
Nosotros en JSOC CERT estamos investigando incidentes. En general, las 170 personas en JSOC están investigando, pero los casos tecnológicamente más desafiantes caen en manos de expertos del CERT. ¿Cómo, por ejemplo, detectar rastros de un malware si un atacante limpió? ¿Cómo encontrar un "asistente" que eliminó documentos comerciales importantes de un servidor de archivos en el que el registro no está configurado correctamente? Bueno, para el postre: ¿cómo puede un atacante obtener contraseñas de docenas de cuentas de dominio no relacionadas sin penetrar en la red? Detalles, como siempre, debajo del corte.
Entre semana JSOC CERT
A menudo tenemos que evaluar el compromiso real de la red del cliente, para esto llevamos a cabo:
- análisis retrospectivo de discos duros e imágenes de memoria,
- ingeniería inversa de malware
- si es necesario, despliegue de emergencia de monitoreo y escaneo de hosts en busca de indicadores de compromiso y rastros de piratería.
En nuestro tiempo libre, escribimos resúmenes detallados, técnicas y libros de jugadas, esencialmente instrucciones que ayudan a escalar incluso investigaciones complejas, como puedes actuar sobre ellos de forma semiautomática.
A veces, durante la respuesta al incidente, justo en medio de la extinción de un "incendio", también debe actuar como un "servicio de apoyo psicológico". Una vez fuimos invitados a ayudar a contrarrestar la infección de la subred de una gran organización. La red fue atendida por dos contratistas que, en esta situación, se
arrojaron desinteresadamente
a un ventilador y se involucraron en cualquier otra cosa, pero no buscaron un gusano malicioso. Para reducir el grado de histeria, tuve que sentarme a todos en la mesa
para obtener una toalla y una botella de bourbon y explicar claramente que ahora no es el momento de buscar al culpable. Determinaron el procedimiento de distribución, lanzaron una auditoría adicional y comenzaron a limpiar sistemáticamente la infección juntos y juntos.
Durante la investigación, a menudo tenemos que elegir imágenes de disco y memoria para encontrar malware activo allí. Para hacer que el proceso sea predecible y objetivo, formalizamos y automatizamos varios métodos para el análisis de disco retrospectivo, y tomamos como base el método
SANS ya clásico: en la versión original es de alto nivel, pero si se usa correctamente permite la detección de infección activa con una precisión muy alta.

Está claro que realizar comprobaciones generales requiere tiempo y un profundo conocimiento experto sobre las características de los diversos componentes de los sistemas operativos (y el software especializado necesita mucho).
¿Cómo simplificar la comprobación de una infección activa en un disco? Compartimos el truco de la vida: puede verificarse dinámicamente (como en el sandbox), para esto:
- copie el disco duro del host sospechoso poco a poco;
- convierte la imagen dd resultante al formato VMDK usando esta utilidad;
- ejecute la imagen VMDK en Virtual Box / VMware;
- y analizar como un sistema vivo, centrándose en el tráfico.
Pero siempre habrá incidentes para los que no se escriben instrucciones detalladas y las técnicas no están automatizadas.Caso 1. El contador no tiene nada que ver con eso, o cómo buscamos malware
El cliente nos pidió que revisáramos la computadora del contador en busca de malware: alguien hizo varias órdenes de pago a una dirección desconocida. El contador afirmó que no estaba involucrado en esto y que la computadora se había comportado de manera extraña antes: el mouse a veces literalmente se movía alrededor de la pantalla; de hecho, se nos pidió que verificaramos estas indicaciones. El problema fue que el troyano dirigido a 1C hizo sus trucos sucios y se aclaró, y después de que la infección pasó casi un mes, durante este tiempo, el diligente enikeyschik puso un montón de software, frotando el espacio en disco no asignado y minimizando así la probabilidad de éxito en la investigación.
En tales casos, solo un analista experimentado y meticuloso y una base de datos de inteligencia de amenazas extensa y actualizada automáticamente pueden ayudar. Entonces, durante el escaneo de la carpeta de inicio, una etiqueta sospechosa atrajo la atención indicando una supuesta utilidad de actualización antivirus:

Desafortunadamente, la carcasa del troyano desde el disco no se pudo restaurar, pero los hechos de iniciar la utilidad de administración remota desde la misma carpeta "hicieron alarde" en el caché
Superfetch :

Comparándolos con el momento del incidente, demostramos que no era el contador el culpable de robar el dinero, sino un atacante externo.
Caso 2. ¿Quién borró mis archivos?
La mayoría de nuestras investigaciones y respuestas a incidentes están de alguna manera relacionadas con la detección de malware, ataques dirigidos utilizando utilidades de múltiples módulos e historias similares donde hay un atacante externo. Sin embargo, a veces hay investigaciones mucho más mundanas, pero no menos interesantes.
El cliente tenía el servidor de archivos antiguo más común, cuyas carpetas públicas eran accesibles para varios departamentos. En el servidor hay muchos documentos comerciales muy importantes que alguien tomó y eliminó. Nos dimos cuenta tarde, después de que la copia de seguridad se sobrecargó. Comenzaron a buscar al culpable.
Si alguna vez trató de buscar en Google cómo determinar qué usuario eliminó el archivo, es probable que haya encontrado consejos que aparecen en los registros de Windows, si los configura correctamente de antemano (por cierto, ya le dimos un
par de consejos sobre cómo configurar registros):
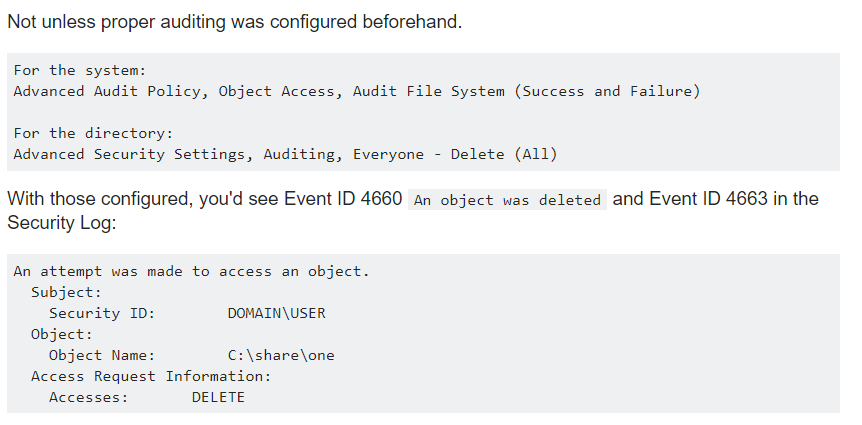 Fuente
FuentePero en realidad, pocas personas realizan auditorías del sistema de archivos, cursi porque hay muchas operaciones de archivos y los registros se deshilacharán rápidamente, y se necesita un servidor separado para almacenar los registros ...
Decidimos dividir la tarea en dos: primero, determinar CUÁNDO se eliminaron los archivos; segundo, - La OMS se estaba conectando al servidor en el momento de la eliminación. Si tiene una idea de las características de NTFS, entonces sabe que en la mayoría de las implementaciones de este sistema de archivos, cuando elimina un archivo, el espacio que ocupaba se marca como libre y sus marcas de tiempo no cambian. Por lo tanto, a primera vista, no se puede establecer el tiempo de eliminación.
Sin embargo, el sistema de archivos contiene no solo archivos, sino también carpetas. Además, las carpetas tienen un atributo especial $ INDEX_ROOT, que describe el contenido de la carpeta como un árbol B. Naturalmente, eliminar un archivo cambia el atributo $ INDEX_ROOT de la carpeta y, por lo tanto, cambia sus marcas de tiempo, en particular, en la estructura de $ STD_INFO. Por lo tanto, es posible determinar el tiempo aproximado para eliminar una gran cantidad de archivos y carpetas por anomalía en la
MFT (tabla de archivos principal) :

Después de saber cuándo se eliminaron aproximadamente los archivos, puede intentar averiguar quién estaba trabajando en el norte en ese momento para reducir el círculo de sospechosos. Me vienen a la mente los siguientes métodos:
- Por los registros del servidor mismo: por eventos con EventID 4624/4625, es visible cuando el usuario se conecta y desconecta;
- por registros de controlador de dominio: EventID 4768 le permite determinar que un usuario específico ha solicitado acceso al servidor;
- por tráfico (netflow / registros de enrutador interno) puede averiguar quién se comunicó activamente a través de la red con este servidor a través de smb.
En nuestro caso, estos datos ya no estaban allí: había pasado demasiado tiempo, los registros giraban. En este caso, hay otro no muy confiable, pero sigue siendo un método, o más bien la clave de registro:
Shellbags . Almacena información, en particular, sobre qué tipo de carpeta la última vez que el usuario la visitó: tabla, lista, iconos grandes, iconos pequeños, contenidos, etc. Y la misma clave contiene marcas de tiempo, que pueden interpretarse con gran confianza como el momento de la última visita a la carpeta.
Se encontró un método, lo único que quedaba era recopilar los registros de los hosts necesarios y analizarlos. Para hacer esto, necesitas:
- determinar por grupo de dominio quién tuvo acceso a la carpeta (en nuestro caso, había aproximadamente 300 usuarios);
- recopilar registros de todos los hosts en los que trabajaron estos usuarios (simplemente no puede hacer esto, necesita una utilidad especial para trabajar con la unidad directamente, por ejemplo, https://github.com/jschicht/RawCopy );
- "Alimente" todos los registros en Autopsia y use el complemento Shellbags;
- Beneficio!

Específicamente, en este incidente, el momento de eliminar archivos coincidió con el momento en que un usuario visitó la raíz de la carpeta eliminada, lo que nos permitió reducir el círculo de sospechosos de 300 a 1.
Lo que sucedió después con este empleado: la historia es silenciosa. Solo sabemos que la niña confesó que lo hizo por accidente y continúa trabajando en la empresa.
Caso 3. Contraseña maestra: "robar" en un par de segundos (e incluso más rápido)
Un atacante ingresó a la red de un cliente que nos pidió ayuda a través de una VPN y fue detectado de inmediato. Lo que no es sorprendente, porque justo después de ingresar, comenzó a escanear la subred con un escáner de vulnerabilidades: el chanipot parpadeó como un árbol de Navidad.
Después de que se bloqueó la cuenta, el personal de seguridad del cliente comenzó a analizar los registros de VPN y vio que el atacante había usado más de 20 cuentas de dominio diferentes para penetración (con la mayoría, inició sesión con éxito, pero para algunos la autenticación falló). Y surgió la pregunta lógica: ¿cómo descubrió las contraseñas de estas cuentas? Nuestros muchachos de JSOC CERT fueron invitados a buscar la respuesta.
En uno de los
artículos anteriores, ya hemos dicho que en las investigaciones las hipótesis deben formarse y verificarse a medida que disminuye su probabilidad. Así lo hicimos esta vez, comenzando a describir los típicos vectores de robo de cuentas:
- fuga de datos del servicio externo
- Fuerza bruta
- Mimikatz o similar
- Keylogger
- Suplantación de identidad
- NTLM-hash harvesting (por ejemplo, https://github.com/CylanceSPEAR/SMBTrap ) o ataques de red similares.
Verificamos un montón de versiones, pero en ninguna parte hubo ni siquiera un indicio de un ataque. No es que la investigación estuviera en un punto muerto, pero la voz interior y el sentido común sugirieron que algo andaba mal: debes dar un paso atrás y mirar la imagen más ampliamente.
De hecho, a primera vista, todas estas cuentas no están conectadas de ninguna manera. Sus propietarios son de diferentes departamentos separados geográficamente. Usualmente usan un conjunto no superpuesto de servicios de la compañía. Incluso el nivel de alfabetización en TI es diferente. Sí, un paso atrás no fue suficiente, se necesitaba uno más.
En este momento, logramos recolectar una gran cantidad de registros de diferentes sistemas de la empresa e identificar las huellas dejadas por el atacante. Comenzaron a analizar dónde apareció (recuerdo: escaneó activamente la red interna de la compañía). Notamos que en el contexto de un ruido de red distribuido uniformemente debido a exploits voladores, hay un número anormalmente grande de solicitudes al servicio de recuperación de contraseña. Un servicio accesible desde Internet. Hmm ...
Si está monitoreando eventos de seguridad, probablemente sepa que analizar los intentos de atacar un servidor accesible externamente a menudo no tiene sentido debido al ruido de Internet: generalmente es difícil distinguir ataques realmente serios de numerosos intentos de script kiddie. Pero no siempre


Después de pasar algún tiempo revisando los registros del servicio web, pudimos destacar los siguientes ataques al servicio:
- Escanear con Acunetix
- Escaneo SQLmap
- Un gran número de solicitudes a una página.
El tercer ataque, a primera vista, es similar a los inicios de sesión de usuarios brutales. Pero esto no es así, porque el servicio está protegido de esto, al menos por el hecho de que las contraseñas se almacenan en forma hash con sal, ¿o no? Era necesario verificarlo rápidamente.
La siguiente imagen muestra un esquema típico del servicio de restablecimiento de contraseña:
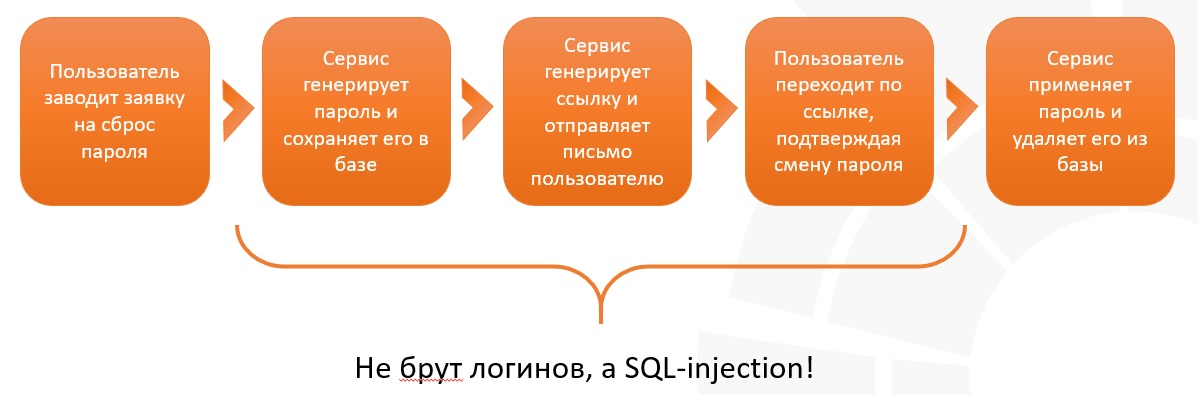
Es interesante porque las contraseñas no siempre se almacenan de forma segura, hay un momento en el que están en el dominio público, ¡inmediatamente después de que se abre la aplicación y antes de su ejecución! Una gran cantidad de consultas a una página resultó no ser fuerza bruta y no escaneo, sino consultas de alta frecuencia con inyección SQL, cuyo propósito era extraer contraseñas en el momento de su cambio.
Entonces, después de modelar el ataque al servicio, comparar la información de los registros del servidor web, los registros de cambio de contraseña y varios dispositivos de red, aún encontramos el punto de penetración del atacante en la empresa.
Entonces, colegas, profundicen en datos sin procesar y que la fuerza los acompañe.
