el lenguaje fuente en IR
- Middleland: optimiza IR
- Backend: compila IR en código máquina
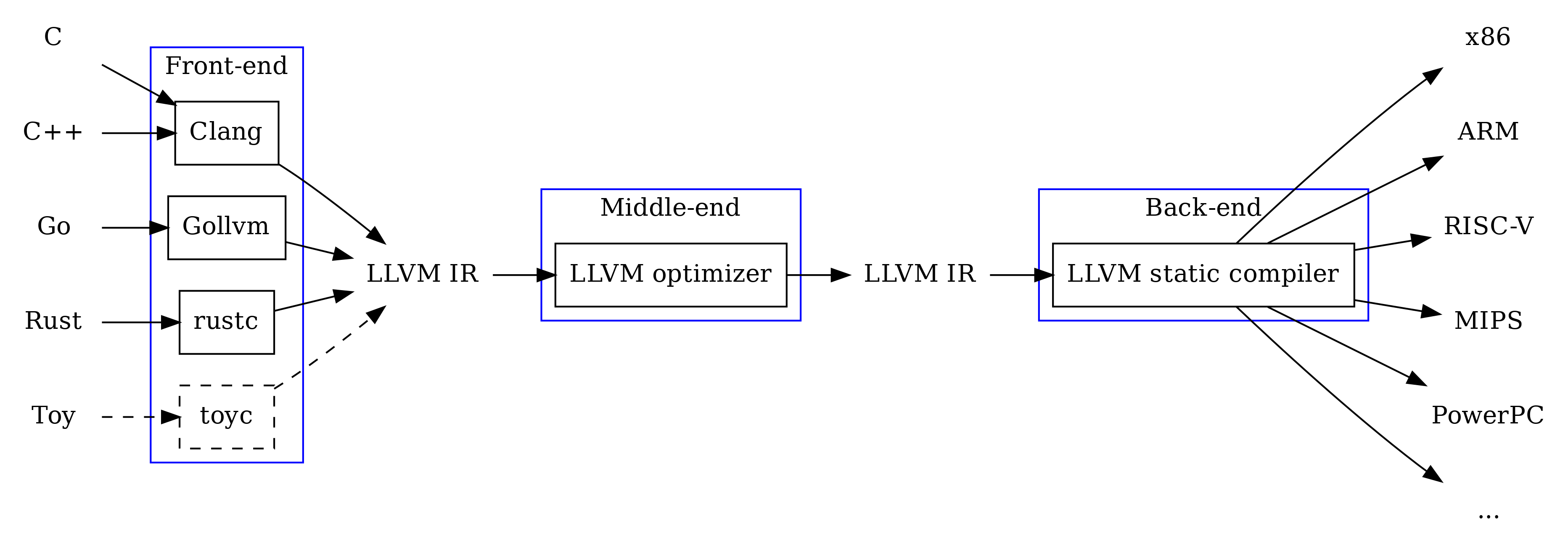
Programa de ejemplo de ensamblador IR LLVM
Para tener una idea de cómo se ve el ensamblador IR LLVM, considere el siguiente programa.
int f(int a, int b) { return a + 2*b; } int main() { return f(10, 20); }
Usamos Clang y compilamos el código C anterior en el ensamblador IR LLVM.
Clangclang -S -emit-llvm -o foo.ll foo.c.
define i32 @f(i32 %a, i32 %b) { ; <label>:0 %1 = mul i32 2, %b %2 = add i32 %a, %1 ret i32 %2 } define i32 @main() { ; <label>:0 %1 = call i32 @f(i32 10, i32 20) ret i32 %1 }
Mirando el código del ensamblador de LLVM IR arriba, podemos notar algunas características notables de LLVM IR, a saber:
LLVM IR está estáticamente tipado (es decir, los enteros de 32 bits están intersectados por el tipo i32).
Las variables locales tienen alcance dentro de la función (es decir,% 1 en
main es diferente de% 1 en @f).
Los nombres sin nombre (registros temporales) reciben identificadores locales (por ejemplo,% 1,% 2), en orden ascendente, en cada una de las funciones. Cada función puede usar un número infinito de registros (no limitado a 32 registros de propósito general). Los identificadores globales (por ejemplo, @f) y los identificadores locales (por ejemplo,% a,% 1) se distinguen por un prefijo (@ y%, respectivamente).
La mayoría de los comandos hacen lo que esperas, por lo que mul multiplica, agrega, etc.
Los comentarios comienzan con; como es habitual en los lenguajes ensambladores.
Estructura de ensamblador IR LLMV
El contenido del archivo de ensamblaje IR LLVM es un módulo. El módulo contiene declaraciones de alto nivel, como variables y funciones globales.
Una declaración de función no contiene bloques base, una definición de función contiene uno o más bloques básicos (es decir, un cuerpo de función).
A continuación se muestra un ejemplo más detallado del módulo LLVM IR. incluyendo la definición de la variable global @foo y la definición de la función @f que contiene tres bloques base (% entry,% block_1 y% block_2).
; , 32- 21 @foo = global i32 21 ; f 42, cond , 0 define i32 @f(i1 %cond) { ; , ; entry: ; br block_1, %cond ; , block_2 . br i1 %cond, label %block_1, label %block_2 ; , , block_1: %tmp = load i32, i32* @foo %result = mul i32 %tmp, 2 ret i32 %result ; , , block_2: ret i32 0 }
Unidad base
Una unidad base es una secuencia de comandos que no son comandos de transición (comandos de terminación). La idea clave de la unidad base es que si se ejecuta un comando de la unidad base, se ejecutan todos los demás comandos de la unidad base. Esto simplifica el análisis del flujo de ejecución.
El equipo
Un comando que no es un comando de salto generalmente realiza cálculos o acceso a la memoria (por ejemplo, agregar, cargar), pero no cambia el flujo de control del programa.
Equipo de terminación
El comando de terminación se encuentra al final de cada unidad base y determina dónde se realizará la transición al final de la unidad base. Por ejemplo, el comando ret de terminación devuelve el flujo de control de la función de llamada y br realiza la transición, condicional o incondicional.
Formulario SSA
Una propiedad muy importante de LLVM IR es que está escrito en forma SSA (Asignación estática individual), lo que esencialmente significa que cada registro se asigna solo una vez. Esta propiedad simplifica el análisis estático del flujo de datos.
Para procesar variables que se asignan más de una vez en el código fuente original, el comando phi se usa en LLVM IR. El comando phi esencialmente devuelve un único valor de un conjunto de valores de entrada, dependiendo de la ruta de ejecución a la que se llegó este comando. Cada valor de entrada se asocia así con un bloque de entrada anterior.
Como ejemplo, considere la siguiente función IR LLVM:
define i32 @f(i32 %a) { ; <label>:0 switch i32 %a, label %default [ i32 42, label %case1 ] case1: %x.1 = mul i32 %a, 2 br label %ret default: %x.2 = mul i32 %a, 3 br label %ret ret: %x.0 = phi i32 [ %x.2, %default ], [ %x.1, %case1 ] ret i32 %x.0 }
El comando phi (también llamado a veces nodo phi) en el ejemplo anterior simula varias asignaciones utilizando un conjunto de valores de entrada posibles, uno para cada ruta posible en el hilo de ejecución, lo que lleva a la asignación variable. Por ejemplo, una de las rutas correspondientes en la secuencia de datos es la siguiente:
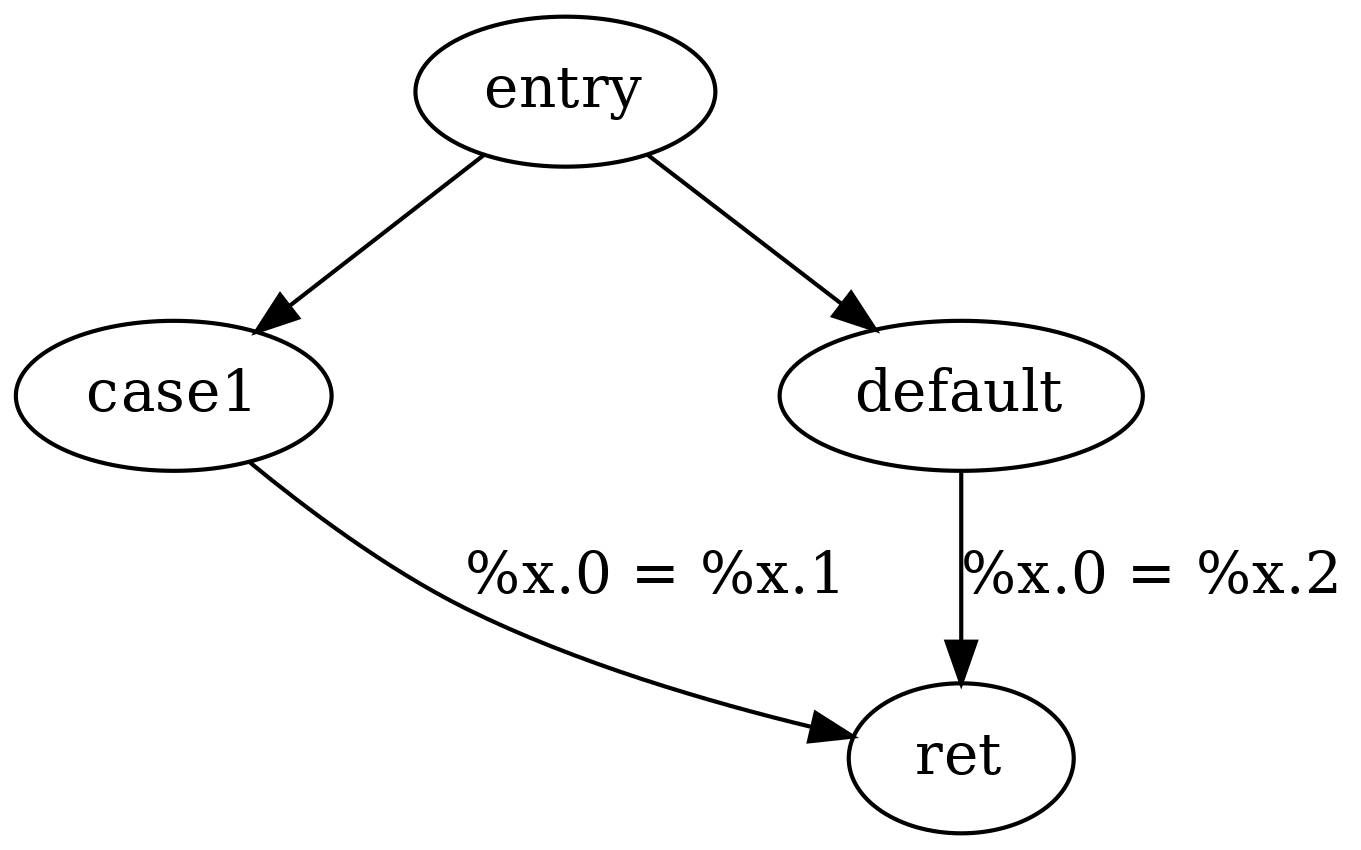
En general, cuando se desarrolla un compilador que convierte el código fuente a LLVM IR, todas las variables de código fuente local se pueden convertir a la forma SSA, con la excepción de las variables para las cuales se toma su dirección.
Para simplificar la implementación de la interfaz LLVM, se recomienda modelar las variables locales en el idioma de origen como variables asignadas en la memoria (usando alloca), simulando asignaciones a las variables locales como se escriben en la memoria y usando una variable local como lecturas de la memoria. La razón es que puede ser una tarea no trivial traducir directamente el lenguaje fuente a LLVM IR en forma SSA. Mientras los accesos a la memoria sigan ciertos patrones, podemos confiar en el pase de optimización de mem2reg como parte de LLVM para convertir las variables locales asignadas en la memoria en registros en forma SSA (usando nodos phi cuando sea necesario).
Biblioteca de LLVM IR en Go puro
Hay dos bibliotecas principales para trabajar con LLVM IR en Go:
https://godoc.org/llvm.org/llvm/bindings/go/llvm : enlaces LLVM oficiales para el idioma Go.
github.com/llir/llvm : una biblioteca Go limpia para interactuar con LLVM IR.
Los enlaces LLVM oficiales para el lenguaje Go usan Cgo para proporcionar acceso a las API ricas y poderosas del marco del compilador LLVM, mientras que el proyecto llir / llvm está completamente escrito en Go y usa LLVM IR para interactuar con el marco LLVM.
Este artículo se centra en llir / llvm, pero se puede generalizar para trabajar con otras bibliotecas.
¿Por qué escribir una nueva biblioteca?
La principal motivación para desarrollar una biblioteca Go limpia para interactuar con LLVM IR fue hacer que los compiladores de escritura y las herramientas de análisis estático, que se basan en el marco de compilación LLVM IR, sean una tarea más divertida. También estuvo influenciado por el hecho de que el tiempo de compilación de un proyecto basado en enlaces oficiales de LLVM con Go puede ser significativo (gracias a @aykevl, el autor de TinyGo, ahora es posible acelerar la compilación debido a la vinculación dinámica, a diferencia de la versión estándar de LLVM 4).
Otra gran motivación fue intentar desarrollar la API Go desde cero. La principal diferencia entre las API de enlace de LLVM para Go y llir / llvm es cómo se modelan los valores de LLVM. En las carpetas de LLVM para Go, los valores de LLVM se modelan como un tipo estructural concreto, que, en esencia, contiene todos los métodos posibles para todos los valores de LLVM posibles. Mi experiencia personal al usar esta API sugiere que es difícil saber qué subconjunto de métodos puede solicitar un valor dado. Por ejemplo, para obtener un código de operación de instrucción, llame al método InstructionOpcode, que es intuitivo. Sin embargo, si llama al método Opcode, que está diseñado para obtener el código operativo de una expresión constante, obtendrá un error de tiempo de ejecución: "argumento cast () de tipo incompatible". (conversión de argumento a tipo incompatible).
La biblioteca llir / llvm fue diseñada para verificar los tipos en tiempo de compilación y garantizar que se usen correctamente con el sistema de tipos Go. Los valores de LLVM en llir / llvm se modelan como tipos de interfaz. Este enfoque solo hace disponible un conjunto mínimo de métodos, compartidos por todos los valores, y si desea acceder a métodos o campos específicos, utilice el cambio de tipo (como se muestra en el ejemplo a continuación).
Ejemplo de uso
Ahora veamos algunos ejemplos de usos específicos. tengamos una biblioteca, pero ¿qué debemos hacer con el IR LLVM?
Primero, podríamos querer analizar el LLVM IR generado por otra herramienta, como Clang y el optimizador LLVM opt (vea la entrada de muestra a continuación).
En segundo lugar, es posible que queramos procesar el IR LLVM y realizar nuestro propio análisis sobre él, o realizar nuestros propios pases de optimización, o implementar un intérprete o un compilador JIT (consulte el ejemplo de análisis a continuación).
En tercer lugar, es posible que queramos generar un IR LLVM, que será una entrada para otros instrumentos. Este enfoque se puede elegir si estamos desarrollando una interfaz para un nuevo lenguaje de programación (vea el código de salida de muestra a continuación).
Código de entrada de muestra: análisis de LLVM IR
Ejemplo de análisis: procesamiento de LLVM IR
Código de salida de muestra: generación IR LLVM
Conclusión
El desarrollo e implementación de llir / llvm se llevó a cabo y fue dirigido por una comunidad de contribuyentes que no solo escribieron código, sino que también lideraron debates, sesiones de programación emparejadas, depuraron, perfilaron y mostraron curiosidad en el proceso de aprendizaje.
Una de las partes más difíciles del proyecto llir / llvm fue construir una gramática EBNF para LLVM IR, cubriendo todo el lenguaje LLVM IR hasta la versión LLVM 7.0. La dificultad aquí no está en el proceso en sí, sino en el hecho de que no existe una gramática publicada oficialmente que abarque todo el idioma. Algunas comunidades de código abierto han intentado definir la gramática formal para el ensamblador LLVM, pero cubren, hasta donde sabemos, solo subconjuntos del lenguaje.
Grammar LLVM IR allana el camino para proyectos interesantes. Por ejemplo, la generación de un ensamblador LLVM IR sintácticamente válido se puede usar para varias herramientas y bibliotecas usando LLVM IR, un enfoque similar se usa en GoSmith. Esto se puede usar para la validación cruzada de proyectos LLVM implementados en otros idiomas, así como para verificar vulnerabilidades y errores de implementación.
¡El futuro es maravilloso, feliz pirateo!
Referencias
1. Un
capítulo muy bien escrito sobre LLVM, escrito por Chris Lattner, autor del proyecto inicial de LLVM, en el libro "Arquitectura de aplicaciones de código abierto".
2.
El tutorial Implementar un lenguaje con LLVM , a menudo también llamado Kaleidoscope Language Guide, describe en detalle cómo implementar un lenguaje de programación simple compilado en LLVM IR. El artículo describe todas las etapas principales de escribir una interfaz, incluido un analizador léxico, un analizador sintáctico y la generación de código.
3. Para aquellos que estén interesados en escribir un compilador del lenguaje de entrada a LLVM IR, se recomienda el libro "
Mapeando construcciones de alto nivel a LLVM IR ".
Un buen conjunto de diapositivas es
LLVM, en gran detalle , que describe los conceptos importantes de LLVM IR, proporciona una introducción a la API LLVM C ++ y describe algunos pasajes de optimización de LLVM muy útiles.
Los enlaces Go oficiales para LLVM son adecuados para muchos proyectos, representan la API LLVM C, potente y estable.
Una buena adición a la publicación es
Una introducción a LLVM en Go.