
Mi nombre es Eduard Tyantov, lidero el equipo de Computer Vision en Mail.ru Group. A lo largo de varios años de nuestra existencia, nuestro equipo ha resuelto docenas de problemas de visión por computadora, y hoy les contaré qué métodos usamos para crear con éxito modelos de aprendizaje automático que funcionan en una amplia gama de tareas. Compartiré trucos que pueden acelerar el modelo en todas las etapas: establecer una tarea, preparar datos, capacitación e implementación en producción.
Computer Vision en Mail.ru
Para empezar, qué es Computer Vision en Mail.ru y qué proyectos hacemos. Brindamos soluciones en nuestros productos, como Mail, Mail.ru Cloud (una aplicación para almacenar fotos y videos), Vision (soluciones B2B basadas en visión por computadora) y otras. Daré algunos ejemplos.
La nube (este es nuestro primer y principal cliente) tiene 60 mil millones de fotos. Desarrollamos varias características basadas en el aprendizaje automático para su procesamiento inteligente, por ejemplo, reconocimiento facial y visitas turísticas (
hay una publicación separada sobre esto ). Todas las fotos de los usuarios se ejecutan a través de modelos de reconocimiento, lo que le permite organizar una búsqueda y agrupación por personas, etiquetas, ciudades y países visitados, etc.
Para Mail, hicimos OCR: reconocimiento de texto de una imagen. Hoy te contaré un poco más sobre él.
Para los productos B2B, reconocemos y contamos a las personas en las colas. Por ejemplo, hay una cola para el remonte y debe calcular cuántas personas hay en él. Para empezar, para probar la tecnología y jugar, implementamos un prototipo en el comedor de la oficina. Hay varios mostradores de efectivo y, en consecuencia, varias colas, y nosotros, usando varias cámaras (una para cada una de las colas), usando el modelo, calculamos cuántas personas hay en las colas y cuántos minutos quedan aproximadamente en cada una de ellas. De esta manera podemos equilibrar mejor las líneas en el comedor.

Declaración del problema.
Comencemos con la parte crítica de cualquier tarea: su formulación. Casi cualquier desarrollo de ML lleva al menos un mes (esto es mejor cuando sabes qué hacer), y en la mayoría de los casos varios meses. Si la tarea es incorrecta o inexacta, al final del trabajo hay una gran posibilidad de escuchar del gerente de producto algo en el espíritu: “Todo está mal. Esto no es bueno Quería algo más ". Para evitar que esto suceda, debe seguir algunos pasos. ¿Qué tienen de especial los productos basados en ML? A diferencia de la tarea de desarrollar un sitio, la tarea de aprendizaje automático no se puede formalizar solo con texto. Además, como regla general, a una persona no preparada le parece que todo ya es obvio, y simplemente se requiere que haga todo "bellamente". Pero, ¿qué pequeños detalles hay? Es posible que el administrador de tareas ni siquiera lo sepa, nunca haya pensado en ellos y no piense hasta que vea el producto final y diga: "¿Qué has hecho?
Los problemas
Comprendamos con ejemplos qué problemas pueden ser. Supongamos que tiene una tarea de reconocimiento facial. Lo recibe, se regocija y llama a su madre: "¡Hurra, una tarea interesante!" Pero, ¿es posible romper directamente y comenzar a hacerlo? Si hace esto, al final puede esperar sorpresas:
- Hay diferentes nacionalidades. Por ejemplo, no había asiáticos ni nadie más en el conjunto de datos. Su modelo, en consecuencia, no sabe cómo reconocerlos en absoluto, y el producto lo necesita. O viceversa, pasó tres meses adicionales en la revisión, y el producto solo tendrá caucásicos, y esto no fue necesario.
- Hay niños Para los padres sin hijos como yo, todos los niños están en una sola cara. Estoy totalmente de acuerdo con el modelo, cuando ella envía a todos los niños a un grupo: ¡no está claro cómo difieren la mayoría de los niños! ;) Pero las personas que tienen hijos tienen una opinión completamente diferente. Por lo general, también son tus líderes. O todavía hay errores divertidos de reconocimiento cuando la cabeza del niño se compara con éxito con el codo o la cabeza de un hombre calvo (historia real).
- Qué hacer con los personajes pintados generalmente no está claro. ¿Necesito reconocerlos o no?
Tales aspectos de la tarea son muy importantes para identificar al principio. Por lo tanto, debe trabajar y comunicarse con el gerente desde el principio "sobre los datos". No se pueden aceptar explicaciones orales. Es necesario mirar los datos. Es deseable a partir de la misma distribución en la que funcionará el modelo.
Idealmente, en el proceso de esta discusión, se obtendrán algunos conjuntos de datos de prueba en los que finalmente puede ejecutar el modelo y verificar si funciona como el administrador quería. Es aconsejable entregar parte del conjunto de datos de prueba al administrador mismo, para que no tenga acceso a él. Como puedes volver a entrenar fácilmente en este conjunto de prueba, ¡eres un desarrollador de ML!
Establecer una tarea en ML es un trabajo constante entre un gerente de producto y un especialista en ML. Incluso si al principio establece bien la tarea, a medida que el modelo se desarrolle, aparecerán más y más problemas nuevos, nuevas características que aprenderá sobre sus datos. Todo esto debe discutirse constantemente con el gerente. Los buenos gerentes siempre transmiten a sus equipos de ML que deben asumir la responsabilidad y ayudar al gerente a establecer tareas.
Por qué El aprendizaje automático es un área bastante nueva. Los gerentes no tienen (o tienen poca) experiencia en la gestión de tales tareas. ¿Con qué frecuencia las personas aprenden a resolver nuevos problemas? Sobre los errores. Si no desea que su proyecto favorito se convierta en un error, debe involucrarse y asumir la responsabilidad, enseñar al gerente de producto a establecer la tarea correctamente, desarrollar listas de verificación y políticas; Todo esto ayuda mucho. Cada vez que salgo (o alguien de mis colegas me saca) cuando llega una nueva tarea interesante, y corremos para hacerlo. Todo lo que acabo de contarte, lo olvido yo mismo. Por lo tanto, es importante tener algún tipo de lista de verificación para comprobarlo usted mismo.
Datos
Los datos son súper importantes en ML. Para el aprendizaje profundo, cuantos más datos alimentes a los modelos, mejor. El gráfico azul muestra que, por lo general, los modelos de aprendizaje profundo mejoran enormemente cuando se agregan datos.
Y los algoritmos "antiguos" (clásicos) desde algún punto ya no pueden mejorar.
Por lo general, los conjuntos de datos de ML están sucios Fueron marcados por personas que siempre mienten. Los evaluadores a menudo son desatentos y cometen muchos errores. Utilizamos esta técnica: tomamos los datos que tenemos, entrenamos el modelo en ellos y luego, con la ayuda de este modelo, borramos los datos y repetimos el ciclo nuevamente.
Echemos un vistazo más de cerca al ejemplo del mismo reconocimiento facial. Digamos que descargamos avatares de usuario de VKontakte. Por ejemplo, tenemos un perfil de usuario con 4 avatares. Detectamos rostros que están en las 4 imágenes y ejecutamos el modelo de reconocimiento de rostros. Entonces obtenemos incrustaciones de personas, con la ayuda de las cuales pueden "pegar" personas similares en grupos (grupo). A continuación, seleccionamos el grupo más grande, suponiendo que los avatares del usuario contengan principalmente su cara. En consecuencia, podemos limpiar todas las otras caras (que son ruido) de esta manera. Después de eso, podemos repetir el ciclo nuevamente: en los datos limpiados, entrene el modelo y úselo para limpiar los datos. Puedes repetir varias veces.
Casi siempre para tales agrupamientos usamos algoritmos CLink. Este es un algoritmo de agrupamiento jerárquico en el que es muy conveniente establecer un valor umbral para "pegar" objetos similares (esto es exactamente lo que se requiere para la limpieza). CLink genera grupos esféricos. Esto es importante, ya que a menudo aprendemos el espacio métrico de estas incrustaciones. El algoritmo tiene una complejidad de O (n
2 ), que, en principio, es de aprox.
A veces, los datos son tan difíciles de obtener o marcar que no queda nada por hacer tan pronto como comience a generarlos. El enfoque generativo le permite producir una gran cantidad de datos. Pero para esto necesitas programar algo. El ejemplo más simple es OCR, reconocimiento de texto en imágenes. El marcado del texto para esta tarea es extremadamente costoso y ruidoso: debe resaltar cada línea y cada palabra, firmar el texto, etc. Los asesores (personas de marcado) ocuparán cien páginas de texto durante un tiempo extremadamente largo, y se necesita mucho más para la capacitación. Obviamente, de alguna manera puede generar el texto y de alguna manera "moverlo" para que el modelo aprenda de él.
Hemos descubierto por nosotros mismos que el mejor y más conveniente juego de herramientas para esta tarea es una combinación de PIL, OpenCV y Numpy. Tienen todo para trabajar con texto. Puede complicar la imagen con texto de cualquier manera para que la red no se vuelva a entrenar con ejemplos simples.

A veces necesitamos algunos objetos del mundo real. Por ejemplo, productos en los estantes de las tiendas. Una de estas imágenes se genera automáticamente. ¿Piensas izquierda o derecha?

De hecho, ambos se generan. Si no observa los pequeños detalles, no notará diferencias con la realidad. Hacemos esto usando Blender (análogo de 3dmax).
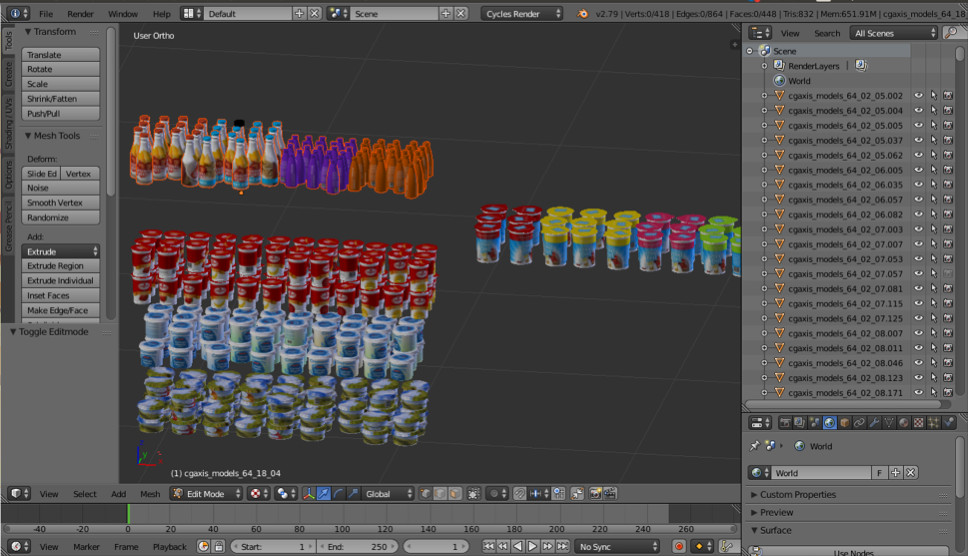
La principal ventaja importante es que es de código abierto. Tiene una excelente API de Python, que le permite colocar objetos directamente en el código, configurar y aleatorizar el proceso y finalmente obtener un conjunto de datos diverso.
Para el renderizado, se utiliza el trazado de rayos. Este es un procedimiento bastante costoso, pero produce un resultado con excelente calidad. La pregunta más importante: ¿dónde obtener modelos para objetos? Como regla, deben comprarse. Pero si eres un estudiante pobre y quieres experimentar con algo, siempre hay torrentes. Está claro que para la producción necesita comprar u ordenar modelos renderizados de alguien.
Eso es todo acerca de los datos. Pasemos al aprendizaje.
Aprendizaje métrico
El objetivo del aprendizaje métrico es capacitar a la red para que traduzca objetos similares en regiones similares en el espacio métrico incrustado. Volveré a dar un ejemplo con las vistas, lo cual es inusual porque en esencia es una tarea de clasificación, pero para decenas de miles de clases. Parecería, ¿por qué aquí el aprendizaje métrico, que, como regla, es apropiado en tareas como el reconocimiento facial? Tratemos de resolverlo.
Si usa pérdidas estándar cuando entrena un problema de clasificación, por ejemplo, Softmax, entonces las clases en el espacio métrico están bien separadas, pero en el espacio de inserción, los puntos de diferentes clases pueden estar cerca uno del otro ...

Esto crea posibles errores durante la generalización, ya que Una ligera diferencia en los datos de origen puede cambiar el resultado de la clasificación. Realmente nos gustaría que los puntos sean más compactos. Para esto, se utilizan varias técnicas de aprendizaje métrico. Por ejemplo, la pérdida del centro, cuya idea es extremadamente simple: simplemente juntamos puntos al centro de aprendizaje de cada clase, que eventualmente se vuelven más compactos.
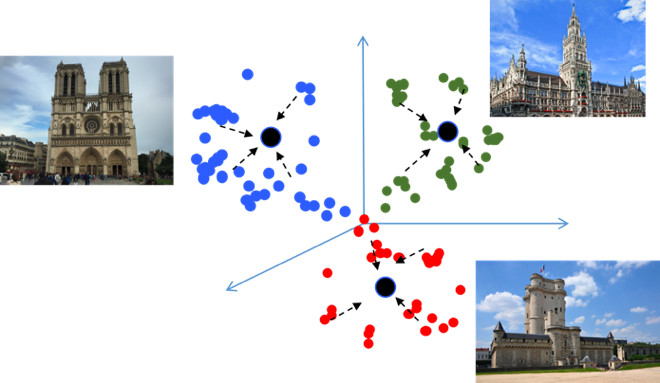
La pérdida central se programa literalmente en 10 líneas en Python, funciona muy rápidamente y, lo más importante, mejora la calidad de la clasificación, porque La compacidad conduce a una mejor capacidad de generalización.
Softmax angular
Probamos muchos métodos diferentes de aprendizaje métrico y llegamos a la conclusión de que Angular Softmax produce los mejores resultados. Entre la comunidad de investigación, también se le considera estado de la técnica.
Veamos un ejemplo de reconocimiento facial. Aquí tenemos dos personas. Si usa el Softmax estándar, se dibujará un plano divisorio entre ellos, basado en dos vectores de peso. Si hacemos la norma de incrustación 1, entonces los puntos se ubicarán en el círculo, es decir en la esfera en el caso n-dimensional (imagen a la derecha).
Entonces puede ver que el ángulo entre ellos ya es responsable de la separación de clases, y puede optimizarse. Pero eso no es suficiente. Si solo optimizamos el ángulo, la tarea no cambiará de hecho, porque simplemente lo reformulamos en otros términos. Recuerdo que nuestro objetivo es hacer que los grupos sean más compactos.
Es necesario de alguna manera exigir un ángulo mayor entre las clases, para complicar la tarea de la red neuronal. Por ejemplo, de tal manera que ella piensa que el ángulo entre los puntos de una clase es mayor que en la realidad, por lo que trata de comprimirlos cada vez más. Esto se logra al introducir el parámetro m, que controla la diferencia en los cosenos de los ángulos.
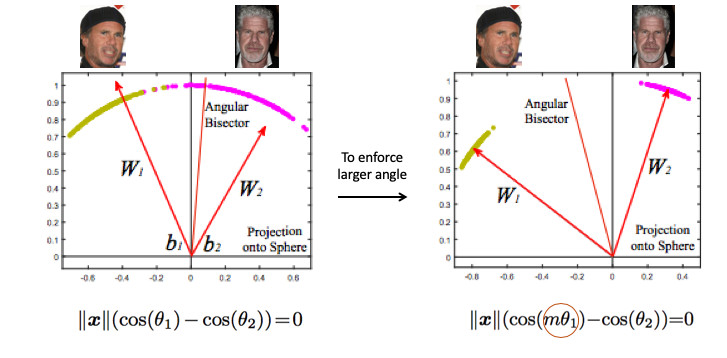
Hay varias opciones para Angular Softmax. Todos juegan con el hecho de que multiplican por m este ángulo o suman, o multiplican y suman. Estado del arte - ArcFace.
De hecho, este es bastante fácil de integrar en la clasificación de la tubería.
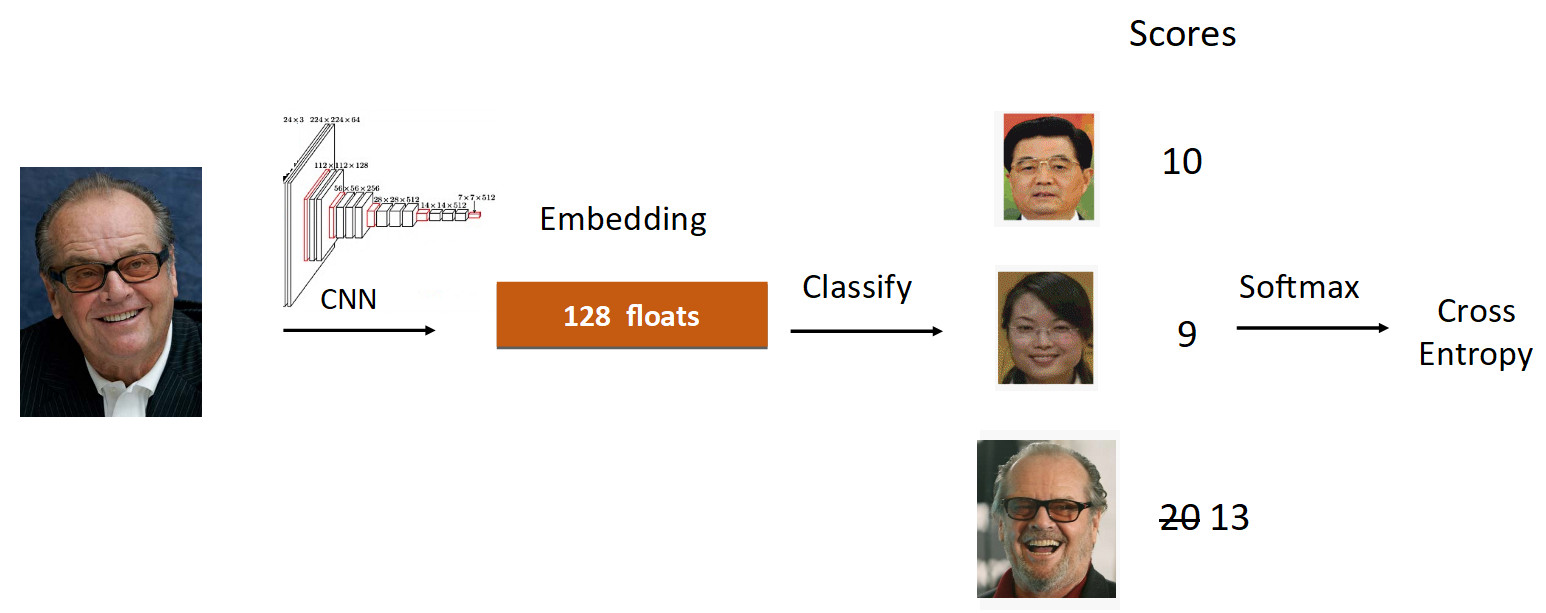
Veamos el ejemplo de Jack Nicholson. Corremos su foto a través de la cuadrícula en el proceso de aprendizaje. Nos incrustamos, corremos a través de la capa lineal para la clasificación y obtenemos puntajes en la salida, que reflejan el grado de pertenencia a la clase. En este caso, la fotografía de Nicholson tiene una velocidad de 20, la más grande. Además, de acuerdo con la fórmula de ArcFace, reducimos la velocidad de 20 a 13 (solo para la clase de verdad), lo que complica la tarea para la red neuronal. Luego hacemos todo como de costumbre: Softmax + Cross Entropy.
En total, la capa lineal habitual se reemplaza por la capa ArcFace, que no está escrita en 10, sino en 20 líneas, pero proporciona excelentes resultados y un mínimo de sobrecarga para la implementación. Como resultado, ArcFace es mejor que la mayoría de los otros métodos para la mayoría de las tareas. Se integra perfectamente con las tareas de clasificación y mejora la calidad.
Transferencia de aprendizaje
La segunda cosa de la que quería hablar es el aprendizaje de transferencia: usar una red pre-entrenada en una tarea similar para volver a capacitarse en una nueva tarea. Por lo tanto, el conocimiento se transfiere de una tarea a otra.
Hicimos nuestra búsqueda en imágenes. La esencia de la tarea es producir semánticamente similares a partir de la base de datos en la imagen (consulta).

Es lógico tomar una red que ya ha estudiado en una gran cantidad de imágenes, en conjuntos de datos ImageNet u OpenImages, en los que hay millones de imágenes, y entrenar en nuestros datos.
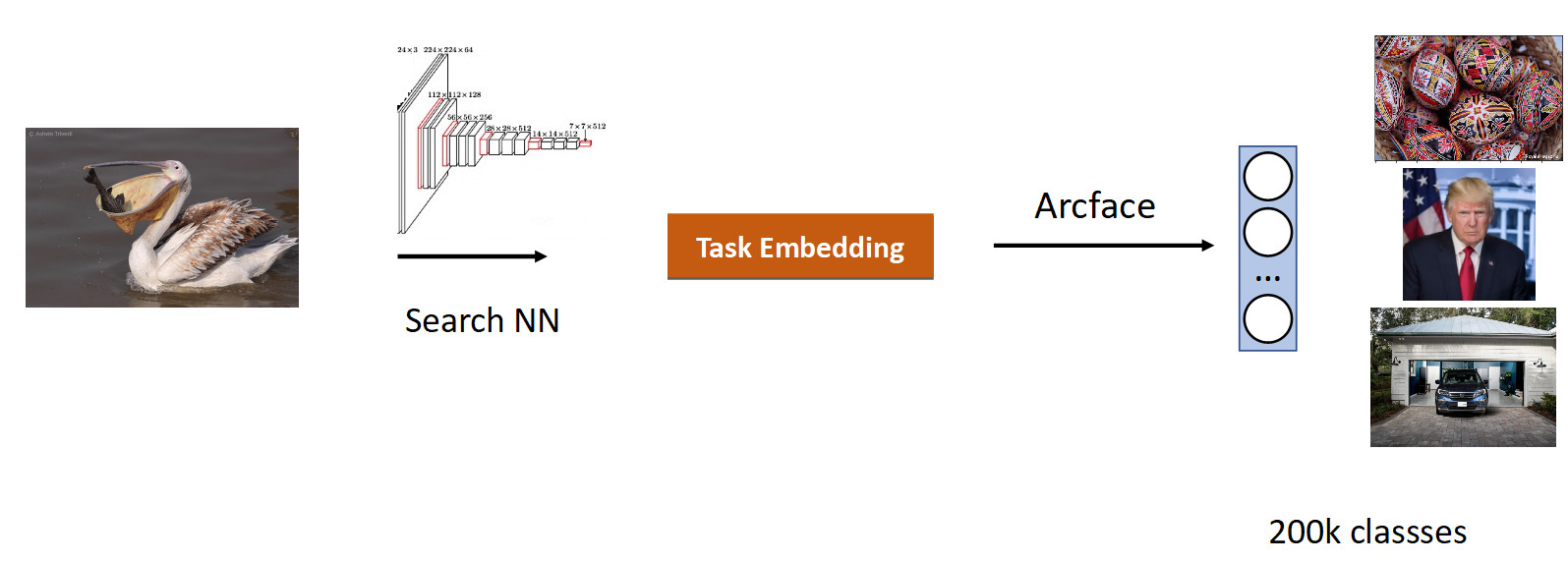
Recopilamos datos para esta tarea en función de la similitud de las imágenes y los clics de los usuarios y obtuvimos 200k clases. Después de entrenar con ArFace, obtuvimos el siguiente resultado.

En la imagen de arriba, vemos que para el pelícano solicitado, los gorriones también se metieron en el problema. Es decir la incrustación resultó semánticamente cierta: es un pájaro, pero racialmente infiel. Lo más molesto es que el modelo original con el que nos volvimos a entrenar conocía estas clases y las distinguía perfectamente. Aquí vemos el efecto que es común a todas las redes neuronales, llamado olvido catastrófico. Es decir, durante el reciclaje, la red olvida la tarea anterior, a veces incluso por completo. Esto es exactamente lo que impide en esta tarea lograr una mejor calidad.
Destilación de conocimiento
Esto se trata utilizando una técnica llamada destilación de conocimiento, cuando una red enseña a otra y "le transfiere su conocimiento". Cómo se ve (canal de entrenamiento completo en la imagen a continuación).
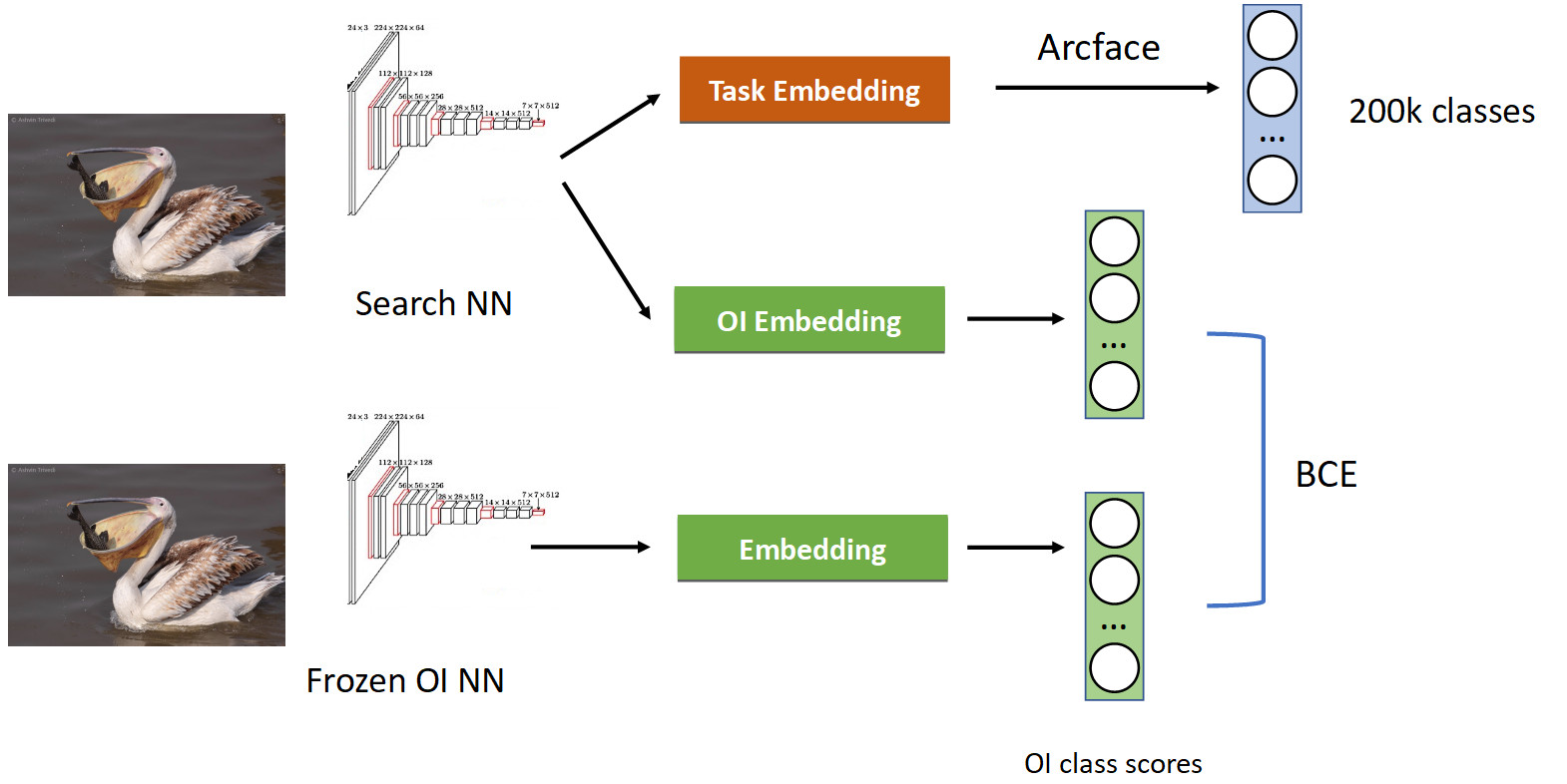
Ya tenemos una tubería de clasificación familiar con Arcface. Recordemos que tenemos una red con la que estamos fingiendo. Lo congelamos y simplemente calculamos sus incrustaciones en todas las fotos en las que aprendemos nuestra red, y obtenemos las clases de las clases de OpenImages: pelícanos, gorriones, autos, personas, etc. OpenImages, que produce puntuaciones similares. Con BCE, hacemos que la red produzca una distribución similar de estos puntajes. Por lo tanto, por un lado, estamos aprendiendo una nueva tarea (en la parte superior de la imagen), pero también hacemos que la red no olvide sus raíces (en la parte inferior): recuerde las clases que solía conocer. Si equilibras correctamente los gradientes en una proporción condicional de 50/50, esto dejará a todos los pelícanos en la parte superior y arrojará todos los gorriones desde allí.

Cuando aplicamos esto, obtuvimos un porcentaje completo en el mAP. Esto es bastante
Entonces, si su red olvida la tarea anterior, entonces trate usando la destilación de conocimiento, esto funciona bien.
Cabezas adicionales
La idea básica es muy simple. De nuevo en el ejemplo del reconocimiento facial. Tenemos un conjunto de personas en el conjunto de datos. Pero también a menudo en los conjuntos de datos hay otras características de la cara. Por ejemplo, qué edad, qué color de ojos, etc. Todo esto se puede agregar como un complemento más. señal: enseñe a los jefes individuales a predecir estos datos. Por lo tanto, nuestra red recibe una señal más diversa y, como resultado, puede ser mejor aprender la tarea principal.
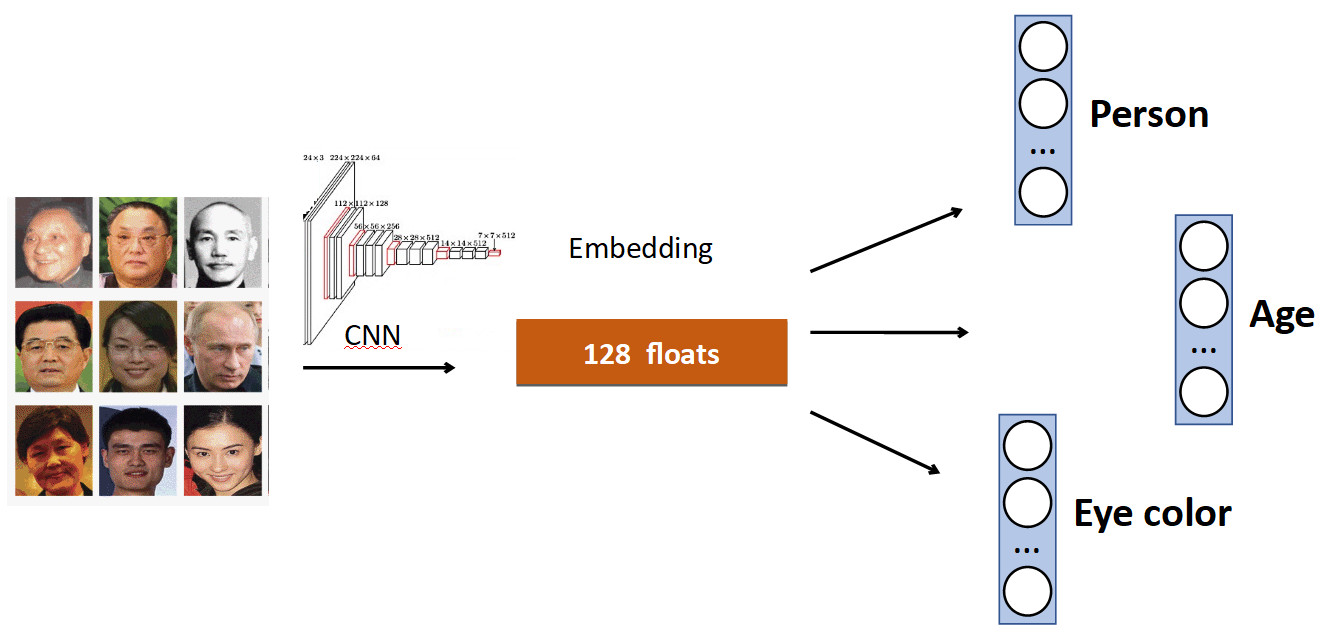
Otro ejemplo: detección de colas.

A menudo, en conjuntos de datos con personas, además del cuerpo, hay una marca separada de la posición de la cabeza, que, obviamente, se puede usar. Por lo tanto, agregamos a la red la predicción del cuadro delimitador de la persona y la predicción del cuadro delimitador de la cabeza, y obtuvimos un aumento del 0,5% en precisión (mAP), que es decente. Y lo más importante: gratis en términos de rendimiento, porque en producción, el cabezal adicional se "desconecta".

OCR
Un caso más complejo e interesante es el OCR, ya mencionado anteriormente. La tubería estándar es así.
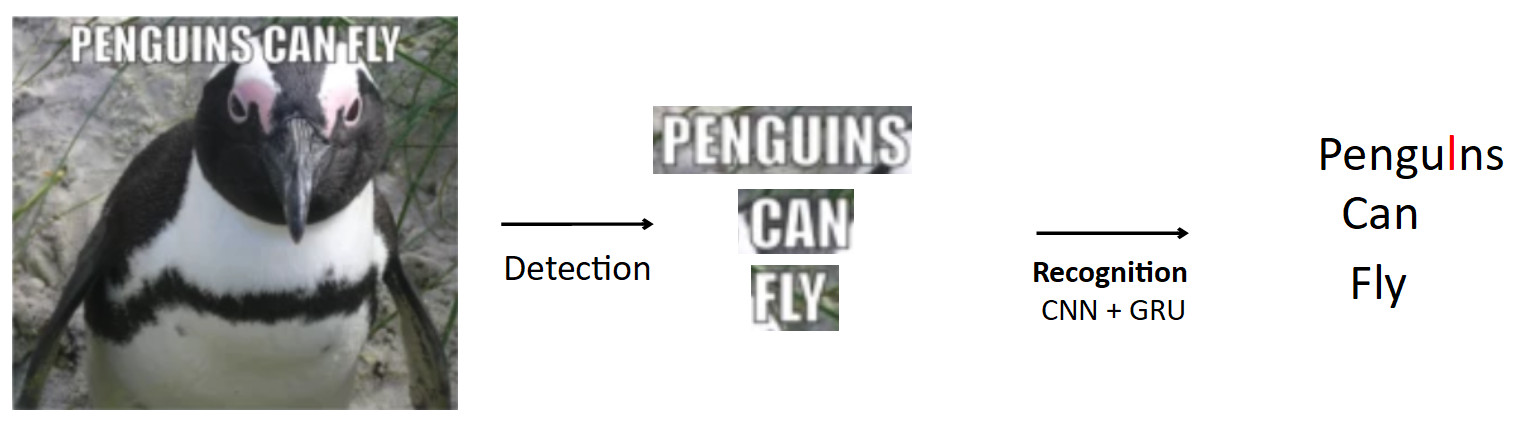
Que haya un cartel con un pingüino, el texto está escrito en él. Usando el modelo de detección, destacamos este texto. Además, alimentamos este texto a la entrada del modelo de reconocimiento, que produce el texto reconocido. Digamos que nuestra red está mal y en lugar de "i" en la palabra pingüinos predice "l". Este es realmente un problema muy común en OCR cuando la red confunde caracteres similares. La pregunta es cómo evitar esto: ¿traducir pingüinos en pingüinos? Cuando una persona mira este ejemplo, es obvio para él que esto es un error, porque él tiene conocimiento de la estructura del lenguaje. Por lo tanto, el conocimiento sobre la distribución de caracteres y palabras en el idioma debe estar integrado en el modelo.
Usamos una cosa llamada BPE (codificación de par de bytes) para esto. Este es un algoritmo de compresión que generalmente se inventó en los años 90, no para el aprendizaje automático, pero ahora es muy popular y se utiliza en el aprendizaje profundo. El significado del algoritmo es que las subsecuencias que ocurren con frecuencia en el texto se reemplazan con nuevos caracteres. Supongamos que tenemos la cadena "aaabdaaabac" y queremos obtener un BPE. Encontramos que el par de caracteres "aa" es el más frecuente en nuestra palabra. Lo reemplazamos con un nuevo carácter "Z", obtenemos la cadena "ZabdZabac". Repetimos la iteración: vemos que ab es la subsecuencia más frecuente, reemplácela con "Y", obtenemos la cadena "ZYdZYac". Ahora "ZY" es la subsecuencia más frecuente, la reemplazamos con "X", obtenemos "XdXac". Por lo tanto, codificamos algunas dependencias estadísticas en la distribución del texto. Si nos encontramos con una palabra en la que hay subsecuencias muy "extrañas" (raras para el cuerpo docente), entonces esta palabra es sospechosa.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYCómo todo encaja en el reconocimiento.
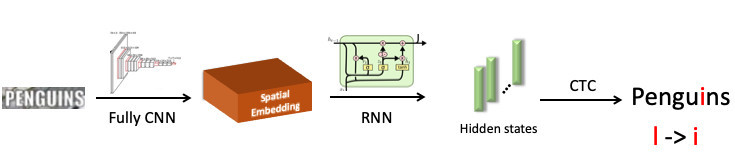
Destacamos la palabra "pingüino", la enviamos a la red neuronal convolucional, que produjo incrustación espacial (un vector de longitud fija, por ejemplo 512). Este vector codifica información de símbolo espacial. A continuación, usamos una red de recurrencia (UPD: de hecho, ya usamos el modelo Transformer), proporciona algunos estados ocultos (barras verdes), en cada uno de los cuales se cose la distribución de probabilidad, que, según el modelo, el símbolo se representa en una posición específica. Luego, usando CTC-Loss, desenrollamos estos estados y obtenemos nuestra predicción para toda la palabra, pero con un error: L en lugar de i.
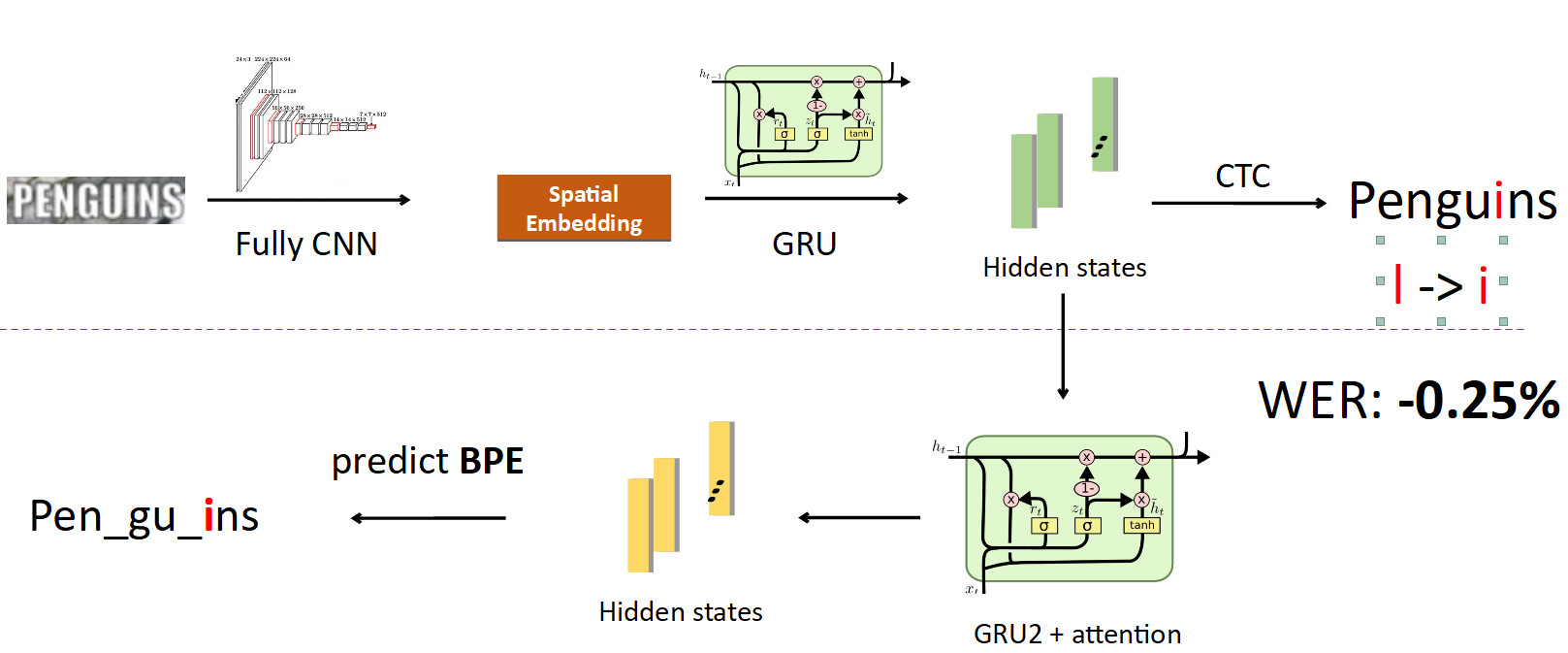
Ahora integrando BPE en la tubería. Queremos alejarnos de la predicción de caracteres individuales a palabras, por lo que nos separamos de los estados en los que se cose la información sobre los caracteres y establecemos otra red recursiva en ellos; ella predice BPE. En el caso del error descrito anteriormente, se obtienen 3 BPE: "peng", "ul", "ns". Esto difiere significativamente de la secuencia correcta para la palabra pingüinos, es decir, pen, gu, ins. Si observa esto desde el punto de vista del entrenamiento de modelos, entonces, en una predicción de carácter por palabra, la red cometió un error en solo una de cada ocho letras (error del 12.5%); y en términos de BPE, estaba 100% equivocada al predecir los 3 BPE incorrectamente. Esta es una señal mucho más grande para la red de que algo salió mal y necesita corregir su comportamiento. Cuando implementamos esto, pudimos corregir errores de este tipo y redujimos la tasa de error de Word en un 0.25%, eso es mucho. Esta cabeza extra se elimina cuando se hace inferencia, cumpliendo su papel en el entrenamiento.
FP16
Lo último que quería decir sobre el entrenamiento fue FP16. Sucedió históricamente que las redes se entrenaron en la GPU con precisión de unidad, es decir, FP32. Pero esto es redundante, especialmente para la inferencia, donde la precisión media (FP16) es suficiente sin pérdida de calidad. Sin embargo, este no es el caso con el entrenamiento.
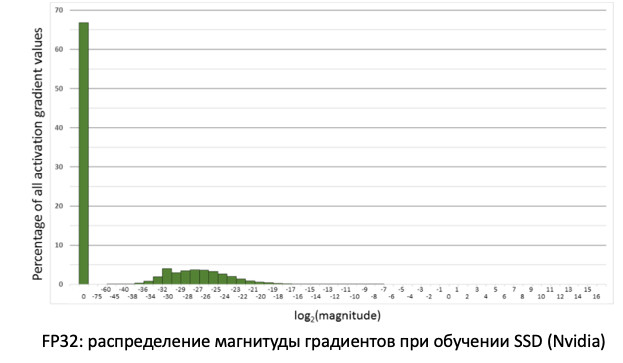
Si observamos la distribución de gradientes, información que actualiza nuestros pesos al propagar errores, veremos que hay un enorme pico en cero. Y en general, muchos valores están cerca de cero. Si solo transferimos todos los pesos al FP16, resulta que cortamos el lado izquierdo en la región de cero (desde la línea roja).
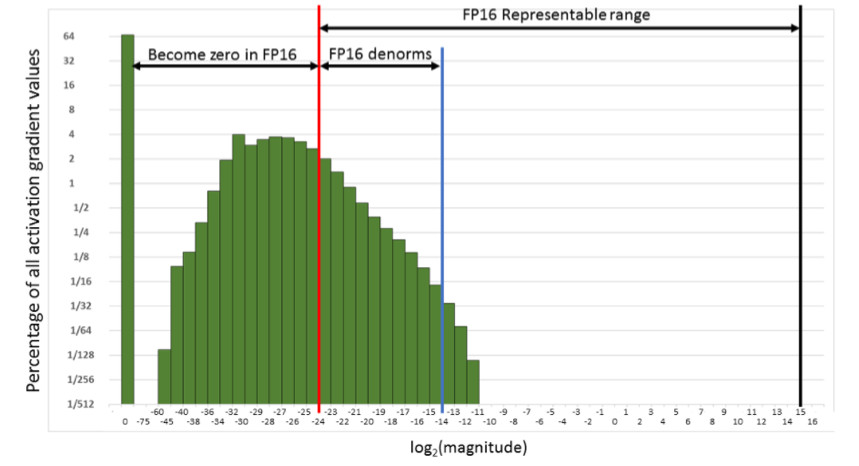
Es decir, restableceremos una gran cantidad de gradientes. Y la parte correcta, en el rango de trabajo FP16, no se utiliza en absoluto. Como resultado, si entrena la frente en FP16, es probable que el proceso se disperse (el gráfico gris en la imagen a continuación).
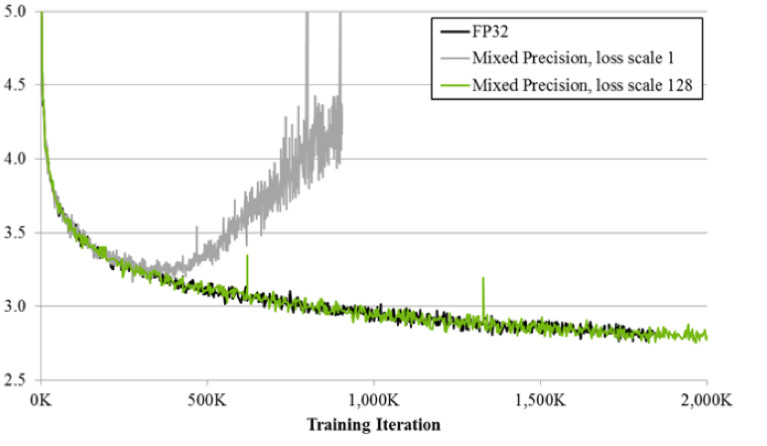
Si entrenas usando la técnica de precisión mixta, el resultado es casi idéntico al FP32. La precisión mixta implementa dos trucos.
Primero: simplemente multiplicamos la pérdida por una constante, por ejemplo, 128. Por lo tanto, escalamos todos los gradientes y movemos sus valores de cero al rango de trabajo FP16. Segundo: almacenamos la versión maestra de la balanza FP32, que se usa solo para actualizar, y en las operaciones de computación de redes de paso hacia adelante y hacia atrás, solo se usa FP16.
Usamos Pytorch para entrenar redes. NVIDIA realizó un ensamblaje especial con el llamado APEX, que implementa la lógica descrita anteriormente. Él tiene dos modos. El primero es la precisión mixta automática. Vea el código a continuación para ver lo fácil que es usarlo.

Literalmente, se agregan dos líneas al código de capacitación que envuelven la pérdida y el procedimiento de inicialización del modelo y los optimizadores. ¿Qué hace AMP? Él mono patch'it todas las funciones. ¿Qué está pasando exactamente? Por ejemplo, él ve que hay una función de convolución, y ella recibe una ganancia de FP16. Luego lo reemplaza con el suyo, que primero se convierte en FP16, y luego realiza una operación de convolución. Entonces AMP lo hace para todas las funciones que se pueden usar en la red. Para algunos, no lo hace. No habrá aceleración. Para la mayoría de las tareas, este método es adecuado.
Segunda opción: optimizador FP16 para fanáticos de control completo. Adecuado si usted mismo desea especificar qué capas estarán en FP16 y cuáles en FP32. Pero tiene una serie de limitaciones y dificultades. No comienza con una media patada (al menos tuvimos que sudar para comenzar). También FP_optimizer funciona solo con Adam, e incluso solo con ese Adam, que está en APEX (sí, tienen su propio Adam en el repositorio, que tiene una interfaz completamente diferente a Paytorch).
Hicimos una comparación al aprender sobre las tarjetas Tesla T4.
En Inference, tenemos la aceleración esperada dos veces. En el entrenamiento, vemos que el marco Apex proporciona una aceleración del 20% con FP16 relativamente simple. Como resultado, tenemos un entrenamiento que es dos veces más rápido y consume 2 veces menos memoria, y la calidad del entrenamiento no se ve afectada de ninguna manera. Freebie
Inferencia
Porque Como usamos PyTorch, la pregunta es con urgencia cómo implementarlo en producción.
Hay 3 opciones sobre cómo hacerlo (y todas las que usamos).
- ONNX -> Caffe2
- ONNX -> TensorRT
- Y más recientemente Pytorch C ++
Veamos cada uno de ellos.
ONNX y Caffe2
ONNX apareció hace 1,5 años. Este es un marco especial para convertir modelos entre diferentes marcos. Y Caffe2 es un marco adyacente a Pytorch, los cuales se están desarrollando en Facebook. Históricamente, Pytorch se está desarrollando mucho más rápido que Caffe2. Caffe2 va a la zaga de Pytorch en características, por lo que no todos los modelos que entrenaste en Pytorch se pueden convertir a Caffe2. A menudo tienes que volver a aprender con otras capas. Por ejemplo, en Caffe2 no existe una operación estándar como el muestreo ascendente con la interpolación de vecino más cercano. Como resultado, llegamos a la conclusión de que para cada modelo obtuvimos una imagen acoplable especial, en la que clavamos las versiones del marco con clavos para evitar discrepancias durante sus futuras actualizaciones, de modo que cuando una de las versiones se actualiza nuevamente, no perdamos tiempo en su compatibilidad . Todo esto no es muy conveniente y alarga el proceso de implementación.
Tensor rt
También está Tensor RT, un marco NVIDIA que optimiza la arquitectura de red para acelerar la inferencia. Hicimos nuestras mediciones (en el mapa Tesla T4).
Si observa los gráficos, puede ver que la transición de FP32 a FP16 proporciona una aceleración 2x en Pytorch, y TensorRT al mismo tiempo proporciona 4x. Una diferencia muy significativa. Lo probamos en Tesla T4, que tiene núcleos tensoriales que utilizan muy bien los cálculos de FP16, lo que obviamente es excelente en TensorRT. Por lo tanto, si hay un modelo altamente cargado que se ejecuta en docenas de tarjetas gráficas, entonces todos son motivadores para probar Tensor RT.
Sin embargo, cuando se trabaja con TensorRT hay incluso más dolor que en Caffe2: las capas son aún menos compatibles. Desafortunadamente, cada vez que usamos este marco, tenemos que sufrir un poco para convertir el modelo. Pero para modelos muy cargados, tienes que hacer esto. ;) Observo que en los mapas sin núcleos tensoriales no se observa un aumento tan masivo.
Pytorch C ++
Y el último es Pytorch C ++. Hace seis meses, los desarrolladores de Pytorch se dieron cuenta del dolor de las personas que usan su marco y lanzaron el
tutorial de TorchScript , que le permite rastrear y serializar el modelo de Python en un gráfico estático sin gestos innecesarios (JIT). Fue lanzado en diciembre de 2018, de inmediato comenzamos a usarlo, inmediatamente
detectamos algunos errores de rendimiento y esperamos varios meses para que
Chintala lo reparara . Pero ahora es una tecnología bastante estable, y la estamos utilizando activamente para todos los modelos. Lo único es la falta de documentación, que se complementa activamente. Por supuesto, siempre puedes mirar archivos * .h, pero para las personas que no conocen las ventajas, es difícil. Pero luego hay un trabajo realmente idéntico con Python. En C ++, el código j se ejecuta en un intérprete mínimo de Python, que prácticamente garantiza la identidad de C ++ con Python.
Conclusiones
- La declaración del problema es súper importante. Debe comunicarse con los gerentes de producto sobre los datos. Antes de comenzar a realizar la tarea, es recomendable tener un conjunto de pruebas listo para usar en el que medimos las métricas finales antes de la etapa de implementación.
- Limpiamos los datos nosotros mismos con la ayuda de la agrupación. Obtenemos el modelo en los datos de origen, limpiamos los datos utilizando el clúster CLink y repetimos el proceso hasta la convergencia.
- Aprendizaje métrico: incluso la clasificación ayuda. Estado del arte: ArcFace, que es fácil de integrar en el proceso de aprendizaje.
- Si transfiere el aprendizaje de una red previamente capacitada, para que la red no olvide la tarea anterior, utilice la destilación de conocimiento.
- También es útil usar varios cabezales de red que utilizarán diferentes señales de los datos para mejorar la tarea principal.
- Para FP16, debe usar los ensamblajes Apex de NVIDIA, Pytorch.
- Y, por inferencia, es conveniente usar Pytorch C ++.