¿Quiere aprender sobre tres métodos de minería de datos para su próximo proyecto de ML? ¡Luego lea la traducción del artículo de Rebecca Vickery publicado en el blog Towards Data Science en Medium! Ella será interesante para los principiantes.
Obtener datos de calidad es el primer paso y el más importante en cualquier proyecto de aprendizaje automático. Los especialistas en ciencia de datos a menudo usan varios métodos para obtener conjuntos de datos. Pueden usar datos disponibles públicamente, así como datos disponibles a través de la API u obtenidos de varias bases de datos, pero la mayoría de las veces combinan estos métodos.
El propósito de este artículo es proporcionar una breve descripción de tres métodos diferentes para recuperar datos usando Python. Te diré cómo hacer esto con el cuaderno Jupyter. En mi
artículo anterior
, escribí sobre la aplicación de algunos comandos que se ejecutan en el terminal.
SQL
Si necesita obtener datos de una base de datos relacional, lo más probable es que trabaje con el lenguaje SQL. La biblioteca SQLAlchemy le permite asociar el código de su computadora portátil con los tipos más comunes de bases de datos.
Aquí encontrará información sobre qué bases de datos son compatibles y cómo enlazar a cada tipo.
Puede usar la biblioteca SQLAlchemy para examinar tablas y consultar datos, o escribir consultas sin procesar. Para enlazar a la base de datos, necesitará una URL con sus credenciales. A continuación, debe inicializar el método
create_engine para crear la conexión.
from sqlalchemy import create_engine engine = create_engine('dialect+driver://username:password@host:port/database')
Ahora puede escribir consultas en la base de datos y obtener resultados.
connection = engine.connect() result = connection.execute("select * from my_table")
Raspado
El raspado web se utiliza para descargar datos de sitios web y extraer la información necesaria de sus páginas. Hay muchas bibliotecas de Python disponibles para esto, pero la más simple es
Beautiful Soup .
Puede instalar el paquete a través de pip.
pip install BeautifulSoup4
Veamos un ejemplo simple de cómo usarlo. Usaremos Beautiful Soup y la biblioteca
urllib para obtener los nombres y precios de
hoteles de
TripAdvisor .
Primero, importamos todas las bibliotecas con las que vamos a trabajar.
from bs4 import BeautifulSoup import urllib.request
Ahora cargue el contenido de la página que desecharemos. Quiero recopilar datos sobre los precios de los hoteles en la isla griega de Creta y tomar la dirección URL que contiene una lista de hoteles en este lugar.
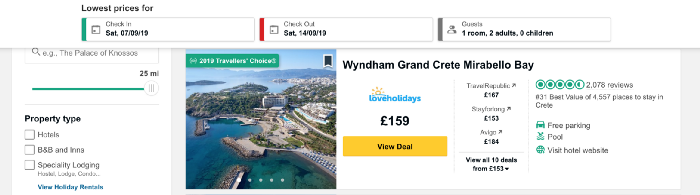
El siguiente código define la URL como una variable y utiliza la biblioteca urllib para abrir la página, y la biblioteca Beautiful Soup para leerla y devolver los resultados en un formato simple. Parte de los datos de salida se muestran debajo del código.
URL = 'https://www.tripadvisor.co.uk/Hotels-g189413-Crete-Hotels.html' page = urllib.request.urlopen(URL) soup = BeautifulSoup(page, 'html.parser') print(soup.prettify())

Ahora obtengamos una lista con los nombres de los hoteles en la página. Introduciremos la función
find_all , que extraerá partes del documento que nos interese. Puede filtrarlo de manera diferente utilizando la función
find_all para pasar una sola línea, expresión regular o lista. También puede filtrar uno de los atributos de la etiqueta; este es exactamente el método que aplicaremos. Si es nuevo en las etiquetas y atributos HTML, consulte este
artículo para obtener una descripción general rápida.
Para comprender la mejor manera de proporcionar acceso a los datos en la etiqueta, debemos verificar el código de este elemento en la página. Encontramos el código para el nombre del hotel haciendo clic derecho sobre el nombre en la lista, como se muestra en la figura a continuación.

Después de hacer clic en
inspect aparecerá el código
inspect elemento y se resaltará la sección con el nombre del hotel.

Vemos que el nombre del hotel es el único texto de la clase con el nombre
listing_title . Después de la clase viene el código y el nombre de este atributo a la función
find_all , así como la etiqueta
div .
content_name = soup.find_all('div', attrs={'class': 'listing_title'}) print(content_name)
Cada sección del código con el nombre del hotel se devuelve como una lista.

Para extraer los nombres de los hoteles del código, utilizamos la función
getText de la biblioteca Beautiful Soup.
content_name_list = [] for div in content_name: content_name_list.append(div.getText().split('\n')[0]) print(content_name_list)
Los nombres de los hoteles se devuelven como una lista.

Del mismo modo obtenemos datos de precios. La estructura del código para el precio se muestra a continuación.

Como puede ver, podemos trabajar con un código muy similar al utilizado para los hoteles.
content_price = soup.find_all('div', attrs={'class': 'price-wrap'}) print(content_price)
En el caso del precio, hay poca dificultad. Puede verlo ejecutando el siguiente código:
content_price_list = [] for div in content_price: content_price_list.append(div.getText().split('\n')[0]) print(content_price_list)
El resultado se muestra a continuación. Si se indica una reducción de precio en la lista de hoteles, además de algún texto, se devuelve tanto el precio inicial como el precio final. Para solucionar este problema, simplemente devolvemos el precio actual de hoy.

Podemos usar una lógica simple para obtener el último precio indicado en el texto.
content_price_list = [] for a in content_price: a_split = a.getText().split('\n')[0] if len(a_split) > 5: content_price_list.append(a_split[-4:]) else: content_price_list.append(a_split) print(content_price_list)
Esto nos dará el siguiente resultado:

API
API: interfaz de programación de aplicaciones (de la interfaz de programación de aplicaciones en inglés). Desde la perspectiva de la minería de datos, es un sistema basado en la web que proporciona un punto final de datos que puede contactar a través de la programación. Por lo general, los datos se devuelven en formato JSON o XML.
Este método probablemente será útil en el aprendizaje automático. Daré un ejemplo simple de recuperación de datos meteorológicos de la API pública de
Dark Sky . Para conectarse, debe registrarse, y tendrá 1000 llamadas gratis por día. Esto debería ser suficiente para las pruebas.
Para acceder a los datos de Dark Sky,
requests biblioteca de
requests . En primer lugar, necesito obtener la URL correcta para la solicitud. Además del pronóstico, Dark Sky proporciona datos históricos del clima. En este ejemplo, los tomaré y obtendré la URL correcta de la
documentación .
La estructura de esta URL es:
https://api.darksky.net/forecast/[key]/[latitude],[longitude],[time]
Utilizaremos la biblioteca de
requests para obtener
resultados para una latitud y longitud específicas, así como la fecha y la hora. Imagine que después de extraer datos de precios diarios de hoteles en Creta, decidimos averiguar si la política de precios está relacionada con el clima.
Por ejemplo, tomemos las coordenadas de uno de los hoteles en la lista: Mitsis Laguna Resort & Spa.

Primero, cree una URL con las coordenadas correctas, así como la hora y fecha solicitadas. Usando la biblioteca de
requests , tenemos acceso a los datos en el formato JSON.
import requests request_url = 'https://api.darksky.net/forecast/fd82a22de40c6dca7d1ae392ad83eeb3/35.3378,-25.3741,2019-07-01T12:00:00' result = requests.get(request_url).json() result
Para facilitar la lectura y el análisis de los resultados, podemos convertir los datos en un marco de datos.
import pandas as pd df = pd.DataFrame.from_dict(json_normalize(result), orient='columns') df.head()

Hay muchas más opciones para automatizar la extracción de datos utilizando estos métodos. En el caso del raspado web, puede escribir diferentes funciones para automatizar el proceso y facilitar la extracción de datos para más días y / o lugares. En este artículo, quería revisar y proporcionar suficientes ejemplos de código. Los siguientes materiales serán más detallados: le diré cómo crear grandes conjuntos de datos y analizarlos utilizando los métodos descritos anteriormente.
Gracias por su atencion!