
La solución del problema del reconocimiento de imágenes (OCR) está llena de diversas dificultades. Esa imagen no se puede reconocer debido al esquema de color no estándar o debido a la distorsión. Que el cliente quiere reconocer todas las imágenes sin restricciones, y esto está lejos de ser siempre posible. Los problemas son diferentes y no siempre es posible resolverlos de inmediato. En esta publicación, daremos algunos consejos útiles basados en la experiencia de resolver situaciones reales con los clientes.
Pero primero, un poco de historia. Ha pasado mucho tiempo desde la publicación del artículo sobre
cómo reescribimos el servicio de filtrado . En él, hablamos un poco sobre el filtrado y el procesamiento de mensajes, sobre cómo está organizado nuestro servicio de filtrado en su conjunto. Esta vez trataremos de responder la pregunta "¿Cómo procesamos las imágenes, cómo interactúan los servicios y qué le sucede al sistema bajo carga?" Si operamos en un artículo sobre un servicio de filtrado, ahora consideraremos solo una interacción de rama de servicio: esta es la interacción de un servicio de filtrado y OCR.
¿Qué es un OCR?
Antes de hablar sobre la interacción de los servicios y los problemas de usar OCR, tratemos de entender qué es OCR. Tome la definición
complicada de Wikipedia.
Reconocimiento
óptico de caracteres (OCR): la traducción mecánica o electrónica de imágenes de texto manuscritas, mecanografiadas o mecanografiadas en datos de texto utilizados para representar caracteres en una computadora (por ejemplo, en un editor de texto).
En pocas palabras, tomaron una foto, la enviaron para su reconocimiento, luego la
magia estaba fuera de Hogwarts y recibieron el texto.

También puede tomar la definición de OCR del sitio web de ABBYY, que parece más simple.
El reconocimiento óptico de caracteres (OCR) es una tecnología que le permite convertir varios tipos de documentos, como documentos escaneados, archivos PDF o fotos desde una cámara digital, en formatos editables de búsqueda.
¿Y por qué necesitamos (reconocimiento de imagen)?
Podemos utilizar el reconocimiento de imágenes incluso en una PC doméstica para convertir imágenes digitales en datos de texto editables, pero la tarea que tenemos ante nosotros es mucho más amplia (un sistema DLP después de todo): necesitamos controlar el flujo de información en la organización.
Los sistemas DLP han aparecido en el mercado desde hace mucho tiempo y ahora forman parte del arsenal familiar de sistemas de seguridad de la información corporativa (herramientas de protección de la información). DLP se enfrenta a la tarea de controlar el movimiento de la información gráfica (documentos escaneados, capturas de pantalla, fotos). Y no solo controla el movimiento de los archivos gráficos, sino, en primer lugar, el análisis de sus contenidos. El sistema debería ser capaz de comprender exactamente qué información encontró, compararla con muestras de información protegida y proporcionar oportunidades para que el usuario busque más esta información. El uso de otras herramientas de análisis, como la comparación con huellas digitales, cálculo hash, análisis por formato de archivo, tamaño y estructura, también son fuentes valiosas de información, pero no permiten responder a la pregunta: "¿qué texto se transmite en esta imagen?" Mientras tanto, el texto sigue siendo el portador más común de información estructurada, incluso en archivos gráficos.
Tradicionalmente, la tecnología OCR se usa para reconocer información gráfica (lo que ya hemos determinado). De hecho, OCR es generalmente la única clase de tecnologías que proporcionan la capacidad de extraer información de texto de imágenes. Por lo tanto, no se trata tanto del enfoque tradicional, sino de la falta de opciones.
¿Cuántas imágenes se procesan por sistema DLP?
¿No puedes prescindir de OCR? ¿Realmente hay tantas imágenes en DLP que necesita aplicar OCR? La respuesta a esta pregunta es "¡Sí!". Más de un millón de imágenes pueden ingresar al sistema por día, y todas estas imágenes pueden contener texto.
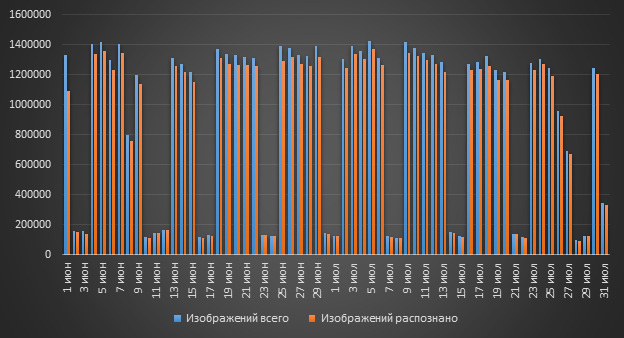
OCR como parte del sistema Rostelecom-Solar DLP es utilizado por compañías de petróleo y gas y agencias gubernamentales. Todos los clientes usan OCR para detectar datos confidenciales en documentos escaneados. ¿Qué puede contener ese "horario"? Si, cualquier cosa. Estos pueden ser escaneos de varios documentos internos, por ejemplo, que contienen PD. O información de la categoría de secretos comerciales, aglomerado (para uso oficial), estados financieros, etc.
¿Cómo reconoce OCR las imágenes?
El proceso es el siguiente: DLP intercepta un mensaje que contiene una imagen (escaneo de documentos, fotografía, etc.), determina que la imagen está realmente en el mensaje, lo extrae y lo envía a OCR para su reconocimiento. En la salida, el DLP recibe información sobre el contenido de la imagen (y el mensaje como un todo) en forma de TEXTO / LLANO extraído.
Si hablamos de la interacción de los servicios directamente en nuestro sistema Solar Dozor, el servicio de filtrado envía imágenes (si las hay) del mensaje al servicio de extracción de texto de imagen (OCR). Este último, después de completar el reconocimiento, envía el texto recibido a mailfilter. Resulta algo como hacer malabares con imágenes y texto.

Consideremos el mecanismo de reconocimiento más profundo por el ejemplo de las tecnologías OCR ABBYY, que usamos en nuestro propio DLP.
Quizás el principal problema para OCR al reconocer texto es la ortografía de un carácter. Si tomamos cualquier letra del alfabeto (por ejemplo, ruso o inglés), encontraremos varias opciones de ortografía para cada una. Los motores OCR resuelven este problema de varias maneras:
- Encontrar un personaje por patrón. Por ejemplo, usando una variedad de fuentes de ortografía.
- Identificación de signos para escribir un personaje.
Si da un ejemplo de trabajo bastante burdo, entonces OCR divide el texto en caracteres que previamente identificó en la imagen, y los impone en plantillas listas para usar. Luego se verifica si el símbolo parece una ortografía de plantilla o no. Cuando se identifica un carácter, se convierte al código de caracteres en la codificación utilizada. Como resultado de este proceso, los símbolos se agregan en palabras, oraciones en el texto final.
Hay muchos artículos diferentes sobre el trabajo de OCR. Puede leer más sobre el trabajo de OCR, por ejemplo, aquí
https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/¿Cómo preparar OCR en su conjunto para el reconocimiento?
Ya hemos descubierto que más de un millón de imágenes pueden ingresar a DLP. ¿Pero nos son útiles todas las imágenes de este millón?
La respuesta a la pregunta es más que obvia, por supuesto que no. Pero, ¿por qué no todas las imágenes nos serán útiles? La respuesta a esta pregunta también es bastante transparente: muchas fotos de firmas en mensajes "caminan" por correo. Probablemente el 90% de los mensajes (si no más) contendrán el logotipo de la empresa.
Estas imágenes son demasiado pequeñas para su reconocimiento; puede que no haya ningún texto en ellas. Aquí podemos aconsejar (e incluso recomendar) establecer restricciones en el tamaño de las imágenes reconocidas. En este caso, las restricciones deben establecerse tanto en el límite inferior como en el superior. La probabilidad de enviar archivos pesados para su procesamiento es menor que para las imágenes de una firma, pero sigue siendo bastante alta.Vale la pena señalar que las imágenes digitales a menudo tienen diferentes defectos. Es poco probable que DLP siempre obtenga escaneos de documentos en buena resolución. Por el contrario, los escaneos no siempre serán de la mejor calidad y con muchos defectos.
Por ejemplo, en una foto digital, la perspectiva puede estar distorsionada, puede estar resaltada o invertida, las líneas de escaneo pueden estar curvadas. Tal distorsión puede complicar el reconocimiento. Por lo tanto, los motores OCR pueden preprocesar imágenes para prepararlas para el reconocimiento. Por ejemplo, una imagen se puede torcer, convertir a blanco y negro, invertir colores y corregir líneas oblicuas.
Todo esto se puede establecer en la configuración de OCR y, como resultado, estas herramientas pueden ayudar a mejorar el reconocimiento de texto en las imágenes.Como resultado, llegamos a los principios básicos de la preparación de OCR para el reconocimiento:
- Determine los tamaños de las imágenes que reconoceremos, tanto en píxeles como en Mb.
- Habilite el preprocesamiento de imágenes.
Para aumentar la eficiencia del OCR, también puede almacenar en caché los datos reconocidos para no enviar las mismas imágenes varias veces para su reconocimiento.
A qué más debe prestar atención cuando prepare el OCR, describiremos a continuación ejemplos de uso de esta tecnología en la práctica de combate.
¿Qué desafíos son posibles cuando se usa OCR en DLP bajo una carga pesada?
1. Límites demasiado amplios en el tamaño de las imágenes reconocidas.Comencemos con lo que ya hemos mencionado, con límites.
Según nuestra práctica, los clientes suelen establecer límites demasiado amplios en el tamaño de los archivos de imagen reconocidos. Sí, para que OCR funcione bien, debe limitar el tamaño de las imágenes. Pero los clientes se esfuerzan por controlar todo, creyendo que incluso en una imagen de 100x100 píxeles y 5 KB de tamaño, se pueden filtrar datos valiosos. En general, por supuesto, 100x100 píxeles y 5 Kb también son limitaciones, pero estos umbrales son demasiado bajos.
El otro extremo es el deseo de reconocer archivos pesados de varios cientos de MB. Está claro que tales imágenes no se rastrearán a través del correo corporativo debido a restricciones en el tamaño de los mensajes enviados. Pero aquí, en otros canales de interceptación (por ejemplo, desde la red de la red corporativa), los archivos pesados persisten en reconocer. Si el cliente desea agregar a esto una gran cantidad de imágenes de alta resolución, entonces para esto necesita tener las capacidades de servidor apropiadas. Como resultado, con tales umbrales mínimos y máximos tan amplios para el tamaño de los archivos reconocidos, se crea una alta carga de procesador en los servidores, lo que ralentiza el funcionamiento de todos los subsistemas.
¿Qué se puede recomendar aquí? En primer lugar, analice qué "cronograma" utilizado por la empresa contiene datos confidenciales y luego calcule las restricciones mínimas y máximas razonables en el tamaño de las imágenes monitoreadas. Por lo general, recomendamos que los clientes fijen el límite inferior de resolución de imagen de 200 píxeles, idealmente de 400 píxeles (a lo largo de los ejes X e Y), y tamaños de archivo de al menos 20 Kb, mejor aún más. Tampoco tiene sentido enviar imágenes pesadas a OCR: simplemente sobrecargarán sus servidores y no el hecho de que serán reconocidas.2. Filtrado de colas y tiempos de espera de procesamiento de solicitudesLa carga excesiva en los servidores, que surge por las razones anteriores, lleva a lo largo de la cadena a aumentar el tiempo de reconocimiento de imágenes y procesamiento de consultas en general. Como resultado, la cola de mensajes para el filtrado comienza a aumentar en el sistema DLP. Además, los archivos gráficos que no se pueden reconocer en principio (archivos pesados, mala calidad, etc.) pueden llegar al módulo OCR, lo que resulta en tiempos de espera de procesamiento de imágenes. Si hay muchos archivos no reconocidos y el sistema tiene tiempos de espera de alto reconocimiento, el servicio de filtrado espera hasta que se produzca este tiempo de espera y solo entonces procesa la siguiente solicitud. Todo el proceso de procesamiento puede ser seriamente inhibido.
¿Qué podemos aconsejar? Si hay una cola para procesar imágenes gráficas, debe mirar la configuración de OCR en el sistema DLP e intentar encontrar la causa del frenado. Esto puede ocurrir, por ejemplo, debido a problemas de comunicación entre procesos en el propio servidor. En general, estos problemas merecen una discusión por separado. Algunos detalles sobre cuestiones generales se pueden encontrar en el artículo "Introducción a la comunicación entre procesos en Linux" .Además, un punto importante al configurar OCR es establecer tiempos de espera adecuados para el reconocimiento de imágenes. En general, 90 segundos son suficientes para que la imagen se reconozca con precisión. Si no se extrajo texto de la imagen en 90 segundos, entonces se puede suponer que OCR no reconoce la imagen en principio. En este punto, los problemas de configuración de OCR también pueden ocurrir cuando establecen tiempos de espera de reconocimiento altos y, por lo tanto, intentan reconocer lo no reconocido.¿Qué más podría causar un tiempo de espera? Aquí volvemos al tema de la configuración del sistema. El servicio de filtrado, como el servicio de OCR, opera con hilos que procesan mensajes e imágenes. Es posible que el sistema no esté configurado correctamente en términos de la cantidad de controladores de servicio de filtrado y la cantidad de controladores de OCR. Por ejemplo, un servicio de filtrado tendrá muchos manejadores de subprocesos, mientras que OCR tendrá solo uno. En tal situación, en algunos puntos, OCR puede simplemente no tener tiempo para procesar todas las solicitudes de reconocimiento y, por lo tanto, aparecerán tiempos de espera de procesamiento de imágenes.
Este comportamiento del sistema sugiere ideas sobre problemas de diseño y errores en la arquitectura, pero de hecho no lo es. La arquitectura de nuestro DLP proporciona la flexibilidad para configurar el sistema y personalizarlo según las necesidades de los clientes. Por ejemplo, simplemente podemos configurar un OCR para que funcione con dos servicios de filtrado sin sacrificar el rendimiento.
3. Imágenes no reconocidasSi una imagen que el OCR no puede reconocer ingresa al sistema DLP para su análisis, hay varias soluciones al problema.
¿Por qué motivos pueden no reconocerse las imágenes? Por ejemplo, por lo siguiente:
1. Esquema de color no estándar de la imagen.
2. Imagen de baja resolución.
3. Orientación incorrecta de la imagen y el texto que contiene en el espacio.
4. Desviaciones de línea y distorsión de las proporciones del texto en la imagen, etc.
Aquí hay un ejemplo: uno de los clientes durante el proceso de monitoreo descubrió que OCR no reconoce los documentos pdf ejecutados en un esquema de color no estándar. Es decir, la imagen se extrajo del documento PDF en el modo normal, pero cuando se trataba de procesar el módulo OCR, no entendió el esquema de color de la imagen y produjo el "cuadrado de Malevich" en la salida. En nuestra interfaz, la imagen se parecía a esto:
 Los motores OCR tienen varias funciones para la corrección automática de imágenes, lo que aumenta en gran medida las posibilidades de reconocimiento exitoso del texto contenido en él. Sin embargo, en la práctica, estas herramientas mágicas no siempre funcionan. En este caso particular, hemos personalizado el módulo OCR para el cliente para que reconozca este esquema de color no estándar.
Los motores OCR tienen varias funciones para la corrección automática de imágenes, lo que aumenta en gran medida las posibilidades de reconocimiento exitoso del texto contenido en él. Sin embargo, en la práctica, estas herramientas mágicas no siempre funcionan. En este caso particular, hemos personalizado el módulo OCR para el cliente para que reconozca este esquema de color no estándar.5. La inconsistencia de uno de los parámetros del documento a los tamaños especificados reconocidos
imágenes
Por ejemplo, en la configuración del sistema, los límites de tamaño de las imágenes reconocidas se establecen en 200x1000 píxeles y se recibe un archivo de 500x1500 píxeles en OCR (límite superior excedido).
En este caso, debe corregir la configuración de OCR para reconocer dichas imágenes.Este es quizás uno de los escenarios de reconfiguración del sistema más populares después de que se nos dice que OCR no funciona.
¿Por qué OCR no está en los agentes?
OCR en sistemas DLP se implementa en dos versiones: en agentes y en servidores. Estamos a favor del segundo enfoque, ya que el reconocimiento de imágenes directamente en la estación de trabajo crea una gran carga en su procesador y, en consecuencia, ralentiza el trabajo de otras aplicaciones. El OCR en sí es una tecnología muy voraz, incluso para servidores, y su aplicación requiere una planificación adecuada de las capacidades del procesador y la supervisión del rendimiento.
Sin embargo, muchas empresas nacionales, especialmente en el sector público, aún poseen una flota de PC bastante antigua. ¿Qué pasa en este caso? Los usuarios comienzan a quejarse al departamento de TI sobre el "frenado" de la PC, y los especialistas de TI finalmente descubren que la causa del frenado es el módulo OCR del sistema DLP. Esto los molesta y los usuarios que no pueden resolver rápidamente las tareas de trabajo. Al final, todo esto se suma a un dolor de cabeza para un guardia de seguridad que tiene muchas otras tareas.
El uso de OCR en agentes se justifica solo cuando el sistema DLP funciona "de forma aislada". En este caso, el reconocimiento de imágenes debe ocurrir exactamente en el momento en que el usuario realiza acciones con este archivo gráfico en su estación de trabajo. Es decir, el sistema DLP debería decidir instantáneamente el destino del documento que contiene esta imagen: permitir que se envíe / copie o prohíba. Pero en la práctica, solo unos pocos clientes usan el sistema DLP en modo de bloqueo activo, y esto se aplica no solo a nuestro propio DLP. Aquí el principio funciona: "todo lo que se puede sacar para verificar en el servidor debe realizarse en el servidor".
Total
Las tecnologías OCR proporcionan capacidades de reconocimiento gráfico y, además, siempre ofrecemos recomendaciones generales para la configuración del sistema. Sin embargo, en un proyecto en particular, puede ser necesario reconfigurar el módulo OCR para satisfacer las necesidades específicas del cliente tanto en las etapas de puesta a prueba e implementación de la solución como en la etapa de su operación industrial. Esto no es solo normal: es la única forma correcta de dar resultados tangibles, hacer que el OCR funcione en la empresa de la manera más eficiente posible y minimizar la filtración de información confidencial a través de imágenes gráficas.
Nikita Igonkin, ingeniero de servicio líder, Rostelecom Solar