Ya nos hemos familiarizado con el dispositivo de
caché del
búfer , uno de los objetos principales en la memoria compartida, y nos hemos dado cuenta de que para recuperarse de una falla cuando se pierde el contenido de la RAM, debe mantener un
registro de pregrabación .
El problema no resuelto que detuvimos la última vez es que no se sabe en qué momento puede comenzar a reproducir los registros durante la recuperación. Comenzar desde el principio, como aconsejó el Rey de
Alicia , no funcionará: es imposible almacenar todas las entradas del diario desde el inicio del servidor; esto es potencialmente una gran cantidad y el mismo gran tiempo de recuperación. Necesitamos un punto de avance gradual desde el cual podamos comenzar la recuperación (y, en consecuencia, podemos eliminar con seguridad todas las entradas de diario anteriores). Este es el
punto de control que se discutirá hoy.
Punto de control
¿Qué propiedad debe tener un punto de control? Debemos estar seguros de que todas las entradas de diario, comenzando desde el punto de control, se aplicarán a las páginas escritas en el disco. Si no fuera así, durante la restauración podríamos leer del disco una versión demasiado antigua de la página y aplicarle una entrada de diario, y así dañar permanentemente los datos.
¿Cómo obtener un punto de interrupción? La opción más fácil es suspender periódicamente el sistema y vaciar al disco todas las páginas sucias del búfer y otras memorias caché. (Tenga en cuenta que las páginas solo se escriben, pero no se expulsan de la memoria caché). Tales puntos satisfarán la condición, pero, por supuesto, nadie querrá trabajar con un sistema que se congela constantemente por un tiempo indefinido pero muy significativo.
Por lo tanto, en la práctica, todo es algo más complicado: un punto de control de un punto se convierte en un segmento. Primero comenzamos
el punto de ruptura. Después de eso, sin interrumpir el trabajo y, si es posible, sin crear cargas máximas, volcamos lentamente los buffers sucios en el disco.

Cuando se escribieron todos los búferes que estaban sucios
al comienzo del punto
de control, el punto de control se considera
completo . Ahora (pero no antes) podemos usar el punto de
inicio como el punto desde el cual puede comenzar la recuperación. Y las entradas de diario hasta este punto ya no las necesitamos.

El punto de verificación se maneja mediante un proceso especial de puntero de verificación en segundo plano.
La duración de los buffers sucios está determinada por el valor del parámetro
checkpoint_completion_target . Muestra cuánto tiempo transcurrirá entre dos puntos de control adyacentes la grabación. El valor predeterminado es 0.5 (como en las figuras anteriores), es decir, la grabación tarda la mitad del tiempo entre los puntos de control. Típicamente, el valor se incrementa hasta 1.0 para una mayor uniformidad.
Consideremos con más detalle lo que sucede cuando se ejecuta un punto de control.
El proceso de punto de control primero descarga los buffers de estado de transacción (XACT) en el disco. Como hay pocos (128 en total), se registran de inmediato.
Entonces comienza el trabajo principal: escribir páginas sucias desde la memoria caché del búfer. Como ya dijimos, es imposible restablecer todas las páginas a la vez, ya que el tamaño de la memoria caché del búfer puede ser significativo. Por lo tanto, primero, todas las páginas actualmente sucias se marcan en la memoria caché del búfer en los encabezados con un indicador especial.
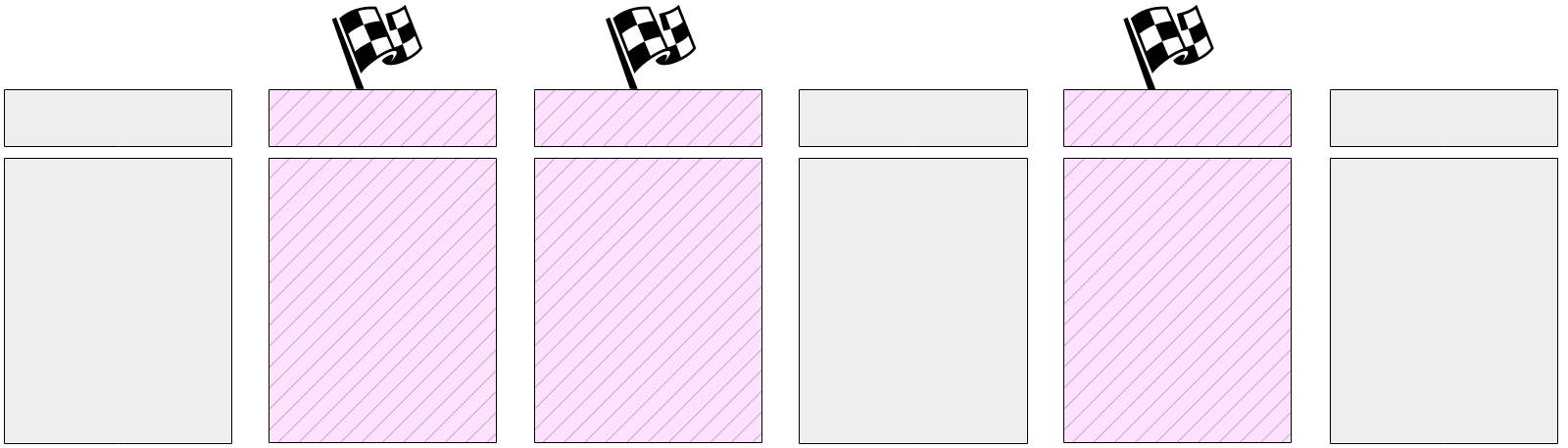
Y luego, el proceso del punto de control pasa gradualmente por todos los buffers y vacía los marcados en el disco. Recuerde que las páginas no se expulsan del caché, sino que solo se escriben en el disco, por lo que no necesita prestar atención a la cantidad de llamadas al búfer ni a su reparación.
Los buffers etiquetados también pueden ser escritos por procesos del servidor, dependiendo de quién llegue primero al buffer. En cualquier caso, el indicador previamente establecido se elimina al grabar, por lo que (para el punto de control) el búfer se escribirá solo una vez.
Naturalmente, durante la ejecución del punto de control, las páginas continúan cambiando en la memoria caché del búfer. Pero los nuevos buffers sucios no están marcados y el proceso del punto de control no debería escribirlos.
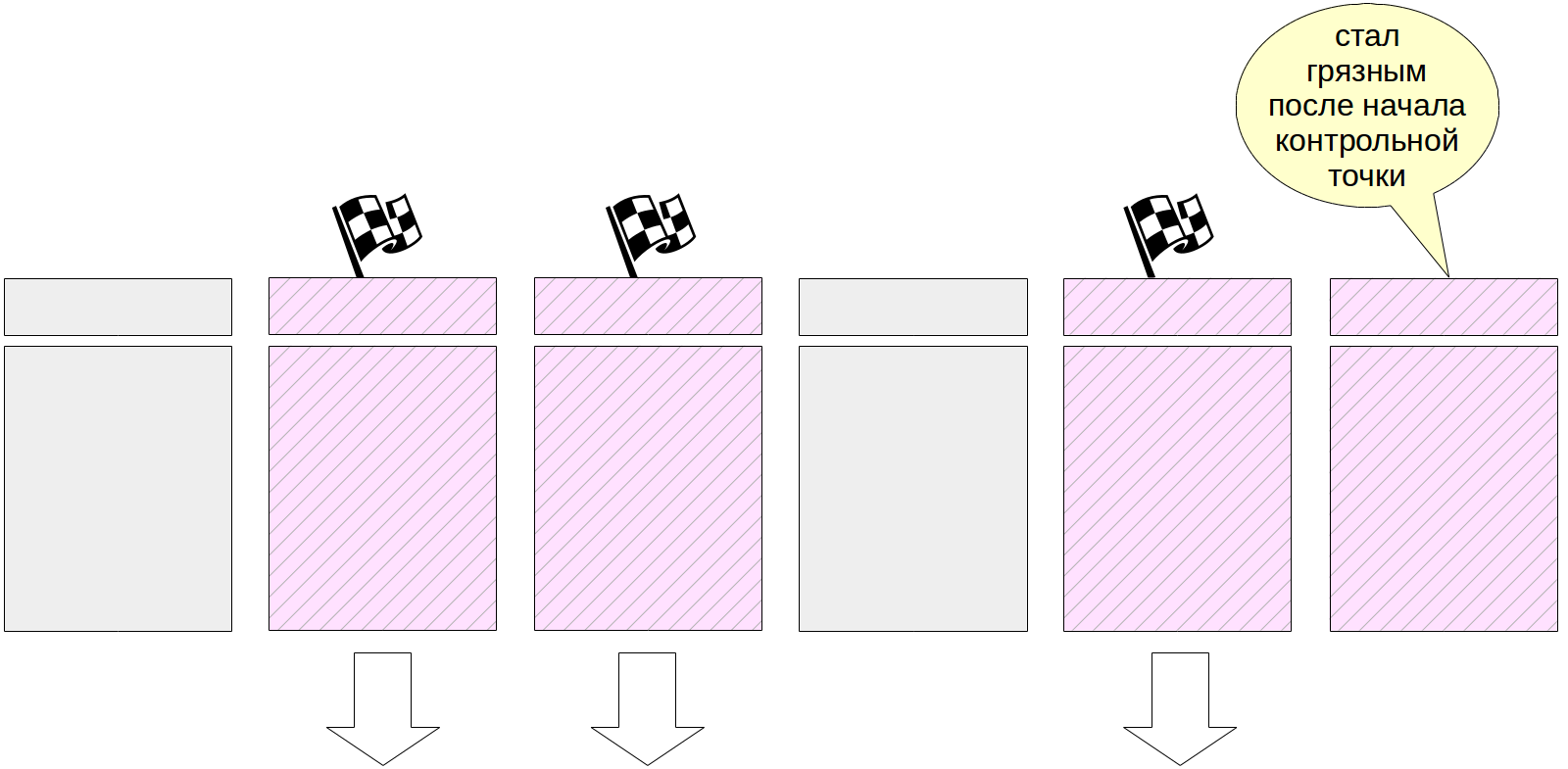
Al final de su trabajo, el proceso crea una entrada de diario para el final del punto de control. Este registro contiene el LSN del inicio del trabajo del punto de control. Dado que el punto de control no escribe nada en el registro al comienzo de su trabajo, este LSN puede contener cualquier registro de registro.
Además, el archivo $ PGDATA / global / pg_control actualiza la indicación del último punto de control
pasado . Antes de que se complete el punto de control, pg_control apunta al punto de control anterior.

Para ver el trabajo del punto de control, cree una tabla: sus páginas irán al caché del búfer y estarán sucias:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); => CREATE EXTENSION pg_buffercache; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 78 (1 row)
Recuerde la posición actual en el registro:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A048 (1 row)
Ahora ejecutaremos el punto de control manualmente y nos aseguraremos de que no haya páginas sucias en el caché (como dijimos, pueden aparecer nuevas páginas sucias, pero en nuestro caso no hubo cambios en el proceso de ejecución del punto de control):
=> CHECKPOINT; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
Veamos cómo se reflejó el punto de control en el registro:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A0E4 (1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
Aquí vemos dos entradas. El último es un registro de pasar el punto de control (CHECKPOINT_ONLINE). El LSN del inicio del punto de control se indica después de la palabra rehacer, y esta posición corresponde a la entrada del diario, que fue la última al comienzo del punto de control.
Encontraremos la misma información en el archivo de control:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C Latest checkpoint's REDO location: 0/3514A048
Recuperación
Ahora estamos listos para aclarar el algoritmo de recuperación descrito en el artículo anterior.
Si el servidor falla, la próxima vez que se inicie, el proceso de inicio lo detecta al mirar el archivo pg_control y ver un estado que no sea "apagado". En este caso, se realiza la recuperación automática.
Primero, el proceso de recuperación leerá desde el mismo pg_control la posición del inicio del punto de control. (Para completar, observamos que si el archivo backup_label está presente, entonces se lee el registro del punto de control; esto es necesario para restaurar desde copias de seguridad, pero este es un tema para un ciclo separado).
Luego leerá la revista, comenzando desde la posición encontrada, aplicando secuencialmente entradas de diario a las páginas (si es necesario, como lo discutimos la
última vez ).
En conclusión, todas las tablas no registradas se sobrescriben usando imágenes en los archivos init.
En este punto, el proceso de inicio finaliza y el proceso del puntero de verificación ejecuta inmediatamente un punto de verificación para corregir el estado restaurado en el disco.
Puede simular un fallo deteniendo por la fuerza el servidor en modo inmediato.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(La clave
--skip-systemctl-redirect es necesaria aquí porque PostgreSQL está instalado en Ubuntu desde el paquete. Está controlado por el comando pg_ctlcluster, que en realidad llama systemctl, y ya llama a pg_ctl. Con todos estos contenedores, el nombre del modo se pierde en el camino, y el
--skip-systemctl-redirect permite prescindir de systemctl y guardar información importante).
Verifique el estado del clúster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
Al iniciarse, PostgreSQL comprende que se ha producido un error y que se requiere una recuperación.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK 2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress 2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048 2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0 2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C 2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections 2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
La necesidad de recuperación se observa en el registro de mensajes: el
sistema de base de datos no se cerró correctamente; recuperación automática en progreso . Luego, las entradas de diario comienzan a reproducirse desde la posición marcada en "rehacer comienza en" y continúan hasta que se puedan recuperar las siguientes entradas de diario. Esto completa la recuperación en la posición "rehacer en" y el DBMS comienza a trabajar con los clientes (el
sistema de base de datos está listo para aceptar conexiones ).
¿Y qué sucede durante un apagado normal del servidor? Para vaciar las páginas sucias al disco, PostgreSQL desconecta todos los clientes y luego ejecuta el punto de control final.
Recuerde la posición actual en el registro:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A14C (1 row)
Ahora detenga suavemente el servidor:
student$ sudo pg_ctlcluster 11 main stop
Verifique el estado del clúster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
Y en el registro encontramos el único registro sobre el punto de control final (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(En un terrible mensaje fatal, pg_waldump solo quiere decir que leyó hasta el final de la revista).
Ejecute la instancia nuevamente.
student$ sudo pg_ctlcluster 11 main start
Grabación de fondo
Como descubrimos, el punto de control es uno de los procesos que escribe páginas sucias desde la memoria caché del búfer al disco. Pero no el único.
Si el backend necesita sacar la página del búfer y la página está sucia, tendrá que escribirla en el disco por sí misma. Esta es una mala situación, que lleva a expectativas: es mucho mejor cuando la grabación se produce de forma asíncrona en segundo plano.
Por lo tanto, además del
proceso de punto de control
, también hay
un proceso de grabación de fondo (escritor de fondo, bgwriter o simplemente escritor). Este proceso utiliza el mismo algoritmo de búsqueda de búfer que el mecanismo de preferencia. Básicamente hay dos diferencias.
- No utiliza un puntero a la "próxima víctima", sino el suyo. Puede adelantarse al puntero de la "víctima", pero nunca se queda atrás.
- Al atravesar buffers, el contador de golpes no disminuye.
Se escriben buffers que son simultáneamente:
- contener datos modificados (sucios),
- no fijo (número de pines = 0),
- tener cero aciertos (recuento de uso = 0).
Por lo tanto, el proceso de grabación en segundo plano, por así decirlo, se adelanta al desplazamiento y encuentra esos búferes que probablemente se desplazarán pronto. Idealmente, debido a esto, los procesos de servicio deberían encontrar que los buffers que seleccionan pueden usarse sin detenerse para escribir.
Personalización
El proceso del punto de control generalmente se configura por los siguientes motivos.
Primero debe decidir cuántos archivos de registro podemos guardar (y qué tiempo de recuperación nos conviene). Cuanto más grande, mejor, pero por razones obvias, este valor será limitado.
A continuación, podemos calcular cuánto tiempo se generará este volumen bajo carga normal. Ya hemos considerado cómo hacer esto (necesitamos recordar las posiciones en el diario y restar una de la otra).
Esta vez será nuestro intervalo habitual entre puntos de control. Lo escribimos en el parámetro
checkpoint_timeout . El valor predeterminado de 5 minutos es obviamente demasiado pequeño, por lo general, el tiempo se incrementa, por ejemplo, a media hora. Repito: cuanto menos pueda permitirse hitos, mejor, esto reduce los gastos generales.
Sin embargo, es posible (e incluso probable) que a veces la carga sea más alta de lo normal, y se generarán demasiados asientos en el tiempo especificado en el parámetro. En este caso, me gustaría realizar el punto de control con más frecuencia. Para hacer esto, en el parámetro
max_wal_size especificamos la cantidad que es válida dentro del mismo punto de control. Si el volumen real se obtiene más, el servidor inicia un punto de control no programado.
Por lo tanto, la mayoría de los puntos de control ocurren en un horario: una vez por unidades de tiempo
checkpoint_timeout . Pero con el aumento de la carga, el punto de control se llama con mayor frecuencia cuando se
alcanza el volumen
max_wal_size .
Es importante comprender que el parámetro
max_wal_size no determina en absoluto la cantidad máxima que pueden ocupar los archivos de registro en el disco.
- Para recuperarse de una falla, debe almacenar los archivos desde el momento en que se pasó el último punto de control, más los archivos que se acumularon durante la operación del punto de control actual. Por lo tanto, el volumen total puede estimarse aproximadamente como
(1 + checkpoint_completion_target ) × max_wal_size . - Antes de la versión 11, PostgreSQL también almacenaba archivos para el punto de control de dos años, por lo que hasta la versión 10 en la fórmula anterior, debe establecer 2 en lugar de 1.
- El parámetro max_wal_size es solo un deseo, pero no un límite estricto . Puede resultar más.
- El servidor no tiene derecho a borrar archivos de registro que aún no se han transferido a través de las ranuras de replicación y que aún no se han archivado durante el archivado continuo. Si se utiliza esta funcionalidad, es necesaria una supervisión constante, ya que es fácil desbordar la memoria del servidor.
Para completar la imagen, puede establecer no solo el volumen máximo, sino también el mínimo: parámetro
min_wal_size . El significado de esta configuración es que el servidor no elimina archivos mientras se ajustan en
min_wal_size en
volumen , sino que simplemente los renombra y los usa nuevamente. Esto le ahorra un poco al crear y eliminar archivos constantemente.
El proceso de grabación en segundo plano tiene sentido para configurar después de configurar el punto de control. Juntos, estos procesos deben tener tiempo para escribir buffers sucios antes de que sean necesarios para los procesos de mantenimiento.
El proceso de grabación en segundo plano se ejecuta en ciclos de, como máximo, páginas
bgwriter_lru_maxpages , quedando dormido entre ciclos en
bgwriter_delay .
El número de páginas que se registrarán en un ciclo de trabajo está determinado por el número promedio de memorias intermedias que se solicitaron mediante los procesos de servicio de la última ejecución (utilizando un promedio móvil para suavizar las desigualdades entre las ejecuciones, pero no depende de un largo historial). El número calculado de buffers se multiplica por el coeficiente
bgwriter_lru_multiplier (pero en cualquier caso no excederá
bgwriter_lru_maxpages ).
Valores predeterminados:
bgwriter_delay = 200ms (lo más probable es que gotee mucha agua en 1/5 de segundo),
bgwriter_lru_maxpages = 100,
bgwriter_lru_multiplier = 2.0 (tratamos de responder a la demanda antes de lo programado).
Si el proceso no detecta buffers sucios (es decir, no sucede nada en el sistema), "hiberna" de lo que se deduce que el proceso del servidor accede al buffer. Después de eso, el proceso se despierta y vuelve a funcionar de la manera habitual.
Monitoreo
El punto de control y la configuración de grabación en segundo plano pueden y deben ajustarse, recibiendo comentarios de la supervisión.
El parámetro
checkpoint_warning muestra una advertencia si los puntos de control causados por desbordamientos del tamaño del archivo de registro se ejecutan con demasiada frecuencia. Su valor predeterminado es de 30 segundos, y debe alinearse con el valor de
checkpoint_timeout .
El parámetro
log_checkpoints (deshabilitado de forma predeterminada) permite recibir información sobre los puntos de verificación ejecutados en el registro de mensajes del servidor. Enciéndelo.
=> ALTER SYSTEM SET log_checkpoints = on; => SELECT pg_reload_conf();
Ahora cambie algo en los datos y ejecute el punto de control.
=> UPDATE chkpt SET n = n + 1; => CHECKPOINT;
En el registro de mensajes veremos algo como esto:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait 2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
Aquí puede ver cuántos búferes se escribieron, cómo cambió la composición de los archivos de registro después del punto de control, cuánto tiempo tomó el punto de control y la distancia (en bytes) entre los puntos de control adyacentes.
Pero, probablemente, la información más útil son las estadísticas del trabajo del punto de control y los procesos de grabación en segundo plano en la vista pg_stat_bgwriter. La vista es una para dos, porque una vez que ambas tareas fueron realizadas por un proceso; entonces sus funciones se dividieron y la vista permaneció.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------ checkpoints_timed | 0 checkpoints_req | 1 checkpoint_write_time | 1 checkpoint_sync_time | 13 buffers_checkpoint | 79 buffers_clean | 0 maxwritten_clean | 0 buffers_backend | 42 buffers_backend_fsync | 0 buffers_alloc | 363 stats_reset | 2019-07-17 15:27:49.826414+03
Aquí, entre otras cosas, vemos la cantidad de puntos de control completados:
- checkpoints_timed - de acuerdo con el horario (al llegar a checkpoint_timeout),
- checkpoints_req: bajo demanda (incluso al llegar a max_wal_size).
El gran valor de checkpoint_req (en comparación con checkpoints_timed) indica que los puntos de control ocurren con más frecuencia de lo esperado.
Información importante sobre el número de páginas grabadas:
- buffers_checkpoint - proceso de punto de control,
- buffers_backend: al servir procesos,
- buffers_clean: proceso de grabación en segundo plano.
En un sistema bien ajustado, el valor de buffers_backend debería ser sustancialmente menor que la suma de buffers_checkpoint y buffers_clean.
Además, maxwritten_clean es útil para configurar la grabación en segundo plano: este número muestra cuántas veces el proceso de grabación en segundo plano dejó de funcionar debido a que excedió
bgwriter_lru_maxpages .
Puede restablecer las estadísticas acumuladas mediante la siguiente llamada:
=> SELECT pg_stat_reset_shared('bgwriter');
Continuará