Crear y mantener componentes comunes es un proceso en el que muchos equipos deben participar. El jefe del servicio de componentes comunes de Yandex, Vladimir Grinenko
tadatuta, explicó cómo su desarrollo superó al equipo dedicado de Lego, cómo hicimos un mono-repositorio basado en GitHub usando Lerna, y configuramos lanzamientos de Canary con los servicios implementados directamente en CI, qué se necesitaba y qué aún por ser.
"Me alegro de darles la bienvenida a todos". Mi nombre es Vladimir, hago cosas comunes en las interfaces de Yandex. Quiero hablar sobre ellos Probablemente, si no utiliza nuestros servicios muy profundamente, puede tener una pregunta: ¿qué estamos escribiendo todos? ¿Qué hay para componer?


Hay una lista de respuestas en los resultados de búsqueda, a veces hay una columna a la derecha. Cada uno de ustedes probablemente lo superará en un día. Si recuerda que hay diferentes navegadores, etc., agregamos otro día para corregir errores, y luego todos lo solucionarán.
Alguien recordará que todavía existe una interfaz de este tipo. Teniendo en cuenta todas las pequeñas cosas que puede darle otra semana e ir a por ello. Y Dima nos acaba de decir que somos tantos que necesitamos nuestra propia escuela. Y toda esta gente inventa páginas todo el tiempo. Todos los días vienen a trabajar y escriben, ¿te imaginas? Claramente hay algo más.

De hecho, los servicios en Yandex, de hecho, son más. Y hay incluso un poco más que en esta diapositiva. Detrás de cada uno de estos enlaces hay un montón de interfaces diferentes con gran variabilidad. Son para diferentes dispositivos, en diferentes idiomas. A veces trabajan incluso en automóviles y otras cosas extrañas.

Yandex hoy no es solo la web, no solo diferentes productos con almacenes, entregas y todo eso. Coches de paseo amarillo. Y no solo lo que puedes comer, y no solo pedazos de hierro. Y no solo todo tipo de inteligencias automáticas. Pero todo lo anterior está unido por el hecho de que para cada elemento se necesitan interfaces. A menudo, muy rico. Yandex es cientos de diferentes servicios enormes. Estamos constantemente creando algo nuevo todos los días. Tenemos miles de empleados, incluidos cientos de desarrolladores front-end y desarrolladores de interfaces. Estas personas trabajan en diferentes oficinas, viven en diferentes zonas horarias, los nuevos tipos constantemente vienen a trabajar.
Al mismo tiempo, nosotros, en la medida en que tengamos suficiente fuerza, intentamos que sea monótono y uniforme para los usuarios.

Esta es la búsqueda de documentos en Internet. Pero si cambiamos a la emisión de imágenes, el encabezado coincide, a pesar del hecho de que este es un repositorio separado, que participa en un equipo completamente separado, posiblemente incluso en otras tecnologías. Parece que hay algo complicado? Bueno, hicieron un sombrero dos veces, como algo simple. Cada botón en la tapa también tiene su propio mundo interior rico y separado. Algunas ventanas emergentes aparecen aquí, algo también puede ser empujado allí. Todo esto está traducido a diferentes idiomas, funciona en diferentes plataformas. Y aquí pasamos de las imágenes, por ejemplo, al video, y este es nuevamente un nuevo servicio, otro equipo. Otro repositorio de nuevo. Pero sigue siendo el mismo sombrero, aunque hay diferencias. Y todo esto debe dejarse uniforme.
¿Qué vale, cambiando así en las diapositivas, para asegurarse de que no haya pasado nada en el píxel? Tratamos de evitar que esto suceda.

Para mostrar un poco más la escala, tomé una captura de pantalla del repositorio, que almacena solo el código front-end para los nuevos navegadores, solo la salida de documentos, sin imágenes y videos. Hay decenas de miles de confirmaciones y casi 400 contribuyentes. Esto es solo en diseño, solo un proyecto. Aquí hay una lista de enlaces azules que estás acostumbrado a ver.
Sergey Berezhnoy, mi líder, ama mucho esta historia, ya que como nos hemos reunido tanto en la compañía, quiero que nuestra interacción funcione como si estuviera en JavaScript: uno más uno es más que dos.
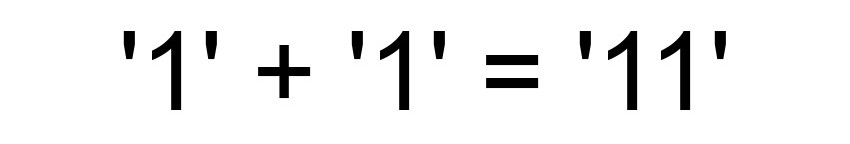
Y estamos tratando de obtener todo lo que podamos de la interacción. Lo primero que viene a la mente en tales condiciones es la reutilización. Aquí, por ejemplo, un fragmento de video en un servicio en los resultados de búsqueda de un video. Esta es una especie de imagen con una firma y algunos otros elementos diferentes.
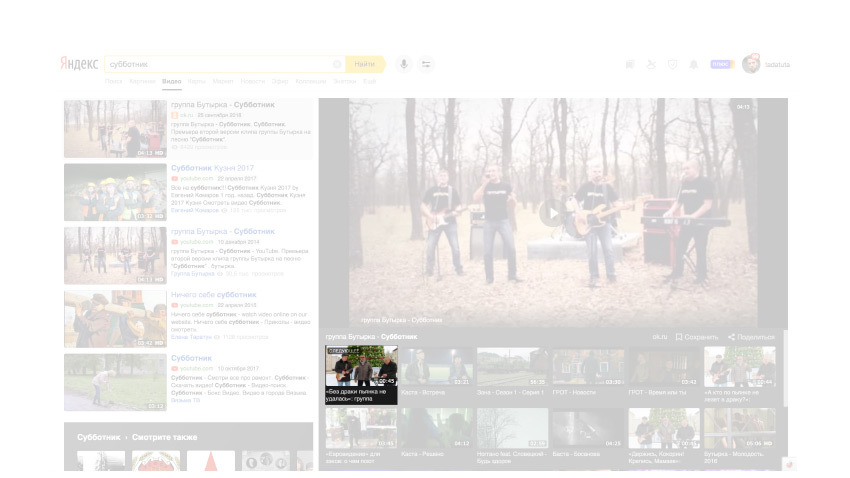
Si busca más, aquí está la emisión habitual de documentos. Pero aquí, también, hay exactamente el mismo fragmento.

O, digamos, hay un servicio Yandex.Air separado, que consiste en fragmentos poco menos que completamente.

O, digamos, el fragmento de video en el notificador, que se encuentra en diferentes páginas del portal.
O aquí hay un fragmento de video cuando lo agrega a sus Favoritos y luego lo mira en sus Colecciones.

Suena como? Obviamente, parece. ¿Y qué? Si realmente dejamos que los servicios integren fácilmente nuestros componentes terminados en otros servicios del portal, entonces, obviamente, este servicio, debido al hecho de que los usuarios pueden interactuar con sus datos en diferentes sitios, obtendrá más usuarios. Esto es genial Los usuarios también se beneficiarán de esto. Verán las mismas cosas por igual. Se comportarán como siempre. Es decir, uno no tiene que adivinar una y otra vez lo que el diseñador tenía en mente aquí y cómo interactuar con él.
Y finalmente, la compañía obtendrá ahorros obvios de esto. Además, simplemente parece: qué hay para inventar una vista previa de video y algún tipo de firma / De hecho, para obtenerlo así, debes realizar muchos experimentos diferentes, probar diferentes hipótesis, elegir tamaños, colores, sangrías. Agregue algunos elementos, tal vez, luego elimine, porque no volaron. Y lo que sucedió, lo que realmente funciona, es el resultado de un proceso muy largo. Y si cada vez en cada lugar nuevo para hacerlo de nuevo, este es un gran esfuerzo.
Ahora imagina. Digamos que tenemos algo que funciona bien. En todas partes, en todas partes lo implementaron, y luego realizaron un nuevo experimento y se dieron cuenta de lo que podría mejorarse. Y nuevamente, tenemos que repetir toda esta cadena de implementación. Caro

Ok, parece obvio reutilizar bien. Pero ahora tenemos que resolver una serie de problemas nuevos. Debe comprender dónde almacenar dicho código nuevo. Por un lado, parece ser lógico. Aquí tenemos un fragmento de video, está hecho por el equipo de video, tienen un repositorio con su proyecto. Probablemente debería ponerse allí. Pero, ¿cómo distribuirlo a otros repositorios de todos los demás? ¿Y si otros chicos quieren aportar algo propio a este fragmento? De nuevo no está claro.
Es necesario versionarlo de alguna manera. No puedes cambiar nada, y así, voila, todo se despliega de repente. Algo necesita ser probado. Además, por ejemplo, probamos esto en el servicio del video en sí. Pero, ¿qué pasa si, cuando se integra a otro servicio, algo se rompe? De nuevo no está claro.
Al final, es necesario garantizar de alguna manera la entrega lo suficientemente rápida a diferentes servicios, porque será extraño si tenemos en algún lugar la versión anterior, en algún lugar nuevo. El usuario parece hacer clic en lo mismo, y hay un comportamiento diferente. Y tenemos que proporcionar de alguna manera la oportunidad para que los desarrolladores de diferentes equipos realicen cambios en dicho código común. Necesitamos enseñarles de alguna manera cómo usarlo todo. Tenemos un largo camino para hacer que la reutilización de interfaces sea conveniente.

Comenzamos a tiempo inmemorial, de vuelta en SVN, y era como una lámpara y conveniente: un papá con HTML, al igual que en Bootstrap. Te lo copias a ti mismo. Al lado de papá con estilos, algún tipo de JS allí, que luego sabía cómo mostrar / ocultar algo simplemente. Y eso es todo.

De alguna manera, la lista de componentes se veía así. Aquí se resalta el b-domeg, responsable de la autorización. Quizás aún recuerde, en Yandex, de hecho, había un formulario para iniciar sesión y contraseña, con un techo. Llamamos a la "casa", aunque insinuó el sobre del correo, porque generalmente ingresaban el correo.
Luego se nos ocurrió una metodología completa para poder soportar interfaces comunes.

La propia biblioteca dentro de la empresa ha adquirido su propio sitio web con una búsqueda y cualquier taxonomía.

El repositorio ahora se ve así. Ya ves, también casi 10 mil commits y más de 100 contribuyentes.

Pero esta es la carpeta de la casa b en la nueva reencarnación. Ahora ella se ve así. Ya hay más carpetas propias dentro de media pantalla.

Y así el sitio se ve hoy.

Como resultado, la biblioteca compartida se utiliza en más de 360 repositorios dentro de Yandex. Y hay diferentes implementaciones, un ciclo de lanzamiento depurado, etc. Parece que, aquí, tenemos una biblioteca común, ahora la usamos en todas partes, y todo es genial. El problema de introducir cosas comunes en cualquier lugar resuelto. En realidad no

Intentar resolver el problema de la reutilización en la etapa en la que ya tiene un código listo es demasiado tarde. Esto significa que desde el momento en que el diseñador dibujó el diseño de los servicios, los distribuyó a los servicios y, en particular, al equipo que se ocupa de componentes comunes, ha pasado algún tiempo. Lo más probable es que en este momento resulte que en cada servicio por separado, o al menos en varios de ellos, este mismo elemento de interfaz también esté compuesto. Se inventaron de alguna manera a su manera.
E incluso si una solución general apareció más tarde en la biblioteca compartida, seguirá siendo así que ahora tendrá que volver a implementar todo lo que logró completar en cada servicio. Y esto es nuevamente un problema. Es muy difícil de justificar. Aquí está el equipo. Ella tiene sus propios objetivos, todo ya está funcionando bien. Y decimos esas cosas: mira, finalmente tenemos una cosita común, tómala. Pero el equipo es así: ya tenemos suficiente trabajo. ¿Por qué lo necesitamos? Además, ¿de repente algo no nos conviene allí? No queremos
El segundo gran problema es, de hecho, la difusión de información sobre cuáles son estos nuevos componentes geniales. Solo porque hay tantos desarrolladores, están ocupados con sus tareas diarias. Y tienen la oportunidad de sentarse y estudiar lo que está sucediendo allí en el área común, sin importar lo que signifique, de hecho, tampoco.
Y el mayor problema es que es fundamentalmente imposible resolver los problemas comunes a todos los servicios con un solo equipo dedicado. Es decir, cuando tenemos un equipo que se ocupa del video y crea su propio fragmento con video, está claro que estaremos de acuerdo con ellos y haremos este fragmento en alguna biblioteca centralizada. Pero hay directamente miles de tales ejemplos en diferentes servicios. Y aquí ciertamente no hay manos suficientes. Por lo tanto, la única solución es que todos deben tratar con componentes generales todo el tiempo.

Y debe comenzar, curiosamente, no con los desarrolladores de interfaces, sino con los diseñadores. Ellos también entienden eso. Tenemos varios intentos simultáneos en el interior para que este proceso converja. Los diseñadores hacen sistemas de diseño. Realmente espero que tarde o temprano sea posible reducirlos a un solo sistema común que tenga en cuenta todas las necesidades.

Ahora hay varios de ellos. Sorprendentemente, las tareas allí son exactamente las mismas: acelerar el proceso de desarrollo, resolver el problema de consistencia, no reinventar la rueda y no duplicar el trabajo realizado.

Y una forma de resolver el problema de la comunicación de información es permitir que los desarrolladores conozcan a otros equipos, incluido uno que se ocupa de componentes de interfaz comunes. Lo resolvemos de este lado por el hecho de que tenemos un bootcamp, que, cuando aparece un desarrollador en Yandex, primero le permite ir a diferentes equipos durante ocho semanas, ver cómo funciona y luego elegir dónde funcionará. . Pero durante este tiempo sus horizontes se expandirán significativamente. Será guiado donde sea eso.
Hablamos de cosas comunes. Veamos ahora cómo se ve todo más cerca del proceso de desarrollo. Digamos que tenemos una biblioteca común llamada Lego. Y queremos implementar alguna característica nueva o hacer algún tipo de revisión. Arreglamos el código y lanzamos la versión.
Necesitamos publicar esta versión en npm, y luego ir al repositorio de algún proyecto donde se usa la biblioteca e implementar esta versión. Lo más probable es que esto arregle algún número en package.json, reinicie el ensamblaje. Quizás incluso regenere el bloqueo de paquete, cree una solicitud de extracción y vea cómo pasan las pruebas. ¿Y qué veremos?
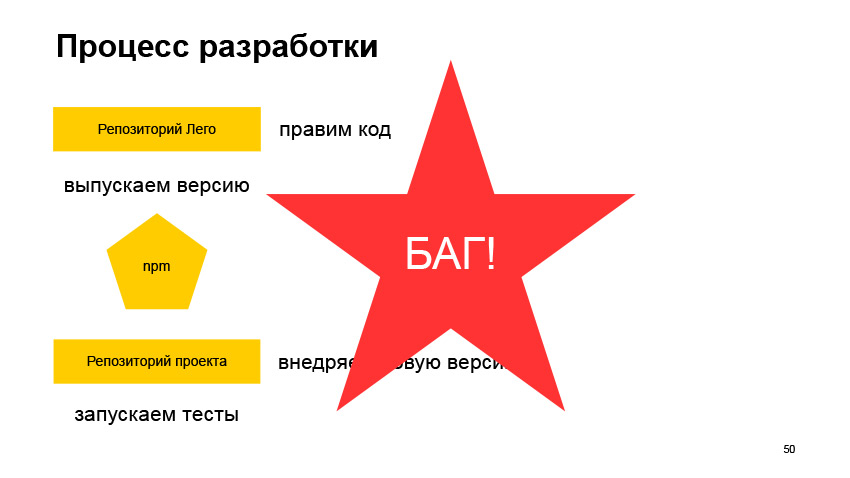
Lo más probable es que veamos que se ha producido un error. Porque es muy difícil predecir todas las formas de usar el componente en diferentes servicios. Y si eso sucedió, entonces, ¿cuál es nuestra salida? Entonces nos dimos cuenta de que no encajaba. Seguimos rehaciendo. Regresamos al repositorio con una biblioteca compartida, reparamos el error, lanzamos la nueva versión, la enviamos a npm, implementamos, ejecutamos las pruebas y ¿qué es? Lo más probable es que vuelva a ocurrir un error.
Y esto sigue siendo bueno cuando lo implementamos en un servicio, y allí todo se rompió de inmediato. Fue mucho más triste cuando hicimos todo esto, lo implementamos en diez servicios diferentes. Nada se rompió allí. Ya hemos ido a preparar un batido, o lo que sea necesario. En este momento, la versión se está introduciendo en el undécimo proyecto o en el 25. Y hay un error. Regresamos a lo largo de toda la cadena, hacemos un parche y lo implementamos en los 20 servicios anteriores. Además, este parche puede explotar en uno de los anteriores. Bueno y así sucesivamente. Diviértete
Parece que la única salida es escribir mucho código muy rápidamente. Luego, tarde o temprano, si corremos muy, muy rápido, lo más probable es que logremos tener tiempo para lanzar a la producción una versión en la que todavía no haya errores. Pero luego aparecerá una nueva característica, y nada nos salvará.
Esta bien De hecho, el esquema puede ser algo como lo siguiente. La automatización nos ayudará. Se trata de esto, en general, de toda la historia, de hecho. Se nos ocurrió la idea de que se puede construir un repositorio con una biblioteca común de acuerdo con el esquema de mono-repositorio. Probablemente te hayas encontrado, ahora hay muchos proyectos de este tipo, especialmente los de infraestructura. Todo tipo de Babel, y cosas así, viven como mono-repositorios cuando hay muchos paquetes npm diferentes dentro. Pueden estar de alguna manera conectados entre sí. Y se gestionan, por ejemplo, a través de Lerna, por lo que es conveniente publicar todo esto, dadas las dependencias.
Exactamente de acuerdo con este esquema, es posible organizar un proyecto donde todo lo común se almacena para toda la empresa. Puede haber una biblioteca, que se dedica a un equipo separado. Y, incluso, puede haber paquetes que cada servicio individual desarrolla, pero que quiere compartir con otros.

Entonces el circuito se ve así. El comienzo no es diferente. De una forma u otra, tenemos que hacer cambios en el código común. Y luego, con la ayuda de la automatización, de un solo golpe queremos ejecutar pruebas no solo al lado de este código, sino de inmediato en todos los proyectos en los que este código común está incrustado. Y ver su resultado agregado.
Luego, incluso si ocurrió un error allí, aún no hemos logrado lanzar ninguna versión, no la hemos publicado en ningún minuto, no la hemos implementado específicamente con nuestras manos, no hemos hecho todos estos esfuerzos adicionales. Vimos un error, lo solucionamos de inmediato localmente, volvimos a ejecutar pruebas generales, y todo eso está en producción.
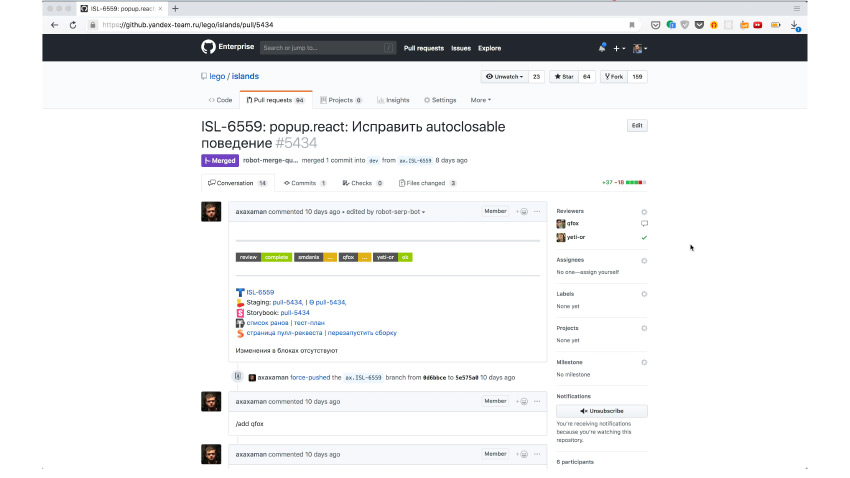
¿Cómo se ve en la práctica? Aquí hay una solicitud de extracción con una solución. Aquí puede ver que la automatización solicitó los revisores necesarios para verificar que todo esté bien en el código. De hecho, los revisores vinieron y acordaron que todo estaba bien. Y en este momento, el desarrollador simplemente escribe un comando especial / canario, directamente en la solicitud de extracción.
Llega un robot y dice: está bien, creé una tarea para que ocurra el próximo milagro. El milagro es que ahora se ha lanzado una versión canaria con estos cambios y se ha implementado automáticamente en todos los repositorios donde se usa este componente. Las pruebas automáticas se lanzaron allí, como en este repositorio. Aquí puede ver que se han lanzado un montón de controles.
Detrás de cada prueba puede haber otras cien pruebas diferentes. Pero es importante que, además de las pruebas locales que podríamos escribir en el componente por separado, también lanzamos pruebas para cada proyecto donde se implementó. Las pruebas de integración ya se han lanzado allí: verificamos que este componente funcione normalmente en el entorno en el que está concebido en el servicio. Esto ya nos garantiza que no hemos olvidado nada, no le hemos revelado nada a nadie. Si todo está bien aquí, entonces podemos lanzar una versión de forma segura. Y si algo está mal aquí, lo arreglaremos aquí.
Parece que esto debería ayudarnos. Si su empresa tiene algo similar, verá que hay partes que podría reutilizar, pero por ahora debe reorganizarlas porque no hay automatización, le recomiendo que busque una solución similar.

Que conseguimos El monorepository general en el que se reconstruyen las linters. Es decir, todos escriben el código de la misma manera, tiene todo tipo de pruebas. Cualquier equipo puede venir, poner su componente y probarlo con las pruebas de la unidad JS, cubrirlo con capturas de pantalla, etc. Todo ya estará listo para usar. La revisión inteligente del código que mencioné. Gracias a las ricas herramientas internas, es realmente inteligente aquí.
¿El desarrollador está de vacaciones ahora? Llamarlo a una solicitud de extracción no tiene sentido; el sistema lo tendrá en cuenta. ¿Está enfermo el desarrollador? El sistema también tendrá esto en cuenta. Si no se cumplen ambas condiciones y el desarrollador parece ser libre, recibirá una notificación en uno de sus mensajeros de su elección. Y él es así: no, ahora estoy ocupado con algo urgente o en una reunión. Él puede venir allí y simplemente escribir el comando / busy. El sistema comprenderá automáticamente que debe asignar el siguiente de la lista.
El siguiente paso es publicar la misma versión canaria. Es decir, con cualquier cambio de código, necesitamos lanzar un paquete de servicios que podamos verificar en diferentes servicios. A continuación, debemos ejecutar pruebas al implementar en todos estos servicios. Y cuando todo se unió, lanza los lanzamientos.
Si un cambio afecta a alguna estática que debe cargarse desde la CDN, debe publicarla automáticamente por separado. . , , , , . , , , changelog - .
, , , , . , , .
, . . , , : , ? . , . . , .