
Hace casi 9 años, Cloudflare era una pequeña empresa, pero no trabajé en ella, solo era un cliente. Un mes después de lanzar Cloudflare, recibí una notificación de que DNS no parece estar funcionando en mi sitio web jgc.org. Cloudflare hizo un cambio en Protocol Buffers y hubo un DNS roto.
Inmediatamente le escribí a Matthew Prince, encabezando la carta "¿Dónde está mi DNS?", Y él envió una respuesta larga, llena de detalles técnicos ( lea toda la correspondencia aquí ), a lo que respondí:
De: John Graham Cumming
Fecha: 7 de octubre de 2010 9:14
Asunto: Re: ¿Dónde está mi DNS?
Para: Matthew Prince
Buen informe, gracias. Definitivamente llamaré si hay problemas. Probablemente valga la pena escribir una publicación sobre esto cuando recopiles toda la información técnica. Creo que a la gente le gustará una historia abierta y honesta. Especialmente si le adjuntas gráficos para mostrar cómo creció el tráfico después del lanzamiento.
Tengo un buen monitoreo en el sitio y recibo un SMS sobre cada falla. El monitoreo muestra que la falla fue de 13:03:07 a 14:04:12. Las pruebas se realizan cada cinco minutos.
Estoy seguro de que lo descubrirás. ¿Definitivamente no necesitas tu propia persona en Europa? :-)
Y él respondió:
De: Matthew Prince
Fecha: 7 de octubre de 2010, 9:57
Asunto: Re: ¿Dónde está mi DNS?
Para: John Graham Cumming
Gracias Respondimos a todos los que escribieron. Voy a la oficina ahora, y escribiremos algo en el blog o publicaremos una publicación oficial en nuestro tablón de anuncios. Estoy completamente de acuerdo, la honestidad es nuestro todo.
Ahora Cloudflare es una compañía realmente grande, trabajo en ella y ahora tengo que escribir abiertamente sobre nuestro error, sus consecuencias y nuestras acciones.
2 de julio eventos
El 2 de julio, implementamos una nueva regla en reglas administradas para WAF, debido a qué recursos de procesador se agotaron en cada núcleo de procesador que procesa el tráfico HTTP / HTTPS en la red Cloudflare en todo el mundo. Mejoramos constantemente las reglas administradas para WAF en respuesta a nuevas vulnerabilidades y amenazas. En mayo, por ejemplo, nos apresuramos a agregar una regla para protegernos de una vulnerabilidad grave en SharePoint. El objetivo de nuestro WAF es la capacidad de implementar reglas de manera rápida y global.
Desafortunadamente, la actualización del jueves pasado contenía una expresión regular que gastaba demasiados recursos de procesador dedicados a HTTP / HTTPS en el seguimiento. Esto afectó nuestras funciones principales de proxy, CDN y WAF. El gráfico muestra que los recursos del procesador para atender el tráfico HTTP / HTTPS alcanzan casi el 100% en los servidores de nuestra red.
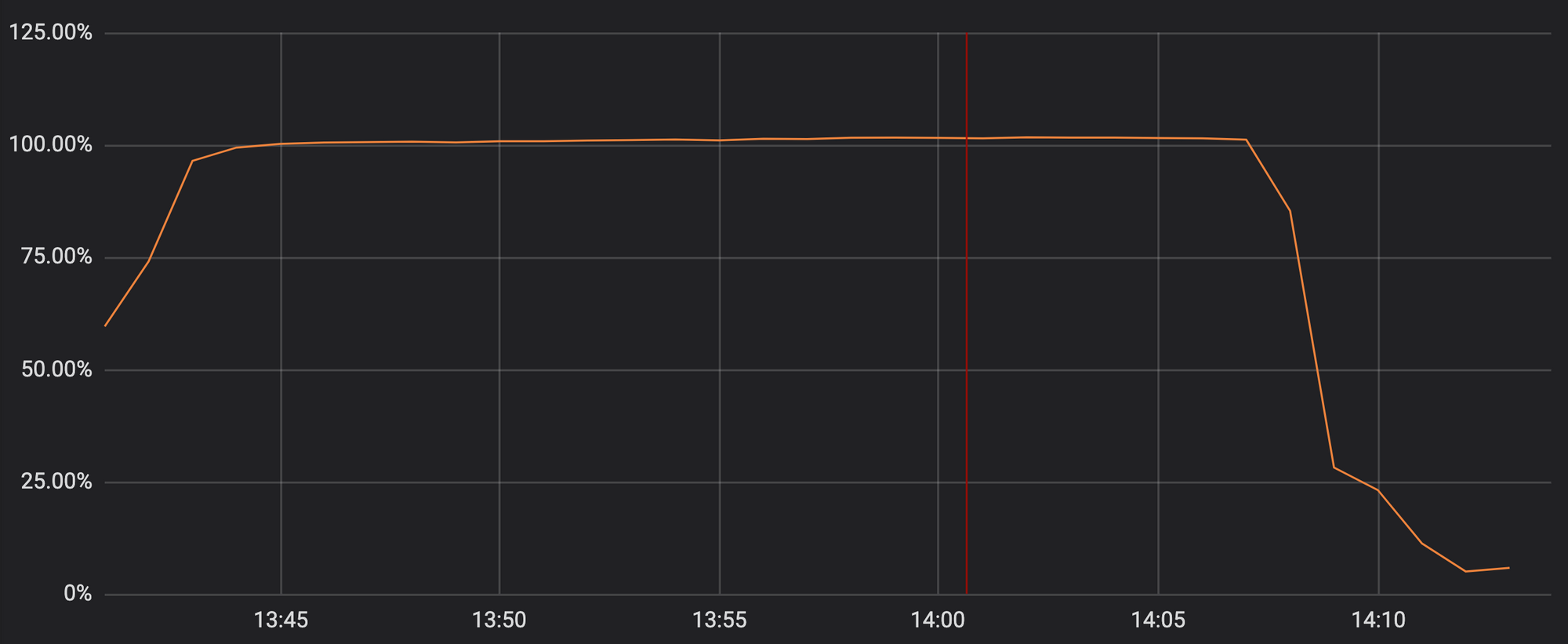
Usar los recursos del procesador en uno de los puntos de presencia durante un incidente
Como resultado, nuestros clientes (y los clientes de nuestros clientes) se encontraron con una página con un error 502 en los dominios de Cloudflare. Los servidores web front-end Cloudflare generaron 502 errores, que todavía tenían núcleos libres, pero no pudieron contactar con los procesos que procesan el tráfico HTTP / HTTPS.
Sabemos cuántos inconvenientes esto causó a nuestros clientes. Estamos terriblemente avergonzados. Y esta falla nos impidió lidiar efectivamente con el incidente.
Si fueras uno de estos clientes, probablemente te asustó, enojó y molestó. Además, no hemos tenido fallas globales durante 6 años. El alto consumo de CPU se debió a una regla WAF con una expresión regular mal formulada, lo que condujo a un retroceso excesivo. Aquí está la expresión culpable: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Aunque es interesante en sí mismo (y le contaré más al respecto a continuación), el servicio Cloudflare se cortó durante 27 minutos, no solo debido a la expresión regular no apta. Nos tomó un tiempo describir la secuencia de eventos que llevaron al fracaso, por lo que no respondimos rápidamente. Al final de la publicación, describiré el retroceso en expresión regular y le diré qué hacer al respecto.
Que paso
Comencemos en orden. Todo el tiempo se indica aquí en UTC.
A las 13:42, un ingeniero del equipo de firewall realizó un pequeño cambio en las reglas para detectar XSS mediante un proceso automático. En consecuencia, se creó un ticket de solicitud de cambio. Gestionamos estos tickets a través de Jira (captura de pantalla a continuación).
Después de 3 minutos, apareció la primera página PagerDuty, informando un problema con WAF. Fue una prueba sintética que verifica la funcionalidad de WAF (tenemos cientos de ellas) fuera de Cloudflare para monitorear el funcionamiento normal. Luego, inmediatamente hubo páginas con notificaciones de fallas de otras pruebas de extremo a extremo de los servicios de Cloudflare, problemas de tráfico global, errores generalizados 502 y un montón de informes de nuestros puntos de presencia (PoP) en ciudades de todo el mundo que indicaban una falta de recursos de procesador.


Recibí varias de esas notificaciones, me salí de la reunión y ya estaba caminando hacia la mesa cuando el jefe de nuestro departamento de desarrollo de soluciones dijo que perdimos el 80% del tráfico. Me encontré con nuestros ingenieros de SRE que ya estaban trabajando en el problema. Al principio pensamos que era algún tipo de ataque desconocido.

Los ingenieros de Cloudflare SRE están dispersos por todo el mundo y monitorean la situación durante todo el día. Por lo general, tales alertas le notifican problemas locales específicos de alcance limitado, se monitorean en paneles internos y se resuelven muchas veces al día. Pero tales páginas y notificaciones indicaron algo realmente serio, y los ingenieros de SRE anunciaron de inmediato el nivel de gravedad P0 y recurrieron a los ingenieros de administración y sistemas.
Nuestros ingenieros de Londres en ese momento estaban escuchando una conferencia en la sala principal. La conferencia tuvo que ser interrumpida, todos se reunieron en una gran sala de conferencias y se invitó a más expertos. Este no era un problema común que SRE pudiera resolver por sí mismos. Era urgente conectar a los especialistas correctos.
A las 14:00 determinamos que había un problema con WAF y que no hubo ataque. El departamento de rendimiento recuperó los datos del procesador y se hizo evidente que la culpa era de WAF. Otro colaborador confirmó esta teoría con strace. Alguien más vio en los registros que el problema con WAF. A las 14:02, todo el equipo se acercó a mí cuando se me propuso usar la destrucción global, un mecanismo integrado en Cloudflare que desactiva un componente en todo el mundo.
La forma en que matamos globalmente a WAF es una historia aparte. No es tan simple. Usamos nuestros propios productos, y dado que nuestro servicio de acceso no funcionaba, no podíamos autenticarnos e ingresar al panel de control interno (cuando todo fue reparado, supimos que algunos miembros del equipo perdieron el acceso debido a una característica de seguridad que deshabilita las credenciales si No use el panel de control interno por mucho tiempo).
Y no pudimos acceder a nuestros servicios internos, como Jira o el sistema de compilación. Necesitábamos una solución alternativa, que usábamos con poca frecuencia (esto también debería resolverse). Finalmente, un ingeniero pudo cortar WAF a las 14:07, y a las 14:09 el nivel de tráfico y procesador en todas partes volvió a la normalidad. El resto de los mecanismos de defensa de Cloudflare funcionaron como se esperaba.
Luego nos pusimos a restaurar WAF. La situación era fuera de lo común, por lo que realizamos pruebas negativas (preguntándonos si el problema realmente era este cambio) y positivas (asegurándonos de que la reversión funcionó) en una ciudad usando tráfico separado, transfiriendo clientes pagados desde allí.
A las 2:52 p.m., estábamos convencidos de que entendíamos el motivo, hicimos una corrección y volvimos a encender el WAF.
Cómo funciona Cloudflare
Cloudflare tiene un equipo de ingenieros que administran las reglas administradas para WAF. Intentan aumentar la tasa de detección, reducir la cantidad de falsos positivos y responder rápidamente a las nuevas amenazas a medida que surgen. En los últimos 60 días, se han procesado 476 solicitudes de cambio para reglas administradas por WAF (en promedio, una cada 3 horas).
Este cambio en particular necesitaba implementarse en modo de simulación, donde el tráfico real del cliente pasa a través de la regla, pero nada está bloqueado. Utilizamos este modo para verificar la efectividad de las reglas y medir la proporción de resultados falsos positivos y falsos negativos. Pero incluso en modo de simulación, las reglas deben ejecutarse realmente, y en este caso, la regla contenía una expresión regular que consumía demasiados recursos de procesador.
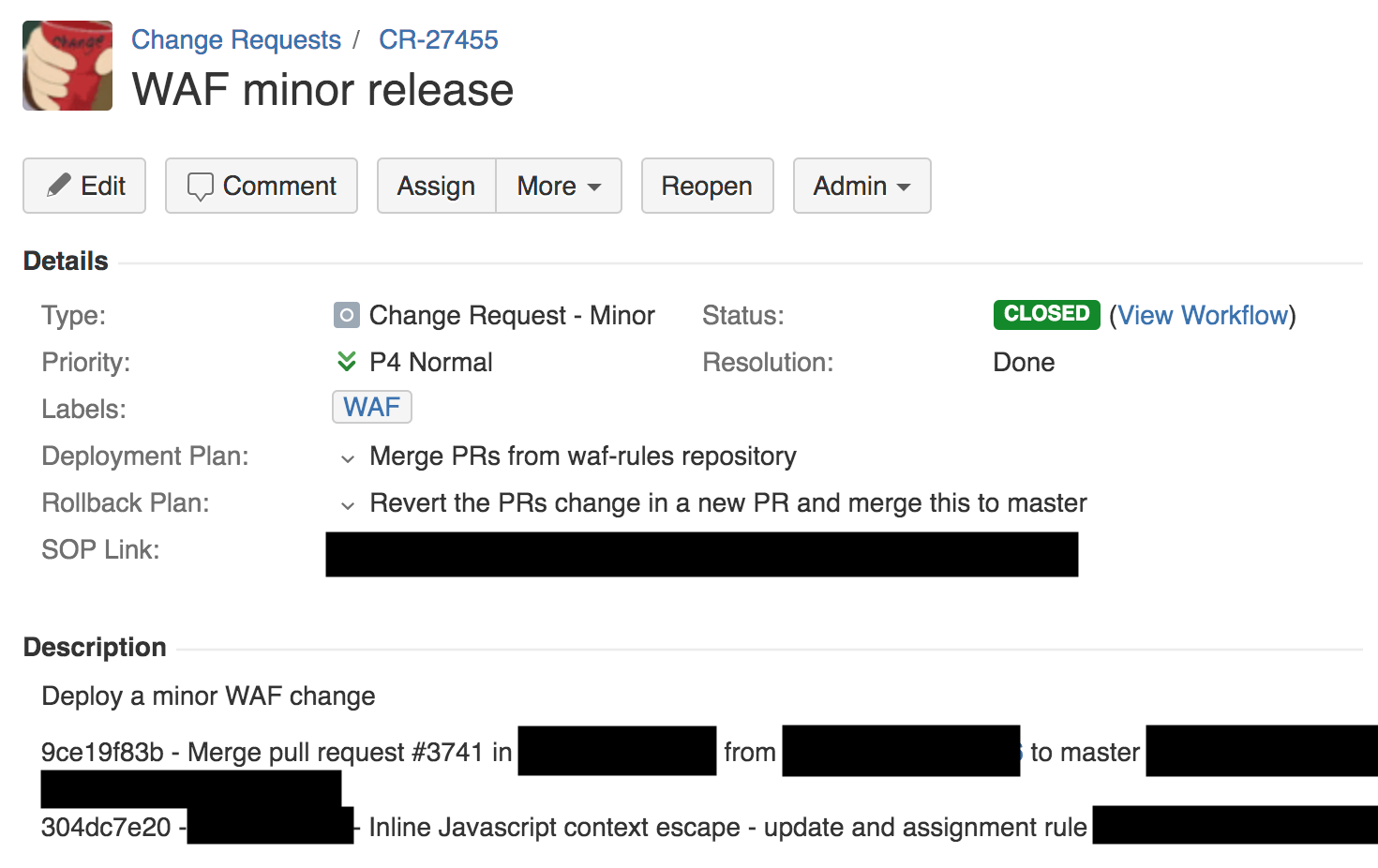
Como puede ver en la solicitud de cambio anterior, tenemos un plan de implementación, un plan de reversión y un enlace al procedimiento operativo estándar interno (SOP) para este tipo de implementación. El SOP para cambiar una regla permite publicarlo globalmente. De hecho, en Cloudflare, todo está organizado de manera completamente diferente, y SOP requiere primero enviar el software para pruebas y uso interno a un punto de presencia interno (PoP) (que usan nuestros empleados), luego a un pequeño número de clientes en un lugar aislado, luego a un gran número de clientes, y solo entonces a todo el mundo
Así es como se ve. Usamos git en el sistema interno a través de BitBucket. Los ingenieros de cambio envían el código que compilan a TeamCity, y cuando la compilación pasa, se asignan revisores. Cuando se aprueba la solicitud del grupo, se recopila el código y se realizan una serie de pruebas (nuevamente).
Si el ensamblaje y las pruebas tienen éxito, se crea una solicitud de cambio en Jira, y el cambio debe ser aprobado por el supervisor apropiado o el especialista principal. Después de la aprobación, se despliega en la llamada "casa de fieras PoP": PERRO, CERDO y Canario (perro, paperas y canario).
DOG PoP es Cloudflare PoP (como cualquier otra de nuestras ciudades), que solo usan los empleados de Cloudflare. PoP para uso interno le permite detectar problemas incluso antes de que la solución comience a recibir tráfico de clientes. Cosa útil
Si la prueba DOG tiene éxito, el código pasa a la etapa PIG (conejillo de indias). Este es Cloudflare PoP, donde una pequeña cantidad de tráfico de cliente libre fluye a través del nuevo código.
Si todo está bien, el código va a Canarias. Tenemos tres PoP Canarios en diferentes partes del mundo. El tráfico de clientes pagos y gratuitos pasa a través del nuevo código en ellos, y esta es la última comprobación de errores.

Proceso de lanzamiento del software Cloudflare
Si el código está bien en Canarias, lo publicamos. Pasar por todas las etapas (DOG, PIG, Canary, todo el mundo) lleva varias horas o días, dependiendo del cambio de código. Debido a la diversidad de la red y los clientes de Cloudflare, probamos a fondo el código antes de un lanzamiento global para todos los clientes. Pero WAF no sigue específicamente este proceso porque las amenazas deben ser respondidas rápidamente.
Amenazas WAF
En los últimos años, ha habido muchas más amenazas en las aplicaciones convencionales. Esto se debe a la mayor disponibilidad de herramientas de prueba de software. Por ejemplo, recientemente escribimos sobre fuzzing ).
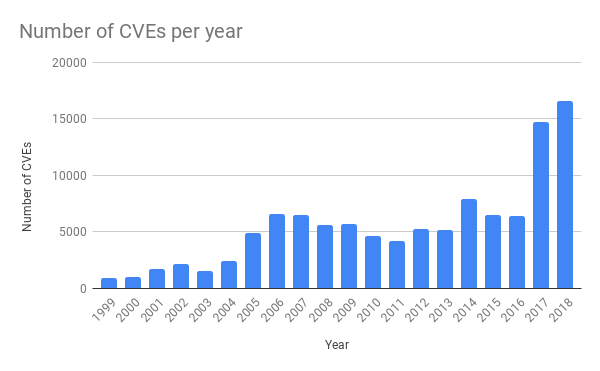
Fuente: https://cvedetails.com/
Muy a menudo, se crea una confirmación del concepto y se publica inmediatamente en Github para que los equipos que dan servicio a la aplicación puedan probarla rápidamente y asegurarse de que esté adecuadamente protegida. Por lo tanto, Cloudflare necesita la capacidad de responder a nuevos ataques lo más rápido posible para que los clientes tengan la oportunidad de arreglar su software.
Un gran ejemplo de la respuesta rápida de Cloudflare es la implementación de la protección contra vulnerabilidades de SharePoint en mayo ( lea aquí ). Casi inmediatamente después de la publicación de los anuncios, notamos una gran cantidad de intentos de aprovechar la vulnerabilidad en las instalaciones de SharePoint de nuestros clientes. Nuestros muchachos constantemente monitorean nuevas amenazas y escriben reglas para proteger a nuestros clientes.
La regla que causó el problema el jueves fue proteger contra las secuencias de comandos entre sitios (XSS). También ha habido muchos más ataques de este tipo en los últimos años.
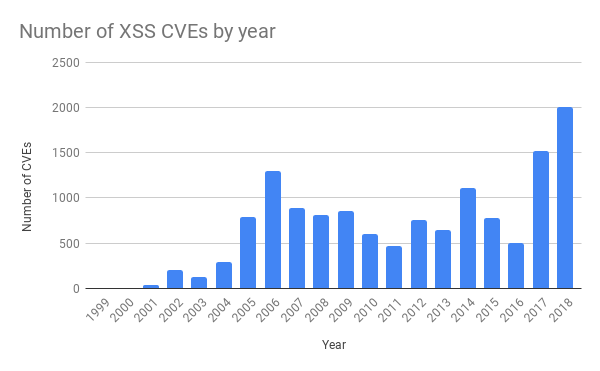
Fuente: https://cvedetails.com/
El procedimiento estándar para modificar una regla administrada para WAF requiere pruebas de integración continua (CI) antes de la implementación global. El jueves pasado lo hicimos y ampliamos las reglas. A las 13:31, un ingeniero envió una solicitud de grupo aprobada con un cambio.
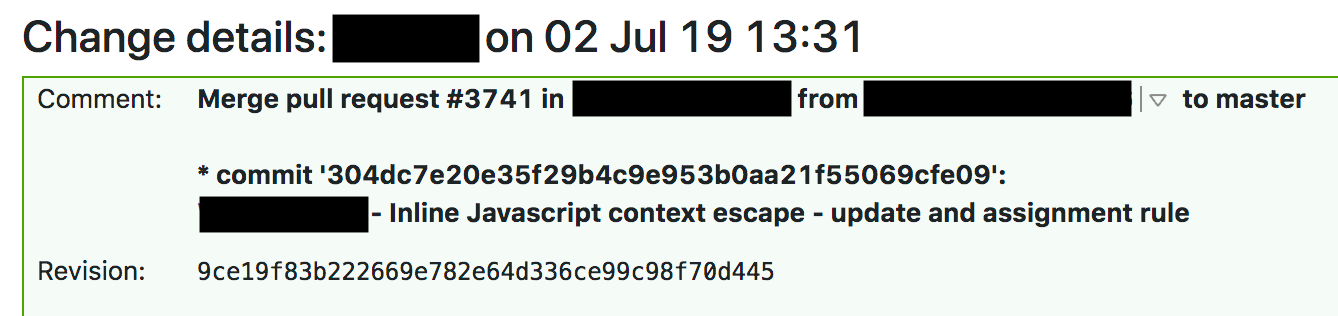
A las 13:37, TeamCity reunió las reglas, realizó las pruebas y dio el visto bueno. El conjunto de pruebas WAF prueba la funcionalidad central de WAF y consta de una gran cantidad de pruebas unitarias para funciones individuales. Después de las pruebas unitarias, verificamos las reglas para WAF con una gran cantidad de solicitudes HTTP. Las solicitudes HTTP verifican qué solicitudes debe bloquear WAF (para interceptar el ataque) y cuáles se pueden omitir (para no bloquear todo y evitar falsos positivos). Pero no realizamos pruebas para el uso excesivo de los recursos del procesador, y el estudio de los registros de ensamblajes WAF anteriores muestra que el tiempo de ejecución de la prueba con la regla no aumentó, y era difícil sospechar que no había suficientes recursos.
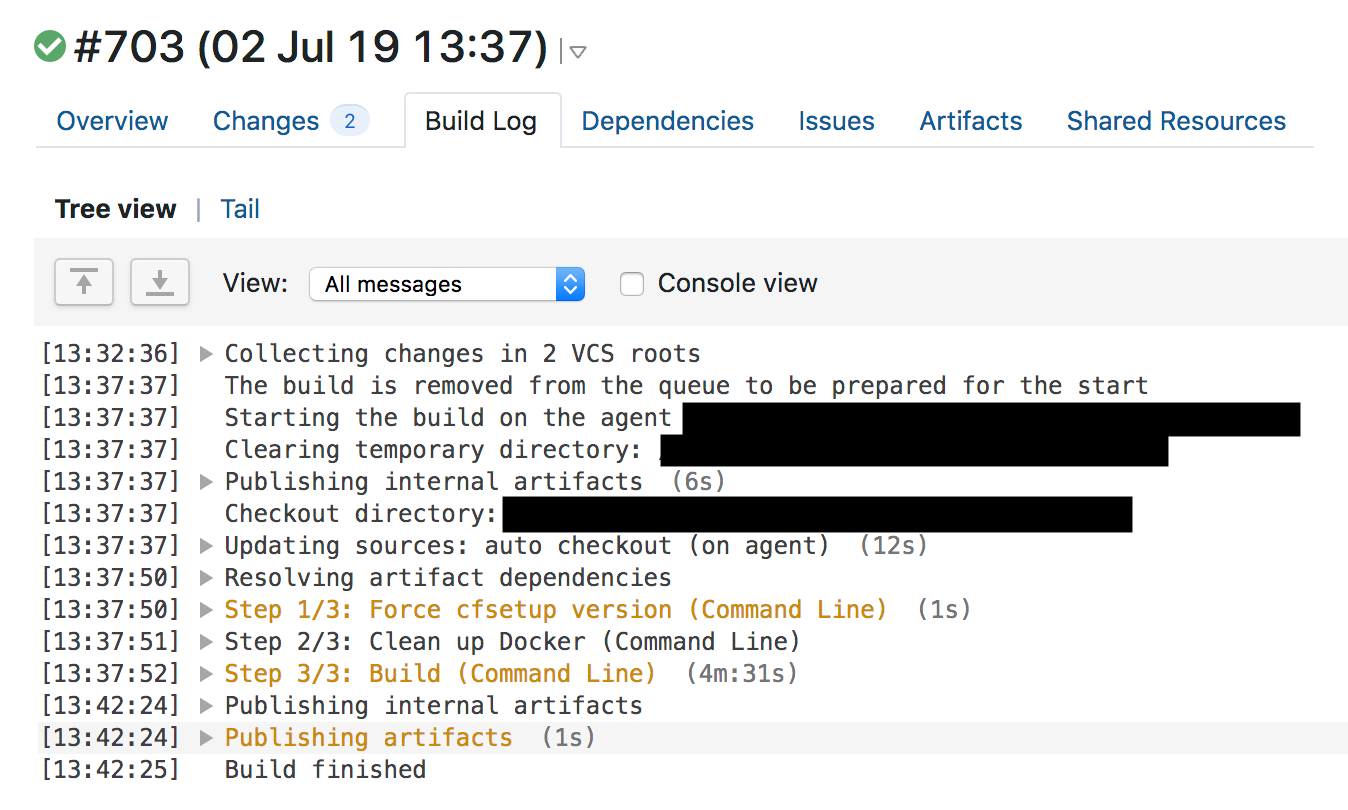
Se aprobaron las pruebas y TeamCity comenzó a implementar automáticamente el cambio a las 13:42.
Mercurio
Las reglas de WAF abordan la eliminación urgente de amenazas, por lo que las implementamos utilizando los pares de clave-valor distribuidos Quicksilver, que distribuye los cambios a nivel mundial en segundos. Todos nuestros clientes usan esta tecnología cuando cambian la configuración en el tablero o a través de la API, y es gracias a eso que respondemos a los cambios con la velocidad del rayo.
Hablamos un poco sobre Quicksilver. Solíamos usar Kyoto Tycoon como un repositorio distribuido globalmente de pares clave-valor, pero había problemas operativos con él, y escribimos nuestro repositorio replicado en más de 180 ciudades. Ahora, con Quicksilver, enviamos cambios en la configuración del cliente, actualizamos las reglas de WAF y distribuimos el código JavaScript escrito por los clientes en Cloudflare Workers.
Solo toma unos segundos para que una configuración dé la vuelta al mundo presionando un botón en un tablero o llamando a una API para hacer cambios en la configuración. Los clientes adoran esta configuración de velocidad. Y Workers les proporciona una implementación de software global casi instantánea. En promedio, Quicksilver distribuye alrededor de 350 cambios por segundo.
Y Quicksilver es muy rápido. En promedio, alcanzamos el percentil 99 de 2.29 para propagar los cambios a todas las computadoras del mundo. Por lo general, la velocidad es buena. Después de todo, cuando enciende una función o borra el caché, ocurre casi al instante y en todas partes. El envío de código a través de Cloudflare Workers es a la misma velocidad. Cloudflare promete a sus clientes actualizaciones rápidas en el momento adecuado.
Pero en este caso, la velocidad nos jugó una mala pasada, y las reglas cambiaron en todas partes en cuestión de segundos. Probablemente hayas notado que el código WAF usa Lua. Cloudflare hace un uso extensivo de Lua en el entorno de producción y ya hemos discutido los detalles de Lua en WAF . Lua WAF utiliza PCRE internamente y aplica el seguimiento posterior para la coincidencia. No tiene mecanismos de defensa contra expresiones que están fuera de control. A continuación hablaré más sobre esto y lo que estamos haciendo con él.

Antes de que se implementaran las reglas, todo transcurrió sin problemas: la solicitud del grupo se creó y aprobó, la canalización de CI / CD compiló y probó el código, la solicitud de cambio se envió de acuerdo con el SOP, que regula el despliegue y la reversión, y el despliegue se completó.

Proceso de implementación de CloudFare WAF
Que salió mal
Como dije antes, implementamos docenas de nuevas reglas WAF cada semana, y tenemos muchos sistemas de protección contra las consecuencias negativas de tal implementación. Y cuando algo sale mal, generalmente es una combinación de varias circunstancias. Si encuentra una sola razón, esto, por supuesto, es tranquilizador, pero no siempre es cierto. Estas son las razones que juntas llevaron a la falla de nuestro servicio HTTP / HTTPS.
- El ingeniero escribió una expresión regular que podría conducir a un retroceso excesivo.
- Una herramienta que podría evitar el uso excesivo de los recursos del procesador utilizados por la expresión regular se eliminó por error durante la refactorización de WAF unas semanas antes; se necesitaba refactorizar para que WAF consumiera menos recursos.
- El motor regex no tenía garantías de complejidad.
- El conjunto de pruebas no pudo revelar un consumo excesivo de CPU.
- El procedimiento SOP permite el despliegue global de cambios de reglas no urgentes sin un proceso de varios pasos.
- El plan de reversión requirió un ensamblaje WAF completo dos veces, lo que llevó mucho tiempo.
- La primera alerta de alerta de tráfico global funcionó demasiado tarde.
- Retrasamos la actualización de la página de estado.
- Tuvimos problemas para acceder a los sistemas debido a un bloqueo, y la solución no se resolvió lo suficientemente bien.
- Los ingenieros de SRE han perdido el acceso a algunos sistemas porque sus credenciales han expirado por razones de seguridad.
- Nuestros clientes no tenían acceso al panel o API de Cloudflare porque atraviesan la región de Cloudflare.
Lo que ha cambiado desde el jueves pasado
Primero, detuvimos completamente todo el trabajo en lanzamientos para WAF y hacemos lo siguiente:
- Reintroduciendo la protección contra los recursos excesivos del procesador que eliminamos. (Hecho)
- Compruebe manualmente todas las reglas 3868 en las reglas administradas para que WAF encuentre y repare otros casos potenciales de retroceso excesivo. (Verificación completada)
- Incluimos perfiles de rendimiento para todas las reglas en el conjunto de pruebas. (Esperado: 19 de julio)
- Cambiamos al motor re2 o Rust regex , ambos brindan garantías en el tiempo de ejecución. (Esperado: 31 de julio)
- Reescribimos SOP para implementar las reglas en etapas, como otro software en Cloudflare, pero al mismo tiempo tenemos la capacidad de una implementación global de emergencia si los ataques ya han comenzado.
- Estamos desarrollando la posibilidad de retirar urgentemente el panel de control de Cloudflare y la API de la región de Cloudflare.
- Estamos automatizando la actualización de la página de estado de Cloudflare .
A la larga, estamos abandonando Lua WAF, que escribí hace varios años. Migramos WAF al nuevo sistema de firewall . Entonces WAF será más rápido y recibirá un nivel adicional de protección.
Conclusión
Esta falla nos causó problemas a nosotros y a nuestros clientes. Rápidamente reaccionamos para corregir la situación, y ahora estamos trabajando en fallas en los procesos que causaron la falla, y también profundizando aún más para protegernos de posibles problemas con expresiones regulares en el futuro, cambiando a una nueva tecnología.
Estamos muy avergonzados de este fracaso, y nos disculpamos con nuestros clientes. Esperamos que estos cambios garanticen que esto no vuelva a suceder.
Solicitud Seguimiento de expresiones regulares
Para entender cómo la expresión:
(?:(?:\"|'|\]|\}|\\|\d (?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\- |\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Si se comen todos los recursos del procesador, necesita saber un poco sobre cómo funciona el motor regex estándar. El problema aquí es el patrón .*(?:.*=.*) . (?: y el correspondiente ) no es un grupo emocionante (es decir, la expresión entre paréntesis se agrupa como una expresión).
En el contexto del consumo excesivo de recursos del procesador, este patrón puede designarse como .*.*=.* . Como tal, el patrón parece innecesariamente complejo. Pero lo más importante, en el mundo real, tales expresiones (similares a las expresiones complejas en las reglas WAF) que le piden al motor que coincida con un fragmento, seguido de otro fragmento, pueden conducir a un retroceso catastrófico. Y aquí está el por qué.
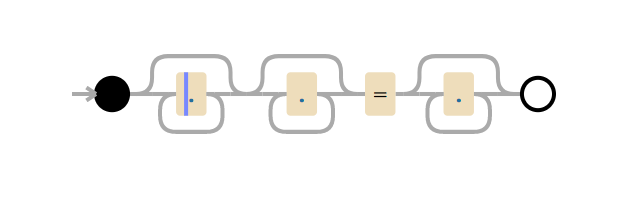
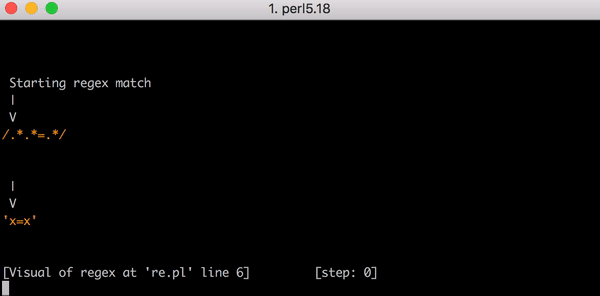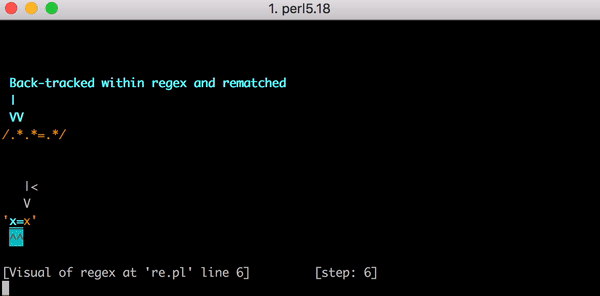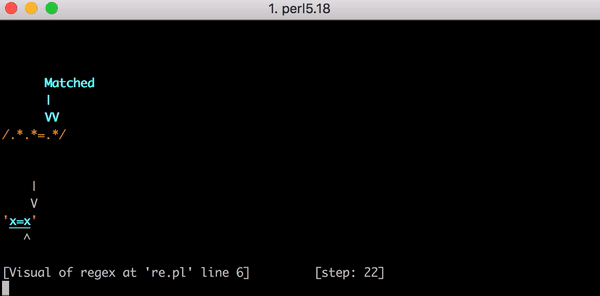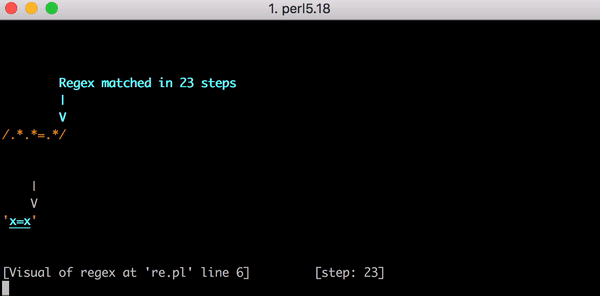
En expresión regular . significa que debe coincidir con un carácter. .* : coincide con cero o más caracteres "con avidez", es decir, captura un máximo de caracteres, por lo tanto .*.*=.* significa coincide con cero o más caracteres, luego coincide con cero o más caracteres, encuentre carácter literal =, coincide con cero o más caracteres.
Tome la línea de prueba x=x . Coincide con la expresión .*.*=.*. .*.* .*.*=.*. .*.* hasta el signo igual corresponde a la primera x (uno de los grupos .* corresponde a x , y el segundo a cero caracteres). .* after = coincide con la última x .
Para tal comparación, se necesitan 23 pasos. El primer grupo .* .*.*=.* Actúa "con avidez" y coincide con toda la línea x=x . El motor se mueve al siguiente grupo .* . Ya no tenemos caracteres para hacer coincidir, por lo que el segundo grupo .* Coincide con cero caracteres (esto está permitido). Entonces el motor va al signo = . No hay más caracteres (el primer grupo .* Se usó la expresión completa x=x ), no se produce ninguna coincidencia.
Y aquí el motor de expresión regular vuelve al principio. Él va al primer grupo .* Y lo compara x= (en lugar de x=x ), y luego toma el segundo grupo .* . El segundo grupo .* asigna a la segunda x , y nuevamente no nos quedan caracteres. Y cuando el motor alcanza = v .*.*=.* Nuevamente, no pasa nada. Y vuelve a dar marcha atrás.
Esta vez, el grupo .* Todavía coincide con x= , pero el segundo grupo .* Ya no es x , sino cero caracteres. El motor intenta encontrar el símbolo literal = en el patrón .*.*=.* , Pero no sale (después de todo, el primer grupo ya lo ha ocupado .* ). Y vuelve a dar marcha atrás.
Esta vez el primer grupo .* Toma solo la primera x. Pero el segundo grupo .* "Codicioso" captura =x . ¿Ya has adivinado lo que sucederá? El motor intenta hacer coincidir literal = , falla y realiza el siguiente retroceso.
.* x . .* = . , = , .* . . !
.* x , .* — , = = . .* x .
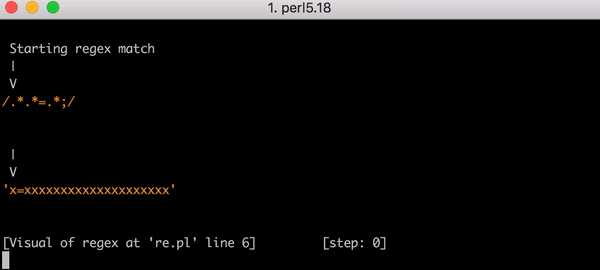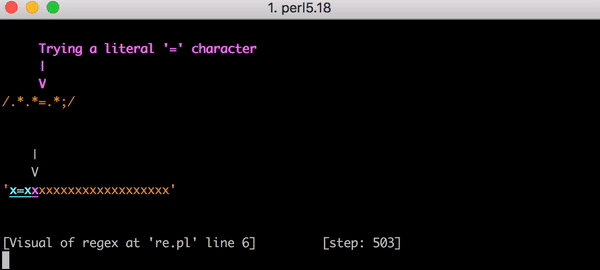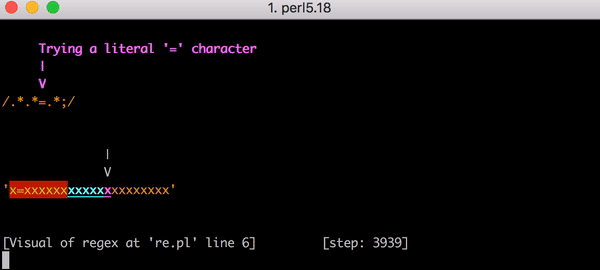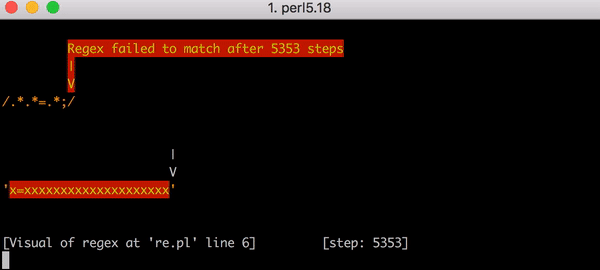
23 x=x . Perl Regexp::Debugger , , .
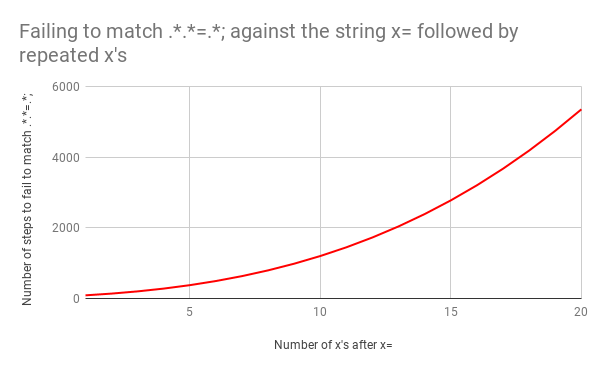
, x=x x=xx ? 33 . x=xxx ? 45. . x=x x=xxxxxxxxxxxxxxxxxxxx (20 x = ). 20 x = , 555 ! ( , x= 20 x , 4067 , , ).
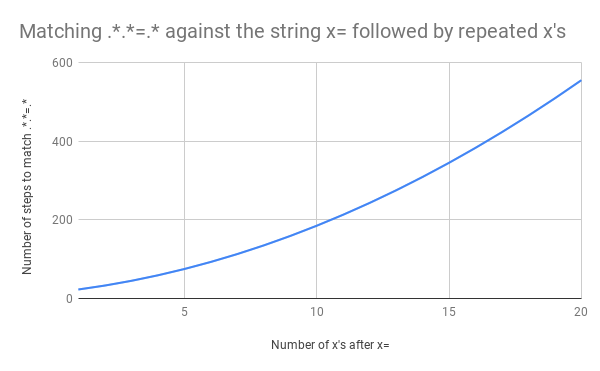
x=xxxxxxxxxxxxxxxxxxxx :
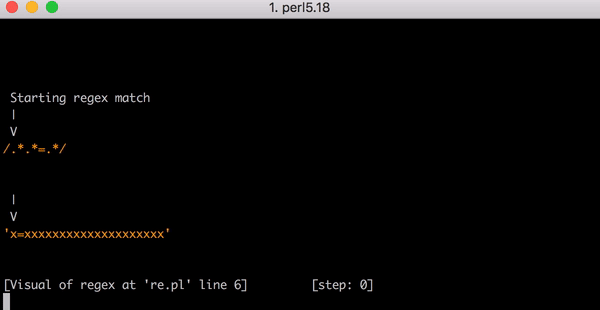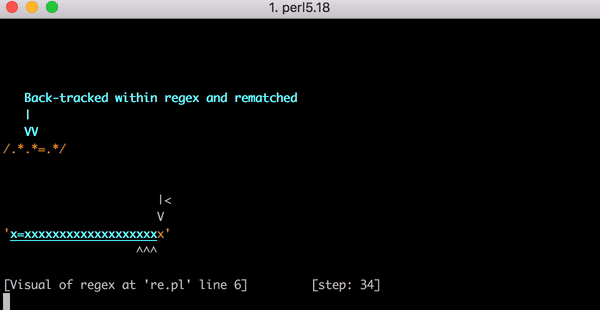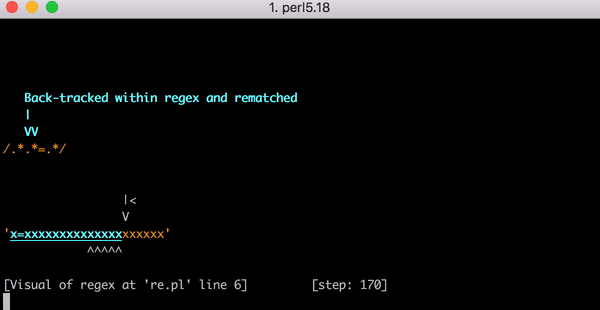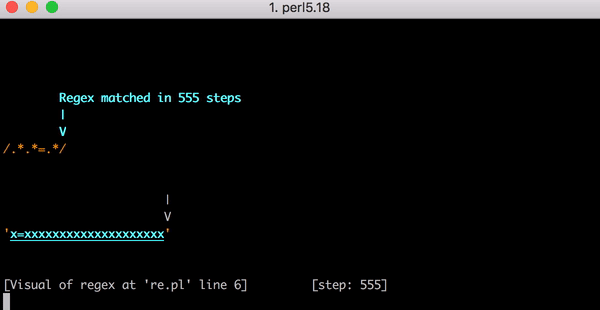
, . , . , .*.*=.* ; ( ). , , foo=bar; .
. x=x 90 , 23. . x= 20 x , 5353 . . Y .
, 5353 x=xxxxxxxxxxxxxxxxxxxx .*.*=.*;
«», «» , . .*?.*?=.*? , x=x 11 ( 23). x=xxxxxxxxxxxxxxxxxxxx . , ? .* , .
«» . .*.*=.*; .*?.*?=.*?; , . x=x 555 , x= 20 x — 5353.
, ( ) — . .
1968 , Programming Techniques: Regular expression search algorithm (« : »). , , , .

(Ken Thompson)
Bell Telephone Laboratories, Inc., -, -
. IBM 7094 . , . , .
, .
. . — .
. , . , .
, IBM 7094.
. — , . «·» . . . 2 , .
, ALGOL-60, IBM 7094. , .
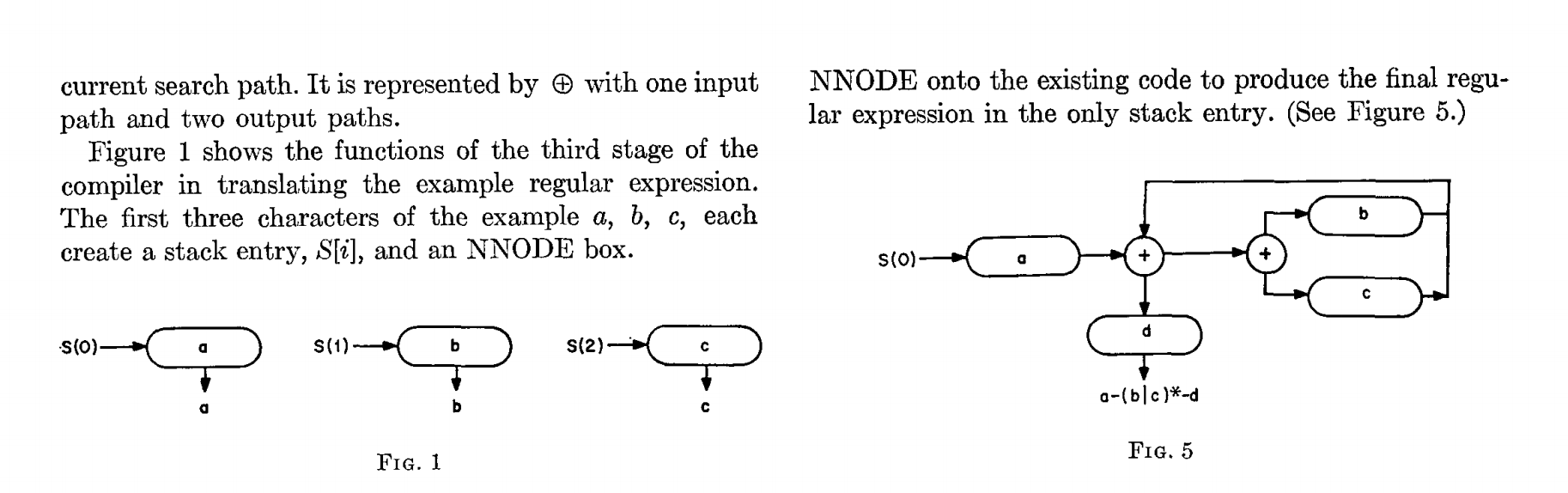
. ⊕ .
1 . — a, b, c, S[i] NNODE.
NNODE , (. . 5)
.*.*=.* , , .
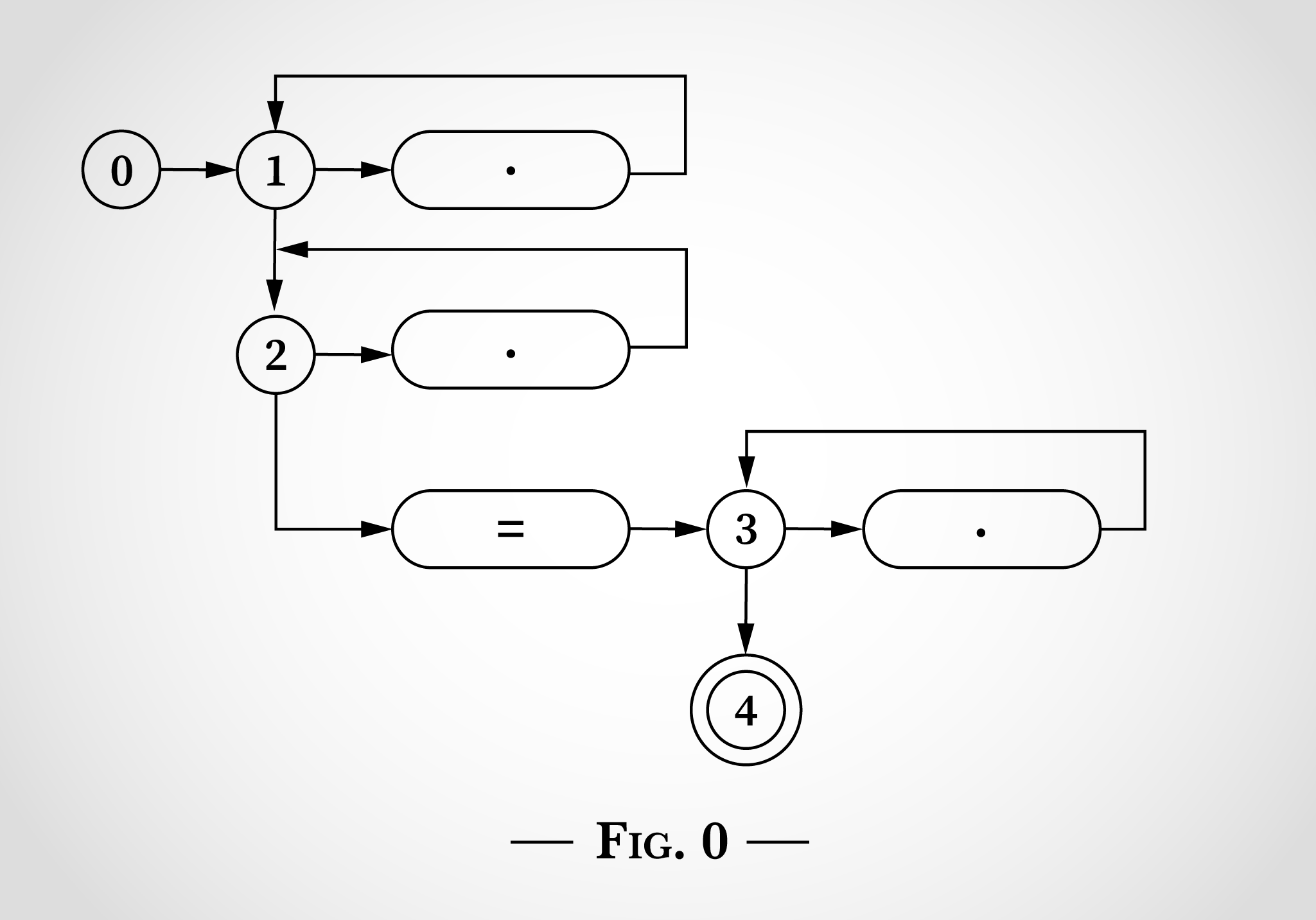
En la fig. 0 , 0, 3 , 1, 2 3. .* . 3 . = = . 4 . , .
, .*.*=.* , x=x . 0, . 1)
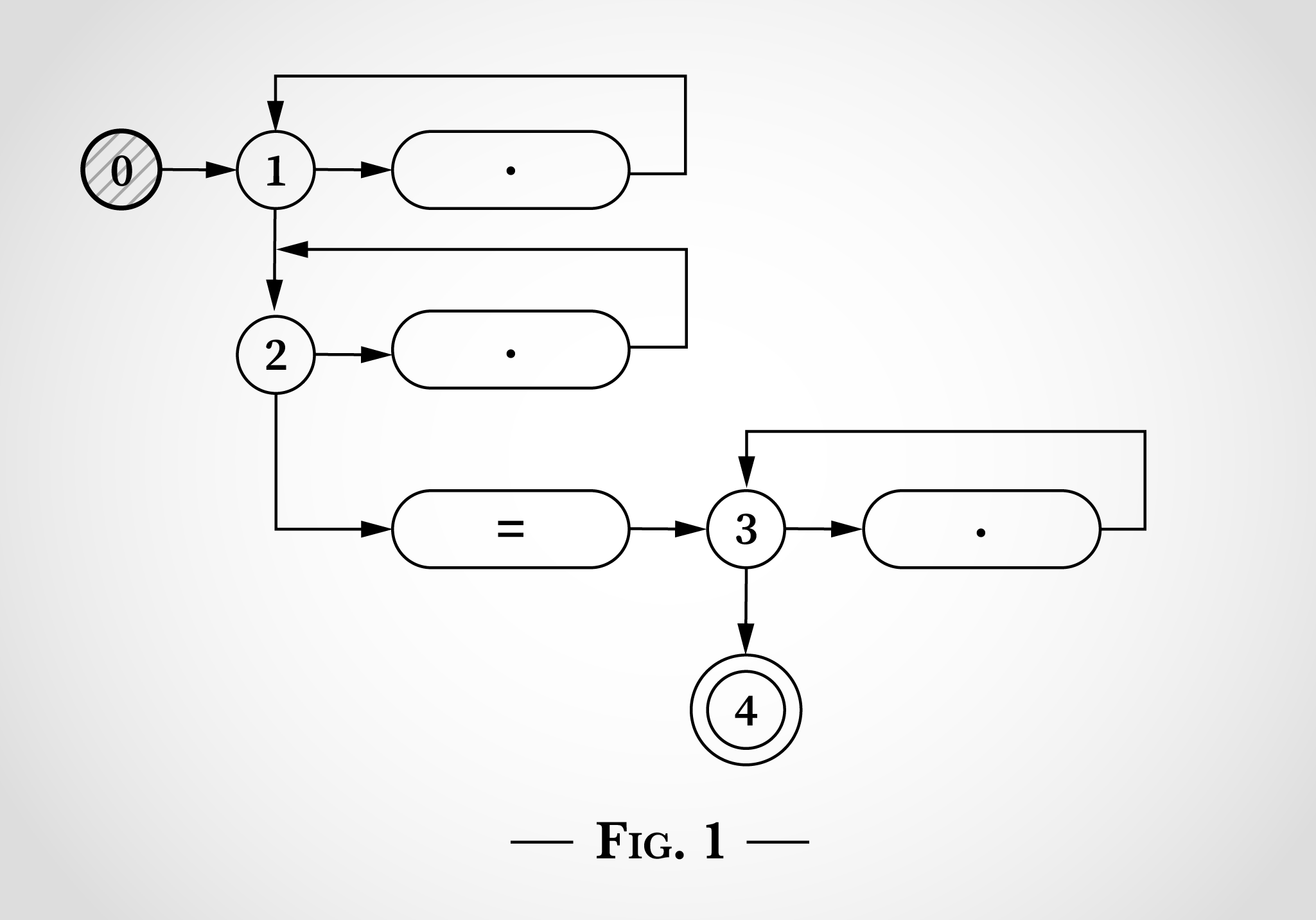
, . .
, (1 2), . 2)
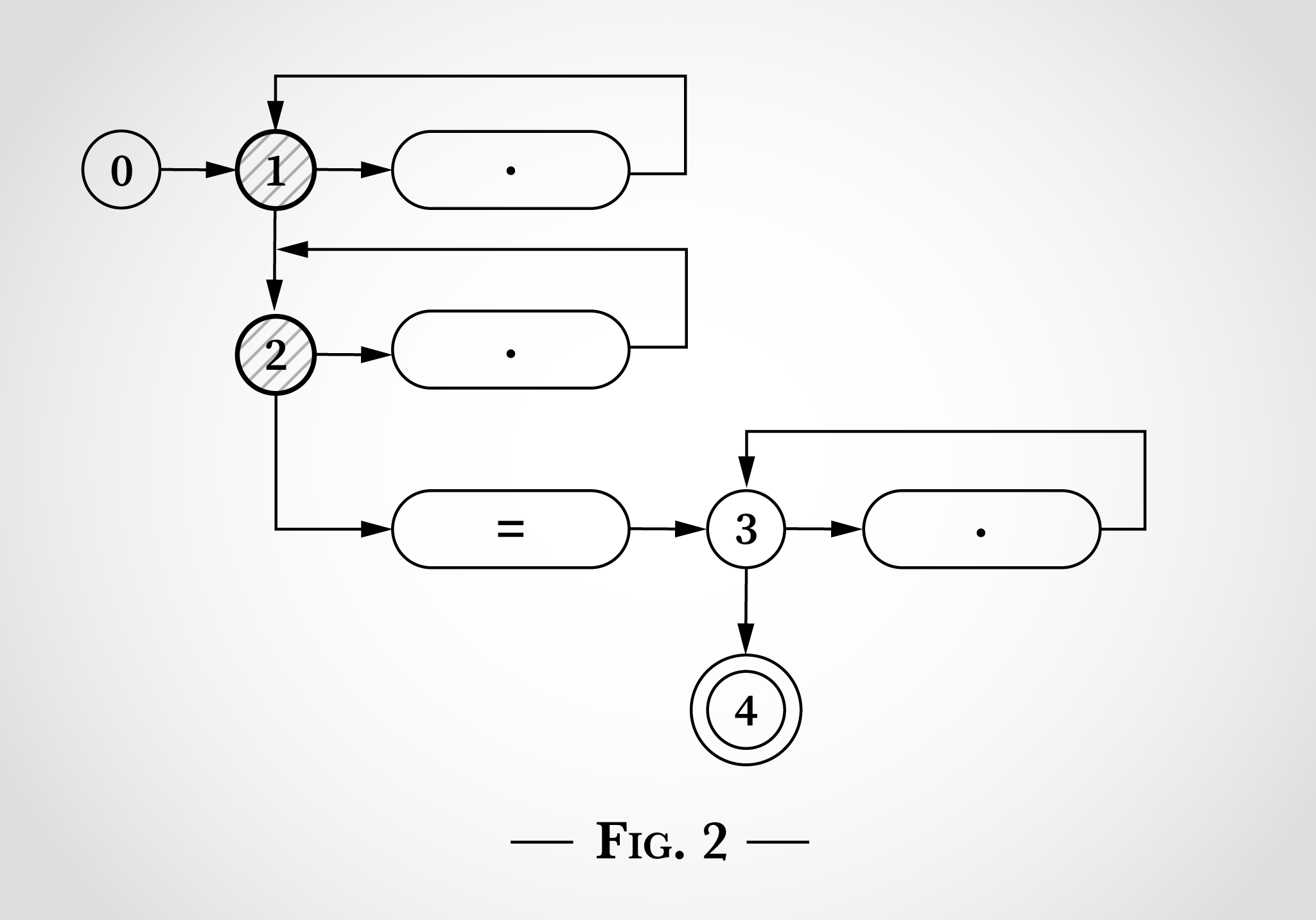
En la fig. 2 , , x x=x . x , 1 1. x , 2 2.
x x=x - 1 2. 3 4, = .
= x=x . x , 1 1 2 2, = 2 3 ( 4). . 3)
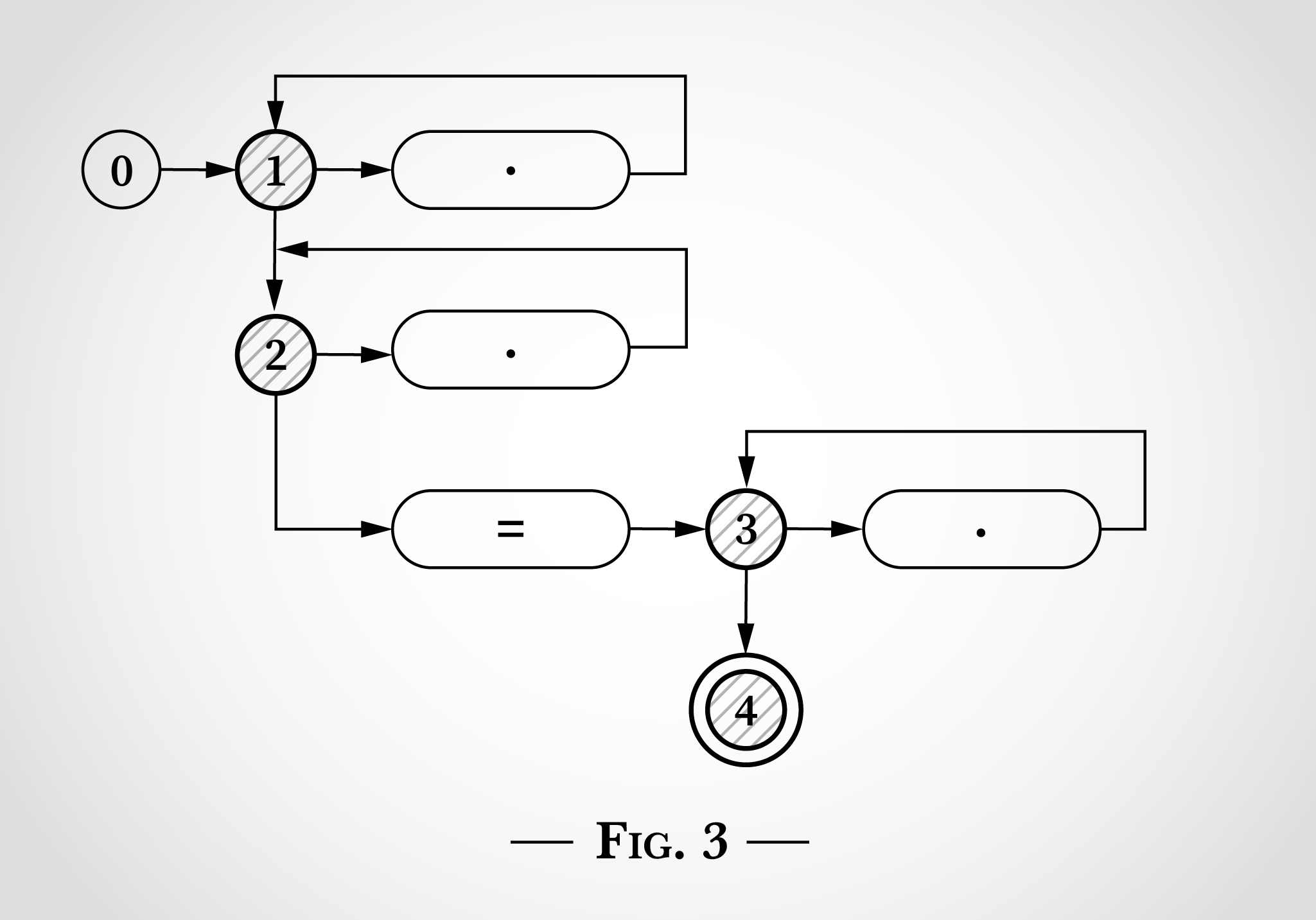
x x=x . 1 2 1 2. 3 x 3.
x=x , 4, . , . .
, 4 ( x= ) , , x .
.