El 27 de mayo, en la sala principal de la conferencia DevOpsConf 2019, celebrada como parte del festival
RIT ++ 2019 , como parte de la sección Entrega continua, se hizo un informe "werf es nuestra herramienta para CI / CD en Kubernetes". Habla sobre los
problemas y desafíos que todos enfrentan cuando se implementan en Kubernetes , así como sobre los matices que pueden no ser inmediatamente perceptibles. Analizando posibles soluciones, mostramos cómo se implementa esto en la herramienta
werf Open Source.
Desde el programa, nuestra utilidad (anteriormente conocida como dapp) ha superado el límite histórico de
1000 estrellas en GitHub ; esperamos que la creciente comunidad de usuarios simplifique la vida de muchos ingenieros de DevOps.

Entonces, presentamos el
video con el informe (~ 47 minutos, mucho más informativo que el artículo) y el extracto principal del mismo en forma de texto. Vamos!
Entrega de código en Kubernetes
La charla ya no será sobre werf, sino sobre CI / CD en Kubernetes, lo que implica que nuestro software está empaquetado en contenedores Docker
(hablé de esto en el informe de 2016 ) , y los K8 se usarán para lanzarlo en producción
(sobre esto - en 2017 ) .
¿Cómo es la entrega de Kubernetes?
- Hay un repositorio Git con código e instrucciones para construirlo. La aplicación se compila en una imagen de Docker y se publica en el Registro de Docker.
- En el mismo repositorio hay instrucciones sobre cómo implementar y ejecutar la aplicación. En la etapa de implementación, estas instrucciones se envían a Kubernetes, que recibe la imagen deseada del registro y la inicia.
- Además, generalmente hay pruebas. Algunos de ellos se pueden realizar al publicar una imagen. También puede (siguiendo las mismas instrucciones) desplegar una copia de la aplicación (en un espacio de nombres K8s separado o en un clúster separado) y ejecutar pruebas allí.
- Finalmente, necesitamos un sistema de CI que reciba eventos de Git (o clics de botón) y llame a todas las etapas indicadas: compilar, publicar, implementar, probar.

Aquí hay algunas notas importantes:
- Como tenemos una infraestructura inmutable, la imagen de la aplicación que se utiliza en todas las etapas (puesta en escena, producción, etc.) debe ser una . Hablé más sobre esto y con ejemplos aquí .
- Dado que estamos siguiendo la infraestructura como un enfoque de código (IaC) , el código de la aplicación y las instrucciones para construirlo y ejecutarlo deben estar en un repositorio . Para más información sobre esto, vea el mismo informe .
- Por lo general, vemos la cadena de entrega (entrega) así: la aplicación se ensambla, se prueba, se lanza (etapa de lanzamiento) y eso es todo: la entrega se ha producido. Pero en realidad, el usuario recibe lo que usted implementó, no cuando lo entregó a producción, sino cuando pudo ir allí y esta producción funcionó. Por lo tanto, creo que la cadena de entrega finaliza solo en la etapa operativa (ejecución) , y más precisamente, incluso en el momento en que el código se eliminó de la producción (reemplazándolo por uno nuevo).
Volvamos al esquema de entrega de Kubernetes descrito anteriormente: fue inventado no solo por nosotros, sino literalmente por todos los que se ocuparon de este problema. En esencia, este patrón ahora se llama GitOps
(puede encontrar más información sobre el término y las ideas detrás de él aquí ) . Veamos las etapas del esquema.
Etapa de construcción
Parece que en 2019 puedes contar sobre el ensamblaje de las imágenes de Docker, cuando todos sepan cómo escribir Dockerfiles y ejecutar Docker
docker build ? ... Aquí están los matices a los que me gustaría prestar atención:
- El peso de la imagen es importante, así que use múltiples etapas para dejar solo la aplicación realmente necesaria para la imagen.
- El número de capas debe minimizarse combinando las cadenas de comandos
RUN dentro del significado. - Sin embargo, esto se suma a los problemas de depuración , ya que cuando el ensamblaje falla, debe encontrar el comando necesario de la cadena que causó el problema.
- La velocidad de creación es importante porque queremos implementar rápidamente los cambios y ver el resultado. Por ejemplo, no quiero volver a ensamblar las dependencias en las bibliotecas de idiomas con cada compilación de la aplicación.
- A menudo, se requieren muchas imágenes de un repositorio Git, que puede resolverse mediante un conjunto de Dockerfiles (o etapas con nombre en un archivo) y un script Bash con su ensamblaje secuencial.
Era solo la punta del iceberg que todos enfrentan. Pero hay otros problemas, y en particular:
- A menudo, en la etapa de ensamblaje, necesitamos montar algo (por ejemplo, almacenar en caché el resultado de un comando como apt en un directorio de terceros).
- Queremos Ansible en lugar de escribir en el shell.
- Queremos construir sin Docker (¿por qué necesitamos una máquina virtual adicional en la que necesite configurar todo para esto cuando ya hay un clúster de Kubernetes en el que puede ejecutar contenedores?).
- Ensamblaje en paralelo , que puede entenderse de diferentes maneras: diferentes comandos del Dockerfile (si se usan varias etapas), varias confirmaciones de un repositorio, varios Dockerfiles.
- Ensamblaje distribuido : queremos recolectar algo en vainas que sean "efímeras", porque su caché desaparece, lo que significa que debe almacenarse en algún lugar por separado.
- Finalmente, llamé al pináculo de los deseos auto- mágico : sería ideal ir al repositorio, escribir algún equipo y obtener una imagen preparada, ensamblada con una comprensión de cómo y qué hacer bien. Sin embargo, personalmente no estoy seguro de que todos los matices se puedan prever de esta manera.
Y aquí están los proyectos:
- moby / buildkit : un creador de la compañía Docker Inc (ya integrado en las versiones actuales de Docker), que está tratando de resolver todos estos problemas;
- kaniko : un recopilador de Google, que le permite construir sin Docker;
- Buildpacks.io : un intento de CNCF de hacer magia automática y, en particular, una solución interesante con rebase para capas;
- y un montón de otras utilidades como buildah , genuinetools / img ...
... y ver cuántas estrellas tienen en GitHub. Es decir, por un lado, la
docker build es y puede hacer algo, pero en realidad, el
problema no se ha resuelto por completo ; esto se evidencia por el desarrollo paralelo de constructores alternativos, cada uno de los cuales resuelve algunos de los problemas.
Construir en werf
Así que llegamos a
werf (anteriormente conocido como dapp) , la utilidad Open Source de Flant, que hemos estado haciendo durante muchos años. Todo comenzó hace unos 5 años con scripts Bash que optimizan el ensamblaje de Dockerfiles, y en los últimos 3 años, el desarrollo completo ha estado en curso dentro del marco de un proyecto con su propio repositorio Git
(primero en Ruby, y luego reescrito en Go, y al mismo tiempo renombrado) . ¿Qué problemas de compilación se resuelven en werf?

Los problemas de sombreado azul ya se han implementado, el ensamblaje paralelo se ha realizado dentro del mismo host, y planeamos completar las preguntas amarillas para el final del verano.
Etapa de publicación en el registro (publicar)
Escribimos
docker push ... ¿Qué puede ser difícil al subir una imagen al registro? Y luego surge la pregunta: "¿Qué etiqueta poner la imagen?" Surge por la razón de que tenemos
Gitflow (u otra estrategia de Git) y Kubernetes, y la industria se compromete a garantizar que lo que sucede en Kubernetes siga lo que se está haciendo en Git. Git es nuestra única fuente de verdad.
¿Qué es tan complicado?
Garantice la reproducibilidad : desde un commit en Git, que es inherentemente
inmutable , hasta una imagen de Docker que debe mantenerse igual.
También es importante para nosotros
determinar el origen , porque queremos entender a partir de qué compromiso se creó la aplicación lanzada en Kubernetes (entonces podemos hacer diferencias y cosas similares).
Estrategias de etiquetado
El primero es una simple
etiqueta git . Tenemos un registro con una imagen etiquetada como
1.0 . Kubernetes tiene escenario y producción, donde se bombea esta imagen. En Git, hacemos commits y en algún momento ponemos la etiqueta
2.0 . Lo recopilamos de acuerdo con las instrucciones del repositorio y lo colocamos en el registro con la etiqueta
2.0 . Lo lanzamos al escenario y, si todo está bien, a la producción.
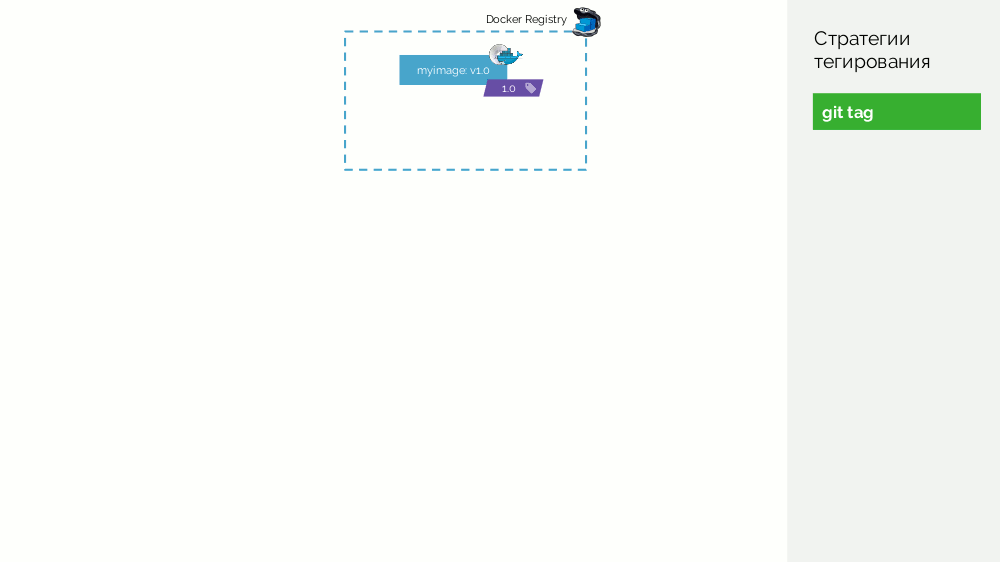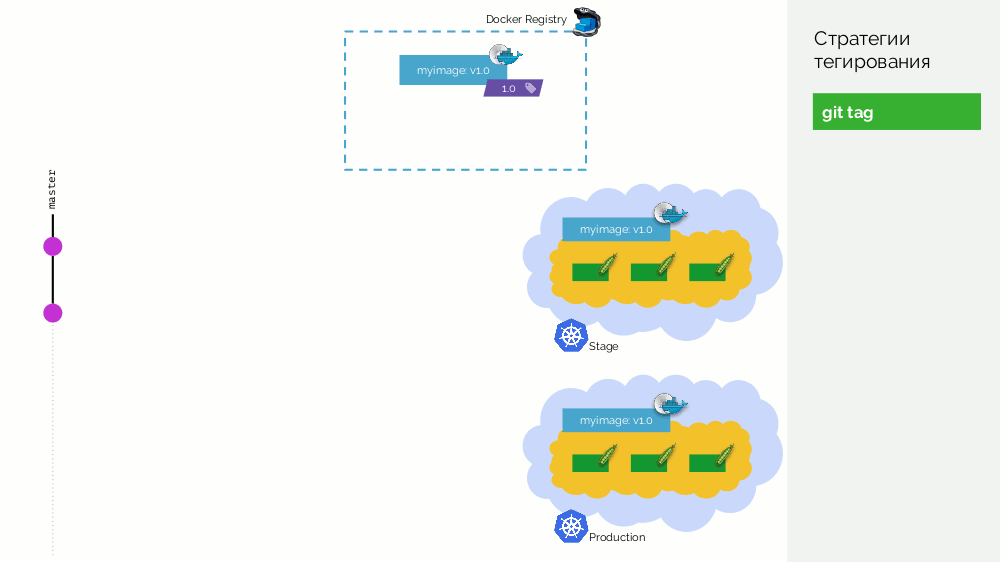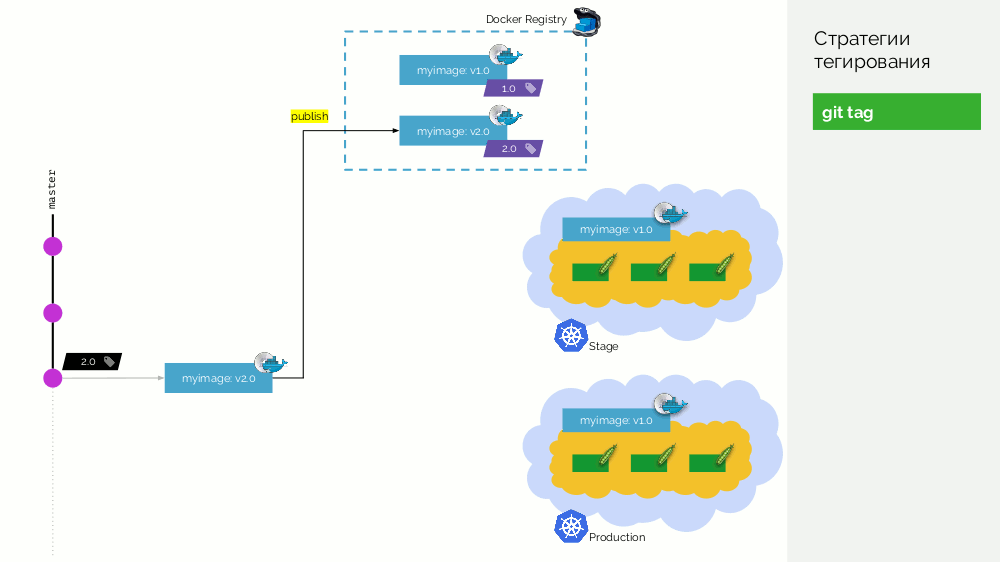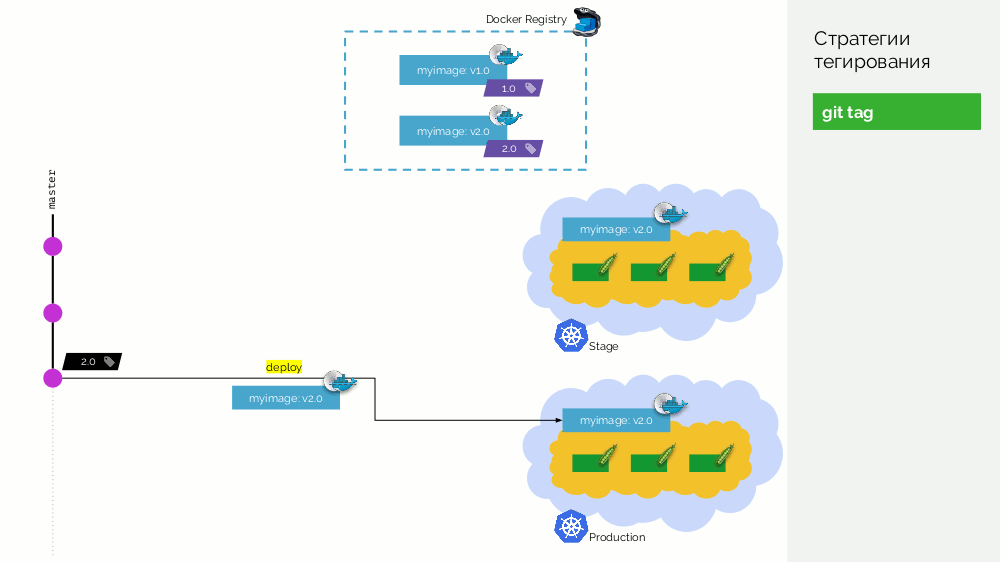
El problema con este enfoque es que primero configuramos la etiqueta, y solo luego la probamos y la implementamos. Por qué En primer lugar, esto es simplemente ilógico: entregamos una versión de software que ni siquiera hemos probado (no podemos hacer lo contrario, porque para verificar, debe colocar una etiqueta). En segundo lugar, esta forma no es compatible con Gitflow.
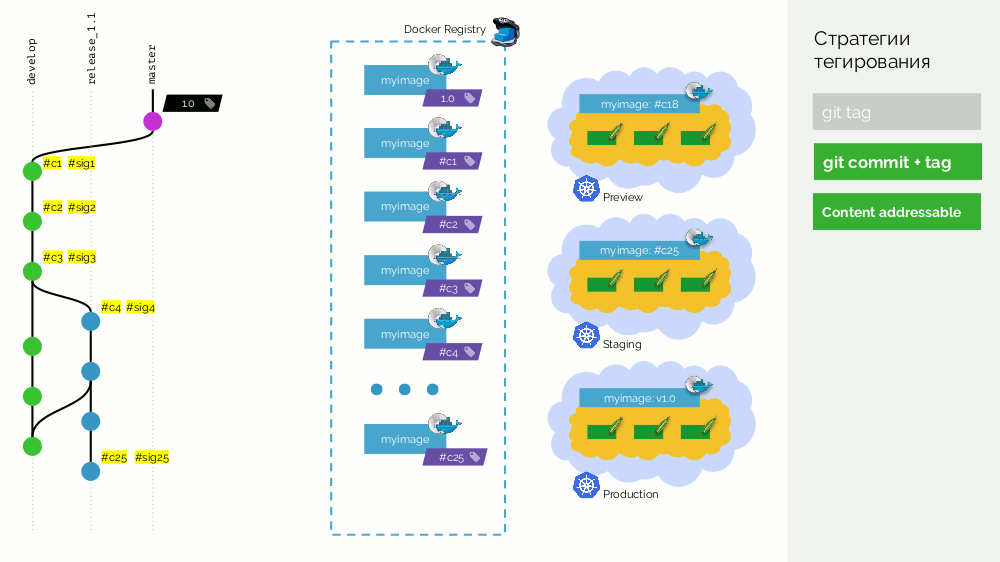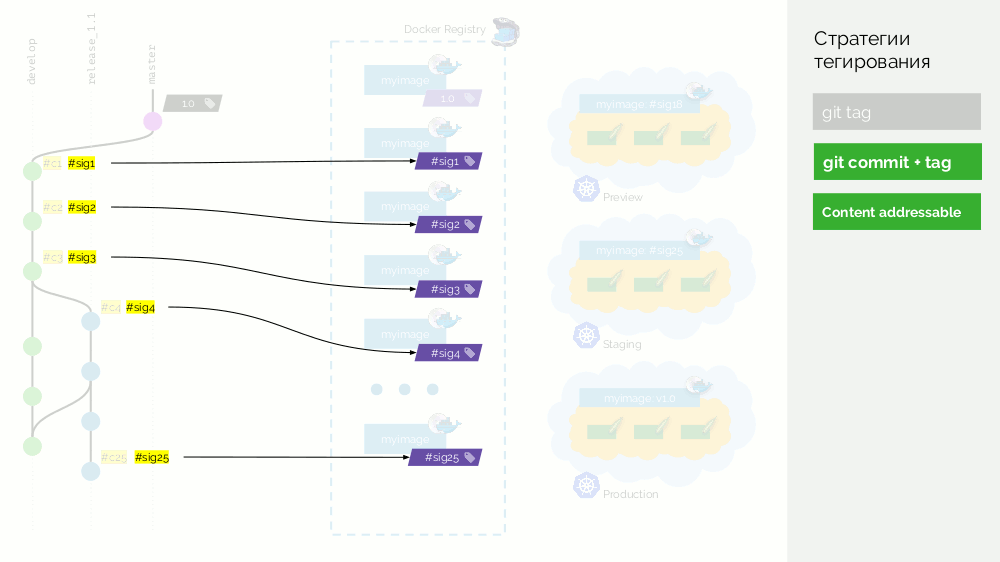
La segunda opción es
git commit + tag . Hay una etiqueta
1.0 en la rama maestra; para él en el registro: una imagen desplegada en producción. Además, el clúster de Kubernetes tiene bucles de vista previa y etapas. Además, seguimos a Gitflow: en la rama principal para el desarrollo
develop nuevas características, como resultado de lo cual existe una confirmación con el identificador
#c1 . Lo recopilamos y lo publicamos en el registro utilizando este identificador (
#c1 ). Lanzamos la vista previa con el mismo identificador. Hacemos lo mismo con los commits
#c2 y
#c3 .
Cuando nos damos cuenta de que hay suficientes características, comenzamos a estabilizar todo. En Git, cree la rama
release_1.1 (basada en
#c3 de
develop ). No es necesario recopilar esta versión porque Esto se hizo en el paso anterior. Por lo tanto, podemos implementarlo en la puesta en escena. Solucionamos errores en
#c4 y de forma similar se implementan en la puesta en escena. Al mismo tiempo, el desarrollo está en curso en el
develop , donde los cambios de la
release_1.1 se toman periódicamente. En algún momento, nos comprometemos y nos comprometemos con la puesta en escena, con lo que estamos contentos (
#c25 ).
Luego hacemos una fusión (con avance rápido) de la rama de lanzamiento (
release_1.1 ) en master. Ponemos una etiqueta con la nueva versión (
1.1 ) en este commit. Pero esta imagen ya está ensamblada en el registro, por lo que para no volver a recopilarla, solo agregamos una segunda etiqueta a la imagen existente (ahora tiene las etiquetas
#c25 y
1.1 en el registro). Después de eso, lo implementamos en producción.
Existe el inconveniente de que una imagen (
#c25 ) se
#c25 en la preparación y otra (
1.1 ) se
#c25 en la producción, pero sabemos que "físicamente" es la misma imagen del registro.
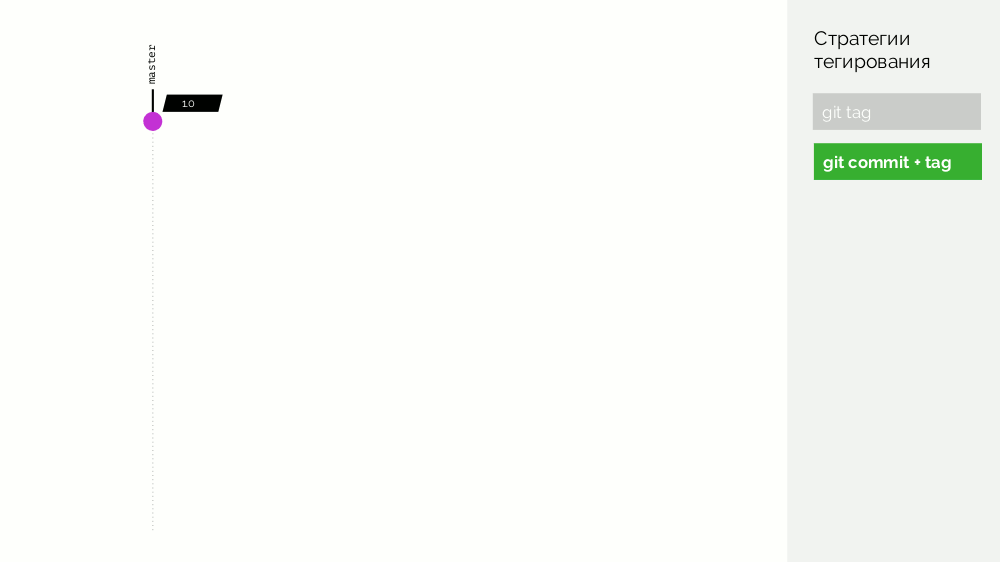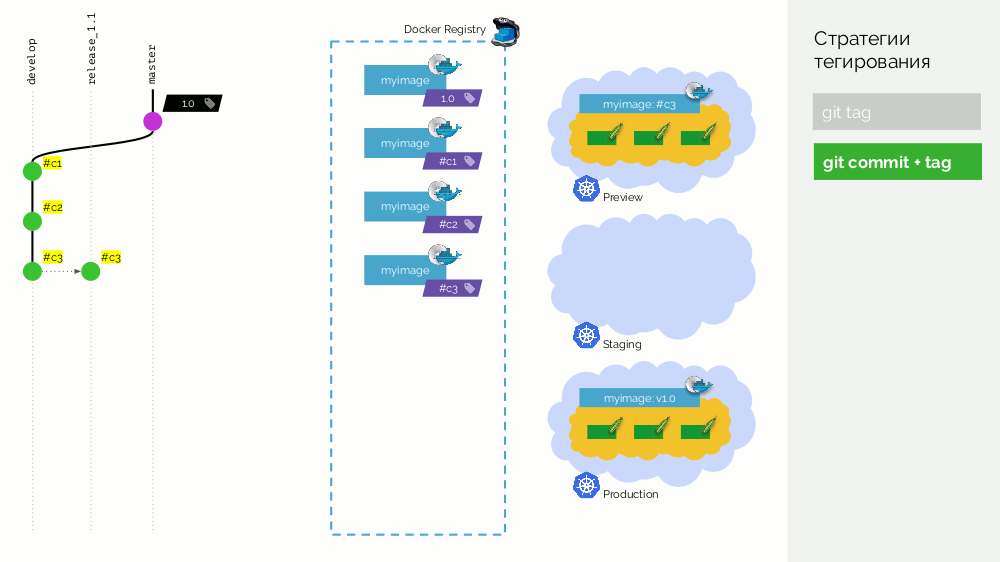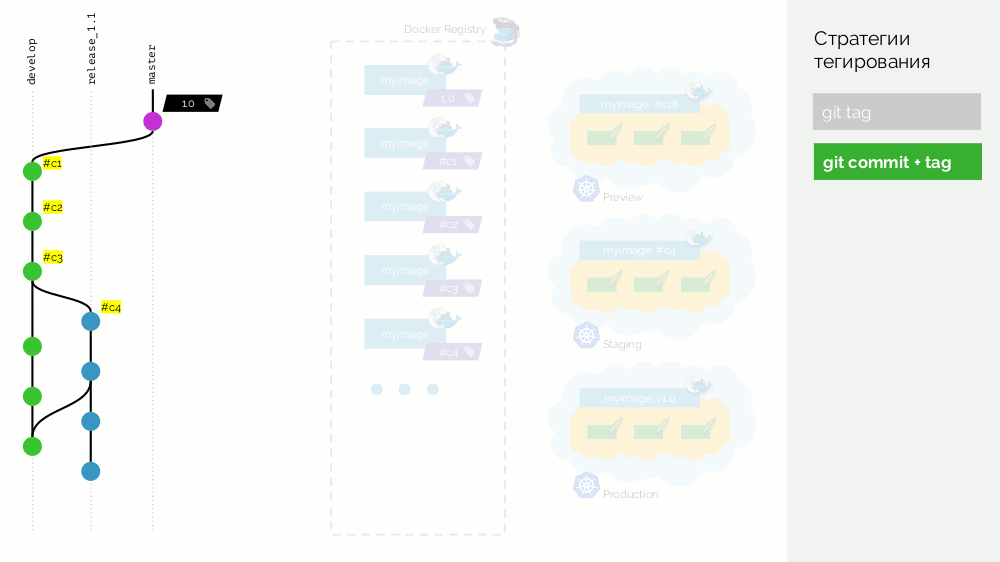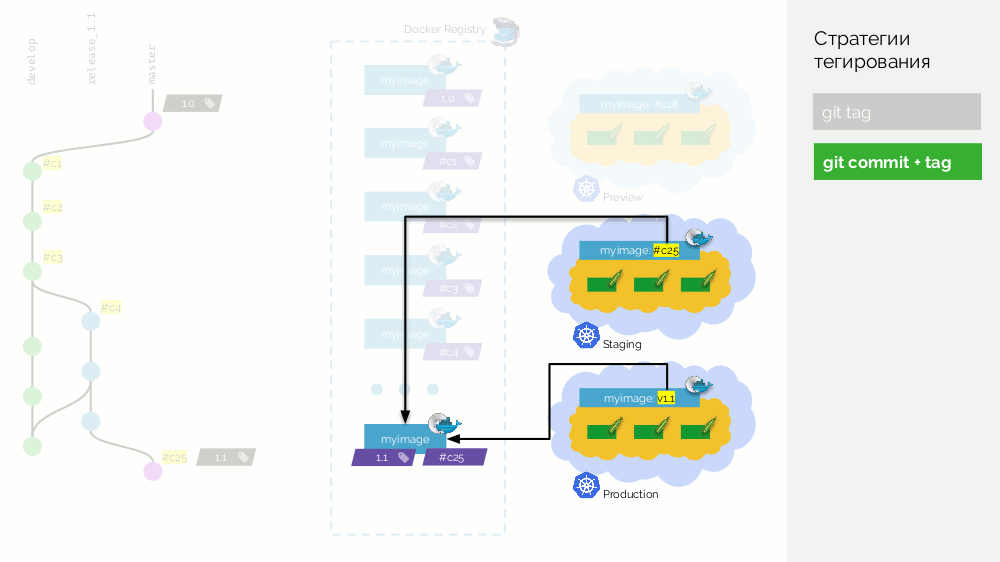
El verdadero inconveniente es que no hay soporte para merge commit'ov, debe avanzar rápidamente.
Puede ir más allá y hacer el truco ... Considere un ejemplo de un Dockerfile simple:
FROM ruby:2.3 as assets RUN mkdir -p /app WORKDIR /app COPY . ./ RUN gem install bundler && bundle install RUN bundle exec rake assets:precompile CMD bundle exec puma -C config/puma.rb FROM nginx:alpine COPY --from=assets /app/public /usr/share/nginx/www/public
Construimos un archivo a partir de él de acuerdo con este principio, que tomamos:
- SHA256 de identificadores de imágenes usadas (
ruby:2.3 y nginx:alpine ), que son sumas de comprobación de su contenido; - todos los equipos (
RUN , CMD , etc.); - SHA256 de los archivos que se agregaron.
... y tome la suma de comprobación (nuevamente SHA256) de dicho archivo. Esta es la
firma de todo lo que define el contenido de una imagen Docker.

Volvamos al esquema y en
lugar de commits usaremos tales firmas , es decir. etiquetar imágenes con firmas.
Ahora, cuando necesite, por ejemplo, fusionar los cambios de la versión a la maestra, podemos hacer una confirmación de fusión real: tendrá un identificador diferente, pero la misma firma. Con el mismo identificador, también desplegaremos la imagen en producción.
La desventaja es que ahora no será posible determinar qué tipo de compromiso se ha aplicado a la producción: las sumas de verificación funcionan solo en una dirección. Este problema se resuelve con una capa adicional con metadatos; más adelante te contaré más.
Etiquetado en werf
En werf, hemos ido aún más lejos y nos estamos preparando para hacer un ensamblaje distribuido con un caché que no está almacenado en la misma máquina ... Entonces, tenemos dos tipos de imágenes Docker, las llamamos
escenario e
imagen .
El repositorio werf Git almacena instrucciones de compilación específicas que describen las diferentes etapas de la compilación (
beforeInstall ,
install ,
beforeSetup ,
setup ). Recopilamos la imagen de la primera etapa con una firma definida como la suma de comprobación de los primeros pasos. Luego agregamos el código fuente, para la nueva imagen de escenario consideramos su suma de comprobación ... Estas operaciones se repiten para todas las etapas, como resultado de lo cual obtenemos un conjunto de imágenes de escenario. Luego hacemos la imagen-imagen final que contiene también metadatos sobre su origen. Y etiquetamos esta imagen de diferentes maneras (detalles más adelante).

Después de eso, aparece una nueva confirmación, en la que solo se cambia el código de la aplicación. Que va a pasar Se creará un parche para cambios de código, se preparará una nueva imagen de escenario. Su firma se definirá como la suma de comprobación de la imagen del escenario anterior y el nuevo parche. A partir de esta imagen se formará una nueva imagen-imagen final. Se producirá un comportamiento similar con los cambios en otras etapas.
Por lo tanto, las imágenes de escenario son un caché que se puede distribuir distribuido, y las imágenes de imágenes ya creadas a partir de él se cargan en el Registro Docker.
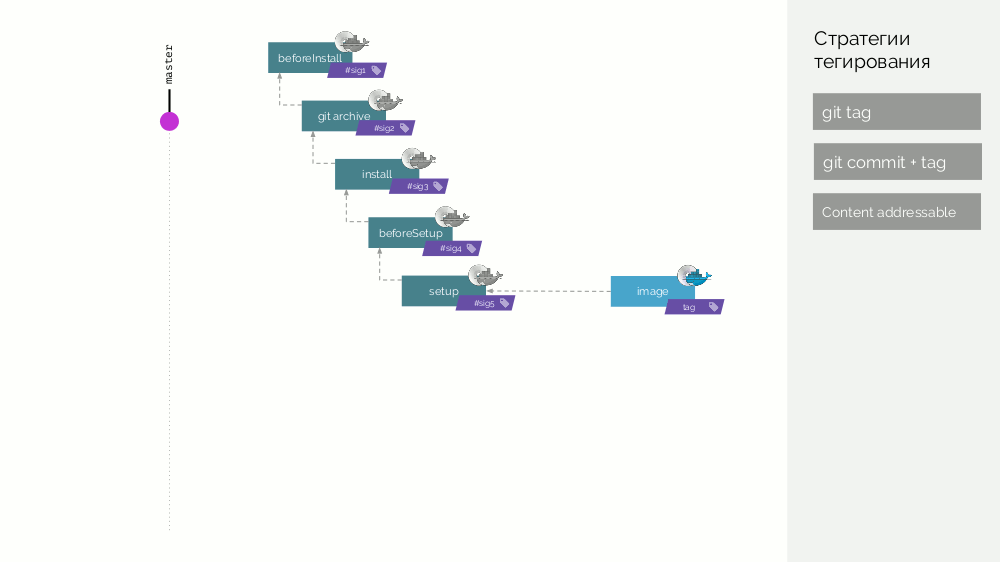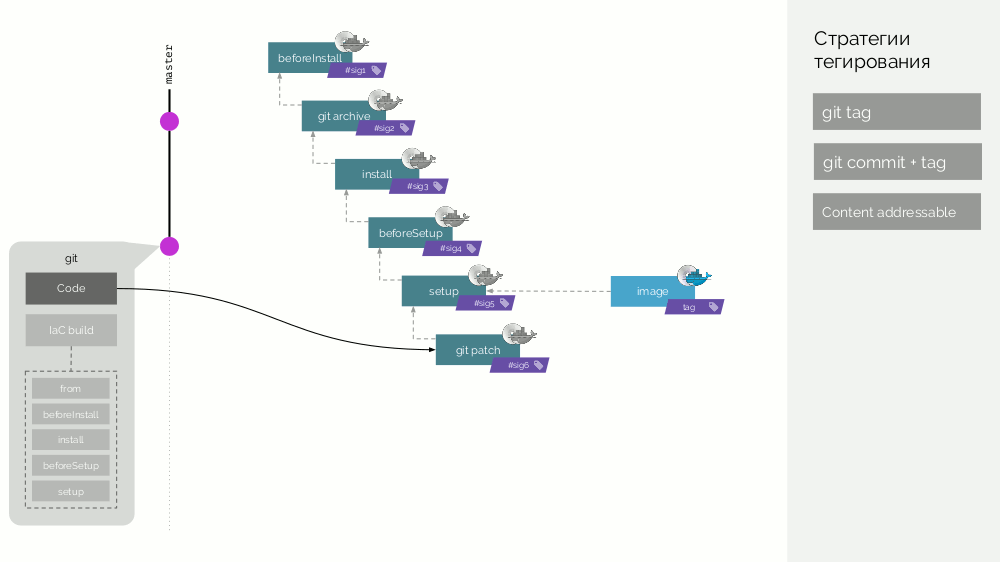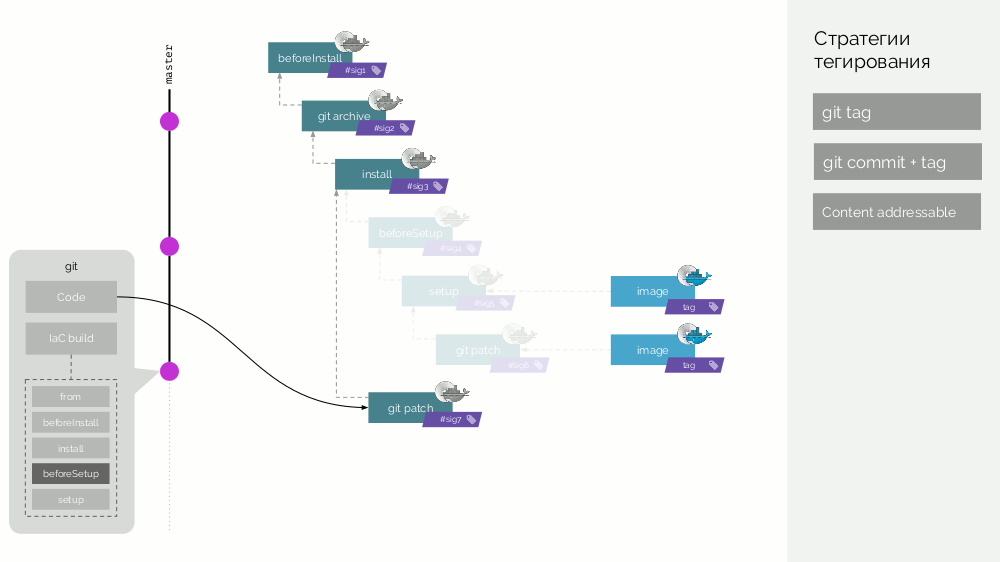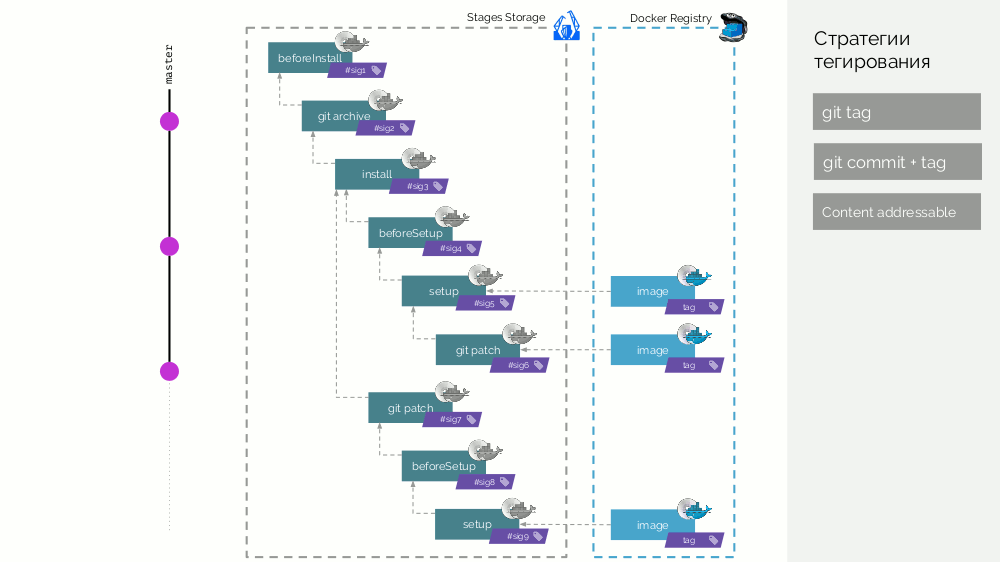
Limpieza del registro
No se trata de eliminar capas que permanecen colgadas después de las etiquetas eliminadas; esta es una característica estándar del propio Registro de Docker. Esta es una situación en la que se están acumulando muchas etiquetas Docker y entendemos que ya no necesitamos algunas, y que ocupan espacio (y / o pagamos por ello).
¿Cuáles son las estrategias de limpieza?
- Simplemente no puedes limpiar nada. A veces es realmente más fácil pagar un poco por el espacio extra que desentrañar una gran bola de etiquetas. Pero esto solo funciona hasta cierto punto.
- Restablecimiento completo Si elimina todas las imágenes y reconstruye solo las relevantes en el sistema CI, puede surgir un problema. Si el contenedor se reinicia en producción, se cargará una nueva imagen, una que aún no ha sido probada por nadie. Esto mata la idea de infraestructura inmutable.
- Azul verdoso Un registro comenzó a desbordarse, cargando imágenes en otro. El mismo problema que en el método anterior: ¿en qué punto puede limpiar el registro que comenzó a desbordarse?
- Por tiempo ¿Eliminar todas las imágenes de más de 1 mes? Pero seguramente habrá un servicio que no se haya actualizado durante un mes ...
- Determine manualmente lo que ya se puede eliminar.
Hay dos opciones realmente viables: no limpiar o una combinación de azul-verde + manualmente. En el último caso, estamos hablando de lo siguiente: cuando comprenda que es hora de limpiar el registro, cree uno nuevo y agregue todas las imágenes nuevas durante, por ejemplo, un mes. Un mes después, vea qué pods en Kubernetes todavía usan el registro anterior y transfiéralos también al nuevo registro.
¿ A
dónde fuimos a
werf ? Recopilamos:
- Cabeza de Git: todas las etiquetas, todas las ramas, suponiendo que todo lo que se prueba en Git, necesitamos en las imágenes (y si no, necesitamos eliminarlo en el propio Git);
- todos los pods que ahora se descargan en Kubernetes;
- ReplicaSets antiguos (algo que se extrajo recientemente), así como también planeamos escanear lanzamientos de Helm y seleccionar las últimas imágenes allí.
... y hacemos una lista blanca de este conjunto, una lista de imágenes que no eliminaremos. Limpiamos todo lo demás, después de lo cual encontramos las imágenes de escenario huérfanas y las eliminamos también.
Etapa de implementación (implementación)
Declaratividad robusta
El primer punto al que me gustaría llamar la atención en la implementación es implementar la configuración de recursos actualizada, declarada declarativamente. El documento original de YAML que describe los recursos de Kubernetes siempre es muy diferente del resultado que realmente funciona en el clúster. Porque Kubernetes agrega a la configuración:
- identificadores
- información de servicio;
- muchos valores por defecto;
- sección con estado actual;
- cambios realizados como parte del webhook de admisión;
- El resultado del trabajo de varios controladores (y planificador).
Por lo tanto, cuando aparece una nueva configuración de un recurso (
nuevo ), no podemos simplemente tomar y sobrescribir la configuración actual "en vivo" (en
vivo ). Para hacer esto, tenemos que comparar
nuevo con la última configuración aplicada (
última aplicación ) y poner el parche resultante en
vivo .
Este enfoque se llama
fusión bidireccional . Se usa, por ejemplo, en Helm.
También hay una
fusión de 3 vías , que difiere en que:
- comparando el último aplicado y el nuevo , observamos lo que se ha eliminado;
- Al comparar lo nuevo y lo vivo , vemos lo que se ha agregado o cambiado;
- aplique el parche resumido para vivir .
Implementamos más de 1000 aplicaciones con Helm, por lo que en realidad vivimos con una fusión bidireccional. Sin embargo, tiene una serie de problemas que resolvimos con nuestros parches que ayudan a Helm a funcionar normalmente.
Estado de despliegue real
Después del próximo evento, nuestro sistema CI generó una nueva configuración para Kubernetes, la envía para
aplicar al clúster usando Helm o
kubectl apply . A continuación, tiene lugar la fusión N-way ya descrita, a lo que la API de Kubernetes aprueba el sistema CI y este último responde a su usuario.

Sin embargo, hay un gran problema: después de todo, una
aplicación exitosa no significa una implementación exitosa . Si Kubernetes entiende qué cambios aplicar, lo aplica, aún no sabemos cuál será el resultado. Por ejemplo, actualizar y reiniciar pods en la interfaz puede ser exitoso, pero no en el backend, y obtendremos diferentes versiones de las imágenes de la aplicación en ejecución.
Para hacer todo bien, surge un enlace adicional en este esquema: un rastreador especial que recibirá información de estado de la API de Kubernetes y la transmitirá para un análisis más detallado del estado real de las cosas. Creamos una biblioteca de código abierto en Go,
kubedog (vea su anuncio aquí ) , que resuelve este problema y está integrado en werf.
El comportamiento de este rastreador en el nivel werf se configura mediante anotaciones que se colocan en implementaciones o StatefulSets. La anotación principal,
fail-mode , comprende los siguientes significados:
IgnoreAndContinueDeployProcess : ignore los problemas de IgnoreAndContinueDeployProcess de este componente y continúe con la implementación;FailWholeDeployProcessImmediately : un error en este componente detiene el proceso de implementación;HopeUntilEndOfDeployProcess : esperamos que este componente funcione al final de la implementación.
Por ejemplo, una combinación de recursos y valores de anotación en
fail-mode :

Cuando se implementa por primera vez, es posible que la base de datos (MongoDB) aún no esté lista: las implementaciones se bloquearán. Pero puede esperar hasta el momento en que comience, y la implementación aún pasará.
Hay dos anotaciones más para kubedog en werf:
failures-allowed-per-replica - el número de caídas permitidas por réplica;show-logs-until : ajusta el momento hasta el cual werf muestra registros (en stdout) de todas las vainas que se están desplegando. De forma predeterminada, esto es PodIsReady (para ignorar los mensajes que apenas necesitamos cuando el tráfico comienza a llegar al pod), sin embargo, los valores ControllerIsReady y EndOfDeploy también EndOfDeploy .
¿Qué más queremos del despliegue?
Además de los dos puntos ya descritos, nos gustaría:
- ver registros , y solo es necesario, pero no todo;
- realizar un seguimiento del progreso , porque si un trabajo "en silencio" se cuelga durante varios minutos, es importante comprender lo que está sucediendo allí;
- tener una reversión automática en caso de que algo salga mal (y, por lo tanto, es fundamental conocer el estado real de la implementación). El despliegue debe ser atómico: o llega al final o todo vuelve a su estado anterior.
Resumen
Como empresa, para nosotros, para implementar todos los matices descritos en las diferentes etapas de entrega (compilación, publicación, implementación), el sistema CI y la utilidad
werf son
suficientes .
En lugar de una conclusión:

Con la ayuda de werf, hemos hecho un buen progreso en la resolución de una gran cantidad de problemas de los ingenieros de DevOps y nos alegrará si la comunidad en general al menos prueba esta utilidad en la práctica. Lograr un buen resultado juntos será más fácil.
Videos y diapositivas
Video de la actuación (~ 47 minutos):
Presentación del informe:
PS
Otros informes de Kubernetes en nuestro blog: