 Nota perev. : Dailymotion es uno de los servicios de alojamiento de video más grandes del mundo y, por lo tanto, un notable usuario de Kubernetes. En este artículo, el arquitecto de sistemas David Donchez comparte los resultados de la creación de una plataforma de producción para la empresa basada en K8, que comenzó con una instalación en la nube en GKE y terminó como una solución híbrida, que permitió lograr un mejor tiempo de reacción y ahorrar en costos de infraestructura.
Nota perev. : Dailymotion es uno de los servicios de alojamiento de video más grandes del mundo y, por lo tanto, un notable usuario de Kubernetes. En este artículo, el arquitecto de sistemas David Donchez comparte los resultados de la creación de una plataforma de producción para la empresa basada en K8, que comenzó con una instalación en la nube en GKE y terminó como una solución híbrida, que permitió lograr un mejor tiempo de reacción y ahorrar en costos de infraestructura.Al tomar la decisión de reconstruir la API principal de
Dailymotion hace tres años, queríamos desarrollar una forma más eficiente de alojar aplicaciones y facilitar
los procesos de desarrollo y producción . Para este propósito, decidimos usar la plataforma de orquestación de contenedores y, naturalmente, elegimos Kubernetes.
¿Por qué vale la pena crear su propia plataforma basada en Kubernetes?
API de nivel de producción lo antes posible con Google Cloud
Verano de 2016
Hace tres años, justo después de que
Vivendi comprara Dailymotion, nuestros equipos de ingeniería se centraron en un objetivo global: crear un producto Dailymotion completamente nuevo.
Basado en el análisis de contenedores, soluciones de orquestación y nuestra experiencia pasada, nos aseguramos de que Kubernetes sea la elección correcta. Algunos desarrolladores ya tenían una idea de los conceptos básicos y sabían cómo usarla, lo cual era una gran ventaja para la transformación de la infraestructura.
Desde el punto de vista de la infraestructura, se requería un sistema potente y flexible para alojar nuevos tipos de aplicaciones nativas de la nube. Elegimos permanecer en la nube al comienzo de nuestro viaje para construir con calma la plataforma local más confiable. Decidieron implementar sus aplicaciones utilizando Google Kubernetes Engine, aunque sabían que tarde o temprano cambiaríamos a nuestros propios centros de datos y aplicaríamos una estrategia híbrida.
¿Por qué elegir GKE?
Tomamos esta decisión principalmente por razones técnicas. Además, era necesario proporcionar rápidamente la infraestructura que satisfaga las necesidades del negocio de la empresa. Teníamos algunos requisitos de aplicación, como distribución geográfica, escalabilidad y tolerancia a fallas.
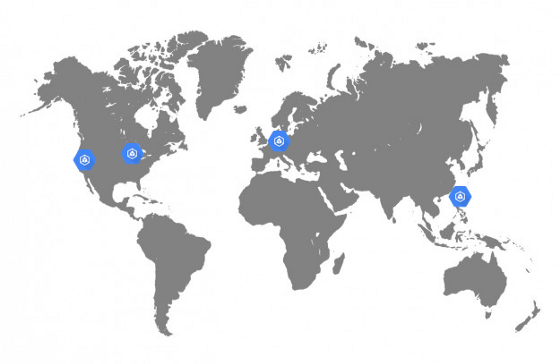 Grupos de GKE en Dailymotion
Grupos de GKE en DailymotionDado que Dailymotion es una plataforma de video disponible en todo el mundo, realmente queríamos mejorar la calidad del servicio reduciendo la
latencia . Anteriormente,
nuestra API solo estaba disponible en París, lo que no era óptimo. Quería poder alojar aplicaciones no solo en Europa, sino también en Asia y Estados Unidos.
Esta sensibilidad a los retrasos significaba que tendríamos que trabajar seriamente en la arquitectura de red de la plataforma. Si bien la mayoría de los servicios en la nube los obligaron a crear su propia red en cada región y luego conectarlos a través de una VPN o un determinado servicio administrado, Google Cloud hizo posible crear una red unificada totalmente enrutable que cubriera todas las regiones de Google. Esta es una gran ventaja en términos de operación y eficiencia del sistema.
Además, los servicios de red y los equilibradores de carga de Google Cloud hacen un excelente trabajo. Simplemente le permiten usar direcciones IP públicas arbitrarias de cada región, y el maravilloso protocolo BGP se encarga del resto (es decir, redirige a los usuarios al clúster más cercano). Obviamente, en caso de falla, el tráfico irá automáticamente a otra región sin intervención humana.
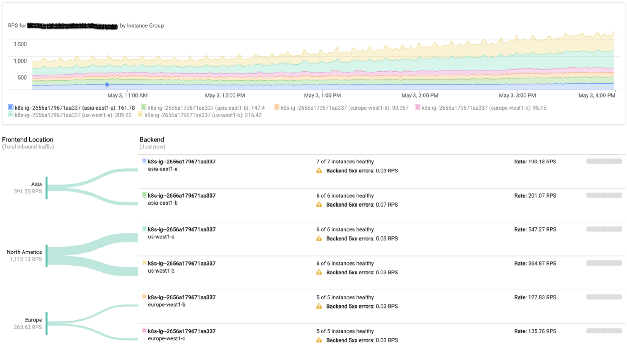 Monitoreo de equilibrio de carga de Google
Monitoreo de equilibrio de carga de GoogleNuestra plataforma también utiliza activamente procesadores gráficos. Google Cloud hace que sea extremadamente eficiente usarlos directamente en clústeres de Kubernetes.
En ese momento, el equipo de infraestructura se concentró principalmente en la antigua pila implementada en servidores físicos. Es por eso que el uso de un servicio administrado (incluidos los componentes maestros de Kubernetes) cumplió con nuestros requisitos y nos permitió capacitar a los equipos para trabajar con clústeres locales.
Como resultado, pudimos comenzar a aceptar el tráfico de producción en la infraestructura de Google Cloud solo 6 meses después del inicio del trabajo.
Sin embargo, a pesar de una serie de ventajas, trabajar con un proveedor de la nube está asociado con ciertos costos, que pueden aumentar dependiendo de la carga. Es por eso que analizamos cuidadosamente cada servicio administrado usado, con la esperanza de implementarlos en las instalaciones en el futuro. De hecho, la introducción de los clústeres locales comenzó a fines de 2016 y al mismo tiempo se inició una estrategia híbrida.
Lanzamiento de la plataforma de orquestación de contenedores locales Dailymotion
Otoño 2016
En condiciones en que toda la pila estaba lista para la producción, y el trabajo en la API
continuaba , había tiempo para concentrarse en los clústeres regionales.
En ese momento, los usuarios veían más de 3 mil millones de videos cada mes. Por supuesto, llevamos años ejecutando nuestra propia red de distribución de contenido ramificada. Queríamos aprovechar esta circunstancia e implementar clústeres de Kubernetes en los centros de datos existentes.
La infraestructura de Dailymotion totalizó más de 2.5 mil servidores en seis centros de datos. Todos están configurados con Saltstack. Comenzamos a preparar todas las recetas necesarias para crear nodos maestros y trabajadores, así como un clúster, etc.

Parte de la red
Nuestra red es completamente enrutable. Cada servidor anuncia su IP en la red usando Exabgp. Comparamos varios complementos de red y
Calico fue el único que satisfizo todas las necesidades (debido al enfoque utilizado en el nivel L3). Se adapta perfectamente al modelo de infraestructura de red existente.
Como quería usar todos los elementos de infraestructura disponibles, antes que nada, tuve que lidiar con nuestra utilidad de red local (utilizada en todos los servidores): úsela para anunciar rangos de direcciones IP en una red con nodos Kubernetes. Permitimos que Calico asigne direcciones IP a los pods, pero no lo usamos y aún no lo usamos para sesiones de BGP en equipos de red. De hecho, el enrutamiento es manejado por Exabgp, que anuncia las subredes utilizadas por Calico. Esto nos permite llegar a cualquier pod desde la red interna (y en particular desde los equilibradores de carga).
Cómo gestionamos el tráfico de ingreso
Para redirigir las solicitudes entrantes al servicio deseado, se decidió utilizar Ingress Controller debido a su integración con los recursos de ingreso de Kubernetes.
Hace tres años, nginx-ingress-controller era el controlador más maduro: Nginx se ha utilizado durante mucho tiempo y es conocido por su estabilidad y rendimiento.
En nuestro sistema, decidimos colocar los controladores en servidores blade dedicados de 10 gigabits. Cada controlador se conectó al punto final del kube-apiserver del grupo correspondiente. Exabgp también se utilizó en estos servidores para anunciar direcciones IP públicas o privadas. La topología de nuestra red nos permite usar BGP desde estos controladores para enrutar todo el tráfico directamente a los pods sin usar un servicio como NodePort. Este enfoque ayuda a evitar el tráfico horizontal entre nodos y mejora la eficiencia.
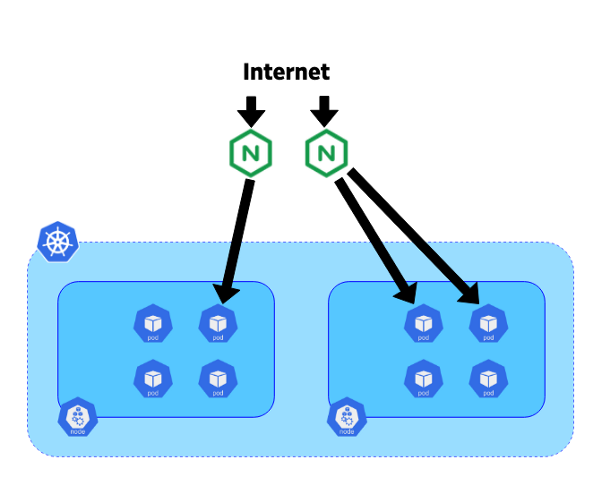 El movimiento del tráfico de Internet a las cápsulas.
El movimiento del tráfico de Internet a las cápsulas.Ahora que ha descubierto nuestra plataforma híbrida, puede profundizar en el proceso de migración de tráfico.
Migración del tráfico de Google Cloud a la infraestructura de Dailymotion
Otoño 2018
Después de casi dos años de crear, probar y configurar, finalmente obtuvimos una pila completa de Kubernetes, lista para recibir parte del tráfico.

La estrategia de enrutamiento actual es bastante simple, pero satisface bastante las necesidades. Además de la IP pública (en Google Cloud y Dailymotion), AWS Route 53 se usa para establecer políticas y redirigir a los usuarios al clúster de nuestra elección.
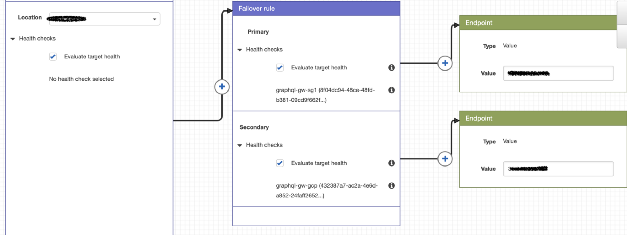 Ejemplo de política de enrutamiento con la ruta 53
Ejemplo de política de enrutamiento con la ruta 53Con Google Cloud, es fácil, porque usamos una única IP para todos los clústeres, y el usuario es redirigido al clúster GKE más cercano. La tecnología es diferente para nuestros clústeres porque sus IP son diferentes.
Durante la migración, buscamos redirigir las solicitudes regionales a los grupos respectivos y evaluamos las ventajas de este enfoque.
Dado que nuestros clústeres GKE están configurados para escalar automáticamente utilizando métricas personalizadas, aumentan / disminuyen la potencia según el tráfico entrante.
En modo normal, todo el tráfico regional se dirige al clúster local y GKE sirve como reserva en caso de problemas (la Ruta 53 realiza controles de estado).
...
En el futuro, queremos automatizar completamente las políticas de enrutamiento para obtener una estrategia híbrida autónoma que mejore constantemente la accesibilidad del usuario. En cuanto a las ventajas: el costo de la nube se redujo significativamente e incluso logró reducir el tiempo de respuesta de la API. Confiamos en la plataforma en la nube resultante y estamos listos para redirigir más tráfico a ella si es necesario.
PD del traductor
También podría estar interesado en otra publicación reciente de Dailymotion sobre Kubernetes. Se dedica a implementar aplicaciones de Helm en muchos grupos de Kubernetes y
se publicó hace aproximadamente un mes.
Lea también en nuestro blog: