Hola a todos! En junio se celebró en Novosibirsk una conferencia sobre el desarrollo de aplicaciones altamente cargadas HighLoad ++ Siberia 2019. Anteriormente en los artículos sobre Habré, mencionamos que en Plesk realizamos una retrospectiva de conferencias e informes a los que asistimos para no perder el conocimiento adquirido y posteriormente aplicarlos. Le diremos qué informes notamos para nosotros y también compartiremos con usted una receta retrospectiva. Los organizadores están publicando gradualmente el video aquí:
canal de youtube . Parte de lo que estamos describiendo ya se puede ver.
Resumen de informes
Victor Eremchenko (Miro)Este es un informe de revisión sobre la migración exitosa de Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. El autor ofrece esquemas, trampas típicas de soluciones obvias, habla sobre soluciones alternativas y por qué no encajan. De lo interesante:
- Los ingenieros de Miro han reunido su solución para no pagar Amazon RDS, y esta solución hasta ahora les conviene.
- Likbez sobre gestores de conexión para PostgreSQL.
- Describe el proceso de actualización de nodos del clúster sin detener la aplicación.
- Muestra un truco para actualizar rápidamente PostgreSQL.
Es útil ver aquellos que usan o van a usar PostgreSQL y que tienen una cantidad creciente de datos.
Vasily Bogonatov (Yandex)Como orador introductorio, hizo una breve comparación de algunas características de Kafka y RabbitMQ. Brevemente: Kafka: una cola simple, un receptor complejo; RabbitMQ es una cola compleja, un receptor simple. El autor también habló sobre los tipos de garantías para entregar mensajes desde la cola. Nota importante: ninguna cola puede garantizar la entrega de un mensaje exactamente 1 vez sin soporte en el remitente y el destinatario.
El informe está dedicado a YandexMQ. YandexMQ (YMQ) es una API compatible con la cola de Amazon SQS. La base de YandexMQ es la base de datos Yandex (YDB). Vasily mostró la ventaja de YandexMQ, cómo lograr una consistencia y confiabilidad estrictas, y revisó la arquitectura de YMQ. YMQ implementa el patrón de consumidores competidores: un mensaje para un consumidor. Chip YMQ: cuando el consumidor solicita un mensaje, se oculta en la cola para que nadie más lo procese. Si hay problemas durante el procesamiento, luego de VisibilityTimeout el mensaje vuelve a estar visible en la cola. El orador afirma que Apache Kafka tiene un problema de pérdida de datos cuando el proceso se detiene repentinamente, Yandex MessageQueue es resistente a esto.

El informe se recomienda a todos los que quieran comprender las características fundamentales de las colas.
Ivan Muratov (Primera Compañía de Monitoreo)Informe sobre cómo almacenar y procesar datos en la serie temporal de PostgreSQL.
TimescaleDB le permite almacenar grandes volúmenes debido a la partición astuta, y PipelineDB proporciona trabajo con secuencias directamente en PostgreSQL (así como la integración con colas).
TimescaleDB:
- Tiene una velocidad de grabación muy estable con un aumento en el volumen de la base de datos bajo cargas pesadas y con un aumento en el número de particiones, medido en miles.
- Le permite usar características estándar de PostgreSQL como SQL, replicación, copia de seguridad, restauración, etc.
- Se anuncia un buen conjunto de integraciones, por ejemplo, con Prometheus, Telegraf, Grafana, Zabbix, Kubernetes.
- Hay una versión gratuita de código abierto.
La idea principal: TimescaleDB se necesita principalmente para almacenar datos.
PipelineDB:
- Le permite procesar continuamente datos entrantes usando SQL y agregar el resultado a una tabla.
- Tiene una interfaz SQL.
- Hay una ejecución de procedimientos almacenados bajo las condiciones.
- Las integraciones con Apache Kafka y Amazon Kinesis son posibles.
- Hay una versión gratuita de código abierto.
- El desarrollo de PipelineDB está congelado en la versión 1.0, y ahora solo se lanzan correcciones de errores.
La idea principal: PipelineDB es necesaria principalmente para el procesamiento de datos.
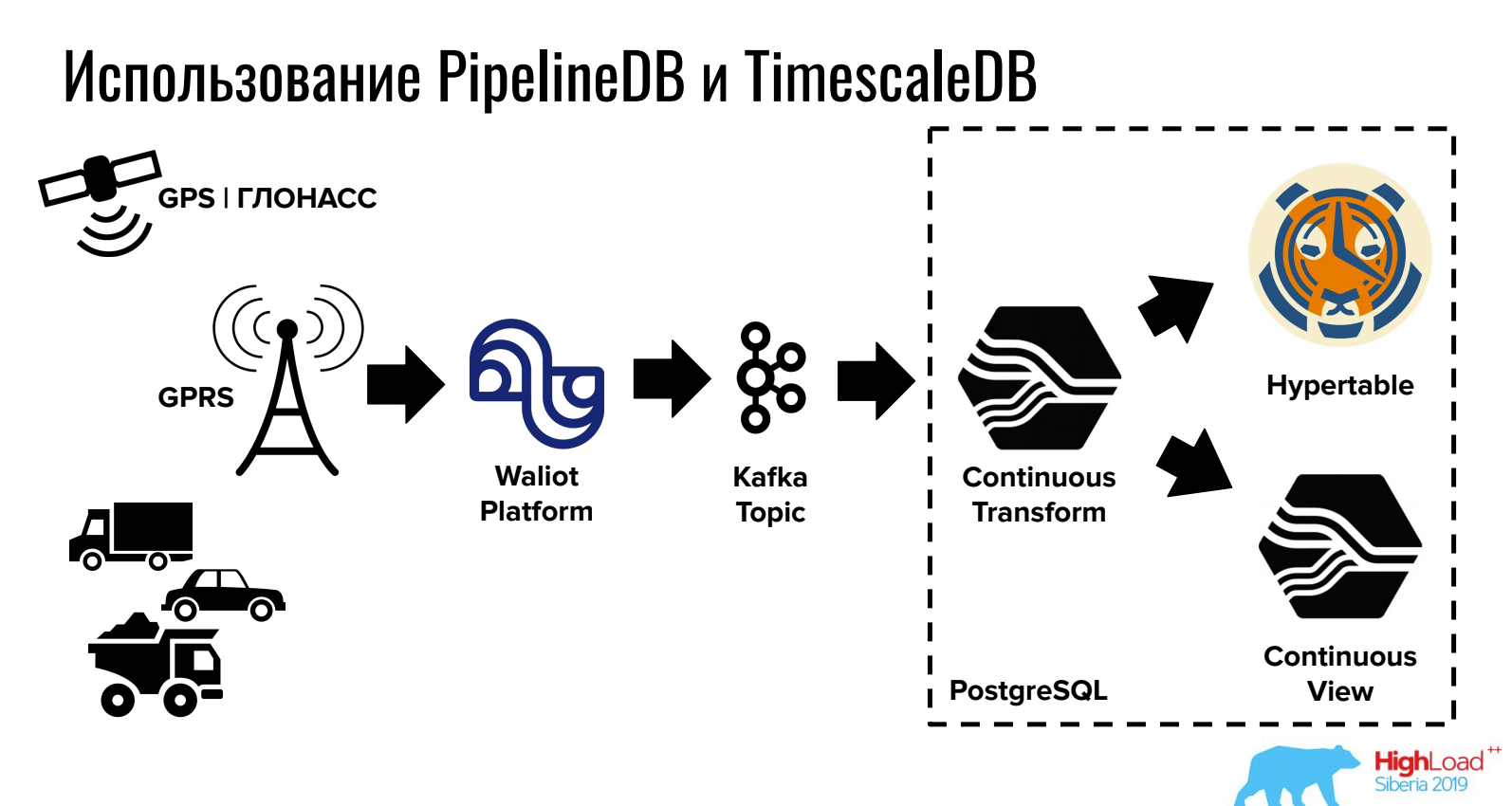
Para las tareas donde se necesitan un DBMS relacional, NoSQL y series de tiempo al mismo tiempo, esta opción puede ser bastante conveniente.
Pavel Luzanov (profesional de Postgres)Un buen informe general sobre PostgreSQL, herencia de tablas y rendimiento de Consejos y trucos de PostgreSQL 10, 11, 12+. Particionamiento a través de herencia, fragmentación. Es útil ver a todos los que usan PostgreSQL y quieren hacerlo un poco más rápido.
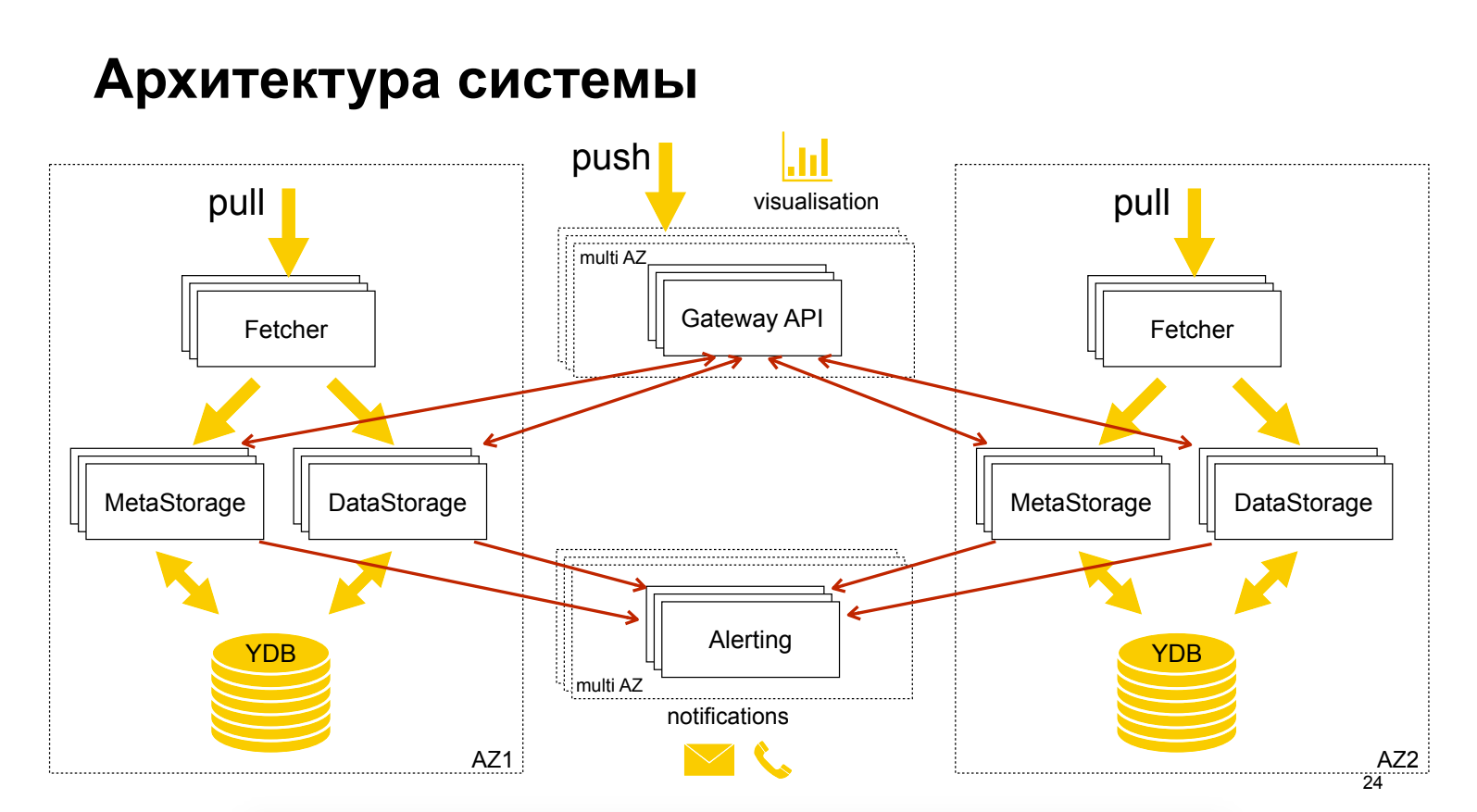
Sergey Polovko (Yandex)Acerca del producto en la nube Yandex Monitoring, que aún se encuentra en la etapa de "Vista previa", es gratuito. Bastante sobre arquitectura. Se muestra una técnica interesante: la separación de los metadatos de los datos, lo que permite una escala y optimización independientes. Grafana se utiliza como GUI, mientras que sus alertas no están en Grafana.
 Andrey Salnikov (Garceta de datos)
Andrey Salnikov (Garceta de datos)Experiencia en administración de sistemas comerciales de muchos servidores PostgreSQL. Indica qué parámetros del servidor se supervisan automáticamente y cómo se priorizan las tareas.
Data Egret utiliza la experiencia generalizada en el Wiki con recetas, listas de verificación: esta es la base para futuros artículos e informes. Utilizan una base de datos de incidentes con una descripción de problemas y soluciones, lo que ahorra recursos de manera significativa. Lanzó una serie de utilidades para trabajar con PostgreSQL, proporcionar enlaces a ellas.
 Evgeny Sokolov (Yandex.Market)
Evgeny Sokolov (Yandex.Market)Informe sobre la arquitectura de una aplicación Yandex.Market compleja, altamente accesible y distribuida, y sobre los procesos y herramientas para su desarrollo, prueba, actualización y monitoreo. De lo interesante:
- "Stop-crane" es su solución para la aplicación rápida y la reversión de la configuración, ayuda a probar nuevas funcionalidades.
- El tráfico se redirige desde el centro de datos actual por el equilibrador a otro centro de datos en caso de problemas.
- Grafito y Grafana se utilizan para el monitoreo.
- Hay monitoreo básico duplicado en otra pila de tecnología.
- Se utiliza un clúster Shadow para desarrolladores, que duplica parte del tráfico de usuarios. Los usuarios no ven las respuestas del clúster Shadow.
- Se realiza un cálculo automático de calidad durante las pruebas A / B.
 Anton Alekseev (2GIS)
Anton Alekseev (2GIS)Informe sobre qué ClickHouse es bueno y cómo cocinarlo junto con Grafana. El principal interesante:
- Si no hay suficiente velocidad, debe usar el muestreo (se argumenta que la precisión de los datos después del muestreo es suficiente). Muestreo en ClickHouse: el muestreo parcial de datos con agregación mientras se mantiene la relación de varios valores en la clave de la tabla, le permite acelerar la agregación en ocasiones y al mismo tiempo obtener un resultado muy cercano al real.
- ClickHouse puede usarse para investigar rápidamente incidentes (un ejemplo interesante en el informe).
- ClickHouse también tiene un MaterializedView para acelerar la recuperación.
- Se describe la interfaz HTTP ClickHouse para consultas y carga de datos.
En conclusión de la revisión de los informes, me gustaría señalar que también nos gustó mucho el informe
"Videollamadas: de millones por día a 100 participantes en una conferencia" (
Alexander Tobol / Odnoklassniki), que se incluyó en la lista de los mejores informes de la conferencia según los resultados de la votación. Este es un gran resumen de cómo funciona la videoconferencia para un grupo de participantes. El informe se distingue por una presentación sistémica comprensible. Si de repente tiene que hacer videollamadas, puede ver el informe para obtener rápidamente información sobre el tema.
Estructura de Flashback de la Conferencia de Plesk
Y ahora, de postre, sobre cómo escribimos una retrospectiva dentro de la empresa. En primer lugar, tratamos de escribir retro en la primera semana después de asistir a la conferencia, mientras nuestros recuerdos aún están frescos. Por cierto, el material retrospectivo puede servir como base para el artículo, como puede suponer;)
El propósito de escribir una retrospectiva no es solo consolidar el conocimiento, sino también compartirlo con aquellos que no estuvieron en la conferencia, sino que desean mantenerse al tanto de las últimas tendencias, soluciones interesantes. Una lista preparada ayuda a reducir el tiempo de búsqueda de informes interesantes para ver. Escribimos las lecciones que hemos aprendido por nosotros mismos, marcamos a personas específicas con una nota, por qué necesita ver el informe y pensar en las ideas y decisiones de los demás. Las lecciones escritas ayudan a enfocar y no perder lo que queríamos hacer. Mirando las grabaciones en 3-6 meses, entenderemos si nos hemos olvidado de algo importante.
Almacenamos documentación en la empresa en Confluence, para conferencias tenemos un árbol de páginas separado, un trozo de madera:
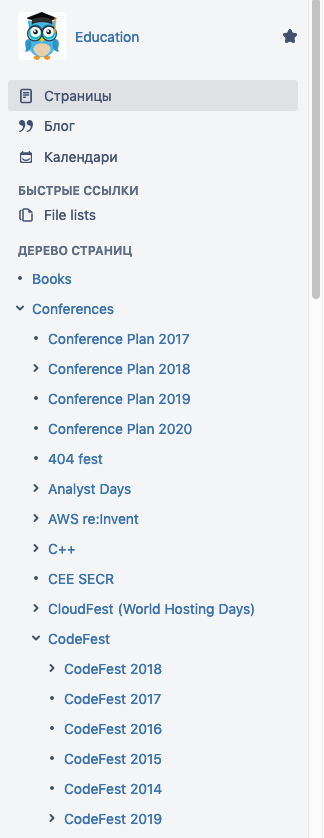
Como se puede ver en la captura de pantalla, presentamos los materiales por año para facilitar la navegación.
Dentro de la página dedicada a una conferencia en particular, almacenamos las siguientes secciones: resumen con enlaces al sitio web del evento, calendario, videos y presentaciones, lista de participantes (en persona y en transmisiones), impresión general (impresión general) y resumen detallado (resumen detallado) ) Por cierto, generamos una página para retro a partir de una plantilla en la que toda la estructura ya existe. También creamos el contenido de los títulos para que pueda ver muy rápidamente la lista de informes y pasar al deseado.
La sección Impresión general ofrece una breve evaluación de la conferencia y las impresiones de los participantes. Si los participantes estuvieron en la conferencia en los últimos años, pueden comparar sus niveles y, en general, comprender la utilidad de asistir al evento.
La sección Resumen detallado contiene una tabla:

Un ejemplo de llenar una tabla:

Nos interesaría conocer los informes que le gustaron en Highload Siberia 2019, así como su experiencia en la realización de retrospectivas.