¡Hola a todos, recientemente
escribimos sobre cómo aprendimos a manejar los datos con GoPractice Simulator! En este número continuaremos con el tema del análisis de datos y hablaremos sobre cómo construir el proceso de trabajo con análisis en el equipo de Plesk.
Plesk es un producto complejo con 20 años de experiencia y no siempre pudimos recopilar de manera efectiva las estadísticas necesarias. Durante mucho tiempo, observamos los datos solo en retrospectiva, y las decisiones se tomaron sobre la base de sensaciones subjetivas "como debería ser". En el pasado, ya teníamos las tristes consecuencias de este enfoque: en 2012 cambiamos el diseño, deseando hacer lo mejor, pero recibimos una ola de comentarios negativos, rechazo a actualizar a la última versión del producto y la salida de clientes.
Habiendo comprendido esta triste experiencia, llegamos a conclusiones y decidimos avanzar hacia el establecimiento de una empresa Data Driven. De esta manera, nos esperaban dificultades de diferente naturaleza. A gran escala, se pueden dividir en dos grupos principales: sistema y proceso, y en este artículo me centraré en la tarea de construir el proceso de trabajar con análisis.
Los problemas sistémicos asociados con los detalles del producto en caja merecen un artículo separado, por lo que no me detendré en ellos aquí en detalle, solo enumeraré los más importantes.
- Muchos eventos, altos volúmenes de uso. Si solo hablamos sobre el seguimiento de las acciones de los usuarios en el panel, de acuerdo con nuestros cálculos, son 60 millones de eventos por mes y es una pena dar $ 150k para Google Analytics avanzado. Otra dificultad es que para trabajar con GA, debe manejar explícitamente cada acción personalizada, pero queríamos obtener un mecanismo unificado que no requiera marcar manualmente eventos o acciones para cada nueva característica.
- Debido al volumen y al formato de la caja (la implementación de cualquier cambio lleva tiempo), los análisis no pueden hacerlo en tiempo real. Los usuarios están sentados en 8 versiones diferentes del producto, con 4 de ellos ya EOLed. Incluso en las últimas versiones, solo el 60% de los usuarios reciben nuevos cambios en las primeras dos semanas después del lanzamiento.
- Producto complejo Plesk admite 14 sistemas operativos de la familia Linux, 4 OC Windows, un componente de terceros de 150, varios servidores web, servidores de correo, clientes de correo web, visualizadores de estadísticas, soluciones antivirus, etc. Una gran cantidad de configuraciones posibles afecta principalmente la complejidad y el volumen de las pruebas y hace que sea casi imposible usar pruebas A / B.
- Especificaciones B2B2C. El tomador de decisiones no siempre es igual al "usuario real del panel".
- RGPD: la necesidad de cumplir con la letra de la ley requiere esfuerzos adicionales para anonimizar los datos y complica las tareas de segmentación del usuario, y también nos priva de la capacidad de contactarnos de manera fácil y rápida a los clientes utilizando su información de contacto.
Hablaremos sobre los dolores del proceso con más detalle. Hasta hace poco, el proceso de recopilar análisis con nosotros estaba completamente divorciado del proceso de desarrollo: recordamos el seguimiento y las métricas al final, arruinamos una solución única, y así sucesivamente hasta la próxima característica. Además, a lo largo de los años, Plesk ha acumulado un montón de fuentes de datos, lo que conlleva los costos de mantener la consistencia, relevancia de los datos, la necesidad de tener en cuenta de dónde provienen, en qué condiciones llega a la base de datos y por qué las mismas métricas en diferentes lugares. difieren (por ejemplo, el número de claves de licencia e instalaciones físicas). Se escribió una gran cantidad de información en estas fuentes (recortes mensuales de una base de datos de 270 mil claves e informes que llegan el doble de 300 mil servidores), pero solo unas pocas personas pudieron trabajar con estos datos y encontraron tiempo. Llegué a Plesk en 2015, y mis primeras tareas fueron solo obtener estadísticas heterogéneas del cubo OLAP y la base de datos MongoDB. 'Cómo' a esta base de datos era una página con un nombre de usuario y contraseña del host y un archivo de texto con un script js de la última solicitud popular.
Un montón de fuentes significaba un montón de herramientas y servicios, cada uno de los cuales debería ser capaz de usar cada Gerente de Programa. La sensación en los primeros días de trabajo era algo así:

Que hemos hecho
La solución fue la siguiente: hace aproximadamente un año y medio, comenzamos una revisión completa del proceso de recopilación de datos: ahora desarrollamos análisis de la misma manera que la característica en sí, en cada etapa participa todo el equipo (equipo de características), desde PM y desarrollo hasta ingeniero de control de calidad.
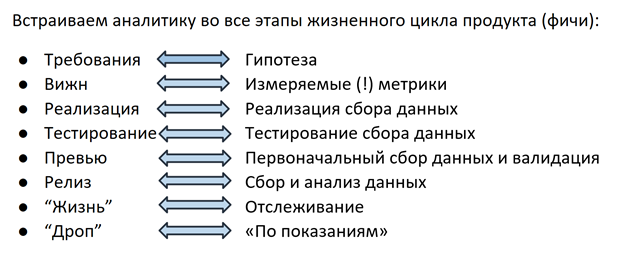
Hipótesis
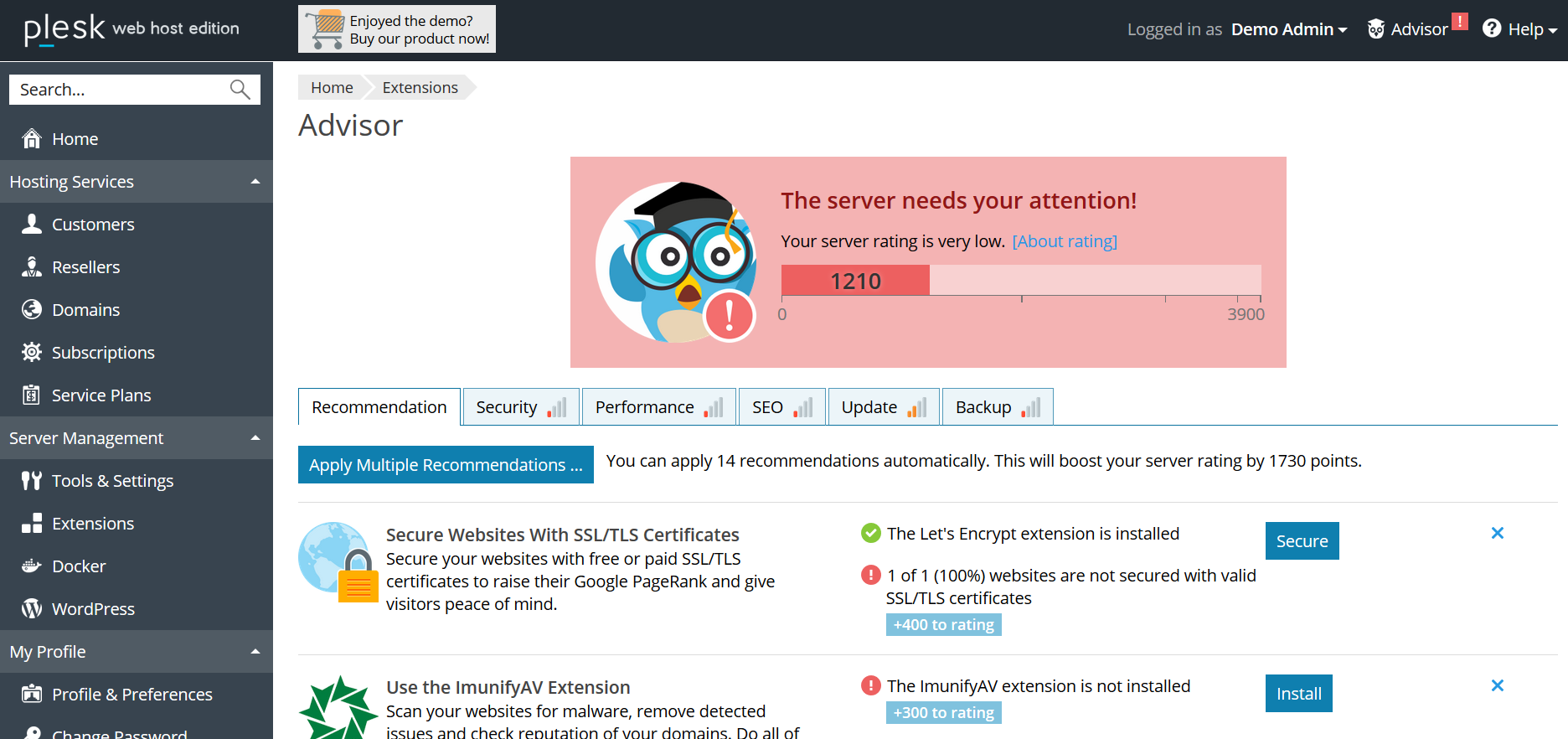
Todo comienza en la etapa de planificación de características: PM formula una hipótesis en base a la cual se seleccionará la métrica en el siguiente paso. Por ejemplo: Plesk tiene un sistema de recomendación de Asesores que ayuda al usuario a mejorar el estado del servidor siguiendo los pasos propuestos (agregar un certificado SSL, habilitar actualizaciones, actualizar la versión de PHP, etc.). Al lanzar Advisor, asumimos que el usuario seguirá las recomendaciones, la calificación de "estado" del servidor aumentará y, gracias a los "logros" gamificados, el usuario estará involucrado en la interacción con el Asesor de manera continua.
Métrica
En el siguiente paso, se selecciona una métrica para cada hipótesis: para Advisor, este es el número de clics en las recomendaciones, el porcentaje de sitios protegidos por certificados, puntaje de calificación, etc. Toda esta información (hipótesis + métrica) se ingresa en el documento Visión - con los requisitos para las características. En este punto, los analistas de datos están involucrados en el proceso; su tarea es ayudar a que la métrica sea medible, fácil de recopilar y sin ambigüedades. Incluso detalles como la estructura del campo futuro en la base de datos o el informe son importantes, ya que el primer ministro responsable de la función accederá con mayor frecuencia a esta información, le interesa determinar cómo es más conveniente hacerlo, hasta la estructura deseada de la solicitud de la base de datos. Gracias a este enfoque, por cierto, se ha vuelto más fácil para todos en el sentido de que la necesidad de escalar a 100.500 fuentes ha disminuido significativamente: ahora usted decide en qué formato se recopilarán los datos y cómo prefiere obtenerlos. Al fijar la lógica de contar en una vista, el primer ministro también tiene la oportunidad en cualquier momento de volver al documento y recordar por qué criterios la base de datos ingresa / aumenta el contador / el hecho de enviar, etc. Esto resuelve el problema de comprender la lógica de los informes.
Implementación
Cuando se formula una hipótesis y se selecciona una métrica, es el turno de la implementación. Los desarrolladores implementan al mismo tiempo la función en sí y el mecanismo para recopilar sus estadísticas. Como ya se mencionó, el uso de soluciones preparadas como GA es difícil para nosotros por varias razones, por lo tanto, hace 2 años, nuestros ingenieros implementaron su propio mecanismo para rastrear las acciones de los usuarios en el panel. Además de las acciones del usuario, también pueden ser de interés diversos detalles técnicos, ajustes de configuración, etc. - Todo esto se envía a la base de datos MongoDB ya mencionada.
Pruebas y avances
Al igual que cualquier producto, el mecanismo de recopilación de datos debe probarse: en nuestro caso, el ingeniero de control de calidad verifica que las recomendaciones se muestren y se abran, se supervise la calificación y se recopile información sobre todos estos eventos en la base de datos. A menudo, los casos de uso seleccionados para el seguimiento y el análisis se convierten en nuevos casos de prueba para probar la funcionalidad de la función en sí.
Después de que el ingeniero de control de calidad verificó todos los escenarios, el primer ministro junto con el desarrollador examinó los primeros datos y se aseguró de que la función 1) no rompiera nada y 2) funciona como se esperaba, y las estadísticas recopilan lo que le interesa: todo está listo para su lanzamiento en liberar.
Característica de vida
Cuando se lanza una característica en un lanzamiento, comienza la parte más interesante: su "vida" en el producto. No más tiradas: “¿sabes qué campo de nuestra base de datos almacena información sobre cómo mostrar recomendaciones? no? blin ... ". El analista de datos no recibe mensajes en vacío: "¿puede contar de nuevo cuántas impresiones hay en la última versión?" - para esto hay gráficos en los tableros con alertas configuradas que envían cartas si el valor monitoreado se redujo bruscamente / aumentó / cambió / no se encontraron registros en la base de datos. Pero eso no es todo. Comprender que el contador ha aumentado o disminuido en un n% no siempre es suficiente para decir con confianza que se trata de un cambio significativo, y no un salto o fluctuación estacional dentro del margen de error. Uno de los miembros de nuestro equipo está desarrollando un marco para medir la importancia estadística de los cambios métricos. Usando el aparato de estadística matemática, calcula la muestra mínima (el número de usuarios / instalaciones / eventos) necesaria para evaluar la importancia de los cambios, selecciona segmentos entre los que puede comparar y determina el intervalo de confianza que probablemente contiene el valor real de la métrica de interés para nosotros. Este marco ya se probó y dio resultados interesantes la semana pasada: descubrimos que después de que comenzamos a mostrar los precios en el catálogo de extensiones dentro del panel de Plesk, la gente comenzó a comprar menos claves de licencia anuales y con mayor frecuencia mensual para estos productos. En este momento, nuestros colegas están calculando el pronóstico de LTV, después de lo cual quedará claro que estos cambios son para nosotros a largo plazo y qué opción debemos promover en la lógica de mostrar los precios.
Terminación del soporte
El resultado de la vida útil de cualquier producto o característica es la finalización de su soporte en caso de que se deba a la falta de demanda u otras razones (por ejemplo, consideraciones de seguridad en caso de finalización del soporte para un sistema operativo o una versión de PHP obsoletos). Aquí, los análisis también nos ayudan: por ejemplo, cuando decidimos alentar a los usuarios a cambiar a nuevas versiones de PHP, lo primero que hicimos fue recopilar estadísticas de uso de versiones entre los usuarios de Plesk. Aprendimos que el porcentaje que usa PHP 7 llega solo al 20% de los usuarios y nos dimos cuenta de que los costos potenciales del cambio forzado en forma de millones de sitios rotos superan los riesgos de posibles vulnerabilidades de versiones anteriores. Como resultado, decidimos medidas de influencia más leves y comenzamos con una notificación sobre la conveniencia de una actualización en el panel. Otro ejemplo puede ser numerosas historias con la interrupción del soporte para sistemas operativos: en el caso de que descubrimos que uno de los clientes más grandes con decenas de miles de instalaciones de Plesk está utilizando un determinado sistema operativo, nos comunicamos de manera específica con este socio y, en caso de imposibilidad de una transición rápida, le ofrecimos la llamada caída lenta: la finalización del soporte para nuevas instalaciones y la capacidad de continuar trabajando en las existentes después de actualizar a la última versión de Plesk.
Conclusión
Para resumir, quiero expresar una vez más lo que consideramos más importante: ahora trabajar con análisis para nosotros es una parte integral del trabajo en cada función. Pero el proceso construido no es el final. Desde nuestra propia experiencia, estábamos convencidos de que el control de calidad de los datos no es menos importante que el proceso en sí. Todo no tiene sentido si en cualquier etapa de la recopilación los datos se pierden o se distorsionan. Para evitar que esto suceda, en cada etapa nos esforzamos por agregar comprobaciones de integridad y exactitud de los datos, así como registrar cada paso de procesamiento.

Y el último. No se pese con las métricas simplemente porque puede :) indicar claramente cuál es esta información para usted y, cuando la reciba, pregúntese si lleva a una conclusión que conduzca a la acción. Después de todo, entender qué hacer es exactamente para qué comenzó todo :)