El deseo de alejarse de las pruebas de regresión manual es una buena razón para introducir pruebas automáticas. La pregunta es cuáles. Los desarrolladores de interfaces Natalya Stus y Alexei Androsov recordaron cómo su equipo pasó por varias iteraciones y construyeron pruebas frontend en Auto.ru basadas en Jest y Puppeteer: pruebas unitarias, pruebas para componentes React individuales, pruebas de integración. Lo más interesante de esta experiencia es la prueba aislada de componentes React en un navegador sin Selenium Grid, Java y otras cosas.

Alexey:
- Primero debes contar un poco qué es Automotive News. Este es un sitio que vende autos. Hay una búsqueda, cuenta personal, servicios de automóviles, repuestos, revisiones, concesionarios y mucho más. Auto.ru es un proyecto muy grande, con mucho código. Escribimos todo el código en un gran monorepe, porque todo está mezclado. Las mismas personas realizan tareas similares, por ejemplo, para dispositivos móviles y de escritorio. Resulta mucho código, y monorepa es vital para nosotros. La pregunta es cómo probarlo.

Tenemos React y Node.js, que realiza la representación del lado del servidor y solicita datos del backend. Piezas restantes y pequeñas en el BEM.

Natalya
- Comenzamos a pensar en la automatización. El ciclo de lanzamiento de nuestras aplicaciones individuales incluyó varios pasos. Primero, el programador desarrolla la característica en una rama separada. Después de eso, en la misma rama separada, la característica es probada por probadores manuales. Si todo está bien, la tarea recae en el candidato de liberación. De lo contrario, vuelva a la iteración de desarrollo nuevamente, pruebe nuevamente. Hasta que el probador diga que todo está bien en esta función, no entrará en el candidato de lanzamiento.
Después de ensamblar el candidato de lanzamiento, hay una regresión manual, no solo Auto.ru, sino solo el paquete que vamos a lanzar. Por ejemplo, si vamos a rodar la web de escritorio, entonces hay una regresión manual de la web de escritorio. Estos son muchos casos de prueba manual. Tal regresión tomó aproximadamente un día hábil de un probador manual.
Cuando se completa la regresión, se produce una liberación. Después de eso, la rama de lanzamiento se fusiona con el maestro. En este punto, solo podemos inyectar el código maestro, que probamos solo para la web de escritorio, y este código puede romper la web móvil, por ejemplo. Esto no se verifica de inmediato, sino solo en la próxima regresión manual: la web móvil.

Naturalmente, el lugar más doloroso en este proceso fue la regresión manual, que tomó mucho tiempo. Todos los probadores manuales, naturalmente, están cansados de hacer lo mismo todos los días. Por lo tanto, decidimos automatizar todo. La primera solución que se ejecutó fueron las autocomprobaciones de Selenium y Java, escritas por un equipo separado. Estas fueron pruebas de extremo a extremo, e2e, que probaron toda la aplicación. Escribieron alrededor de 5 mil de tales pruebas. ¿Con qué terminamos?
Naturalmente, aceleramos la regresión. Las pruebas automáticas pasan mucho más rápido que un probador manual, aproximadamente 10 veces más rápido resultó. En consecuencia, las acciones de rutina que realizaban todos los días se eliminaron de los probadores manuales. Los errores encontrados de las pruebas automáticas son más fáciles de reproducir. Simplemente reinicie esta prueba o observe los pasos que sigue, a diferencia del probador manual, que dirá: "Hice clic en algo y todo se rompió".
Proporcionó estabilidad del recubrimiento. Siempre realizamos las mismas pruebas de ejecución, en contraste, de nuevo, de las pruebas manuales, cuando el evaluador puede considerar que no tocamos este lugar, y no lo comprobaré esta vez. Agregamos pruebas para comparar capturas de pantalla, mejoramos la precisión de las pruebas de IU; ahora verificamos la diferencia en un par de píxeles que el probador no verá con sus ojos. Todo gracias a las pruebas de captura de pantalla.
Pero había contras. El más grande: para las pruebas e2e, necesitamos un entorno de prueba que sea totalmente coherente con el producto. Siempre debe mantenerse actualizado y operativo. Esto requiere casi tanta fuerza como vender soporte de estabilidad. Naturalmente, no siempre podemos pagarlo. Por lo tanto, a menudo tuvimos situaciones en las que el entorno de prueba no funciona o en algún lugar se rompe algo, y las pruebas fallan, aunque no hubo problemas en el paquete principal.
Estas pruebas también están siendo desarrolladas por un equipo separado, que tiene sus propias tareas, su propio turno en el rastreador de tareas y las nuevas funciones están cubiertas con cierto retraso. No pueden venir inmediatamente después del lanzamiento de una nueva función e inmediatamente escribir autotests en ella. Como las pruebas son caras y difíciles de escribir y mantener, no cubrimos todos los escenarios con ellos, sino solo los más críticos. Al mismo tiempo, se necesita un equipo separado, y tendrá herramientas separadas, una infraestructura separada, propia. Y el análisis de las pruebas caídas también es una tarea no trivial para los probadores manuales o para los desarrolladores. Mostraré un par de ejemplos.
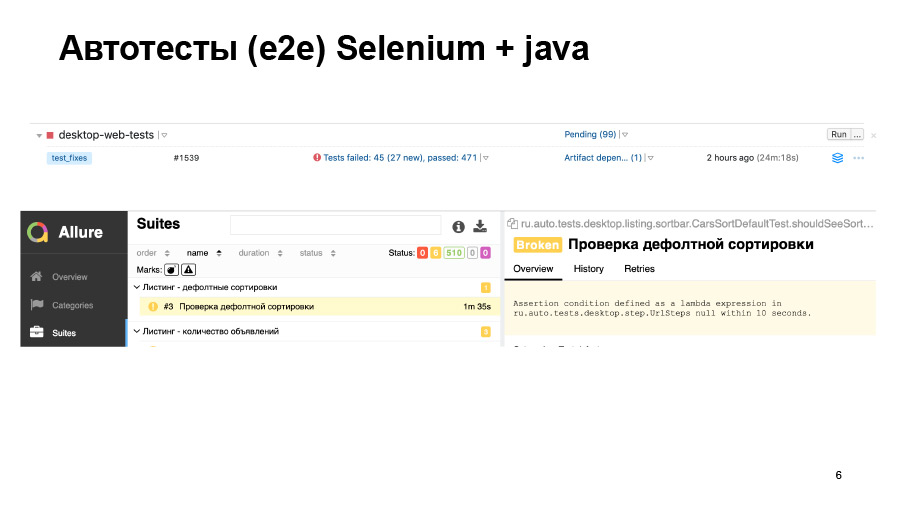
Hemos realizado pruebas. Pasaron 500 pruebas, de las cuales algunas cayeron. Podemos ver tal cosa en el informe. Aquí la prueba simplemente no comenzó, y no está claro si todo está bien allí o no.
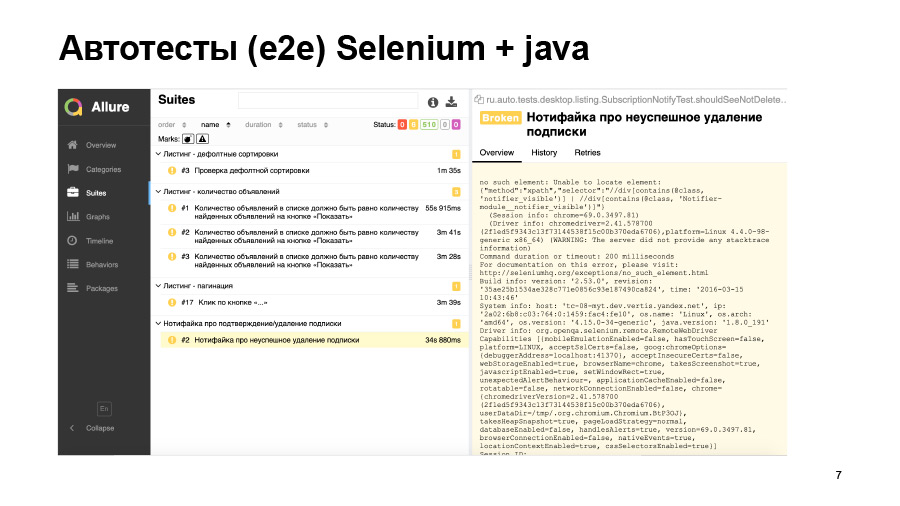
Otro ejemplo: la prueba comenzó, pero se bloqueó con dicho error. No pudo encontrar ningún elemento en la página, pero no sabemos por qué. O este elemento simplemente no apareció, o resultó estar en la página incorrecta, o el localizador cambió. Todo lo que necesitas para ir y debatir las manos.
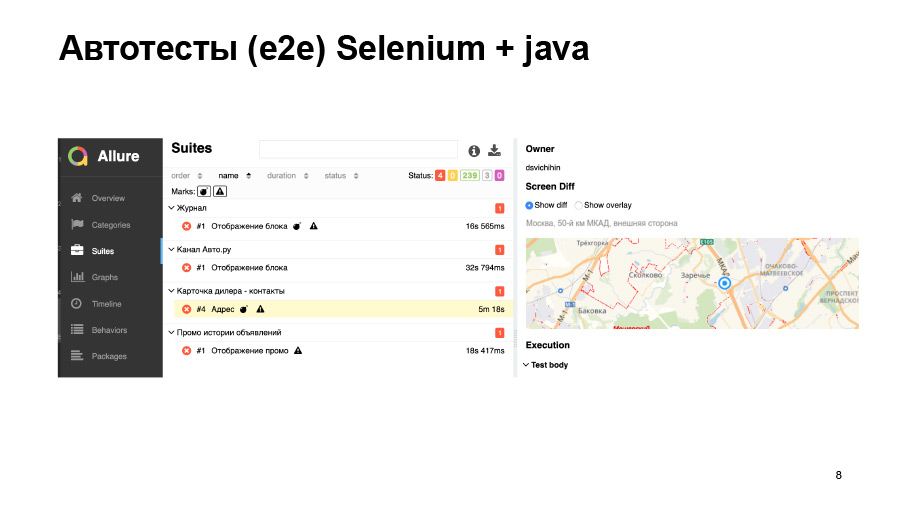
Las pruebas de captura de pantalla tampoco siempre nos dan una buena precisión. Aquí cargamos algún tipo de tarjeta, se ha movido ligeramente, nuestra prueba ha caído.

Intentamos resolver varios de estos problemas. Comenzamos a ejecutar parte de las pruebas en el producto; las que no afectan los datos del usuario no cambian nada en la base de datos. Es decir, en prod hicimos una máquina separada que examina el entorno prod. Simplemente instalamos un nuevo paquete frontend y ejecutamos pruebas allí. El producto es al menos estable.
Transferimos algunas de las pruebas a mokeys, pero tenemos muchos backends diferentes, diferentes API, y bloquearlo todo es una tarea muy difícil, especialmente para 5 mil pruebas. Para esto, se escribió un servicio especial llamado mockritsa, que ayuda a hacer los mokas necesarios para el frontend con bastante facilidad y es bastante fácil representarlos.
También tuvimos que comprar un montón de hierro para que nuestra red de dispositivos Selenium desde la que se inician estas pruebas fuera más grande para que no se cayeran, ya que no podrían elevar el navegador y, en consecuencia, irían más rápido. Incluso después de que intentamos resolver estos problemas, llegamos a la conclusión de que tales pruebas no son adecuadas para CI, toman mucho tiempo. No podemos ejecutarlos en cada solicitud de grupo. Simplemente nunca en nuestra vida analizaremos más adelante estos informes, que se generarán para cada solicitud de grupo.

En consecuencia, para CI, necesitamos pruebas rápidas y estables que no fallen por algunas razones aleatorias. Queremos ejecutar pruebas para la solicitud de grupo sin ningún banco de pruebas, backends, bases de datos, sin ningún caso de usuario complicado.
Queremos que estas pruebas se escriban simultáneamente con el código, y que los resultados de las pruebas dejen en claro de inmediato en qué archivo salió algo mal.
Alexey:
- Sí, y decidimos probar todo lo que queramos, enderezar todo desde el principio hasta el final en la misma infraestructura de Jest. ¿Por qué elegimos Jest? Ya escribimos pruebas unitarias en Jest, nos gustó. Esta es una herramienta popular y compatible, ya tiene un montón de integraciones listas para usar: React test render, Enzyme. Todo funciona de fábrica, no es necesario construir nada, todo es simple.

Y Jest personalmente ganó para mí en eso, a diferencia de cualquier moka, es difícil disparar el efecto secundario de algún tipo de prueba de terceros en su pierna si olvidé limpiarlo u otra cosa. En moka, esto se hace una o dos veces, pero en Jest es difícil hacerlo: se lanza constantemente en hilos separados. Es posible, pero difícil. Y para e2e lanzó Puppeteer, también decidimos probarlo. Eso es lo que tenemos.

Natalya
"También comenzaré con un ejemplo de pruebas unitarias". Cuando escribimos pruebas simplemente para alguna función, no hay problemas especiales. Llamamos a esta función, pasamos algunos argumentos, comparamos lo que sucedió con lo que debería haber sucedido.
Si hablamos de componentes React, entonces todo se vuelve un poco más complicado. Necesitamos representarlos de alguna manera. Existe un procesador de prueba React, pero no es muy conveniente para las pruebas unitarias, ya que no nos permitirá probar componentes de forma aislada. Representará el componente completamente hasta el final, para su diseño.
Y quiero mostrar cómo con Enzyme es posible escribir pruebas unitarias para componentes React utilizando un ejemplo de dicho componente donde tenemos un cierto MyComponent. Obtiene algún tipo de apoyo, tiene algún tipo de lógica. Luego devuelve el componente Foo, que, a su vez, devolverá el componente de barra, que ya en el componente de barra nos devuelve, de hecho, el diseño.

Podemos usar una herramienta de enzimas como el renderizado superficial. Esto es justo lo que necesitamos para probar el componente MyComponent de forma aislada. Y estas pruebas no dependerán de lo que los componentes foo y bar contendrán dentro de sí mismos. Simplemente probaremos la lógica del componente MyComponent.
Jest tiene algo así como Instantánea, y también pueden ayudarnos aquí. "Esperar algo para hacer una captura de pantalla" creará una estructura para nosotros, solo un archivo de texto que almacena, de hecho, lo que pasamos a esperar, lo que sucede, y cuando se ejecuta esta prueba por primera vez, este archivo se escribe. Con más ejecuciones de las pruebas, lo que se obtenga se comparará con el estándar contenido en el archivo MyComponent.test.js.snap.
Aquí vemos que todo el renderizado nos devuelve exactamente lo que el método de renderizado de MyComponent devuelve, y lo que es, en general, no importa. Podemos escribir esas dos pruebas para nuestros dos casos, para nuestros dos casos para el componente MyComponent.

En principio, podemos probar lo mismo sin una instantánea, simplemente comprobando los scripts que necesitamos, por ejemplo, comprobando qué accesorio se pasa al componente foo. Pero este enfoque tiene un menos. Si agregamos algún otro elemento a MyComponent, nuestra nueva prueba, esto no se muestra de ninguna manera.

Por lo tanto, después de todo, las pruebas de Instantáneas son aquellas que nos mostrarán casi cualquier cambio dentro del componente. Pero si escribimos ambas pruebas en Snapshot, y luego hacemos los mismos cambios en el componente, entonces veremos que ambas pruebas caerán. En principio, los resultados de estas pruebas fallidas nos dirán sobre lo mismo, que agregamos algún tipo de "hola" allí.

Y esto también es redundante, por lo tanto, creo que es mejor usar una prueba de Instantánea para la misma estructura. Verifique el resto de la lógica de alguna manera diferente, sin Snapshot, porque Snapshot, no son muy indicativos. Cuando ve Instantánea, solo ve que se ha procesado algo, pero no está claro qué lógica probó aquí. Esto es completamente inadecuado para TDD si desea usarlo. Y no funcionará como documentación. Es decir, cuando veas este componente, verás que sí, Snapshot corresponde a algo, pero qué tipo de lógica había allí no está muy claro.


Del mismo modo, escribiremos pruebas unitarias en el componente foo, en el componente de barra, por ejemplo, Instantánea.

Obtenemos 100% de cobertura para estos tres componentes. Creemos que hemos comprobado todo, estamos bien hechos.
Pero digamos que cambiamos algo en el componente de la barra, le agregamos un nuevo accesorio, y obviamente tuvimos una prueba para el componente de la barra. Corregimos la prueba, y las tres pruebas pasan con nosotros.

Pero, de hecho, si recopilamos toda esta historia, entonces nada funcionará, porque MyComponent no se juntará con tal error. En realidad, no pasamos el accesorio que espera al componente de la barra. Por lo tanto, estamos hablando del hecho de que en este caso también necesitamos pruebas de integración que verifiquen, incluso si llamamos correctamente a su componente hijo desde nuestro componente.

Teniendo tales componentes y cambiando uno de ellos, inmediatamente verá qué cambios en este componente han afectado.
¿Qué oportunidades tenemos en Enzyme para realizar pruebas de integración? El renderizado en sí mismo devuelve dicha estructura. Tiene un método de inmersión, si se llama en algún componente React, fallará. En consecuencia, al llamarlo al componente foo, obtenemos lo que el componente foo representa, esto es una barra, si hacemos la inmersión nuevamente, obtendremos, de hecho, el diseño que el componente de la barra nos devuelve. Esto solo será una prueba de integración.

O puede renderizar todo a la vez utilizando el método de montaje, que implementa la representación DOM completa. Pero no aconsejo hacer esto, porque será una instantánea muy difícil. Y, como regla, no es necesario que verifique toda la estructura por completo. Solo necesita verificar la integración entre el componente primario y secundario en cada caso.

Y para MyComponent agregamos una prueba de integración, por lo que en la primera prueba agrego solo dive, y resulta que probamos no solo la lógica del componente en sí, sino también su integración con el componente foo. Lo mismo, agregamos la prueba de integración para el componente foo que llama correctamente el componente de barra, y luego verificamos toda esta cadena, y estamos seguros de que ningún cambio nos interrumpirá, de hecho, la representación de MyComponent

Otro ejemplo, ya de un proyecto real. Solo brevemente sobre qué más pueden hacer Jest y Enzyme. Jest puede hacer moki. Puede, si usa alguna función externa en su componente, puede bloquearla. Por ejemplo, en este ejemplo, llamamos a algún tipo de API, por supuesto, no queremos ir a ninguna API en la prueba unitaria, por lo que simplemente borramos la función getResource con algún objeto jest.fn. De hecho, la función simulada. Luego podemos verificar si se llamó o no, cuántas veces se llamó y con qué argumentos. Todo esto te permite hacer bromas.

En el renderizado superficial, puede pasar la tienda a un componente. Si necesita una tienda, simplemente puede transferirla allí y funcionará.

También puede cambiar el estado y el accesorio en un componente ya renderizado.

Puede llamar al método de simulación en algún componente. Simplemente llama al manejador. Por ejemplo, si simula hacer clic, llamará a onClick para el componente del botón aquí. Todo esto se puede leer, por supuesto, en la documentación sobre Enzyme, muchas piezas útiles. Estos son solo algunos ejemplos de un proyecto real.

Alexey:
- Llegamos a la pregunta más interesante. Podemos probar Jest, podemos escribir pruebas unitarias, verificar componentes, verificar qué elementos responden incorrectamente a un clic. Podemos verificar su html. Ahora necesitamos verificar el diseño del componente, css.

Y es aconsejable hacer esto para que el principio de prueba no difiera de ninguna manera del que describí anteriormente. Si reviso html, llamé renderizado superficial, me tomó y me mostró html. Quiero verificar css, solo llamar a algún tipo de render y simplemente verificar, sin subir nada, sin configurar ninguna herramienta.

Comencé a buscarlo, y en casi todas partes se dio la misma respuesta a todo esto llamado Titiritero, o grilla de selenio. Abre alguna pestaña, va a una página html, toma una captura de pantalla y la compara con la opción anterior. Si no ha cambiado, entonces todo está bien.
La pregunta es, ¿qué es la página html si solo quiero verificar un componente de forma aislada? Es deseable, en diferentes condiciones.

No quiero escribir un montón de estas páginas html para cada componente, para cada estado. Avito tiene una buena racha. Roma Dvornov publicó un artículo sobre Habré, y él, por cierto, tuvo un discurso. ¿Qué hicieron ellos? Toman componentes, ensamblan html a través de un render estándar. Luego, con la ayuda de complementos y todo tipo de trucos, recopilan todos los activos que tienen: imágenes, css. Insértelo todo en html y obtendrán el html correcto.

Y luego levantaron un servidor especial, enviaron html allí, lo renderiza y devuelve algún resultado. Un artículo muy interesante, lea, sin embargo, puede extraer muchas ideas interesantes a partir de ahí.

Lo que no me gusta allí. Ensamblar un componente es diferente de cómo va a la producción. Por ejemplo, tenemos webpack, y allí será recolectado por algún tipo de activos de babel, allí se extrae de manera diferente. No puedo garantizar que probé lo que voy a descargar ahora.
Y de nuevo, un servicio separado para capturas de pantalla. Quiero hacerlo de alguna manera más fácil. Y, de hecho, existía la idea de que, vamos a recogerlo exactamente igual que lo haremos. Y trate de usar algo como Docker, porque es tal cosa, se puede poner en una computadora, localmente, será simple, aislado, no tocará nada, todo está bien.

Pero este problema es con la página html, sigue siendo lo que realmente es. Y nació una idea. Tiene un webpack.conf simplificado, y de él hay algo de EntryPoint para el cliente js. Se describen los módulos, cómo ensamblarlos, el archivo de salida, todos los complementos que ha descrito, todo está configurado, todo está bien.

¿Qué pasa si me gusta esto? Él entrará en mi componente y lo recogerá de forma aislada. Y habrá exactamente un componente. Si agrego html webpack allí, también me dará html, y estos activos se recopilarán allí, y esto, sin embargo, ya puede probarse automáticamente.
Y estaba a punto de escribir todo esto, pero luego encontré esto.

Jest-titiritero-React, un complemento joven. Y comencé a contribuir activamente a ello. Si de repente quieres probarlo, puedes, por ejemplo, venir a mí, de alguna manera puedo ayudarte. El proyecto, de hecho, no es mío.
Escribe un archivo normal como test.js, y estos archivos deben escribirse un poco por separado para ayudar a encontrarlos, a fin de no compilar todo el proyecto por usted, sino compilar solo los componentes necesarios. De hecho, tomas la configuración del paquete web. Y los puntos de entrada cambian a estos archivos browser.js, es decir, exactamente lo que queremos probar se empaquetará en html, y con la ayuda de Puppeteer le tomará capturas de pantalla.

Que puede hacer el? , jest-image-snapshot. . , , js, media-query, , .
headless-, , , , , headless-, Chrome . web-, , , , .
Docker. . . , Docker, . . Docker , , , Linux, - , - . Docker , .

? , . , . before-after, , . , . , Chrome, Firefox. .
. pixelmatch. , looksame, «», . , .

— . , , . , : - , — Enzyme. Redux store . . viewport, , . , , .

. , . ? , .

: 5-10 . Selenium . , , , . .

Puppeteer, e2e-. , e2e- — , Selenium.
:
— , Selenium Java , . - JS Puppeteer, , .
, . , , .

— Selenium Java, — JS Puppeteer. . 18 . , , Java. , , Java Selenium.

:
— ? . , html-, css . e2e. Genial , .

, , . . , , — , . , . - , , : , .
, , . git hook, -, . green master — , , , . Gracias