Nota perev. : La autora de este material es Cindy Sridharan, una ingeniera de imgix que participa en el desarrollo de API y, en particular, prueba de microservicios. En este artículo, comparte su visión detallada de los problemas reales en el campo del rastreo distribuido, donde, en su opinión, faltan herramientas verdaderamente efectivas para resolver problemas apremiantes.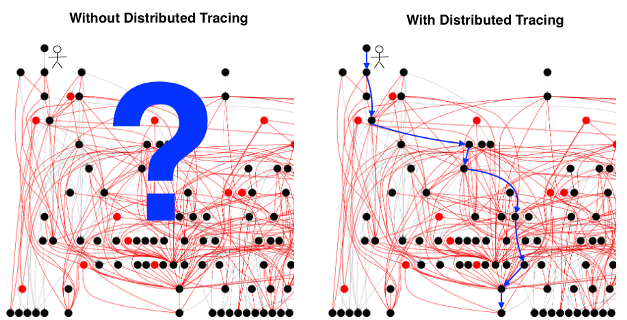 [La ilustración está tomada de otro material sobre el rastreo distribuido.]
[La ilustración está tomada de otro material sobre el rastreo distribuido.]Se cree que el
rastreo distribuido es difícil de implementar, y el retorno
es dudoso en el mejor de los casos . El "problema" de la traza se explica por muchas razones, que a menudo se refieren a la complejidad de configurar cada componente del sistema para transmitir los encabezados correspondientes junto con cada solicitud. Aunque este problema ocurre, no se puede llamar insuperable en absoluto. Por cierto, no explica por qué a los desarrolladores realmente no les gusta el rastreo (incluso si ya funciona).
La principal dificultad con el rastreo distribuido es no recopilar datos, no estandarizar los formatos para distribuir y presentar los resultados, y no determinar cuándo, dónde y cómo muestrear. No estoy tratando de presentar estos "problemas de digestibilidad" como
triviales ; de hecho, existen desafíos técnicos y políticos bastante significativos (si realmente estamos analizando los
estándares y protocolos de código abierto) que deben superarse para que estos problemas puedan considerarse resuelto
Sin embargo, si imagina que todos estos problemas se han resuelto, es probable que nada cambie significativamente en términos de
la experiencia del usuario final . El seguimiento puede no ser práctico en los escenarios de depuración más comunes, incluso después de que se haya implementado.
Un rastro tan diferente
El rastreo distribuido incluye varios componentes dispares:
- equipar aplicaciones y middleware con controles;
- Transmisión de contexto distribuido
- colección de trazas;
- almacenamiento de trazas;
- su extracción y visualización.
Mucho se habla sobre el rastreo distribuido se reduce a considerarlo como una especie de operación unaria, cuyo único propósito es ayudar en el diagnóstico completo del sistema. Esto se debe en gran medida a la forma en que se formó el concepto de rastreo distribuido. En
una publicación de blog realizada cuando se abrieron las fuentes de Zipkin, se mencionó que
él [Zipkin] acelera Twitter . Las primeras ofertas comerciales para el rastreo también se promocionaron como
herramientas APM .
Nota perev. : Para que el texto adicional se entienda mejor, definimos dos términos básicos de acuerdo con la documentación del proyecto OpenTracing :- Span : el elemento básico del rastreo distribuido. Es una descripción de un determinado flujo de trabajo (por ejemplo, una consulta de base de datos) con un nombre, horas de inicio y finalización, etiquetas, registros y contexto.
- Los tramos generalmente contienen enlaces a otros tramos, lo que le permite combinar muchos tramos en Trace , una visualización de la vida de una solicitud a medida que se mueve a través de un sistema distribuido.
Trace'y contiene datos increíblemente valiosos que pueden ayudar en tareas tales como: pruebas en producción, realización de pruebas de recuperación ante desastres, pruebas con la introducción de errores, etc. De hecho, algunas empresas ya utilizan el rastreo para tales fines. Para comenzar,
la transferencia de contexto universal tiene otros usos además de simplemente transferir tramos al sistema de almacenamiento:
- Por ejemplo, Uber usa resultados de rastreo para distinguir entre el tráfico de prueba y el tráfico de producción.
- Facebook utiliza datos de rastreo para analizar la ruta crítica y para cambiar el tráfico durante las pruebas regulares de recuperación ante desastres.
- La red social también utiliza portátiles Jupyter, que permiten a los desarrolladores ejecutar consultas arbitrarias sobre los resultados del rastreo.
- Los adherentes a la inyección de falla impulsada por linaje ( LDFI) usan trazas distribuidas para pruebas de error.
Ninguna de las opciones anteriores se relaciona completamente con el escenario de
depuración , durante el cual el ingeniero intenta resolver el problema observando el rastro.
Cuando se trata del escenario de depuración, el diagrama de vista de
rastreo sigue siendo la interfaz principal (aunque algunos también lo llaman el
"diagrama de Gantt" o el
"diagrama en cascada" ). Por
traceview, me
refiero a todos los tramos y metadatos asociados que juntos forman el rastreo. Cada sistema de rastreo de código abierto, así como cada solución de rastreo comercial, ofrece una
interfaz de usuario basada en
traceview para visualizar, detallar y filtrar datos de rastreo.
El problema con todos los sistemas de rastreo con los que he estado familiarizado en este momento es que la
visualización final
(vista de rastreo) refleja casi por completo las características del proceso de generación de rastreo. Incluso cuando se ofrecen visualizaciones alternativas: mapas de intensidad (mapa de calor), topologías de servicio, histogramas de latencia, al final todavía se reducen a la
vista de
rastreo .
En el pasado, me
quejé de que la mayoría de las "innovaciones" en la trazabilidad con respecto a UI / UX parecen
estar limitadas a
incluir metadatos adicionales en el rastreo, incrustar información con
alta cardinalidad en ellos o proporcionar la capacidad de profundizar en tramos específicos o ejecutar consultas
inter e intra-trace . En este caso,
traceview sigue siendo el principal medio de visualización. Mientras persista este estado de cosas, el rastreo distribuido ocupará (en el mejor de los casos) el 4to lugar como herramienta de depuración, seguido de métricas, registros y seguimientos de pila, y en el peor de los casos resultará una pérdida de dinero y tiempo.
Problema con traceview
El propósito de
traceview es proporcionar una imagen completa del movimiento de una solicitud individual en todos los componentes de un sistema distribuido con el que se relaciona. Algunos sistemas de rastreo más avanzados le permiten profundizar en tramos individuales y ver el desglose de tiempo
dentro de un solo proceso (cuando los tramos tienen límites funcionales).
La premisa básica de la arquitectura de microservicios es la idea de que la estructura organizacional crece con las necesidades de la empresa. Los defensores de los microservicios argumentan que la distribución de varias tareas comerciales a través de servicios separados permite a los equipos de desarrollo pequeños y autónomos controlar todo el ciclo de vida de dichos servicios, lo que les permite crear, probar e implementar estos servicios de forma independiente. Sin embargo, la desventaja de esta distribución es la pérdida de información sobre cómo cada servicio interactúa con los demás. En tales circunstancias, el rastreo distribuido afirma ser una herramienta indispensable para
depurar interacciones complejas entre servicios.
Si tiene un
sistema distribuido realmente
increíblemente complejo , nadie podrá tener en cuenta su imagen
completa . De hecho, desarrollar una herramienta basada en el supuesto de que generalmente es posible es un poco antipatrón (enfoque ineficiente e improductivo). Idealmente, la depuración requiere una herramienta para ayudar a
reducir su búsqueda para que los ingenieros puedan centrarse en un subconjunto de las dimensiones (servicios / usuarios / hosts, etc.) que son relevantes para el escenario en cuestión. Al determinar la causa de la falla, los ingenieros no están obligados a comprender lo que sucedió en
todos los servicios a la vez , ya que tal requisito contradiría la idea misma de una arquitectura de microservicio.
Sin embargo, traceview es
solo eso. Sí, algunos sistemas de rastreo ofrecen vistas de rastreo comprimidas cuando el número de tramos en el rastreo es tan grande que no se pueden mostrar en una sola visualización. Sin embargo, debido a la gran cantidad de información contenida incluso en una visualización tan truncada, los ingenieros aún se
ven obligados a "filtrarla", reduciendo manualmente la selección a un conjunto de problemas de fuentes de servicio. Por desgracia, en este campo las máquinas son mucho más rápidas que los humanos, menos propensas a errores y sus resultados son más repetibles.
Otra razón por la que creo que el método de seguimiento es incorrecto es porque no es adecuado para la depuración hipotética. En esencia, la depuración es un proceso
iterativo que comienza con una hipótesis, seguido de la verificación de varias observaciones y hechos recibidos del sistema utilizando diferentes vectores, conclusiones / generalizaciones y una evaluación adicional de la verdad de la hipótesis.
La capacidad
de probar hipótesis de forma
rápida y económica y mejorar el modelo mental en consecuencia es la
piedra angular de la depuración. Cualquier herramienta de depuración debe ser
interactiva y reducir el espacio de búsqueda o, en el caso de una traza falsa, permitir al usuario regresar y enfocarse en otra área del sistema. Una herramienta ideal lo hará de forma
proactiva , atrayendo inmediatamente la atención del usuario hacia áreas potencialmente problemáticas.
Por desgracia,
traceview no se puede llamar una herramienta de interfaz interactiva. Lo mejor que puede esperar al usarlo es detectar una determinada fuente de mayores retrasos y ver todo tipo de etiquetas y registros asociados con él. Esto no ayuda al ingeniero a identificar
patrones en el tráfico, como los detalles de la distribución de demoras, ni a detectar correlaciones entre diferentes mediciones.
El análisis de trazas genérico puede solucionar algunos de estos problemas. De hecho,
hay ejemplos de análisis exitosos que utilizan el aprendizaje automático para identificar tramos anormales e identificar un subconjunto de etiquetas que pueden estar asociadas con un comportamiento anormal. Sin embargo, todavía no he encontrado visualizaciones convincentes de hallazgos realizados mediante aprendizaje automático o análisis de datos aplicados a tramos que serían significativamente diferentes de traceview o DAG (gráfico acíclico direccional).
Los tramos tienen un nivel demasiado bajo.
El problema fundamental con traceview es que los
tramos son primitivas de nivel demasiado bajo para el análisis de latencia y el análisis de causa raíz. Es como analizar comandos de procesador individuales en un intento de eliminar una excepción, sabiendo que hay herramientas de nivel mucho más alto, como la traza inversa, con las que es mucho más conveniente trabajar.
Además, me tomaré la libertad de afirmar lo siguiente: idealmente, no necesitamos una
imagen completa de lo que sucedió durante el ciclo de vida de la solicitud, que representan las herramientas modernas para el rastreo. En cambio, se requiere alguna forma de abstracción de nivel superior, que contenga información sobre lo que
salió mal (similar a la traza inversa), junto con algún contexto. En lugar de observar todo el rastro, prefiero ver
parte de él donde sucede algo interesante o inusual. Actualmente, la búsqueda se lleva a cabo manualmente: el ingeniero recibe un rastro y analiza de forma independiente los tramos en busca de algo interesante. El enfoque cuando las personas miran los tramos en trazas separadas con la esperanza de detectar actividad sospechosa no se escala en absoluto (especialmente cuando tienen que comprender todos los metadatos codificados en diferentes tramos, como la identificación del intervalo, el nombre del método RPC, la duración del intervalo 'a, registros, etiquetas, etc.).
Alternativas de seguimiento
Los resultados de rastreo son más útiles cuando se pueden visualizar de tal manera que se obtenga una idea no trivial de lo que está sucediendo en las partes interconectadas del sistema. Hasta que este sea el caso, el proceso de depuración permanece en gran medida
inerte y depende de la capacidad del usuario para notar las correlaciones correctas, verificar las partes correctas del sistema o ensamblar piezas del mosaico, a diferencia de la
herramienta que ayuda al usuario a formular estas hipótesis.
No soy un diseñador visual o un especialista en UX, pero en la siguiente sección quiero compartir algunas ideas sobre cómo se verían esas visualizaciones.
Centrarse en servicios específicos.
En un entorno en el que la industria se está consolidando en torno a las ideas de
SLO (objetivos de nivel de servicio) y SLI (indicadores de nivel de servicio) , parece razonable que los equipos individuales primero deben monitorear la relevancia de sus servicios para estos objetivos. Se deduce que
la visualización
orientada al servicio es la más adecuada para dichos equipos.
Las trazas, especialmente sin muestreo, son un depósito de información sobre cada componente de un sistema distribuido. Esta información se puede enviar a un controlador complicado que entregará hallazgos orientados al
servicio a los usuarios, que pueden detectarse con anticipación, incluso antes de que el usuario mire los rastros:
- Retrase los diagramas de distribución solo para solicitudes muy distinguidas (solicitudes atípicas) ;
- Retrasar los diagramas de distribución para casos en los que no se alcanzan los objetivos de servicio de SLO;
- Las etiquetas más "comunes", "interesantes" y "extrañas" en las consultas, que se repiten con mayor frecuencia;
- Desglose de demoras para casos en que las dependencias de servicio no alcanzan los objetivos de SLO establecidos;
- Desglose de retrasos por diversos servicios posteriores.
Las métricas integradas simplemente no pueden responder algunas de estas preguntas, lo que obliga a los usuarios a estudiar cuidadosamente los tramos. Como resultado, tenemos un mecanismo extremadamente hostil para el usuario.
A este respecto, surge la pregunta: ¿qué pasa con las complejas interacciones entre los diversos servicios controlados por diferentes equipos? ¿No se considera que
traceview es la herramienta más adecuada para cubrir tal situación?
Los desarrolladores móviles, propietarios de servicios sin estado, propietarios de servicios administrados con estado (como bases de datos) y propietarios de plataformas pueden estar interesados en otra
vista de un sistema distribuido;
traceview es una solución demasiado universal para estas necesidades fundamentalmente diferentes. Incluso en una arquitectura de microservicios muy compleja, los propietarios de servicios no necesitan un conocimiento profundo de más de dos o tres servicios ascendentes y descendentes. En esencia, en la mayoría de los escenarios, los usuarios solo necesitan responder preguntas sobre un
conjunto limitado de servicios .
Es como mirar un pequeño subconjunto de servicios a través de una lupa en aras de un estudio meticuloso. Esto permitirá al usuario hacer preguntas más urgentes con respecto a la compleja interacción entre estos servicios y sus dependencias inmediatas. Esto es similar a la traza en el mundo de los servicios, donde el ingeniero sabe
lo que está mal y también tiene una idea de lo que está sucediendo en los servicios circundantes para comprender
por qué .
El enfoque que estoy promoviendo es exactamente el opuesto al enfoque de arriba hacia abajo basado en la vista de rastreo, cuando el análisis comienza con el rastreo completo y luego desciende gradualmente a tramos individuales. Por el contrario, el enfoque ascendente comienza con un análisis de un área pequeña cercana a la causa potencial del incidente, y luego el espacio de búsqueda se amplía si es necesario (con la posible participación de otros equipos para analizar una gama más amplia de servicios). El segundo enfoque es más adecuado para probar rápidamente las hipótesis iniciales. Después de obtener resultados específicos, será posible pasar a un análisis más centrado y detallado.
Edificio de topología
Las vistas asociadas con un servicio en particular pueden ser increíblemente útiles si el usuario sabe
qué servicio o grupo de servicios es responsable de aumentar las demoras o es una fuente de errores. Sin embargo, en un sistema complejo, la identificación de un intruso puede no ser una tarea trivial durante una falla, especialmente si no se han recibido mensajes de error de los servicios.
La creación de una topología de servicio puede ser muy útil para determinar qué servicio muestra un aumento en la tasa de error o un aumento en la latencia, lo que lleva a un deterioro notable en el rendimiento del servicio. Hablando sobre la construcción de una topología, no me refiero a
un mapa de servicios que muestre todos los servicios disponibles en el sistema y conocidos por sus
mapas de arquitectura en forma de estrella de la muerte . Tal representación no es mejor que una vista de rastreo basada en un gráfico acíclico dirigido. En cambio, me gustaría ver una
topología de servicio generada dinámicamente basada en ciertos atributos, como la tasa de error, el tiempo de respuesta o cualquier parámetro especificado por el usuario que ayude a aclarar la situación con servicios sospechosos específicos.
Veamos un ejemplo. Imagine un sitio hipotético de noticias. El servicio de
portada se comunica con Redis, con un servicio de recomendación, con un servicio de publicidad y servicio de video. El servicio de video toma videos de S3 y los metadatos de DynamoDB. El servicio de recomendación recibe metadatos de DynamoDB, descarga datos de Redis y MySQL, escribe mensajes en Kafka. El servicio de publicidad recibe datos de MySQL y escribe mensajes a Kafka.
La siguiente es una representación esquemática de esta topología (muchos programas de enrutamiento comerciales crean la topología). Puede ser útil si necesita comprender las dependencias de los servicios. Sin embargo, durante la
depuración , cuando un determinado servicio (por ejemplo, un servicio de video) demuestra un mayor tiempo de respuesta, dicha topología no es muy útil.
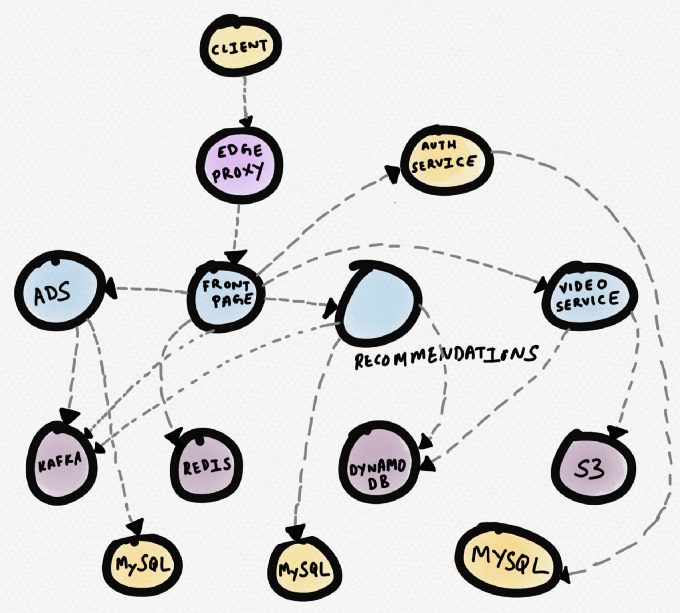 Esquema hipotético de servicios del sitio de noticias
Esquema hipotético de servicios del sitio de noticiasEl siguiente diagrama sería mejor. En él se representa un servicio problemático
(video) justo en el centro. El usuario lo nota de inmediato. A partir de esta visualización, queda claro que el servicio de video funciona de manera anormal debido al mayor tiempo de respuesta de S3, que afecta la velocidad de descarga de parte de la página principal.
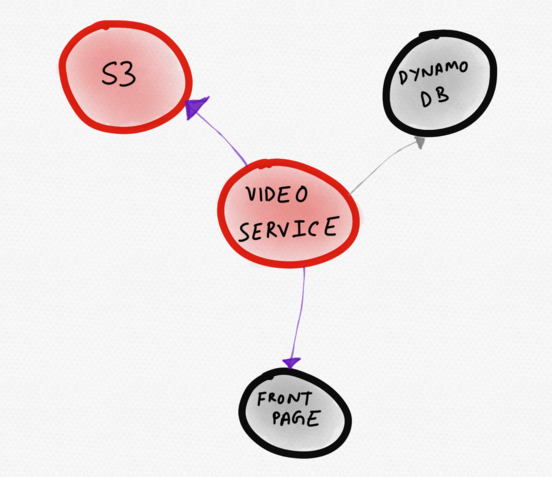 Topología dinámica que muestra solo servicios "interesantes"
Topología dinámica que muestra solo servicios "interesantes"Los esquemas topológicos generados dinámicamente pueden ser más eficientes que los mapas de servicios estáticos, especialmente en infraestructuras flexibles y autoescalables. La capacidad de comparar y contrastar topologías de servicio permite al usuario hacer preguntas más relevantes. Las preguntas más precisas sobre el sistema tienen más probabilidades de conducir a una mejor comprensión de cómo funciona el sistema.
Pantalla comparativa
Otra visualización útil sería una pantalla comparativa. Las trazas actualmente no son adecuadas para comparaciones de lado a lado, por lo que generalmente se comparan los
tramos . Y la idea principal de este artículo es precisamente que los tramos son de nivel demasiado bajo para extraer la información más valiosa de los resultados de seguimiento.
La comparación de dos trace'ov no exige visualizaciones fundamentalmente nuevas. De hecho, algo como un histograma que representa la misma información que traceview es suficiente. Sorprendentemente, incluso este método simple puede traer mucho más fruto que un simple estudio de dos trazas por separado. Aún más potente sería la capacidad de
visualizar la comparación de trazas
en el agregado . Sería extremadamente útil ver cómo un cambio de configuración de la base de datos recientemente implementado con la inclusión de GC (recolección de basura) afecta el tiempo de respuesta de un servicio posterior en unas pocas horas. Si lo que estoy describiendo aquí parece un análisis A / B del impacto de los cambios
en la infraestructura
en una variedad de servicios utilizando resultados de seguimiento, entonces no está muy lejos de la verdad.
Conclusión
No cuestiono la utilidad de la traza misma. Sinceramente, creo que no hay otra forma de recopilar datos tan ricos, casuales y contextuales como los que se encuentran en la traza. , . , traceview-, , , trace'. , , .
, , . ,
, . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PD del traductor
Lea también en nuestro blog: