
Imagine que discutió con un amigo lo que sucedió antes: una
gallina o un huevo, algún aumento de impuestos, por ejemplo, o noticias sobre este tema, o un evento importante que ahogó por completo una nube de noticias sobre una nueva canción, por ejemplo, Kirkorov. Sería conveniente calcular la cantidad de noticias sobre cada tema en un momento dado y luego visualizarlo. En realidad, esto es de lo que trata el proyecto "Runet News Radar". Debajo del corte, le diremos qué tiene que ver el aprendizaje automático y cómo cualquier voluntario puede participar en esto.
Referencia rápida
Machine Learning for Social Good (ML4SG) es una iniciativa dentro de la comunidad ODS destinada a crear las condiciones para los proyectos, como su nombre indica, que utilizan el aprendizaje automático para aportar algún beneficio a la sociedad. La creación de condiciones aquí se refiere principalmente a los recursos de la organización. Se parece a esto: alguien formula la idea del proyecto y alienta a los voluntarios, mientras que alguien simplemente se une al proyecto, en aras de una idea, experiencia u otros intereses. Todo se basa en el entusiasmo, más a menudo en el tiempo libre del trabajo principal. El radar de noticias Runet, o como lo llamamos brevemente en el equipo de noticias, es uno de los proyectos dentro del ML4SG.
Descargo de responsabilidad
En algunas ilustraciones de este artículo, se mencionarán algunos eventos políticos o personas. Vamos a dejar opiniones sobre ellos a nosotros mismos. Habr no es para la política.
Que hacemos
En pocas palabras sobre la motivación
Ahora el proyecto se posiciona como una herramienta para analizar los medios en su conjunto. Si existe alguna hipótesis acerca de cómo se desarrolló la atención en las noticias sobre diversos temas, eventos, personas, etc., entonces podemos hablar sobre la base de números específicos, no de especulaciones.
La idea inicial era esta: tomamos todos los datos de noticias que encontramos, aplicamos modelos temáticos, presentamos los resultados a tiempo y dibujamos el resultado.
¿Qué es el modelado temático?Definición de machinelearning.ru:
Un modelo de tema es una colección de documentos de texto que determina a qué temas pertenece cada documento de colección. El algoritmo para construir un modelo temático recibe una colección de documentos de texto en la entrada. El resultado de cada documento es un vector numérico compuesto por estimaciones del grado de pertenencia de este documento a cada uno de los temas. La dimensión de este vector, igual al número de temas, puede establecerse en la entrada o puede determinarse automáticamente por el modelo.
Más detalles
aquí .
Está claro que esto requiere las noticias en sí, y las descargamos. Y dado que tendremos un gran cuerpo de noticias, puede hacer muchas cosas más interesantes, sin limitarse a temas. Pero teniendo en cuenta las condiciones reales, de las que hablaremos, a saber, que la multitud de voluntarios, y no un equipo bien trabajado de especialistas remunerados, implementará el proyecto, al principio todavía resolvemos el problema casi sin cambios.

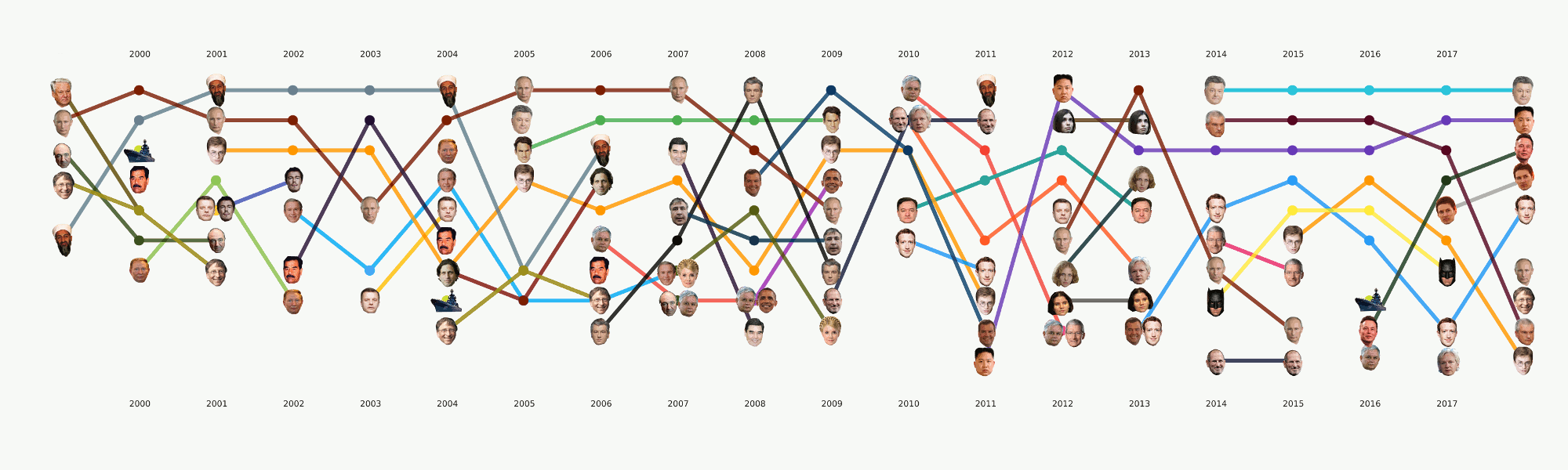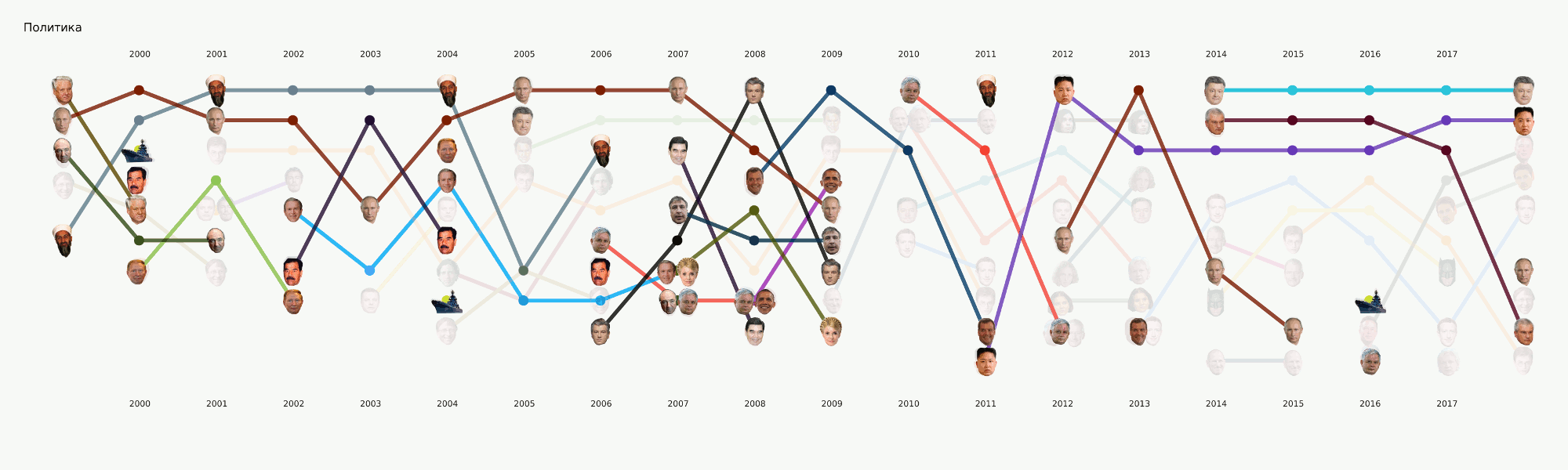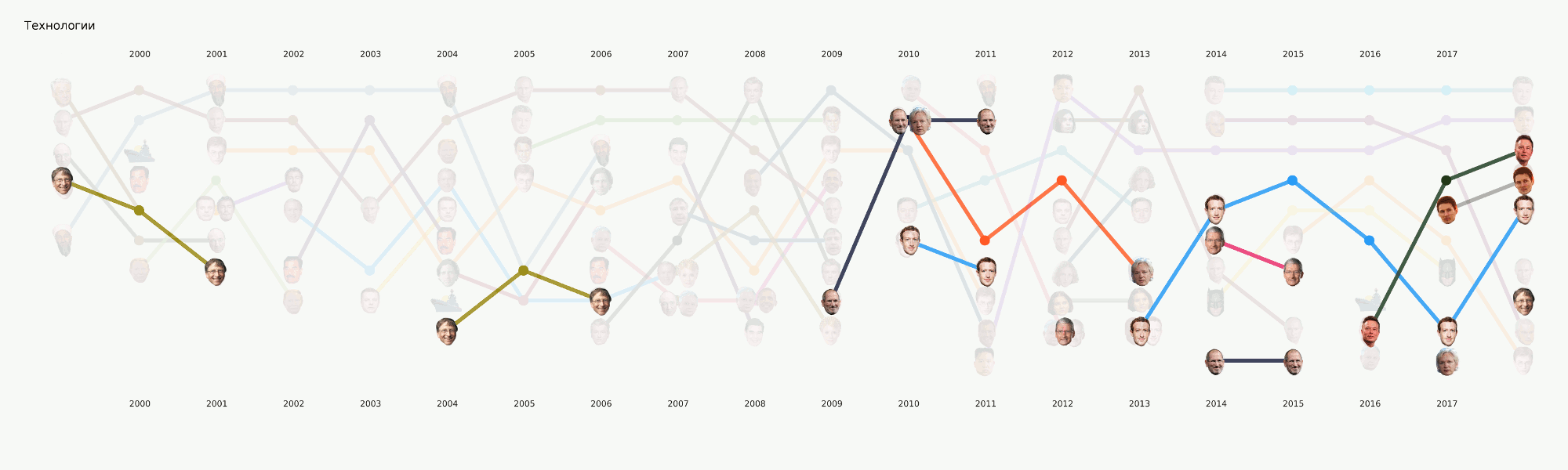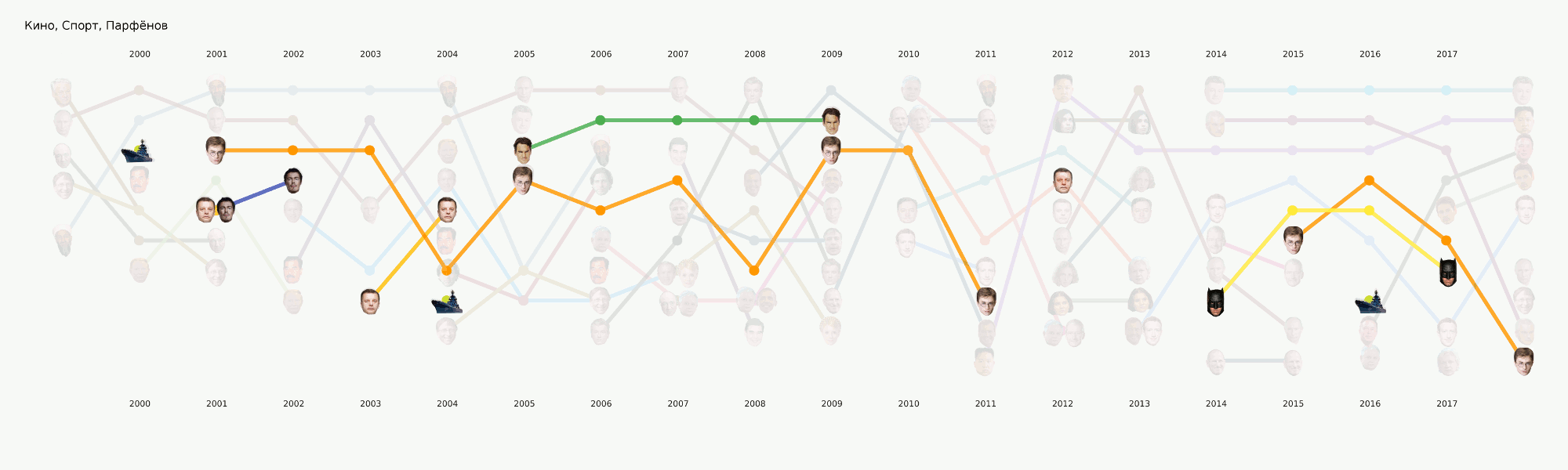
Ahora hemos llegado a este formato de visualización, se llama diagrama de cresta. En la diapositiva, por cierto, estos temas son una pantalla de una demostración interna antigua. Es decir, aquí tenemos tiempo en el eje de abscisas, el grosor de la tira es proporcional a cuánto está representado el tema en ese momento entre otras noticias. En este caso, agregación por mes.
En el plan básico, tenemos la opción de elegir una fuente de noticias y elegir cómo mostrar un gráfico. También puede seleccionar datos adicionales no de las noticias, por ejemplo, cómo se comportó el precio del petróleo o cualquier otro indicador en ese momento en el mismo período de tiempo. La elección de encabezados y un conjunto de temas en él. Además de esto, hay muchas más ideas, pero más sobre eso más adelante.
Proyectos similares
Existen muchos otros proyectos relacionados con la visualización de noticias. Me gustan
estos dos . El primero compara cómo se presentan las mismas noticias en diferentes fuentes y, al mismo tiempo, una muy buena forma de presentación e interactividad. El segundo simplemente tiene una muy buena relación de información a simplicidad. Compara cuánto se dice sobre las diferentes causas de muerte en las noticias, con qué frecuencia se mencionan las causas de muerte en las consultas de búsqueda y cómo es estadísticamente. Bueno, en las conclusiones sobre cómo se sobreestima catastróficamente el terrorismo y cómo se subestiman las enfermedades cardíacas y el cáncer.
Como lo hacemos
El proyecto es bastante sencillo. Primero descargamos los datos, luego los procesamos, hacemos cualquier aprendizaje automático y dibujamos gráficos. Luego hacemos un sitio web, y todos observan. Todo está claro (bueno, sí, por supuesto).

Recogida de datos
Para empezar, tuvimos un conjunto de datos de cinta ru durante 20 años. Básicamente, hicimos todos los experimentos al respecto. Ahora hemos recopilado varias fuentes más y continuamos recolectando todo lo que alcanzamos. Hay muchos materiales detallados sobre raspado y arañas, por lo que no nos detendremos en este tema aquí en detalle.
Nlp
Estaba más preocupado por la parte de PNL, porque es difícil formalizar los requisitos para el resultado de la temática. Además, hay muchas subtareas secundarias. Ahora hemos realizado bastantes experimentos con diferentes herramientas para el modelado temático, antes de eso nos deshicimos del preprocesamiento, hicimos muchos puntos de referencia y comparaciones. Por el momento, bigARTM resultó ser el líder indiscutible en temas en términos de recursos y calidad. Ahora esta es nuestra opción de trabajo, hasta que alguien muestre algo mejor.
En general, todo el aprendizaje automático se concentra principalmente en esta sección. Además de la tarea principal del tema originalmente establecida, hay muchos otros que también traerán conclusiones interesantes. Por ejemplo, NER. Ya hemos sacado todos los nombres de los datos que tenemos, diccionarios compilados, contados a quienes mencionamos muchas veces. Resultó, por ejemplo, que sobre Poroshenko en Lente.ru durante todo el tiempo escribieron cuatro veces más que sobre Putin. Me resultó interesante que Assange vaya sincrónicamente con Magnitsky, y todo esto exactamente después de que Bush se fue. Pero Batman es más popular que Medvedev.
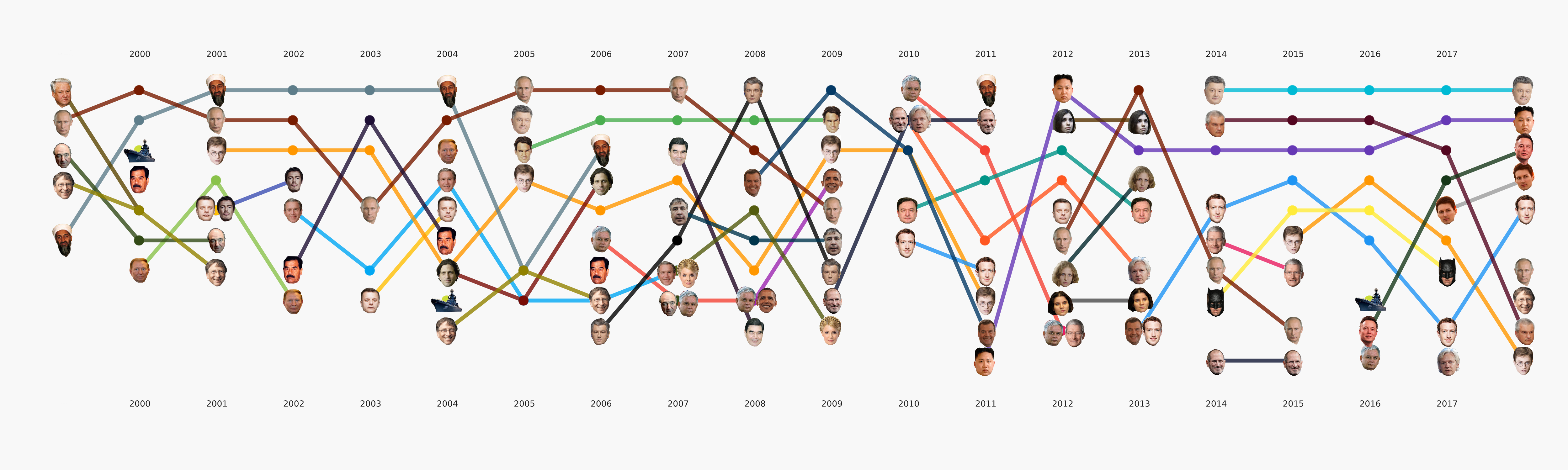

Animación desglosada en categorías.Este es un tipo de avance para nuestros próximos artículos, donde hablaremos con más detalle sobre cómo resultó esta imagen y qué conclusiones se pueden sacar de ella.
Aunque esta etapa aún está en proceso, hemos realizado una gran cantidad de experimentos y comparado muchas herramientas y enfoques. En el proceso, un gran tutorial sobre varias tareas de PNL con ejemplos de código y puntos de referencia de las herramientas más populares e inusuales.
Visualización
Esta etapa no parecía demasiado complicada, pero por alguna razón casi nadie estaba listo para enfrentarla. Los requisitos de visualización van un poco más allá del enfoque EDA habitual en datasense. Dibujar un gráfico para usted u otro centro de datos es mucho más fácil que dibujar un gráfico para el público en general. Estuvimos ocupados con formatos y herramientas durante mucho tiempo y ahora hemos llegado a algunos enfoques que parecen más razonables, pero todavía hay mucho trabajo por delante, ya que prácticamente no hay herramientas listas para nuestras tareas. Por ejemplo, el gráfico con las caras anteriores se realizó en dos etapas: los elementos principales se generaron en el código y luego se realizó una larga etapa de redibujo manual para que al menos se leyera algo. En términos de un análisis detallado de esta visualización en un artículo separado, refleja en cierta medida la historia de Rusia en los últimos 20 años.
El equipo
Es condicionalmente posible dividir a los participantes en dos grupos: principiantes y profesionales. Para los principiantes, la motivación es simple: poner en una alcancía algún tipo de proyecto para mostrar a los empleadores, o simplemente adquirir experiencia, aprender algo. Y ya me informaron que las diferentes cosas que hicimos en el marco del proyecto fueron útiles en el trabajo de los participantes, apreciaron las autoridades. Los profesionales vienen por el objetivo mismo del proyecto, porque están interesados en unirse a la idea o porque quieren probar algunas de sus ideas en las noticias.
De hecho, hay otro grupo de participantes: estos son los esquivos ninjas que encajan y no hacen nada o simplemente comienzan y luego desaparecen. Pero como ya expliqué, nadie trabaja en el proyecto por dinero, por lo que la desorganización de los recursos humanos es inevitable. La observación desde el lado de la curiosidad también es posible.

Ahora formalmente hay alrededor de 80 personas, de las cuales aproximadamente 10-20 están activas y 2-4 personas están activas casi constantemente. En este formato, puede compensar la falta de experiencia con el tiempo. Mucha gente escribe que no se sabe cómo hacerlo, existe el temor de fracasar debido a la ineptitud, pero de hecho es importante hacerlo y no esperar un momento. Porque ml4sg es una actividad muy buena. Puede traer beneficios y al mismo tiempo obtener ganancias en forma de experiencia y cartera, mientras que el riesgo es solo tiempo, el gerente también tiene una reputación, por supuesto, pero el principal recurso aquí es el tiempo, que finalmente vale la pena.
Planes adicionales
Ahora estoy tratando de posicionarlo como una herramienta de investigación. Planeamos agregar una búsqueda "exploratoria", que puede evaluar el tema de la solicitud y proporcionar estadísticas sobre las noticias de este tema, gráficos de varios datos que no son noticias, pero relevantes para el tema del proyecto. Entonces será posible probar todo tipo de hipótesis sobre cómo se comportan los medios, cómo se relacionan los eventos y otros indicadores arbitrarios, sociales o económicos. Tal herramienta para investigar los medios en su conjunto.
¿Quién necesita un proyecto?
- Tenemos muy pocas personas involucradas en la visualización. Vamos más allá de las herramientas habituales de datacenterism como matplotlib o plotly, por lo que necesitamos personas que realmente amen la visualización de datos y quieran profundizar en ella.
- Necesitamos personas que entiendan algo en el desarrollo web.
- Necesitamos personas que nos digan qué buscar. De hecho, deberían ser nuestros clientes los que estén interesados en realizar un estudio y llegar al fondo de algunas cosas sobre cómo los medios en ruso han cambiado últimamente.
- Siempre necesitamos especialistas en PNL, creo que no hay necesidad de explicarlo aquí. Y hay algo que hacer para aquellos que quieren aprender y para los muchachos experimentados, ya que hay muchos problemas interesantes en esta área.
- Y, por supuesto, tenemos que construir un proyecto decente para que todo no funcione en cinta aislante, por lo que si estás metido en la arquitectura de los proyectos, puedes volver a ensamblar un montón de experimentos en una sola tubería y estar listo para compartir tu experiencia, entonces siéntete libre de hacerlo. Si quieres aprender sobre la marcha, entonces bienvenido también.