 Nota perev. : El entusiasmo que experimentaron los líderes de nuestro equipo cuando vieron este material en el blog de IBM Cloud, una especie de "extensión" de la legendaria aplicación Twelve-Factor, habla por sí mismo. Las preguntas planteadas por el autor no son solo de oído, sino que son realmente vitales, es decir. relevante en la vida cotidiana. Su comprensión es útil no solo para los ingenieros de DevOps, sino también para los desarrolladores que crean aplicaciones modernas que se ejecutan en Kubernetes.
Nota perev. : El entusiasmo que experimentaron los líderes de nuestro equipo cuando vieron este material en el blog de IBM Cloud, una especie de "extensión" de la legendaria aplicación Twelve-Factor, habla por sí mismo. Las preguntas planteadas por el autor no son solo de oído, sino que son realmente vitales, es decir. relevante en la vida cotidiana. Su comprensión es útil no solo para los ingenieros de DevOps, sino también para los desarrolladores que crean aplicaciones modernas que se ejecutan en Kubernetes.La conocida metodología de
aplicación de 12 factores es un conjunto de reglas claramente definidas para desarrollar microservicios. Son ampliamente utilizados para ejecutar, escalar e implementar aplicaciones. En la plataforma IBM Cloud Private, seguimos los mismos 12 principios al desarrollar aplicaciones en contenedores. El artículo "
Kubernetes y aplicaciones de 12 factores " discute los detalles del uso de estos 12 factores (son compatibles con el modelo de orquestación de contenedores de Kubernetes).
Pensando en los principios del desarrollo de microservicios en contenedores que funcionan bajo el control de Kubernetes, llegamos a la siguiente conclusión: los 12 factores anteriores son completamente ciertos, pero otros son extremadamente importantes para organizar un entorno de producción, en particular:
- observable
- previsibilidad (programable) ;
- actualizabilidad (actualizable) ;
- privilegios mínimos
- controlabilidad (auditable) ;
- seguridad (asegurable) ;
- medible
Detengámonos en estos principios e intentemos evaluar su significado. Para mantener la uniformidad, los agregamos a los existentes; en consecuencia, comenzaremos con XIII ...
Principio XIII: Observabilidad
Las aplicaciones deben proporcionar información sobre su estado actual e indicadores.Los sistemas distribuidos pueden ser difíciles de administrar porque muchos microservicios están integrados en una aplicación. De hecho, los diversos engranajes deben moverse en concierto para que el mecanismo (aplicación) funcione. Si ocurre una falla en uno de los microservicios, el sistema debería detectarlo y corregirlo automáticamente. Kubernetes proporciona excelentes mecanismos de rescate, como
pruebas de preparación y
vivacidad .
Con su ayuda, Kubernetes se asegura de que la aplicación esté lista para recibir tráfico. Si la preparación falla, Kubernetes deja de enviar tráfico al pod hasta que la próxima prueba muestre que el pod está listo.
Supongamos que tenemos una aplicación que consta de 3 microservicios: interfaz, lógica de negocios y una base de datos. Para que la aplicación funcione, antes de aceptar el tráfico, la interfaz de usuario debe asegurarse de que la lógica de negocios y las bases de datos estén listas. Esto se puede hacer usando la prueba de preparación: le permite asegurarse de que todas las dependencias estén funcionando.
La animación muestra que las solicitudes al pod no se envían hasta que la prueba de disponibilidad muestre su disponibilidad:
 Prueba de preparación en acción: Kubernetes utiliza una sonda de preparación para verificar si las cápsulas están listas para recibir tráfico
Prueba de preparación en acción: Kubernetes utiliza una sonda de preparación para verificar si las cápsulas están listas para recibir tráficoHay tres tipos de pruebas: usar HTTP, solicitudes TCP y comandos. Puede controlar la configuración de las pruebas, por ejemplo, indicar la frecuencia de los inicios, los umbrales de éxito / fracaso y cuánto tiempo esperar una respuesta. En el caso de las pruebas de vida, debe establecer un parámetro muy importante:
initialDelaySeconds . Asegúrese de que la prueba comience solo después de que la aplicación esté lista. Si este parámetro se configura incorrectamente, la aplicación se reiniciará constantemente. Así es como se puede implementar:
livenessProbe: # an http probe httpGet: path: /readiness port: 8080 initialDelaySeconds: 20 periodSeconds: 5
A través de pruebas de vitalidad, Kubernetes verifica si su aplicación se está ejecutando. Si la aplicación funciona normalmente, Kubernetes no hace nada. Si "murió", Kubernetes retira la cápsula y comienza una nueva a cambio. Esto corresponde a las necesidades de microservicios sin estado y su reciclabilidad (
factor IX, desechabilidad ). La siguiente animación ilustra una situación en la que Kubernetes reinicia el pod después de fallar la prueba de vivacidad:
 Prueba de vivacidad en acción: Kubernetes comprueba si las cápsulas están "vivas" con ella
Prueba de vivacidad en acción: Kubernetes comprueba si las cápsulas están "vivas" con ellaLa gran ventaja de estas pruebas es que puede implementar aplicaciones en cualquier orden sin preocuparse por las dependencias.
Sin embargo, descubrimos que estas pruebas no son suficientes para el entorno de producción. Por lo general, las aplicaciones tienen sus propias métricas que deben rastrearse, por ejemplo, el número de transacciones por segundo. Los clientes establecen umbrales para ellos y configuran notificaciones. IBM Cloud Private llena este vacío con la pila de monitoreo altamente segura de Prometheus y Grafana con un sistema de control de acceso basado en roles. Consulte la sección de
supervisión del clúster privado de IBM Cloud para obtener más información.
Prometheus recopila datos de destino a partir de métricas de punto final. Su aplicación debe especificar métricas de punto final utilizando la siguiente anotación:
prometheus.io/scrape: 'true'
Después de eso, Prometheus detecta automáticamente el punto final y recopila métricas de él (como se muestra en la siguiente animación):
 Colección de métricas personalizadasNota perev. : Sería más correcto girar las flechas en la dirección opuesta, ya que Prometeo camina y sondea los puntos finales, y Grafana toma datos de Prometeo, pero en el sentido de una ilustración general, esto no es tan crítico.
Colección de métricas personalizadasNota perev. : Sería más correcto girar las flechas en la dirección opuesta, ya que Prometeo camina y sondea los puntos finales, y Grafana toma datos de Prometeo, pero en el sentido de una ilustración general, esto no es tan crítico.Principio XIV: previsibilidad
Las aplicaciones deben proporcionar previsibilidad de los requisitos de recursos.Imagine que una guía ha elegido a su equipo para experimentar con un proyecto de Kubernetes. Trabajaste duro para crear un ambiente apropiado. El resultado es una aplicación que demuestra un tiempo de respuesta y rendimiento ejemplares. Luego, otro equipo se unió al trabajo. Ella creó su aplicación y la lanzó en el mismo entorno. Después de iniciar la segunda aplicación, el rendimiento de la primera disminuyó repentinamente. En este caso, la razón de este comportamiento debe buscarse en los recursos informáticos (CPU y memoria) disponibles para sus contenedores. Alta probabilidad de su deficiencia. Surge la pregunta: ¿cómo garantizar la asignación de los recursos informáticos que necesita la aplicación?
Kubernetes tiene una excelente opción que le permite establecer mínimos de recursos y restricciones para contenedores. Los mínimos están garantizados. Si un contenedor requiere un recurso, Kubernetes lo ejecuta solo en el host que este recurso puede proporcionar. Por otro lado, el límite superior asegura que el apetito del contenedor nunca exceda un cierto valor.
 Mínimos y restricciones para contenedores
Mínimos y restricciones para contenedoresEl siguiente fragmento de código YAML muestra el ajuste de los recursos informáticos:
resources: requests: memory: "64Mi" cpu: "150m" limits: memory: "64Mi" cpu: "200m"
Nota perev. : Para obtener más información sobre cómo proporcionar recursos en Kubernetes, solicitudes y límites, consulte nuestro informe reciente y su revisión, " Escalado automático y gestión de recursos en Kubernetes ", así como la documentación de K8s .Otra oportunidad interesante para los administradores en un entorno de producción es establecer cuotas para el
espacio de
nombres . Si se establece la cuota, Kubernetes no creará contenedores para los que las solicitudes / límites no están definidos en este espacio de nombres. Un ejemplo de cómo establecer cuotas para el espacio de nombres se puede ver en la figura a continuación:
 Cuotas para espacios de nombres
Cuotas para espacios de nombresPrincipio XV. Capacidad de actualización
Las aplicaciones deben actualizar los formatos de datos de generaciones anteriores.A menudo es necesario parchear una aplicación de producción en funcionamiento para eliminar una vulnerabilidad o ampliar la funcionalidad. Es importante que la actualización se realice sin interrupciones en el trabajo. Kubernetes proporciona
un mecanismo de actualización continua que le permite actualizar su aplicación sin tiempo de inactividad. Usando este mecanismo, puede actualizar por pod a la vez sin detener todo el servicio. Aquí hay una representación esquemática de este proceso (en él, la aplicación se actualiza a la segunda versión):

Un ejemplo de una descripción de YAML correspondiente:
minReadySeconds: 5 strategy: # , type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 1
Presta atención a los
maxSurge maxUnavailable y
maxSurge :
maxUnavailable : un parámetro opcional que establece el número máximo de pods que pueden no estar disponibles durante el proceso de actualización. Aunque es opcional, todavía vale la pena establecer un valor específico para garantizar la disponibilidad del servicio;maxSurge es otro parámetro opcional pero crítico. Establece el número máximo de pods que se pueden crear en exceso de su número deseado.
Principio XVI: privilegios mínimos
Los contenedores deben funcionar con un mínimo de privilegios.Suena pesimista, pero debe pensar en cada resolución en el contenedor como una vulnerabilidad potencial (vea la ilustración). Por ejemplo, si el contenedor se ejecuta como root, cualquier persona con acceso a él puede inyectar allí un proceso malicioso. Kubernetes proporciona una
Política de seguridad de pod (PSP) para restringir el acceso al sistema de archivos, el puerto host, las capacidades de Linux y más. IBM Cloud Private ofrece un conjunto de PSP listo para usar que se une a los contenedores cuando se aprovisionan en el espacio de nombres. Para obtener más información, consulte
Uso de espacios de nombres con políticas de seguridad de pod .
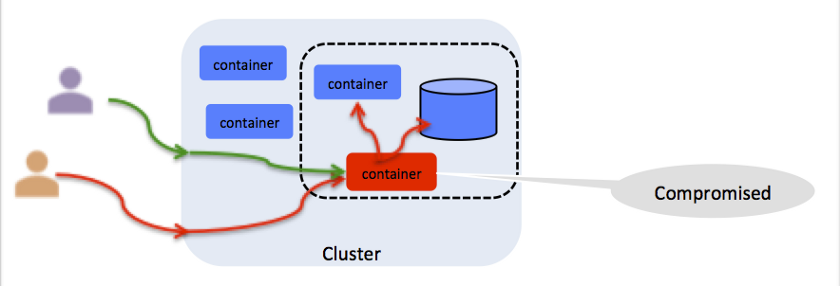 Toda resolución es un vector de ataque potencial
Toda resolución es un vector de ataque potencialPrincipio XVII: Controlabilidad
Necesita saber quién, qué, dónde y cuándo para todas las operaciones de misión crítica.La capacidad de control es crítica para cualquier operación con un clúster o aplicación Kubernetes. Por ejemplo, si la aplicación procesa transacciones de tarjeta de crédito, debe habilitar una auditoría para tener un seguimiento de control de cada transacción. IBM Cloud Private utiliza la
Federación de Datos de Auditoría de la Nube (CADF), estándar de la industria, que es invariable para implementaciones específicas de la nube. Para obtener más información, consulte
Registro de auditoría en IBM Cloud Private .
Un evento CADF contiene los siguientes datos:
initiator_id : ID del usuario que realizó la operación;target_uri - URI CADF objetivo (por ejemplo: datos / seguridad / proyecto);action : la action realizar, generalmente operation: resource_type .
Principio XVIII: Seguridad (identificación, red, alcance, certificados)
Es necesario proteger la aplicación y los recursos de extraños.Este artículo merece un artículo separado. Baste decir que las aplicaciones de producción necesitan protección de extremo a extremo. IBM Cloud Private toma las siguientes medidas para garantizar la seguridad de los entornos de producción:
- autenticación: verificación de identidad;
- autorización: verificación de acceso de usuario autenticado;
- gestión de certificados: trabaje con certificados digitales, incluida la creación, el almacenamiento y la renovación;
- protección de datos: garantizar la seguridad de los datos transmitidos y almacenados;
- seguridad y aislamiento de la red: evitar el acceso a la red por parte de usuarios y procesos no autorizados;
- asesor de vulnerabilidades: identificación de vulnerabilidades en imágenes;
- Asesor de mutaciones: detección de mutaciones en contenedores.
Para obtener más información, consulte la
Guía de seguridad privada de IBM Cloud .
De particular interés es el administrador de certificados.
Este servicio en IBM Cloud Private se basa en el proyecto de
código abierto
Jetstack . Certificate Manager le permite emitir y gestionar certificados para servicios que se ejecutan en IBM Cloud Private. Admite certificados públicos y autofirmados, se integra completamente con
kubectl y control de acceso basado en roles.
Principio XIX: Medibilidad
El uso de la aplicación debe ser medible a efectos de cuotas y acuerdos entre departamentos.En última instancia, las empresas tienen que pagar los costos de TI (consulte la figura a continuación). Los recursos informáticos dedicados a ejecutar contenedores deben ser medibles, y las organizaciones que usan el clúster deben ser responsables. Asegúrese de seguir el Principio XIV - Previsibilidad. IBM Cloud Private ofrece un
servicio de contabilidad que recopila datos sobre recursos informáticos para cada contenedor y los combina en el nivel del espacio de nombres para realizar más cálculos (como parte de las devoluciones o devoluciones de cargo).
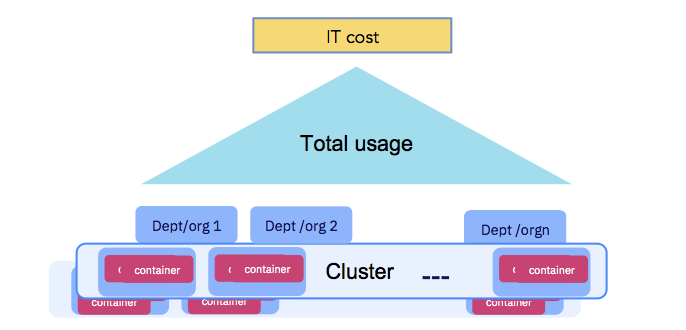 El uso de la aplicación debe ser medible.
El uso de la aplicación debe ser medible.Conclusión
Espero que les haya gustado el tema planteado en este artículo, hayan notado los factores que ya están utilizando y hayan pensado en aquellos que aún están al margen.
Para obtener más información, le recomiendo que se familiarice con la
grabación de nuestra actuación en KubeCon 2019 en Shanghai. En él,
Michael Elder y
yo discutimos los principios 12 + 7 para la orquestación de contenedores basada en Kubernetes.
PD del traductor
Lea también en nuestro blog: