
Hola lectores de Habr! En un artículo anterior, hablamos sobre una herramienta simple de tolerancia a desastres en los sistemas de almacenamiento AERODISK ENGINE, sobre la replicación. En este artículo, profundizaremos en un tema más complejo e interesante: el clúster metropolitano, es decir, un medio de protección automatizada ante desastres para dos centros de datos, que permite a los centros de datos trabajar en modo activo-activo. Lo diremos, mostraremos, romperemos y arreglaremos.
Como siempre, al principio de la teoría.
Un grupo de metro es un grupo dividido en varios sitios dentro de una ciudad o distrito. La palabra "clúster" nos sugiere claramente que el complejo está automatizado, es decir, el cambio de nodos del clúster en caso de fallas se produce automáticamente.
Aquí es donde radica la principal diferencia entre el clúster metropolitano y la replicación ordinaria. Automatización de operaciones. Es decir, en el caso de ciertos incidentes (falla del centro de datos, canales rotos, etc.), el sistema de almacenamiento realizará independientemente las acciones necesarias para mantener la disponibilidad de datos. Cuando se utilizan réplicas regulares, el administrador realiza estas acciones completa o parcialmente de forma manual.
¿Para qué es esto?
El objetivo principal que los clientes persiguen utilizando una u otra implementación del clúster de metro es minimizar el RTO (Objetivo del tiempo de recuperación). Es decir, minimice el tiempo de recuperación de los servicios de TI después de una falla. Si usa la replicación normal, el tiempo de recuperación siempre será más largo que el tiempo de recuperación con el clúster metro. Por qué Muy simple El administrador debe estar en el lugar de trabajo y cambiar la replicación a mano, y el clúster de metro lo hace automáticamente.
Si no tiene un administrador dedicado de guardia que no duerma, coma, fume o se enferme y observe el estado de almacenamiento las 24 horas del día, no hay forma de garantizar que el administrador estará disponible para el cambio manual durante una falla.
En consecuencia, RTO en ausencia de un grupo de metro o administrador inmortal nivel 99 El servicio en servicio del administrador será igual a la suma del tiempo de conmutación de todos los sistemas y el período máximo de tiempo después del cual se garantiza que el administrador comenzará a trabajar con los sistemas de almacenamiento y sistemas relacionados.
Por lo tanto, llegamos a la conclusión obvia de que el clúster metropolitano debe usarse si el requerimiento de RTO es minutos, no horas o días, es decir, cuando el departamento de TI debe proporcionar a las empresas tiempo para restablecer el acceso a TI en el caso de la peor caída del centro de datos -servicios en minutos, o incluso segundos.
Como funciona
En el nivel inferior, el clúster metropolitano utiliza el mecanismo de replicación de datos síncronos, que describimos en un artículo anterior (ver enlace ). Como la replicación es sincrónica, los requisitos para ella son apropiados, o más bien:
- fibra como física, 10 gigabit Ethernet (o superior);
- la distancia entre los centros de datos no es más de 40 kilómetros;
- Retardo de canal óptico entre centros de datos (entre sistemas de almacenamiento) hasta 5 milisegundos (óptimamente 2).
Todos estos requisitos son de naturaleza consultiva, es decir, el clúster de metro funcionará incluso si no se cumplen estos requisitos, pero debe entenderse que las consecuencias del incumplimiento de estos requisitos son iguales a la desaceleración de ambos sistemas de almacenamiento en el clúster de metro.
Entonces, una réplica sincrónica se usa para transferir datos entre sistemas de almacenamiento, y cómo las réplicas se cambian automáticamente, y lo más importante, ¿cómo evitar el cerebro dividido? Para esto, en el nivel anterior, se utiliza una entidad adicional: el árbitro.
¿Cómo funciona el árbitro y cuál es su tarea?
El árbitro es una pequeña máquina virtual, o un clúster de hardware, que debe ejecutarse en la tercera plataforma (por ejemplo, en la oficina) y proporcionar acceso al almacenamiento a través de ICMP y SSH. Después del lanzamiento, el árbitro debe establecer la IP y luego, desde el lado del almacenamiento, indicar su dirección, más las direcciones de los controladores remotos que participan en el clúster metropolitano. Después de eso, el árbitro está listo para trabajar.
El árbitro supervisa constantemente todos los sistemas de almacenamiento en el clúster metropolitano y, si un sistema de almacenamiento no está disponible, después de confirmar que no está disponible desde otro miembro del clúster (uno de los sistemas de almacenamiento "en vivo"), toma la decisión de iniciar el procedimiento para cambiar las reglas de replicación y el mapeo.
Un punto muy importante. El árbitro siempre debe estar en un sitio diferente de aquellos en los que se encuentra el almacenamiento, es decir, ni en el centro de datos-1, donde se encuentra el almacenamiento 1, ni en el centro de datos-2, donde está instalado el almacenamiento 2.
Por qué Porque la única forma en que un árbitro con la ayuda de uno de los sistemas de almacenamiento sobrevivientes puede determinar de manera inequívoca y precisa la caída de cualquiera de los dos sitios donde están instalados los sistemas de almacenamiento. Cualquier otra forma de colocar un árbitro puede resultar en un cerebro dividido.
Ahora sumérgete en los detalles del árbitro
El árbitro ejecuta varios servicios que son interrogados constantemente por todos los controladores de almacenamiento. Si el resultado de la encuesta difiere del anterior (disponible / inaccesible), se registra en una pequeña base de datos, que también funciona como árbitro.
Considere la lógica del árbitro con más detalle.
Paso 1. Determinación de la inaccesibilidad. Una señal de evento sobre la falla del sistema de almacenamiento es la ausencia de ping de ambos controladores del mismo sistema de almacenamiento durante 5 segundos.
Paso 2. Inicie el procedimiento de cambio. Después de que el árbitro comprende que uno de los sistemas de almacenamiento no está disponible, envía una solicitud al sistema de almacenamiento "en vivo" para asegurarse de que el sistema de almacenamiento "muerto" realmente haya muerto.
Después de recibir dicha orden del árbitro, el segundo sistema de almacenamiento (en vivo) verifica adicionalmente la disponibilidad del primer sistema de almacenamiento caído y, si no es así, envía al árbitro la confirmación de sus conjeturas. El almacenamiento realmente no está disponible.
Después de recibir dicha confirmación, el árbitro inicia el procedimiento remoto para cambiar la replicación y elevar la asignación en aquellas réplicas que estaban activas (primarias) en el sistema de almacenamiento descartado, y envía un comando al segundo sistema de almacenamiento para que estas réplicas pasen de secundaria a primaria y aumenten la asignación. Bueno, el segundo sistema de almacenamiento, respectivamente, realiza estos procedimientos, después de lo cual proporciona acceso a los LUN perdidos de sí mismo.
¿Por qué necesito verificación adicional? Para quórum. Es decir, la mayoría del número impar total (3) de miembros del clúster debería confirmar la caída de uno de los nodos del clúster. Solo entonces esta decisión será correcta. Esto es necesario para evitar cambios erróneos y, en consecuencia, cerebro dividido.
El paso 2 en el tiempo toma aproximadamente 5 a 10 segundos, por lo tanto, teniendo en cuenta el tiempo requerido para determinar la inaccesibilidad (5 segundos), dentro de los 10 a 15 segundos después del accidente, los LUN con almacenamiento caído estarán disponibles automáticamente para trabajar con almacenamiento en vivo.
Está claro que para evitar desconectar los hosts, también debe cuidar la configuración correcta de los tiempos de espera en los hosts. El tiempo de espera recomendado es de al menos 30 segundos. Esto no permitirá que el host se desconecte del sistema de almacenamiento durante la transferencia de carga durante un accidente y podrá garantizar que no haya interrupción de la entrada-salida.
Resulta que solo un segundo, si todo está bien con el clúster de metro, ¿por qué necesita una replicación regular?
De hecho, no todo es tan simple.
Considere los pros y los contras del clúster de metro
Entonces, nos dimos cuenta de que las ventajas obvias del clúster metro en comparación con la replicación convencional son:
- Automatización completa que proporciona un tiempo de recuperación mínimo en caso de desastre;
- Y eso es todo :-).
Y ahora, atención, contras:
- El costo de la decisión. Aunque el clúster metropolitano en los sistemas Aerodisk no requiere licencias adicionales (se usa la misma licencia que para la réplica), el costo de la solución seguirá siendo mayor que el uso de la replicación sincrónica. Será necesario implementar todos los requisitos para la réplica síncrona, más los requisitos para el clúster metropolitano relacionados con la conmutación adicional y el sitio adicional (consulte la planificación del clúster metropolitano);
- La complejidad de la decisión. El clúster metropolitano es mucho más complejo que una réplica normal y requiere mucha más atención y trabajo para la planificación, configuración y documentación.
Al final Metro cluster es, por supuesto, una solución muy tecnológica y buena cuando realmente necesita proporcionar RTO en segundos o minutos. Pero si no existe tal tarea, y RTO en horas está bien para el negocio, entonces no tiene sentido disparar gorriones desde el cañón. La replicación habitual de los trabajadores y campesinos es suficiente, porque el clúster de metro incurrirá en costos adicionales y complicará la infraestructura de TI.
Planificación de clúster de metro
Esta sección no pretende ser una guía completa para el diseño del clúster metropolitano, sino que solo muestra las instrucciones principales que deben elaborarse si decide construir dicho sistema. Por lo tanto, con la implementación real del clúster metro, asegúrese de involucrar al fabricante de los sistemas de almacenamiento (es decir, nosotros) y otros sistemas relacionados para consultas.
Plataformas
Como se indicó anteriormente, se requieren un mínimo de tres sitios para un clúster de metro. Dos centros de datos, donde funcionarán los sistemas de almacenamiento y sistemas relacionados, así como una tercera plataforma donde trabajará el árbitro.
La distancia recomendada entre los centros de datos no es más de 40 kilómetros. Es muy probable que distancias más grandes causen demoras adicionales, que en el caso de un grupo de metro son altamente indeseables. Recuerde, los retrasos deben ser de hasta 5 milisegundos, aunque es deseable cumplir con 2.
También se recomienda verificar las demoras durante el proceso de planificación. Cualquier proveedor más o menos adulto que proporciona fibra entre los centros de datos, un control de calidad puede organizarse con bastante rapidez.
En cuanto a las demoras ante el árbitro (es decir, entre la tercera plataforma y las dos primeras), el umbral de demora recomendado es de hasta 200 milisegundos, es decir, es adecuada una conexión VPN corporativa regular a través de Internet.
Conmutación y redes
A diferencia de un esquema de replicación, donde es suficiente para interconectar sistemas de almacenamiento de diferentes sitios, un esquema con un clúster metropolitano requiere conectar hosts con ambos sistemas de almacenamiento en diferentes sitios. Para aclarar cuál es la diferencia, ambos esquemas se enumeran a continuación.
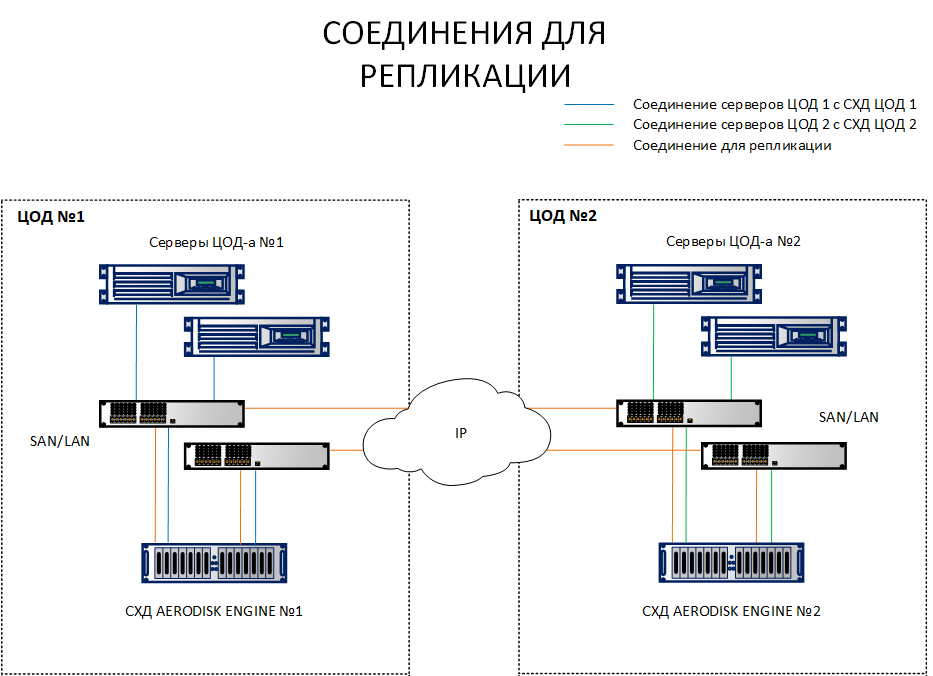

Como puede ver en el diagrama, los hosts en el sitio 1 están mirando tanto SHD1 como SHD 2. Además, por el contrario, los hosts de la plataforma 2 están mirando SHD 2 y SHD1. Es decir, cada host ve ambos sistemas de almacenamiento. Este es un requisito previo para el funcionamiento del clúster de metro.
Por supuesto, no es necesario tirar de cada host con un cable óptico a un centro de datos diferente, no habrá suficientes puertos y cordones. Todas estas conexiones deben realizarse a través de conmutadores Ethernet 10G + o FibreChannel 8G + (FC solo para conectar hosts y almacenamiento para IO, el canal de replicación actualmente solo está disponible a través de IP (Ethernet 10G +).
Ahora algunas palabras sobre la topología de la red. Un punto importante es la configuración correcta de las subredes. Debe identificar inmediatamente varias subredes para los siguientes tipos de tráfico:
- La subred para la replicación sobre la cual se sincronizarán los datos entre los sistemas de almacenamiento. Puede haber varios, en este caso no importa, todo depende de la topología de red actual (ya implementada). Si hay dos de ellos, entonces obviamente el enrutamiento entre ellos debe configurarse;
- Subredes de almacenamiento a través de las cuales los hosts accederán a los recursos de almacenamiento (si es iSCSI). Debe haber una de esas subredes en cada centro de datos;
- Controle las subredes, es decir, tres subredes enrutables en tres sitios desde los que se realiza la gestión de almacenamiento, y también hay un árbitro.
No consideramos subredes para acceder a los recursos del host aquí, ya que dependen mucho de las tareas.
La separación de tráfico diferente en subredes diferentes es extremadamente importante (es especialmente importante separar la réplica de E / S), porque si mezcla todo el tráfico en una subred "gruesa", este tráfico será imposible de administrar, y en las condiciones de dos centros de datos aún puede causar diferentes opciones de colisión de red. No profundizaremos mucho en este tema en el marco de este artículo, ya que puede leer sobre la planificación de una red extendida entre centros de datos sobre los recursos de los fabricantes de equipos de red, donde se describe con gran detalle.
Configuración de árbitro
El árbitro debe proporcionar acceso a todas las interfaces de administración de almacenamiento a través de los protocolos ICMP y SSH. También debe considerar la tolerancia a fallas del árbitro. Hay un matiz.
La tolerancia a fallos del árbitro es muy deseable, pero opcional. ¿Y qué pasa si el árbitro se estrella en el momento equivocado?
- El funcionamiento del clúster metro en modo normal no cambiará porque arbtir no afecta el funcionamiento del clúster metropolitano en modo normal de ninguna manera (su tarea es cambiar oportunamente la carga entre los centros de datos)
- Además, si el árbitro por una razón u otra cae y "despierta" el accidente en el centro de datos, entonces no ocurrirá ningún cambio, porque no habrá nadie para dar los comandos necesarios para cambiar y organizar un quórum. En este caso, el clúster metropolitano se convertirá en un esquema de replicación regular, que deberá cambiarse manualmente durante un desastre, que afectará a RTO.
¿Qué se sigue de esto? Si realmente necesita garantizar un RTO mínimo, debe garantizar la tolerancia a fallos del árbitro. Hay dos opciones para esto:
- Ejecute una máquina virtual con un árbitro en un hipervisor de conmutación por error, ya que todos los hipervisores adultos admiten la conmutación por error;
- Si está en el tercer sitio (en una oficina condicional)
pereza para poner un clúster normal Dado que no existe un clúster de hipervizor existente, hemos proporcionado una versión de hardware del árbitro, que se realiza en una caja de 2U, en la que funcionan dos servidores x-86 ordinarios y que pueden sobrevivir a una falla local.
Recomendamos encarecidamente que el árbitro sea tolerante a fallas a pesar de que el clúster metropolitano no lo necesita en modo normal. Pero tanto la teoría como la práctica muestran que si construyes una infraestructura verdaderamente confiable a prueba de desastres, entonces es mejor ir a lo seguro. Es mejor protegerse y proteger a su empresa de la "ley de la mezquindad", es decir, de la falla tanto del árbitro como de uno de los sitios donde se encuentra el sistema de almacenamiento.
Arquitectura de soluciones
Teniendo en cuenta los requisitos anteriores, obtenemos la siguiente arquitectura de solución general.

Los LUN deben distribuirse uniformemente en dos sitios para evitar una congestión intensa. Al mismo tiempo, al dimensionar en ambos centros de datos, es necesario colocar no solo un doble volumen (que es necesario para almacenar datos simultáneamente en dos sistemas de almacenamiento), sino también un doble rendimiento en IOPS y MB / s, para evitar la degradación de las aplicaciones en caso de falla de uno de los centros de datos: ov.
Por separado, observamos que con un enfoque adecuado para el dimensionamiento (es decir, siempre que hayamos proporcionado los límites superiores adecuados para IOPS y MB / s, así como los recursos necesarios de CPU y RAM), si uno de los sistemas de almacenamiento falla en el clúster metropolitano, no habrá una reducción seria en el rendimiento bajo trabajo temporal en un sistema de almacenamiento.
Esto se debe al hecho de que, en las condiciones de dos sitios simultáneamente, el trabajo de replicación sincrónica "consume" la mitad del rendimiento de escritura, ya que cada transacción debe escribirse en dos sistemas de almacenamiento (similar a RAID-1/10). Entonces, si uno de los sistemas de almacenamiento falla, el efecto de la replicación temporalmente (hasta que el sistema de almacenamiento con fallas aumente) desaparece, y obtenemos un aumento doble en el rendimiento de escritura. Después de que los LUN del sistema de almacenamiento fallido se reiniciaron en un sistema de almacenamiento en funcionamiento, este aumento doble desaparece debido a la carga de los LUN de otro sistema de almacenamiento, y volvemos al mismo nivel de rendimiento que teníamos antes de la "caída", pero solo dentro del marco de una plataforma.
Con la ayuda de un tamaño competente, es posible proporcionar condiciones bajo las cuales los usuarios no sentirán la falla de un sistema de almacenamiento completo. Pero, de nuevo, esto requiere un tamaño muy cuidadoso, por lo que, por cierto, puede contactarnos gratis :-).
Configuración de Metro Cluster
Configurar un clúster de metro es muy similar a configurar una replicación regular, que describimos en un artículo anterior . Por lo tanto, nos enfocamos solo en las diferencias. Configuramos un soporte basado en la arquitectura anterior en el laboratorio solo en la versión mínima: dos sistemas de almacenamiento conectados por Ethernet 10G entre sí, dos conmutadores 10G y un host que observa los 10 puertos de almacenamiento a través de los conmutadores en ambos sistemas de almacenamiento. El árbitro se ejecuta en una máquina virtual.

Al configurar IP virtuales (VIP) para una réplica, seleccione el tipo de VIP para el cluster de metro.

Creamos dos enlaces de replicación para dos LUN y los distribuimos en dos sistemas de almacenamiento: LUN TEST Primary para SHD1 (enlace METRO), LUN TEST2 Primary para SHD2 (enlace METRO2).

Para ellos, configuramos dos objetivos idénticos (en nuestro caso iSCSI, pero FC también es compatible, la lógica de configuración es la misma).
SHD1:

SHD2:

Para las conexiones de replicación, hicieron asignaciones en cada sistema de almacenamiento.
SHD1:

SHD2:

Multipath configurado y presentado al host.


Configurar el árbitro
No necesita hacer nada especial con el árbitro, solo debe habilitarlo en la tercera plataforma, configurar una IP y configurar el acceso a ella a través de ICMP y SSH. La configuración en sí se realiza desde los propios sistemas de almacenamiento. En este caso, es suficiente configurar el árbitro una vez en cualquiera de los controladores de almacenamiento en el clúster metro, esta configuración se distribuirá a todos los controladores automáticamente.
En la sección Replicación remota >> Metrocluster (en cualquier controlador) >> botón Configurar.
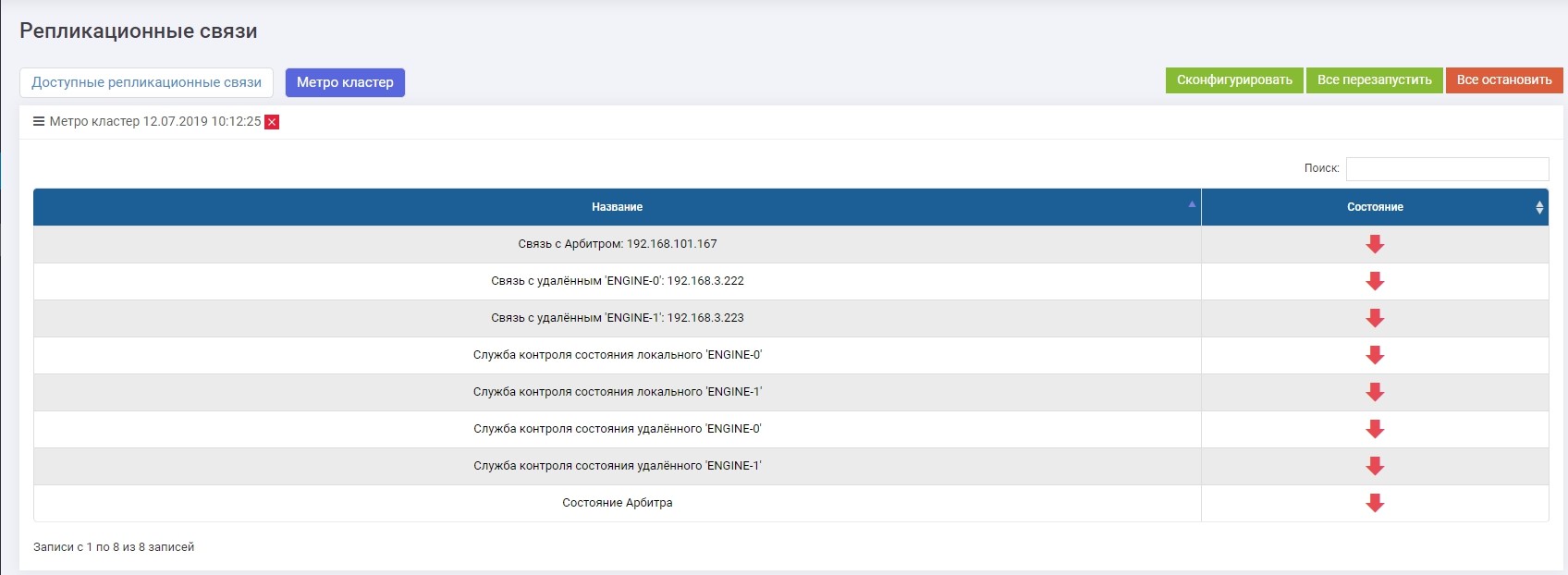
Introducimos la IP del árbitro, así como las interfaces de control de los dos controladores del sistema de almacenamiento remoto.

Después de eso, debe habilitar todos los servicios (el botón "Reiniciar todo"). En el caso de una reconfiguración en el futuro, los servicios deben reiniciarse para que la configuración surta efecto.

Verifique que todos los servicios se estén ejecutando.

Esto completa la configuración del clúster de metro.
Prueba de choque
La prueba de choque en nuestro caso será bastante simple y rápida, ya que la funcionalidad de replicación (cambio, consistencia, etc.) se consideró en un artículo anterior . Por lo tanto, para probar la confiabilidad de un clúster de metro, es suficiente para nosotros verificar la automatización de la detección de accidentes, la conmutación y la ausencia de pérdidas de registro (paradas de E / S).
Para hacer esto, emulamos la falla completa de uno de los sistemas de almacenamiento apagando físicamente sus dos controladores, comenzando una copia preliminar de un archivo grande en el LUN, que debe activarse en el otro sistema de almacenamiento.

Deshabilitar un almacenamiento. En el segundo sistema de almacenamiento, vemos alertas y mensajes en los registros de que la conexión con el sistema vecino ha desaparecido. Si ha configurado alertas para la supervisión SMTP o SNMP, el administrador recibirá las alertas correspondientes.

Exactamente 10 segundos después (visto en ambas capturas de pantalla), el enlace de replicación METRO (el que era Primario en el sistema de almacenamiento bloqueado) se convirtió automáticamente en Primario en el sistema de almacenamiento en ejecución. Usando el mapeo existente, LUN TEST permaneció disponible para el host, la grabación se hundió un poco (dentro del 10 por ciento prometido), pero no se interrumpió.


Prueba completada con éxito.
Para resumir
La implementación actual del metrocluster en los sistemas de almacenamiento de la serie N del motor AERODISK permite resolver por completo los problemas en los que es necesario eliminar o minimizar el tiempo de inactividad de los servicios de TI y garantizar su funcionamiento 24/7/365 con una mano de obra mínima.
, , , … , , . , , , .
, .