Foto tomada de la publicación.Introduccion
Una de las tareas más urgentes del procesamiento de la señal digital es la tarea de limpiar la señal del ruido. Cualquier señal práctica contiene no solo información útil, sino también rastros de algunos efectos extraños de interferencia o ruido. Además, durante el diagnóstico de vibración, las señales de los sensores de vibración tienen un espectro de frecuencia no estacionario, lo que complica la tarea de filtrado.
Hay muchas formas diferentes de eliminar el ruido de alta frecuencia de una señal. Por ejemplo, la biblioteca Scipy contiene filtros basados en varios métodos de filtrado: Kalman; suavizando la señal promediando a lo largo del eje de tiempo y otros.
Sin embargo, la ventaja del método de transformación de wavelet discreta (DWT) es la variedad de formas de wavelet. Puede seleccionar una wavelet, que tendrá una forma característica de los fenómenos esperados. Por ejemplo, puede seleccionar una señal en un rango de frecuencia dado, cuya forma es responsable de la aparición de un defecto.
El propósito de esta publicación es analizar los métodos de filtrado de las señales de los sensores de vibración utilizando la conversión de señal DWT, el filtro de Kalman y el método de promedio móvil.
Fuente de datos para análisis
En la publicación, se analizará el funcionamiento de los filtros basados en varios métodos de filtrado utilizando
un conjunto de datos de la NASA . Datos obtenidos en la plataforma experimental PRONOSTIA:

El kit contiene datos sobre las señales del sensor de vibración para el desgaste de varios tipos de rodamientos. El propósito de las carpetas con los archivos de señal se da en la
tabla :
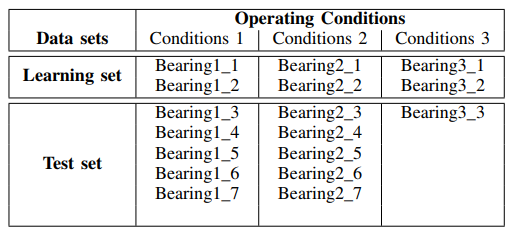
El monitoreo del estado de los rodamientos es proporcionado por las señales de los sensores de vibración (acelerómetros horizontales y verticales), la fuerza y la temperatura.

Señales recibidas para tres cargas diferentes:
- Primeras condiciones de trabajo: 1800 rpm y 4000 N;
- Segundas condiciones de trabajo: 1650 rpm y 4200 N;
- Terceras condiciones de funcionamiento: 1500 rpm y 5000 N.
Para estas condiciones, utilizando la conversión continua de señal wavelet, construimos los
escalogramas de
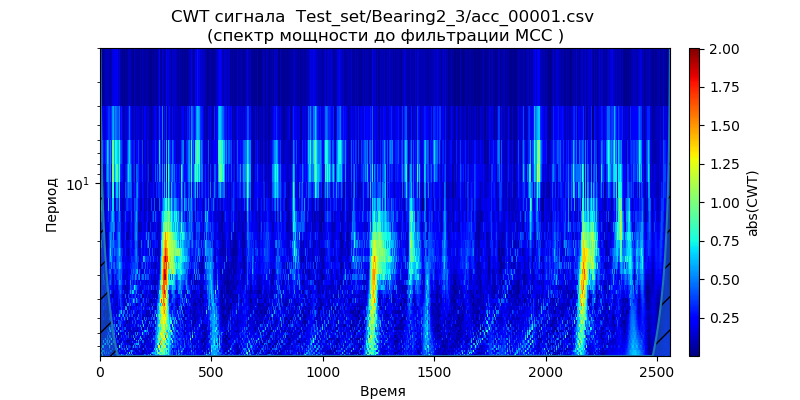
espectro de potencia para los datos del conjunto de prueba: un archivo (para un tipo de rodamientos) de las carpetas: ['Test_set / Bearing1_3 / acc_00001.csv', 'Test_set / Bearing2_3 / acc_00001. csv ',' Test_set / Bearing3_3 / acc_00001.csv '] (ver tabla 1).
Listado de escaleogramasimport scaleogram as scg import pandas as pd from pylab import * import pywt filename_n = ['Test_set/Bearing1_3/acc_00001.csv', 'Test_set/Bearing2_3/acc_00001.csv', 'Test_set/Bearing3_3/acc_00001.csv'] for filename in filename_n: df = pd.read_csv(filename, header=None) signal = df[4].values wavelet = 'cmor1-0.5' ax = scg.cws(signal, scales=arange(1, 40), wavelet=wavelet, figsize=(8, 4), cmap="jet", cbar=None, ylabel=' ', xlabel=" ", yscale="log", title='- %s \n( )'%filename) show()


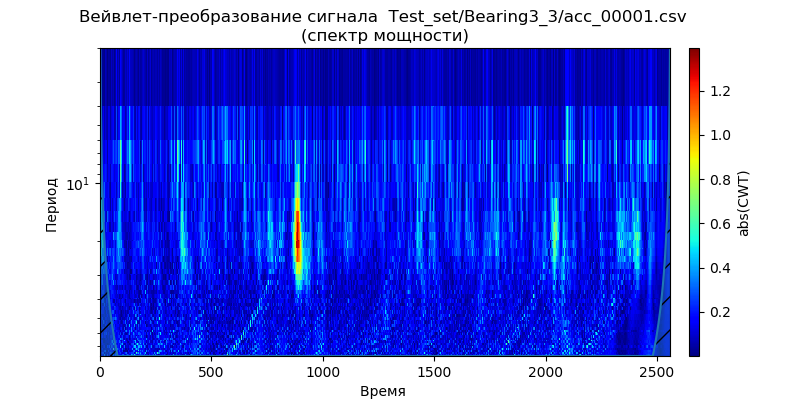
De los escaogramas dados se deduce que los momentos de aumento de la potencia del espectro aparecen antes en el tiempo y demuestran la frecuencia para las condiciones de operación: 1650 rpm y 4200 N, lo que indica una degradación acelerada de los rodamientos en esta banda de frecuencia para la fuerza reducida. Utilizaremos esta señal ('Test_set / Bearing2_3 / acc_00001.csv') para analizar los métodos de eliminación de ruido.
Deconstrucción de señal utilizando DWT
En la
publicación, vimos cómo se implementa un banco de filtros en el DWT que puede deconstruir una señal en sus subbandas de frecuencia. Los coeficientes de aproximación (cA) representan la parte de baja frecuencia de la señal (filtro de promedio). Los coeficientes de detalle (cD) representan la porción de alta frecuencia de la señal. A continuación, examinaremos cómo se puede usar DWT para deconstruir una señal en sus subbandas de frecuencia y restaurar la señal original.
Hay dos formas de resolver el problema de deconstrucción de señal utilizando las herramientas PyWavelets:
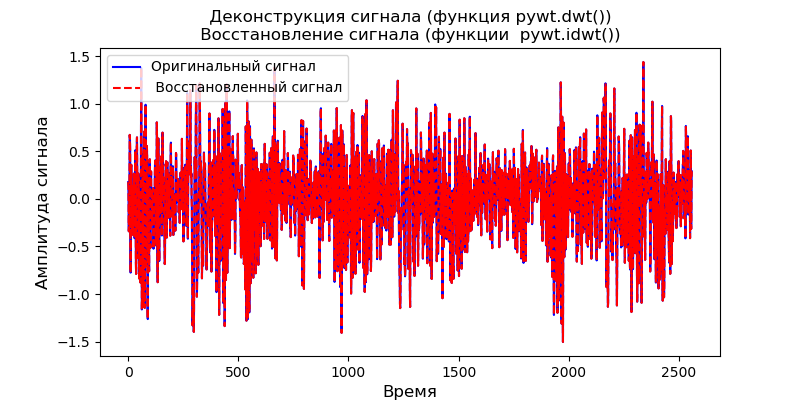
La primera forma es aplicar pywt.dwt () a la señal para extraer los coeficientes de aproximación y detalle (cA1, cD1). Luego, para restaurar la señal, usaremos pywt.idwt ():
Listado import pywt from scipy import * import pandas as pd from pylab import * filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values (cA1, cD1) = pywt .dwt (signal, 'db2', 'smooth') r_signal = pywt.idwt (cA1, cD1, 'db2', 'smooth') fig, ax =subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r', label=' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' ( pywt.dwt()) \n ( pywt.idwt()) ') show()
La segunda forma de aplicar la función pywt.wavedec () a la señal es restaurar todos los coeficientes de aproximación y detalle a un cierto nivel. Esta función toma la señal y el nivel iniciales como entrada y devuelve un conjunto de coeficientes de aproximación (enésimo nivel) yn conjuntos de coeficientes de detalle (del 1 al enésimo nivel). Para la deconstrucción, aplique pywt.waverec ():
Listado import pywt import pandas as pd from pylab import * filename = 'Test_set/Bearing3_3/acc_00026.csv' df = pd.read_csv(filename, header=None) signal = df[4].values coeffs = pywt.wavedec(signal, 'db2', level=8) r_signal = pywt.waverec(coeffs, 'db2') fig, ax = plt.subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r ',label= ' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' - level.\n ( pywt.wavedec()) ') show()

La segunda forma de deconstruir y restaurar la señal es más conveniente, ya que le permite establecer inmediatamente el nivel deseado de deconstrucción.
Eliminar el ruido de alta frecuencia eliminando algunos de los coeficientes de detalle durante la deconstrucción de la señal
Restauraremos la señal eliminando algunos de los coeficientes de detalle. Dado que los coeficientes de detalle representan la parte de alta frecuencia de la señal, simplemente filtramos esta parte del espectro de frecuencia. Si hay ruido de alta frecuencia en la señal, esta es una forma de filtrarlo.
En la biblioteca PyWavelets, esto se puede hacer usando la función de procesamiento de umbral pywt.threshol ():
pywt.threshold (datos, valor, modo = 'soft', sustituto = 0) ¶
data: array_like
Datos numéricosvalor: escalar
Valor umbralmodo: {'suave', 'duro', 'garrote', 'mayor', 'menor'}
Define el tipo de umbral que se aplicará a la entrada. El valor predeterminado es "suave".sustituto: flotador, opcional
Valor de sustitución (predeterminado: 0).salida: matriz
Arreglo de umbral.La aplicación de la función de procesamiento de umbral para un valor de umbral dado se considera mejor usando el siguiente ejemplo:
>>>> from scipy import* >>> import pywt >>> data =linspace(1, 4, 7) >>> data array([1. , 1.5, 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'soft') array([0. , 0. , 0. , 0.5, 1. , 1.5, 2. ]) >>> pywt.threshold(data, 2, 'hard') array([0. , 0. , 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'garrote') array([0. , 0. , 0., 0.9,1.66666667, 2.35714286, 3.])
Trazamos el gráfico de la función de umbral usando la siguiente lista:
Listado from scipy import* from pylab import* import pywt s = linspace(-4, 4, 1000) s_soft = pywt.threshold(s, value=0.5, mode='soft') s_hard = pywt.threshold(s, value=0.5, mode='hard') s_garrote = pywt.threshold(s, value=0.5, mode='garrote') figsize=(10, 4) plot(s, s_soft) plot(s, s_hard) plot(s, s_garrote) legend(['soft (0.5)', 'hard (0.5)', 'non-neg. garrote (0.5)']) xlabel(' ') ylabel(' ') show()
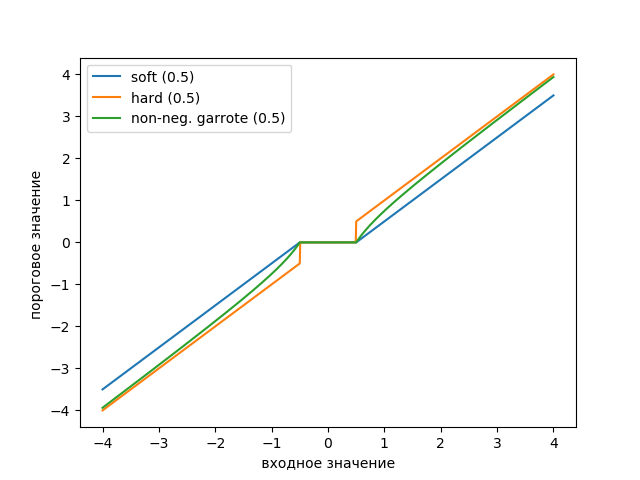
El gráfico muestra que el umbral de Garott no negativo es intermedio entre el umbral blando y el duro. Se requieren un par de umbrales que definen el ancho de la región de transición.
La influencia de la función umbral en las características del filtro
Como se deduce del gráfico anterior, solo dos funciones de umbral 'soft' y 'garrote' son adecuadas para nosotros, para estudiar su influencia en las características del filtro, anotamos la lista:
Listado import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=['soft' ,'garrote'] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode=w ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n :%s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()

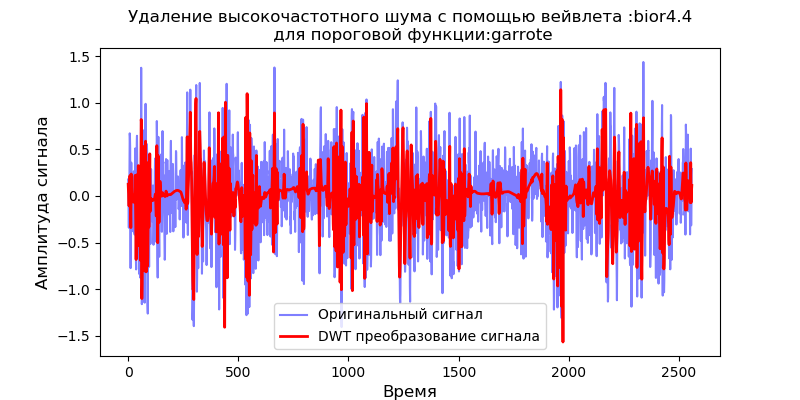
Como se desprende de los gráficos, la función suave proporciona un mejor suavizado que la función 'garrote', por lo que utilizaremos la función suave en el futuro.
La influencia del umbral de detalle en las características del filtro.
Para el tipo de filtro en consideración, el umbral para cambiar los coeficientes de detalle es una característica importante, por lo tanto, estudiamos su efecto utilizando la siguiente lista:
Listado import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=[0.1,0.4,0.6] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal,w) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n %s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()



Como se deduce de los gráficos obtenidos, el umbral del nivel de detalle afecta la escala de las partes apantalladas. Con un aumento en el umbral, la wavelet resta ruido de un nivel cada vez mayor hasta que se produce un aumento excesivo de la escala de detalle y la transformación comienza a distorsionar la forma de la señal original. Para nuestra señal, el umbral no debe ser superior a 0,63.
El efecto de wavelet en las características del filtro
La biblioteca PyWavelets tiene un número suficiente de wavelets para la conversión DWT, que se puede obtener de esta manera:
>>> import pywt >>> print(pywt.wavelist(kind= 'discrete')) ['bior1.1', 'bior1.3', 'bior1.5', 'bior2.2', 'bior2.4', 'bior2.6', 'bior2.8', 'bior3.1', 'bior3.3', 'bior3.5', 'bior3.7', 'bior3.9', 'bior4.4', 'bior5.5', 'bior6.8', 'coif1', 'coif2', 'coif3', 'coif4', 'coif5', 'coif6', 'coif7', 'coif8', 'coif9', 'coif10', 'coif11', 'coif12', 'coif13', 'coif14', 'coif15', 'coif16', 'coif17', 'db1', 'db2', 'db3', 'db4', 'db5', 'db6', 'db7', 'db8', 'db9', 'db10', 'db11', 'db12', 'db13', 'db14', 'db15', 'db16', 'db17', 'db18', 'db19', 'db20', 'db21', 'db22', 'db23', 'db24', 'db25', 'db26', 'db27', 'db28', 'db29', 'db30', 'db31', 'db32', 'db33', 'db34', 'db35', 'db36', 'db37', 'db38', 'dmey', 'haar', 'rbio1.1', 'rbio1.3', 'rbio1.5', 'rbio2.2', 'rbio2.4', 'rbio2.6', 'rbio2.8', 'rbio3.1', 'rbio3.3', 'rbio3.5', 'rbio3.7', 'rbio3.9', 'rbio4.4', 'rbio5.5', 'rbio6.8', 'sym2', 'sym3', 'sym4', 'sym5', 'sym6', 'sym7', 'sym8', 'sym9', 'sym10', 'sym11', 'sym12', 'sym13', 'sym14', 'sym15', 'sym16', 'sym17', 'sym18', 'sym19', 'sym20']
La influencia de la wavelet en la característica del filtro depende de su función primitiva. Para demostrar esta dependencia, seleccionamos dos wavelets de la familia Dobeshi: db1 y db38, y consideramos estas familias:
Listado import pywt from pylab import* db_wavelets = ['db1', 'db38'] fig, axarr = subplots(ncols=2, nrows=5, figsize=(14,8)) fig.suptitle(' : db1,db38', fontsize=14) for col_no, waveletname in enumerate(db_wavelets): wavelet = pywt.Wavelet(waveletname) no_moments = wavelet.vanishing_moments_psi family_name = wavelet.family_name for row_no, level in enumerate(range(1,6)): wavelet_function, scaling_function, x_values = wavelet.wavefun(level = level) axarr[row_no, col_no].set_title("{} : {}. : {}. :: {} ".format( waveletname, level, no_moments, len(x_values)), loc='left') axarr[row_no, col_no].plot(x_values, wavelet_function, 'b--') axarr[row_no, col_no].set_yticks([]) axarr[row_no, col_no].set_yticklabels([]) tight_layout() subplots_adjust(top=0.9) show()
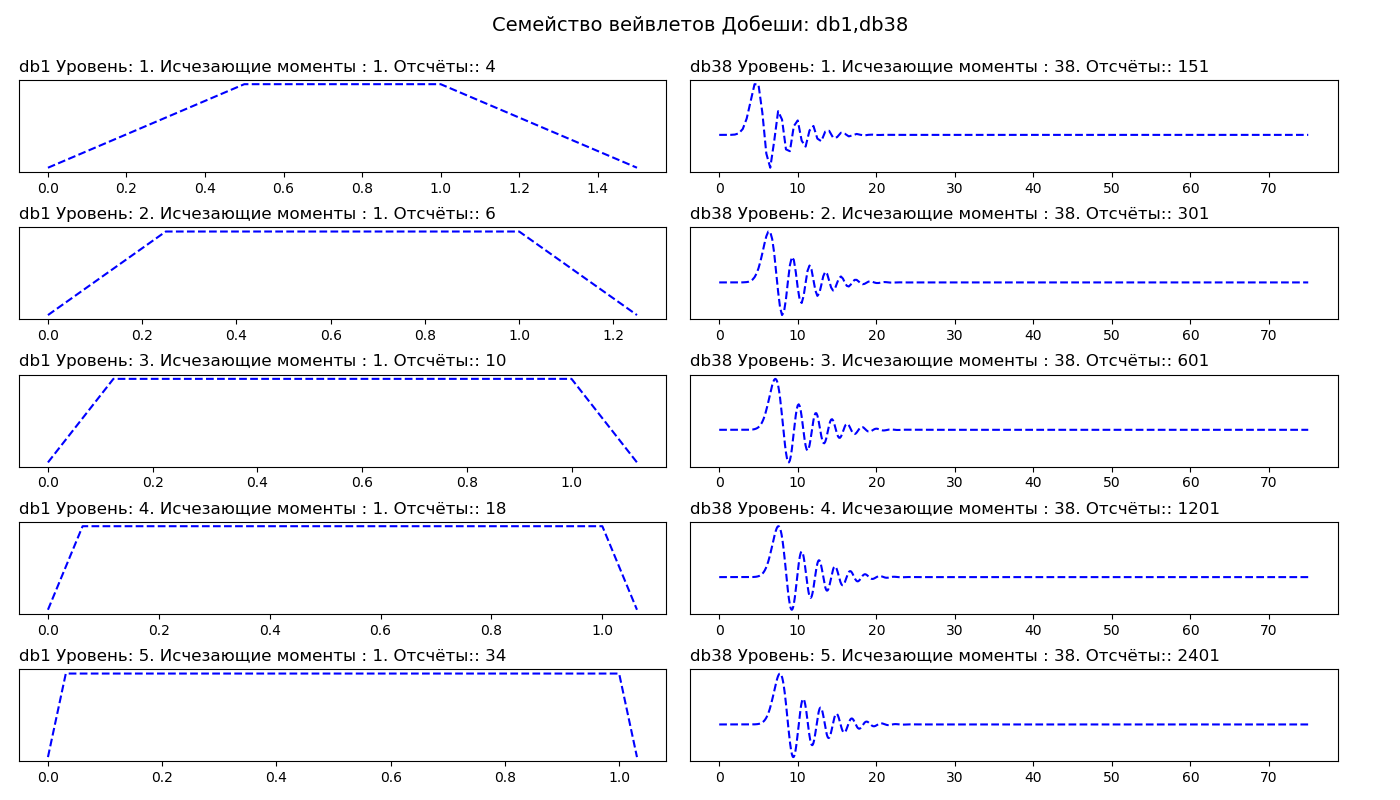
En la primera columna vemos las wavelets Daubeshi del primer orden (db1), en la segunda columna del trigésimo octavo orden (db38). Por lo tanto, db1 tiene un momento de extinción, y db38 tiene 38 momentos de extinción. El número de momentos de desaparición está relacionado con el orden de aproximación y la suavidad de la wavelet. Si una wavelet tiene P puntos de desaparición, puede aproximarse a polinomios de grado P - 1.
Las wavelets más suaves crean una aproximación de señal más suave y viceversa: las wavelets "cortas" siguen mejor los picos de la función aproximada. Al elegir una wavelet, también podemos indicar cuál debería ser el nivel de descomposición. Por defecto, PyWavelets selecciona el nivel máximo de descomposición posible para la señal de entrada. El nivel máximo de descomposición depende de la longitud de la señal de entrada y wavelet:
Listado import pandas as pd import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) data = df[4].values w=['db1', 'db38'] for v in w: n_level=pywt.dwt_max_level(len(data),v) print(' %s : %s ' %(v,n_level))
Para wavelet db1, nivel máximo de descomposición: 11
Para wavelet db38, nivel máximo de descomposición: 5
Para los valores obtenidos de los niveles máximos de descomposición de wavelets, consideramos la operación del filtro para eliminar el ruido de alta frecuencia:
Listado import pandas as pd import scaleogram as scg from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values discrete_wavelets =[('db38', 5),('db1',11)] for v in discrete_wavelets: def lowpassfilter(signal, thresh = 0.63, wavelet=v[0]): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal wavelet = pywt.DiscreteContinuousWavelet(v[0]) phi, psi, x = wavelet.wavefun(level=v[1]) fig, ax = subplots(figsize=(8,4)) ax.set_title(" : %s,level=%s"%(v[0],v[1]), fontsize=12) ax.plot(x,phi,linewidth=2) fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' \n :%s,level=%s'%(v[0],v[1]),fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) wavelet = 'cmor1-0.5' ax = ax = scg.cws(rec, scales=arange(1,128), wavelet=wavelet,figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT \n( DWT )') show()

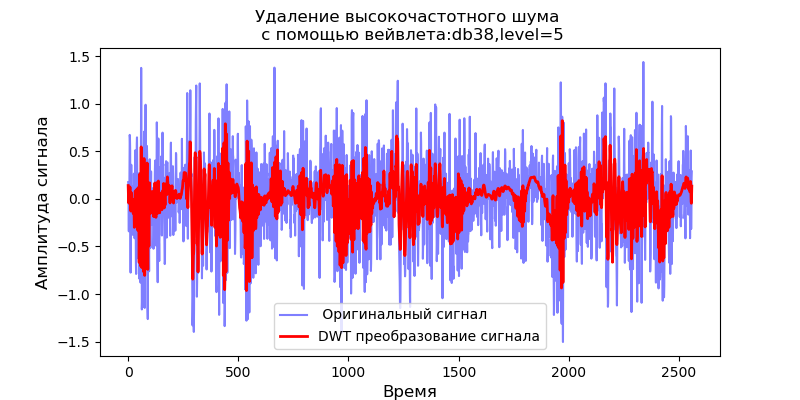
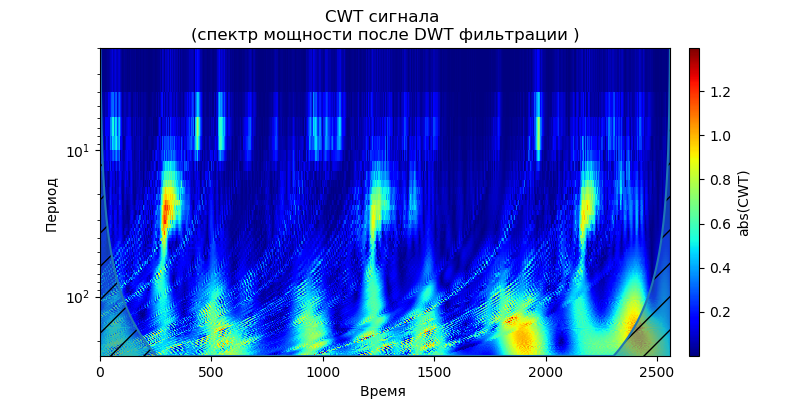

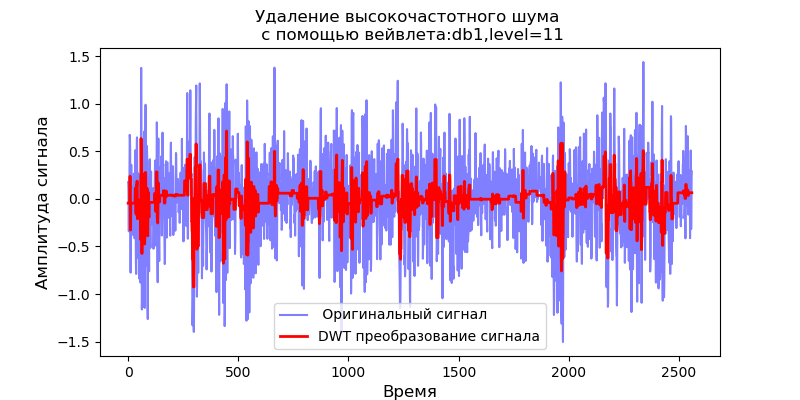

Se deduce de los escalogramas dados de las señales en la salida del filtro que, para la wavelet db38, la potencia máxima del espectro es seguida por regiones localizadas, para la wavelet db1, estas regiones desaparecen. Cabe señalar que, por ejemplo, la wavelet db38 puede aproximarse a una señal de polinomio de grado 37. Esto extiende la clasificación de las señales, por ejemplo, para identificar el mal funcionamiento del equipo por las señales de los sensores de vibración.
Dado que la señal después del filtro con la wavelet de Daubechies forma una serie temporal utilizando los coeficientes de aproximación y descomposición como características de la serie, es posible determinar el grado de proximidad de dicha serie, lo que simplifica enormemente su búsqueda y clasificaciónFiltro de Kalman para eliminar el ruido de alta frecuencia
El filtro Kalman se usa ampliamente para filtrar el ruido en varios sistemas dinámicos. Considere un sistema dinámico con un vector de estado x.
donde F es la matriz de transición
w (Q) es un proceso aleatorio (ruido) con cero expectativas matemáticas y una matriz de covarianza Q.
Observaremos las transiciones de estado del sistema con un error de medición conocido en cada momento del tiempo. Eliminar el ruido usando el método de Kalman consta de dos pasos: extrapolación y corrección, se ve así.
Establezca los parámetros del sistema:
Matriz Q de covarianza de ruido (covarianza de ruido de proceso).
H es la matriz de observación (medición).
R - covarianza del ruido de observación (covarianza del ruido de medición).
P = Q es el valor inicial de la matriz de covarianza para el vector de estado.
z (t) es el estado observado del sistema.
x = z (0) es el valor inicial de la evaluación del estado del sistema.
Para cada observación z, calcularemos el estado filtrado x
y para esto realizamos los siguientes pasos.
• paso 1: extrapolación
1. extrapolación (predicción) del estado del sistema
2. calcular la matriz de covarianza para el vector de estado extrapolado
• paso 2: corrección
1. calcular el vector de error, la desviación de la observación del estado esperado
2. calcular la matriz de covarianza para el vector de desviación (vector de error)
3. calcular las ganancias de Kalman
4. corrección de la estimación vectorial del estado
5. corregimos la matriz de covarianza para estimar el vector de estado del sistema
Listado para la implementación del algoritmo from scipy import* from pylab import* import pandas as pd def kalman_filter( z, F = eye(2), # (transitionMatrix) Q = eye(2)*3e-3, # (processNoiseCov) H = eye(2), # (measurement) R = eye(2)*3e-1 # (measurementNoiseCov) ): n = z.shape[0]
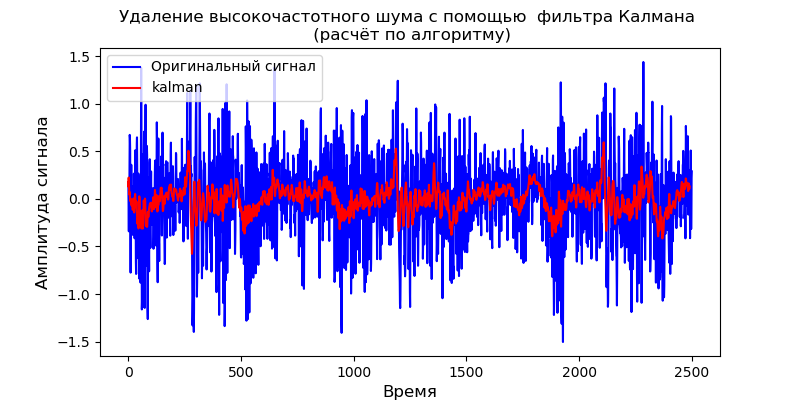
Para el modelo dinámico dado, puede usar la biblioteca pyKalman:
Listado from pykalman import KalmanFilter import pandas as pd from pylab import * import scaleogram as scg filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values measurements =signal kf = KalmanFilter(transition_matrices=[1] ,



El filtro Kalman elimina bien el ruido de alta frecuencia, sin embargo, no permite cambiar la forma de la señal de salida.
Método de media móvil
Al determinar la dirección principal de los cambios en una secuencia fuertemente oscilante, surge el problema de suavizarlo utilizando el método de la media móvil. Estas pueden ser las lecturas del sensor de nivel de combustible en el automóvil o, como en nuestro caso, los datos de los sensores de alta frecuencia con respecto a la degradación acelerada de los rodamientos. El problema puede considerarse como la restauración de alguna secuencia r sobre la cual se superpuso el ruido.
Media móvil simple para abreviar: SMA (Media móvil simple). Para calcular el valor del filtro actual
solo promediamos los n elementos anteriores de la secuencia, por lo que el filtro comienza a funcionar con el elemento de secuencia n.
Listado <source lang="python">from scipy import * import pandas as pd from pylab import * import pywt import scaleogram as scg def get_ave_values(xvalues, yvalues, n = 6): signal_length = len(xvalues) if signal_length % n == 0: padding_length = 0 else: padding_length = n - signal_length//n % n xarr = array(xvalues) yarr = array(yvalues) xarr.resize(signal_length//n, n) yarr.resize(signal_length//n, n) xarr_reshaped = xarr.reshape((-1,n)) yarr_reshaped = yarr.reshape((-1,n)) x_ave = xarr_reshaped[:,0] y_ave = nanmean(yarr_reshaped, axis=1) return x_ave, y_ave def plot_signal_plus_average(time, signal, average_over = 5): fig, ax = subplots(figsize=(8, 4)) time_ave, signal_ave = get_ave_values(time, signal, average_over) ax.plot(time_ave, signal_ave,"b", label = ' (n={})'.format(5)) ax.set_xlim([time[0], time[-1]]) ax.set_ylabel(' ', fontsize=12) ax.set_title(' SMA', fontsize=14) ax.set_xlabel('', fontsize=12) ax.legend() return signal_ave filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) df_nino = df[4].values N = df_nino.shape[0] time = arange(0, N) signal = df_nino signal_ave=plot_signal_plus_average(time, signal) wavelet = 'cmor1-0.5' ax = ax = scg.cws(signal, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4),cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) ax = ax = scg.cws(signal_ave, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) show()


Como se desprende del escalograma, el método SMA no limpia la señal del ruido de alta frecuencia, y
como se mencionó anteriormente se utiliza para alisar.
Conclusiones:
- Usando el módulo de escalagrama, se obtuvieron escalogramas wavelet CWT de tres señales de sensor de vibración de prueba para diferentes condiciones de prueba para rodamientos del mismo tipo. Según los datos del escalograma, se seleccionó una señal con signos claramente expresados de degradación tardía. Esta señal se utilizó para demostrar el funcionamiento de los filtros en todos los ejemplos dados.
- Se consideran los métodos de la biblioteca PyWavelets para la deconstrucción DWT y la restauración de la señal del sensor de vibración utilizando los módulos pywt.dwt (), pywt.idwt () y el módulo pywt.wavedec () para un nivel de wavelet dado.
- Los ejemplos muestran las características de la aplicación del módulo pywt.threshol () para filtrar los coeficientes de refinamiento de DWT, que son responsables de la parte de alta frecuencia del espectro utilizando funciones de umbral para un valor de umbral dado.
- Se consideran los efectos de la wavelet antiderivada DWT en la forma de una señal libre de ruido.
- Se obtiene un modelo de filtro Kalman para un medio dinámico, el modelo se prueba con la señal de prueba del sensor de vibración. La gráfica de eliminación de ruido es la misma que la obtenida usando el módulo pyKalman. La naturaleza del gráfico coincide con el escalograma.
- .