Hace algún tiempo, en una discusión sobre uno de los lanzamientos de SObjectizer, nos preguntaron: "¿Es posible hacer un DSL para describir una tubería de procesamiento de datos?" En otras palabras, ¿es posible escribir algo así?
A | B | C | D
y obtenga un canal de trabajo donde los mensajes van de A a B, y luego a C, y luego a D. Con control, B recibe exactamente ese tipo que A devuelve. Y C recibe exactamente ese tipo que B devuelve. Y así sucesivamente.
Fue una tarea interesante con una solución sorprendentemente simple. Por ejemplo, así es como puede verse la creación de una tubería:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
O, en un caso más complejo (que se discutirá a continuación):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
En este artículo, hablaremos sobre la implementación de dicha tubería DSL. Analizaremos principalmente partes relacionadas con las funciones stage() , broadcast() y operator|() con varios ejemplos de uso de plantillas C ++. Así que espero que sea interesante incluso para los lectores que no conocen SObjectizer (si nunca ha oído hablar de SObjectizer aquí hay una descripción general de esta herramienta).
Un par de palabras sobre la demostración utilizada
El ejemplo utilizado en el artículo ha sido influenciado por mi experiencia antigua (y más bien olvidada) en el área SCADA.
La idea de la demostración es el manejo de datos leídos desde algún sensor. Los datos se obtienen de un sensor con cierto período, luego esos datos deben validarse (los datos incorrectos deben ignorarse) y convertirse en algunos valores reales. Por ejemplo, los datos sin procesar leídos de un sensor pueden ser dos valores enteros de 8 bits y esos valores deben convertirse en un número de punto flotante.
Luego, los valores válidos y convertidos deben archivarse, distribuirse en algún lugar (en diferentes nodos para visualización, por ejemplo), comprobarse si hay "alarmas" (si los valores están fuera de los rangos seguros, entonces eso debería manejarse especialmente). Estas operaciones son independientes y se pueden realizar en paralelo.
Las operaciones relacionadas con la alarma detectada también se pueden realizar en paralelo: se debe iniciar una "alarma" (para que la parte de SCADA en el nodo actual pueda reaccionar sobre ella) y la información sobre la "alarma" se debe distribuir en otros lugares (por ejemplo : almacenado en una base de datos histórica y / o visualizado en la pantalla del operador SCADA).
Esta lógica se puede expresar en forma de texto de esa manera:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
O, en forma gráfica:

Es un ejemplo bastante artificial, pero tiene algunas cosas interesantes que quiero mostrar. El primero es la presencia de etapas paralelas en una tubería (la operación broadcast() existe solo por eso). El segundo es la presencia de un estado en algunas etapas. Por ejemplo, alarm_detector es una etapa con estado.
Capacidades de tubería
Una tubería se construye desde etapas separadas. Cada etapa es una función o un functor del siguiente formato:
opt<Out> func(const In &);
o
void func(const In &);
Las etapas que devuelven void solo se pueden usar como la última etapa de una tubería.
Las etapas están unidas en una cadena. Cada etapa siguiente recibe un objeto devuelto por la etapa anterior. Si la etapa anterior devuelve el valor opt<Out> vacío, entonces no se llama a la siguiente etapa.
Hay una etapa especial de broadcast . Está construido a partir de varias tuberías. Una etapa de broadcast recibe un objeto de la etapa anterior y lo transmite a todas las canalizaciones subsidiarias.
Desde el punto de vista de la canalización, la etapa de broadcast ve como una función del siguiente formato:
void func(const In &);
Debido a que no hay un valor de retorno de la etapa de broadcast una etapa de broadcast solo puede ser la última etapa de una canalización.
¿Por qué la etapa de canalización devuelve un valor opcional?
Es porque es necesario eliminar algunos valores entrantes. Por ejemplo, la etapa de validate no devuelve nada si un valor bruto es incorrecto y no tiene sentido manejarlo.
Otro ejemplo: la etapa alarm_detector no devuelve nada si el valor sospechoso actual no produce un nuevo caso de alarma.
Detalles de implementación
Comencemos por los tipos de datos y las funciones relacionadas con la lógica de la aplicación. En el ejemplo discutido, los siguientes tipos de datos se utilizan para pasar información de una etapa a otra:
Una instancia de raw_value va a la primera etapa de nuestra canalización. Este raw_value contiene información adquirida de un sensor en forma de objeto raw_measure . Entonces raw_value se transforma en valid_raw_value . Entonces valid_raw_value transformó en sensor_value con el valor real de un sensor en forma de calulated_measure . Si una instancia de sensor_value contiene un valor sospechoso, se genera una instancia de suspicious_value . Y ese valor suspicious_value puede transformarse en alarm_detected instancia alarm_detected por la alarm_detected más tarde.
O, en forma gráfica:

Ahora podemos echar un vistazo a la implementación de nuestras etapas de canalización:
Simplemente omita cosas como stage_result_t , make_result y make_empty , lo discutiremos en la siguiente sección.
Espero que el código de esas etapas sea bastante trivial. La única parte que requiere una explicación adicional es la implementación de la etapa alarm_detector .
En ese ejemplo, una alarma se inicia solo si hay al menos dos valores suspicious_values en una ventana de tiempo de 25 ms. Así que tenemos que recordar la hora de la instancia anterior de suspicious_value en la etapa alarm_detector . Esto se debe a que alarm_detector se implementa como un functor con estado con un operador de llamada de función.
Las etapas devuelven el tipo de SObjectizer en lugar de std :: opcional
Dije anteriormente que la etapa podría devolver un valor opcional. Pero std::optional no se usa en el código, el tipo diferente stage_result_t se puede ver en la implementación de etapas.
Es porque algunos de los específicos de SObjectizer juegan su papel aquí. Los valores devueltos se distribuirán como mensajes entre los agentes de SObjectizer (también conocidos como actores). Cada mensaje en SObjectizer se envía como un objeto asignado dinámicamente. Entonces tenemos algún tipo de "optimización" aquí: en lugar de devolver std::optional y luego asignar un nuevo objeto de mensaje, simplemente asignamos un objeto de mensaje y le devolvemos un puntero inteligente.
De hecho, stage_result_t es solo un typedef para el análogo shared_ptr de SObjectizer:
template< typename M > using stage_result_t = message_holder_t< M >;
Y make_result y make_empty son solo funciones auxiliares para construir stage_result_t con o sin un valor real dentro:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
Por simplicidad, es seguro decir que la etapa de validation podría expresarse de esa manera:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
Pero, debido al SObjectizer específico, no podemos usar std::shared_ptr y tenemos que tratar con el tipo so_5::message_holder_t . Y stage_result_t ese específico detrás de los stage_result_t , make_result y make_empty .
separación de stage_handler_t y stage_builder_t
Un punto importante de la implementación de la canalización es la separación de los conceptos de controlador de etapa y generador de etapa . Esto se hace por simplicidad. La presencia de estos conceptos me permitió tener dos pasos en la definición de la tubería.
En el primer paso, un usuario describe las etapas de la canalización. Como resultado, recibo una instancia de stage_t que contiene todas las etapas de canalización en su interior.
En el segundo paso, se crea un conjunto de agentes SObjectizer subyacentes. Esos agentes reciben mensajes con resultados de las etapas anteriores y llaman a los controladores de etapas reales, luego envían los resultados a las siguientes etapas.
Pero para crear este conjunto de agentes, cada etapa debe tener un generador de etapas . El generador de escenarios puede verse como una fábrica que crea un agente SObjectizer subyacente.
Por lo tanto, tenemos la siguiente relación: cada etapa de canalización produce dos objetos: el controlador de etapa que contiene la lógica relacionada con la etapa y el generador de etapas que crea un agente SObjectizer subyacente para llamar al controlador de etapa en el momento apropiado:

El controlador de escenario se representa de la siguiente manera:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
Donde handler_traits_t se definen de la siguiente manera:
El generador de etapas está representado simplemente por std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
Tipos de ayuda lambda_traits_t y callable_traits_t
Debido a que las etapas se pueden representar mediante funciones libres o functores (como instancias de la clase alarm_detector o clases anónimas generadas por el compilador que representan lambdas), necesitamos algunos ayudantes para detectar los tipos de argumento de la etapa y el valor de retorno. Usé el siguiente código para ese propósito:
Espero que este código sea bastante comprensible para los lectores con buenos conocimientos de C ++. Si no, no dude en preguntarme en los comentarios, me complacerá explicar la lógica detrás de lambda_traits_t y lambda_traits_t en detalles.
funciones stage (), broadcast () y operator | ()
Ahora podemos mirar dentro de las funciones principales de construcción de tuberías. Pero antes de eso, es necesario echar un vistazo a la definición de una clase de plantilla stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
Es una estructura muy simple que contiene solo la instancia stage_bulder_t . Los parámetros de plantilla no se usan dentro de stage_t , entonces ¿por qué están presentes aquí?
Son necesarios para la verificación en tiempo de compilación de la compatibilidad de tipos entre etapas de canalización. Lo veremos pronto.
Veamos la función más simple de construcción de tuberías, la stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Recibe un controlador de etapa real como un solo parámetro. Puede ser un puntero a una función o función lambda o functor. Los tipos de entrada y salida de la etapa se deducen automáticamente debido a la "plantilla mágica" detrás de la plantilla callable_traits_t .
Dentro se crea una instancia del creador de etapas y esa instancia se devuelve en un nuevo objeto stage_t como resultado de la función stage() . El generador de escenarios lambda captura un controlador de etapa real, que luego se utilizará para la construcción de un agente SObjectizer subyacente (hablaremos de eso en la siguiente sección).
La siguiente función para revisar es el operator|() que concatena dos etapas juntas y devuelve una nueva etapa:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
La forma más sencilla de explicar la lógica del operator|() es intentar dibujar una imagen. Supongamos que tenemos la expresión:
stage(A) | stage(B) | stage(C) | stage(B)
Esta expresión se transformará de esa manera:

Allí también podemos ver cómo funciona la verificación de tipos en tiempo de compilación: la definición de operator|() requiere que el tipo de salida de la primera etapa sea la entrada de la segunda etapa. Si este no es el caso, el código no se compilará.
Y ahora podemos echar un vistazo a la función de construcción de tuberías más compleja, broadcast() . La función en sí es bastante simple:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
La principal diferencia entre una etapa ordinaria y una etapa de transmisión es que la etapa de transmisión tiene que contener un vector de constructores de etapas subsidiarias. Así que tenemos que crear ese vector y pasarlo al generador de escenario principal de broadcast-stage. Por eso, podemos ver una llamada a collect_sink_builders en una lista de captura de lambda dentro de la función broadcast() :
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
Si buscamos en collect_sink_builder , veremos el siguiente código:
La verificación de tipos en tiempo de compilación también funciona aquí: es porque una llamada a move_sink_builder_to se parametriza explícitamente por tipo 'In'. Significa que una llamada en la forma collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) conducirá a un error de compilación porque el compilador prohíbe una llamada move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) .
También puedo notar que debido a que se conoce el recuento de canalizaciones subsidiarias para broadcast() en tiempo de compilación, podemos usar std::array lugar de std::vector y podemos evitar algunas asignaciones de memoria. Pero std::vector se usa aquí solo por simplicidad.
Relación entre etapas y agentes / mboxes de SObjectizer
La idea detrás de la implementación de la tubería es la creación de un agente separado para cada etapa de la tubería. Un agente recibe un mensaje entrante, lo pasa al controlador de etapa correspondiente, analiza el resultado y, si el resultado no está vacío, envía el resultado como un mensaje entrante a la siguiente etapa. Se puede ilustrar con el siguiente diagrama de secuencia:

Algunas cosas relacionadas con SObjectizer tienen que ser discutidas, al menos brevemente. Si no tiene interés en tales detalles, puede omitir las secciones a continuación e ir directamente a la conclusión.
Coop es un grupo de agentes para trabajar juntos.
Los agentes se introducen en SObjectizer no individualmente sino en grupos llamados cooperativas. Una cooperativa es un grupo de agentes que deberían trabajar juntos y no tiene sentido continuar el trabajo si falta uno de los agentes del grupo.
Entonces, la introducción de agentes en SObjectizer se parece a la creación de una instancia de cooperativa, llenando esa instancia con los agentes apropiados y luego registrando la cooperativa en SObjectizer.
Debido a eso, el primer argumento para un generador de escenarios es una referencia a una nueva cooperativa. Esta cooperativa se crea en la función make_pipeline() (que se analiza a continuación), luego se completa con los creadores de etapas y luego se registra (nuevamente en la función make_pipeline() ).
Cuadros de mensaje
SObjectizer implementa varios modelos relacionados con la concurrencia. El modelo de actor es solo uno de ellos. Por eso, SObjectizer puede diferir significativamente de los marcos de otros actores. Una de las diferencias es el esquema de direccionamiento para mensajes.
Los mensajes en SObjectizer están dirigidos no a actores, sino a cuadros de mensajes (mboxes). Los actores tienen que suscribirse a los mensajes de un mbox. Si un actor se suscribe a un tipo de mensaje en particular desde un mbox, recibirá mensajes de ese tipo:
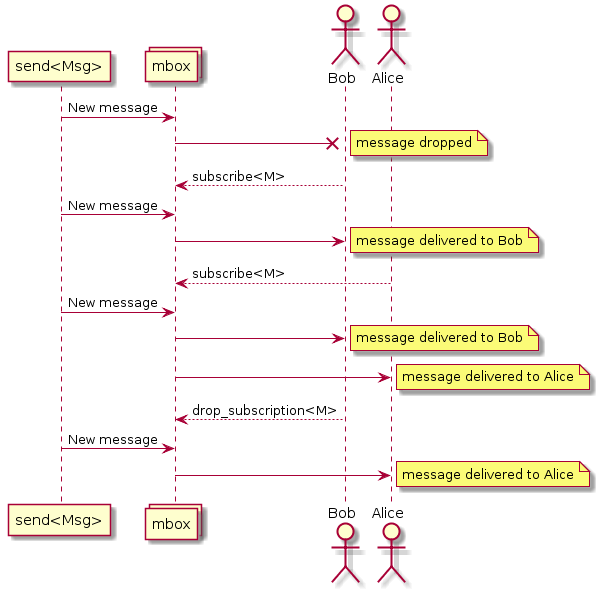
Este hecho es crucial porque es necesario enviar mensajes de una etapa a otra. Significa que cada etapa debe tener su mbox y que mbox debe ser conocido para la etapa anterior.
Cada actor (también conocido como agente) en SObjectizer tiene el mbox directo . Este mbox está asociado solo con el agente propietario y no puede ser utilizado por ningún otro agente. Los mboxes directos de agentes creados para etapas se usarán para la interacción de etapas.
La característica específica de este SObjectizer dicta algunos detalles de implementación de canalización.
El primero es el hecho de que el creador de escenarios tiene el siguiente prototipo:
mbox_t builder(coop_t &, mbox_t);
Significa que el generador de etapas recibe un mbox de la siguiente etapa y debe crear un nuevo agente que enviará los resultados de la etapa a ese mbox. El generador de etapas debe devolver un mbox del nuevo agente. Ese mbox se usará para la creación de un agente para la etapa anterior.
El segundo es el hecho de que los agentes para etapas se crean en orden de reserva. Significa que si tenemos una tubería:
stage(A) | stage(B) | stage(C)
Primero se creará un agente para la etapa C, luego se usará su mbox para la creación de un agente para la etapa B, y luego se usará mbox del agente de la etapa B para la creación de un agente para la etapa A.
También vale la pena señalar que el operator|() no crea agentes:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
El operator|() crea un constructor que solo llama a otros constructores pero no introduce agentes adicionales. Entonces para el caso:
stage(A) | stage(B)
solo se crearán dos agentes (para la etapa A y la etapa B) y luego se vincularán en el generador de etapas creado por el operator|() .
No hay agente para la implementación de broadcast()
Una forma obvia de implementar una etapa de transmisión es crear un agente especial que reciba un mensaje entrante y luego reenvíe ese mensaje a una lista de mboxes de destino. Esa forma se utilizó en la primera implementación de la tubería DSL descrita.
Pero nuestro proyecto complementario, so5extra , ahora tiene una variante especial de mbox: transmitir uno. Ese mbox hace exactamente lo que se requiere aquí: toma un nuevo mensaje y lo entrega a un conjunto de mboxes de destino.
Debido a que no hay necesidad de crear un agente de transmisión por separado, solo podemos usar la transmisión de mbox desde so5extra:
Implementación de agente de escena
Ahora podemos echar un vistazo a la implementación del agente de escenario:
Es bastante trivial si comprende los conceptos básicos de SObjectizer. Si no, será bastante difícil de explicar en pocas palabras (así que siéntase libre de hacer preguntas en los comentarios).
La implementación principal del agente a_stage_point_t crea una suscripción a un mensaje de tipo In. Cuando llega un mensaje de este tipo, se llama al controlador de la etapa . Si el controlador de la etapa devuelve un resultado real, el resultado se envía a la siguiente etapa (si esa etapa existe).
También hay una versión de a_stage_point_t para el caso en que la etapa correspondiente es la etapa terminal y no puede haber la siguiente etapa.
La implementación de a_stage_point_t puede parecer un poco complicada, pero créeme, es uno de los agentes más simples que he escrito.
función make_pipeline ()
Es hora de discutir la última función de construcción de tuberías, make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
No hay magia ni sorpresas aquí. Solo necesitamos crear una nueva cooperativa para los agentes subyacentes de la tubería, llenar esa cooperativa con agentes llamando a un generador de etapas de nivel superior y luego registrar esa cooperativa en SObjectizer. Que todo
El resultado de make_pipeline() es el mbox de la etapa más a la izquierda (la primera) de la tubería. Ese mbox debe usarse para enviar mensajes a la canalización.
La simulación y los experimentos con ella.
Entonces, ahora tenemos tipos de datos y funciones para nuestra lógica de aplicación y las herramientas para encadenar esas funciones en una tubería de procesamiento de datos. Hagámoslo y veamos un resultado:
int main() {
Si ejecutamos ese ejemplo, veremos el siguiente resultado:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
Funciona
Pero parece que las etapas de nuestra tubería funcionan secuencialmente, una tras otra, ¿no?
Si lo es. Esto se debe a que todos los agentes de canalización están vinculados al distribuidor predeterminado de SObjectizer. Y ese despachador usa solo un subproceso de trabajo para servir el procesamiento de mensajes de todos los agentes.
Pero esto se puede cambiar fácilmente. Simplemente pase un argumento adicional a make_pipeline() call:
Esto crea un nuevo grupo de subprocesos y vincula a todos los agentes de canalización a ese grupo. Cada grupo será atendido por el grupo independientemente de otros agentes.
Si ejecutamos el ejemplo modificado, podemos ver algo así:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
Entonces podemos ver que las diferentes etapas de la tubería funcionan en paralelo.
¿Pero es posible ir más allá y tener la capacidad de vincular etapas a diferentes despachadores?
Sí, es posible, pero tenemos que implementar otra sobrecarga para la función stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Esta versión de stage() acepta no solo un controlador de escenario sino también una carpeta de despachador. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository .