Queremos presentar nuestra nueva herramienta para la tokenización de texto: YouTokenToMe. Funciona 7-10 veces más rápido que otras versiones populares en idiomas similares en estructura al europeo, y 40-50 veces, en idiomas asiáticos. Hablamos de YouTokenToMe y lo compartimos con usted en código abierto en GitHub. Enlace al final del artículo!

Hoy, una proporción significativa de las tareas para los algoritmos de redes neuronales son el procesamiento de textos. Pero, dado que las redes neuronales funcionan con números, el texto debe convertirse antes de transferirse al modelo.
Enumeramos las soluciones populares que generalmente se usan para esto:
- descanso espacial
- algoritmos basados en reglas: spaCy, NLTK;
- stemming, lematización.
Cada uno de ellos tiene sus propias desventajas:
- No puede controlar el tamaño del diccionario de tokens. El tamaño de la capa de incrustación en el modelo depende directamente de esto;
- no se utiliza información sobre el parentesco de palabras que difieren por sufijos o prefijos, por ejemplo: educado - descortés;
- Depende del idioma.
Recientemente, el enfoque de
codificación de par de bytes ha sido popular. Inicialmente, este algoritmo estaba destinado a la compresión de texto, pero hace varios años se utilizó para simular el texto en la traducción automática. Ahora se utiliza para una amplia gama de tareas, incluidas las utilizadas en los modelos BERT y GPT-2.
Las implementaciones de BPE más efectivas fueron
SentencePiece , desarrollada por ingenieros de Google, y
fastBPE , creada por Facebook AI Research. Pero logramos demostrar que la tokenización puede acelerarse significativamente. Optimizamos el algoritmo BPE y publicamos el código fuente, y también publicamos el paquete terminado en el repositorio de pip.
A continuación puede comparar los resultados de medir la velocidad de nuestro algoritmo y otras versiones. Como ejemplo, tomamos los primeros 100 MB
del corpus de datos de Wikipedia en ruso, inglés, japonés y chino.
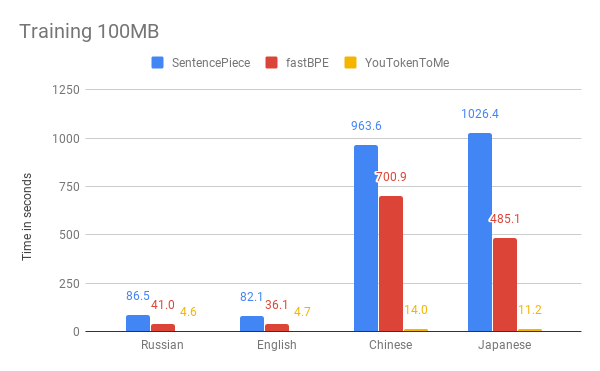

Los gráficos muestran que el tiempo de funcionamiento depende significativamente del idioma. Esto se debe a que los idiomas asiáticos tienen más alfabetos y las palabras no están separadas por espacios. YouTokenToMe funciona 7-10 veces más rápido en idiomas similares en estructura al europeo, y 40-50 veces en asiático. La tokenización se aceleró al menos dos veces, y en algunas pruebas más de diez veces.
Logramos estos resultados gracias a dos ideas clave:
- El nuevo algoritmo tiene un tiempo de ejecución lineal dependiendo del tamaño del caso para el entrenamiento. SentencePiece y fastBPE tienen un comportamiento asintótico menos efectivo;
- El nuevo algoritmo puede usar efectivamente varias transmisiones tanto en el proceso de aprendizaje como en el proceso de tokenización, lo que le permite acelerar varias veces más.
Puede usar YouTokenToMe a través de la interfaz para trabajar desde la línea de comandos y directamente desde Python.
Puede encontrar más información en el repositorio:
github.com/vkcom/YouTokenToMe